深入浅出高并发内存池:原理、设计与实现
一.引言
传统内存分配的痛点:
1.对于一些操作系统封装的malloc可能对于多线程并发场景下性能较差
2.频繁申请释放不同大小的内存,导致大量内存碎片,降低内存利用率
所以针对以上问题
本项目采用了池化技术,像一些连接池,线程池,对象池。
内存池:由我们自己负责管理一块大块内存,当我们需要的时候通过自己管理的接口进行内存的申请和释放,相比于传统的内存申请和释放来言,一方面因为一次申请大批内存,减少了系统调用以及,归还不连续内存块导致的内存碎片问题。
tcmalloc: TCMalloc (google-perftools) 是用于优化C++写的多线程应用,比glibc 2.3的malloc快。这个模块可以用来让MySQL在高并发下内存占用更加稳定。
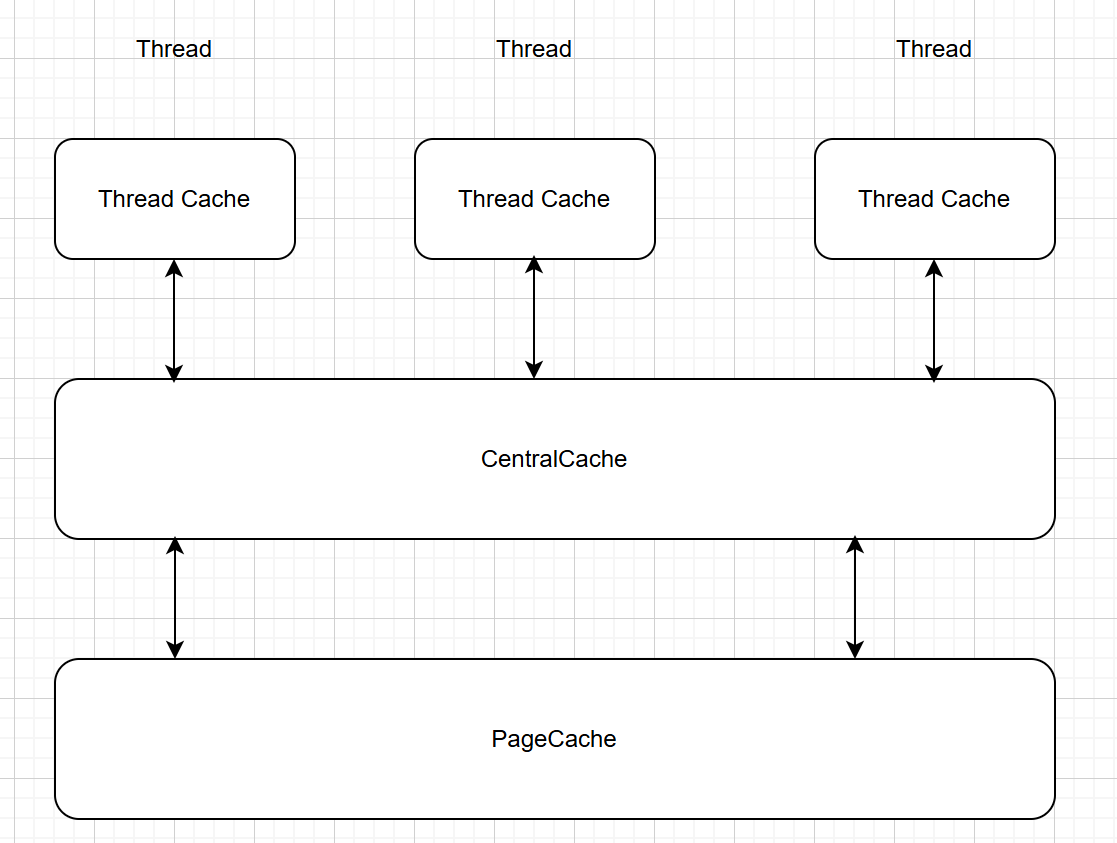
二.高并发内存池的整体架构
1.三层架构
本项目采用三层架构
Thread Cache(线程缓存):线程独享,并且是无锁操作
Central Cache(中心缓存):所有线程共享,一方面给Thread Cache切好的小块批量内存块,另一方面,将归还的小块内存整体管理,如果达到回收条件,归还给PageCache。
Page Cache(页缓存):所有线程共享,管理更大的内存,通常以页为单位,当Central Cache需要内存,通过Page Cache系统申请大块内存,并且大块内存切好后给予Central Cache。对于归还的内存块,首先还给对应的页
1).Thread Cache
结构示意图
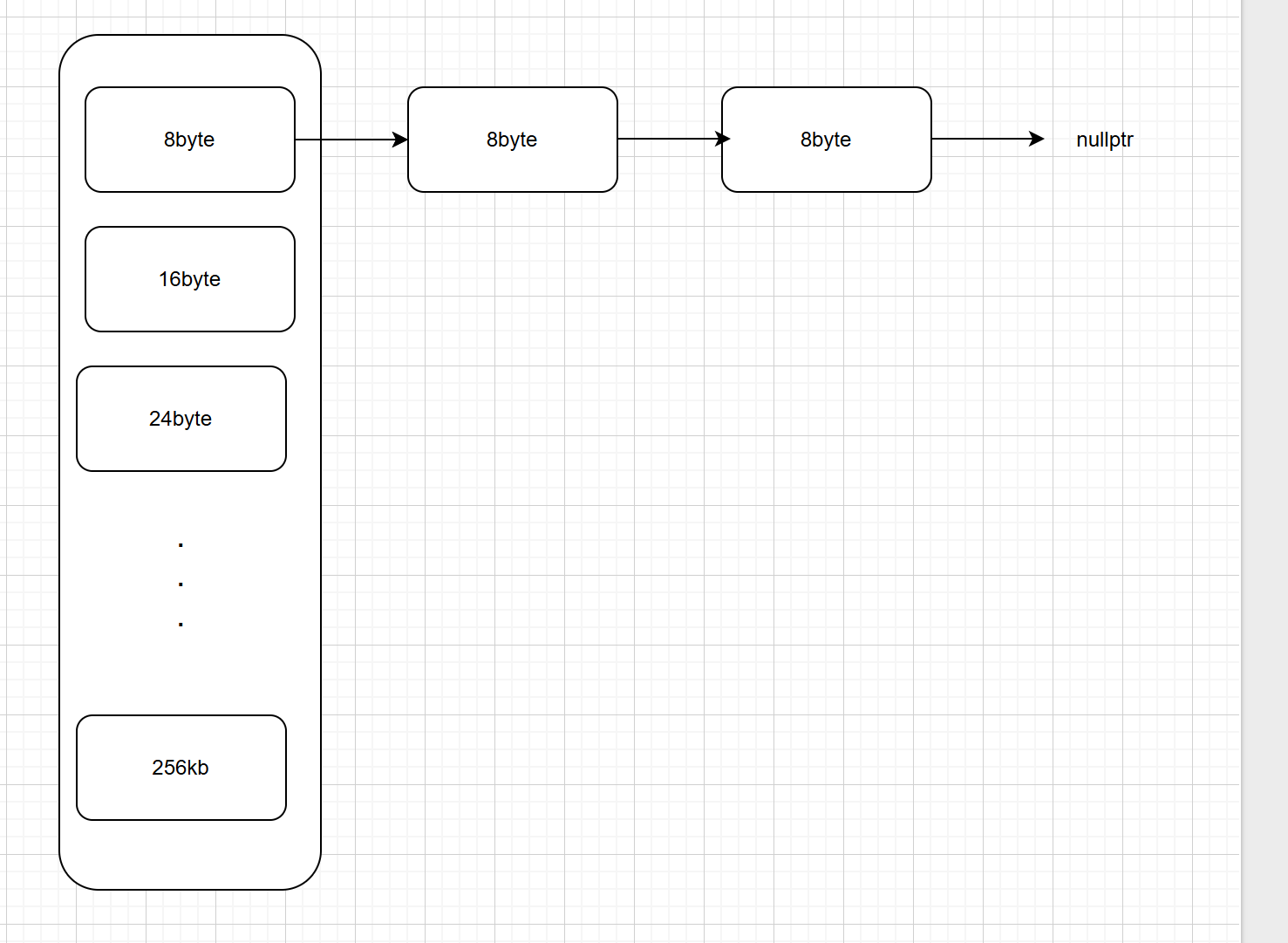
ThreadCache的数据结构是哈希桶,每一桶管理一个固定大小的自由链表。并且是无锁结构的。
假设需要8个字节的内存,首先先去Thread Cache通过哈希找到哈希桶中对应自由链表的位置,然后将其取出一块。
但是我们可以看到并不是每个大小的内存都有对应的链表,这是因为如果给每个大小的的内存都有对应的链表的话,那么这个桶的大小可能会非常的大,从结构图可以看到会有256*1024个自由链表,所以为了解决这个问题:
采用内存对齐的方式:
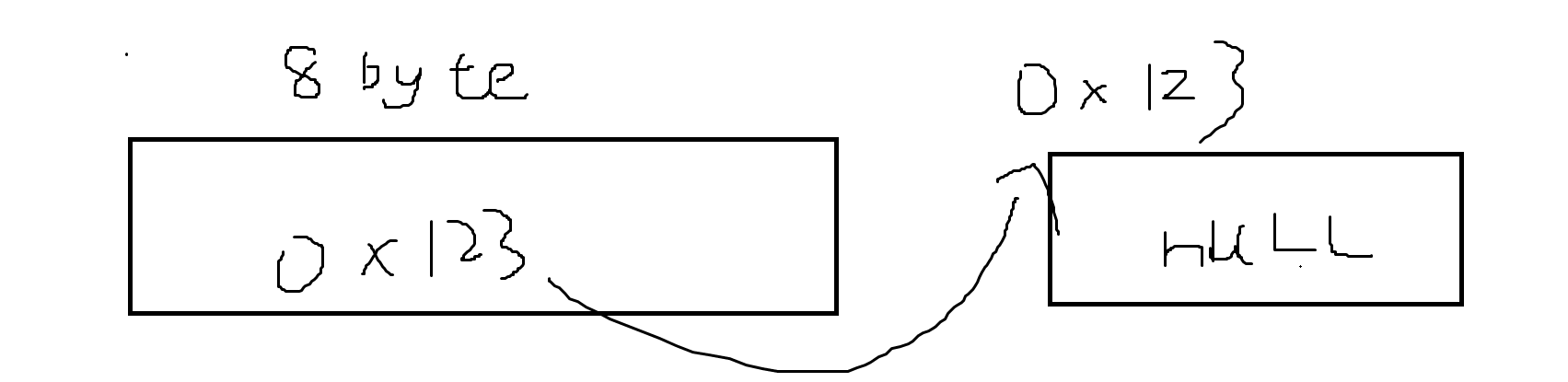
1.首先保证最小大小必须是一个指针大小(64位),为了保证能够存储下一个结点的地址,如下图。
2.保证内存向上对齐(比如你申请的大小是5字节)的同时减少内存碎片所以
// [1,128] 8byte对齐 freelist[0,16)
// [128+1,1024] 16byte对齐 freelist[16,72)
// [1024+1,8 * 1024] 128byte对齐 freelist[72,128)
// [8 * 1024+1,64 * 1024] 1024byte对齐 freelist[128,184)
// [64 * 1024+1,256 * 1024] 8 * 1024byte对齐 freelist[184,208)按照以下规则进行内存对齐,保证的桶数目的同时一定程度减少内碎片,将其控制在了10%
为什么可以保证无锁呢?
通过TLS(Thread Local Shorage)我们可以保证无锁。
Thread Local Storage (TLS) 是 C++ 中一项重要的多线程编程特性,它允许每个线程拥有某个变量的独立副本,从而避免数据竞争和锁开销。
简单一句话,保证每个线程都独立的创建这个被标记为TLS的变量。

所以对于多线程而言,TLS保证了线程在数据的私有。
2).Central Cache
Central Cache更像是Thread Cache 和 Page Cache的过度阶段,就好比是一个缓冲区对上(Page Cache)申请以Span为的单位(管理多个页),对下(Thread Cache)给予批量内存块。
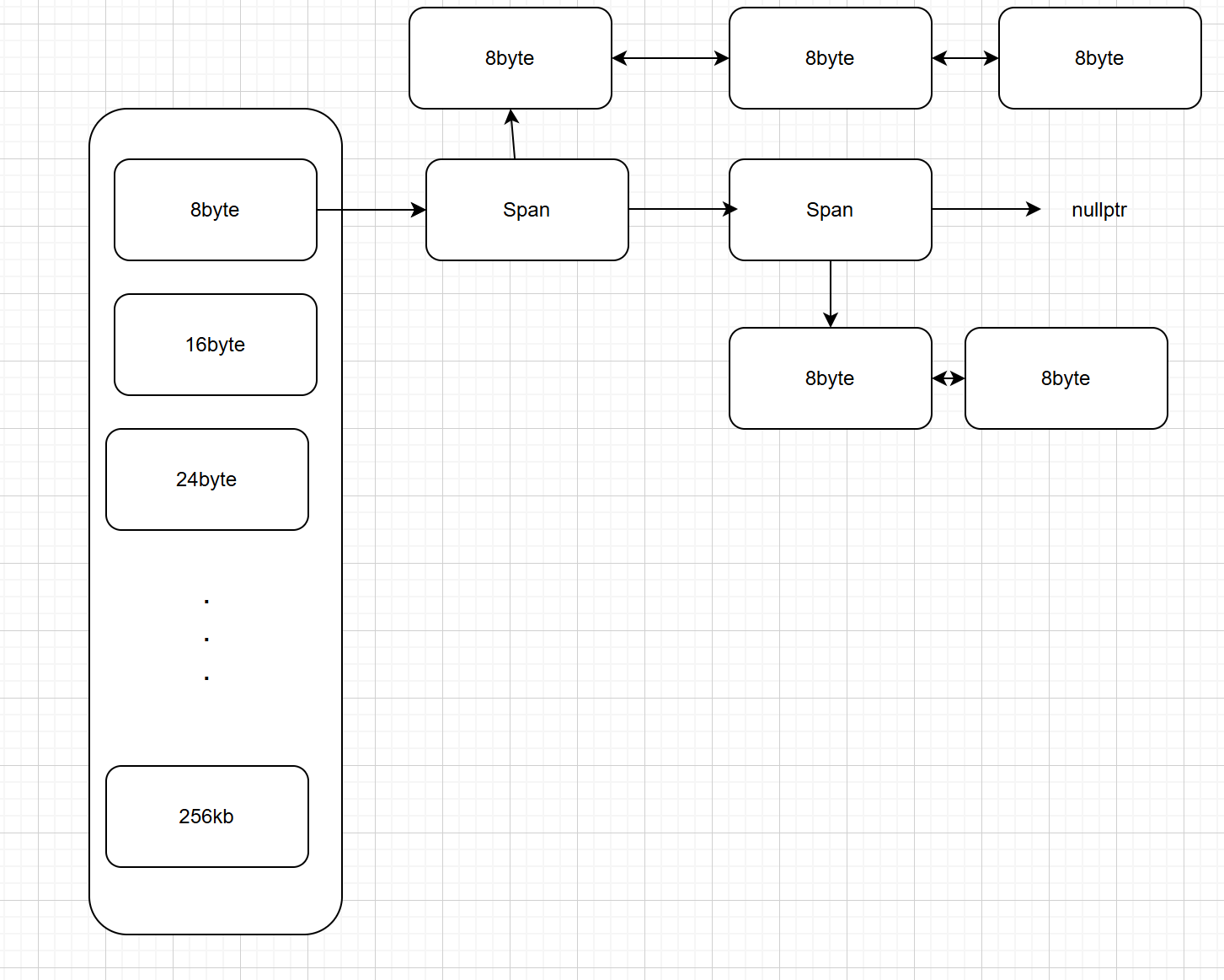
CentralCache的桶的结构跟ThreadCache一样,但是自由链表管理的结点变成了Span
Span可以理解为管理多个内存块的双向链表结构
那么Central Cache有什么特点呢?
相比于ThreadCache的无锁结构,Central Cache因为是唯一的,所以需要加锁,但是只需要桶锁即可,因为归还的内存块大小确定只需要找到响应的索引,并将其对应的自由链表加锁即可。
对于ThreadCache而言,如果自己的管理的内存块超过通过Central Cache获得的批量内存块数量时就将其归还给CentralCache,并把每个内存块归还给对应的Span(为什么可以找到对应的Span呢?看下文的Page Cache部分)。当Central Cache中某个Span分配给Thread Cache所有内存块都归还时,将Span归还给PageCache
而ThreadCache获取内存块的时候,Central Cache如何知道该给多少块内存块呢?
这个时候我们采用慢启动(在一定程度上,如果某大小的内存块被多次申请,Central Cache一次给予的批量内存块数量会随着申请次数的增加而增加)的方式来获取,一方面保证了效率,另一方面保证,给予的内存块得到更大程度的利用。
3).Page Cache
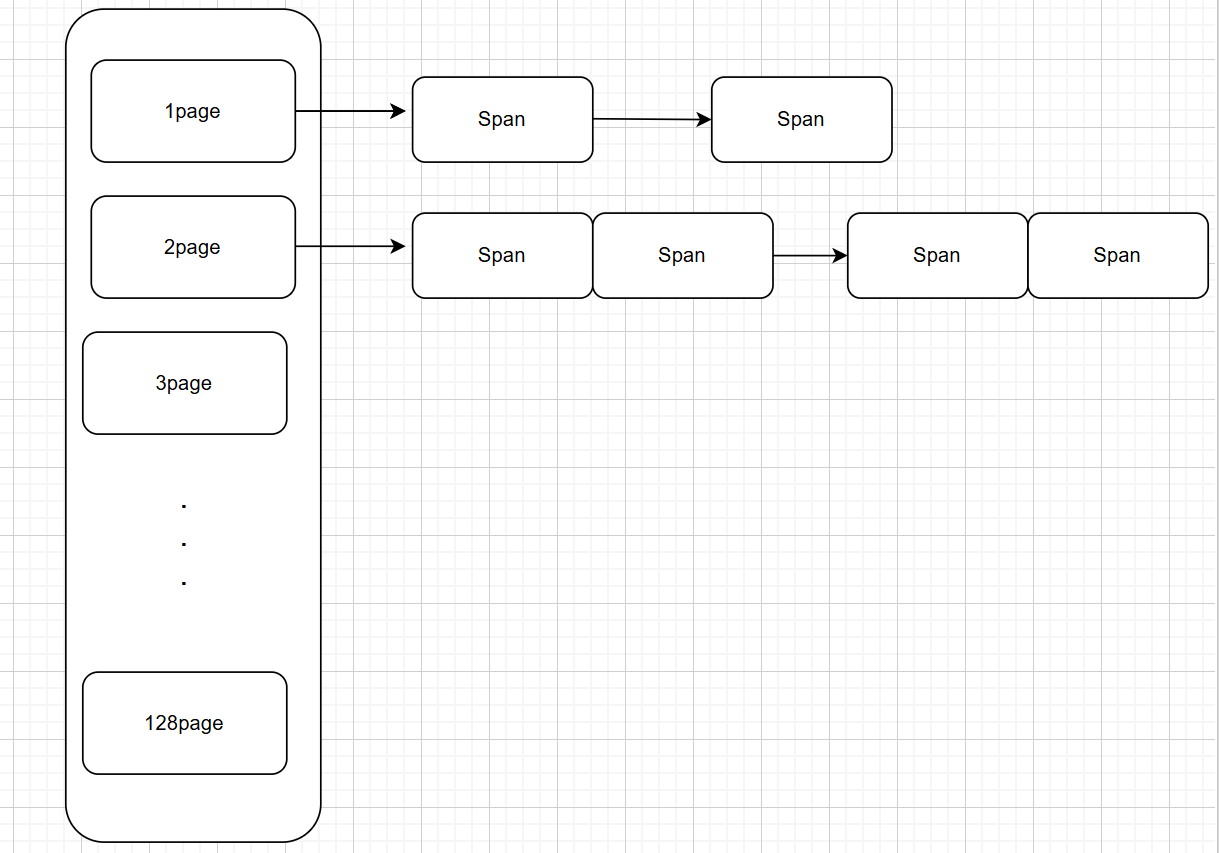
PageCache的数据结构也是哈希桶,每个自由链表管理相应大小的Span双向链表。
大小以page为单位,也就是页
Span管理连续内存的起始地址(页号 >> 页大小),页的数量。
大概就类似如下图的效果
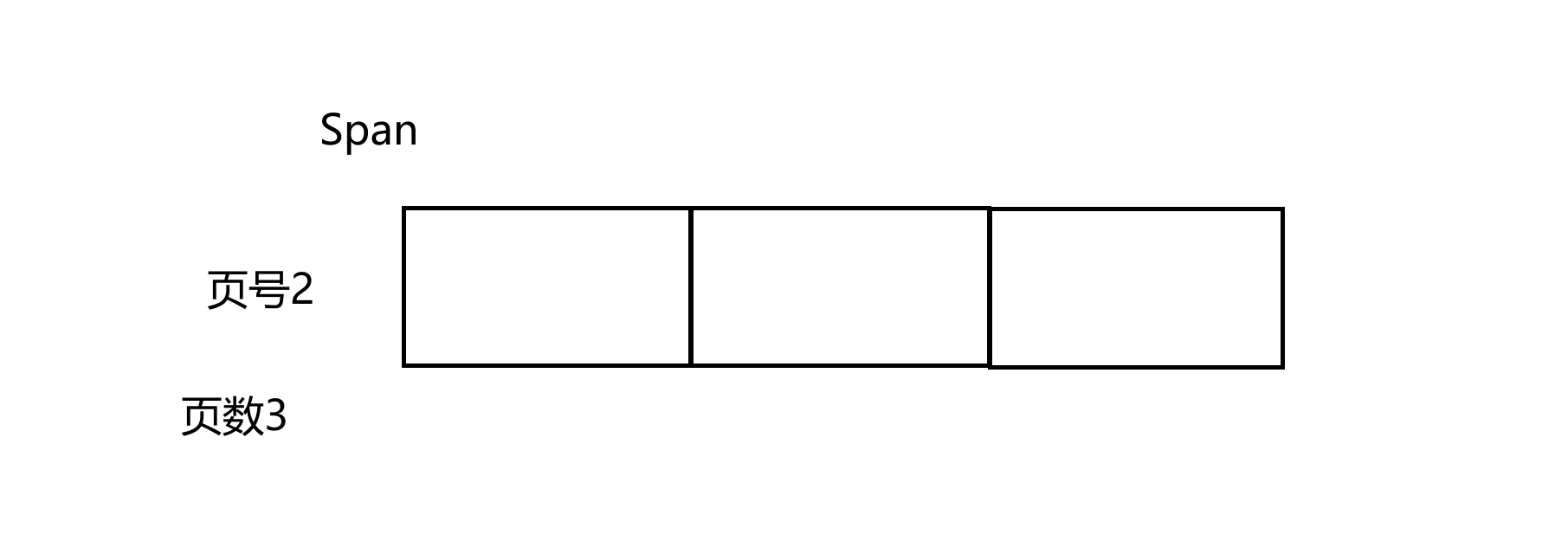
对于Central Cache申请的内存,首先需要通过Central Cache申请内存块的数量以及内存块的大小来知道需要几页的连续内存,接着将这个Span给CentralCache,CentralCache将这个连续内存切成小块,放到链表中,虽说是链表,但实际物理上是连续的。将内存块的空间的前8个byte指向下一个内存块。如果PageCache没有对应大小页的Span,会选择一个有多页的大块Span并将其切成目标Span,以及剩余的页搞成Span放回对应的桶。
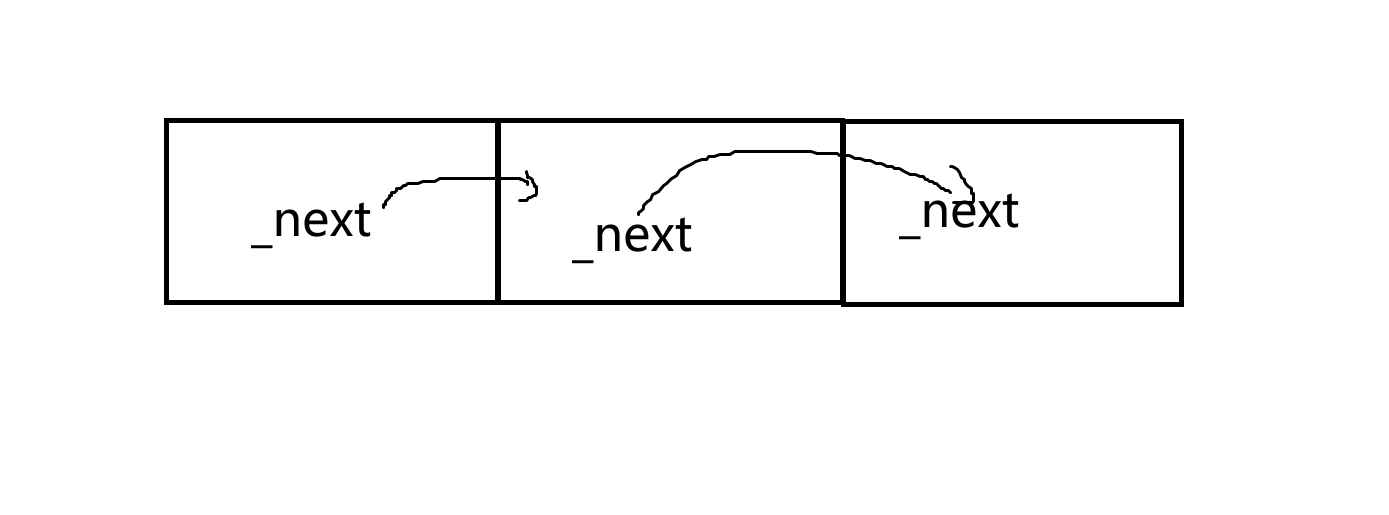
对于Thread Cache归还的批量内存块,Central Cache可以通过其内存块的地址来找到对应的Span位置,因为在对小块内存块取余PAGE_SIZE获得的是页号,在PageCache向系统申请内存的时候会把每个页对应的Span记录到页号与Span的映射。当对应的Span得到归还,会将把该Span的前后进行合并(因为可能是一个大的Span切成小的Span)。