【文献阅读】基于机器学习的网络最差鲁棒性可扩展快速评估框架
这篇题为《Scalable rapid framework for evaluating network worst robustness with machine learning》的研究论文聚焦于网络最差鲁棒性的评估问题,提出了一种结合最大破坏攻击和卷积神经网络的快速评估框架。
摘要:
鲁棒性对于理解、设计和优化网络以及网络修复至关重要,而仿真攻击是当前主流的评估方法。然而,仿真攻击往往耗时甚至难以实施;更关键但长期被忽视的缺陷在于,任何攻击策略仅能提供一种潜在的瓦解范式。核心问题是:在最坏情况下或面临最严峻攻击时,给定系统的鲁棒性极限(称为"最差鲁棒性")究竟为何?理解系统的最差鲁棒性,对于掌握其可靠性边界、评估防护能力以及确定相关设计与安全维护成本具有决定性意义。 为解决这些挑战,我们提出基于知识堆叠思想的"最大破坏攻击"(Most Destruction Attack, MDA)概念。通过MDA评估网络的最差鲁棒性后,采用改进的CNN算法加速最差鲁棒性预测。我们论证了MDA的逻辑有效性,并证明改进CNN算法在预测不同网络拓扑最差鲁棒性时的卓越性能。该最差鲁棒性评估(Worst Robustness Evaluation, WRE)框架具有可扩展性:既能兼容现有或未来的各种攻击策略,也可通过更强大的机器学习算法提升预测能力。
一、研究重点
核心问题:如何评估网络在最坏情况下的鲁棒性下限,即“最差鲁棒性”。
目标:提供一个可扩展、快速的框架,避免传统模拟攻击方法的高计算成本,并能近似网络在最具破坏性攻击下的性能极限。
二、研究思路
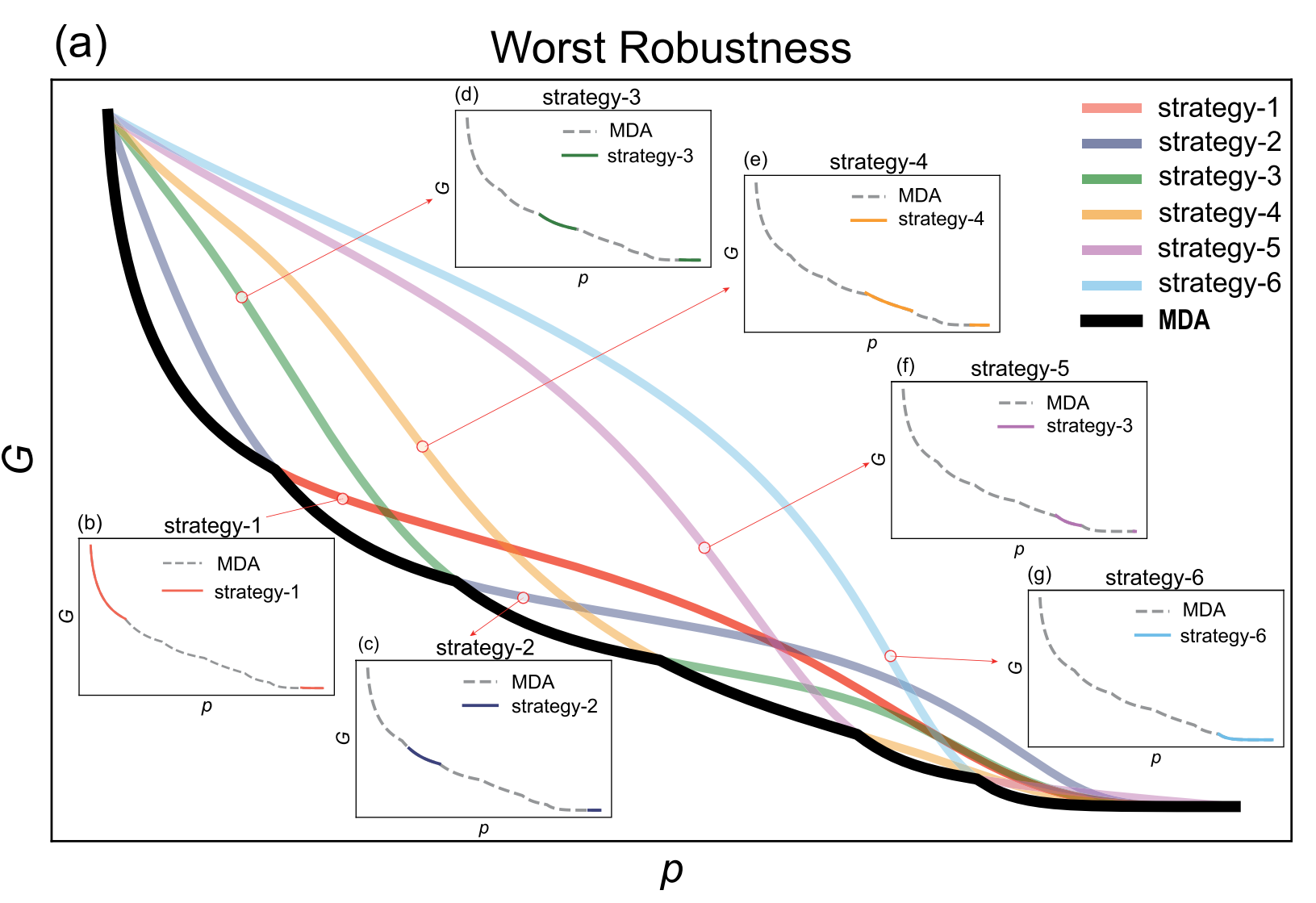
提出概念:引入最大破坏攻击(MDA),通过“知识堆叠”方法,将多种攻击策略在每个步骤中最具破坏性的部分组合成一条连续的攻击路径,以近似理论上的最优攻击。
加速评估:使用改进的CNN-SPP模型对MDA曲线进行快速预测,避免重复模拟攻击策略的高时间成本。
三、受什么启发?在哪些研究基础上进行?
启发:现有网络鲁棒性评估方法大多依赖单一攻击策略,无法反映网络在最坏情况下的性能极限,且直接枚举所有攻击组合是NP难问题。
研究基础:
传统鲁棒性评估方法(如基于中心性、渗流理论、社区结构等)。
多特征融合的攻击策略(如TOPSIS、QRE等)。
卷积神经网络在图像和网络结构分析中的应用(如邻接矩阵作为图像处理)。
四、是否对现有研究进行了改进?
是,主要改进包括:
首次明确定义并系统评估“最差鲁棒性”这一网络固有属性。
提出MDA方法 Most Destruction Attack,通过策略堆叠逼近最优攻击,优于单一策略。
引入CNN-SPP模型实现秒级预测,比模拟攻击快数百倍。
SPP:Spatial Pyramid Pooling(空间金字塔池化),是何凯明等人提出的技术,解决了CNN需要固定尺寸输入图像的限制。
传统CNN问题:全连接层要求输入特征的尺寸是固定的。因此,输入图像必须被缩放或裁剪到统一尺寸,这可能造成信息失真。
SPP的解决方案:在卷积层和全连接层之间加入SPP层。SPP层对卷积生成的特征图进行多尺度的最大池化(例如,将特征图分别划分为4x4、2x2、1x1的网格,然后在每个格子内做池化),并将所有尺度的池化结果拼接成一个固定长度的向量,再送入全连接层。这样,网络可以接受任意尺寸的输入图像。
五、Challenge(挑战)是什么?
理论挑战:最差鲁棒性的精确计算是NP难问题(复杂度为 2N2N),无法直接求解。
实践挑战:
如何组合多种攻击策略才能最大程度破坏网络?
如何在高维网络数据上快速预测MDA曲线?
如何保证模型对不同拓扑网络的泛化能力?
六、模型架构与输入输出数据
模型架构:CNN-SPP
输入层:网络的邻接矩阵(二进制图像,节点数 N×N)。
卷积模块:8个卷积块,每块包含:
卷积层(3×3或5×5卷积核)
ReLU激活函数
最大池化层(2×2)
SPP层:多尺度池化(4×4, 3×3, 2×2, 1×1),生成固定长度特征向量。
全连接层:两个全连接层进行回归预测。
输出层:MDA曲线(即GCC相对大小随节点移除比例的变化序列)。
输入输出数据
输入:网络的邻接矩阵。
输出:MDA曲线(长度为 N 的序列),用于计算最差鲁棒性 RW。
七、模型训练与验证
数据:
实证网络(用于测试模型性能)
网络名称 类型 节点数 (N) 边数 (M) 平均度 (<k>) 领域是否在训练集中 bible-nouns 语言网络(名词共现) 1,771 9,131 10.3 否 (Type I) GD96-a 杂项(图论模型) 1,096 1,677 3.1 否 (Type I) CAG-mat1916 组合问题网络 1,916 164,934 172.2 否 (Type I) routers-rf 技术网络(路由器) 2,113 6,632 6.3 否 (Type I) tech-as-caida2007 技术网络(互联网) 1,000 3,342 6.7 是 (Type II) fb-pages-company 社交网络(Facebook页面) 1,000 2,490 5.0 是 (Type II) econ-poli-large 经济网络(政治关系) 1,000 1,173 2.3 是 (Type II) email-emon-large 通信网络(邮件) 1,000 6,119 12.2 是 (Type II) 合成网络(用于训练和测试基础性能)
合成网络的节点数在训练时统一设置为 N = 1000,以便于处理。它们在不同平均度
<k> = 4, 6, 8下生成。BA网络: 异质,无标度网络。
ER网络: 同质,随机网络。
WS网络: 小世界网络。
Regular网络: 规则网络(如环状网络)。
论文采用了两阶段训练法,这是为了保证模型既学习到基础的网络拓扑原理,又能适应真实世界的复杂情况。
第一阶段训练(基础训练)
训练数据: 仅使用合成网络。
4种网络模型(BA, ER, WS, Regular)x 3种平均度(4, 6, 8)x 每种组合生成1000个实例 = 12,000个网络。
从中分配:9,600个用于训练,1,200个用于交叉验证,1,200个用于测试。
目的: 让模型学习不同拓扑结构(异质/同质/小世界/规则)如何影响其鲁棒性。
第二阶段训练(增强泛化)
训练数据: 第一阶段数据 + 新增的真实网络数据。
新增了多种类型的真实网络(社交、经济、技术、通信),将它们采样成连通子图,大小为N=1000。
新增了5,000个网络实例。
最终训练集: 9,600(合成)+ 4,000(真实)= 13,600个。
验证集和测试集也相应增加。
目的: 让模型适应真实网络的不规则特性,提升其在实际应用中的泛化能力。
验证数据(最终性能评估)
最终模型的测试是在未见过的数据上进行的,包括:
合成网络: 与训练集同类型但新生成的实例。
实证网络:
Type I: 其领域(如“语言网络”、“路由器网络”)未出现在训练集的真实网络数据中。用于测试模型的泛化能力。
Type II: 其领域(如“社交网络”、“技术网络”)包含在训练集的真实网络数据中。用于测试模型在“熟悉”的真实网络类型上的精确度。
效果评估(是否都好?)
答案是:效果总体非常好,但在不同情况下有细微差别。 论文通过多个图表(图4, 图5, 图6)展示了结果。
合成网络(图4):效果极好。预测的MDA曲线(红点)与模拟的真实曲线(蓝点)几乎完全重合。计算出的最差鲁棒性值 RWRW 的预测值与模拟值也高度一致。 模型完全掌握了这四种基本网络模型的鲁棒性规律。
实证网络 - Type I(未知类型,图5):效果良好,但有微小误差。预测曲线能准确捕捉到整体下降趋势,但在一些曲线陡降的局部位置可能出现偏差。原因: 这些网络的结构可能含有训练数据中未出现过的独特模式,模型难以预测某个特定节点的移除会引发如此剧烈的连锁反应。 尽管局部有偏差,但最终计算出的整体 RW 值差异很小,在工程应用上是可接受的。这证明了模型强大的泛化能力。
实证网络 - Type II(已知类型,图6):效果极好。预测曲线和模拟曲线几乎完美匹配,RW值基本无差异。当训练数据充分覆盖了目标网络的类型时,模型可以做出非常精确的预测。
可扩展性验证(附录图A.4):模型在远超训练尺寸(N=1000)的大型网络(如N=8000, 10000)上依然表现良好。