从零开始的python学习(五)P63+P64+P65+P66
本文章记录观看B站python教程学习笔记和实践感悟,视频链接:【花了2万多买的Python教程全套,现在分享给大家,入门到精通(Python全栈开发教程)】 https://www.bilibili.com/video/BV1wD4y1o7AS/?p=6&share_source=copy_web&vd_source=404581381724503685cb98601d6706fb
上节课学习了本单元的四个实战题(实战一千年虫是什么虫,实战二模拟京东的购物流程,实战三模拟12306购票流程,实战四模拟手机通讯录),本节课学习字符串的常用方法(1和2),格式化字符串的三种方式和format详细格式控制。
一、字符串的用法
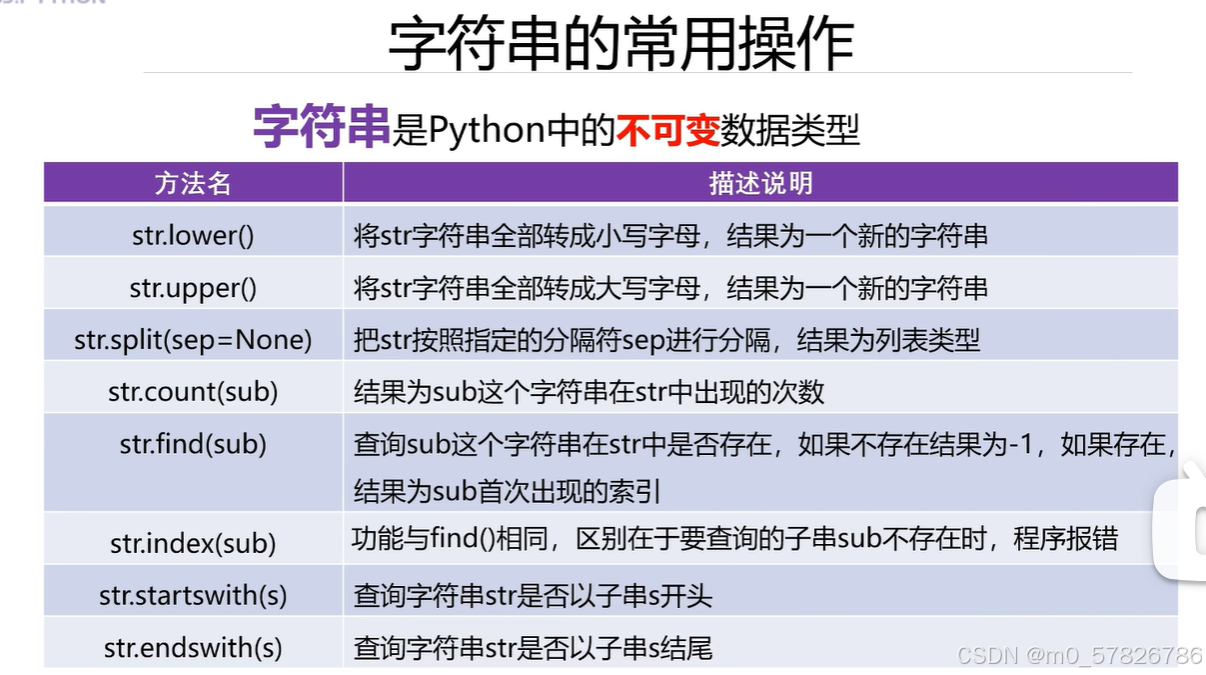
总结:
str='XAXX' #对于字符串假设有这样的定义
#1.小写化语法
s1=str.lower()
#2.大写化语法
s1=str.upper()
#3.按照某一字符分隔开
lst=str.split('A')
#4.计算字符串中的某个字符的个数
print(str.count('X'))
#5.计算字符串中的某个字符的个数
print(str.count('X'))s1='HelloWorld'
new_s2=s1.lower()#注意这里变量+.+对应字符串的操作,形成新的字符串(全是小写)
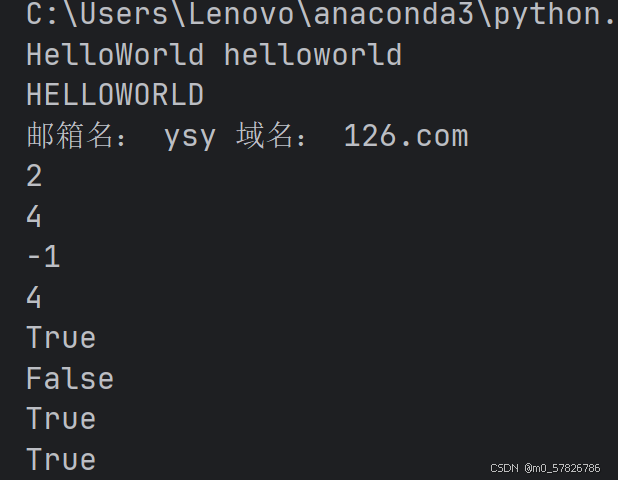
print(s1,new_s2)
new_s3=s1.upper()#全变成大写
print(new_s3)
#字符串的分割(split)
e_mail='ysy@126.com'
#下面规定是分割符号为@,并且形成的是一个列表,这里用lst来表示
lst=e_mail.split('@')
print('邮箱名:',lst[0],'域名:',lst[1])
print(s1.count('o')) #o在字符串中出现了两次
#检索操作(区分find和index)
print(s1.find('o'))#检索到o在字符串中第一次出现的位置
print(s1.find('p'))#p并不在字符串中,因此理论上是检索不到的,因此返回-1
print(s1.index('o'))#这个跟find的功能一样,检索到o在字符串中第一次出现的位置
'''
print(s1.index('p'))#与find不一样,如果找不到就会报错ValueError: substring not found
'''
#判断前缀和后缀(前缀是startswith,后缀是endswith)
print(s1.startswith('H'))#True,因为确实是以H开头
print(s1.startswith('P'))#False,因为确实不是以P开头
print('demo.py'.endswith('.py'))#True
print('test.txt'.endswith('.txt'))#True
除了报错的index(上面代码将其注释掉了),结果如下
二、字符串的方法2

实例以及解释如下:
s='HelloWorld'
#字符串的替换
new_s=s.replace('l','你好',1)#最后一个参数是替换次数,默认是全部替换
print(new_s)
#字符串在指定的宽度范围内居中
print(s.center(20))
print(s.center(20,'*'))#设定宽度为20.将字符串s填在中间,将左右分空用*填起来
#去掉字符串左右的空格
s=' Hello World '
print(s.strip())#只能删去字符串左右的字符,这里的字符是空格
print(s.lstrip())#只能删去字符串左边字符,这里的字符是空格
print(s.rstrip())#只能删去字符串右的字符,这里的字符是空格
#去掉指定的字符
s3='dl-Helloworld'
print(s3.strip('ld'))#与顺序无关,不管是何种顺序都能删掉指定的字符
print(s3.lstrip('ld'))#只删掉左边的字符
print(s3.rstrip('ld'))#只删掉右边的字符运行结果:

三、格式化字符串的三种方式
考虑这样一种情况,对于字符串之间分“+”执行的是字符串之间的连接,对于不同数据类型之间的连接,就会报错。而格式化字符串就是解决这样的问题的,下面三种格式化字符串,连接不同数据类型的时候就不会报错:
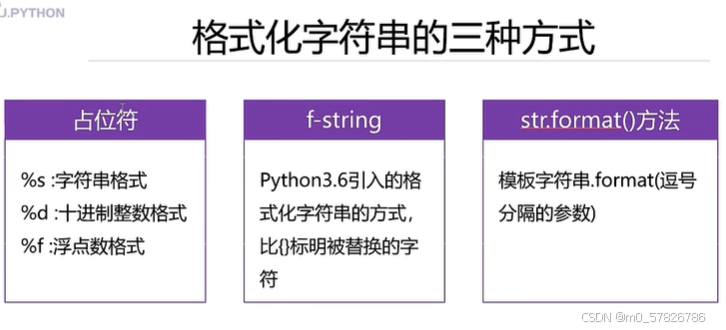
1.占位符:这里只是列举出来的三种,当然不止三种
2.f-string:必须是python3.6以后的,用{}表明被替换分字符
3.foemat:使用一个字符串模板,然后去加“.”调用format
格式可简写如下
参数1=a
参数2=b
参数3=c
#(1)使用占位符进行格式化,下面的%s%d%f只是举的例子,可以换成别的
print('参数4:%s,参数5:%d,参数6:%f' %(参数1,参数2,参数3))
#(1)使用f-string进行格式化,{}里面是需要替换上的内容
print(f'参数4:{参数1},参数5:{参数2},参数5:{参数3}')
#(1)使用format进行格式化,这里的换括号里代表的是索引位置,0,1,2代表的是formart当中参数位置的的0,1,2
print('参数4:{0},参数5:{1},参数6:{2}'.format(参数1,参数2,参数3))
实例和相关解释在下面:
#(1)使用占位符进行格式化
name='马冬梅'
age=18
score=98.5
#下边是输出的格式,后面跟着%是因为用了%,%后面跟着元组(需要替换1,需要替换2,需要替换3,...)
print('姓名:%s,年龄:%d,成绩:%f' %(name,age,score))
print('姓名:%s,年龄:%d,成绩:%.1f' %(name,age,score))#.1f表示的是保留一位小数的浮点类型
#(1)使用f-string进行格式化,{}里面是需要替换上的内容
print(f'姓名:{name},年龄:{age},成绩:{score}')
#(1)使用format进行格式化,这里的换括号里代表的是索引位置,0,1,2代表的是formart当中参数位置的的0,1,2
print('姓名:{0},年龄:{1},成绩:{2}'.format(name,age,score))
print('姓名:{2},年龄:{0},成绩:{1}'.format(age,score,name))#换了format中参数的索引为主,前面的只要对应好位置也可以输出相同的结果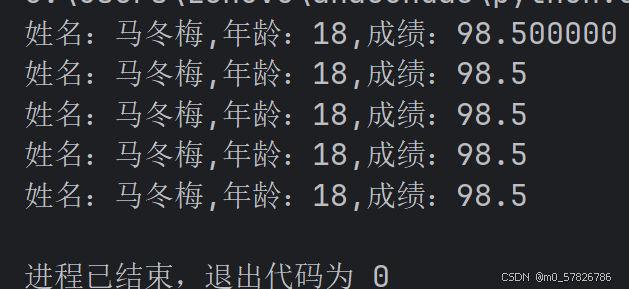
四、format详细格式控制
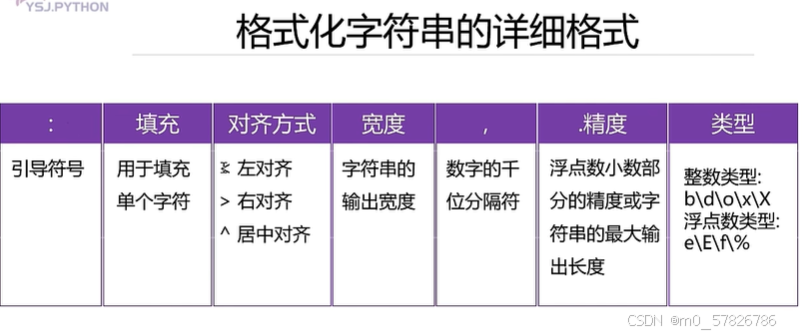
下面具体的实例以及详解:
s='helloworld'
print('{0:*<20}'.format(s))#0是索引,:是引导符,*是填充符号,<是左对齐,字符串的表示宽度为20,左对齐,空白部分用*填充
print('{0:*>20}'.format(s))#其他都跟上面一样。就是“左对齐”改成了右对齐
print('{0:*^20}'.format(s))#其他都跟上面一样。就是“左对齐”改成了居中对齐
#居中对齐
print(s.center(20,'*'))
#千位分隔符(只适用于整数和浮点数,结果就是三位一逗号)
print('{0:,}'.format(987654321))#意思就是用,分隔format括号里面的数
print('{0:,}'.format(987654321.7865))
#浮点数小数部分的精度
print('{0:.2f}'.format(3.1415926))#对于浮点数类型,“.2f”表示保留两位小数
print('{0:.5}'.format('helloworld'))#对于字符串类型,“.5”表示从左到右最大的显示长度
#整数类型
a=425
print('二进制:{0:b},十进制:{0:d},八进制:{0:o},十六进制:{0:x},十六进制:{0:X}'.format(a))#因为都是0,也就是只需要一个索引为0的参数,这里format只需要一个参数就可以了
#浮点数类型
b=3.1415926
print('{0:2f},{0:2E},{0:2e},{0:2%}'.format(b))#这里f表示保留几位小数,E和e表示科学计数法,%表示百分数
下为运行结果:

本节完