Java数据结构第二十七期:布隆过滤器,用 “模糊” 换高效的查重黑科技



专栏:Java数据结构秘籍
个人主页:手握风云
目录
一、布隆过滤器的提出
二、布隆过滤器的概念
三、布隆过滤器的插入
四、布隆过滤器的查找
五、布隆过滤器的模拟实现
六、布隆过滤器的删除
七、布隆过滤器的优点
八、布隆过滤器的缺陷
九、布隆过滤器的应用场景
一、布隆过滤器的提出
日常生活中,包括在设计计算机软件时,我们经常要判断一个元素是否在一个集合中。比如在字处理软件中,需要检查一个英语单词是否拼写正确(也就是要判断它是否在已知的字典中);在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上;在网络爬虫里,一个网址是否被访问过等等。最直接的方法就是将集合中全部的元素存在计算机中,遇到一个新元素时,将它和集合中的元素直接比较即可。
一般来讲,计算机中的集合是用哈希表(hash table)来存储的。它的好处是快速准确,缺点是费存储空间。当集合比较小时,这个问题不显著,但是当集合巨大时,哈希表存储效率低的问题就显现出来了。
比如说,一个像 Yahoo、Hotmail 和 Gmai 那样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。
如果用哈希表,每存储一亿个 email 地址, 就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个 email 地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要1.6GB, 即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB 的内存。除非是超级计算机,一般服务器是无法存储的。
- 用哈希表存储用户记录,缺点:浪费空间;
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了;
- 将哈希与位图结合,即布隆过滤器;
二、布隆过滤器的概念
布隆过滤器是1970 年由布隆提出的概率型数据结构,用于高效判断一个元素是否存在于集合中。它通过多个哈希函数将元素映射到一个位图(BitMap)的不同位置,利用比特位的 “集体状态” 判断存在性,具有高空间效率和常数时间复杂度的查询 / 插入能力,但允许一定概率的误判(假阳性)。
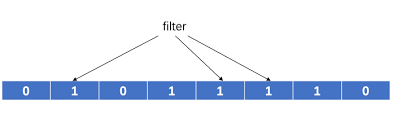
三、布隆过滤器的插入
比如下图中,插入"baidu"字符串通过3个哈希函数,3 个哈希函数映射到位图的位置 1、5、8,将对应索引的0置为1;插入"google"字符串映射到位置5、7、10。
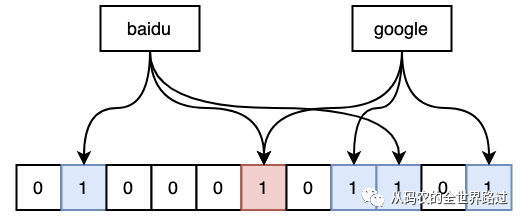
四、布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零, 代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
五、布隆过滤器的模拟实现
import java.util.BitSet;class SimpleHash {public int cap; // 当前容量public int seed; // 随机数public SimpleHash(int cap, int seed) {this.cap = cap;this.seed = seed;}}关于随机数的生成,我们可以看下HashMap.put()的源码。所以我们也可以自己实现
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}但是我们需要根据随机数的不同来生成随机函数。我们可以利用(cap-1)*seed & hash。
int hash(String key) {int h;// (n - 1) & hash找到数组下标// 将key的hashCode与自身右移16位后的结果进行异或运算,增加哈希的随机性return (key == null) ? 0 : (seed * (cap - 1)) & ((h = key.hashCode()) ^ (h >>> 16));
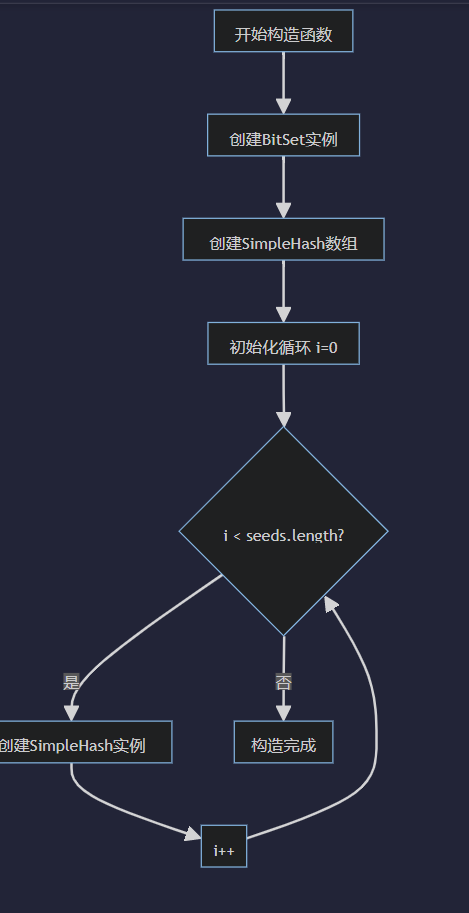
}接下来使用BitSet作为底层存储结构,它是一个位数组,默认大小为1 << 20。并且这里使用了多个通过HashSimpleHash对元素进行多次哈希计算定义了6个不同的种子值,每种子值对应一个哈希函数实例,用于产生不同的哈希值,这种多哈希函数的设计可以降低哈希冲突的概率。
public class MyBloomFilter {// 布隆过滤器的大小public static final int DEFAULT_SIZE = 1 << 20;public BitSet bitSet; //位图public int usedSize; // 已使用的位数public static final int[] seeds = {5, 7, 11, 13, 27, 33};public SimpleHash[] simpleHashes;// 初始化伪数组大小和哈希函数数组public MyBloomFilter() {bitSet = new BitSet(DEFAULT_SIZE);simpleHashes = new SimpleHash[seeds.length];for (int i = 0; i < seeds.length; i++) {simpleHashes[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);}}
}
接下来需要实现布隆过滤器的添加和查找方法。
/*** 向布隆过滤器中添加元素* @param val 需要添加的元素*/
public void add(String val) {}/*** 判断布隆过滤器中是否包含指定元素,存在一定误判性* @param val 需要判断的元素* @return 如果包含返回true,否则返回false*/
public boolean contains(String val) {}当添加元素时:使用多个不同的哈希函数对元素进行哈希计算;将每个哈希值对位数组长度取模,得到多个位置;将这些位置在位数组中对应的比特位设置为1。
/*** 向布隆过滤器中添加元素* @param val 需要添加的元素*/
public void add(String val) {// 让多个哈希函数分别处理当前数据for (SimpleHash simpleHash : simpleHashes) {int index = simpleHash.hash(val);// 将对应位置的bit设置为1bitSet.set(index);}
}查询时,用同样的哈希函数计算位置,检查所有对应位是否都为1。对于每个哈希函数,计算输入值val的哈希值,得到在位数组中的位置。检查位数组中这些位置是否都为1:如果有任何一位为0,则该元素一定不存在于集合中,返回false;如果所有位都为1,则该元素可能存在于集合中,返回true。
/*** 判断布隆过滤器中是否包含指定元素,存在一定误判性* @param val 需要判断的元素* @return 如果包含返回true,否则返回false*/
public boolean contains(String val) {if (val == null) {return false;}// 让多个哈希函数分别处理当前数据for (SimpleHash simpleHash : simpleHashes) {int index = simpleHash.hash(val);// 如果有一个位置的bit为0,则说明该元素一定不存在if (!bitSet.get(index)) {return false;}}return true;
}测试用例:
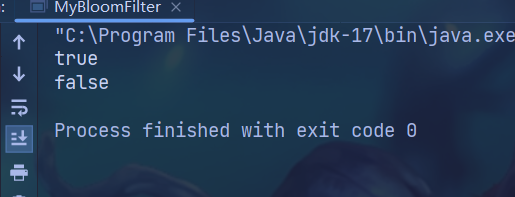
public static void main(String[] args) {MyBloomFilter myBloomFilter = new MyBloomFilter();myBloomFilter.add("Baidu");myBloomFilter.add("Google");myBloomFilter.add("bytedance");myBloomFilter.add("Facebook");myBloomFilter.add("YouTube");myBloomFilter.add("Tencent");System.out.println(myBloomFilter.contains("Baidu"));System.out.println(myBloomFilter.contains("MicroSoft"));
}
六、布隆过滤器的删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。比如我们把"Baidu"的位置都置为0,就会影响到"Google"的映射。
七、布隆过滤器的优点
- 增加和查询元素的时间复杂度为:0(K),(K为哈希的数的个数,一般比较小),与数据量大小无关;
- 哈希函数相互之间没有关系,方便硬件并行运算;
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势;
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算。
八、布隆过滤器的缺陷
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中;
- 不能获取元素本身;
- 一般情况下不能从布隆过滤器中删除元素。
九、布隆过滤器的应用场景
- 网贡爬虫对URL的去重,避免爬去相同的URL地址;
- 垃圾邮件过滤,从数十亿个垃圾邮件列表中判断某邮箱是否是垃圾邮箱;
- 解决数据库缓存击穿,黑客攻击服务器时,会构建大量不存在于缓存中的key向服务器发起请求,在数据量足够大的时候,频繁的数据库查询会导致挂机。