长视频分析模型 LongVU 论文内容总结与技术架构解析
LongVU 论文内容总结与技术架构解析
一、论文核心内容总结
LongVU 是一种面向长视频-语言理解的时空自适应压缩机制,旨在解决多模态大语言模型(MLLMs)处理长视频时受限于上下文长度的核心问题。其核心思路是通过「时间冗余去除+文本引导的空间压缩+帧间依赖的空间剪枝」三级压缩策略,在减少视频令牌数量的同时保留关键视觉细节,最终实现对小时级长视频的高效理解。
1. 核心挑战
-
令牌冗余问题:先进 MLLMs 单图需数百至数千令牌(如 LLaVA-OneVision 单图 7290 令牌),8k 上下文仅能处理 125 帧(2 分钟视频),而小时级视频需 20 万+令牌,远超模型承载能力。
-
现有方法缺陷:均匀采样丢失关键帧、密集采样超上下文长度、强压缩模块丢失视觉信息。
二、模型架构介绍
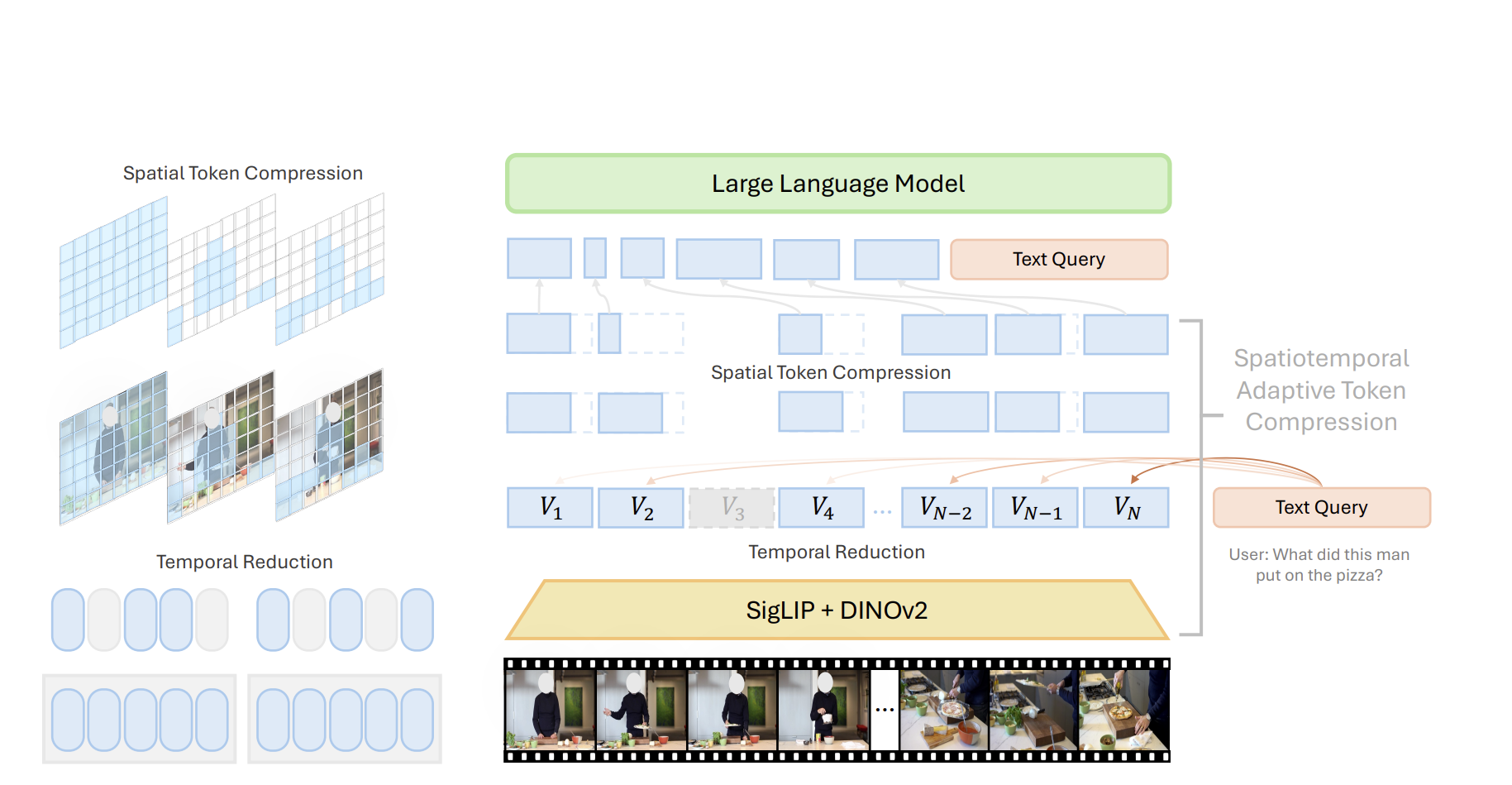
(1)时间冗余去除(Temporal Reduction)
-
核心逻辑:利用 DINOv2 自监督特征的帧间相似度,去除冗余帧,将原始 N 帧压缩至 T 帧(约减少 50%)。
-
实现细节:
-
1fps 采样视频帧,用 DINOv2 提取每帧特征 (Vdinoi)(V_{\text{dino}}^i)(Vdinoi);
-
按非重叠窗口(J=8 帧)计算帧平均相似度
(simi=1J−1∑j≠isim(Vdinoi,Vdinoj))(sim^i = \frac{1}{J-1}\sum_{j≠i}sim(V_{\text{dino}}^i, V_{\text{dino}}^j))(simi=J−11∑j=isim(Vdinoi,Vdinoj));
过滤相似度高于阈值的帧,保留 T 帧(约 45.9% 原始帧)。
- 公式参数与代码变量的对应表
公式参数 代码变量 / 操作 含义说明 simisim^isimi similarities[i]第 i 帧与窗口内其他所有帧的平均相似度(值越高,帧越冗余) Jwindow_size(如 16)或len(segment)窗口内的总帧数(即参与相似度计算的帧数量) j≠i工程简化(包含 j=i 但影响极小) 因 J 较大(如 16), 1/J与1/(J-1)差异可忽略,直接用均值替代sim(·,·)query_feature @ query_feature.T点积相似度(因特征已归一化,等价于余弦相似度) VdinoiV_{\text{dino}}^iVdinoi query_feature[i]第 i 帧经 DINO 提取并归一化的特征向量(维度为 C×H×W,展平后的值) (2)文本引导的空间压缩(Selective Feature Reduction)
-
-
核心逻辑:基于文本查询与帧特征的跨模态注意力,选择(Nh)(N_h)(Nh) 帧保留高分辨率((H_h×W_h),其余帧空间池化至低分辨率((H_l×W_l))。
-
关键公式:
-
保留高分辨率帧数:
(Nh=max(0,Lmax−Lq−T⋅HlWlHhWh−HlWl))(N_h = \max\left(0, \frac{L_{\text{max}} - L_q - T·H_lW_l}{H_hW_h - H_lW_l}\right))(Nh=max(0,HhWh−HlWlLmax−Lq−T⋅HlWl))
- (Lmax)(L_{\text{max}})(Lmax):模型最大上下文长度,(L_q):文本查询长度,T:时间压缩后帧数;
- (Hh×Wh):高分辨率令牌数(如12×12=144),(H_h×W_h):高分辨率令牌数(如 12×12=144),(Hh×Wh):高分辨率令牌数(如12×12=144),(H_l×W_l)$:低分辨率令牌数(如 8×8=64)。
-
帧选择依据:(TopNh(1HhWhLq∑h,w,lF(V)QT))(\text{Top}_{N_h}\left(\frac{1}{H_hW_hL_q}\sum_{h,w,l}\mathcal{F}(V)Q^T\right))(TopNh(HhWhLq1∑h,w,lF(V)QT))
- (F(⋅))(\mathcal{F}(·))(F(⋅)):MLP 多模态适配器(对齐视觉特征与 LLM 空间),Q:文本查询的 LLM 嵌入;
- 选择注意力分数最高的 (N_h) 帧保留高分辨率,其余帧用双线性插值池化至低分辨率。
公式分为 “帧选择规则”(左侧)和 “保留帧数计算”(右侧)两部分,需结合理解
(一)、保留高分辨率帧的数量 (N_h) 计算
1. 公式展开与参数定义
公式参数 定义与物理意义 LongVU 项目中的来源 (N_h) 最终输出:可保留的高分辨率帧数量(整数,≥0),即需计算的目标值。 代码中对应 highres_num,决定将多少帧从低分辨率升级为高分辨率。(L_{\text{max}}) 模型最大上下文长度(固定值,如 8192),即文本 + 视觉 token 总长度不能超过该值。 从模型配置 self.get_model().config.tokenizer_model_max_length获取。(L_q) 文本查询长度( text query length),即输入文本的 token 数。代码中通过 sum([x.shape[0] for x in cur_input_embeds_no_im])计算(文本嵌入的总长度)。T 视频总帧数(即当前处理的视频包含的帧数量)。 从 frame_split_sizes[cur_image_idx]获取(批量处理中单个视频的帧拆分尺寸)。(H_lW_l) 单帧低分辨率视觉 token 数(如 4×4=16),即低分辨率帧编码后的 token 数量。 代码中通过 split_image_features_unpadded[cur_image_idx].shape[0] // T计算(低分辨率特征总长度 ÷ 帧数)。(H_hW_h) 单帧高分辨率视觉 token 数(如 8×8=64),即高分辨率帧编码后的 token 数量。 代码中通过 visual_emb.shape[0] // T计算(高分辨率特征总长度 ÷ 帧数),或直接从配置self.get_model().config.image_token_len获取。2. 计算逻辑拆解
-
公式推导与意义拆解
- 分子:剩余可分配的视觉 token 空间(L_{\text{max}} - L_q - T·H_lW_l)
- 含义:模型总上下文长度((L_{\text{max}}))扣除文本长度((L_q))和 “全低分辨率视觉” 的总 token 数((T·H_lW_l))后,剩余的可用于 “升级高分辨率” 的 token 空间。
- 若分子 ≤0:说明即使全用低分辨率,视觉 token 已超限,此时 (N_h=0)(不升级任何帧)。
- 分母:每帧升级高分辨率增加的 token 数(H_hW_h - H_lW_l)
- 含义:单帧从低分辨率升级为高分辨率时,额外增加的 token 数(如 64-16=48)。
- 整体含义分子 ÷ 分母 = 最多可升级为高分辨率的帧数((N_h)),再用
max(0, ·)确保结果非负(避免无剩余空间时出现负数)。
例:若 (L_{\text{max}}=8192),(L_q=512),(T=10),(H_lW_l=16),(H_hW_h=64)
分子 = 8192 - 512 - 10×16 = 7520
分母 = 64 - 16 = 48
(N_h = 7520 ÷ 48 ≈ 156)
(二)部分 1:基于跨模态注意力的帧选择规则
1. 公式展开与参数定义
公式参数 定义与物理意义 LongVU 项目中的对应实现 (\mathcal{F}(·)) MLP 多模态适配器,作用是将视觉特征从原始空间(如 DINO 输出)对齐到 LLM 特征空间(确保视觉与文本特征维度一致,可计算相似度)。 代码中对应 visual_emb(注释明确其为 “经过 MLP 适配器的视觉特征”),维度为[T×Hh×Wh, Dq](Dq 是 LLM 文本特征维度)。V 原始视觉特征(如 DINO 提取的高分辨率帧特征),未经跨模态对齐。 对应输入到 MLP 适配器的原始视觉特征(代码中未直接显示, visual_emb是其经 (\mathcal{F}(·)) 处理的结果)。Q 文本查询的 LLM 嵌入(Query),维度为 [Lq, Dq](Lq 是文本长度,Dq 是特征维度)。代码中对应 text_emb,通过 LLM 对输入文本编码得到(如 Qwen2 的文本嵌入)。(H_hW_h) 单帧高分辨率视觉 token 数(如 8×8=64),即每帧高分辨率特征包含的 token 数量。 代码中通过 visual_emb.reshape(T, -1, Dq)中的-1得到(每帧的 token 数)。(L_q) 文本查询的长度(token 数),即 Q 的序列长度。 对应 text_emb.shape[0](文本嵌入的第一维是长度)。(\sum_{h,w,l}) 对视觉特征的空间维度((h,w),对应高分辨率 token 的空间位置)和文本的序列维度(l,对应文本 token 位置)求和。 代码中通过矩阵乘法 torch.matmul(visual_emb, text_emb.transpose(0,1))实现(内积等价于求和)。(\frac{1}{H_hW_hL_q}) 归一化系数:对三重求和结果取平均,得到 “视觉帧与文本的平均关联度”(消除维度对数值的影响)。 代码中通过两次 .mean(dim=-1)实现(分别对文本维度和视觉 token 维度取平均)。(\text{Top}_{N_h}(·)) 选择分数最高的 (N_h) 个结果,即保留与文本关联度最高的 (N_h) 帧为高分辨率。 代码中通过 torch.topk(sim_frame, highres_num)实现(highres_num即 (N_h))。2. 计算逻辑拆解(以单帧为例)
LongVU 中 “高分辨率帧选择” 的核心矛盾是:有限的 token 资源应优先分配给 “对文本理解最关键的帧”。公式通过以下逻辑解决这一矛盾:
- 计算跨模态关联度:通过 (\mathcal{F}(V)Q^T) 计算视觉特征(经对齐)与文本特征的内积,量化 “视觉 token 与文本 token 的匹配程度”(值越高,关联越紧密)。
- 归一化消除维度影响:除以 (H_hW_hL_q) 得到平均关联度(避免 “长文本” 或 “多视觉 token” 导致分数偏高)。
- 选择关键帧:取 Top (N_h) 的帧保留高分辨率 —— 这些帧与文本关联最紧密,保留细节能最大程度提升模型对 “文本 - 视觉” 对应关系的理解。
- 矩阵乘法等对所有视觉 token((h,w) 维度)和文本 token(l 维度)的内积求和,即公式中的 (\sum_{h,w,l} \mathcal{F}(V)Q^T)。
-
(3)帧间依赖的空间剪枝(Spatial Token Compression, STC)
- 核心逻辑:若低分辨率令牌仍超上下文长度((T⋅HlWl≥Lmax))((T·H_lW_l ≥ L_{\text{max}}))((T⋅HlWl≥Lmax)),基于帧间空间令牌相似度剪枝冗余令牌。
- 实现细节:
- 滑动窗口划分帧序列(窗口大小 K=8,非重叠),保留窗口第一帧完整令牌;
- 计算后续帧与第一帧同位置令牌的余弦相似度,剪枝相似度>阈值(θ=0.8)的令牌:(vi∗(h,w)={vi(h,w)if sim(v1(h,w),vi(h,w))≤θ∅otherwise)(v_i^*(h,w) = \begin{cases} v_i(h,w) & \text{if } sim(v_1(h,w), v_i(h,w)) ≤ θ \\∅ & \text{otherwise}\end{cases})(vi∗(h,w)={vi(h,w)∅if sim(v1(h,w),vi(h,w))≤θotherwise)
- 令牌减少率约 40.4%,最终平均每帧令牌数降至 2 个,8k 上下文可承载小时级视频。
3. 模型架构:多模态融合与 LLM 适配
- 视觉编码器:融合 DINOv2(低阶视觉细节)与 SigLIP(语言对齐语义)特征,通过空间视觉聚合器(SVA)融合为统一特征 V;
- 语言 backbone:Qwen2-7B / Llama3.2-3B,适配多模态输入;
- 跨模态交互:通过可学习查询的交叉注意力,将视觉特征映射至 LLM 嵌入空间,实现视觉 - 语言融合。
4.模型架构详解
LongVU 由 视觉编码器、特征融合模块和语言模型三部分组成,结合 DINOv2 和 SigLIP 的优势:
1. 视觉编码器双分支
-
DINOv2(视觉中心特征):
- 通过自监督学习捕获低层视觉特征(如纹理、边缘)和帧间细微差异。
- 用于时间压缩:计算帧间相似度,剔除冗余帧(平均保留率 54.1%)。
-
SigLIP(语言对齐特征):
- 基于对比学习对齐图像-文本语义空间,擅长高层语义理解。
- 用于提取剩余帧的空间特征(分辨率 384×384 → 24×24 token)。
2. 特征融合:Spatial Vision Aggregator (SVA)
- 输入:DINOv2 和 SigLIP 的特征序列。
- 过程:通过可学习查询动态聚合双编码器特征,生成统一表示。
- 输出:融合特征 V∈RT×(Hh×Wh)×Dv(T=帧数,Hh×Wh=空间 token 数)。
3. 语言模型:Qwen-7B
- 作为推理 backbone,处理压缩后的视频 token 序列。
- 支持 8K 上下文长度,适配长视频输入。
4.数据处理流程与阶段变化
阶段 1: 时间压缩(Temporal Reduction)
-
输入:1fps 采样的视频帧序列 {I1,…,IN}。
-
DINOv2 特征提取:
- 每帧提取特征 Vdinoi,计算窗口内(J=16 帧)平均相似度:
simi=J−11∑j=isim(Vdinoi,Vdinoj)
-
帧剔除:保留相似度低的帧(约剔除 46% 冗余帧)。
-
输出:关键帧序列 {I1,…,IT}(T≈0.54N)。
阶段 2: 空间自适应压缩
-
SigLIP 特征提取:对剩余帧提取特征 {Vsig1,…,VsigT}。
-
SVA 融合:生成统一特征 V={V1,…,VT}。
-
跨模态查询选择:
- 文本查询 Q(LLM 嵌入)与帧特征计算注意力得分:
$Score=HhWhLq1∑h,w,lF(V)QTScore=HhWhLq1∑h,w,lF(V)QTScore=HhWhLq1∑h,w,lF(V)QT - 选择得分最高的 Nh 帧保留全分辨率(144 token/帧),其余降至 64 token/帧。
- Nh 动态计算:
$Nh=max(0,HhWh−HlWlLmax−Lq−THlWl)Nh=max(0,HhWh−HlWlLmax−Lq−THlWl)Nh=max(0,HhWh−HlWlLmax−Lq−THlWl)
阶段 3: 空间 Token 压缩(STC)
-
条件:若 token 总数仍超上下文长度 Lmax。
-
过程:
- 分窗口处理(大小 K=8 帧)。
- 首帧保留全 token,后续帧 token 与首帧逐位置计算余弦相似度。
- 剪枝相似度 >θ(θ=0.8)的 token,保留差异区域。
-
效果:平均减少 40.4% token,聚焦动态内容。
阶段 4: LLM 推理
- 压缩后 token 序列输入 Qwen-7B,生成视频理解结果(问答、描述等)。
性能优势
- 长视频理解:
- VideoMME-Long(1小时视频)准确率 59.5%,超越 LLaVA-OneVision 12.8%。
- MLVU(2小时视频)准确率 65.4%,SOTA。
- 轻量化适配:
- 基于 Llama3.2-3B 的小模型在 VideoMME-Long 上超越 Phi-3.5V 3.4%。
- 效率:
- 1fps 采样 + 自适应压缩 → 处理 1 小时视频仅需 8K 上下文。
文档核心内容总结
LongVU 是一种针对长视频理解(Long Video-Language Understanding)的时空自适应压缩框架,旨在解决多模态大语言模型(MLLMs)处理长视频时因上下文长度限制导致的视觉细节丢失问题。其核心创新是通过跨模态查询和帧间依赖关系自适应压缩视频的时空冗余,在保留关键视觉信息的同时大幅减少 token 数量。
三、数据处理流程
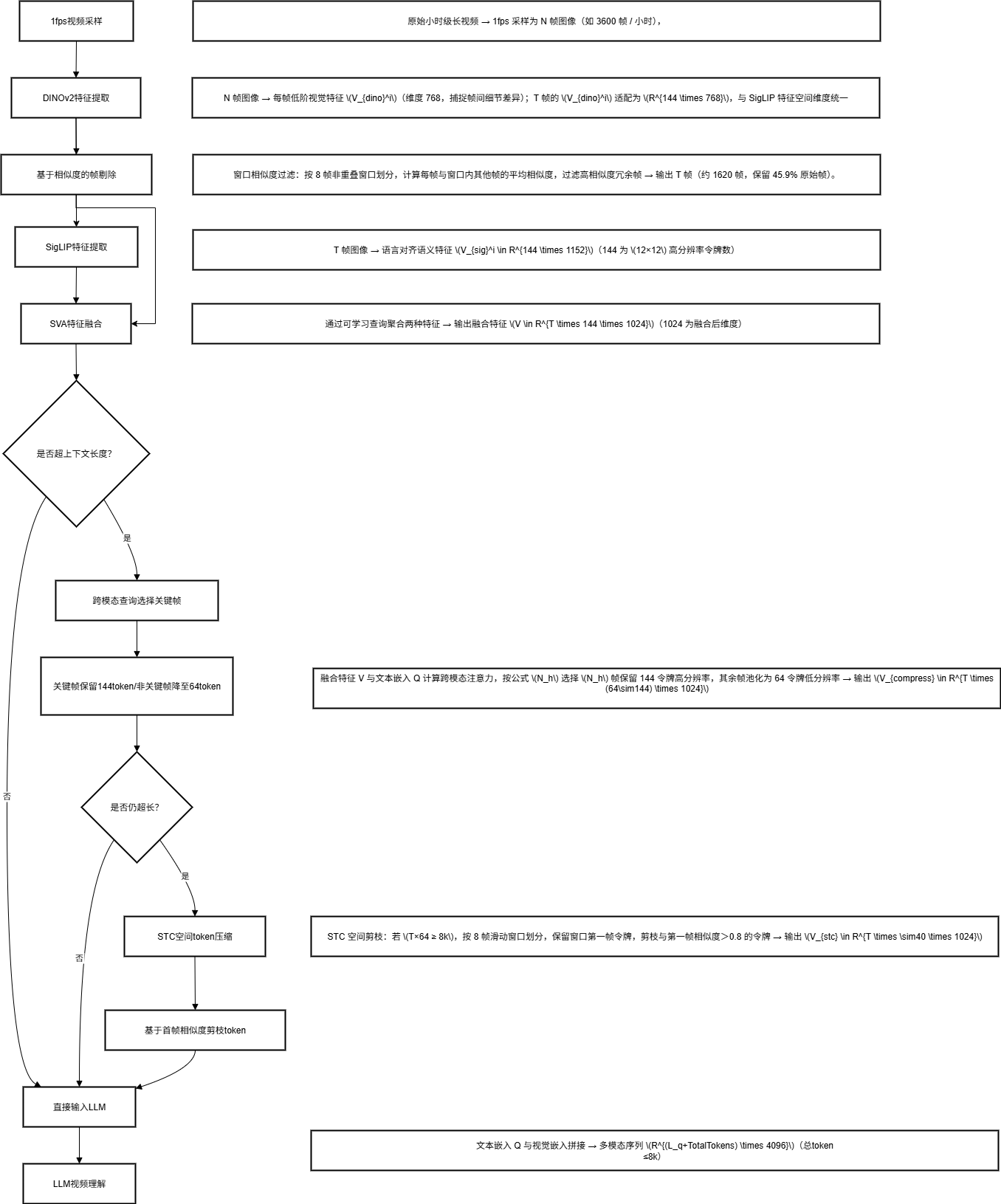
第一层:输入层
- 视频输入:原始小时级长视频 → 1fps 采样为 N 帧图像(如 3600 帧 / 小时);
- 文本输入:用户文本查询(如 “描述视频中人物动作”)→ 经 Qwen 文本编码器生成文本嵌入$ (Q \in R^{L_q \times D_q})$((L_q) 为文本长度,(D_q=4096) 为 Qwen 嵌入维度)。
第二层:时间冗余去除模块(DINOv2 核心)
- DINOv2 编码:N 帧图像 → 每帧低阶视觉特征$ (V_{dino}^i)$(维度 768,捕捉帧间细节差异);
- 窗口相似度过滤:按 8 帧非重叠窗口划分,计算每帧与窗口内其他帧的平均相似度,过滤高相似度冗余帧 → 输出 T 帧(约 1620 帧,保留 45.9% 原始帧)。
第三层:视觉特征融合模块(DINOv2 + SigLIP + SVA)
- SigLIP 编码:T 帧图像 → 语言对齐语义特征 (Vsigi∈R144×1152)(V_{sig}^i \in R^{144 \times 1152})(Vsigi∈R144×1152)(144 为 (12×12) 高分辨率令牌数);
- DINOv2 特征适配:T 帧的 (V_{dino}^i) 适配为 (R144×768)(R^{144 \times 768})(R144×768),与 SigLIP 特征空间维度统一;
- SVA 聚合:通过可学习查询聚合两种特征 → 输出融合特征 (V∈RT×144×1024)(V \in R^{T \times 144 \times 1024})(V∈RT×144×1024)(1024 为融合后维度)。
第四层:时空压缩模块(文本引导 + STC)
- 文本引导空间压缩:融合特征 V 与文本嵌入 Q 计算跨模态注意力,按公式 (N_h) 选择 (N_h) 帧保留 144 令牌高分辨率,其余帧池化为 64 令牌低分辨率 → 输出 (Vcompress∈RT×(64∼144)×1024)(V_{compress} \in R^{T \times (64\sim144) \times 1024})(Vcompress∈RT×(64∼144)×1024);
- STC 空间剪枝:若 (T×64 ≥ 8k),按 8 帧滑动窗口划分,保留窗口第一帧令牌,剪枝与第一帧相似度>0.8 的令牌 → 输出 (Vstc∈RT×∼40×1024)(V_{stc} \in R^{T \times \sim40 \times 1024})(Vstc∈RT×∼40×1024)。
第五层:多模态大模型 Qwen 推理
- 特征投影:(V_{stc}) 经投影层对齐至 Qwen 嵌入空间 (RTotalTokens×4096)(R^{TotalTokens \times 4096})(RTotalTokens×4096);
- 序列拼接:文本嵌入 Q 与视觉嵌入拼接 → 多模态序列 (R(Lq+TotalTokens)×4096)(R^{(L_q+TotalTokens) \times 4096})(R(Lq+TotalTokens)×4096)(总令牌≤8k);
- Qwen 解码:自回归生成长视频理解结果(如问答、描述、动作计数)。
2. 数据处理流程拆解(阶段 + 变化)
| 阶段 | 处理步骤 | 输入数据 | 输出数据 | 核心变化 |
|---|---|---|---|---|
| 1. 时间压缩 | 1fps 采样 → DINOv2 编码 → 相似度过滤 | 原始长视频 | T 帧图像(1620 帧 / 小时) | 帧数量:3600→1620(减少 50%),无空间令牌 → 无令牌(仅图像) |
| 2. 特征融合 | SigLIP 编码 → DINOv2 适配 → SVA 聚合 | T 帧图像 | 融合特征 (T×144×1024) | 图像 → 带空间令牌的特征(144 令牌 / 帧),维度从 768/1152→1024 |
| 3. 文本引导压缩 | 跨模态注意力 → N_h 计算 → 分辨率调整 | 融合特征 (T×144×1024) + 文本嵌入 | 压缩特征 (T×(64~144)×1024) | 令牌数:144→64~144 / 帧,总令牌减少 25% |
| 4. STC 剪枝 | 滑动窗口划分 → 相似度计算 → 令牌剪枝 | 压缩特征 (T×(64~144)×1024) | 剪枝特征 (T×~40×1024) | 令牌数:64144→40 / 帧,减少 40.4% |
| 5. 多模态推理 | 特征投影 → 序列拼接 → Qwen 解码 | 剪枝特征 (T×~40×1024) + 文本嵌入 | 长视频理解结果 | 视觉特征维度 1024→4096(对齐 Qwen),总令牌≤8k |
四、核心组件作用总结
| 组件 | 输入 | 输出 | 核心作用 |
|---|---|---|---|
| DINOv2 编码器 | 单帧图像 | (D_dino,) 特征 | 提取帧间相似度高的自监督特征,用于时间去冗余 |
| SigLIP 编码器 | 单帧图像 | (H_hW_h, D_sig) 特征 | 提取语言对齐的语义特征,用于跨模态交互 |
| SVA(空间聚合器) | DINOv2 + SigLIP 特征 | (H_hW_h, D_v) 融合特征 | 可学习查询聚合多源视觉特征,统一维度 |
| 跨模态注意力模块 | 融合特征 + 文本嵌入 | N_h 帧索引 | 选择高相关帧保留高分辨率,减少空间令牌 |
| STC(空间剪枝模块 | 低分辨率特征 | 剪枝后特征 | 基于帧间令牌相似度,进一步减少冗余令牌 |
| Qwen 大模型 | 文本 + 视觉序列 | 理解结果 | 处理多模态输入,输出长视频问答/描述 |