RPC在分布式存储系统中的应用
摘要
本文旨在介绍远程过程调用(Remote Procedure Call,以下简称RPC)的基本原理和发展过程,并介绍了RPC机制作为一种底层通信框架,是如何应用在分布式存储系统中,为存储系统上层应用组件服务的。
1. 引言
在当今的数据中心和云计算环境中,分布式存储系统起着关键作用。分布式存储是指将数据存储在多个点(或服务器)上,通过网络连接将这些节点连接起来,形成一个统一的存储系统。在分布式存储中,数据可以被分散存储在不同的节点上,而且每个节点可能存储数据的副本,以提高数据的可靠性。这种存储方式允许数据在不同节点之间进行分布和复制,从而提高了数据的可用性、可靠性和性能。
分布式存储系统通常采用分布式文件系统或分布式数据库来管理数据的存储和访问。它通常采用数据分片、数据块副本、数据冗余备份等技术,以确保数据的安全和可靠性。此外,分布式存储系统还能够通过智能负载均衡、数据压缩、数据加密等技术来提高数据的访问效率和安全性。
分布式存储系统可以横向扩展,通过增加节点来扩展存储容量和计算能力,而且能够动态地调整和分配存储资源,以满足不同的业务需求和数据访问模式。因此,在分布式系统中,最主要的是如何让各个节点协同高效工作。这里面就涉及通信的问题。因此,通信是分布式系统的基石。
分布式系统对通信框架的要求有以下一些:
- 异步通信。基于异步通信,能够处理大量并发请求并充分利用系统资源。
- 高性能。分布式节点之间网络通信要高性能,不能成为系统处理的瓶颈。
- 可靠性。具备自动故障转移和容错机制,能够保障系统的稳定性。
- 接口简单。对于分布在不同节点上的组件来说,希望通信接口尽量简单易用。
基于以上要求,我们在分布式存储系统中引入了一套RPC通信机制。通过该套RPC机制,对上提高了简单易用的调用接口,对下可对接普通TCP传输网络和高效的RDMA网络。
2. 分布式通信概念
传统TCP/UDP通信
说起通信,就不得不提到我们熟知的TCP/IP。我们都知道,网络是分层的。在TCP/IP网络分层模型中,网络通信分为链路层、网络层、传输层、应用层。

最底层也是第一层叫链路层,负责在以太网、Wi-Fi这样的底层网络上收发原始数据包。使用 MAC 地址来标记网络上的设备,所以有时候也叫 MAC层。
第二层叫网络互连层,IP协议就处在这一层。通过IP地址实现了广域网的互联。
第三层叫传输层,负责保证数据在 IP地址标记的两点之间可靠地传输,例如 TCP、UDP、SCTP等协议工作在这一层。该层对上层应用层呈现通信接口。传统TCP/UDP通信在软件层面一般采用Socket进行编程。TCP是面向连接的,可靠的,基于字节流的通信方式。而UDP则是尽力而为的,基于分组的通信方式。他们各有优缺点。
第四层叫应用层,顾名思义,是面向具体应用的协议,如 HTTP、SSH、FTP、SMTP、DNS等。
以下是基本的通信编程过程:
- 先创建socket,以TCP为例:fd = socket(AF_INET,SOCK_STREAM,0);
- 在定义了socket之后,我们就可以对这个socket进行操作,比如用bind()绑定IP和端口,listen()侦听此socket。
- 然后用connect()发起连接建立请求。accept()接受请求。
- 使用send()发送数据,recv()接收数据。
以上就是一条纯裸TCP,而TCP是基于字节流的,字节流可以理解为一个双向的通道里流淌的数据,就像水管里的水流一样。这个数据其实就是我们常说的二进制数据,简单来说就是一大堆 01 串。纯裸TCP收发的这些01串之间是没有任何边界的,你根本不知道到哪个地方才算一条完整消息。这也是TCP中著名的“粘包”问题。
![]()
纯裸TCP是不能直接拿来用的,需要在这个基础上加入一些自定义的规则,用于区分消息边界。于是我们会把每条要发送的数据都包装一下,比如加入消息头,消息头里写清楚一个完整的包长度是多少,根据这个长度可以继续接收数据,截取出来后它们就是我们真正要传输的消息体:
![]()
而这里头提到的消息头,还可以放各种东西,比如消息体是否被压缩过和消息体格式之类的,只要上下游都约定好了,互相都认识就可以了,这就是所谓的协议。
每个使用TCP的项目都可能会定义一套类似这样的协议解析标准,他们可能有区别,但原理都类似。于是基于TCP,就衍生了非常多的协议,比如HTTP和RPC。
RPC和HTTP
前面提到,RPC和HTTP都是基于TCP(或UDP)传输层之上的一种协议,其实他们都可以看做是一种应用层协议。HTTP协议(Hyper Text Transfer Protocol),又叫做超文本传输协议。我们用的比较多,平时上网使用浏览器访问网页,用到的就是HTTP协议。
而RPC(Remote Procedure Call),又叫做远程过程调用。它本身并不是一个具体的协议,而是一种调用方式。举个例子,我们平时调用一个本地方法就像下面这样:
res = localFunc(req)
如果现在这不是个本地方法,而是个远端服务器暴露出来的一个方法remoteFunc,如果我们还能像调用本地方法那样去调用它,这样就可以屏蔽掉一些网络细节,如此一来就方便了许多。
res = remoteFunc(req)
基于这个思路,业界造出了非常多款式的RPC协议,比如比较有名的谷歌的gRPC,Facebook 的thrift,百度的bRPC等。
值得注意的是,虽然大部分RPC协议底层使用TCP,但实际上它们不一定非得使用TCP,改用UDP或者RDMA,其实也可以做到类似的功能。
为什么同时有RPC和HTTP
HTTP是上世纪90年代出现的。在70年代TCP技术出现后,最开始其实是定义了很多的RPC协议。那时还没有HTTP。但随着互联网技术的发展,特别是浏览器,不管是哪家的浏览器,都需要能访问公有或私有的网站。这样就迫切需要一种通用的通信标准,于是HTTP就出现了。此时的软件架构也就从C/S架构变化到B/S架构。从而通信标准也从各种各样的RPC协议统一到HTTP协议。但RPC协议并没有因此而消亡。RPC,因为它定制化程度更高,可以采用体积更小的protobuf或其他序列化协议去保存结构体数据,同时也不需要像HTTP那样考虑各种浏览器行为,因此性能也会更好,这也是在很多分布式系统中抛弃HTTP,选择使用RPC的最主要原因。从发展历史来说,HTTP主要用于B/S架构,而RPC更多用于C/S架构。但现在其实已经没分那么清了,B/S和C/S在慢慢融合。很多软件同时支持多端,所以对外一般用HTTP协议,而内部集群的组件间通信则采用RPC协议进行通讯。
RPC本质上不算是协议,而是一种调用方式,而像gRPC和thrift这样的具体实现,才是协议,它们是实现了RPC调用的协议。目的是希望程序员能像调用本地方法那样去调用远端的服务方法。
RPC工作原理
RPC的使用包括以下几个步骤:RPC服务注册,连接通道建立,调用请求传输,调用结果回复。RPC在客户端和服务端均有服务代理,称为Stub。以一次客户端调用服务端一个服务为例,其过程为:
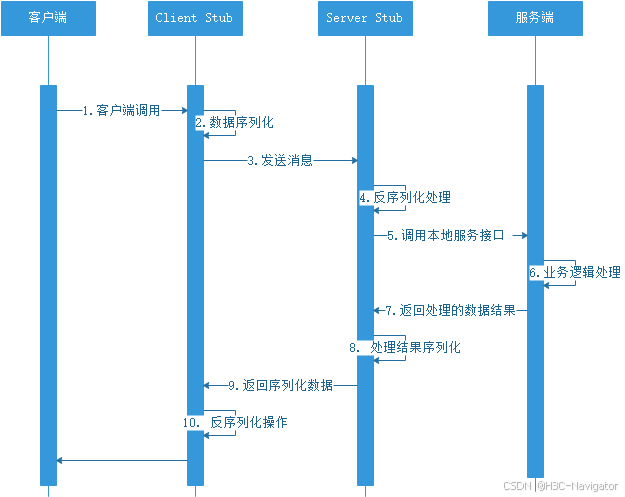
具体调用过程:
1. 服务消费者(client客户端)通过本地调用的方式调用服务。
2. 客户端存根(client stub)接收到请求后负责将方法、入参等信息序列化(组装)成能够进行
网络传输的消息体。
3. 客户端存根(client stub)找到远程的服务地址,并且将消息通过网络发送给服务端。
4. 服务端存根(server stub)收到消息后进行解码(反序列化操作)。
5. 服务端存根(server stub)根据解码结果调用本地的服务进行相关处理。
6. 本地服务执行具体业务逻辑并将处理结果返回给服务端存根(server stub)。
7. 服务端存根(server stub)将返回结果重新打包成消息(序列化)并通过网络发送至消费方。
8. 客户端存根(client stub)接收到消息,并进行解码(反序列化)。
9. 服务消费方得到最终结果。
RPC服务注册
传统的RPC服务注册做法是将服务注册到一个服务注册中心,服务使用方通过订阅机制获得系统注册的服务。在分布式存储系统中,RPC主要用于不同组件在不同节点上的通信,模型相对简单。因此通过在软件层面客户端和服务端均注册RPC ID方式。RPC ID对于一套分布式软件系统来说是全局分配的,业务模块向RPC框架注册不同的消息处理函数,每个消息处理函数映射到不同的RPC ID。Server端根据消息中的RPC ID,即可以找到相应的处理函数并返回处理结果。
连接通道建立
RPC是远程过程调用,自然需要跨网络进行通信。因此,RPC在发送请求前需要先建立网络连接。随着AI/云计算技术的发展,计算业务层面对存储系统的性能要求也越来越高。近年发展起来的RDMA技术相比传统的TCP网络具有更低时延,更大吞吐量,节省CPU资源等优点,已经渐渐成为分布式存储的标准配置。作为对业务层呈现服务请求和响应的RPC层,底层自然需要同时支持TCP网络和RDMA网络。因此,RPC对应的连接通道也需要支持建立TCP连接和RDMA连接两种连接。通常为了可靠性,RDMA连接选择可靠型的RC连接。
RPC序列化和反序列化
在网络传输中,为了提高传输效率。数据必须采用二进制形式, 所以在RPC调用过程中, 需要采用序列化技术,对入参对象和返回值对象进行序列化与反序列化。
- 序列化
在分布式存储系统中,我们采用自动编码方式进行序列化处理。所谓自动编码方式就是每个上层业务将需要编解码的结构放入一个公共的目录。软件在编译的时候自动扫描此目录,得到各个结构的字段以及偏移等信息。业务需要编码的时候,只要传入对应的结构体,自动编码框架即可以帮助业务完成编码动作。特别的,对于大小端一致的分布式系统,自动编码框架不需要逐字段进行网络转序,可以整体copy。进一步提升编码效率。
- 反序列化
反序列处理和序列化处理类似,其过程是将网络收到的消息还原成软件需要的结构。在分布式存储系统中,也可以利用自动解码方式完成反序列化处理。其过程跟序列化类似。
- 兼容性处理
分布式系统一般要求支持在线升级,业务不中断。为此,需要考虑两个方面的兼容处理:
一是RPC消息头本身的兼容,这点通过将RPC头设计为Base Header+可变TLV方式,即RPC有一个基础头base head。包括version,flag,事务id,rpc id等信息。根据flag字段,Base Head后面可选携带若干tlv。例如:时戳信息等。后续版本需要新增字段可以采用增加新的TLV方式。
二是消息体本身的编解码兼容,这部分兼容通过在结构尾部增加字段来保证兼容。
RPC报文格式如下:

RPC在分布式存储系统中的应用
异步收发机制
分布式系统最核心的性能指标包括时延,IOPS,带宽等,因此,对于每个节点的性能要求都很高。为了充分利用多核cpu资源优势,要求存储系统能具有较高的并发量。通常IO模型有同步阻塞和异步非阻塞区分,RPC可以是同步的,也可以是异步的。如果采用同步调用,CPU大部分的时间都在等待而没有去计算,从而导致 CPU的利用率不高。
我们实现的RPC采用全异步方式。在多副本和EC流程中,某次IO对应的RPC发起方发送后,发送流程即退出。结合协程机制,操作系统层面的线程可以将本次IO的异步RPC等待协程切出,继续调度其他协程用于处理其他IO,等RPC回应到达后由RPC框架异步回调业务通知RPC回应到达,此时再唤醒之前等待的协程完成剩下的处理。通过RPC框架完成的全异步交互,较好的提高了系统的并发处理能力。
网络IO模型
网络IO模型一般分为阻塞式IO和IO多路复用。
IO 多路复用特点:IO 多路复用更适合高并发的场景,可以用较少的进程(线程)处理较多的 IO 请求,但使用难度比较高。
阻塞 IO特点:与 IO 多路复用相比,阻塞 IO 每处理一个socket的IO请求都会阻塞进程(线程),但使用难度较低。在并发量较低、业务逻辑只需要同步进行IO操作的场景下,阻塞 IO 已经满足了需求,并且不需要发起大量的select调用,开销上要比 IO多路复用低。
RPC 调用在大多数的情况下,是一个高并发调用的场景, 在 RPC框架的实现中,一般会选择 IO 多路复用的方式。存储分布式系统RPC 框架采用IO 多路复用模型。
RPC超时机制
在RPC中,由于涉及跨网络,而网络是会出现故障的,因此RPC执行可能会失败。由于我们实现的RPC是全异步方式,RPC请求在等待回应过程中,如果网络发生故障,或者对端软件故障,客户端将得不到响应,因此每个RPC需要一个超时时间。在业务规定的时间内如果没收到RPC回应,RPC框架需要通知业务层,因此RPC需要实现一套超时机制。一个较为简单的实现是RPC将所有的返回结果都放入一个集合中,并且通过一个定时任务,每隔一定时间间隔就扫描所有的异步等待状态的RPC,逐个判断是否超时。这样的实现方式虽然比较简单,但是存在一个问题就是会有很多无意义的遍历操作开销。比如一个RPC调用的超时时间是10秒,而设置的超时判定的定时任务是2秒执行一次,那么可能会有4次左右无意义的循环检测判断操作。
为了解决上述场景中的类似问题,我们引入了时间轮算法,减少无意义的轮询判断操作。
时间轮原理:

在时钟轮机制中,类似钟表秒针和分针的概念,对应有时间槽和时间轮。时间槽就相当于时钟的刻度;而时钟轮就相当于指针跳动的一个周期。可以将每个等待的RPC放到对应的时间槽位上。每次只需要遍历当前时间槽里的等待的RPC,这样可以节省大量的 CPU。
RPC和RDMA传输
在使用RDMA操作数据传输时,通常有使用双边操作传输和使用单双边操作结合传输两种方式,我们的RPC选择了更为灵活的单双边操作结合的方式。
使用双边操作(SEND/RECV)传输数据与传统Socket网络传输类似,发送端使用RDMA SEND发送数据,接收端使用RDMA RECV接收数据。但是在发送端发起RDMA SEND操作之前,接收端需要准备好接收数据的内存区并发起RDMA RECV操作,否则就会发送失败。因此双方需要约定一次传输最大的数据大小,一般在在创建RDMA连接时协商,接收端以该大小准备接收内存,发送端以该大小对大请求进行切分。使用双边RDMA SEND/RECV的限制在于当请求小于约定大小时存在接收端内存浪费的现象,而请求大于约定大小时需要发送端切分多次传输并在接收端重组。
在单双边结合的传输方式下,双边SEND/RECV多用于控制类消息传输,而实际数据则是通过单边READ/WRITE来完成。在实际场景中每次需要传输的数据大小不是固定的,所以发起单边操作前需要先协商好数据长度和相应的内存区信息。 其方式为先使用双边SEND/RECV操作把待传输数据的内存地址、大小、rkey等控制信息进行RPC Request请求,然后根据传输类型选择单边READ或WRITE操作完成实际数据的传输,最后使用双边SEND/RECV操作发送RPC Reply结果。
单双边结合传输的方式具有灵活适应各种大小请求的特点,尤其在传输大请求时具有明显优势,只需要一次单边操作即可将数据全部传输,同时单双边结合的方式也实现了应用Buffer到RDMA协议Buffer之间的数据零拷贝,进一步降低了开销和延迟。
通过RDMA双边传输RPC时发送的报文格式如下:
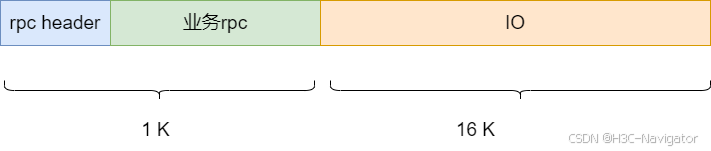
单边传输时则没有IO部分,IO部分通过RDMA单边传输。
总结与展望
RPC在分布式存储系统中价值与作用
RPC作为分布式存储软件系统中整个通信组件的最上层,起到承下启下的作用。对上层业务层呈现简单易用的通信接口。对下对接不同的网络传输层(TCP和RDMA网络)。存储分布式系统的各个组件可能运行在不同的节点上。RPC提供了一种有效的通信方式。RPC组件本身采用全异步,非阻塞IO方式,提高了系统处理的并发能力。在网络传输时,采用高效率的序列化和反序列化二进制协议机制,提高了传输效率。RPC在整个存储系统中扮演了重要的角色。
总结和未来展望
总的来说,RPC作为分布式存储系统的基础设施组件,持续发挥着关键作用,不断为存储系统的性能和可靠性提供坚实的基础。在未来,我们会对 RPC和RDMA网络结合的更加紧密,在可靠性和容错性方面持续改进,以更好地应对复杂多变的存储环境,实现更高效更安全的数据传输。