批次标准化学习(第十六周周报)
摘要
本文系统阐述了深度学习中的规范化技术,重点分析了特征归一化和批量归一化的原理与作用。文章首先通过损失曲面可视化对比,说明输入特征归一化如何通过优化损失地形显著提升训练效率。进而深入探讨深度网络隐藏层激活值分布不稳定性问题,引入批量归一化技术解决内部协变量偏移。最后解析批量归一化在测试阶段的移动平均机制,确保模型推理时的稳定性。全文完整呈现了规范化技术从输入层到隐藏层、从训练到推理的全流程优化方案。
Abstract
This article systematically elaborates normalization techniques in deep learning, focusing on the principles and functions of feature normalization and batch normalization. It first demonstrates how input feature normalization optimizes the loss landscape to significantly improve training efficiency through visualized loss surface comparisons. Then it delves into the instability of hidden layer activation distributions in deep networks, introducing batch normalization to address internal covariate shift. Finally, it analyzes the moving average mechanism of batch normalization during testing phase to ensure model stability during inference. The paper presents a complete optimization pipeline of normalization techniques from input layer to hidden layers, and from training to inference.
目录
1 规范化
2 隐藏层归一
3 总结
1 规范化
通过规范化输入特征来优化损失曲面,从而提升模型训练效率。
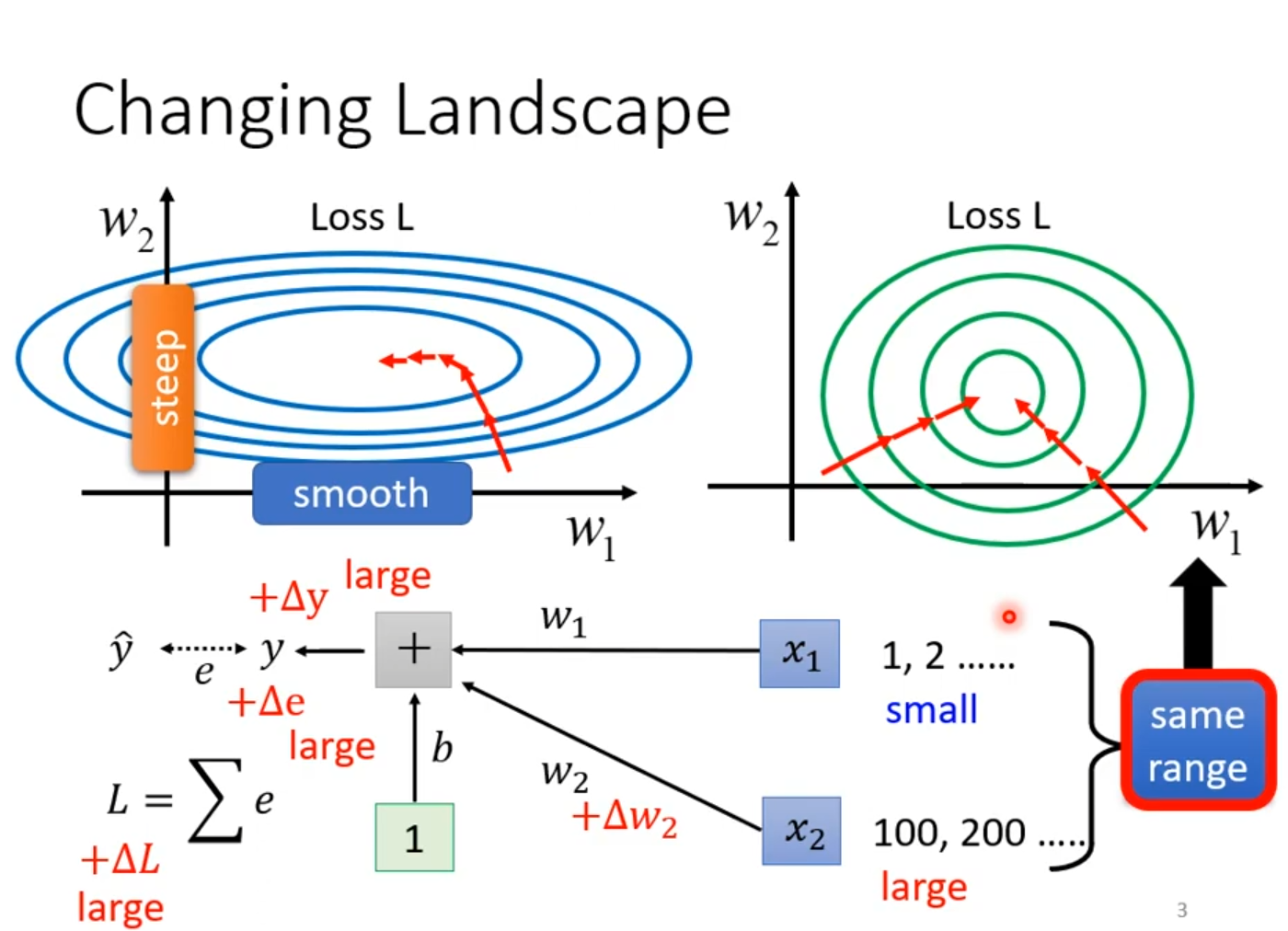
图的左侧描绘了未经处理的原始损失曲面,其形状崎岖不平,等高线在w₂轴方向非常密集,表明曲面在此方向上非常陡峭,而在w₁轴方向则相对平缓。这种不均匀的拓扑结构源于输入特征x₁和x₂的数值范围差异巨大,虽然它们处于“相同范围”的框内,但x₂的数值范围远大于x₁,导致损失函数L对权重w₂的变化极为敏感。由于x₂值很大,即使权重w₂的微小变化也会引起输出y的剧烈波动,进而通过反向传播产生巨大的误差ΔL和权重更新Δw₂,这使得优化路径在陡峭的曲面上曲折前行,训练过程既不稳定又缓慢。
作为对比,图的右侧展示了经过特征缩放等预处理后的理想损失曲面。这个曲面变得平滑而均匀,等高线接近圆形,意味着损失函数在各个方向上的变化率相近。这种“良性”的景观使得优化算法能够沿着一条更直接、更高效的路径快速收敛到最低点。
下图是机器学习中特征归一化的操作流程与作用。
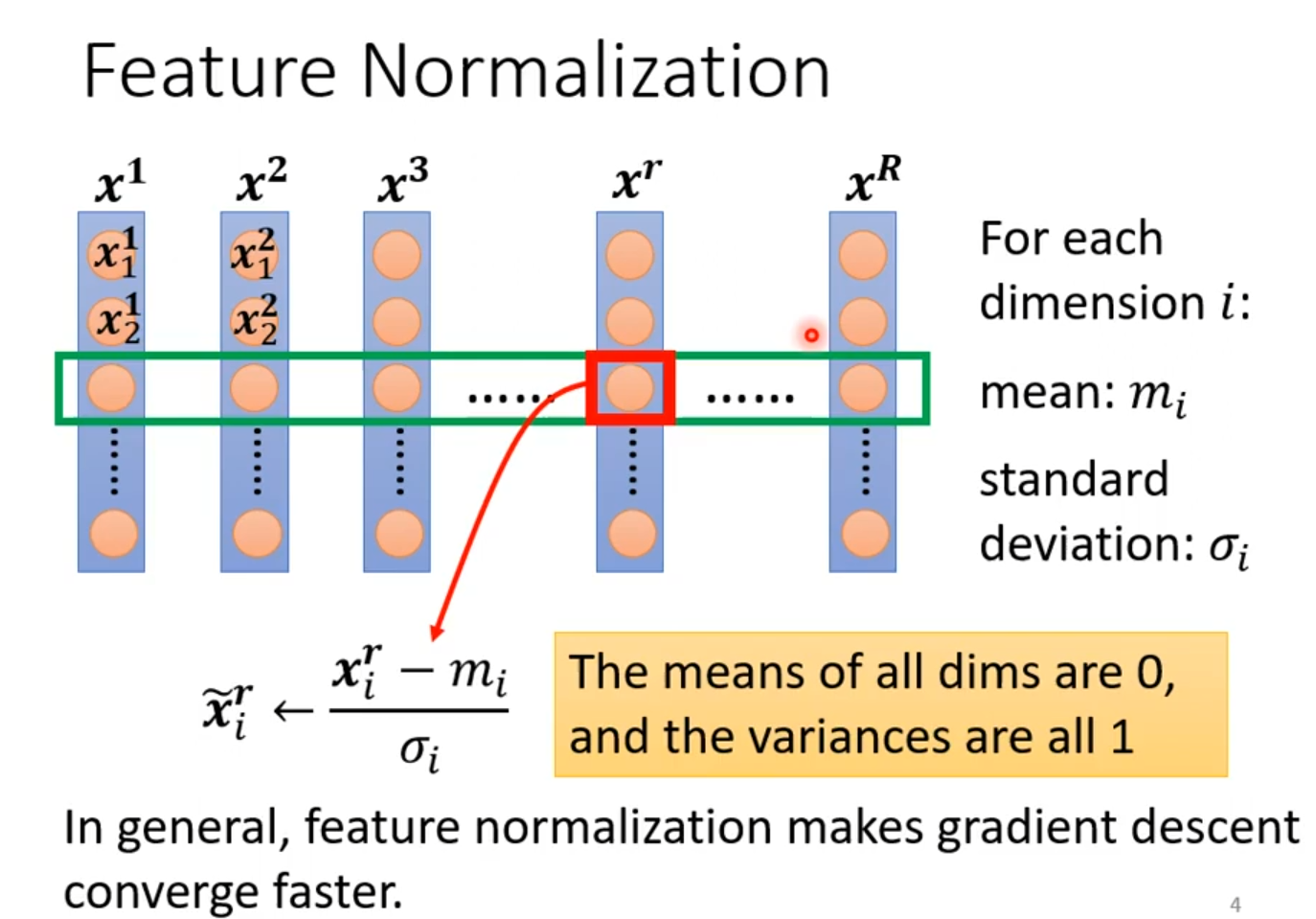
上图中多列垂直排列的橙色圆点代表原始数据集,每个圆点是一个样本,每一列对应一个特征维度。绿色长框标出了当前被处理的维度,其中一个样本被红色方框特别标注,并通过红色箭头指向下方的归一化公式,形象地说明该样本正按此公式进行变换。此操作是对每个特征维度i独立进行的,先计算该维度所有样本的均值mᵢ和标准差σᵢ,然后将每个特征值减去均值后除以标准差。这一过程的最终目标是使所有特征维度被标准化,即均值为0、方差为1,从而将不同尺度的特征统一到相同的分布范围。经过这种处理的数据特征通常能够使梯度下降算法的优化路径更平滑,显著加快模型的收敛速度。
2 隐藏层归一
下图展示了一个简单的网络结构:三个输入特征 ẋ¹、ẋ²、ẋ³ 经过第一层权重 W¹ 的线性变换后,得到中间状态 z¹、z²、z³,随后通过 Sigmoid 这样的非线性激活函数,转化为隐藏层激活值 a¹、a²、a³,这些值继而作为下一层权重 W² 的输入。
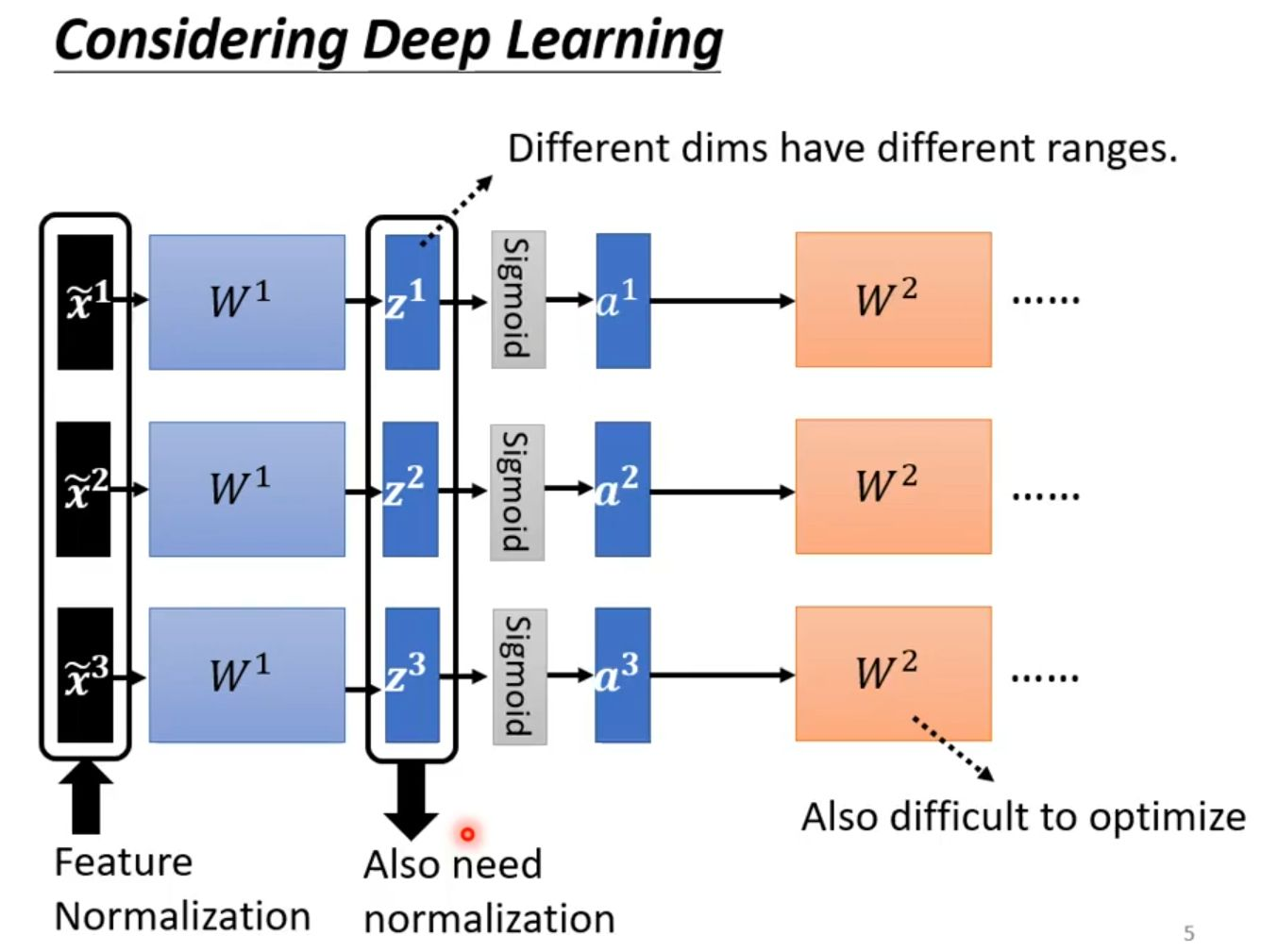
即便输入特征 ẋʳ 已经通过特征归一化进行了标准化处理,但经过 W¹ 和 Sigmoid 变换后,所产生的隐藏层输出 aʳ 很可能仍然具有迥异的分布和取值范围。这种隐藏层内部激活值分布的不一致性,正是图中下方所标注的“Also need normalization”和“Also difficult to optimize”的原因所在。它意味着损失曲面会变得难以优化,梯度下降的路径将崎岖不平,严重制约模型的训练效率与最终性能。因此,不仅需要对输入进行归一化,在深度网络的隐藏层之间进行归一化同样是确保模型稳定、高效训练的关键所在。
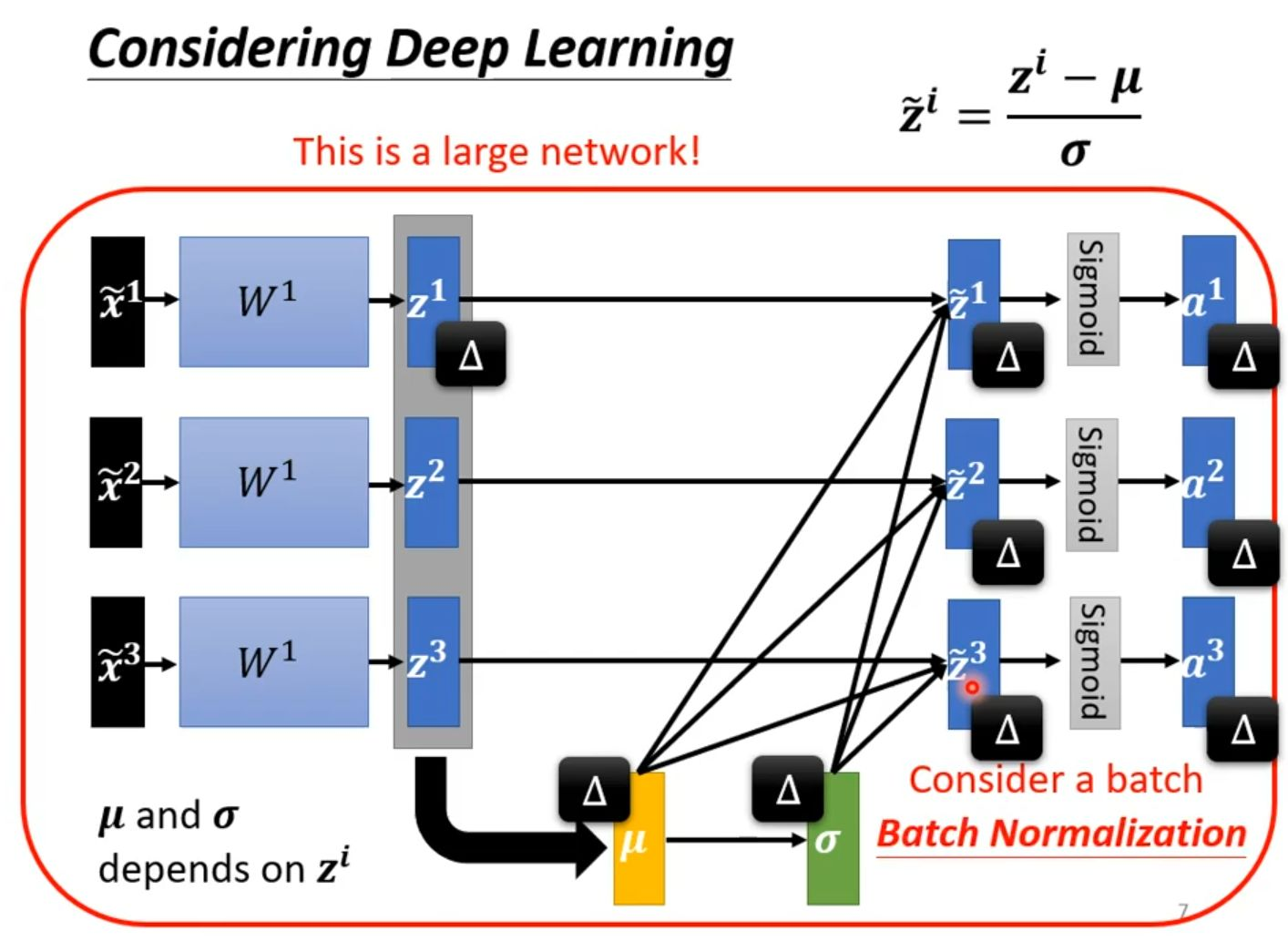
上图三个已标准化的输入特征 𝑥̃¹、𝑥̃²、𝑥̃³ 经过第一层权重 𝑊¹ 的线性变换,生成中间输出 𝐳¹、𝐳²、𝐳³。然而,即便输入已被归一化,这些隐藏层的输出值 𝐳ⁱ 在经过非线性激活函数之前,其分布依然会发生变化,导致不同神经元的激活值具有不同的取值范围,这使得损失曲面难以优化,训练过程极不稳定。为了解决这一问题,图中右上角的核心公式 𝑧̃ᵢ = (𝑧ⁱ − 𝜇) / 𝜎 点明了批量归一化的操作:它在一个批次的数据上,计算该层所有神经元输出的均值 𝜇 和标准差 𝜎,然后用它们对每个 𝐳ⁱ 进行重新标准化,产生分布稳定、均值为0、方差为1的新值 𝑧̃ᵢ,之后再送入非线性激活函数。图左下角的注释“𝜇 and 𝜎 depends on 𝐳ⁱ”强调了这些统计量来源于当前批次的实际数据。通过这种方式,批量归一化对每一层的输出都进行“重塑”,有效控制了内部协变量偏移,使得深度网络即使在规模很大时也能进行稳定、高效的训练。
下图是批归一化在模型测试阶段的工作机制。

输入 x~经权重 W1变换得到 z,但关键在于对 z进行归一化得到 z~时,所使用的 μ和 σ并非来自当前测试数据。图上方文字“We do not always have batch at testing stage”点明了问题核心:测试时可能无法获得一个完整批次的数据来计算均值和方差。
为了解决这个问题,方法是在模型训练期间,持续计算每一批次统计量 μt和 σt的移动平均值,并将其作为模型参数的一部分保存下来。图中下方的公式具体展示了这一指数移动平均的计算过程,其中 p是一个超参数,用于平衡历史平均值 μˉ和当前批次统计量 μt的权重。这样,在测试阶段,模型直接使用训练过程中得到的全局统计量 μˉ和 σˉ对单个样本进行归一化,从而确保了模型在处理单个样本或小批量数据时的稳定性和一致性。
3 总结
规范化技术是深度学习的核心优化手段,通过重塑数据分布稳定训练过程。特征归一化处理输入数据,批量归一化控制隐藏层输出分布,配合测试阶段的移动平均策略,共同构成保证模型训练效率与推理稳定性的关键技术体系。