IBM开源轻量多模态文档处理模型:Granite-Docling 258M,能执行OCR、文档QA
在企业数字化转型的深水区,一个被长期忽视的效率黑洞正在浮出水面:非结构化文档。无论是扫描合同、科研论文、财务报表还是工程图纸,它们躺在硬盘和云盘里,却无法被系统真正“读懂”。OCR 只能识别文字,传统NLP看不懂表格和公式——直到 IBM 端出这张王牌:Granite-Docling 258M。
这不是一个普通的大模型插件,而是一个专为“文档智能”而生的多模态轻骑兵。
谁是 Granite-Docling 258M?
由 IBM Research 团队于 2025 年 9 月正式开源,Granite-Docling 258M 是一款仅 2.58 亿参数的视觉-语言模型(VLM),但它却拥有“以小博大”的惊人能力:
架构精巧:基于 IDEFICS3 改良,换用 SigLIP 视觉编码器 + Granite 165M 语言模型,在保持轻量的同时实现高精度。
图文联合理解:不仅能“看图识字”,更能理解版面结构、数学公式、代码块、图表关系,输出结构化 DocTags。
极速推理 & 多平台支持:支持 Transformers、vLLM、ONNX、MLX(Apple Silicon 本地运行),批量处理速度提升数倍。
多语言实验支持:除英文外,初步支持中文、日文、阿拉伯文,全球化部署潜力巨大。
它不是通用图像模型,而是“文档专属AI”,设计初衷就是无缝嵌入 Docling 文档处理生态,替代多个单点模型,成为企业文档流水线的“智能中枢”。

六大杀手级功能,重新定义文档处理
1、公式识别大师
数学公式不再是一堆乱码。Granite-Docling 能高精度还原 LaTeX 表达式,编辑距离低至 0.073,F1 分数高达 96.8% —— 科研人员和工程师的福音。
2、代码块精准提取
支持 50+ 编程语言,从截图或 PDF 中提取可复制粘贴的干净代码,编辑距离从 0.114 降至惊人的 0.013!
3、图表转结构化表格
不只是识别图表存在,更能将其内容转化为机器可读的表格数据(支持 OTSL 格式),打通数据分析最后一公里。
4、区域引导推理(BBox-Guided)
想只提取签名栏?只想读取页眉页脚?通过坐标框选局部区域,模型精准响应,避免全页计算浪费资源。
5、文档元素问答(QA)
“这份合同第3页有没有担保条款?”、“报告里图表出现在哪几节?”——直接提问,AI 给你定位答案。
6、布局保留导出
输出 HTML 或 Markdown 时,可选择保留原始排版(split-page view),学术论文、法律文书转换后仍保持专业格式。
性能碾压前辈,小模型也有大能量
相比前代 SmolDocling,Granite-Docling 258M 在多项基准测试中全面领先:
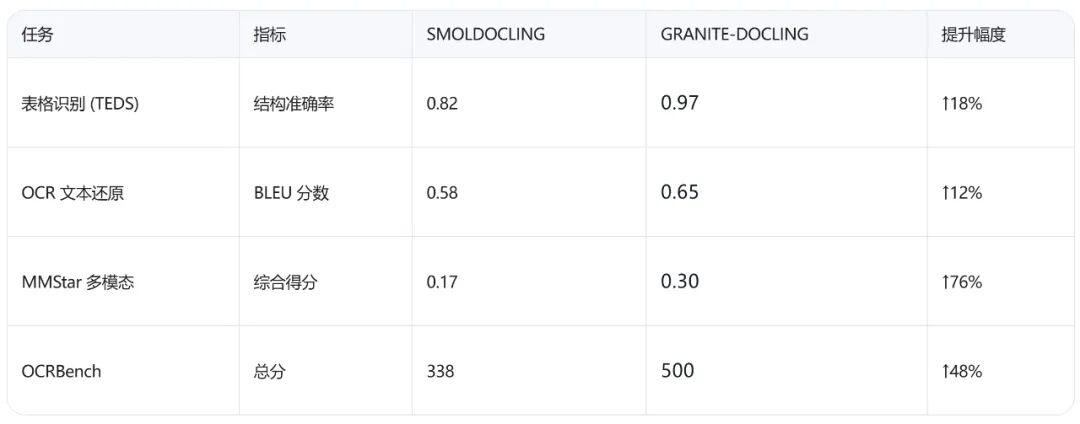
更稳定、更少死循环、更强泛化能力 —— 小体积,大智慧。
如何快速上手?
只需一行命令,即可体验魔法:

开发者也可直接调用 Transformers API,自定义处理逻辑:

支持 CUDA、MPS(Mac)、甚至 ONNX 部署到边缘设备。
负责任的AI:安全与局限
IBM 明确指出:Granite-Docling 不适用于通用图像理解。对于敏感场景,建议搭配 Granite Guardian 安全过滤模型,防范偏见、错误与恶意输出。模型虽小,伦理不小。
Granite-Docling 258M 不仅是工具,更是“文档即数据”时代的基础设施。下一步,IBM 计划集成 RAG 增强检索、实时协作批注、跨文档语义关联等功能,让静态文档“活”起来,成为企业知识图谱的自动构建者。
Hugging Face:https://huggingface.co/ibm-granite/granite-docling-258M