Spring AI(七)Spring AI 的RAG实现集合火山向量模型+阿里云Tair(企业版)
先简单说下踩过的坑:
1、Tair只有企业版,并且是6.0以上的版本才支持向量库
2、redis开源版不支持云厂商进行redisSearch的搭建。
3、在插入之前必须初始化索引库,tair不像redis的sdk提供了初始化的选项。
4、配置连接池的时候启动会报错。
5、向量模型维度设置问题
6、tairVectorStore和Spring ai的通用实现不一致
基本流程:
1、初始化向量存储实例
2、同时创建索引库
3、构造Document,可以读取文档,JSON,字符串等
4、数据向量化
5、插入向量库
6、配置chatClient的Advisors
7、进行结果查询
一、初始化向量存储实体TairVectorStore
tair本质上是redis的二开版本,所以基本的连接和redis是保持一致的
配置连接地址:
springdata:redis:host: XXport: XXpassword: XXtimeout: XX
@Value("${spring.data.redis.host}")private String host;@Value("${spring.data.redis.port}")private Integer port;@Value("${spring.data.redis.password}")private String password;@Value("${spring.data.redis.timeout}")private Integer timeout;@Beanpublic GenericObjectPoolConfig<Jedis> genericObjectPoolConfig(){GenericObjectPoolConfig<Jedis> poolConfig = new GenericObjectPoolConfig<>();poolConfig.setJmxEnabled(false);return poolConfig;}@Beanpublic JedisPool jedisPool(GenericObjectPoolConfig<Jedis> poolConfig) {return new JedisPool(poolConfig,host, port,timeout,password);}@Beanpublic TairVectorApi tairVectorApi(JedisPool jedisPool){return new TairVectorApi(jedisPool);}这里选用的向量大模型是火山的向量模型,所以得指定下模型信息
springai:chat:client:enabled=false:vectorstore:tair:index: spring_ai_tair_vector_storeurl: /api/v3/embeddings #重点注意model: doubao-embedding-large-text-250515# 大模型配置openai:base-url: https://ark.cn-beijing.volces.comapi-key: XX初始化TairVectorStore
@Beanpublic TairVectorStore tairVectorStore(TairVectorApi tairVectorApi,EmbeddingModel embeddingModel, TairVectorStoreOptions options) {return TairVectorStore.builder(tairVectorApi, embeddingModel).options(options).build();}二、初始化索引库
我们再构建TairVectorStore的时候发现大部分的参数都是默认的,和我们期望的向量模型不太匹配
所以这里先根据自由参数构建向量模型
@Value("${spring.ai.openai.base-url}")private String baseUrl;@Value("${spring.ai.openai.api-key}")private String apiKey;@Value("${spring.ai.vectorstore.tair.url}")private String embeddingsUrl ;@Value("${spring.ai.vectorstore.tair.model}")private String embeddingsModel ;@Beanpublic OpenAiEmbeddingModel embeddingModel(TairVectorStoreOptions tairVectorStoreOptions){OpenAiApi openAiApi = OpenAiApi.builder().apiKey(apiKey).baseUrl(baseUrl).embeddingsPath(embeddingsUrl).build();OpenAiEmbeddingOptions openAiEmbeddingOptions = new OpenAiEmbeddingOptions();openAiEmbeddingOptions.setModel(embeddingsModel);openAiEmbeddingOptions.setDimensions(tairVectorStoreOptions.getDimensions());openAiEmbeddingOptions.setEncodingFormat("float");return new OpenAiEmbeddingModel(openAiApi, MetadataMode.EMBED,openAiEmbeddingOptions);}指定模型和维度,同时根据参数可以进行索引的初始化操作。
@Beanpublic TairVectorStoreOptions tairVectorStoreOptions(TairVectorApi tairVectorApi){TairVectorStoreOptions tairVectorStoreOptions = new TairVectorStoreOptions();//设置向量模型维度tairVectorStoreOptions.setDimensions(2048);//获取索引Map<String, String> objs = tairVectorApi.tvsgetindex(tairVectorStoreOptions.getIndexName());//如果不存在,创建索引if (objs.isEmpty()) {//初始化索引tairVectorApi.tvscreateindex(tairVectorStoreOptions.getIndexName(),tairVectorStoreOptions.getDimensions(),tairVectorStoreOptions.getIndexAlgorithm(),tairVectorStoreOptions.getDistanceMethod(),tairVectorStoreOptions.getIndexParams().toArray(new String[0]));}return tairVectorStoreOptions;}三、VectorConfig整体配置
结合上面两个内容,整体的配置内容
@Configuration
public class VectorConfig {@Value("${spring.data.redis.host}")private String host;@Value("${spring.data.redis.port}")private Integer port;@Value("${spring.data.redis.password}")private String password;@Value("${spring.data.redis.timeout}")private Integer timeout;@Value("${spring.ai.openai.base-url}")private String baseUrl;@Value("${spring.ai.openai.api-key}")private String apiKey;@Value("${spring.ai.vectorstore.tair.url}")private String embeddingsUrl ;@Value("${spring.ai.vectorstore.tair.model}")private String embeddingsModel ;@Beanpublic GenericObjectPoolConfig<Jedis> genericObjectPoolConfig(){GenericObjectPoolConfig<Jedis> poolConfig = new GenericObjectPoolConfig<>();poolConfig.setJmxEnabled(false);return poolConfig;}@Beanpublic JedisPool jedisPool(GenericObjectPoolConfig<Jedis> poolConfig) {return new JedisPool(poolConfig,host, port,timeout,password);}@Beanpublic TairVectorApi tairVectorApi(JedisPool jedisPool){return new TairVectorApi(jedisPool);}@Beanpublic TairVectorStoreOptions tairVectorStoreOptions(TairVectorApi tairVectorApi){TairVectorStoreOptions tairVectorStoreOptions = new TairVectorStoreOptions();//设置向量模型维度tairVectorStoreOptions.setDimensions(2048);//获取索引Map<String, String> objs = tairVectorApi.tvsgetindex(tairVectorStoreOptions.getIndexName());//如果不存在,创建索引if (objs.isEmpty()) {//初始化索引tairVectorApi.tvscreateindex(tairVectorStoreOptions.getIndexName(),tairVectorStoreOptions.getDimensions(),tairVectorStoreOptions.getIndexAlgorithm(),tairVectorStoreOptions.getDistanceMethod(),tairVectorStoreOptions.getIndexParams().toArray(new String[0]));}return tairVectorStoreOptions;}@Beanpublic OpenAiEmbeddingModel embeddingModel(TairVectorStoreOptions tairVectorStoreOptions){OpenAiApi openAiApi = OpenAiApi.builder().apiKey(apiKey).baseUrl(baseUrl).embeddingsPath(embeddingsUrl).build();OpenAiEmbeddingOptions openAiEmbeddingOptions = new OpenAiEmbeddingOptions();openAiEmbeddingOptions.setModel(embeddingsModel);openAiEmbeddingOptions.setDimensions(tairVectorStoreOptions.getDimensions());openAiEmbeddingOptions.setEncodingFormat("float");return new OpenAiEmbeddingModel(openAiApi, MetadataMode.EMBED,openAiEmbeddingOptions);}@Beanpublic TairVectorStore tairVectorStore(TairVectorApi tairVectorApi,EmbeddingModel embeddingModel, TairVectorStoreOptions options) {return TairVectorStore.builder(tairVectorApi, embeddingModel).options(options).build();}}这里注意,POM的配置因为是基于Tair做为索引库的,所以这里的用的alibaba的sdk。
<dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter-store-tair</artifactId><version>1.0.0.3</version></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-advisors-vector-store</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-rag</artifactId></dependency>四、文档读取
引入读取配置,当前Spring AI支持的文档格式还是蛮多的,这些引用吧,得在源码里找下。官方文档上有一些没有说明。
<!-- pdf的读取 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pdf-document-reader</artifactId></dependency><!-- docx的读取 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-tika-document-reader</artifactId></dependency><!-- html读取 jsoup实现 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-jsoup-document-reader</artifactId></dependency><!-- markdown读取 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-markdown-document-reader</artifactId></dependency>构建文档读取配置类,简单根据文件类型做个封装如果要对文档做分片处理,建议是读取之后进行切片。
import com.alibaba.cloud.ai.vectorstore.tair.TairVectorStore;
import com.xqxjy.ai.xqxjy.enums.FileType;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.reader.jsoup.JsoupDocumentReader;
import org.springframework.ai.reader.jsoup.config.JsoupDocumentReaderConfig;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;import java.util.ArrayList;
import java.util.List;/*** @Author: 朱维* @Date 10:55 2025/9/23*/
@Service
public class RagFileReadService {@Autowiredprivate TairVectorStore tairVectorStore;/*** 读取文档* @param resource* @param fileType* @return*/public void read(Resource resource, FileType fileType,String fileName){List<Document> documentList = new ArrayList<>();switch (fileType){case PDF:documentList = readPdf(resource);break;case TXT:documentList = readTxt(resource,fileName);break;case HTML:documentList = readHtml(resource,fileName);break;case MD:documentList = readMd(resource,fileName);break;case DOCX:documentList = readDocx(resource);break;default:break;}// 写入向量库(此处Redis)if(!documentList.isEmpty()) {tairVectorStore.doAdd(documentList);}}/*** 读取pdf文档* @param resource 资源* @return 文档列表*/private List<Document> readPdf(Resource resource){// 1.创建PDF的读取器PagePdfDocumentReader reader = new PagePdfDocumentReader(resource, // 文件源PdfDocumentReaderConfig.builder().withPageExtractedTextFormatter(ExtractedTextFormatter.defaults()).withPagesPerDocument(1) // 每1页PDF作为一个Document.build());// 2.读取PDF文档,拆分为Documentreturn reader.read();}/*** 读取文本* @param resource 资源* @return 文档列表*/private List<Document> readTxt(Resource resource,String fileName){TextReader textReader = new TextReader(resource);textReader.getCustomMetadata().put("filename", fileName);return textReader.read();}/*** 读取html* @param resource 资源* @return 文档*/private List<Document> readHtml(Resource resource,String fileName){JsoupDocumentReaderConfig config = JsoupDocumentReaderConfig.builder().selector("article p") // 提起文章P标签的内容.charset("UTF-8") //.includeLinkUrls(true) // 包含连接.metadataTags(List.of("author", "date")) // 提取作者和日期数据.additionalMetadata("source", fileName) // Add custom metadata.build();JsoupDocumentReader reader = new JsoupDocumentReader(resource, config);return reader.get();}/**** @param resource 资源* @return 文档*/private List<Document> readMd(Resource resource,String fileName){MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder().withHorizontalRuleCreateDocument(true).withIncludeCodeBlock(false).withIncludeBlockquote(false).withAdditionalMetadata("filename", fileName).build();MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);return reader.get();}/*** 读取word文档* @param resource 资源* @return 文档列表*/private List<Document> readDocx(Resource resource){TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resource,ExtractedTextFormatter.builder().build());return tikaDocumentReader.read();}
}
五、数据向量化
这一步其实卡了我很久啊,这里用的向量模型是火山的:doubao-embedding-large-text-250515
维度是:2048 (tairVectorStore的默认配置值是1536,所以这里一定要再初始化的时候进行设置)
请求地址:https://ark.cn-beijing.volces.com/api/v3/embeddings(注意图像向量化和文本向量化的氢气地址不一样)
向量化的代码其实很简单哈,就是调用向量模型进行初始化,至于向量模型在上面配置类的时候我们已经初始化完成。
float[] embedding = this.embeddingModel.embed(document);卡我很久的原因:
1、就是还是不是很熟悉,对原理了解一般。
2、就是这个链式编程写起来是方便,Debug跟代码的时候确实难受。
六、数据存储
这里注意一点即可,Redis的正常调用是
vectorStore.add但是tair的调用是
tairVectorStore.doAdd(documentList);整体调用就是构造Document,然后进行add进行
Resource resource = new FileSystemResource("D:"+ File.separator+"ATS2.0操作手册-测试.docx");ragFileReadService.read(resource, FileType.DOCX,"ATS2.0.docx");七、配置chatClient的Advisors
我们希望进行LLM查询的时候能使用我们自己的向量库,所以还是需要进行简单的配置。
这里进行两个配置,一个是聊天的存储,用的mysql,一个就是查询的回答的配置。
@Configuration
public class ChatClientConfig {/*** 初始化chatClient* @param builder* @param jdbcTemplate* @return*/@Beanpublic ChatClient doubaoChatClient(ChatClient.Builder builder, JdbcTemplate jdbcTemplate, TairVectorStore vectorStore){return builder.defaultAdvisors(MessageChatMemoryAdvisor.builder(mysqlJdbcMemory(jdbcTemplate)).build()).defaultAdvisors(QuestionAnswerAdvisor.builder(vectorStore).searchRequest(SearchRequest.builder().similarityThreshold(0.8).topK(2).build()).build()).build();}/*** 初始化memory* @param jdbcTemplate* @return*/@Beanpublic ChatMemory mysqlJdbcMemory(JdbcTemplate jdbcTemplate){ChatMemoryRepository chatMemoryRepository = JdbcChatMemoryRepository.builder().jdbcTemplate(jdbcTemplate).dialect(new MysqlChatMemoryRepositoryDialect()).build();return MessageWindowChatMemory.builder().chatMemoryRepository(chatMemoryRepository).maxMessages(10).build();}
}那么问题又来了:QuestionAnswerAdvisor 这个调用的查询是VectorStrore默认的
List<Document> documents = this.vectorStore.similaritySearch(searchRequestToUse);而这个方法会引用到下面这个方法
@Overridepublic VectorStoreObservationContext.Builder createObservationContextBuilder(String operationName) {return null;}看代码也知道,阿里的实现里面,这里直接返回了null,所以一旦调用查询,直接就会报空指针呢。
怎么解决呢,其实我得解决方式还是蛮粗暴的,直接把QuestionAnswerAdvisor的源码复制出来,重写了下,
package com.xqxjy.ai.xqxjy.config;import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;import com.alibaba.cloud.ai.vectorstore.tair.TairVectorStore;
import reactor.core.scheduler.Scheduler;
import reactor.core.scheduler.Schedulers;import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.AdvisorChain;
import org.springframework.ai.chat.client.advisor.api.BaseAdvisor;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.ai.vectorstore.filter.FilterExpressionTextParser;
import org.springframework.lang.Nullable;
import org.springframework.util.Assert;
import org.springframework.util.StringUtils;/*** Context for the question is retrieved from a Vector Store and added to the prompt's* user text.** @author Christian Tzolov* @author Timo Salm* @author Ilayaperumal Gopinathan* @author Thomas Vitale* @since 1.0.0*/
public class QuestionAnswerAdvisor implements BaseAdvisor {public static final String RETRIEVED_DOCUMENTS = "qa_retrieved_documents";public static final String FILTER_EXPRESSION = "qa_filter_expression";private static final PromptTemplate DEFAULT_PROMPT_TEMPLATE = new PromptTemplate("""{query}Context information is below, surrounded by ------------------------------------------{question_answer_context}---------------------Given the context and provided history information and not prior knowledge,reply to the user comment. If the answer is not in the context, informthe user that you can't answer the question.""");private static final int DEFAULT_ORDER = 0;private final TairVectorStore vectorStore;private final PromptTemplate promptTemplate;private final SearchRequest searchRequest;private final Scheduler scheduler;private final int order;public QuestionAnswerAdvisor(TairVectorStore vectorStore) {this(vectorStore, SearchRequest.builder().build(), DEFAULT_PROMPT_TEMPLATE, BaseAdvisor.DEFAULT_SCHEDULER,DEFAULT_ORDER);}QuestionAnswerAdvisor(TairVectorStore vectorStore, SearchRequest searchRequest, @Nullable PromptTemplate promptTemplate,@Nullable Scheduler scheduler, int order) {Assert.notNull(vectorStore, "vectorStore cannot be null");Assert.notNull(searchRequest, "searchRequest cannot be null");this.vectorStore = vectorStore;this.searchRequest = searchRequest;this.promptTemplate = promptTemplate != null ? promptTemplate : DEFAULT_PROMPT_TEMPLATE;this.scheduler = scheduler != null ? scheduler : BaseAdvisor.DEFAULT_SCHEDULER;this.order = order;}public static Builder builder(TairVectorStore vectorStore) {return new Builder(vectorStore);}@Overridepublic int getOrder() {return this.order;}@Overridepublic ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {// 1. Search for similar documents in the vector store.var searchRequestToUse = SearchRequest.from(this.searchRequest).query(chatClientRequest.prompt().getUserMessage().getText()).filterExpression(doGetFilterExpression(chatClientRequest.context())).build();List<Document> documents = this.vectorStore.doSimilaritySearch(searchRequestToUse);// 2. Create the context from the documents.Map<String, Object> context = new HashMap<>(chatClientRequest.context());context.put(RETRIEVED_DOCUMENTS, documents);String documentContext = documents == null ? "": documents.stream().map(Document::getText).collect(Collectors.joining(System.lineSeparator()));// 3. Augment the user prompt with the document context.UserMessage userMessage = chatClientRequest.prompt().getUserMessage();String augmentedUserText = this.promptTemplate.render(Map.of("query", userMessage.getText(), "question_answer_context", documentContext));// 4. Update ChatClientRequest with augmented prompt.return chatClientRequest.mutate().prompt(chatClientRequest.prompt().augmentUserMessage(augmentedUserText)).context(context).build();}@Overridepublic ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {ChatResponse.Builder chatResponseBuilder;if (chatClientResponse.chatResponse() == null) {chatResponseBuilder = ChatResponse.builder();}else {chatResponseBuilder = ChatResponse.builder().from(chatClientResponse.chatResponse());}chatResponseBuilder.metadata(RETRIEVED_DOCUMENTS, chatClientResponse.context().get(RETRIEVED_DOCUMENTS));return ChatClientResponse.builder().chatResponse(chatResponseBuilder.build()).context(chatClientResponse.context()).build();}@Nullableprotected Filter.Expression doGetFilterExpression(Map<String, Object> context) {if (!context.containsKey(FILTER_EXPRESSION)|| !StringUtils.hasText(context.get(FILTER_EXPRESSION).toString())) {return this.searchRequest.getFilterExpression();}return new FilterExpressionTextParser().parse(context.get(FILTER_EXPRESSION).toString());}@Overridepublic Scheduler getScheduler() {return this.scheduler;}public static final class Builder {private final TairVectorStore vectorStore;private SearchRequest searchRequest = SearchRequest.builder().build();private PromptTemplate promptTemplate;private Scheduler scheduler;private int order = DEFAULT_ORDER;private Builder(TairVectorStore vectorStore) {Assert.notNull(vectorStore, "The vectorStore must not be null!");this.vectorStore = vectorStore;}public Builder promptTemplate(PromptTemplate promptTemplate) {Assert.notNull(promptTemplate, "promptTemplate cannot be null");this.promptTemplate = promptTemplate;return this;}public Builder searchRequest(SearchRequest searchRequest) {Assert.notNull(searchRequest, "The searchRequest must not be null!");this.searchRequest = searchRequest;return this;}public Builder protectFromBlocking(boolean protectFromBlocking) {this.scheduler = protectFromBlocking ? BaseAdvisor.DEFAULT_SCHEDULER : Schedulers.immediate();return this;}public Builder scheduler(Scheduler scheduler) {this.scheduler = scheduler;return this;}public Builder order(int order) {this.order = order;return this;}public QuestionAnswerAdvisor build() {return new QuestionAnswerAdvisor(this.vectorStore, this.searchRequest, this.promptTemplate, this.scheduler,this.order);}}}这里就干了两件事:
1、把VectorStore换成了TairVectorStore
2、把查询Document换成了
List<Document> documents = this.vectorStore.doSimilaritySearch(searchRequestToUse);八、进行结果查询
这个其实就很简单
@GetMapping("/read")public String query(String msg){return chatClient.prompt(msg).call().content();}九、简单做个测试
启动项目,查看数据库,因为tair本质还是redis,所以这里还是用redis的客户端查看了下数据库
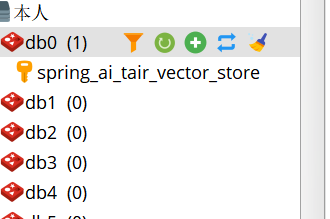
索引库创建成功。
简单做个txt文档,简单写一些内容,稍微吹下牛逼啊。

构建读取存储请求。
@GetMapping("/write")public void read(){Resource resource = new FileSystemResource("D:"+ File.separator+"test.txt");ragFileReadService.read(resource, FileType.TXT,"test.txt");}
http://localhost:18080/ai/rag/V1/write构建查询请求
@GetMapping("/read")public String query(String msg){return chatClient.prompt(msg).call().content();}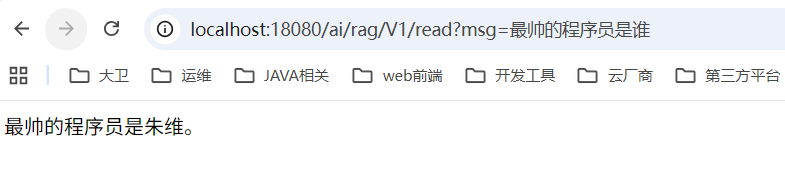
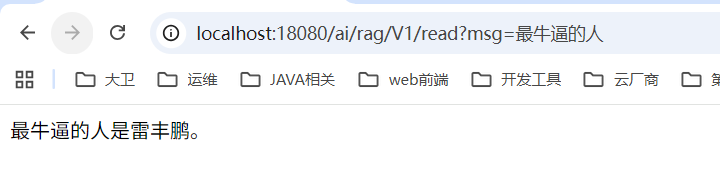
流程完成,然后我们也可以用一个大点的文档进行测试
同样我们先读取,向量化,存储这个文档。这个可能需要点时间,而且注意修改文件格式支持。
接下来进行查询测试。

总结下:
应用场景可以是专业内容存储问答等。和toolCalling结合使用,能使答案更精准准确。
最后:
因为还在做开发,这里暂时不提供源码了,有需求留言,我整理发。