whisper-large-v3部署详细步骤,包括cpu和gpu方式,跟着做一次成功
部署背景
whisper就是一个语音识别的项目,具体细节自行百度了解即可。我这次部署的主要目的是简单测试粤语歌曲的歌词识别效果,之后再抽空做二次开发。讲实话,这些ai模型项目的部署文档大部分就是一坨屎,依赖模块只给出几个,其他模块要在运行代码时出错再一个个修复安装。更痛苦的是,有些是依赖于特定版本模块的,安装错了版本直接各种神奇报错,要一个个版本去试,或者到相应的github issues上面看看。
这里我直接把自己跑通代码时用到的具体依赖模块和对应版本贴出来,避免大家继续做填坑这种无意义的体力劳动。
Demo代码
测试代码如下(主要改篇自这里给出的demo:whisper-large-v3 · 模型库),将该代码保存为test.py
import torch
from modelscope import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
from datetime import datetimestart_time = datetime.now()device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32# device = 'cpu'
# torch_dtype = torch.float32model_id = "AI-ModelScope/whisper-large-v3"model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)processor = AutoProcessor.from_pretrained(model_id)pipe = pipeline("automatic-speech-recognition",model=model,tokenizer=processor.tokenizer,feature_extractor=processor.feature_extractor,dtype=torch_dtype,device=device,)result = pipe("test_3.mp3", generate_kwargs={"language": "cantonese"})# dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
# sample = dataset[0]["audio"]# result = pipe(sample)
print(result["text"])end_time = datetime.now()
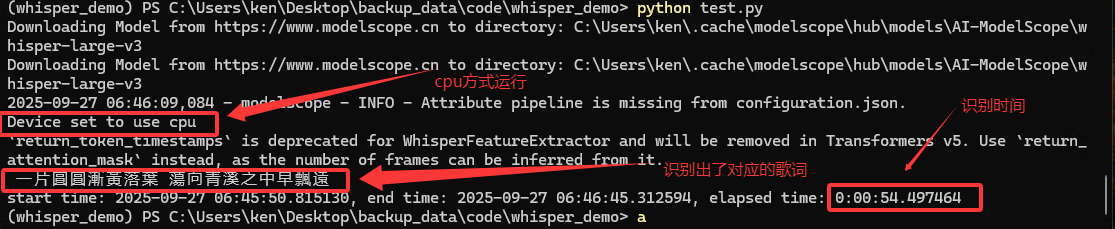
print(f'start time: {start_time}, end time: {end_time}, elapsed time: {end_time - start_time}')上述代码中的test_3.mp3是一首粤语歌曲中片段(叶倩文的祝福),generate_kwargs中的cantonese指定为粤语识别。
系统环境说明
由于我windows系统没有显卡,只有一张显卡在ubuntu系统上。所以我将在windows系统上部署cpu版本的whisper, ubuntu系统上部署cuda版本的whisper。
系统具体信息如下:
windows:以hyper-v虚拟机方式安装 windows 11 24h2工作站专业版,分配16G内存,16核(cpu为xeon d1581)
ubuntu:以hyper-v虚拟方式安装ubuntu server 22.04,分配了24G内存,20核(pu为xeon d1581),以dda方式直通了p104-100显卡(8G显存)
具体步骤(windows篇)
安装miniconda
(直接参考官方文档即可:Installing Miniconda - Anaconda)
备注:这里我推荐使用conda环境,如果直接使用python自带的虚拟环境,大可能会因为的ffmpeg依赖问题无法正常运行
创建虚拟环境
打开Anaconda PowerShell Prompt,输入以下代码
conda create -n whisper_demo python=3.11激活虚拟环境
conda activate whisper_demo安装pytorch相关模块
以cpu方式运行,所以安装这个
pip install torch==2.8.0 torchvision torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cpu
安装其他依赖模块
pip install modelscope datasets==3.6.0 transformers accelerate addict simplejson sortedcontainers安装ffmpeg
conda install ffmpeg 注:ffmpeg安装这一步我试了很多其他的方法,包括手动下载相应版本ffmpeg.exe,并设置系统环境变量,都出错了。只有通过conda来安装ffmpeg才成功。
运行代码
先进入到test.py所在目录,请自行修改为正确的目录
cd C:\Users\ken\Desktop\backup_data\code\whisper_demo然后执行以下代码
python test.py第一次运行时,会从modelscope下载非常多的模型文件,慢慢等吧
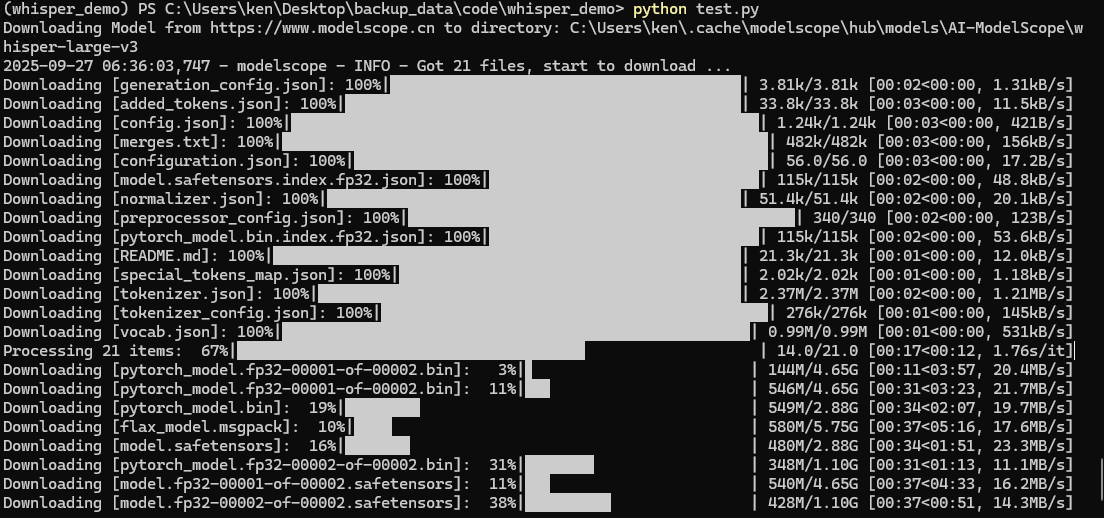
运行结果
上面也运行出结果,但由于第一次运行,把下载时间也统计进去了,所以这里再重新执行python test.py运行一遍
如下图所示
全部依赖模块版本
(whisper_demo) PS C:\Users\ken\Desktop\backup_data\code\whisper_demo> pip list
Package Version
------------------ -----------
accelerate 1.10.1
addict 2.4.0
aiohappyeyeballs 2.6.1
aiohttp 3.12.15
aiosignal 1.4.0
attrs 25.3.0
certifi 2025.8.3
charset-normalizer 3.4.3
colorama 0.4.6
datasets 3.6.0
dill 0.3.8
filelock 3.13.1
frozenlist 1.7.0
fsspec 2024.6.1
huggingface-hub 0.35.1
idna 3.10
Jinja2 3.1.4
MarkupSafe 2.1.5
modelscope 1.30.0
mpmath 1.3.0
multidict 6.6.4
multiprocess 0.70.16
networkx 3.3
numpy 2.1.2
packaging 25.0
pandas 2.3.2
pillow 11.0.0
pip 25.2
propcache 0.3.2
psutil 7.1.0
pyarrow 21.0.0
python-dateutil 2.9.0.post0
pytz 2025.2
PyYAML 6.0.3
regex 2025.9.18
requests 2.32.5
safetensors 0.6.2
setuptools 78.1.1
simplejson 3.20.2
six 1.17.0
sortedcontainers 2.4.0
sympy 1.13.3
tokenizers 0.22.1
torch 2.8.0+cpu
torchaudio 2.8.0+cpu
torchvision 0.23.0+cpu
tqdm 4.67.1
transformers 4.56.2
typing_extensions 4.12.2
tzdata 2025.2
urllib3 2.5.0
wheel 0.45.1
xxhash 3.5.0
yarl 1.20.1具体步骤(ubuntu篇)
安装miniconda
(直接参考官方文档即可:Installing Miniconda - Anaconda)
创建虚拟环境
conda create -n whisper_demo python=3.11激活虚拟环境
conda activate whisper_demo安装pytorch相关模块
以cuda方式运行,所以安装这个
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
注:因为我的显卡比较老,所以最高支持到cuda12.4,如果你的显卡支持该cuda版本,这些torch相关的模块版本可能都要做相应的修改了。
安装其他依赖模块
pip install modelscope datasets==3.6.0 transformers accelerate addict simplejson sortedcontainers安装ffmpeg
conda install ffmpeg 运行代码
先进入到test.py所在目录,请自行修改为正确的目录
cd ~/whisper_demo然后执行以下代码
python test.py与前面的windows部署一样,第一次运行时,会从modelscope下载非常多的模型文件,所以也得慢慢等。
运行结果
执行python test.py运行一遍
如下图所示

全部依赖模块版本
(whisper_demo) ken@ubuntugpu:~/whisper_demo$ pip list
Package Version
------------------------ ------------
accelerate 1.10.1
addict 2.4.0
aiohappyeyeballs 2.6.1
aiohttp 3.12.15
aiosignal 1.4.0
attrs 25.3.0
certifi 2025.8.3
charset-normalizer 3.4.3
datasets 3.6.0
dill 0.3.8
filelock 3.13.1
frozenlist 1.7.0
fsspec 2024.6.1
hf-xet 1.1.10
huggingface-hub 0.35.1
idna 3.10
Jinja2 3.1.4
MarkupSafe 2.1.5
modelscope 1.30.0
mpmath 1.3.0
multidict 6.6.4
multiprocess 0.70.16
networkx 3.3
numpy 2.1.2
nvidia-cublas-cu12 12.4.5.8
nvidia-cuda-cupti-cu12 12.4.127
nvidia-cuda-nvrtc-cu12 12.4.127
nvidia-cuda-runtime-cu12 12.4.127
nvidia-cudnn-cu12 9.1.0.70
nvidia-cufft-cu12 11.2.1.3
nvidia-curand-cu12 10.3.5.147
nvidia-cusolver-cu12 11.6.1.9
nvidia-cusparse-cu12 12.3.1.170
nvidia-cusparselt-cu12 0.6.2
nvidia-nccl-cu12 2.21.5
nvidia-nvjitlink-cu12 12.4.127
nvidia-nvtx-cu12 12.4.127
packaging 25.0
pandas 2.3.2
pillow 11.0.0
pip 25.2
propcache 0.3.2
psutil 7.1.0
pyarrow 21.0.0
python-dateutil 2.9.0.post0
pytz 2025.2
PyYAML 6.0.3
regex 2025.9.18
requests 2.32.5
safetensors 0.6.2
setuptools 78.1.1
simplejson 3.20.2
six 1.17.0
sortedcontainers 2.4.0
sympy 1.13.1
tokenizers 0.22.1
torch 2.6.0+cu124
torchaudio 2.6.0+cu124
torchvision 0.21.0+cu124
tqdm 4.67.1
transformers 4.56.2
triton 3.2.0
typing_extensions 4.12.2
tzdata 2025.2
urllib3 2.5.0
wheel 0.45.1
xxhash 3.5.0
yarl 1.20.1一些有用的ffmpeg命令
剪切最后20秒的音频
.\ffmpeg -sseof -20 -i test.mp3 -c copy test_2.mp3剪切第40秒到65秒之间的音频
.\ffmpeg -i "test.mp3" -ss 00:00:40 -to 00:01:05 -c copy test_3.mp3一些坑备注
(1) 使用python自带虚拟环境时,运行出错torchcodec(ffmpeg)的错误:
RuntimeError: Could not load libtorchcodec. Likely causes: 1. FFmpeg is not properly installed in your environment
如下图所示:
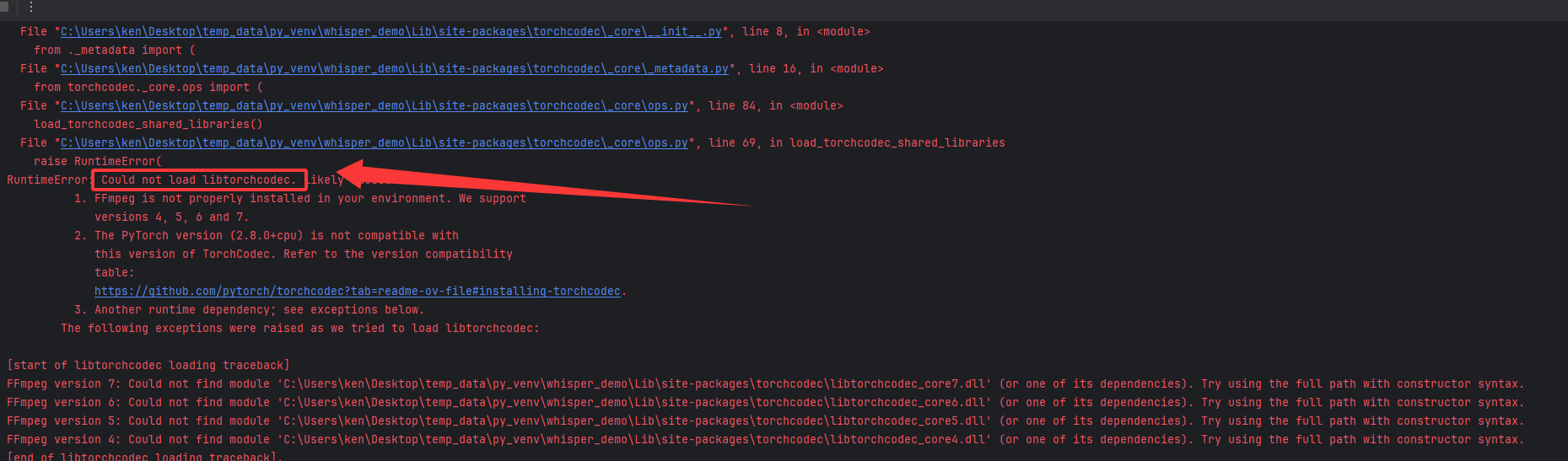
解决办法:改用conda来创建虚拟环境,并使用conda来安装ffmpeg, 前面已提到过。
(2) 如果使用链接中的样例代码,即可能遇到datasets下载不了数据的问题,这是版本原因造成的,可根据我前面pip指令中指定的版本来安装即可。
参考:modelscope下载数据集datasets版本问题_importerror: cannot import name 'largelist' from '-CSDN博客
一些待解决的问题
(1) 上述的test_3.mp3有28秒的长度,但只输出了最后几秒的歌曲,留待之后再解决,目前关注点在于跑通代码
(2) 换用其他的粤语音频时(例如2岁小孩唱的儿歌,客观上咬字没那么清晰,但人耳能分辨出来),识别效果完全不行,这个也留待之后分析
一些可能有用的链接
Whisper语音识别-多语言-large-v3 · 模型库
whisper-large-v3 · 模型库
ChenChenyu/whisper-large-v3-turbo-finetuned · Hugging Face
whisper-large-v2-cantonese开源粤语语音识别模型 - 精准识别,低字错率!
使用Whisper本地部署实现香港版粤语+英语混合语音转文字方案 - 技术栈