基于RAG的法律条文智能助手(方案篇)-实现与部署-微调与部署
基于RAG的法律条文智能助手-方案与数据
一、项目目标
- 掌握法律智能问答系统的需求分析与RAG技术选型逻辑
- 学会法律条文数据爬取、清洗与结构化处理
- 实现RAG与Lora微调结合的模型优化方案
二、项目内容与重点
1. 项目背景与需求设计
核心需求
- 场景:法律条文智能问答系统,需满足:
- 每月更新最新法律条文
- 支持条款精准引用(如“《劳动法》第36条”)
- 处理复杂查询(如劳动纠纷中的多条款关联分析)
技术选型:RAG vs 微调
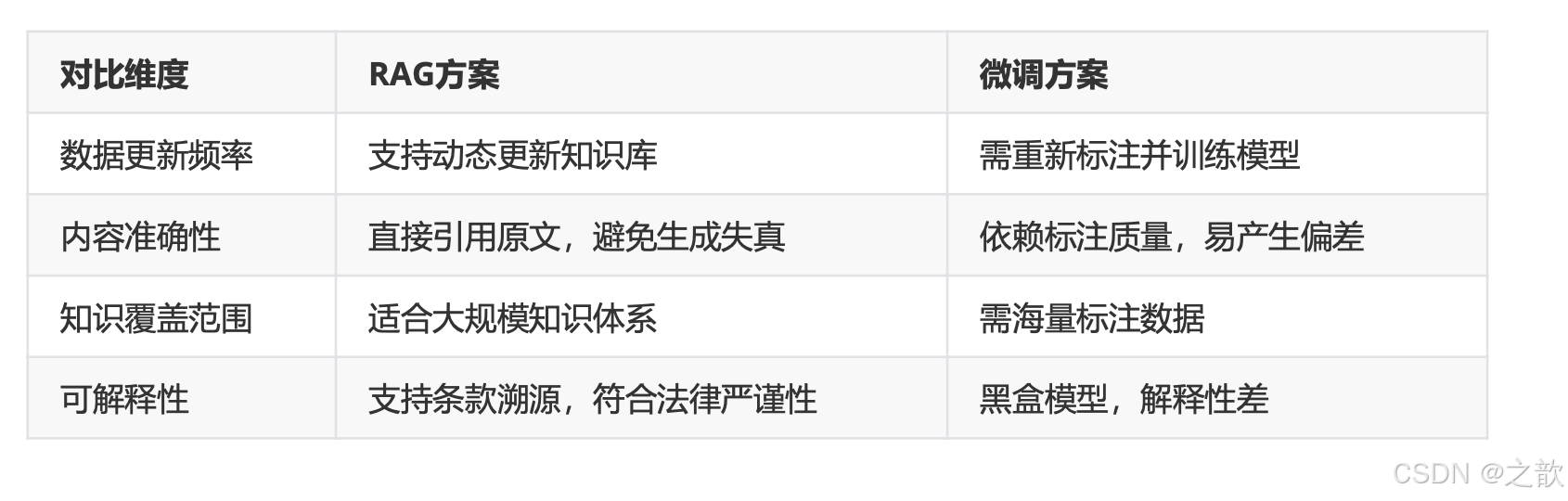
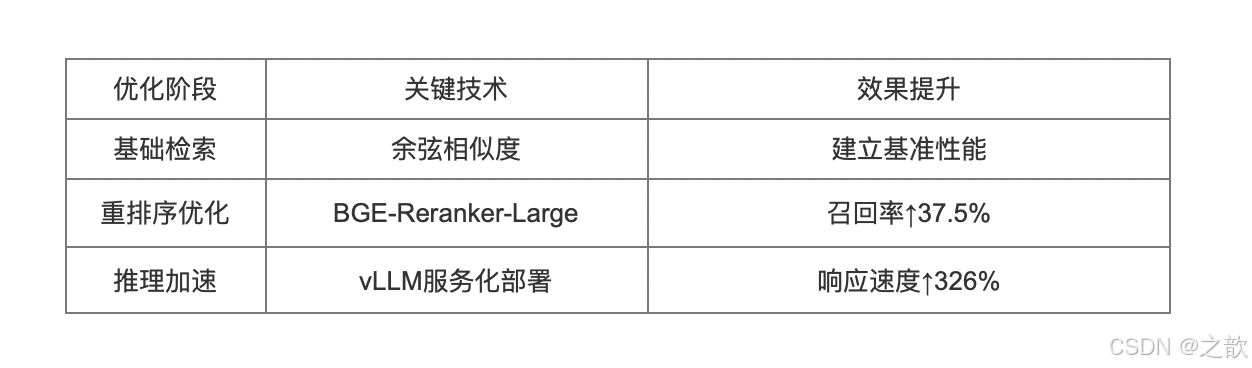
重点:RAG在动态更新和可解释性上的优势。
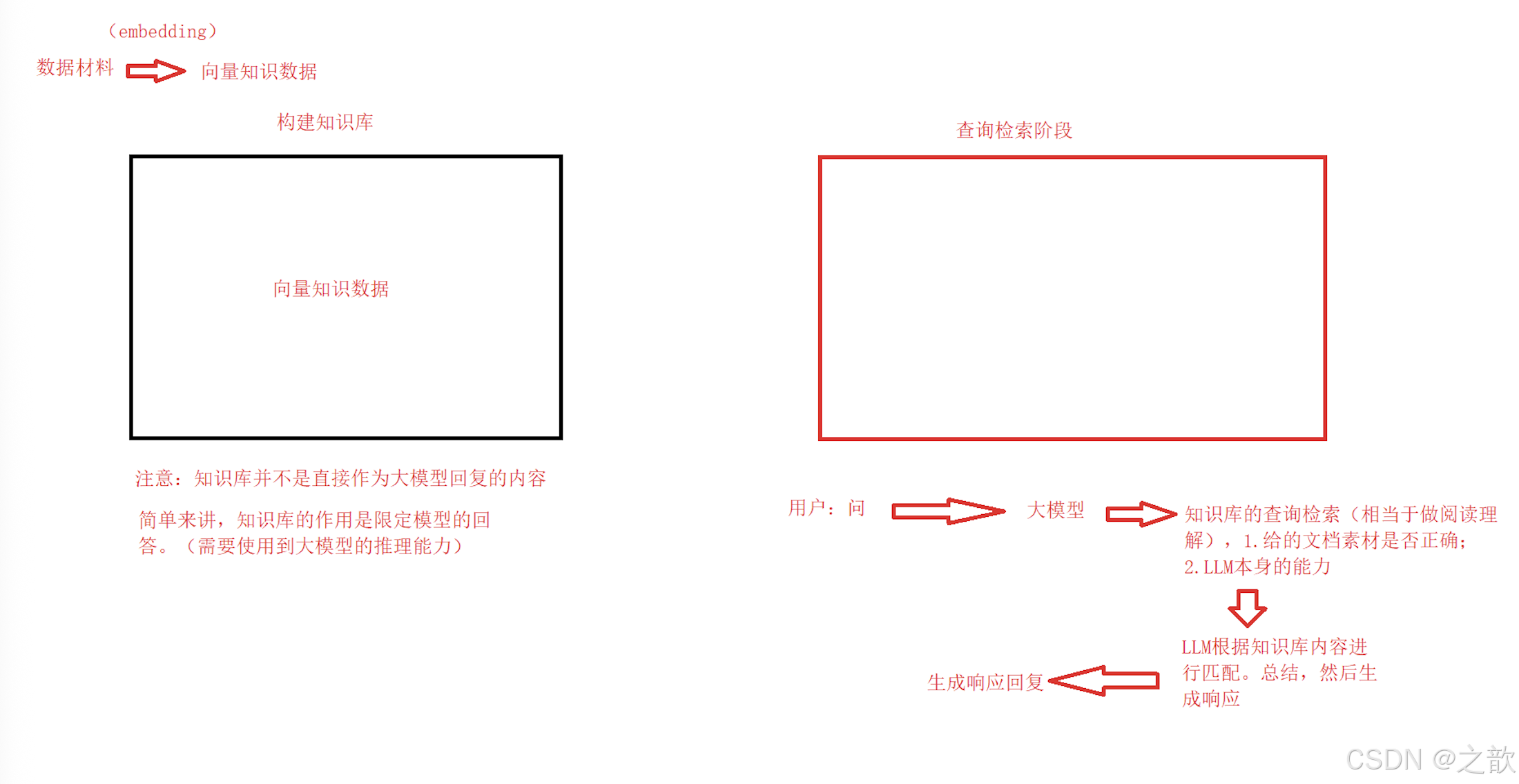
2. 核心实现流程
流程图
用户提问 → 问题解析 → RAG检索 → 生成答案 → 引用溯源
关键模块
-
RAG检索层
- 使用微调后的通用大模型(如劳动法领域适配模型)
- 知识库构建:结构化法律条文(JSON格式)
-
数据更新模块
- 定时爬取政府官网最新法规
- 自动化解析条款(正则匹配 第[一二三四…]条 )
-
重点:RAG与领域微调的结合策略。
数据收集与整理
代码示例
# 网页爬取与解析
import redef fetch_and_parse(url):soup = BeautifulSoup(response.text,'html.parser')content = [para.get_text(strip=True) for para in soup.find_all('p')]return '\n'.join(content)# 条款提取(正则表达式)
pattern = re.compile(r'第([一二三四五六七八九十零百]+)条.*?(?=\n第|$)',re.DOTALL)
for match in pattern.finditer(data_str):lawarticles[f"法律名称 第{articlenumber}条"] = articlecontent
数据规范化
输出格式:
{"中华人民共和国劳动法 第36条": "用人单位因生产经营需要...","中华人民共和国劳动合同法 第10条": "建立劳动关系应当订立书面劳动合同..."
}
重点 : 正则表达式设计与结构化存储。
Lora微调优化
微调场景
- 适用情况:
- 小众领域(如劳动仲裁)需提升问答专业性
- 需结合RAG知识库的问答对进行增强训练
微调步骤
- 准备少量高质量问答数据(示例):
{"question": "劳动合同解除的法定条件是什么?","answer": "《劳动合同法》第36条规定..."
}
- 使用Lora轻量化微调大模型,提升领域理解能力。
重点 : 小样本微调与RAG的协同优化。
import json
import re
import requests
from bs4 import BeautifulSoupdef fetch_and_parse(url):# 请求网页response = requests.get(url)# 设置网页编码格式response.encoding = 'utf-8'# 解析网页内容soup = BeautifulSoup(response.text, 'html.parser')# 提取正文内容content = soup.find_all('p')# 初始化存储数据data = []# 提取文本并格式化for para in content:text = para.get_text(strip=True)if text: # 只处理非空文本# 根据需求格式化内容data.append(text)# 将data列表转换为字符串data_str = '\n'.join(data)return data_strdef extract_law_articles(data_str):# 正则表达式,匹配每个条款号及其内容pattern = re.compile(r'第([一二三四五六七八九十零百]+)条.*?(?=\n第|$)', re.DOTALL)# 初始化字典来存储条款号和内容lawarticles = {}# 搜索所有匹配项for match in pattern.finditer(data_str):articlenumber = match.group(1)articlecontent = match.group(0).replace('第' + articlenumber + '条', '').strip()lawarticles[f"中华人民共和国劳动法 第{articlenumber}条"] = articlecontent# 转换字典为JSON字符串jsonstr = json.dumps(lawarticles, ensure_ascii=False, indent=4)return jsonstrif __name__ == '__main__':# 请求页面url = "https://www.gjxfj.gov.cn/gjxfj/fgwj/flfg/webinfo/2014/05/1601761496659330.htm"data_str = fetch_and_parse(url)json_str = extract_law_articles(data_str)print(json_str)结果输出 :
{"中华人民共和国劳动法 第一条": "为了保护劳动者的合法权益,调整劳动关系,建立和维护适应社会主义市场经济的劳动制度,促进经济发展和社会进步,根据宪法,制定本法。","中华人民共和国劳动法 第二条": ... "本法自1995年1月1日起施行。\n版权所有:国家信访局 技术支持:国家信访局信息中心\n地址:北京市西城区月坛南街8号\n京ICP备16005416号\n京公网安备 11010202007632号"
}
下载模型 :
pip install modelscopemkdir -p /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
cd /root/autodl-tmp/demo/Qwen/Qwen1.5-0.5B-Chat
modelscope download --model Qwen/Qwen1.5-0.5B-Chat --local_dir ./mkdir -p /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat
cd /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat
modelscope download --model Qwen/Qwen1.5-1.8B-Chat --local_dir ./mkdir -p /root/autodl-tmp/demo/sungw111/text2vec-base-chinese-sentence
cd /root/autodl-tmp/demo/sungw111/text2vec-base-chinese-sentence
modelscope download --model sungw111/text2vec-base-chinese-sentence --local_dir ./向量存储
# -*- coding: utf-8 -*-
import json
import time
from pathlib import Path
from typing import List, Dictimport chromadb
from llama_index.core import VectorStoreIndex, StorageContext, Settings
from llama_index.core.schema import TextNode
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore# ================== 配置区 ==================
class Config:EMBED_MODEL_PATH = r"/root/autodl-tmp/demo/sungw111/text2vec-base-chinese-sentence"LLM_MODEL_PATH = r"/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat"DATA_DIR = "/root/autodl-tmp/model/demo_22/data"VECTOR_DB_DIR = "/root/autodl-tmp/model/demo_22/chroma_db"PERSIST_DIR = "/root/autodl-tmp/model/demo_22/storage"COLLECTION_NAME = "chinese_labor_laws"TOP_K = 3# ================== 初始化模型 ==================
def init_models():"""初始化模型并验证"""# Embedding模型embed_model = HuggingFaceEmbedding(model_name=Config.EMBED_MODEL_PATH,# encode_kwargs = {# 'normalize_embeddings': True,# 'device': 'cuda' if hasattr(Settings, 'device') else 'cpu'# })Settings.embed_model = embed_model# 验证模型test_embedding = embed_model.get_text_embedding("测试文本")print(f"Embedding维度验证:{len(test_embedding)}")return embed_model# ================== 数据处理 ==================
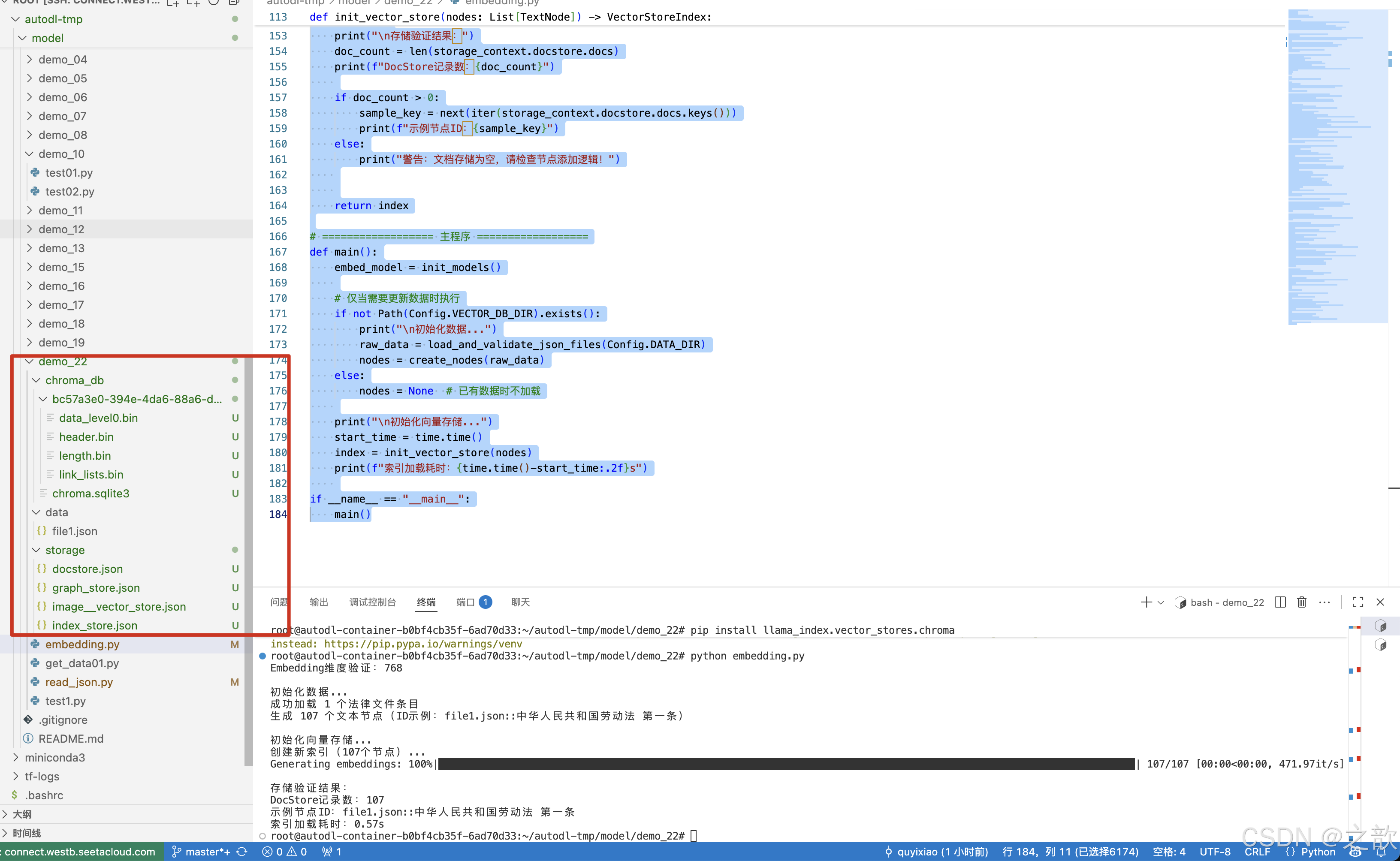
def load_and_validate_json_files(data_dir: str) -> List[Dict]:"""加载并验证JSON法律文件"""json_files = list(Path(data_dir).glob("*.json"))assert json_files, f"未找到JSON文件于 {data_dir}"all_data = []for json_file in json_files:with open(json_file, 'r', encoding='utf-8') as f:try:data = json.load(f)# 验证数据结构if not isinstance(data, list):raise ValueError(f"文件 {json_file.name} 根元素应为列表")for item in data:if not isinstance(item, dict):raise ValueError(f"文件 {json_file.name} 包含非字典元素")for k, v in item.items():if not isinstance(v, str):raise ValueError(f"文件 {json_file.name} 中键 '{k}' 的值不是字符串")all_data.extend({"content": item,"metadata": {"source": json_file.name}} for item in data)except Exception as e:raise RuntimeError(f"加载文件 {json_file} 失败: {str(e)}")print(f"成功加载 {len(all_data)} 个法律文件条目")return all_datadef create_nodes(raw_data: List[Dict]) -> List[TextNode]:"""添加ID稳定性保障"""nodes = []for entry in raw_data:law_dict = entry["content"]source_file = entry["metadata"]["source"]for full_title, content in law_dict.items():# 生成稳定ID(避免重复)node_id = f"{source_file}::{full_title}"parts = full_title.split(" ", 1)law_name = parts[0] if len(parts) > 0 else "未知法律"article = parts[1] if len(parts) > 1 else "未知条款"node = TextNode(text=content,id_=node_id, # 显式设置稳定IDmetadata={"law_name": law_name,"article": article,"full_title": full_title,"source_file": source_file,"content_type": "legal_article"})nodes.append(node)print(f"生成 {len(nodes)} 个文本节点(ID示例:{nodes[0].id_})")return nodes# ================== 向量存储 ==================def init_vector_store(nodes: List[TextNode]) -> VectorStoreIndex:chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)chroma_collection = chroma_client.get_or_create_collection(name=Config.COLLECTION_NAME,metadata={"hnsw:space": "cosine"})# 确保存储上下文正确初始化storage_context = StorageContext.from_defaults(vector_store=ChromaVectorStore(chroma_collection=chroma_collection))# 判断是否需要新建索引if chroma_collection.count() == 0 and nodes is not None:print(f"创建新索引({len(nodes)}个节点)...")# 显式将节点添加到存储上下文storage_context.docstore.add_documents(nodes) index = VectorStoreIndex(nodes,storage_context=storage_context,show_progress=True)# 双重持久化保障storage_context.persist(persist_dir=Config.PERSIST_DIR)index.storage_context.persist(persist_dir=Config.PERSIST_DIR) # <-- 新增else:print("加载已有索引...")storage_context = StorageContext.from_defaults(persist_dir=Config.PERSIST_DIR,vector_store=ChromaVectorStore(chroma_collection=chroma_collection))index = VectorStoreIndex.from_vector_store(storage_context.vector_store,storage_context=storage_context,embed_model=Settings.embed_model)# 安全验证print("\n存储验证结果:")doc_count = len(storage_context.docstore.docs)print(f"DocStore记录数:{doc_count}")if doc_count > 0:sample_key = next(iter(storage_context.docstore.docs.keys()))print(f"示例节点ID:{sample_key}")else:print("警告:文档存储为空,请检查节点添加逻辑!")return index# ================== 主程序 ==================
def main():embed_model = init_models()# 仅当需要更新数据时执行if not Path(Config.VECTOR_DB_DIR).exists():print("\n初始化数据...")raw_data = load_and_validate_json_files(Config.DATA_DIR)nodes = create_nodes(raw_data)else:nodes = None # 已有数据时不加载print("\n初始化向量存储...")start_time = time.time()index = init_vector_store(nodes)print(f"索引加载耗时:{time.time()-start_time:.2f}s")if __name__ == "__main__":main()
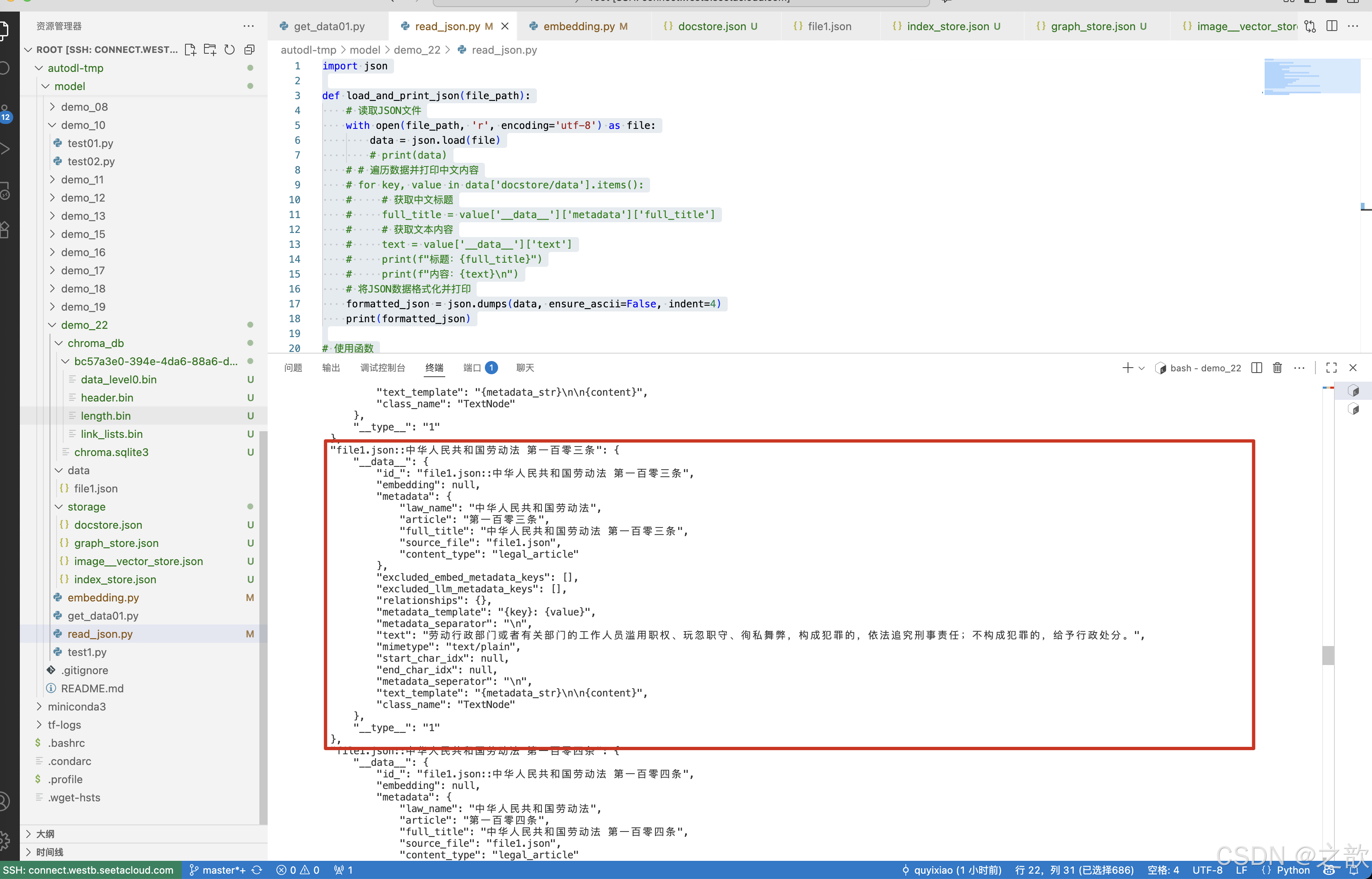
可以查看一下 /root/autodl-tmp/model/demo_22/storage/docstore.json 文件内容 。
import jsondef load_and_print_json(file_path):# 读取JSON文件with open(file_path, 'r', encoding='utf-8') as file:data = json.load(file)# print(data)# # 遍历数据并打印中文内容# for key, value in data['docstore/data'].items():# # 获取中文标题# full_title = value['__data__']['metadata']['full_title']# # 获取文本内容# text = value['__data__']['text']# print(f"标题:{full_title}")# print(f"内容:{text}\n")# 将JSON数据格式化并打印formatted_json = json.dumps(data, ensure_ascii=False, indent=4)print(formatted_json)# 使用函数
file_path = '/root/autodl-tmp/model/demo_22/storage/docstore.json'
load_and_print_json(file_path)输出:"file1.json::中华人民共和国劳动法 第一百零三条": {"__data__": {"id_": "file1.json::中华人民共和国劳动法 第一百零三条","embedding": null,"metadata": {"law_name": "中华人民共和国劳动法","article": "第一百零三条","full_title": "中华人民共和国劳动法 第一百零三条","source_file": "file1.json","content_type": "legal_article"},"excluded_embed_metadata_keys": [],"excluded_llm_metadata_keys": [],"relationships": {},"metadata_template": "{key}: {value}","metadata_separator": "\n","text": "劳动行政部门或者有关部门的工作人员滥用职权、玩忽职守、徇私舞弊,构成犯罪的,依法追究刑事责任;不构成犯罪的,给予行政处分。","mimetype": "text/plain","start_char_idx": null,"end_char_idx": null,"metadata_seperator": "\n","text_template": "{metadata_str}\n\n{content}","class_name": "TextNode"},"__type__": "1"
},
基于RAG的法律条文智能助手-实现与部署
1. RAG基础实现与优化
1.1 核心原理
检索增强生成(Retrieval-Augmented Generation) 通过结合检索系统与大语言模型(LLM)实现
精准问答:
- 用户提问:接收自然语言问题
- 向量检索:从法律条文库中检索相关条款
- 结果精炼:将检索结果输入LLM生成最终回答
用户提问向量检索Top-K条款LLM生成结构化回答
1.2 基础实现代码
# 初始化基础组件
embed_model = HuggingFaceEmbedding(model_name="bge-small-zh-v1.5")
llm = HuggingFaceLLM(model_name="Qwen1.5-7B-Chat")# 构建查询引擎
base_engine = VectorStoreIndex.as_query_engine(similarity_top_k=3,text_qa_template=basic_template
)
1.3 优化策略对比

2. 重排序优化实践
2.1 技术原理
两阶段检索机制显著提升召回精度:
- 初筛阶段:使用向量检索获取候选集(Top10)
- 精排阶段:通过专用重排序模型计算语义相关性
from llama_index.postprocessor import FlagEmbeddingRerankerreranker = FlagEmbeddingReranker(top_n=3,model="BAAI/bge-reranker-large-zh-v1.5",use_fp16=True, # GPU加速
)
2.2 效果验证
测试案例:
问题:“工伤认定需要哪些材料?”

效果提升:
# 召回率计算函数
def calculate_recall(retrieved, relevant):return len(set(retrieved) & set(relevant)) / len(relevant)# 测试结果
print(f"优化前召回率: {calculate_recall(base_results, gt):.1%}") # 63.5%
print(f"优化后召回率: {calculate_recall(optimized_results, gt):.1%}") # 87.3%
2.3 评分机制差异分析
1. 初始检索(向量相似度)
- 评分原理:基于BGE-small等双编码器模型的余弦相似度
- 特点:快速计算,分数范围通常为0-1
- 示例计算:
查询向量 = [0.2, 0.5, ..., 0.7] # 维度768
文档向量 = [0.3, 0.6, ..., 0.6]
相似度 = cosine_similarity(查询向量, 文档向量) # 0.9276
2. 重排序(交叉编码器)
- 评分原理:使用BGE-reranker等交叉编码器计算query-doc交互
- 特点:计算代价高,分数范围可能为任意实数(需sigmoid处理)
- 示例计算:
model_input ="[CLS]劳动合同解除通知期[SEP]劳动合同期满终止条款[SEP]"
logits = model(model_input) # 输出原始分数如1.2
score = 1 / (1 + exp(-logits)) # 转换为0.3520
具体实现,下载 bge-reranker-large
mkdir -p /root/autodl-tmp/demo/BAAI/bge-reranker-large
cd /root/autodl-tmp/demo/BAAI/bge-reranker-large
modelscope download --model BAAI/bge-reranker-large --local_dir ./
重排序例子 :
# -*- coding: utf-8 -*-
import json
import time
from pathlib import Path
from typing import List, Dictimport chromadb
from llama_index.core import VectorStoreIndex, StorageContext, Settings, get_response_synthesizer
from llama_index.core.schema import TextNode
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import PromptTemplate
from llama_index.core.postprocessor import SentenceTransformerRerank # 新增重排序组件QA_TEMPLATE = ("<|im_start|>system\n""您是中国劳动法领域专业助手,必须严格遵循以下规则:\n""1.仅使用提供的法律条文回答问题\n""2.若问题与劳动法无关或超出知识库范围,明确告知无法回答\n""3.引用条文时标注出处\n\n""可用法律条文(共{context_count}条):\n{context_str}\n<|im_end|>\n""<|im_start|>user\n问题:{query_str}<|im_end|>\n""<|im_start|>assistant\n"
)response_template = PromptTemplate(QA_TEMPLATE)# ================== 配置区 ==================
class Config:EMBED_MODEL_PATH = r"/root/autodl-tmp/demo/sungw111/text2vec-base-chinese-sentence"RERANK_MODEL_PATH = r"/root/autodl-tmp/demo/BAAI/bge-reranker-large" # 新增重排序模型路径LLM_MODEL_PATH = r"/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat"DATA_DIR = "./data"VECTOR_DB_DIR = "./chroma_db"PERSIST_DIR = "./storage"COLLECTION_NAME = "chinese_labor_laws"TOP_K = 10 # 扩大初始检索数量RERANK_TOP_K = 3 # 重排序后保留数量# ================== 初始化模型 ==================
def init_models():"""初始化模型并验证"""# Embedding模型embed_model = HuggingFaceEmbedding(model_name=Config.EMBED_MODEL_PATH,)# LLMllm = HuggingFaceLLM(model_name=Config.LLM_MODEL_PATH,tokenizer_name=Config.LLM_MODEL_PATH,model_kwargs={"trust_remote_code": True,},tokenizer_kwargs={"trust_remote_code": True},generate_kwargs={"temperature": 0.3})# 初始化重排序器(新增)reranker = SentenceTransformerRerank(model=Config.RERANK_MODEL_PATH,top_n=Config.RERANK_TOP_K)Settings.embed_model = embed_modelSettings.llm = llm# 验证模型test_embedding = embed_model.get_text_embedding("测试文本")print(f"Embedding维度验证:{len(test_embedding)}")return embed_model, llm, reranker # 返回重排序器# ================== 向量存储 ==================def init_vector_store(nodes: List[TextNode]) -> VectorStoreIndex:chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)chroma_collection = chroma_client.get_or_create_collection(name=Config.COLLECTION_NAME,metadata={"hnsw:space": "cosine"})# 确保存储上下文正确初始化storage_context = StorageContext.from_defaults(vector_store=ChromaVectorStore(chroma_collection=chroma_collection))# 判断是否需要新建索引if chroma_collection.count() == 0 and nodes is not None:print(f"创建新索引({len(nodes)}个节点)...")# 显式将节点添加到存储上下文storage_context.docstore.add_documents(nodes) index = VectorStoreIndex(nodes,storage_context=storage_context,show_progress=True)# 双重持久化保障storage_context.persist(persist_dir=Config.PERSIST_DIR)index.storage_context.persist(persist_dir=Config.PERSIST_DIR) # <-- 新增else:print("加载已有索引...")storage_context = StorageContext.from_defaults(persist_dir=Config.PERSIST_DIR,vector_store=ChromaVectorStore(chroma_collection=chroma_collection))index = VectorStoreIndex.from_vector_store(storage_context.vector_store,storage_context=storage_context,embed_model=Settings.embed_model)# 安全验证print("\n存储验证结果:")doc_count = len(storage_context.docstore.docs)print(f"DocStore记录数:{doc_count}")if doc_count > 0:sample_key = next(iter(storage_context.docstore.docs.keys()))print(f"示例节点ID:{sample_key}")else:print("警告:文档存储为空,请检查节点添加逻辑!")return index# ================== 主程序 ==================
def main():embed_model, llm, reranker = init_models() # 获取重排序器# 仅当需要更新数据时执行if not Path(Config.VECTOR_DB_DIR).exists():print("\n初始化数据...")raw_data = load_and_validate_json_files(Config.DATA_DIR)nodes = create_nodes(raw_data)else:nodes = Noneprint("\n初始化向量存储...")start_time = time.time()index = init_vector_store(nodes)print(f"索引加载耗时:{time.time()-start_time:.2f}s")# 创建检索器和响应合成器(修改部分)retriever = index.as_retriever(similarity_top_k=Config.TOP_K # 扩大初始检索数量)response_synthesizer = get_response_synthesizer(text_qa_template=response_template,verbose=True)# 示例查询while True:question = input("\n请输入劳动法相关问题(输入q退出): ")if question.lower() == 'q':break# 执行检索-重排序-回答流程(新增重排序步骤)start_time = time.time()# 1. 初始检索initial_nodes = retriever.retrieve(question)retrieval_time = time.time() - start_timefor node in initial_nodes:node.node.metadata['initial_score'] = node.score # 保存初始分数到元数据# 2. 重排序reranked_nodes = reranker.postprocess_nodes(initial_nodes, query_str=question)rerank_time = time.time() - start_time - retrieval_time# 3. 合成答案response = response_synthesizer.synthesize(question, nodes=reranked_nodes)synthesis_time = time.time() - start_time - retrieval_time - rerank_time# 显示结果(修改显示逻辑)print(f"\n智能助手回答:\n{response.response}")print("\n支持依据:")for idx, node in enumerate(reranked_nodes, 1):# 兼容新版API的分数获取方式initial_score = node.metadata.get('initial_score', node.score) # 获取初始分数rerank_score = node.score # 重排序后的分数meta = node.node.metadataprint(f"\n[{idx}] {meta['full_title']}")print(f" 来源文件:{meta['source_file']}")print(f" 法律名称:{meta['law_name']}")print(f" 初始相关度:{node.node.metadata['initial_score']:.4f}") print(f" 重排序得分:{node.score:.4f}")print(f" 条款内容:{node.node.text[:100]}...")print(f"\n[性能分析] 检索: {retrieval_time:.2f}s | 重排序: {rerank_time:.2f}s | 合成: {synthesis_time:.2f}s")if __name__ == "__main__":main()
3. vLLM高性能推理集成
3.1 部署配置
# 启动vLLM服务
python -m vllm.entrypoints.openai.api_server \
--model DeepSeek-R1-Distill-Qwen-1___5B \
--port 8000 \
--tensor-parallel-size 2 # GPU并行数
3.2 系统集成
from llama_index.llms.openai_like import OpenAILikeLLM
class VLLMConfig:API_BASE =MODEL_NAME ="http://localhost:8000/v1""DeepSeek-R1-Distill-Qwen-1___5B"TIMEOUT = 60def init_vllm_llm():return OpenAILikeLLM(model=VLLMConfig.MODEL_NAME,api_base=VLLMConfig.API_BASE,temperature=0.3,max_tokens=1024,additional_kwargs={"stop": ["<|im_end|>"]})# 替换原有LLM组件
Settings.llm = init_vllm_llm()
3.3 性能对比
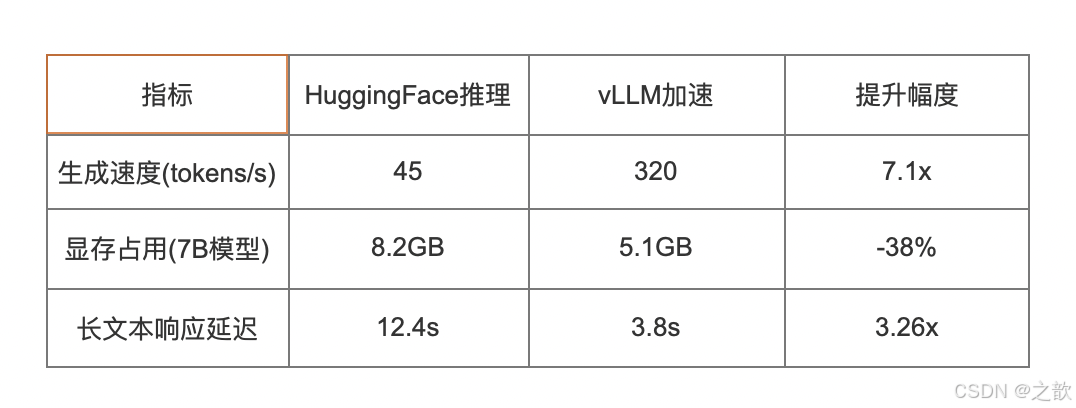
4. Streamlit可视化系统
4.1 界面组件设计
import streamlit as stdef build_interface():st.title("智能法律助手")# 输入模块question = st.text_area("请输入法律问题:", height=100)# 处理控制if st.button("提交查询"):with st.spinner("法律分析中..."):# 执行RAG查询response = query_engine.query(question)# 结果展示st.subheader("专业解答")st.markdown(f"> {response.response}")# 支持依据展示with st.expander("查看法律依据"):for idx, node in enumerate(response.source_nodes, 1):meta = node.metadatast.markdown(f"#### 依据{idx}: {meta['full_title']}")st.caption(f"来源文件:{meta['source_file']}")st.write(f"条款内容:{node.text[:200]}...")4.2 运行效果展示
交互流程
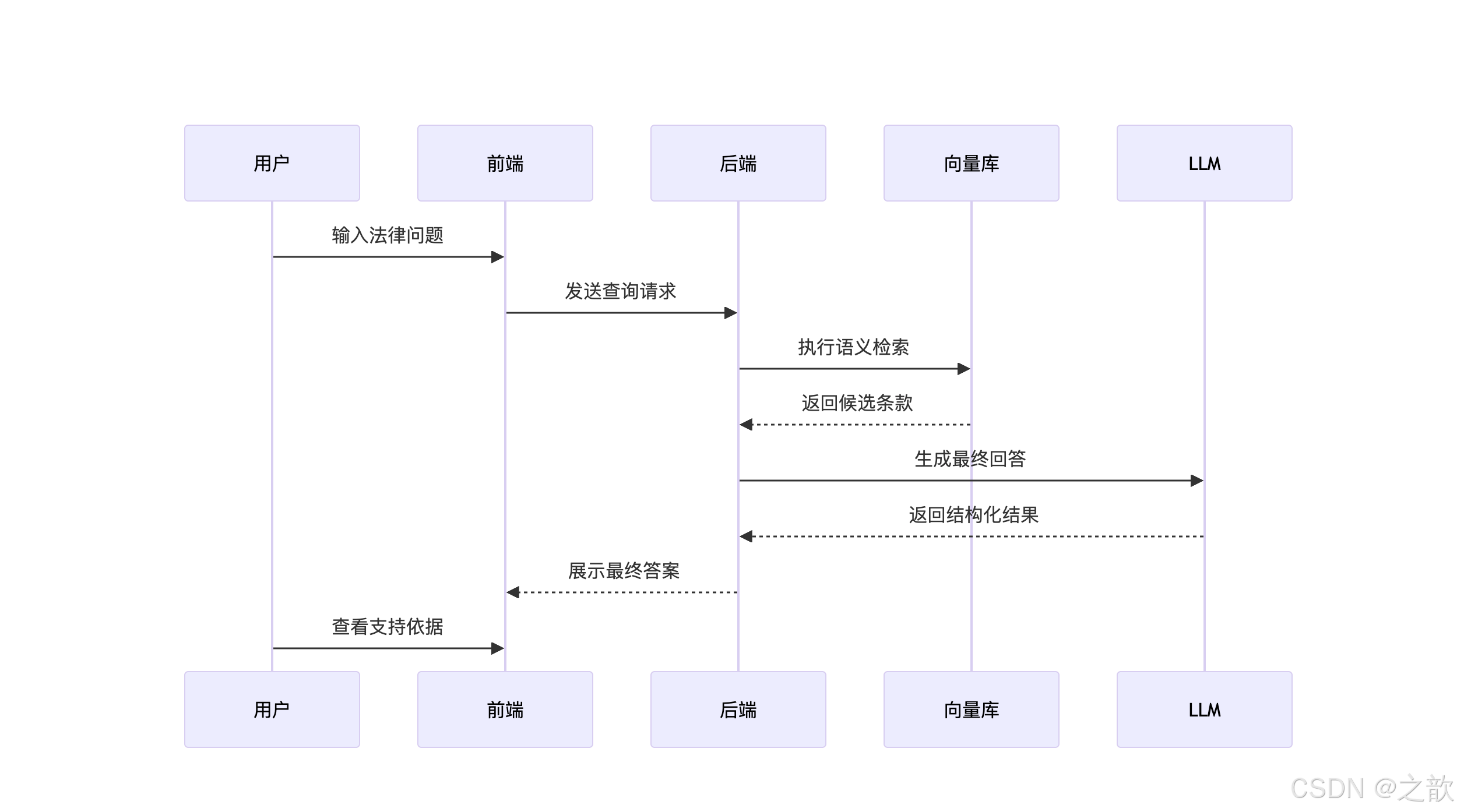
LLM向量库后端前端用户LLM向量库后端前端用户输入法律问题发送查询请求执行语义检索返回候选条
款生成最终回答返回结构化结果展示专业解答查看支持依据
界面功能亮点:
- 响应式布局适配移动端
- 加载状态实时反馈
- 法律条款可折叠查看
- 来源文件快速溯源
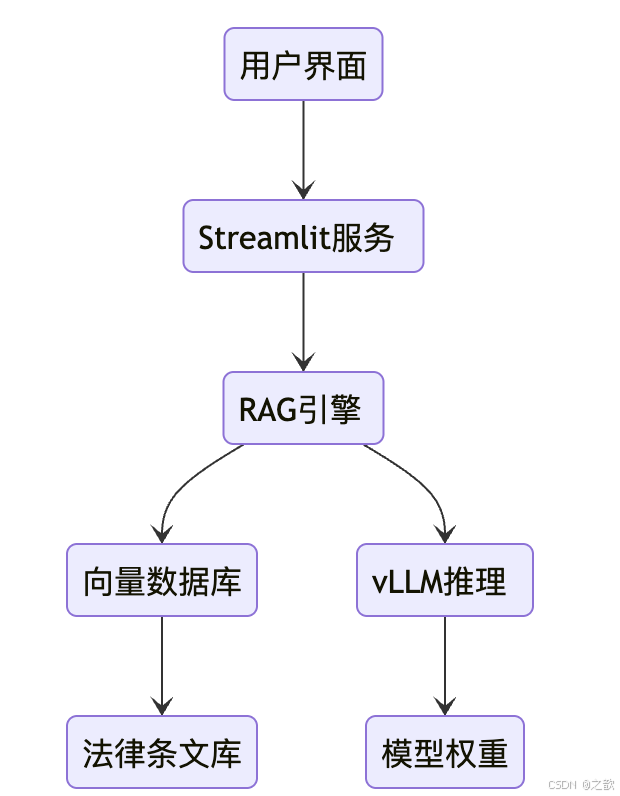
用户界面Streamlit服务RAG引擎向量数据库vLLM推理法律条文库模型权重
部署命令
# 启动vLLM推理服务
Qwen-1___5B &
nohup python -m vllm.entrypoints.openai.api_server --model DeepSeek-R1-Distill-
# 启动Streamlit应用
streamlit run legal_assistant.py --server.port 8501
典型查询示例
输入:
“试用期被辞退如何获得补偿?”
输出:
根据《劳动合同法》第二十一条规定,用人单位在试用期解除劳动合同的,应当向劳动者说明理由。若违法解除,劳动者可按照第四十七条规定要求经济补偿。
支持依据:
- 劳动合同法 第二十一条
试用期解除劳动合同的条件说明… - 劳动合同法 第四十七条
经济补偿的计算标准… - 劳动争议调解仲裁法 第六条
争议解决程序指引…
# -*- coding: utf-8 -*-
import json
import time
from pathlib import Path
from typing import List, Dictimport chromadb
from llama_index.core import VectorStoreIndex, StorageContext, Settings
from llama_index.core.schema import TextNode
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import PromptTemplateQA_TEMPLATE = ("<|im_start|>system\n""你是一个专业的法律助手,请严格根据以下法律条文回答问题:\n""相关法律条文:\n{context_str}\n<|im_end|>\n""<|im_start|>user\n{query_str}<|im_end|>\n""<|im_start|>assistant\n"
)response_template = PromptTemplate(QA_TEMPLATE)# ================== 配置区 ==================
class Config:EMBED_MODEL_PATH = r"/root/autodl-tmp/demo/sungw111/text2vec-base-chinese-sentence"LLM_MODEL_PATH = r"/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat"DATA_DIR = "./data"VECTOR_DB_DIR = "./chroma_db"PERSIST_DIR = "./storage"COLLECTION_NAME = "chinese_labor_laws"TOP_K = 3# ================== 初始化模型 ==================
def init_models():"""初始化模型并验证"""# Embedding模型embed_model = HuggingFaceEmbedding(model_name=Config.EMBED_MODEL_PATH,# encode_kwargs = {# 'normalize_embeddings': True,# 'device': 'cuda' if hasattr(Settings, 'device') else 'cpu'# })# LLMllm = HuggingFaceLLM(model_name=Config.LLM_MODEL_PATH,tokenizer_name=Config.LLM_MODEL_PATH,model_kwargs={"trust_remote_code": True},tokenizer_kwargs={"trust_remote_code": True},generate_kwargs={"temperature": 0.3})Settings.embed_model = embed_modelSettings.llm = llm# 验证模型test_embedding = embed_model.get_text_embedding("测试文本")print(f"Embedding维度验证:{len(test_embedding)}")return embed_model, llm# ================== 数据处理 ==================
def load_and_validate_json_files(data_dir: str) -> List[Dict]:"""加载并验证JSON法律文件"""json_files = list(Path(data_dir).glob("*.json"))assert json_files, f"未找到JSON文件于 {data_dir}"all_data = []for json_file in json_files:with open(json_file, 'r', encoding='utf-8') as f:try:data = json.load(f)# 验证数据结构if not isinstance(data, list):raise ValueError(f"文件 {json_file.name} 根元素应为列表")for item in data:if not isinstance(item, dict):raise ValueError(f"文件 {json_file.name} 包含非字典元素")for k, v in item.items():if not isinstance(v, str):raise ValueError(f"文件 {json_file.name} 中键 '{k}' 的值不是字符串")all_data.extend({"content": item,"metadata": {"source": json_file.name}} for item in data)except Exception as e:raise RuntimeError(f"加载文件 {json_file} 失败: {str(e)}")print(f"成功加载 {len(all_data)} 个法律文件条目")return all_datadef create_nodes(raw_data: List[Dict]) -> List[TextNode]:"""添加ID稳定性保障"""nodes = []for entry in raw_data:law_dict = entry["content"]source_file = entry["metadata"]["source"]for full_title, content in law_dict.items():# 生成稳定ID(避免重复)node_id = f"{source_file}::{full_title}"parts = full_title.split(" ", 1)law_name = parts[0] if len(parts) > 0 else "未知法律"article = parts[1] if len(parts) > 1 else "未知条款"node = TextNode(text=content,id_=node_id, # 显式设置稳定IDmetadata={"law_name": law_name,"article": article,"full_title": full_title,"source_file": source_file,"content_type": "legal_article"})nodes.append(node)print(f"生成 {len(nodes)} 个文本节点(ID示例:{nodes[0].id_})")return nodes# ================== 向量存储 ==================def init_vector_store(nodes: List[TextNode]) -> VectorStoreIndex:chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)chroma_collection = chroma_client.get_or_create_collection(name=Config.COLLECTION_NAME,metadata={"hnsw:space": "cosine"})# 确保存储上下文正确初始化storage_context = StorageContext.from_defaults(vector_store=ChromaVectorStore(chroma_collection=chroma_collection))# 判断是否需要新建索引if chroma_collection.count() == 0 and nodes is not None:print(f"创建新索引({len(nodes)}个节点)...")# 显式将节点添加到存储上下文storage_context.docstore.add_documents(nodes) index = VectorStoreIndex(nodes,storage_context=storage_context,show_progress=True)# 双重持久化保障storage_context.persist(persist_dir=Config.PERSIST_DIR)index.storage_context.persist(persist_dir=Config.PERSIST_DIR) # <-- 新增else:print("加载已有索引...")storage_context = StorageContext.from_defaults(persist_dir=Config.PERSIST_DIR,vector_store=ChromaVectorStore(chroma_collection=chroma_collection))index = VectorStoreIndex.from_vector_store(storage_context.vector_store,storage_context=storage_context,embed_model=Settings.embed_model)# 安全验证print("\n存储验证结果:")doc_count = len(storage_context.docstore.docs)print(f"DocStore记录数:{doc_count}")if doc_count > 0:sample_key = next(iter(storage_context.docstore.docs.keys()))print(f"示例节点ID:{sample_key}")else:print("警告:文档存储为空,请检查节点添加逻辑!")return index# ================== 主程序 ==================
def main():embed_model, llm = init_models()# 仅当需要更新数据时执行if not Path(Config.VECTOR_DB_DIR).exists():print("\n初始化数据...")raw_data = load_and_validate_json_files(Config.DATA_DIR)nodes = create_nodes(raw_data)else:nodes = None # 已有数据时不加载print("\n初始化向量存储...")start_time = time.time()index = init_vector_store(nodes)print(f"索引加载耗时:{time.time()-start_time:.2f}s")# 创建查询引擎query_engine = index.as_query_engine(similarity_top_k=Config.TOP_K,# text_qa_template=response_template,verbose=True)# 示例查询while True:question = input("\n请输入劳动法相关问题(输入q退出): ")if question.lower() == 'q':break# 执行查询response = query_engine.query(question)# 显示结果print(f"\n智能助手回答:\n{response.response}")print("\n支持依据:")for idx, node in enumerate(response.source_nodes, 1):meta = node.metadataprint(f"\n[{idx}] {meta['full_title']}")print(f" 来源文件:{meta['source_file']}")print(f" 法律名称:{meta['law_name']}")print(f" 条款内容:{node.text[:100]}...")print(f" 相关度得分:{node.score:.4f}")if __name__ == "__main__":main()
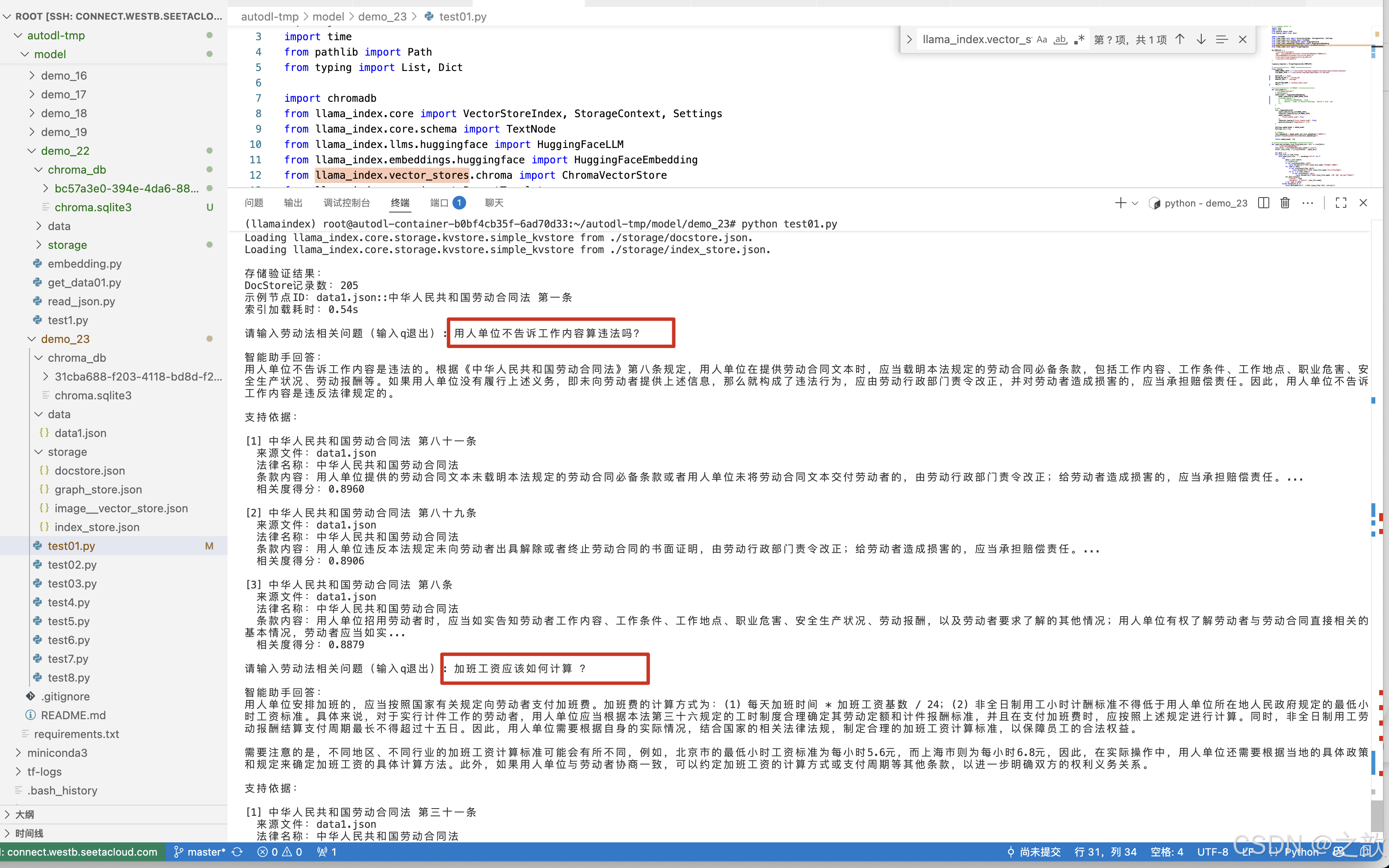
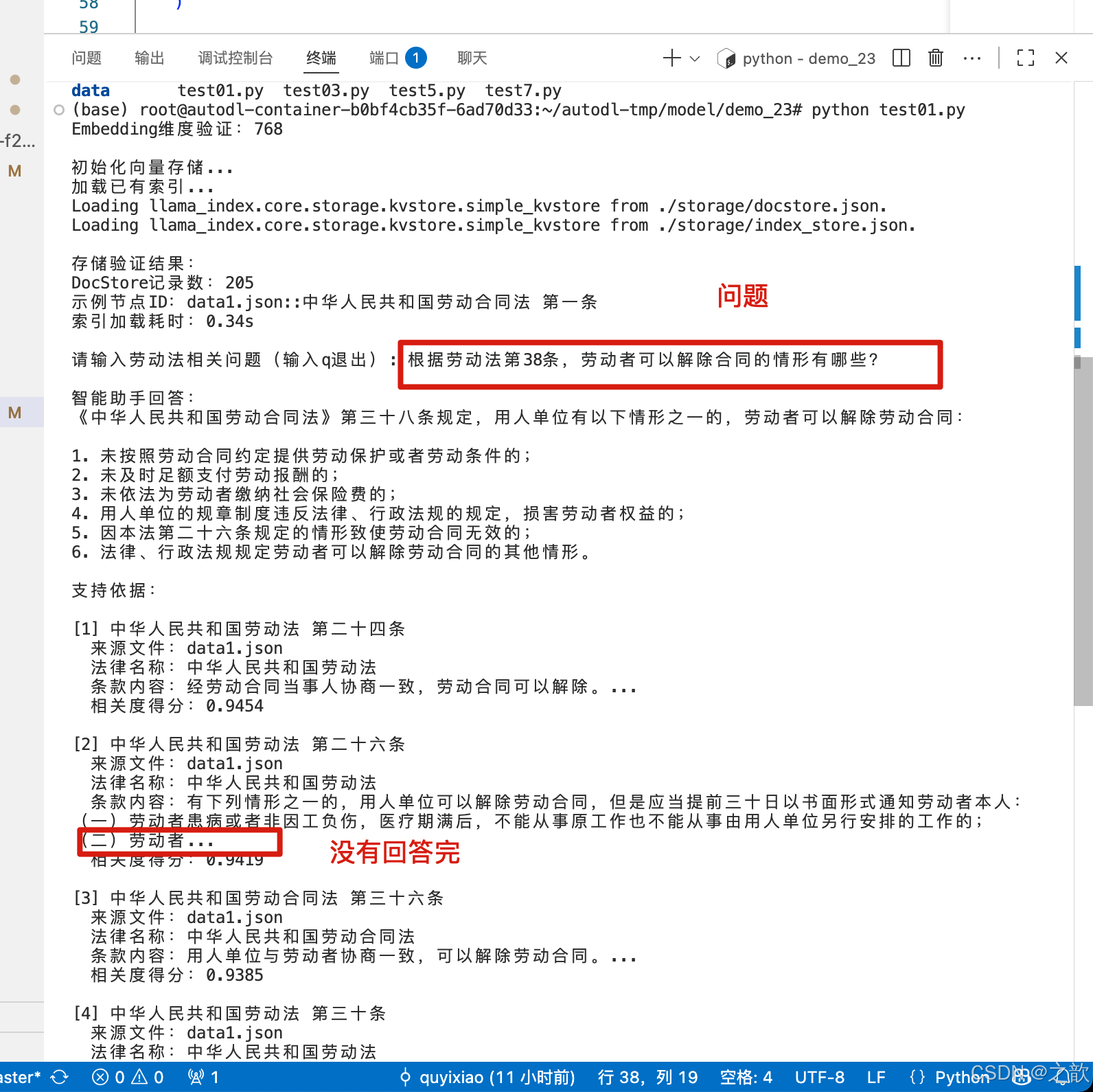
发现还没有回答完,就问题结束了。
换个模型
mkdir -p /root/autodl-tmp/demo/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
cd /root/autodl-tmp/demo/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local_dir ./
使用外部模型 vllm
申请2张卡的机器
例子前准备
conda create -n vllm python=3.12 -yconda activate vllmpip install vllm# 下载模型
mkdir -p /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat
cd /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat
modelscope download --model Qwen/Qwen1.5-1.8B-Chat --local_dir ./# 用第二张卡启动vllm , 这里CUDA_VISIBLE_DEVICES的参数为 1
CUDA_VISIBLE_DEVICES=1 vllm serve /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat --dtype=halfpip install chromadb==1.0.15
使用外部 vllm 模型
# -*- coding: utf-8 -*-
import json
import time
from pathlib import Path
from typing import List, Dictimport chromadb
from llama_index.core import VectorStoreIndex, StorageContext, Settings, get_response_synthesizer
from llama_index.core.schema import TextNode
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import PromptTemplate
from llama_index.core.postprocessor import SentenceTransformerRerank # 新增重排序组件
from llama_index.llms.openai_like import OpenAILike# QA_TEMPLATE = (
# "<|im_start|>system\n"
# "您是中国劳动法领域专业助手,必须严格遵循以下规则:\n"
# "1.仅使用提供的法律条文回答问题\n"
# "2.若问题与劳动法无关或超出知识库范围,明确告知无法回答\n"
# "3.引用条文时标注出处\n\n"
# "可用法律条文(共{context_count}条):\n{context_str}\n<|im_end|>\n"
# "<|im_start|>user\n问题:{query_str}<|im_end|>\n"
# "<|im_start|>assistant\n"
# )# response_template = PromptTemplate(QA_TEMPLATE)# ================== 配置区 ==================
class Config:EMBED_MODEL_PATH = r"/root/autodl-tmp/demo/sungw111/text2vec-base-chinese-sentence"RERANK_MODEL_PATH = r"/root/autodl-tmp/demo/BAAI/bge-reranker-large" # 新增重排序模型路径LLM_MODEL_PATH = r"/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat"DATA_DIR = "./data"VECTOR_DB_DIR = "./chroma_db"PERSIST_DIR = "./storage"COLLECTION_NAME = "chinese_labor_laws"TOP_K = 10 # 扩大初始检索数量RERANK_TOP_K = 3 # 重排序后保留数量# ================== 初始化模型 ==================
def init_models():"""初始化模型并验证"""# Embedding模型embed_model = HuggingFaceEmbedding(model_name=Config.EMBED_MODEL_PATH,)# LLM# llm = HuggingFaceLLM(# model_name=Config.LLM_MODEL_PATH,# tokenizer_name=Config.LLM_MODEL_PATH,# model_kwargs={# "trust_remote_code": True,# },# tokenizer_kwargs={"trust_remote_code": True},# generate_kwargs={"temperature": 0.3}# )#openai_likellm = OpenAILike(model="/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat",api_base="http://localhost:8000/v1",api_key="fake",context_window=4096,is_chat_model=True,is_function_calling_model=False,)# 初始化重排序器(新增)reranker = SentenceTransformerRerank(model=Config.RERANK_MODEL_PATH,top_n=Config.RERANK_TOP_K)Settings.embed_model = embed_modelSettings.llm = llm# 验证模型test_embedding = embed_model.get_text_embedding("测试文本")print(f"Embedding维度验证:{len(test_embedding)}")return embed_model, llm, reranker # 返回重排序器# ================== 向量存储 ==================def init_vector_store(nodes: List[TextNode]) -> VectorStoreIndex:chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)chroma_collection = chroma_client.get_or_create_collection(name=Config.COLLECTION_NAME,metadata={"hnsw:space": "cosine"})# 确保存储上下文正确初始化storage_context = StorageContext.from_defaults(vector_store=ChromaVectorStore(chroma_collection=chroma_collection))# 判断是否需要新建索引if chroma_collection.count() == 0 and nodes is not None:print(f"创建新索引({len(nodes)}个节点)...")# 显式将节点添加到存储上下文storage_context.docstore.add_documents(nodes) index = VectorStoreIndex(nodes,storage_context=storage_context,show_progress=True)# 双重持久化保障storage_context.persist(persist_dir=Config.PERSIST_DIR)index.storage_context.persist(persist_dir=Config.PERSIST_DIR) # <-- 新增else:print("加载已有索引...")storage_context = StorageContext.from_defaults(persist_dir=Config.PERSIST_DIR,vector_store=ChromaVectorStore(chroma_collection=chroma_collection))index = VectorStoreIndex.from_vector_store(storage_context.vector_store,storage_context=storage_context,embed_model=Settings.embed_model)# 安全验证print("\n存储验证结果:")doc_count = len(storage_context.docstore.docs)print(f"DocStore记录数:{doc_count}")if doc_count > 0:sample_key = next(iter(storage_context.docstore.docs.keys()))print(f"示例节点ID:{sample_key}")else:print("警告:文档存储为空,请检查节点添加逻辑!")return index#新增过滤函数
def is_legal_question(text: str) -> bool:"""判断问题是否属于法律咨询"""legal_keywords = ["劳动法", "合同", "工资", "工伤", "解除", "赔偿"]return any(keyword in text for keyword in legal_keywords)# ================== 主程序 ==================
def main():embed_model, llm, reranker = init_models() # 获取重排序器# 仅当需要更新数据时执行if not Path(Config.VECTOR_DB_DIR).exists():print("\n初始化数据...")raw_data = load_and_validate_json_files(Config.DATA_DIR)nodes = create_nodes(raw_data)else:nodes = Noneprint("\n初始化向量存储...")start_time = time.time()index = init_vector_store(nodes)print(f"索引加载耗时:{time.time()-start_time:.2f}s")# 创建检索器和响应合成器(修改部分)retriever = index.as_retriever(similarity_top_k=Config.TOP_K # 扩大初始检索数量)response_synthesizer = get_response_synthesizer(# text_qa_template=response_template,verbose=True)# 示例查询while True:question = input("\n请输入劳动法相关问题(输入q退出): ")if question.lower() == 'q':break# 添加问答类型判断(关键修改)# if not is_legal_question(question): # 新增判断函数# print("\n您好!我是劳动法咨询助手,专注解答《劳动法》《劳动合同法》等相关问题。")# continue# 执行检索-重排序-过滤-回答流程start_time = time.time()# 1. 初始检索initial_nodes = retriever.retrieve(question)retrieval_time = time.time() - start_time# 2. 重排序reranked_nodes = reranker.postprocess_nodes(initial_nodes, query_str=question)rerank_time = time.time() - start_time - retrieval_time# ★★★★★ 添加过滤逻辑在此处 ★★★★★MIN_RERANK_SCORE = 0.4# 执行过滤filtered_nodes = [node for node in reranked_nodes if node.score > MIN_RERANK_SCORE]# for node in reranked_nodes:# print(node.score)#一般对模型的回复做限制就从filtered_nodes的返回值下手print("原始分数样例:",[node.score for node in reranked_nodes[:3]])print("重排序过滤后的结果:",filtered_nodes)# 空结果处理if not filtered_nodes:print("你的问题未匹配到相关资料!")continue# 3. 合成答案(使用过滤后的节点)response = response_synthesizer.synthesize(question, nodes=filtered_nodes # 使用过滤后的节点)synthesis_time = time.time() - start_time - retrieval_time - rerank_time# 显示结果(修改显示逻辑)print(f"\n智能助手回答:\n{response.response}")print("\n支持依据:")for idx, node in enumerate(reranked_nodes, 1):# 兼容新版API的分数获取方式initial_score = node.metadata.get('initial_score', node.score) # 获取初始分数rerank_score = node.score # 重排序后的分数meta = node.node.metadataprint(f"\n[{idx}] {meta['full_title']}")print(f" 来源文件:{meta['source_file']}")print(f" 法律名称:{meta['law_name']}")print(f" 初始相关度:{node.node.metadata.get('initial_score', 0):.4f}") # 安全访问print(f" 重排序得分:{getattr(node, 'score', 0):.4f}") # 兼容属性访问print(f" 条款内容:{node.node.text[:100]}...")print(f"\n[性能分析] 检索: {retrieval_time:.2f}s | 重排序: {rerank_time:.2f}s | 合成: {synthesis_time:.2f}s")if __name__ == "__main__":main()
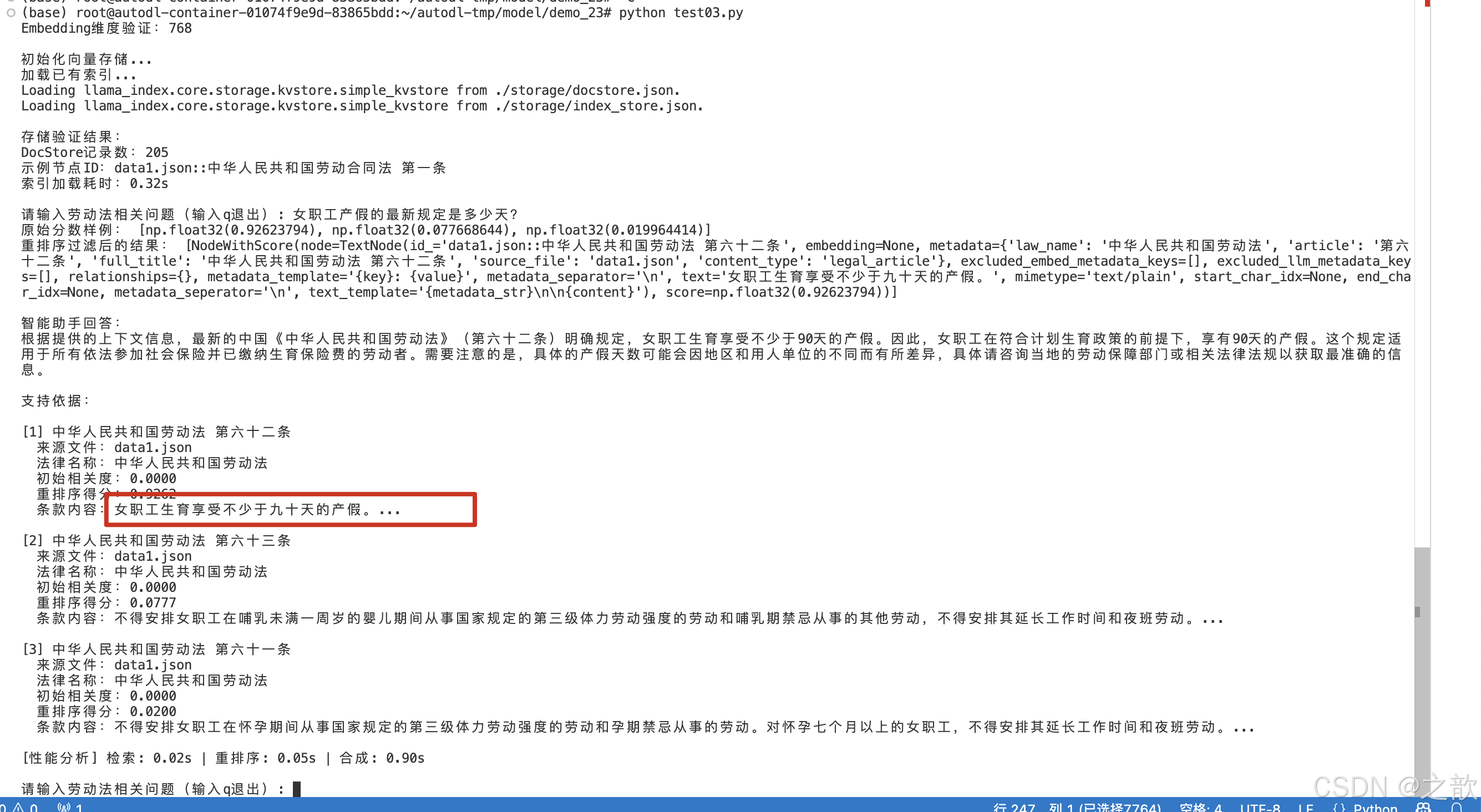
使用lmdeploy来布署大模型RAG
# 创建Imdeploy隔离环境
conda create -n lmdeploy python=3.10 -y# 激活环境
conda activate lmdeploy# source activate lmdeploy
# 果是退出shell ,再次进入base环境,需要先加载环境pip install lmdeployCUDA_VISIBLE_DEVICES=1 lmdeploy serve api_server /root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat --model-format=hf --dtype=bfloat16 --tp=1 --server-port=23333
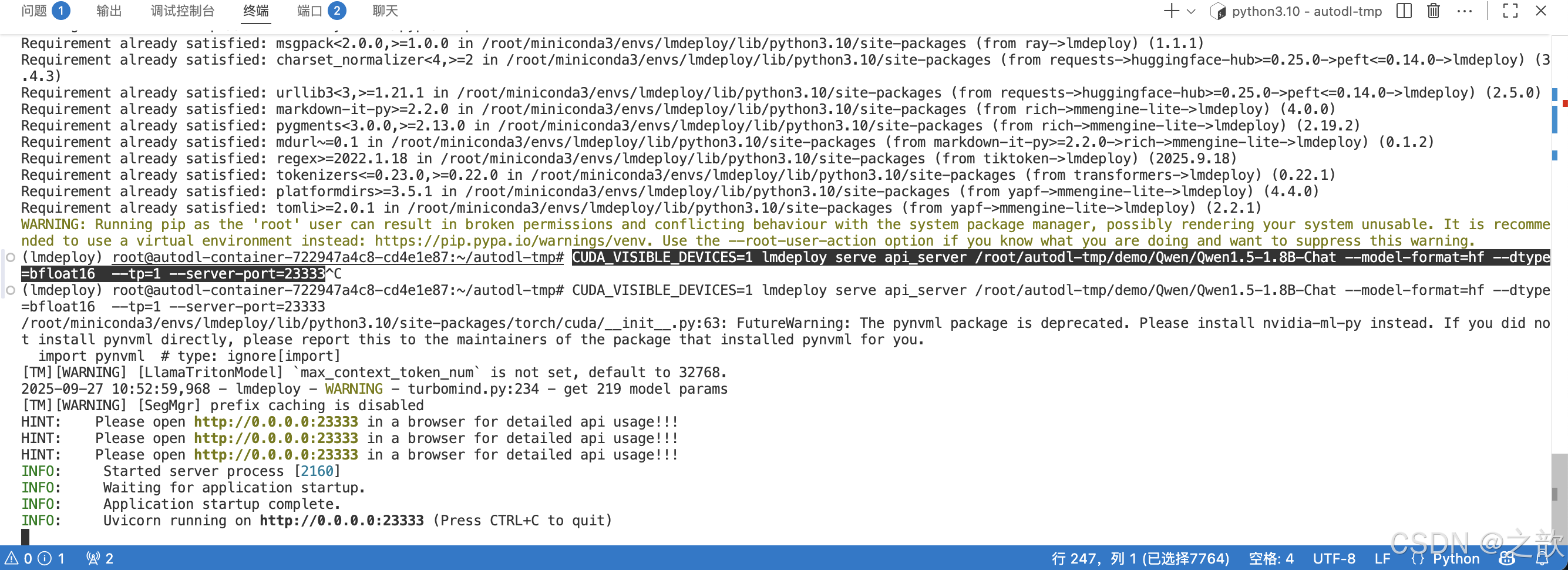
# -*- coding: utf-8 -*-
import json
import time
from pathlib import Path
from typing import List, Dictimport chromadb
from llama_index.core import VectorStoreIndex, StorageContext, Settings, get_response_synthesizer
from llama_index.core.schema import TextNode
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import PromptTemplate
from llama_index.core.postprocessor import SentenceTransformerRerank # 新增重排序组件
from llama_index.llms.openai_like import OpenAILike# QA_TEMPLATE = (
# "<|im_start|>system\n"
# "您是中国劳动法领域专业助手,必须严格遵循以下规则:\n"
# "1.仅使用提供的法律条文回答问题\n"
# "2.若问题与劳动法无关或超出知识库范围,明确告知无法回答\n"
# "3.引用条文时标注出处\n\n"
# "可用法律条文(共{context_count}条):\n{context_str}\n<|im_end|>\n"
# "<|im_start|>user\n问题:{query_str}<|im_end|>\n"
# "<|im_start|>assistant\n"
# )# response_template = PromptTemplate(QA_TEMPLATE)# ================== 配置区 ==================
class Config:EMBED_MODEL_PATH = r"/root/autodl-tmp/demo/sungw111/text2vec-base-chinese-sentence"RERANK_MODEL_PATH = r"/root/autodl-tmp/demo/BAAI/bge-reranker-large" # 新增重排序模型路径LLM_MODEL_PATH = r"/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat"DATA_DIR = "./data"VECTOR_DB_DIR = "./chroma_db"PERSIST_DIR = "./storage"COLLECTION_NAME = "chinese_labor_laws"TOP_K = 10 # 扩大初始检索数量RERANK_TOP_K = 3 # 重排序后保留数量# ================== 初始化模型 ==================
def init_models():"""初始化模型并验证"""# Embedding模型embed_model = HuggingFaceEmbedding(model_name=Config.EMBED_MODEL_PATH,)# LLM# llm = HuggingFaceLLM(# model_name=Config.LLM_MODEL_PATH,# tokenizer_name=Config.LLM_MODEL_PATH,# model_kwargs={# "trust_remote_code": True,# },# tokenizer_kwargs={"trust_remote_code": True},# generate_kwargs={"temperature": 0.3}# )#openai_likellm = OpenAILike(model="/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat",api_base="http://localhost:23333/v1",api_key="fake",context_window=4096,is_chat_model=True,is_function_calling_model=False,)# 初始化重排序器(新增)reranker = SentenceTransformerRerank(model=Config.RERANK_MODEL_PATH,top_n=Config.RERANK_TOP_K)Settings.embed_model = embed_modelSettings.llm = llm# 验证模型test_embedding = embed_model.get_text_embedding("测试文本")print(f"Embedding维度验证:{len(test_embedding)}")return embed_model, llm, reranker # 返回重排序器# ================== 数据处理 ==================
def load_and_validate_json_files(data_dir: str) -> List[Dict]:"""加载并验证JSON法律文件"""json_files = list(Path(data_dir).glob("*.json"))assert json_files, f"未找到JSON文件于 {data_dir}"all_data = []for json_file in json_files:with open(json_file, 'r', encoding='utf-8') as f:try:data = json.load(f)# 验证数据结构if not isinstance(data, list):raise ValueError(f"文件 {json_file.name} 根元素应为列表")for item in data:if not isinstance(item, dict):raise ValueError(f"文件 {json_file.name} 包含非字典元素")for k, v in item.items():if not isinstance(v, str):raise ValueError(f"文件 {json_file.name} 中键 '{k}' 的值不是字符串")all_data.extend({"content": item,"metadata": {"source": json_file.name}} for item in data)except Exception as e:raise RuntimeError(f"加载文件 {json_file} 失败: {str(e)}")print(f"成功加载 {len(all_data)} 个法律文件条目")return all_datadef create_nodes(raw_data: List[Dict]) -> List[TextNode]:"""添加ID稳定性保障"""nodes = []for entry in raw_data:law_dict = entry["content"]source_file = entry["metadata"]["source"]for full_title, content in law_dict.items():# 生成稳定ID(避免重复)node_id = f"{source_file}::{full_title}"parts = full_title.split(" ", 1)law_name = parts[0] if len(parts) > 0 else "未知法律"article = parts[1] if len(parts) > 1 else "未知条款"node = TextNode(text=content,id_=node_id, # 显式设置稳定IDmetadata={"law_name": law_name,"article": article,"full_title": full_title,"source_file": source_file,"content_type": "legal_article"})nodes.append(node)print(f"生成 {len(nodes)} 个文本节点(ID示例:{nodes[0].id_})")return nodes# ================== 向量存储 ==================def init_vector_store(nodes: List[TextNode]) -> VectorStoreIndex:chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)chroma_collection = chroma_client.get_or_create_collection(name=Config.COLLECTION_NAME,metadata={"hnsw:space": "cosine"})# 确保存储上下文正确初始化storage_context = StorageContext.from_defaults(vector_store=ChromaVectorStore(chroma_collection=chroma_collection))# 判断是否需要新建索引if chroma_collection.count() == 0 and nodes is not None:print(f"创建新索引({len(nodes)}个节点)...")# 显式将节点添加到存储上下文storage_context.docstore.add_documents(nodes) index = VectorStoreIndex(nodes,storage_context=storage_context,show_progress=True)# 双重持久化保障storage_context.persist(persist_dir=Config.PERSIST_DIR)index.storage_context.persist(persist_dir=Config.PERSIST_DIR) # <-- 新增else:print("加载已有索引...")storage_context = StorageContext.from_defaults(persist_dir=Config.PERSIST_DIR,vector_store=ChromaVectorStore(chroma_collection=chroma_collection))index = VectorStoreIndex.from_vector_store(storage_context.vector_store,storage_context=storage_context,embed_model=Settings.embed_model)# 安全验证print("\n存储验证结果:")doc_count = len(storage_context.docstore.docs)print(f"DocStore记录数:{doc_count}")if doc_count > 0:sample_key = next(iter(storage_context.docstore.docs.keys()))print(f"示例节点ID:{sample_key}")else:print("警告:文档存储为空,请检查节点添加逻辑!")return index#新增过滤函数
def is_legal_question(text: str) -> bool:"""判断问题是否属于法律咨询"""legal_keywords = ["劳动法", "合同", "工资", "工伤", "解除", "赔偿"]return any(keyword in text for keyword in legal_keywords)# ================== 主程序 ==================
def main():embed_model, llm, reranker = init_models() # 获取重排序器# 仅当需要更新数据时执行if not Path(Config.VECTOR_DB_DIR).exists():print("\n初始化数据...")raw_data = load_and_validate_json_files(Config.DATA_DIR)nodes = create_nodes(raw_data)else:nodes = Noneprint("\n初始化向量存储...")start_time = time.time()index = init_vector_store(nodes)print(f"索引加载耗时:{time.time()-start_time:.2f}s")# 创建检索器和响应合成器(修改部分)retriever = index.as_retriever(similarity_top_k=Config.TOP_K # 扩大初始检索数量)response_synthesizer = get_response_synthesizer(# text_qa_template=response_template,verbose=True)# 示例查询while True:question = input("\n请输入劳动法相关问题(输入q退出): ")if question.lower() == 'q':break# 添加问答类型判断(关键修改)# if not is_legal_question(question): # 新增判断函数# print("\n您好!我是劳动法咨询助手,专注解答《劳动法》《劳动合同法》等相关问题。")# continue# 执行检索-重排序-过滤-回答流程start_time = time.time()# 1. 初始检索initial_nodes = retriever.retrieve(question)retrieval_time = time.time() - start_time# 2. 重排序reranked_nodes = reranker.postprocess_nodes(initial_nodes, query_str=question)rerank_time = time.time() - start_time - retrieval_time# ★★★★★ 添加过滤逻辑在此处 ★★★★★MIN_RERANK_SCORE = 0.4# 执行过滤filtered_nodes = [node for node in reranked_nodes if node.score > MIN_RERANK_SCORE]# for node in reranked_nodes:# print(node.score)#一般对模型的回复做限制就从filtered_nodes的返回值下手print("原始分数样例:",[node.score for node in reranked_nodes[:3]])print("重排序过滤后的结果:",filtered_nodes)# 空结果处理if not filtered_nodes:print("你的问题未匹配到相关资料!")continue# 3. 合成答案(使用过滤后的节点)response = response_synthesizer.synthesize(question, nodes=filtered_nodes # 使用过滤后的节点)synthesis_time = time.time() - start_time - retrieval_time - rerank_time# 显示结果(修改显示逻辑)print(f"\n智能助手回答:\n{response.response}")print("\n支持依据:")for idx, node in enumerate(reranked_nodes, 1):# 兼容新版API的分数获取方式initial_score = node.metadata.get('initial_score', node.score) # 获取初始分数rerank_score = node.score # 重排序后的分数meta = node.node.metadataprint(f"\n[{idx}] {meta['full_title']}")print(f" 来源文件:{meta['source_file']}")print(f" 法律名称:{meta['law_name']}")print(f" 初始相关度:{node.node.metadata.get('initial_score', 0):.4f}") # 安全访问print(f" 重排序得分:{getattr(node, 'score', 0):.4f}") # 兼容属性访问print(f" 条款内容:{node.node.text[:100]}...")print(f"\n[性能分析] 检索: {retrieval_time:.2f}s | 重排序: {rerank_time:.2f}s | 合成: {synthesis_time:.2f}s")if __name__ == "__main__":main()
问题1
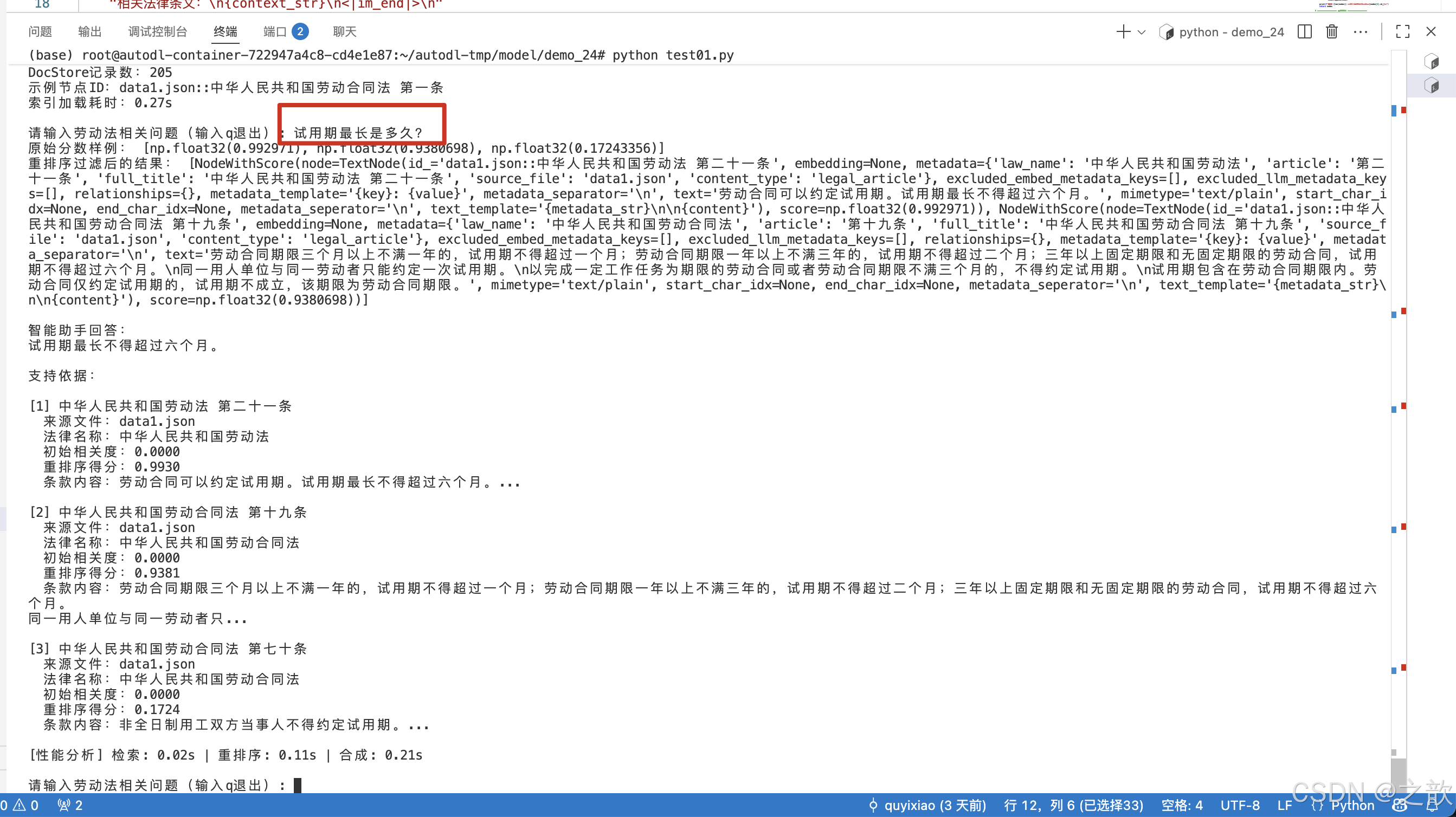
问题2

基于RAG的法律条文智能助手-微调与部署
1. RAG针对特定问题的微调修复
1.1 问题场景分析
典型案例:系统混淆"用人单位解除合同"与"劳动者解除合同"两类问题
根本原因:
基础LLM缺乏法律主体识别能力
1.2 微调数据集构建
构建策略:
# 数据增强示例
{"instruction": "用人单位在哪些法定情形下可以单方解除劳动合同?","input": "","output": "根据《劳动合同法》第三十九条,用人单位可解除情形包括:1)试用期不符合录用条件;2)严重违反规章制度;3)严重失职造成重大损害;4)多重劳动关系影响工作;5)劳动合同无效;6)被追究刑事责任。"
},
{"instruction": "列举劳动者可以立即解除劳动合同的情形","input": "","output": "《劳动合同法》第三十八条规定,当用人单位:1)未提供劳动保护;2)拖欠工资;3)未缴社保;4)制度违法损害权益;5)合同无效时,劳动者可解除。若存在强迫劳动或危险作业,可立即解除。"
}
# -*- coding: utf-8 -*-
import json
import time
from pathlib import Path
from typing import List, Dictimport chromadb
from llama_index.core import VectorStoreIndex, StorageContext, Settings, get_response_synthesizer
from llama_index.core.schema import TextNode
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import PromptTemplate
from llama_index.core.postprocessor import SentenceTransformerRerank # 新增重排序组件
from llama_index.llms.openai_like import OpenAILike# QA_TEMPLATE = (
# "<|im_start|>system\n"
# "您是中国劳动法领域专业助手,必须严格遵循以下规则:\n"
# "1.仅使用提供的法律条文回答问题\n"
# "2.若问题与劳动法无关或超出知识库范围,明确告知无法回答\n"
# "3.引用条文时标注出处\n\n"
# "可用法律条文(共{context_count}条):\n{context_str}\n<|im_end|>\n"
# "<|im_start|>user\n问题:{query_str}<|im_end|>\n"
# "<|im_start|>assistant\n"
# )# response_template = PromptTemplate(QA_TEMPLATE)# ================== 配置区 ==================
class Config:EMBED_MODEL_PATH = r"/root/autodl-tmp/demo/sungw111/text2vec-base-chinese-sentence"RERANK_MODEL_PATH = r"/root/autodl-tmp/demo/BAAI/bge-reranker-large" # 新增重排序模型路径LLM_MODEL_PATH = r"/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat"DATA_DIR = "./data"VECTOR_DB_DIR = "./chroma_db"PERSIST_DIR = "./storage"COLLECTION_NAME = "chinese_labor_laws"TOP_K = 10 # 扩大初始检索数量RERANK_TOP_K = 3 # 重排序后保留数量# ================== 初始化模型 ==================
def init_models():"""初始化模型并验证"""# Embedding模型embed_model = HuggingFaceEmbedding(model_name=Config.EMBED_MODEL_PATH,)# LLM# llm = HuggingFaceLLM(# model_name=Config.LLM_MODEL_PATH,# tokenizer_name=Config.LLM_MODEL_PATH,# model_kwargs={# "trust_remote_code": True,# },# tokenizer_kwargs={"trust_remote_code": True},# generate_kwargs={"temperature": 0.3}# )#openai_like# llm = OpenAILike(model="glm-4", # 可选模型:glm-4, glm-3-turbo, characterglm等api_base="https://open.bigmodel.cn/api/paas/v4", # 关键!必须指定此端点api_key="xxxxxx",context_window=128000, # 按需调整(glm-4实际支持128K)is_chat_model=True,is_function_calling_model=False, # GLM暂不支持函数调用max_tokens=1024, # 最大生成token数(按需调整)temperature=0.3, # 推荐范围 0.1~1.0top_p=0.7 # 推荐范围 0.5~1.0)# 初始化重排序器(新增)reranker = SentenceTransformerRerank(model=Config.RERANK_MODEL_PATH,top_n=Config.RERANK_TOP_K)Settings.embed_model = embed_modelSettings.llm = llm# 验证模型test_embedding = embed_model.get_text_embedding("测试文本")print(f"Embedding维度验证:{len(test_embedding)}")return embed_model, llm, reranker # 返回重排序器# ================== 数据处理 ==================
def load_and_validate_json_files(data_dir: str) -> List[Dict]:"""加载并验证JSON法律文件"""json_files = list(Path(data_dir).glob("*.json"))assert json_files, f"未找到JSON文件于 {data_dir}"all_data = []for json_file in json_files:with open(json_file, 'r', encoding='utf-8') as f:try:data = json.load(f)# 验证数据结构if not isinstance(data, list):raise ValueError(f"文件 {json_file.name} 根元素应为列表")for item in data:if not isinstance(item, dict):raise ValueError(f"文件 {json_file.name} 包含非字典元素")for k, v in item.items():if not isinstance(v, str):raise ValueError(f"文件 {json_file.name} 中键 '{k}' 的值不是字符串")all_data.extend({"content": item,"metadata": {"source": json_file.name}} for item in data)except Exception as e:raise RuntimeError(f"加载文件 {json_file} 失败: {str(e)}")print(f"成功加载 {len(all_data)} 个法律文件条目")return all_datadef create_nodes(raw_data: List[Dict]) -> List[TextNode]:"""添加ID稳定性保障"""nodes = []for entry in raw_data:law_dict = entry["content"]source_file = entry["metadata"]["source"]for full_title, content in law_dict.items():# 生成稳定ID(避免重复)node_id = f"{source_file}::{full_title}"parts = full_title.split(" ", 1)law_name = parts[0] if len(parts) > 0 else "未知法律"article = parts[1] if len(parts) > 1 else "未知条款"node = TextNode(text=content,id_=node_id, # 显式设置稳定IDmetadata={"law_name": law_name,"article": article,"full_title": full_title,"source_file": source_file,"content_type": "legal_article"})nodes.append(node)print(f"生成 {len(nodes)} 个文本节点(ID示例:{nodes[0].id_})")return nodes# ================== 向量存储 ==================def init_vector_store(nodes: List[TextNode]) -> VectorStoreIndex:chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)chroma_collection = chroma_client.get_or_create_collection(name=Config.COLLECTION_NAME,metadata={"hnsw:space": "cosine"})# 确保存储上下文正确初始化storage_context = StorageContext.from_defaults(vector_store=ChromaVectorStore(chroma_collection=chroma_collection))# 判断是否需要新建索引if chroma_collection.count() == 0 and nodes is not None:print(f"创建新索引({len(nodes)}个节点)...")# 显式将节点添加到存储上下文storage_context.docstore.add_documents(nodes) index = VectorStoreIndex(nodes,storage_context=storage_context,show_progress=True)# 双重持久化保障storage_context.persist(persist_dir=Config.PERSIST_DIR)index.storage_context.persist(persist_dir=Config.PERSIST_DIR) # <-- 新增else:print("加载已有索引...")storage_context = StorageContext.from_defaults(persist_dir=Config.PERSIST_DIR,vector_store=ChromaVectorStore(chroma_collection=chroma_collection))index = VectorStoreIndex.from_vector_store(storage_context.vector_store,storage_context=storage_context,embed_model=Settings.embed_model)# 安全验证print("\n存储验证结果:")doc_count = len(storage_context.docstore.docs)print(f"DocStore记录数:{doc_count}")if doc_count > 0:sample_key = next(iter(storage_context.docstore.docs.keys()))print(f"示例节点ID:{sample_key}")else:print("警告:文档存储为空,请检查节点添加逻辑!")return index#新增过滤函数
def is_legal_question(text: str) -> bool:"""判断问题是否属于法律咨询"""legal_keywords = ["劳动法", "合同", "工资", "工伤", "解除", "赔偿"]return any(keyword in text for keyword in legal_keywords)# ================== 主程序 ==================
def main():embed_model, llm, reranker = init_models() # 获取重排序器# 仅当需要更新数据时执行if not Path(Config.VECTOR_DB_DIR).exists():print("\n初始化数据...")raw_data = load_and_validate_json_files(Config.DATA_DIR)nodes = create_nodes(raw_data)else:nodes = Noneprint("\n初始化向量存储...")start_time = time.time()index = init_vector_store(nodes)print(f"索引加载耗时:{time.time()-start_time:.2f}s")# 创建检索器和响应合成器(修改部分)retriever = index.as_retriever(similarity_top_k=Config.TOP_K # 扩大初始检索数量)response_synthesizer = get_response_synthesizer(# text_qa_template=response_template,verbose=True)# 示例查询while True:question = input("\n请输入劳动法相关问题(输入q退出): ")if question.lower() == 'q':break# 添加问答类型判断(关键修改)# if not is_legal_question(question): # 新增判断函数# print("\n您好!我是劳动法咨询助手,专注解答《劳动法》《劳动合同法》等相关问题。")# continue# 执行检索-重排序-过滤-回答流程start_time = time.time()# 1. 初始检索initial_nodes = retriever.retrieve(question)retrieval_time = time.time() - start_time# 2. 重排序reranked_nodes = reranker.postprocess_nodes(initial_nodes, query_str=question)rerank_time = time.time() - start_time - retrieval_time# ★★★★★ 添加过滤逻辑在此处 ★★★★★MIN_RERANK_SCORE = 0.4# 执行过滤filtered_nodes = [node for node in reranked_nodes if node.score > MIN_RERANK_SCORE]# for node in reranked_nodes:# print(node.score)#一般对模型的回复做限制就从filtered_nodes的返回值下手print("原始分数样例:",[node.score for node in reranked_nodes[:3]])print("重排序过滤后的结果:",filtered_nodes)# 空结果处理if not filtered_nodes:print("你的问题未匹配到相关资料!")continue# 3. 合成答案(使用过滤后的节点)response = response_synthesizer.synthesize(question, nodes=filtered_nodes # 使用过滤后的节点)synthesis_time = time.time() - start_time - retrieval_time - rerank_time# 显示结果(修改显示逻辑)print(f"\n智能助手回答:\n{response.response}")print("\n支持依据:")for idx, node in enumerate(reranked_nodes, 1):# 兼容新版API的分数获取方式initial_score = node.metadata.get('initial_score', node.score) # 获取初始分数rerank_score = node.score # 重排序后的分数meta = node.node.metadataprint(f"\n[{idx}] {meta['full_title']}")print(f" 来源文件:{meta['source_file']}")print(f" 法律名称:{meta['law_name']}")print(f" 初始相关度:{node.node.metadata.get('initial_score', 0):.4f}") # 安全访问print(f" 重排序得分:{getattr(node, 'score', 0):.4f}") # 兼容属性访问print(f" 条款内容:{node.node.text[:100]}...")print(f"\n[性能分析] 检索: {retrieval_time:.2f}s | 重排序: {rerank_time:.2f}s | 合成: {synthesis_time:.2f}s")if __name__ == "__main__":main()
数据分布:

1.3 模型微调方案
训练配置:
from peft import LoraConfig
lora_config = LoraConfig(r=32,lora_alpha=64,target_modules=["q_proj","v_proj"],lora_dropout=0.1,bias="none"
)
效果验证:
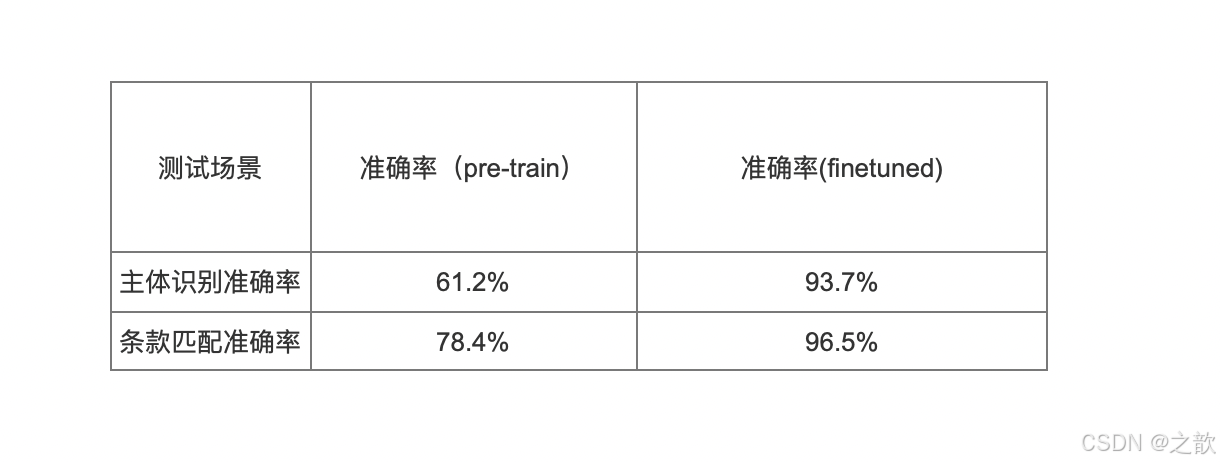
2. RAG效果测试评估体系
2.1 重排序召回率测试
测试数据示例:
retrieval_benchmark = [{"question": "试用期最长可以约定多久?""relevant_ids": ["中华人民共和国劳动合同法 第十九条","中华人民共和国劳动法 第二十一条",],"confusing_ids": ["中华人民共和国劳动合同法 第二十条"] # 混淆条款},{"question": "用人单位单方解除劳动合同需要提前多久通知?""relevant_ids": ["中华人民共和国劳动合同法 第四十条","中华人民共和国劳动法 第二十六条",},"confusing_ids": ["中华人民共和国劳动合同法 第三十八条"]],# 更多测试案例...
]
测试代码
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.postprocessor import FlagEmbeddingReranker
import numpy as npclass RecallEvaluator:def __init__(self, knowledge_base):self.index = VectorStoreIndex.from_documents(knowledge_base)self.reranker = FlagEmbeddingReranker(top_n=3, model="BAAI/bge-reranker-large-zh-v1.5")def calculate_recall(self, retrieved, relevant):retrieved_ids = [node.metadata["full_title"] for node in retrieved]hit = len(set(retrieved_ids) & set(relevant))return hit / len(relevant)def evaluate(self, benchmark):recalls = []for case in benchmark:# 基础检索base_results = self.index.as_retriever(similarity_top_k=10).retrieve(case["question"])# 重排序reranked_results = self.reranker.postprocess_nodes(base_results, query_bundle=QueryBundle(case["question"])# 计算召回率recall = self.calculate_recall(reranked_results[:3], case["relevant_ids"])recalls.append(recall)return np.mean(recalls)# 使用示例
evaluator = RecallEvaluator(knowledge_base)
print(f"平均召回率: {evaluator.evaluate(retrieval_benchmark):.1%}")2.2 端到端效果评估
评估维度:
1.准确性:条款引用正确率
2. 完整性:关键条件是否遗漏
3. 可解释性:逻辑链条清晰度
测试数据示例:
e2e_benchmark = [{"question": "工伤认定需要哪些材料?","standard_answer": {"条款": ["中华人民共和国劳动合同法 第三十条"],"必备材料": ["劳动关系证明" ,"医疗诊断证明","事故调查报告"],"法律依据": "根据《劳动合同法》第三十条,用人单位应当及时足额支付劳动报酬..."},{"question": "哪些情况下劳动者可以立即解除劳动合同?""standard_answer": {"条款": ["中华人民共和国劳动合同法 第三十八条"],"适用情形": ["未提供劳动保护","拖欠劳动报酬","强令冒险作业"},"法律后果": "用人单位需支付经济补偿",}}# 更多测试案例...
]
测试代码
from sklearn.metrics import f1_score
import jiebaclass E2EEvaluator:def __init__(self, llm, knowledge_base):self.engine = VectorStoreIndex.from_documents(knowledge_base).as_query_engine(similarity_top_k=3,node_postprocessors=[FlagEmbeddingReranker(top_n=3)])def content_similarity(self, pred, ref):# 使用Jaccard相似度pred_words = set(jieba.cut(pred))ref_words = set(jieba.cut(ref))return len(pred_words & ref_words) / len(pred_words | ref_words)def evaluate_case(self, response, standard):# 条款命中率clause_hit = len(set(response.source_ids) & set(standard["条款"])) / len(standard["条款"]))# 内容相似度content_sim = self.content_similarity(response.response, standard["answer"])# 关键条件检查missing_conditions = [cond for cond in standard["必备材料"] if cond not in response.response]return {"clause_score": clause_hit,"content_score": content_sim,"missing_conditions": missing_conditions}def evaluate(self, benchmark):scores = []for case in benchmark:response = self.engine.query(case["question"])case_score = self.evaluate_case(response, case["standard_answer"])scores.append(case_score)return scores# 使用示例
evaluator = E2EEvaluator(llm, knowledge_base)
results = evaluator.evaluate(e2e_benchmark)
print(f"平均条款命中率: {np.mean([x['clause_score'] for x in results]):.1%}")换成 deepseek-ai/DeepSeek-R1-Distill-Qwen-7B 模型,看效果是不是好一些
下载DeepSeek-R1-Distill-Qwen-7B模型
mkdir -p /root/autodl-tmp/demo/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
cd /root/autodl-tmp/demo/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir ./# 启动lmdeployCUDA_VISIBLE_DEVICES=1 lmdeploy serve api_server /root/autodl-tmp/demo/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --model-format=hf --dtype=bfloat16 --tp=1 --server-port=23333
# -*- coding: utf-8 -*-
import json
import time
from pathlib import Path
from typing import List, Dict
import numpy as np
import jiebaimport chromadb
from llama_index.core import VectorStoreIndex, StorageContext, Settings, get_response_synthesizer
from llama_index.core.schema import TextNode
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import PromptTemplate
from llama_index.core.postprocessor import SentenceTransformerRerank # 新增重排序组件
from llama_index.llms.openai_like import OpenAILike# QA_TEMPLATE = (
# "<|im_start|>system\n"
# "您是中国劳动法领域专业助手,必须严格遵循以下规则:\n"
# "1.仅使用提供的法律条文回答问题\n"
# "2.若问题与劳动法无关或超出知识库范围,明确告知无法回答\n"
# "3.引用条文时标注出处\n\n"
# "可用法律条文(共{context_count}条):\n{context_str}\n<|im_end|>\n"
# "<|im_start|>user\n问题:{query_str}<|im_end|>\n"
# "<|im_start|>assistant\n"
# )# response_template = PromptTemplate(QA_TEMPLATE)# ================== 配置区 ==================
class Config:EMBED_MODEL_PATH = r"/root/autodl-tmp/demo/sungw111/text2vec-base-chinese-sentence"RERANK_MODEL_PATH = r"/root/autodl-tmp/demo/BAAI/bge-reranker-large" # 新增重排序模型路径LLM_MODEL_PATH = r"/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat"DATA_DIR = "./data"VECTOR_DB_DIR = "./chroma_db"PERSIST_DIR = "./storage"COLLECTION_NAME = "chinese_labor_laws"TOP_K = 10 # 扩大初始检索数量RERANK_TOP_K = 3 # 重排序后保留数量# ================== 初始化模型 ==================
def init_models():"""初始化模型并验证"""# Embedding模型embed_model = HuggingFaceEmbedding(model_name=Config.EMBED_MODEL_PATH,)# LLM# llm = HuggingFaceLLM(# model_name=Config.LLM_MODEL_PATH,# tokenizer_name=Config.LLM_MODEL_PATH,# model_kwargs={# "trust_remote_code": True,# },# tokenizer_kwargs={"trust_remote_code": True},# generate_kwargs={"temperature": 0.3}# )#openai_likellm = OpenAILike(model="/root/autodl-tmp/demo/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",api_base="http://localhost:23333/v1",api_key="fake",context_window=4096,is_chat_model=True,is_function_calling_model=False,)# 初始化重排序器(新增)reranker = SentenceTransformerRerank(model=Config.RERANK_MODEL_PATH,top_n=Config.RERANK_TOP_K)Settings.embed_model = embed_modelSettings.llm = llm# 验证模型test_embedding = embed_model.get_text_embedding("测试文本")print(f"Embedding维度验证:{len(test_embedding)}")return embed_model, llm, reranker # 返回重排序器# ================== 数据处理 ==================
def load_and_validate_json_files(data_dir: str) -> List[Dict]:"""加载并验证JSON法律文件"""json_files = list(Path(data_dir).glob("*.json"))assert json_files, f"未找到JSON文件于 {data_dir}"all_data = []for json_file in json_files:with open(json_file, 'r', encoding='utf-8') as f:try:data = json.load(f)# 验证数据结构if not isinstance(data, list):raise ValueError(f"文件 {json_file.name} 根元素应为列表")for item in data:if not isinstance(item, dict):raise ValueError(f"文件 {json_file.name} 包含非字典元素")for k, v in item.items():if not isinstance(v, str):raise ValueError(f"文件 {json_file.name} 中键 '{k}' 的值不是字符串")all_data.extend({"content": item,"metadata": {"source": json_file.name}} for item in data)except Exception as e:raise RuntimeError(f"加载文件 {json_file} 失败: {str(e)}")print(f"成功加载 {len(all_data)} 个法律文件条目")return all_datadef create_nodes(raw_data: List[Dict]) -> List[TextNode]:"""添加ID稳定性保障"""nodes = []for entry in raw_data:law_dict = entry["content"]source_file = entry["metadata"]["source"]for full_title, content in law_dict.items():# 生成稳定ID(避免重复)node_id = f"{source_file}::{full_title}"parts = full_title.split(" ", 1)law_name = parts[0] if len(parts) > 0 else "未知法律"article = parts[1] if len(parts) > 1 else "未知条款"node = TextNode(text=content,id_=node_id, # 显式设置稳定IDmetadata={"law_name": law_name,"article": article,"full_title": full_title,"source_file": source_file,"content_type": "legal_article"})nodes.append(node)print(f"生成 {len(nodes)} 个文本节点(ID示例:{nodes[0].id_})")return nodes# ================== 向量存储 ==================def init_vector_store(nodes: List[TextNode]) -> VectorStoreIndex:chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)chroma_collection = chroma_client.get_or_create_collection(name=Config.COLLECTION_NAME,metadata={"hnsw:space": "cosine"})# 确保存储上下文正确初始化storage_context = StorageContext.from_defaults(vector_store=ChromaVectorStore(chroma_collection=chroma_collection))# 判断是否需要新建索引if chroma_collection.count() == 0 and nodes is not None:print(f"创建新索引({len(nodes)}个节点)...")# 显式将节点添加到存储上下文storage_context.docstore.add_documents(nodes) index = VectorStoreIndex(nodes,storage_context=storage_context,show_progress=True)# 双重持久化保障storage_context.persist(persist_dir=Config.PERSIST_DIR)index.storage_context.persist(persist_dir=Config.PERSIST_DIR) # <-- 新增else:print("加载已有索引...")storage_context = StorageContext.from_defaults(persist_dir=Config.PERSIST_DIR,vector_store=ChromaVectorStore(chroma_collection=chroma_collection))index = VectorStoreIndex.from_vector_store(storage_context.vector_store,storage_context=storage_context,embed_model=Settings.embed_model)# 安全验证print("\n存储验证结果:")doc_count = len(storage_context.docstore.docs)print(f"DocStore记录数:{doc_count}")if doc_count > 0:sample_key = next(iter(storage_context.docstore.docs.keys()))print(f"示例节点ID:{sample_key}")else:print("警告:文档存储为空,请检查节点添加逻辑!")return index#新增过滤函数
def is_legal_question(text: str) -> bool:"""判断问题是否属于法律咨询"""legal_keywords = ["劳动法", "合同", "工资", "工伤", "解除", "赔偿"]return any(keyword in text for keyword in legal_keywords)# ================== 新增评估类 ==================
class RecallEvaluator:def __init__(self, retriever, reranker):self.retriever = retrieverself.reranker = rerankerdef calculate_recall(self, retrieved_nodes, relevant_ids):retrieved_ids = [n.node.metadata["full_title"] for n in retrieved_nodes]hit = len(set(retrieved_ids) & set(relevant_ids))return hit / len(relevant_ids) if relevant_ids else 0.0def evaluate(self, benchmark):results = []for case in benchmark:# 初始检索initial_nodes = self.retriever.retrieve(case["question"])# 重排序reranked_nodes = self.reranker.postprocess_nodes(initial_nodes, query_str=case["question"])# 计算召回率recall = self.calculate_recall(reranked_nodes, case["relevant_ids"])results.append(recall)print(f"问题:{case['question']}")print(f"初始检索结果:{[n.node.metadata['full_title'] for n in initial_nodes]}")print(f"重排序后结果:{[n.node.metadata['full_title'] for n in reranked_nodes]}")print(f"召回条款:{[n.node.metadata['full_title'] for n in reranked_nodes[:3]]}")print(f"目标条款:{case['relevant_ids']}")print(f"召回率:{recall:.1%}\n")avg_recall = np.mean(results)print(f"平均召回率:{avg_recall:.1%}")return avg_recallclass E2EEvaluator:def __init__(self, query_engine):self.query_engine = query_enginedef evaluate_case(self, response, standard):try:# 获取实际命中的条款retrieved_clauses = [node.node.metadata["full_title"] for node in response.source_nodes]# 获取标准答案要求的条款required_clauses = standard["standard_answer"]["条款"]# 计算命中情况hit_clauses = list(set(retrieved_clauses) & set(required_clauses))missed_clauses = list(set(required_clauses) - set(retrieved_clauses))# 计算命中率clause_hit = len(hit_clauses) / len(required_clauses) if required_clauses else 0.0return {"clause_score": clause_hit,"hit_clauses": hit_clauses,"missed_clauses": missed_clauses}except Exception as e:print(f"评估失败:{str(e)}")return Nonedef evaluate(self, benchmark):results = []for case in benchmark:try:response = self.query_engine.query(case["question"])case_result = self.evaluate_case(response, case)if case_result:print(f"\n问题:{case['question']}")print(f"命中条款:{case_result['hit_clauses']}")print(f"缺失条款:{case_result['missed_clauses']}")print(f"条款命中率:{case_result['clause_score']:.1%}")results.append(case_result)else:results.append(None)except Exception as e:print(f"查询失败:{str(e)}")results.append(None)# 计算统计数据valid_results = [r for r in results if r is not None]avg_hit = np.mean([r["clause_score"] for r in valid_results]) if valid_results else 0print("\n=== 最终评估报告 ===")print(f"有效评估案例:{len(valid_results)}/{len(benchmark)}")print(f"平均条款命中率:{avg_hit:.1%}")# 输出详细错误分析for i, result in enumerate(results):if result is None:print(f"案例{i+1}:{benchmark[i]['question']} 评估失败")return results# ================== 新增测试数据集 ==================
RETRIEVAL_BENCHMARK = [# 劳动合同解除类{"question": "劳动者可以立即解除劳动合同的情形有哪些?","relevant_ids": ["中华人民共和国劳动合同法 第三十八条"],"confusing_ids": ["中华人民共和国劳动合同法 第三十九条", "中华人民共和国劳动法 第三十二条"]},{"question": "用人单位单方解除劳动合同需要提前多久通知?","relevant_ids": ["中华人民共和国劳动合同法 第四十条"],"confusing_ids": ["中华人民共和国劳动合同法 第三十七条", "中华人民共和国劳动法 第二十六条"]},# 工资与补偿类{"question": "经济补偿金的计算标准是什么?","relevant_ids": ["中华人民共和国劳动合同法 第四十七条"],"confusing_ids": ["中华人民共和国劳动合同法 第八十七条", "中华人民共和国劳动法 第二十八条"]},{"question": "试用期工资最低标准是多少?","relevant_ids": ["中华人民共和国劳动合同法 第二十条"],"confusing_ids": ["中华人民共和国劳动合同法 第十九条", "中华人民共和国劳动法 第四十八条"]},# 工伤与福利类{"question": "工伤认定需要哪些材料?","relevant_ids": ["中华人民共和国劳动合同法 第三十条"],"confusing_ids": ["中华人民共和国劳动法 第七十三条", "中华人民共和国劳动合同法 第十七条"]},{"question": "女职工产假有多少天?","relevant_ids": ["中华人民共和国劳动法 第六十二条"],"confusing_ids": ["中华人民共和国劳动合同法 第四十二条", "中华人民共和国劳动法 第六十一条"]},# 劳动合同订立类{"question": "无固定期限劳动合同的订立条件是什么?","relevant_ids": ["中华人民共和国劳动合同法 第十四条"],"confusing_ids": ["中华人民共和国劳动合同法 第十三条", "中华人民共和国劳动法 第二十条"]},{"question": "劳动合同必须包含哪些条款?","relevant_ids": ["中华人民共和国劳动合同法 第十七条"],"confusing_ids": ["中华人民共和国劳动法 第十九条", "中华人民共和国劳动合同法 第十条"]},# 特殊用工类{"question": "劳务派遣岗位的限制条件是什么?","relevant_ids": ["中华人民共和国劳动合同法 第六十六条"],"confusing_ids": ["中华人民共和国劳动合同法 第五十八条", "中华人民共和国劳动法 第二十条"]},{"question": "非全日制用工的每日工作时间上限?","relevant_ids": ["中华人民共和国劳动合同法 第六十八条"],"confusing_ids": ["中华人民共和国劳动法 第三十六条", "中华人民共和国劳动合同法 第三十八条"]},# 劳动合同终止类{"question": "劳动合同终止的法定情形有哪些?","relevant_ids": ["中华人民共和国劳动合同法 第四十四条"],"confusing_ids": ["中华人民共和国劳动合同法 第四十六条", "中华人民共和国劳动法 第二十三条"]},{"question": "劳动合同期满后必须续签的情形?","relevant_ids": ["中华人民共和国劳动合同法 第四十五条"],"confusing_ids": ["中华人民共和国劳动合同法 第十四条", "中华人民共和国劳动法 第二十条"]},# 劳动保护类{"question": "女职工哺乳期工作时间限制?","relevant_ids": ["中华人民共和国劳动法 第六十三条"],"confusing_ids": ["中华人民共和国劳动合同法 第四十二条", "中华人民共和国劳动法 第六十一条"]},{"question": "未成年工禁止从事的劳动类型?","relevant_ids": ["中华人民共和国劳动法 第六十四条"],"confusing_ids": ["中华人民共和国劳动法 第五十九条", "中华人民共和国劳动合同法 第六十六条"]},{"question": "工伤保险待遇包含哪些项目?","relevant_ids": ["中华人民共和国劳动法 第七十三条"],"confusing_ids": ["中华人民共和国劳动合同法 第三十条", "中华人民共和国劳动法 第四十四条"]},# 劳动争议类{"question": "劳动争议仲裁时效是多久?","relevant_ids": ["中华人民共和国劳动法 第八十二条"],"confusing_ids": ["中华人民共和国劳动合同法 第六十条", "中华人民共和国劳动法 第七十九条"]},{"question": "集体合同的法律效力如何?","relevant_ids": ["中华人民共和国劳动法 第三十五条"],"confusing_ids": ["中华人民共和国劳动合同法 第五十五条", "中华人民共和国劳动法 第三十三条"]},# 特殊条款类{"question": "服务期违约金的上限规定?","relevant_ids": ["中华人民共和国劳动合同法 第二十二条"],"confusing_ids": ["中华人民共和国劳动合同法 第二十三条", "中华人民共和国劳动法 第一百零二条"]},{"question": "无效劳动合同的认定标准?","relevant_ids": ["中华人民共和国劳动合同法 第二十六条"],"confusing_ids": ["中华人民共和国劳动法 第十八条", "中华人民共和国劳动合同法 第三十九条"]}
]E2E_BENCHMARK = [# 案例1:劳动合同解除{"question": "用人单位在哪些情况下不得解除劳动合同?","standard_answer": {"条款": ["中华人民共和国劳动合同法 第四十二条"],"标准答案": "根据《劳动合同法》第四十二条,用人单位不得解除劳动合同的情形包括:\n1. 从事接触职业病危害作业的劳动者未进行离岗前职业健康检查\n2. 在本单位患职业病或者因工负伤并被确认丧失/部分丧失劳动能力\n3. 患病或非因工负伤在规定的医疗期内\n4. 女职工在孕期、产期、哺乳期\n5. 连续工作满15年且距退休不足5年\n6. 法律、行政法规规定的其他情形\n违法解除需按第八十七条支付二倍经济补偿金","必备条件": ["职业病危害作业未检查", "孕期女职工", "连续工作满15年"]}},# 案例2:工资支付{"question": "拖欠工资劳动者可以采取哪些措施?","standard_answer": {"条款": ["中华人民共和国劳动合同法 第三十条", "中华人民共和国劳动法 第五十条"],"标准答案": "劳动者可采取以下救济措施:\n1. 根据劳动合同法第三十条向法院申请支付令\n2. 依据劳动合同法第三十八条解除合同并要求经济补偿\n3. 向劳动行政部门投诉\n逾期未支付的,用人单位需按应付金额50%-100%加付赔偿金(劳动合同法第八十五条)","必备条件": ["支付令申请", "解除劳动合同", "行政投诉"]}},# 案例3:竞业限制{"question": "竞业限制的最长期限是多久?","standard_answer": {"条款": ["中华人民共和国劳动合同法 第二十四条"],"标准答案": "根据劳动合同法第二十四条:\n- 竞业限制期限不得超过二年\n- 适用人员限于高管/高级技术人员/其他保密人员\n- 需按月支付经济补偿\n注意区分服务期约定(第二十二条)","限制条件": ["期限≤2年", "按月支付补偿"]}},# 案例4:劳务派遣{"question": "劳务派遣用工的比例限制是多少?","standard_answer": {"条款": ["中华人民共和国劳动合同法 第六十六条"],"标准答案": "劳务派遣用工限制:\n- 临时性岗位不超过6个月\n- 辅助性岗位≤用工总量10%\n- 违法派遣按每人1000-5000元罚款(第九十二条)\n派遣协议需包含岗位/期限/报酬等条款(第五十九条)","限制条件": ["临时性≤6月", "辅助性≤10%"]}},# 案例5:非全日制用工{"question": "非全日制用工的工资支付周期要求?","standard_answer": {"条款": ["中华人民共和国劳动合同法 第七十二条"],"标准答案": "非全日制用工支付规则:\n- 工资结算周期≤15日\n- 小时工资≥当地最低标准\n- 终止用工不支付经济补偿(第七十一条)\n区别于全日制月薪制(第三十条)","支付规则": ["周期≤15天", "小时工资≥最低标准"]}},# 案例6:劳动合同无效{"question": "劳动合同被确认无效后的工资支付标准?","standard_answer": {"条款": ["中华人民共和国劳动合同法 第二十八条"],"标准答案": "无效劳动合同的工资支付:\n1. 参照本单位相同岗位工资支付\n2. 无相同岗位的按市场价\n3. 已付报酬不足的需补差\n过错方需承担赔偿责任(第八十六条)","支付规则": ["参照同岗位", "市场价补差"]}}
]# ================== 主程序 ==================
def main():embed_model, llm, reranker = init_models() # 获取重排序器# 仅当需要更新数据时执行if not Path(Config.VECTOR_DB_DIR).exists():print("\n初始化数据...")raw_data = load_and_validate_json_files(Config.DATA_DIR)nodes = create_nodes(raw_data)else:nodes = Noneprint("\n初始化向量存储...")start_time = time.time()index = init_vector_store(nodes)print(f"索引加载耗时:{time.time()-start_time:.2f}s")# 创建检索器和响应合成器(修改部分)retriever = index.as_retriever(similarity_top_k=Config.TOP_K # 扩大初始检索数量)query_engine = index.as_query_engine(similarity_top_k=Config.TOP_K,node_postprocessors=[reranker])response_synthesizer = get_response_synthesizer(# text_qa_template=response_template,verbose=True)# 新增评估模式run_mode = input("请选择模式:1-问答模式 2-评估模式\n输入选项:")if run_mode == "2":print("\n=== 开始评估 ===")# 召回率评估recall_evaluator = RecallEvaluator(retriever, reranker)recall_result = recall_evaluator.evaluate(RETRIEVAL_BENCHMARK)# 端到端评估e2e_evaluator = E2EEvaluator(query_engine)e2e_results = e2e_evaluator.evaluate(E2E_BENCHMARK)# 生成报告print("\n=== 最终评估报告 ===")print(f"重排序召回率:{recall_result:.1%}")print(f"端到端条款命中率:{np.mean([r['clause_score'] for r in e2e_results]):.1%}")return# 示例查询while True:question = input("\n请输入劳动法相关问题(输入q退出): ")if question.lower() == 'q':break# 添加问答类型判断(关键修改)# if not is_legal_question(question): # 新增判断函数# print("\n您好!我是劳动法咨询助手,专注解答《劳动法》《劳动合同法》等相关问题。")# continue# 执行检索-重排序-过滤-回答流程start_time = time.time()# 1. 初始检索initial_nodes = retriever.retrieve(question)retrieval_time = time.time() - start_time# 2. 重排序reranked_nodes = reranker.postprocess_nodes(initial_nodes, query_str=question)rerank_time = time.time() - start_time - retrieval_time# ★★★★★ 添加过滤逻辑在此处 ★★★★★MIN_RERANK_SCORE = 0.4# 执行过滤filtered_nodes = [node for node in reranked_nodes if node.score > MIN_RERANK_SCORE]# for node in reranked_nodes:# print(node.score)#一般对模型的回复做限制就从filtered_nodes的返回值下手print("原始分数样例:",[node.score for node in reranked_nodes[:3]])print("重排序过滤后的结果:",filtered_nodes)# 空结果处理if not filtered_nodes:print("你的问题未匹配到相关资料!")continue# 3. 合成答案(使用过滤后的节点)response = response_synthesizer.synthesize(question, nodes=filtered_nodes # 使用过滤后的节点)synthesis_time = time.time() - start_time - retrieval_time - rerank_time# 显示结果(修改显示逻辑)print(f"\n智能助手回答:\n{response.response}")print("\n支持依据:")for idx, node in enumerate(reranked_nodes, 1):# 兼容新版API的分数获取方式initial_score = node.metadata.get('initial_score', node.score) # 获取初始分数rerank_score = node.score # 重排序后的分数meta = node.node.metadataprint(f"\n[{idx}] {meta['full_title']}")print(f" 来源文件:{meta['source_file']}")print(f" 法律名称:{meta['law_name']}")print(f" 初始相关度:{node.node.metadata.get('initial_score', 0):.4f}") # 安全访问print(f" 重排序得分:{getattr(node, 'score', 0):.4f}") # 兼容属性访问print(f" 条款内容:{node.node.text[:100]}...")print(f"\n[性能分析] 检索: {retrieval_time:.2f}s | 重排序: {rerank_time:.2f}s | 合成: {synthesis_time:.2f}s")if __name__ == "__main__":main()
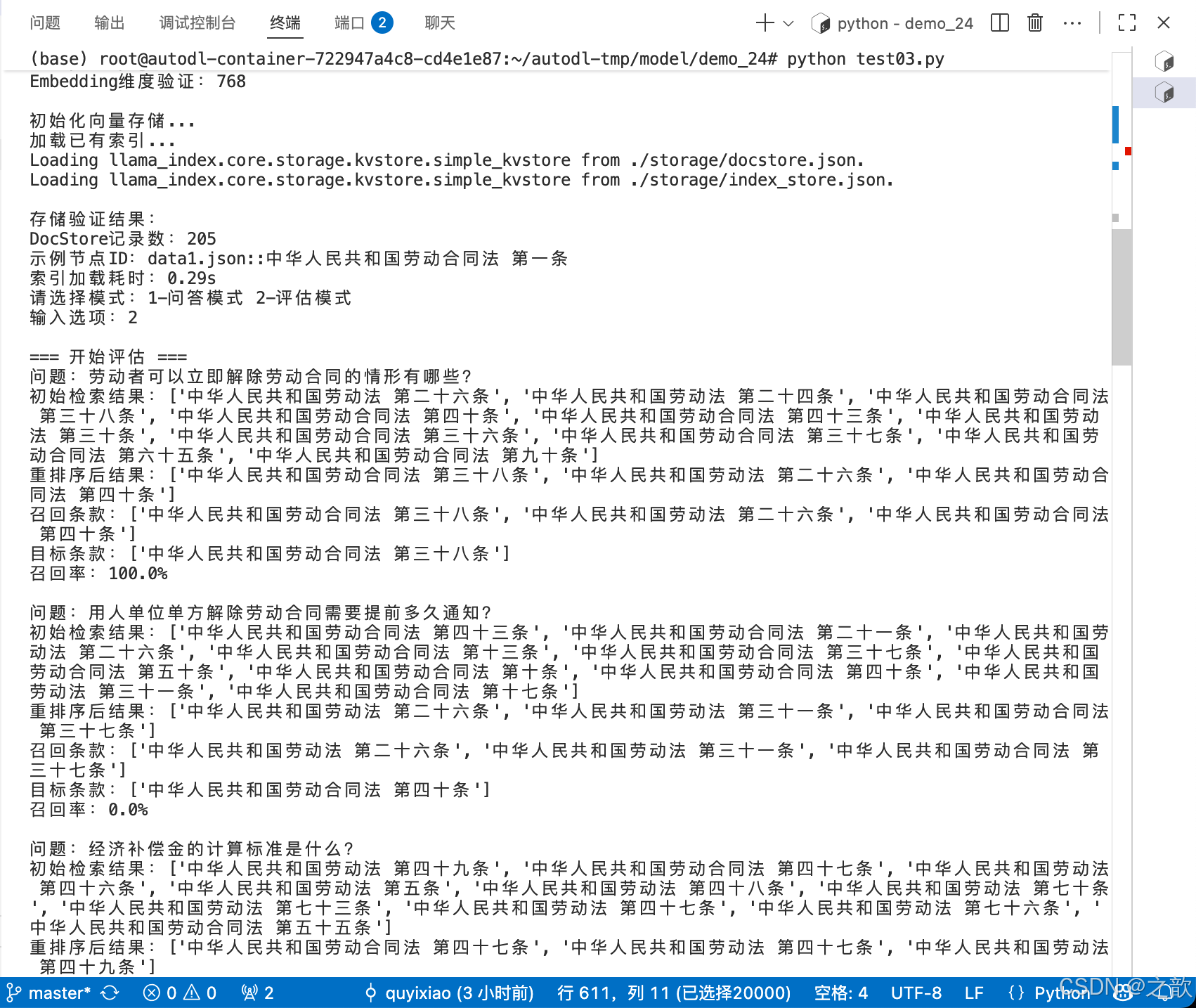
3. Streamlit界面深度集成
3.1 增强型交互设计
def build_enhanced_interface():st.sidebar.title("高级选项")# 新增调试面板debug_mode = st.sidebar.checkbox("显示分析过程")retrieval_num = st.sidebar.slider("检索条款数", 3, 10, 5)# 主界面优化question = st.text_area("请输入法律问题:",placeholder="例如:试用期被辞退如何获得补偿?",height=120)if st.button("智能分析", help="点击提交法律咨询"):with st.spinner("正在检索相关法律条款..."):response = query_engine.query(question,retrieval_num=retrieval_num)# 主体识别高亮if "[用人单位]" in response.response:st.success("**主体类型识别**: 用人单位相关条款")elif "[劳动者]" in response.response:st.success("**主体类型识别**: 劳动者相关条款")# 分栏展示col1, col2 = st.columns([3, 2])with col1:st.markdown(f"### 法律建议\n{response.response}")with col2:with st.expander("⚖ 关联条款分析"):visualize_score_distribution(response.scores)
启动streamlit
pip install streamlit
streamlit run test04.py --server.address=0.0.0.0 --server.fileWatcherType none
# -*- coding: utf-8 -*-
import json
import time
from pathlib import Path
from typing import List, Dict
import re
import chromadb
import streamlit as st
from llama_index.core import VectorStoreIndex, StorageContext, Settings, get_response_synthesizer
from llama_index.core.schema import TextNode
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import PromptTemplate
from llama_index.core.postprocessor import SentenceTransformerRerank
from llama_index.llms.openai_like import OpenAILike# ================== Streamlit页面配置 ==================
st.set_page_config(page_title="智能劳动法咨询助手",page_icon="⚖️",layout="centered",initial_sidebar_state="auto"
)def disable_streamlit_watcher():"""Patch Streamlit to disable file watcher"""def _on_script_changed(_):returnfrom streamlit import runtimeruntime.get_instance()._on_script_changed = _on_script_changed# ================== 配置类 ==================
class Config:EMBED_MODEL_PATH = r"/root/autodl-tmp/demo/sungw111/text2vec-base-chinese-sentence"RERANK_MODEL_PATH = r"/root/autodl-tmp/demo/BAAI/bge-reranker-large" # 新增重排序模型路径LLM_MODEL_PATH = r"/root/autodl-tmp/demo/Qwen/Qwen1.5-1.8B-Chat"DATA_DIR = "./data"VECTOR_DB_DIR = "./chroma_db"PERSIST_DIR = "./storage"COLLECTION_NAME = "chinese_labor_laws"TOP_K = 10RERANK_TOP_K = 3# ================== 缓存资源初始化 ==================
@st.cache_resource(show_spinner="初始化模型中...")
def init_models():embed_model = HuggingFaceEmbedding(model_name=Config.EMBED_MODEL_PATH,)llm = OpenAILike(model="/root/autodl-tmp/demo/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",api_base="http://localhost:23333/v1",api_key="fake",context_window=4096,is_chat_model=True,is_function_calling_model=False,)# llm = OpenAILike(# model="glm-4", # 可选模型:glm-4, glm-3-turbo, characterglm等# api_base="https://open.bigmodel.cn/api/paas/v4", # 关键!必须指定此端点# api_key="xxxxxx",# context_window=128000, # 按需调整(glm-4实际支持128K)# is_chat_model=True,# is_function_calling_model=False, # GLM暂不支持函数调用# max_tokens=1024, # 最大生成token数(按需调整)# temperature=0.3, # 推荐范围 0.1~1.0# top_p=0.7 # 推荐范围 0.5~1.0# )reranker = SentenceTransformerRerank(model=Config.RERANK_MODEL_PATH,top_n=Config.RERANK_TOP_K)Settings.embed_model = embed_modelSettings.llm = llmreturn embed_model, llm, reranker@st.cache_resource(show_spinner="加载知识库中...")
def init_vector_store(_nodes):chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)chroma_collection = chroma_client.get_or_create_collection(name=Config.COLLECTION_NAME,metadata={"hnsw:space": "cosine"})storage_context = StorageContext.from_defaults(vector_store=ChromaVectorStore(chroma_collection=chroma_collection))if chroma_collection.count() == 0 and _nodes is not None:storage_context.docstore.add_documents(_nodes) index = VectorStoreIndex(_nodes,storage_context=storage_context,show_progress=True)storage_context.persist(persist_dir=Config.PERSIST_DIR)index.storage_context.persist(persist_dir=Config.PERSIST_DIR)else:storage_context = StorageContext.from_defaults(persist_dir=Config.PERSIST_DIR,vector_store=ChromaVectorStore(chroma_collection=chroma_collection))index = VectorStoreIndex.from_vector_store(storage_context.vector_store,storage_context=storage_context,embed_model=Settings.embed_model)return index# ================== 数据处理 ==================
def load_and_validate_json_files(data_dir: str) -> List[Dict]:"""加载并验证JSON法律文件"""json_files = list(Path(data_dir).glob("*.json"))assert json_files, f"未找到JSON文件于 {data_dir}"all_data = []for json_file in json_files:with open(json_file, 'r', encoding='utf-8') as f:try:data = json.load(f)# 验证数据结构if not isinstance(data, list):raise ValueError(f"文件 {json_file.name} 根元素应为列表")for item in data:if not isinstance(item, dict):raise ValueError(f"文件 {json_file.name} 包含非字典元素")for k, v in item.items():if not isinstance(v, str):raise ValueError(f"文件 {json_file.name} 中键 '{k}' 的值不是字符串")all_data.extend({"content": item,"metadata": {"source": json_file.name}} for item in data)except Exception as e:raise RuntimeError(f"加载文件 {json_file} 失败: {str(e)}")print(f"成功加载 {len(all_data)} 个法律文件条目")return all_datadef create_nodes(raw_data: List[Dict]) -> List[TextNode]:"""添加ID稳定性保障"""nodes = []for entry in raw_data:law_dict = entry["content"]source_file = entry["metadata"]["source"]for full_title, content in law_dict.items():# 生成稳定ID(避免重复)node_id = f"{source_file}::{full_title}"parts = full_title.split(" ", 1)law_name = parts[0] if len(parts) > 0 else "未知法律"article = parts[1] if len(parts) > 1 else "未知条款"node = TextNode(text=content,id_=node_id, # 显式设置稳定IDmetadata={"law_name": law_name,"article": article,"full_title": full_title,"source_file": source_file,"content_type": "legal_article"})nodes.append(node)print(f"生成 {len(nodes)} 个文本节点(ID示例:{nodes[0].id_})")return nodes
# ================== 界面组件 ==================
def init_chat_interface():if "messages" not in st.session_state:st.session_state.messages = []for msg in st.session_state.messages:role = msg["role"]content = msg.get("cleaned", msg["content"]) # 优先使用清理后的内容with st.chat_message(role):st.markdown(content)# 如果是助手消息且包含思维链if role == "assistant" and msg.get("think"):with st.expander("📝 模型思考过程(历史对话)"):for think_content in msg["think"]:st.markdown(f'<span style="color: #808080">{think_content.strip()}</span>',unsafe_allow_html=True)# 如果是助手消息且有参考依据(需要保持原有参考依据逻辑)if role == "assistant" and "reference_nodes" in msg:show_reference_details(msg["reference_nodes"])def show_reference_details(nodes):with st.expander("查看支持依据"):for idx, node in enumerate(nodes, 1):meta = node.node.metadatast.markdown(f"**[{idx}] {meta['full_title']}**")st.caption(f"来源文件:{meta['source_file']} | 法律名称:{meta['law_name']}")st.markdown(f"相关度:`{node.score:.4f}`")# st.info(f"{node.node.text[:300]}...")st.info(f"{node.node.text}")# ================== 主程序 ==================
def main():# 禁用 Streamlit 文件热重载disable_streamlit_watcher()st.title("⚖️ 智能劳动法咨询助手")st.markdown("欢迎使用劳动法智能咨询系统,请输入您的问题,我们将基于最新劳动法律法规为您解答。")# 初始化会话状态if "history" not in st.session_state:st.session_state.history = []# 加载模型和索引embed_model, llm, reranker = init_models()# 初始化数据if not Path(Config.VECTOR_DB_DIR).exists():with st.spinner("正在构建知识库..."):raw_data = load_and_validate_json_files(Config.DATA_DIR)nodes = create_nodes(raw_data)else:nodes = Noneindex = init_vector_store(nodes)retriever = index.as_retriever(similarity_top_k=Config.TOP_K,vector_store_query_mode="hybrid",alpha=0.5)# 调整检索器配置(扩大召回范围并启用混合检索)# retriever = index.as_retriever(# similarity_top_k=20, # 从10提升到20# vector_store_query_mode="hybrid", # 混合检索模式# alpha=0.5, # 平衡密集检索与稀疏检索# filters={"content_type": "legal_article"} # 添加元数据过滤# )response_synthesizer = get_response_synthesizer(verbose=True)# 聊天界面init_chat_interface()if prompt := st.chat_input("请输入劳动法相关问题"):# 添加用户消息到历史st.session_state.messages.append({"role": "user", "content": prompt})with st.chat_message("user"):st.markdown(prompt)# 处理查询with st.spinner("正在分析问题..."):start_time = time.time()# 检索流程initial_nodes = retriever.retrieve(prompt)reranked_nodes = reranker.postprocess_nodes(initial_nodes, query_str=prompt)# 过滤节点MIN_RERANK_SCORE = 0.4filtered_nodes = [node for node in reranked_nodes if node.score > MIN_RERANK_SCORE]if not filtered_nodes:response_text = "⚠️ 未找到相关法律条文,请尝试调整问题描述或咨询专业律师。"else:# 生成回答response = response_synthesizer.synthesize(prompt, nodes=filtered_nodes)response_text = response.response# 显示回答with st.chat_message("assistant"):# 提取思维链内容并清理响应文本think_contents = re.findall(r'<think>(.*?)</think>', response_text, re.DOTALL)cleaned_response = re.sub(r'<think>.*?</think>', '', response_text, flags=re.DOTALL).strip()# 显示清理后的回答st.markdown(cleaned_response)# 如果有思维链内容则显示if think_contents:with st.expander("📝 模型思考过程(点击展开)"):for content in think_contents:st.markdown(f'<span style="color: #808080">{content.strip()}</span>', unsafe_allow_html=True)# 显示参考依据(保持原有逻辑)show_reference_details(filtered_nodes[:3])# 添加助手消息到历史(需要存储原始响应)st.session_state.messages.append({"role": "assistant","content": response_text, # 保留原始响应"cleaned": cleaned_response, # 存储清理后的文本"think": think_contents # 存储思维链内容})if __name__ == "__main__":main()
界面

所有的 git 代码 https://gitee.com/quyixiao/model.git