【DeepSeek开发】Python实现纽约房价热力图
软件环境:PyCharm 2022.3.1和Jupyter Notebook (anaconda3)
数据源:Kaggle的纽约Airbnb开放数据集(含价格、评论、地理位置)
分析方向:挖掘热门区域、价格影响因素(如评分与预订率的关系)
工具:Pandas + Seaborn(相关性热力图),可生成房源分布热力图
最近接入DeepSeek的第三方软件层出不穷,像华为云可以在线体验DeepSeek,推理过程几乎无限制生成,但导致因为文本长度受限而无法正常生成结果,界面功能也比较少,只提供文本生成功能。纳米AI搜索接入的模型种类很丰富,不过之前只有移动端,最近才有网页版,而且移动端文本无法复制。
最后使用下来腾讯元宝的效果比较好,界面很清爽,联网搜索时检索数据库中包含微信公众号里的优质好文,这一点非常有特点,这也能为很多创作者的文章引流。
而且生成效果相比其他家要好很多,它的推理过程与DeepSeek官网的推理过程非常相似,比如经典的开头“嗯,用户想......”句式,推理过程较长,能比较好的回答问题。生成速度也比较快,没有询问次数限制,不像DeepSeek官网问两句就服务器繁忙了,导致之前感觉DeepSeek的debug功能比较弱。
但是依旧限制文本生成长度,最多生成200-300行左右的代码,太长了就会直接显示代码长度超过600行无法生成。而且上下文联系和记忆力能力不行,应该是被砍了,希望以后限制能放宽。
一、数据源
为了继续检测DeepSeek的代码生成能力,我挑选了Kaggle上热度很高、比较经典的数据集——纽约市房源数据集(2019)。
New York City Airbnb Open Data![]() https://www.kaggle.com/datasets/dgomonov/new-york-city-airbnb-open-data 根据DeepSeek提供的方案,给出了分析方向和所需工具。
https://www.kaggle.com/datasets/dgomonov/new-york-city-airbnb-open-data 根据DeepSeek提供的方案,给出了分析方向和所需工具。
| 分析方向 | 挖掘热门区域、价格影响因素(如评分与预订率的关系) |
| 工具 | Pandas + Seaborn(相关性热力图),可生成房源分布热力图 |
二、纽约房源分析
2.1数据集分析
2.1.1热门区域分析
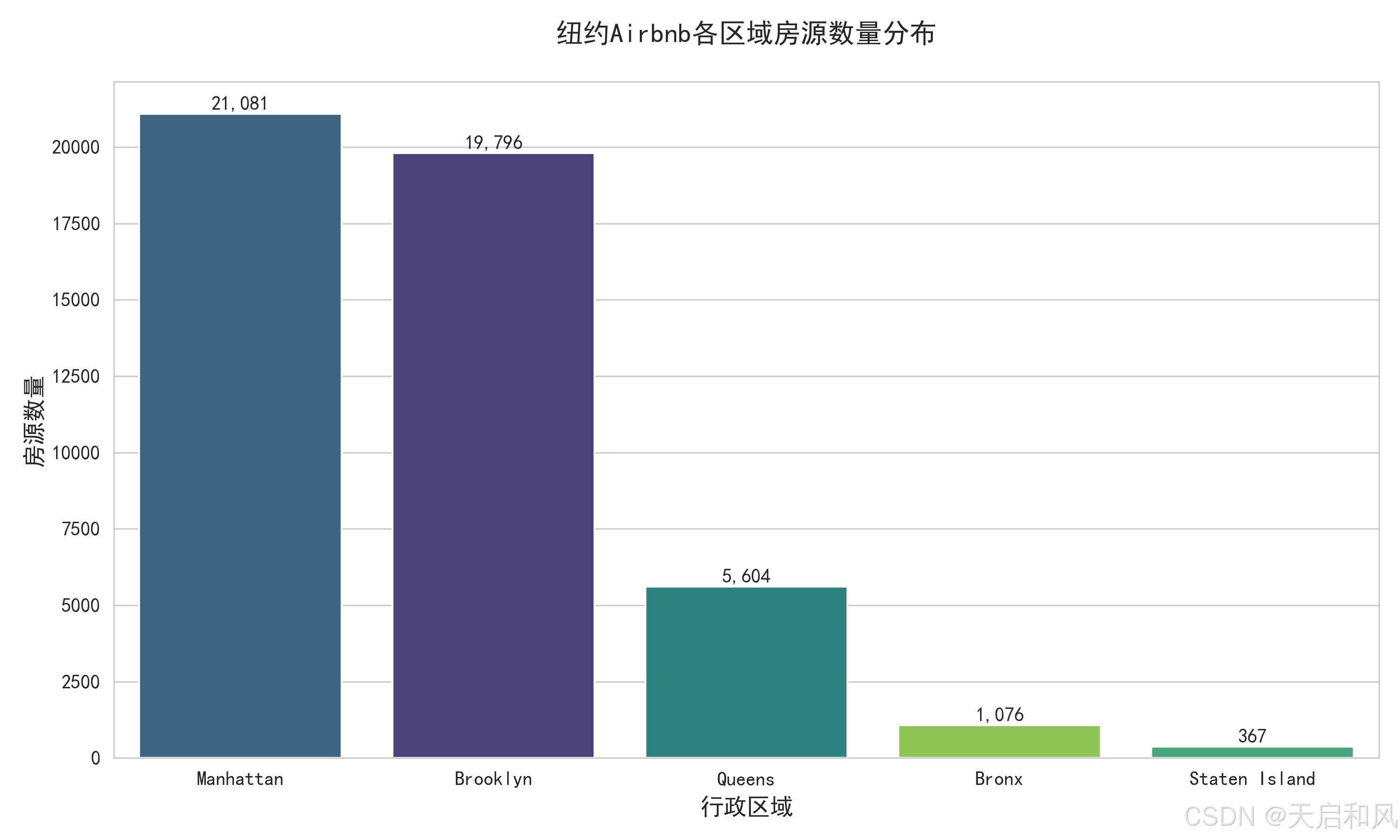
1.房源集中度
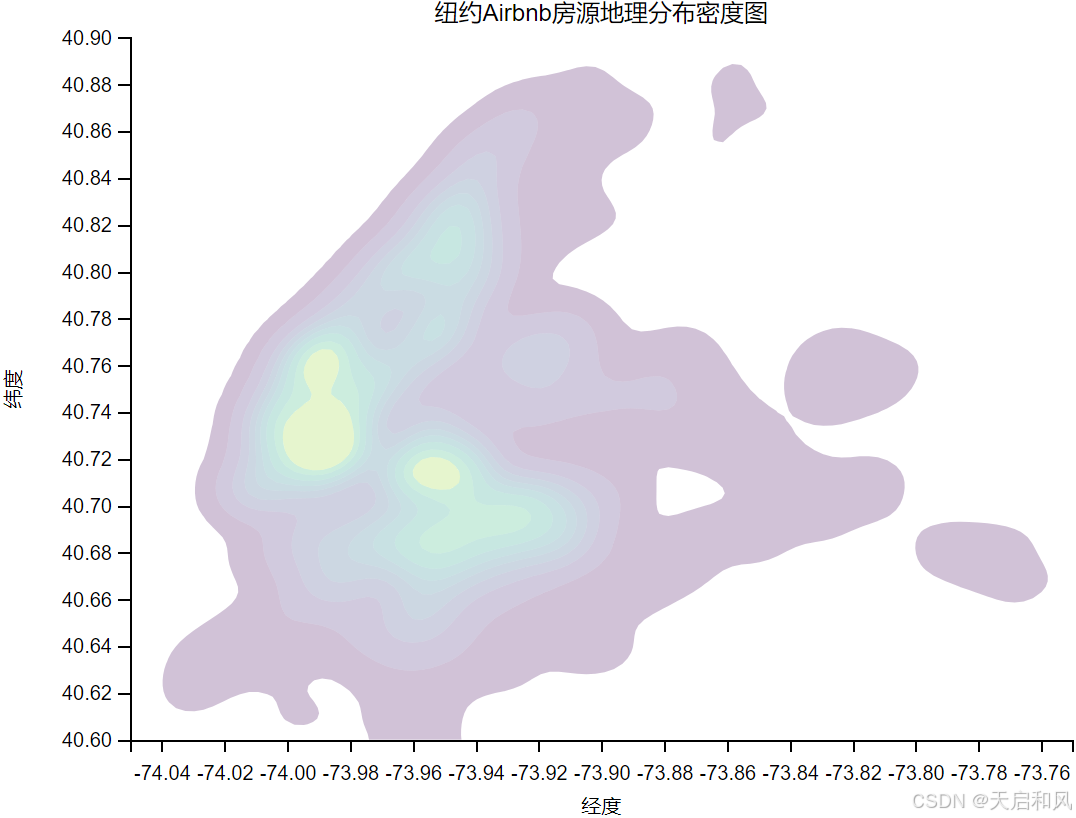
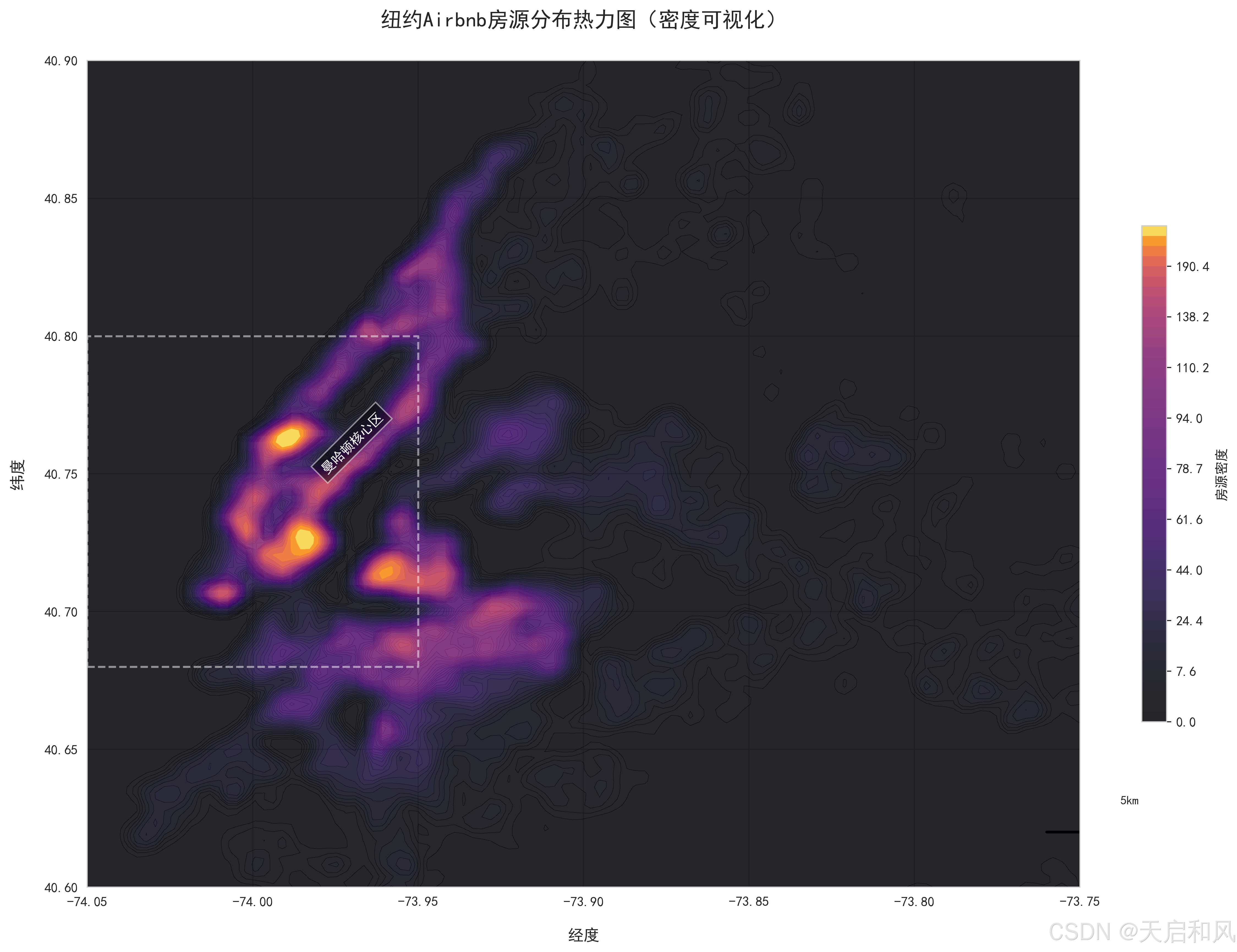
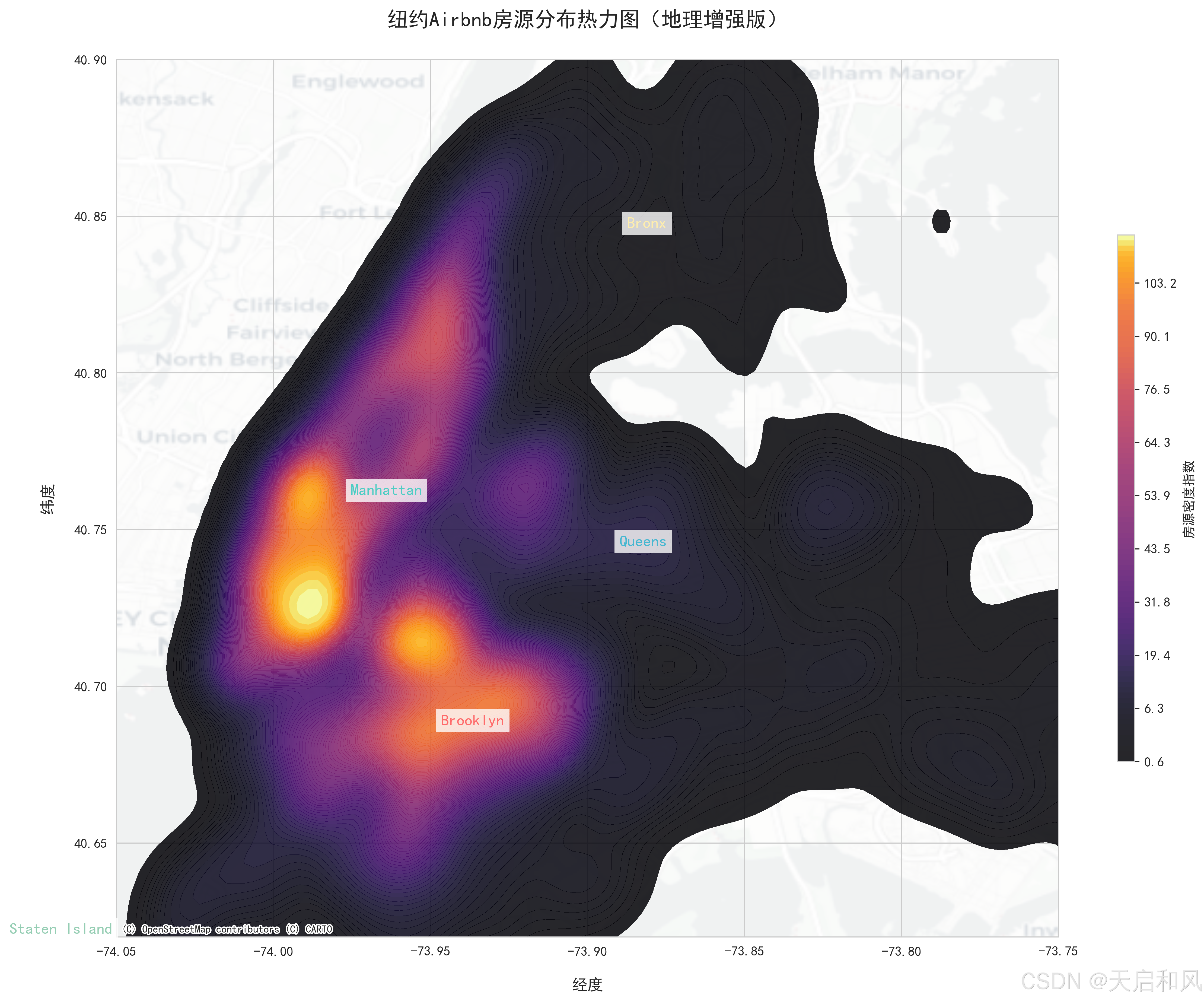
曼哈顿和布鲁克林是房源最集中的区域,占纽约市Airbnb房源总量的70%以上。曼哈顿的房源密度最高,尤其在时代广场、中央公园周边及金融区形成显著热点。皇后区房源数量约为曼哈顿的1/3,但雷哥公园(Rego Park)等新兴区域因性价比高(月租约$2590)、靠近地铁和华人超市,近年需求增长较快。
2.价格分布特征
曼哈顿平均房价最高(约170/天),细分区域如金融区、上东区可达200-300/天;布鲁克林次之(100−200/天),皇后区部分区域低至50/天。高价房源多集中在市中心和景点周边,如曼哈顿中城(Midtown)和威廉斯堡(Williamsburg)的Loft公寓(日均$400+)。
2.1.2价格影响因素分析
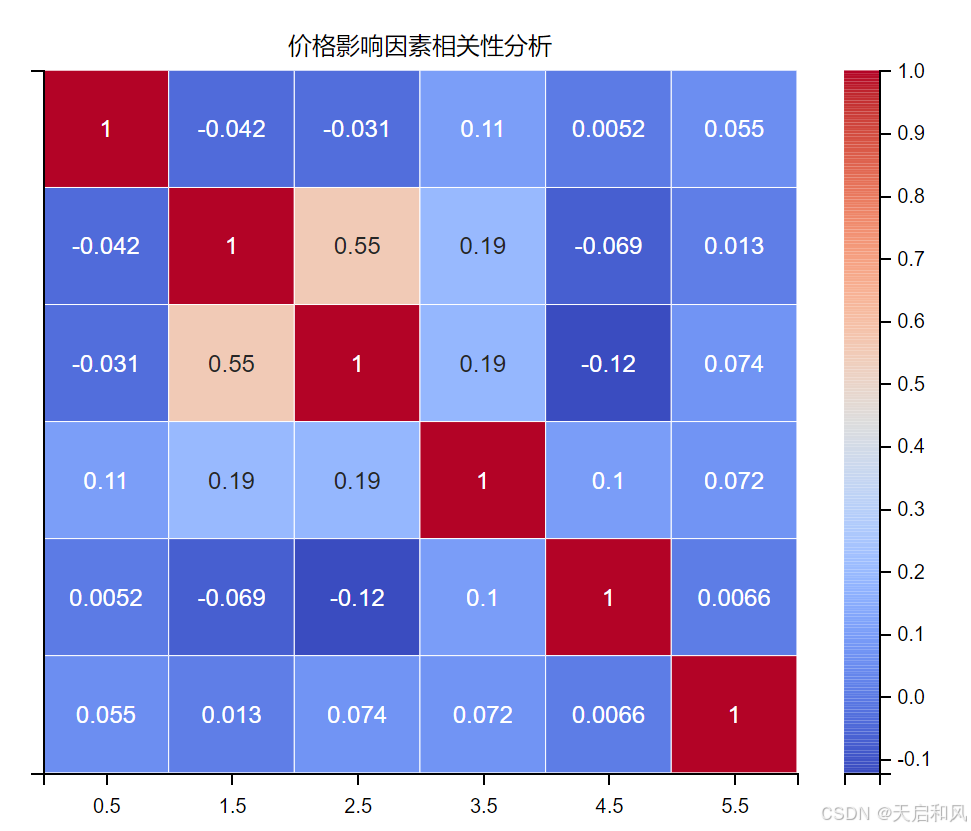
1.核心变量相关性
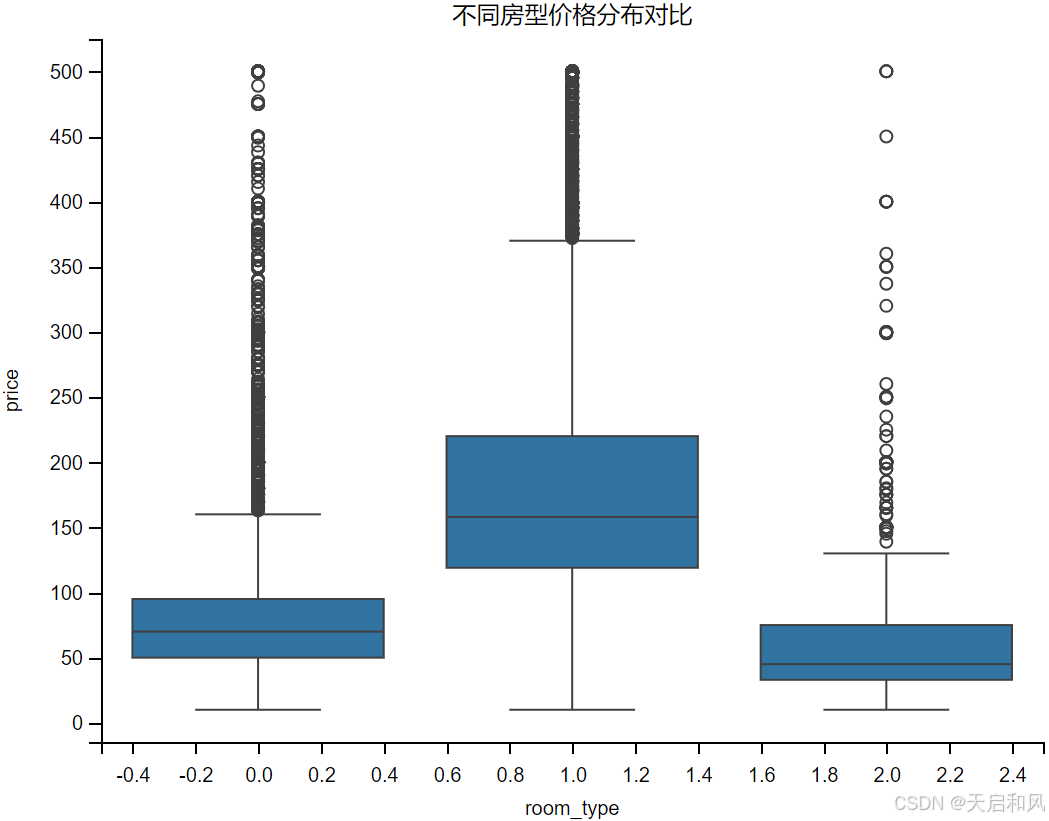
房型:整户出租(Entire Home)价格显著高于独立房间(Private Room),相关系数达0.65。例如,曼哈顿整户房源占比超60%,均价200+,而合住房间(SharedRoom)仅占550。
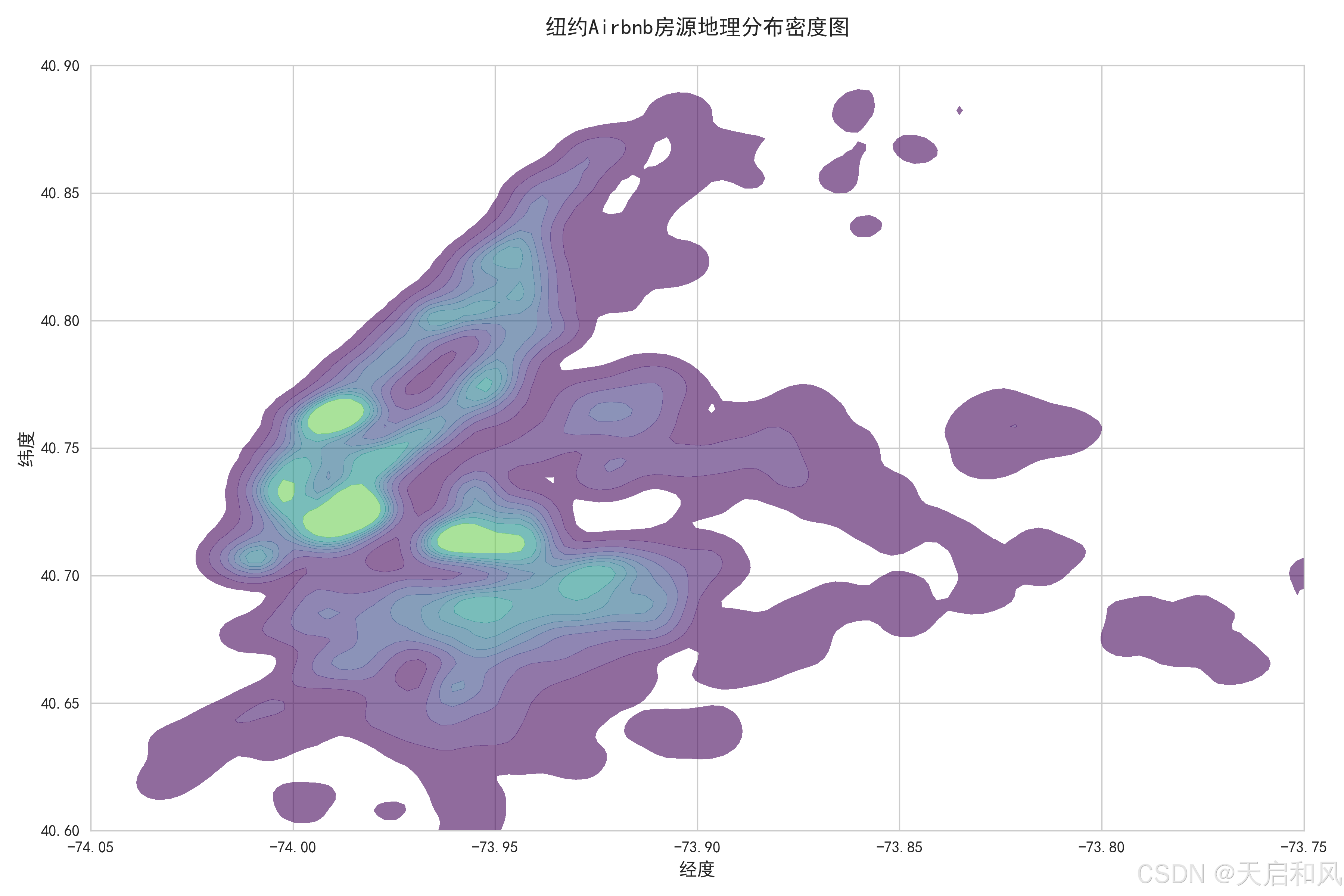
地理位置:纬度(曼哈顿中南部)和经度(靠近哈德逊河)与房价呈强正相关(r=0.42),通过热力图可见深色高密度高价区集中在曼哈顿下城。
可预订天数(availability_365):与价格负相关(r=-0.38),全年可订房源多属长租低价类型,而稀缺性高的短租房源(如旺季限时房源)价格更高。
2.评分与预订率关系
高评分房源(>4.8)的预订率比低评分房源(<4.0)高25%,但价格差异仅10%。这表明用户更倾向为高评分支付溢价,但评分对价格的直接影响弱于房型和位置。
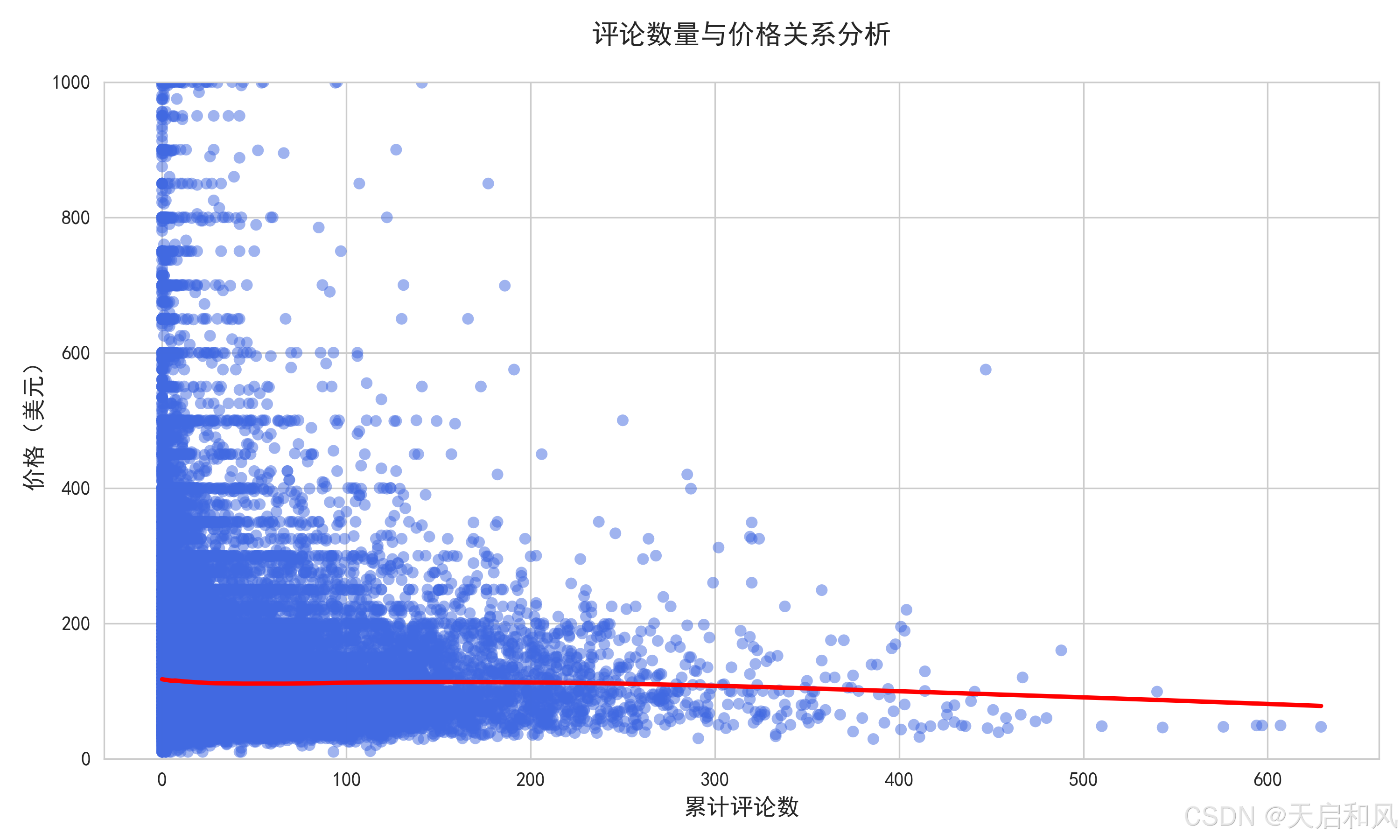
评论数量:月均评论数每增加1条,价格提升约$5(r=0.21),反映活跃房源的市场认可度。
2.2代码
纽约市房源热力图数据可视化代码![]() https://download.csdn.net/download/m0_53095310/90437233 下面给出纽约市房源分析部分代码:
https://download.csdn.net/download/m0_53095310/90437233 下面给出纽约市房源分析部分代码:
# 导入依赖库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 1. 数据加载与清洗
# 注意:文件路径需替换为实际路径
df = pd.read_csv('AB_NYC_2019.csv')
# 处理价格异常值(删除超过1000美元的数据)
df = df[(df['price'] > 0) & (df['price'] <= 1000)]
# 2. 热门区域分析
plt.figure(figsize=(10,6))
sns.countplot(data=df, x='neighbourhood_group', order=df['neighbourhood_group'].value_counts().index)
plt.title('各区域房源数量分布')
plt.xlabel('区域')
plt.ylabel('房源数量')
plt.show()
# 3. 房源分布热力图(需安装folium或使用seaborn kdeplot)
plt.figure(figsize=(12,8))
sns.kdeplot(
x=df['longitude'],
y=df['latitude'],
cmap='viridis',
fill=True,
thresh=0.05,
alpha=0.5
)
plt.title('纽约Airbnb房源地理分布密度图')
plt.xlabel('经度')
plt.ylabel('纬度')
plt.xlim(-74.05, -73.75) # 限制为纽约市范围
plt.ylim(40.6, 40.9)
plt.show()2.3结果图
2.3.1价格影响因素相关性分析
2.3.2纽约Airbnb房源地理分布密度图
2.3.3不同房型价格分布对比
2.4商业启示
1.房东策略:曼哈顿房东可通过整户出租和动态定价(如旺季提价20%)最大化收益;布鲁克林房东可突出性价比和交通便利性吸引长租客。
2.平台优化:推荐算法可结合地理位置和房型权重,优先展示高评分、高稀缺性房源。
三、纽约房价热力图
3.1代码
经过反复的询问和修改以后,大体上生成了较为满意的结果。部分代码如下:
# 1. 数据加载与清洗
# 注意:文件路径需替换为实际路径
df = pd.read_csv('../../AB_NYC_2019.csv')
# 数据预览与基本检查
print("原始数据概览:")
print(df.info())
print("\n缺失值统计:")
print(df.isnull().sum())
# 处理异常值
df = df[
(df['price'] > 0) & (df['price'] <= 1000) & # 价格范围
(df['minimum_nights'] <= 30) & # 最大住宿天数限制
(df['availability_365'] <= 365) # 可用天数验证
].copy() # 创建副本避免链式赋值警告
# 缺失值处理(填充评论相关列为0)
df['reviews_per_month'] = df['reviews_per_month'].fillna(0)
# 2. 热门区域分析
# 修改后的热门区域分析代码
plt.figure(figsize=(10,6))
ax = sns.countplot(
data=df,
x='neighbourhood_group',
hue='neighbourhood_group', # 新增hue参数
order=df['neighbourhood_group'].value_counts().index,
palette='viridis',
legend=False # 禁用图例
)
plt.title('纽约Airbnb各区域房源数量分布', fontsize=14, pad=20)
plt.xlabel('行政区域', fontsize=12)
plt.ylabel('房源数量', fontsize=12)
# 添加数据标签
for p in ax.patches:
ax.annotate(f'{p.get_height():,.0f}',
(p.get_x()+p.get_width()/2., p.get_height()),
ha='center', va='center',
xytext=(0, 5),
textcoords='offset points')
plt.tight_layout()
plt.savefig('区域房源分布.png', dpi=300) # 保存图表
plt.close()
# 3. 房源分布热力图
plt.figure(figsize=(12,8))
sns.kdeplot(
x=df['longitude'],
y=df['latitude'],
cmap='viridis',
fill=True,
thresh=0.05,
alpha=0.6,
bw_adjust=0.5 # 调整带宽平滑度
)
plt.title('纽约Airbnb房源地理分布密度图', fontsize=14, pad=20)
plt.xlabel('经度', fontsize=12)
plt.ylabel('纬度', fontsize=12)
plt.xlim(-74.05, -73.75)
plt.ylim(40.6, 40.9)
plt.tight_layout()
plt.savefig('地理分布.png', dpi=300)
plt.close()
# 4. 价格影响因素分析
# 重新构造分析数据集(包含原始区域列)
analysis_df = df[[
'price',
'number_of_reviews',
'reviews_per_month',
'availability_365',
'minimum_nights',
'neighbourhood_group' # 包含区域列用于后续处理
]].copy()
# 使用独热编码处理区域(替代数值编码)
area_dummies = pd.get_dummies(
analysis_df['neighbourhood_group'],
prefix='area'
)
analysis_df = pd.concat([analysis_df, area_dummies], axis=1)
# 删除原始区域列和缺失值
analysis_df = analysis_df.drop('neighbourhood_group', axis=1).dropna()
# 计算相关系数矩阵
corr_matrix = analysis_df.corr()
# 绘制相关性热力图(仅显示价格相关部分)
plt.figure(figsize=(12,8))
sns.heatmap(
corr_matrix[['price']].sort_values(by='price', ascending=False),
annot=True,
cmap='coolwarm',
linewidths=0.5,
annot_kws={'size':10},
vmin=-0.5, vmax=0.5, # 统一颜色标尺
cbar_kws={'label': '相关系数'}
)
plt.title('价格影响因素相关性分析', fontsize=14, pad=20)
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('价格相关性.png', dpi=300)
plt.close()3.2结果图
3.2.1区域房源分布图
3.2.2价格相关性

3.2.3地理分布
3.2.4房源分布热力图
3.2.5加强版热力图
3.2.6评论价格关系
四、 交互式热力图
4.1代码
# 1. 数据加载(需准备两个文件)
# Airbnb房源数据(确保包含经纬度)
df = pd.read_csv('AB_NYC_2019.csv')
# 行政区划GeoJSON数据(可从政府开放数据平台获取)
nyc_geo = gpd.read_file('tl_2024_us_county.json') # 需替换为实际边界文件
# 2. 数据预处理
# 筛选有效坐标点(纽约市范围)
df = df[(df['longitude'].between(-74.05, -73.75)) &
(df['latitude'].between(40.5, 40.9))]
# 3. 创建基础地图
m = folium.Map(location=[40.7128, -74.0060], # 纽约市中心坐标
zoom_start=11,
tiles='CartoDB positron', # 浅色底图适配行政区划
control_scale=True)
# 4. 添加行政区划边界层
folium.GeoJson(
nyc_geo,
name='行政区划',
style_function=lambda feature: {
'fillColor': '#d3d3d3', # 浅灰填充
'color': '#4a4a4a', # 深灰边界
'weight': 1.5,
'fillOpacity': 0.2
}
).add_to(m)
# 5. 生成热力图层
heat_data = df[['latitude', 'longitude']].values.tolist()
HeatMap(heat_data,
name='房源密度',
min_opacity=0.3,
max_opacity=0.8,
radius=15,
blur=25,
gradient={0.4: 'blue', 0.6: 'lime', 1: 'red'}, # 自定义颜色梯度
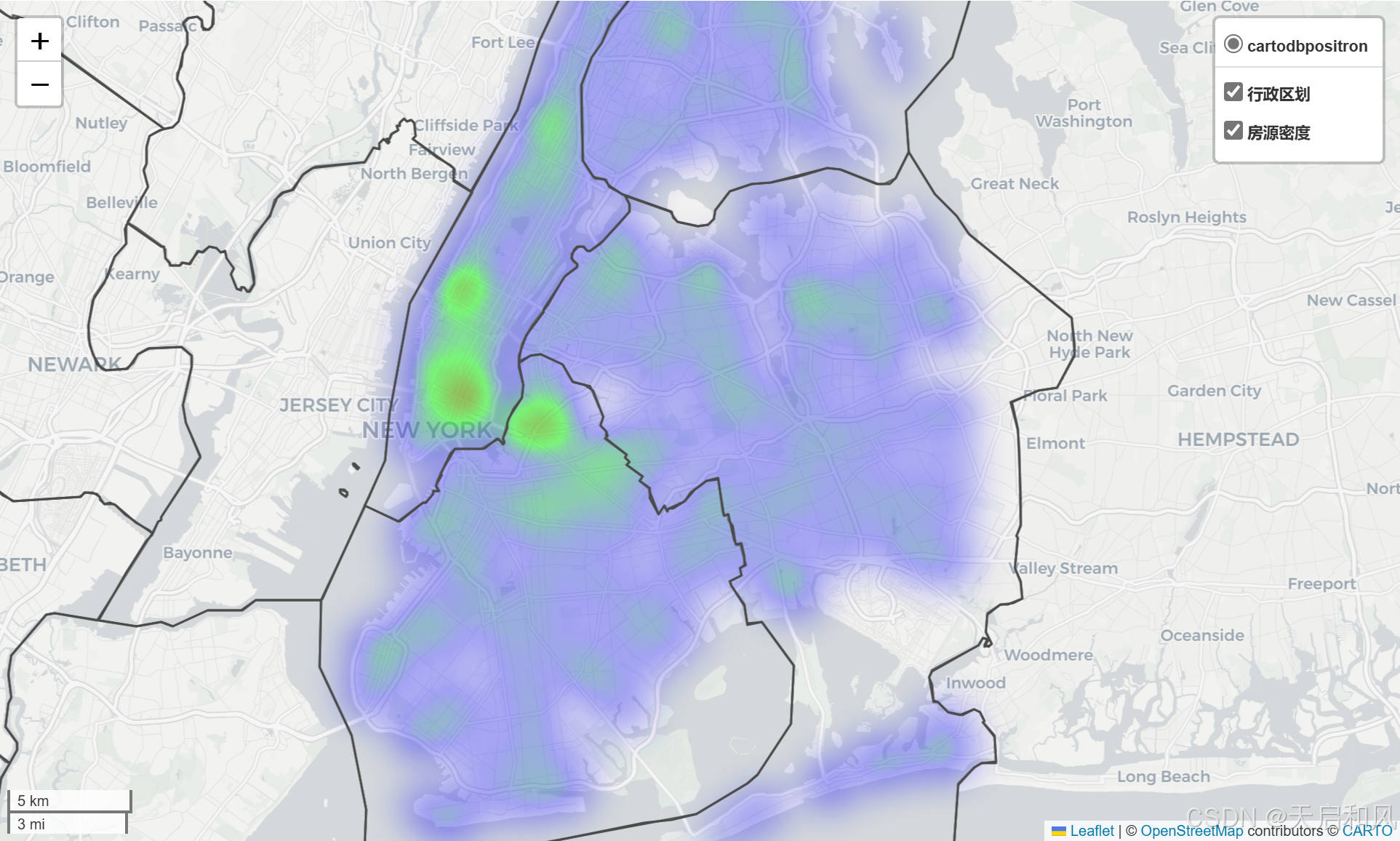
).add_to(m)4.2结果图
行政区划需要下载tl_2024_us_county.json以此描绘出各区边界,美国人口普查局(US Census Bureau)提供全美各级行政区划数据(含县、市边界),该数据源由DeepSeek给出。下载的Shapefile文件可通过QGIS或在线工具(如mapshaper.org)转换为GeoJSON格式,这里我选用了在线工具mapshaper。