LinuxC++项目开发日志——基于正倒排索引的boost搜索引擎(5——通过cpp-httplib库建立网页模块)
基于正倒排索引的boost搜索引擎
- cpp-httplib库
- cpp-httplib 库介绍
- 常用功能与函数
- 1. 服务器相关
- 2. 客户端相关
- 下载与使用
- 下载路径
- 使用方法
- 简单示例
- 网页模块
- 仿照其它成熟搜索页面
- 编写主程序入口
- 编写网页
- 完整代码
- common.h
- Index.hpp
- Log.hpp
- main.cc
- makefile
- Parser.cc
- Parser.h
- Search.hpp
- Util.hpp
- 结果展示
cpp-httplib库
cpp-httplib 库介绍
cpp-httplib 是一个轻量级的 C++ HTTP 客户端 / 服务器库,由日本开发者 yhirose 开发。它的特点是:
- 单文件设计(仅需包含 httplib.h 即可使用)
- 支持 HTTP 1.1
- 同时提供客户端和服务器功能
- 跨平台(Windows、Linux、macOS 等)
- 无需额外依赖(仅需 C++11 及以上标准)
- 支持 SSL/TLS(需配合 OpenSSL)
常用功能与函数
1. 服务器相关
创建服务器
httplib::Server svr;
注册路由处理函数
// GET 请求处理
svr.Get("/hello", [](const httplib::Request& req, httplib::Response& res) {res.set_content("Hello World!", "text/plain");
});// POST 请求处理
svr.Post("/submit", [](const httplib::Request& req, httplib::Response& res) {// 处理表单数据 req.bodyres.set_content("Received!", "text/plain");
});
启动服务器
// 监听 0.0.0.0:8080
if (svr.listen("0.0.0.0", 8080)) {// 服务器启动成功
}
Request 类主要成员
- method: 请求方法(GET/POST 等)
- path: 请求路径
- body: 请求体内容
- headers: 请求头集合
- params: URL 查询参数
- get_param(key): 获取查询参数
Response 类主要成员
- status: 状态码(200, 404 等)
- body: 响应体内容
- headers: 响应头集合
- set_content(content, content_type): 设置响应内容和类型
- set_header(name, value): 设置响应头
2. 客户端相关
创建客户端
httplib::Client cli("http://example.com");
发送 GET 请求
auto res = cli.Get("/api/data");
if (res && res->status == 200) {// 处理响应 res->body
}
发送 POST 请求
httplib::Params params;
params.emplace("name", "test");
params.emplace("value", "123");auto res = cli.Post("/api/submit", params);
发送带请求体的 POST
std::string json_data = R"({"key": "value"})";
auto res = cli.Post("/api/json", json_data, "application/json");
下载与使用
下载路径
GitHub 仓库:https://github.com/yhirose/cpp-httplib
直接下载头文件:https://raw.githubusercontent.com/yhirose/cpp-httplib/master/httplib.h
使用方法
1.下载 httplib.h 文件
2.在项目中包含该文件:#include “httplib.h”
3.编译时需指定 C++11 及以上标准(如 g++ -std=c++11 main.cpp)
4.若使用 SSL 功能,需定义 CPPHTTPLIB_OPENSSL_SUPPORT 并链接 OpenSSL 库
5.编译器版本低可能会报错,升级一下编译器即可
简单示例
下面是一个完整的服务器示例:
#include "httplib.h"
#include <iostream>int main() {httplib::Server svr;// 处理根路径请求svr.Get("/", [](const httplib::Request& req, httplib::Response& res) {res.set_content("<h1>Hello World!</h1>", "text/html");});// 处理带参数的请求svr.Get("/greet", [](const httplib::Request& req, httplib::Response& res) {auto name = req.get_param_value("name");if (name.empty()) {res.status = 400;res.set_content("Name parameter is required", "text/plain");} else {res.set_content("Hello, " + name + "!", "text/plain");}});std::cout << "Server running on http://localhost:8080" << std::endl;svr.listen("localhost", 8080);return 0;
}
这个库非常适合快速开发小型 HTTP 服务或客户端,由于其轻量性和易用性,在 C++ 社区中非常受欢迎。
网页模块
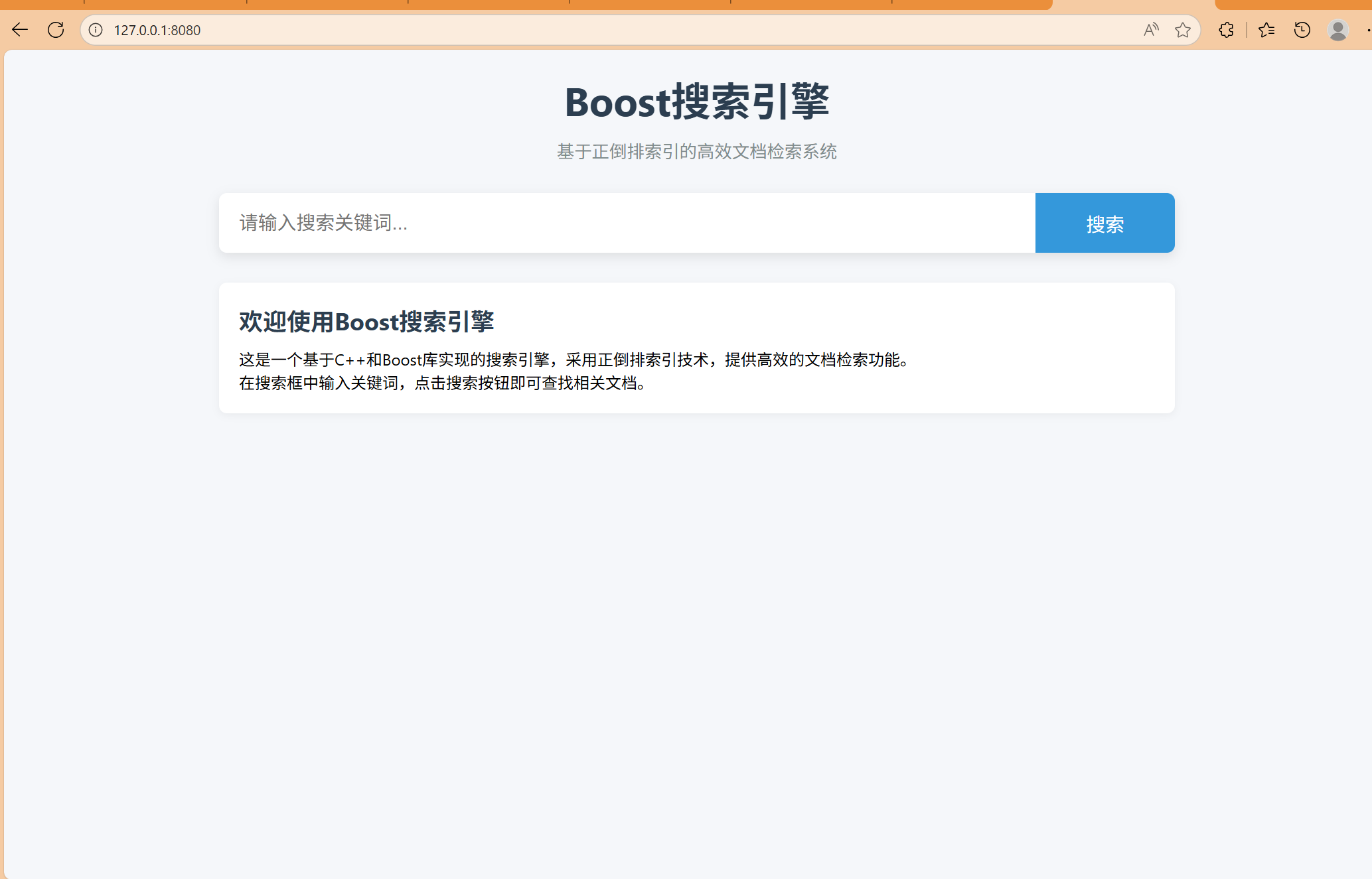
仿照其它成熟搜索页面
这是一个大公司建立的成熟的搜索页面,我们写的可以仿照着来。

经过搜索之后,网页地址上会带上搜索的关键词,从而到数据库内部或者其它建立好的搜索模块中查找,在通过网页映射出来。
编写主程序入口
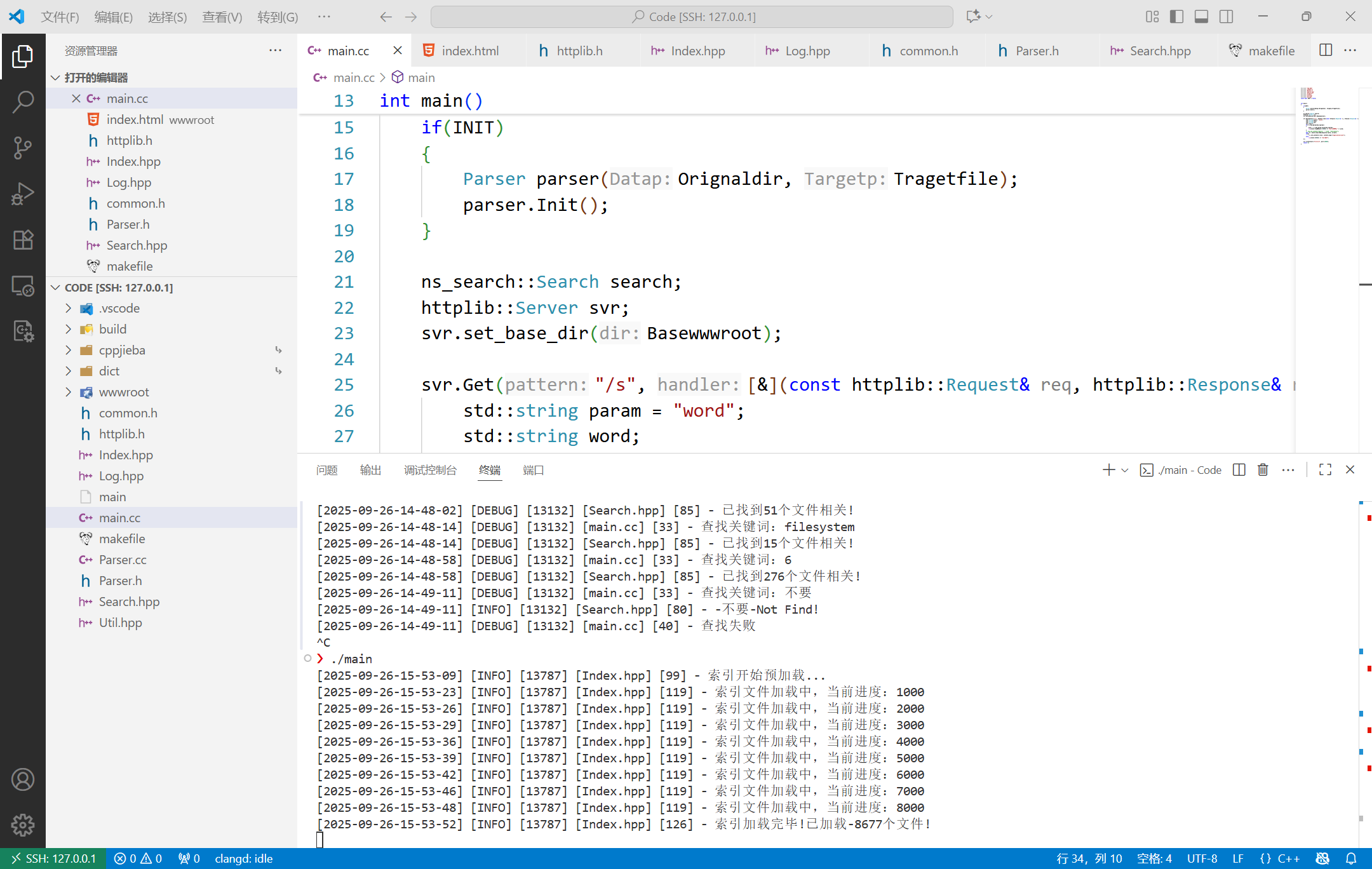
当外部通过网页访问建立好的端口的时候,搜索模块会初始化一次,文档是已经建立好的,先绑定主网页html的路径,然后注册Get方法,网页访问/s的时候实用?word=来带参数,从而出发搜索模块的查找,然后把结果json串返回给浏览器。启动后绑定host和端口号,则开始运行。
#include "Log.hpp"
#include "common.h"
#include "Parser.h"
#include "Search.hpp"
#include "httplib.h"
#include <cstdio>
#include <cstring>
#include <string>
const bool INIT = false;int main()
{if(INIT){Parser parser(Orignaldir, Tragetfile);parser.Init();}ns_search::Search search;httplib::Server svr;svr.set_base_dir(Basewwwroot);svr.Get("/s", [&](const httplib::Request& req, httplib::Response& rep){std::string param = "word";std::string word;std::string out;out.clear();if(req.has_param(param)){word = req.get_param_value(param);Log(LogModule::DEBUG) << "查找关键词:" << word;}// rep.set_content("Search: " + word, "text/plain");bool b = search.SearchBy(word, out);if(b)rep.set_content(out, "application/json");elseLog(DEBUG) << "查找失败";});svr.listen("0.0.0.0", 8080);return 0;
}编写网页
编写网页是从一个大概的框架开始先写主要部分,再用css美化,然后注册相关函数。
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Boost搜索引擎</title><script src="https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js"></script><style>* {margin: 0;padding: 0;box-sizing: border-box;}html, body {height: 100%;font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;background-color: #f5f7fa;}.container {max-width: 1000px;margin: 0 auto;padding: 20px;}.header {text-align: center;margin-bottom: 30px;}.header h1 {color: #2c3e50;font-size: 2.5rem;margin-bottom: 10px;}.header p {color: #7f8c8d;font-size: 1.1rem;}.search-box {display: flex;margin-bottom: 30px;box-shadow: 0 4px 12px rgba(0, 0, 0, 0.1);border-radius: 8px;overflow: hidden;}.search-box input {flex: 1;height: 60px;padding: 0 20px;border: none;font-size: 1.2rem;background-color: white;}.search-box input:focus {outline: none;background-color: #f8f9fa;}.search-box button {width: 140px;height: 60px;border: none;background-color: #3498db;color: white;font-size: 1.2rem;cursor: pointer;transition: background-color 0.3s;}.search-box button:hover {background-color: #2980b9;}.intro {background-color: white;padding: 20px;border-radius: 8px;margin-bottom: 20px;box-shadow: 0 2px 8px rgba(0, 0, 0, 0.05);}.intro h2 {color: #2c3e50;margin-bottom: 10px;}.results-container {display: none; /* 初始隐藏,有结果时显示 */}.result-item {background-color: white;padding: 20px;border-radius: 8px;margin-bottom: 15px;box-shadow: 0 2px 8px rgba(0, 0, 0, 0.05);transition: transform 0.2s, box-shadow 0.2s;}.result-item:hover {transform: translateY(-2px);box-shadow: 0 4px 12px rgba(0, 0, 0, 0.1);}.result-title {font-size: 1.3rem;color: #3498db;margin-bottom: 10px;text-decoration: none;display: block;}.result-title:hover {text-decoration: underline;}.result-desc {color: #5a6c7d;line-height: 1.5;margin-bottom: 10px;}.result-url {color: #95a5a6;font-size: 0.9rem;font-style: italic;}.no-results {text-align: center;padding: 40px;color: #7f8c8d;background-color: white;border-radius: 8px;box-shadow: 0 2px 8px rgba(0, 0, 0, 0.05);}.loading {text-align: center;padding: 30px;color: #3498db;}.footer {text-align: center;margin-top: 40px;color: #95a5a6;font-size: 0.9rem;}@media (max-width: 600px) {.container {padding: 10px;}.search-box {flex-direction: column;}.search-box input {height: 50px;border-radius: 8px 8px 0 0;}.search-box button {width: 100%;height: 50px;border-radius: 0 0 8px 8px;}}</style>
</head>
<body><div class="container"><div class="header"><h1>Boost搜索引擎</h1><p>基于正倒排索引的高效文档检索系统</p></div><div class="search-box"><input type="text" id="search-input" placeholder="请输入搜索关键词..."><button id="search-btn">搜索</button></div><div class="intro" id="intro"><h2>欢迎使用Boost搜索引擎</h2><p>这是一个基于C++和Boost库实现的搜索引擎,采用正倒排索引技术,提供高效的文档检索功能。</p><p>在搜索框中输入关键词,点击搜索按钮即可查找相关文档。</p></div><div class="results-container" id="results-container"><!-- 搜索结果将在这里动态生成 --></div></div><script>$(document).ready(function() {// 绑定搜索按钮点击事件$('#search-btn').click(performSearch);// 绑定输入框回车键事件$('#search-input').keypress(function(e) {if (e.which === 13) {performSearch();}});// 初始显示介绍内容$('#intro').show();});function performSearch() {const searchInput = $('#search-input');const keywords = searchInput.val().trim();if (!keywords) {alert('请输入搜索关键词');return;}// 隐藏介绍内容$('#intro').hide();// 显示结果容器和加载提示const resultsContainer = $('#results-container');resultsContainer.show().html('<div class="loading">搜索中,请稍候...</div>');// 发送搜索请求$.ajax({url: "/s?word=" + encodeURIComponent(keywords),type: "GET",dataType: "json",success: function(data) {buildResults(data);},error: function(xhr) {console.log("error", xhr.status);resultsContainer.html('<div class="no-results">搜索失败,请稍后重试</div>');}});}function buildResults(data) {const resultsContainer = $('#results-container');// 清空之前的结果resultsContainer.empty();if (!data || data.length === 0) {resultsContainer.html('<div class="no-results">未找到相关结果,请尝试其他关键词</div>');return;}// 构建结果列表data.forEach(function(item, index) {const resultItem = $('<div>', { class: 'result-item' });const title = $('<a>', {class: 'result-title',href: item.url || '#',text: item.title || '无标题',target: '_blank'});const desc = $('<div>', {class: 'result-desc',text: item.desc || '无描述信息'});const url = $('<div>', {class: 'result-url',text: item.url || '无URL信息'});resultItem.append(title).append(desc).append(url);resultsContainer.append(resultItem);});}</script>
</body>
</html>
完整代码
common.h
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <cstddef>
#include "Log.hpp"
using std::cout;
using std::endl;
using namespace LogModule;const std::string Boost_Url_Head = "https://www.boost.org/doc/libs/1_89_0/doc/html";
// const std::string Boost_Url_Head = "../Data/html";
const std::string Basewwwroot = "./wwwroot";
const std::string Orignaldir = "../Data/html";
const std::string Tragetfile = "../Data/output.txt";const std::string Output_sep = "\3";
const std::string Line_sep = "\n";// 定义词典路径(根据实际路径修改)
const std::string DICT_PATH = "dict/jieba.dict.utf8";
const std::string HMM_PATH = "dict/hmm_model.utf8";
const std::string USER_DICT_PATH = "dict/user.dict.utf8";
const std::string IDF_PATH = "dict/idf.utf8";
const std::string STOP_WORD_PATH = "dict/stop_words.utf8";// 不可复制基类
class NonCopyable {
protected:// 允许派生类构造和析构NonCopyable() = default;~NonCopyable() = default;// 禁止移动操作(可选,根据需求决定)// NonCopyable(NonCopyable&&) = delete;// NonCopyable& operator=(NonCopyable&&) = delete;private:// 禁止拷贝构造和拷贝赋值NonCopyable(const NonCopyable&) = delete;NonCopyable& operator=(const NonCopyable&) = delete;
};Index.hpp
#pragma once
#include "Log.hpp"
#include "Util.hpp"
#include "common.h"
#include <boost/algorithm/string/case_conv.hpp>
#include <cstddef>
#include <cstring>
#include <fstream>
#include <string>
#include <unistd.h>
#include <unordered_map>
#include <utility>
#include <vector>namespace ns_index
{//正排索引typedef struct ForwordElem{std::string title_;std::string content_;std::string url_;size_t doc_id_ = 0;void Set(std::string title, std::string content, std::string url, size_t doc_id){title_ = title;content_ = content;url_ = url;doc_id_ = doc_id;}}Forword_t;typedef struct InvertedElem{size_t doc_id_ = 0;std::string word_;size_t weight_ = 0;void Set(size_t doc_id, std::string word, size_t weight){doc_id_ = doc_id;word_ = word;weight_ = weight;}}Inverted_t;typedef std::vector<Inverted_t> InvertedList;class Index : public NonCopyable{private:Index() = default;public:static Index* GetInstance(){static Index index;return &index;}public:Forword_t* QueryById(size_t id){if(id < 0 || id >= Forword_Index_.size()){Log(LogModule::DEBUG) << "id invalid!";return nullptr;}return &Forword_Index_[id];}InvertedList* QueryByWord(std::string word){auto it = Inverted_Index_.find(word);if(it == Inverted_Index_.end()){//Log(LogModule::DEBUG) << word << " find fail!";return nullptr;}return &it->second;}size_t count = 0;bool BulidIndex(){if(isInit_)return false;size_t estimated_doc = 10000;size_t estimeted_words = 100000;Forword_Index_.reserve(estimated_doc);Inverted_Index_.reserve(estimeted_words);std::ifstream in(Tragetfile, std::ios::binary | std::ios::in);if(!in.is_open()){Log(LogModule::ERROR) << "Targetfile open fail!BulidIndex fail!";return false;}Log(LogModule::INFO) << "索引开始预加载...";std::string singlefile;while (std::getline(in, singlefile)){bool b = BuildForwordIndex(singlefile);if(!b){Log(LogModule::DEBUG) << "Build Forword Index Error!";continue;}b = BuildInvertedIndex(Forword_Index_.size() - 1);if(!b){Log(LogModule::DEBUG) << "Build Inverted Index Error!";continue;}count++;if(count % 1000 == 0){Log(LogModule::INFO) << "索引文件加载中,当前进度:" << count;//debug//break;}}in.close();isInit_ = true;Log(LogModule::INFO) << "索引加载完毕!已加载-" << count << "个文件!";return true;}~Index() = default;private:typedef struct DocCount{size_t title_cnt_ = 0;size_t content_cnt_ = 0;}DocCount_t;bool BuildForwordIndex(std::string& singlefile){sepfile.clear();bool b = ns_util::JiebaUtile::CutDoc(singlefile, sepfile);if(!b)return false;// if(count == 764)// {// Log(LogModule::DEBUG) << "Index Url: " << sepfile[2]; // }if(sepfile.size() != 3){Log(LogModule::DEBUG) << "Segmentation fail!";return false;}Forword_t ft;ft.Set(std::move(sepfile[0]), std::move(sepfile[1]), std::move(sepfile[2]), Forword_Index_.size());// if(count == 764)// {// Log(LogModule::DEBUG) << "Index Url: " << ft.url_; // }Forword_Index_.push_back(std::move(ft));return true;}bool BuildInvertedIndex(size_t findex){Forword_t ft = Forword_Index_[findex];std::unordered_map<std::string, DocCount_t> map_s;titlesegmentation.clear();ns_util::JiebaUtile::CutPhrase(ft.title_, titlesegmentation);for(auto& s : titlesegmentation){boost::to_lower(s);map_s[s].title_cnt_++;}contentsegmentation.clear();ns_util::JiebaUtile::CutPhrase(ft.content_, contentsegmentation);for(auto& s : contentsegmentation){boost::to_lower(s);map_s[s].content_cnt_++;//cout << s << "--";// if(strcmp(s.c_str(), "people") == 0)// {// Log(LogModule::DEBUG) << "意外的people!";// cout << ft.content_ << "------------end!";// sleep(100);// }}const int X = 10;const int Y = 1;for(auto& p : map_s){Inverted_t it;it.Set(findex, p.first, p.second.title_cnt_ * X + p.second.content_cnt_ * Y);InvertedList& list = Inverted_Index_[p.first];list.push_back(std::move(it));}return true;}private:std::vector<Forword_t> Forword_Index_;std::unordered_map<std::string, InvertedList> Inverted_Index_;bool isInit_ = false;//内存复用,优化时间std::vector<std::string> sepfile;std::vector<std::string> titlesegmentation;std::vector<std::string> contentsegmentation;};
};
Log.hpp
#ifndef __LOG_HPP__
#define __LOG_HPP__
#include <iostream>
#include <ctime>
#include <string>
#include <pthread.h>
#include <sstream>
#include <fstream>
#include <filesystem>
#include <unistd.h>
#include <memory>
#include <mutex>namespace LogModule
{const std::string default_path = "./log/";const std::string default_file = "log.txt";enum LogLevel{DEBUG,INFO,WARNING,ERROR,FATAL};static std::string LogLevelToString(LogLevel level) {switch (level){case DEBUG:return "DEBUG";case INFO:return "INFO";case WARNING:return "WARNING";case ERROR:return "ERROR";case FATAL:return "FATAL";default:return "UNKNOWN";}}static std::string GetCurrentTime(){std::time_t time = std::time(nullptr);struct tm stm;localtime_r(&time, &stm);char buff[128];snprintf(buff, sizeof(buff), "%4d-%02d-%02d-%02d-%02d-%02d",stm.tm_year + 1900,stm.tm_mon + 1,stm.tm_mday,stm.tm_hour,stm.tm_min,stm.tm_sec);return buff;}class Logstrategy{public:virtual ~Logstrategy() = default;virtual void syncLog(std::string &message) = 0;};class ConsoleLogstrategy : public Logstrategy{public:void syncLog(std::string &message) override{std::cerr << message << std::endl;}~ConsoleLogstrategy() override{}};class FileLogstrategy : public Logstrategy{public:FileLogstrategy(std::string filepath = default_path, std::string filename = default_file){_mutex.lock();_filepath = filepath;_filename = filename;if (std::filesystem::exists(filepath)) // 检测目录是否存在,存在则返回{_mutex.unlock();return;} try{// 不存在则递归创建(复数)目录std::filesystem::create_directories(filepath);}catch (const std::filesystem::filesystem_error &e){// 捕获异常并打印std::cerr << e.what() << '\n';}_mutex.unlock();}void syncLog(std::string &message) override{_mutex.lock();std::string path =_filepath.back() == '/' ? _filepath + _filename : _filepath + "/" + _filename;std::ofstream out(path, std::ios::app);if (!out.is_open()){_mutex.unlock();std::cerr << "file open fail!" << '\n';return;}out << message << '\n';_mutex.unlock();out.close();}~FileLogstrategy(){}private:std::string _filepath;std::string _filename;std::mutex _mutex;};class Log{public:Log(){_logstrategy = std::make_unique<ConsoleLogstrategy>();}void useconsolestrategy(){_logstrategy = std::make_unique<ConsoleLogstrategy>();printf("转换控制台策略!\n");}void usefilestrategy(){_logstrategy = std::make_unique<FileLogstrategy>();printf("转换文件策略!\n");}class LogMessage{public:LogMessage(LogLevel level, std::string file, int line, Log &log): _loglevel(level), _time(GetCurrentTime()), _file(file), _pid(getpid()), _line(line),_log(log){std::stringstream ss;ss << "[" << _time << "] "<< "[" << LogLevelToString(_loglevel) << "] "<< "[" << _pid << "] "<< "[" << _file << "] "<< "[" << _line << "] "<< "- ";_loginfo = ss.str();}template <typename T>LogMessage &operator<<(const T &t){std::stringstream ss;ss << _loginfo << t;_loginfo = ss.str();//printf("重载<<Logmessage!\n");return *this;}~LogMessage(){//printf("析构函数\n");if (_log._logstrategy){//printf("调用打印.\n");_log._logstrategy->syncLog(_loginfo);}}private:LogLevel _loglevel;std::string _time;pid_t _pid;std::string _file;int _line;std::string _loginfo;Log &_log;};LogMessage operator()(LogLevel level, std::string filename, int line){return LogMessage(level, filename, line, *this);}~Log(){}private:std::unique_ptr<Logstrategy> _logstrategy;};static Log logger;#define Log(type) logger(type, __FILE__, __LINE__)#define ENABLE_LOG_CONSOLE_STRATEGY() logger.useconsolestrategy()
#define ENABLE_LOG_FILE_STRATEGY() logger.usefilestrategy()
}#endif
main.cc
#include "Log.hpp"
#include "common.h"
#include "Parser.h"
#include "Search.hpp"
#include "httplib.h"
#include <cstdio>
#include <cstring>
#include <string>
const bool INIT = false;int main()
{if(INIT){Parser parser(Orignaldir, Tragetfile);parser.Init();}ns_search::Search search;httplib::Server svr;svr.set_base_dir(Basewwwroot);svr.Get("/s", [&](const httplib::Request& req, httplib::Response& rep){std::string param = "word";std::string word;std::string out;out.clear();if(req.has_param(param)){word = req.get_param_value(param);Log(LogModule::DEBUG) << "查找关键词:" << word;}// rep.set_content("Search: " + word, "text/plain");bool b = search.SearchBy(word, out);if(b)rep.set_content(out, "application/json");elseLog(DEBUG) << "查找失败";});svr.listen("0.0.0.0", 8080);return 0;
}makefile
# 编译器设置
CXX := g++
CXXFLAGS := -std=c++17
LDFLAGS :=
LIBS := -lboost_filesystem -lboost_system -ljsoncpp# 目录设置
SRC_DIR := .
BUILD_DIR := build
TARGET := main# 自动查找源文件
SRCS := $(wildcard $(SRC_DIR)/*.cc)
OBJS := $(SRCS:$(SRC_DIR)/%.cc=$(BUILD_DIR)/%.o)
DEPS := $(OBJS:.o=.d)# 确保头文件依赖被包含
-include $(DEPS)# 默认目标
all: $(BUILD_DIR) $(TARGET)# 创建构建目录
$(BUILD_DIR):@mkdir -p $(BUILD_DIR)# 链接目标文件生成可执行文件
$(TARGET): $(OBJS)$(CXX) $(OBJS) -o $@ $(LDFLAGS) $(LIBS)@echo "✅ 构建完成: $(TARGET)"# 编译每个.cc文件为.o文件
$(BUILD_DIR)/%.o: $(SRC_DIR)/%.cc$(CXX) $(CXXFLAGS) -MMD -MP -c $< -o $@# 清理构建文件
clean:rm -rf $(BUILD_DIR) $(TARGET)@echo "🧹 清理完成"# 重新构建
rebuild: clean all# 显示项目信息
info:@echo "📁 源文件: $(SRCS)"@echo "📦 目标文件: $(OBJS)"@echo "🎯 最终目标: $(TARGET)"# 伪目标
.PHONY: all clean rebuild info# 防止与同名文件冲突
.PRECIOUS: $(OBJS)
Parser.cc
#include "Parser.h"
#include "Log.hpp"
#include "Util.hpp"
#include "common.h"
#include <cstddef>
#include <fstream>
#include <string>
#include <utility>Parser::Parser(fs::path Datap, fs::path Targetp)
{Orignalpath_ = Datap;Targetpath_ = Targetp;
}// 初始化:录入html路径——解析html数据——分割写入Data——记录Url
bool Parser::Init()
{if(!LoadHtmlPath()){Log(LogModule::DEBUG) << "LoadHtmlPath fail!";return false;}if(!ParseHtml()){Log(LogModule::DEBUG) << "ParseHtml fail!";return false;}if(!WriteToTarget()){Log(LogModule::DEBUG) << "WriteToTarget fail!";return false;}return true;
}bool Parser::LoadHtmlPath()
{if(!fs::exists(Orignalpath_) || !fs::is_directory(Orignalpath_)){Log(LogModule::DEBUG) << "Orignalpath is not exists or invalid!";return false;}fs::recursive_directory_iterator end_it;fs::recursive_directory_iterator it(Orignalpath_);for(; it != end_it; it++){if(!it->is_regular_file()){continue;}if(it->path().extension() != ".html"){continue;}htmlpaths_.push_back(it->path());//Log(DEBUG) << "path: " << it->path();}Log(LogModule::DEBUG) << "Found " << htmlpaths_.size() << " HTML files";return true;
}bool Parser::ParseHtml()
{if(htmlpaths_.empty()){Log(LogModule::DEBUG) << "paths is empty!";return false;}size_t successCount = 0;for(fs::path &p : htmlpaths_){// 检查路径是否存在if (!fs::exists(p)) {Log(LogModule::ERROR) << "File not exists: " << p.string();continue;}std::string out;HtmlInfo_t info;// 读取文件并记录错误if(!ns_util::FileUtil::ReadFile(p.string(), &out)){Log(LogModule::ERROR) << "Failed to read file: " << p.string();continue;}// 解析标题并记录错误if(!ParseTitle(out, &info.title_)){Log(LogModule::ERROR) << "Failed to parse title from: " << p.string();continue;}// 解析内容并记录错误if(!ParseContent(out, &info.content_)){Log(LogModule::ERROR) << "Failed to parse content from: " << p.string();continue;}// 检查URL解析结果if(!ParseUrl(p, &info.url_)){Log(LogModule::ERROR) << "Failed to parse URL from: " << p.string();continue;}htmlinfos_.push_back(std::move(info));successCount++;}// 可以根据需要判断是否全部成功或部分成功Log(LogModule::INFO) << "Parse HTML completed. Success: " << successCount << ", Total: " << htmlpaths_.size();return successCount > 0;
}bool Parser::WriteToTarget()
{if(htmlinfos_.empty()){Log(LogModule::DEBUG) << "infos empty!";return false;}for(HtmlInfo_t &info : htmlinfos_){output_ += info.title_;output_ += Output_sep;output_ += info.content_;output_ += Output_sep;output_ += info.url_;output_ += Line_sep;}WriteToTargetFile();return true;
}bool Parser::ParseUrl(fs::path p, std::string *out)
{fs::path head(Boost_Url_Head);head = head / p.string().substr(Orignaldir.size());*out = head.string();//Log(LogModule::DEBUG) << "filename: " << p.filename();return true;
}bool Parser::ParseTitle(std::string& fdata, std::string* title)
{if(fdata.empty() || title == nullptr){Log(LogModule::DEBUG) << "parameter invalid!";return false;}size_t begin = fdata.find("<title>");size_t end = fdata.find("</title>");if(begin == std::string::npos || end == std::string::npos){Log(LogModule::DEBUG) << "title find fail!";return false;}begin += std::string("<title>").size();*title = fdata.substr(begin, end - begin);return true;
}bool Parser::ParseContent(std::string& fdata, std::string* content)
{if(fdata.empty() || content == nullptr){Log(LogModule::DEBUG) << "parameter invalid!";return false;}typedef enum htmlstatus{LABEL,CONTENT}e_hs;e_hs statu = LABEL;for(char& c: fdata){switch (c) {case '<':statu = LABEL;break;case '>':statu = CONTENT;break;default:{if(statu == CONTENT)*content += (c == '\n' ? ' ' : c);}break;}}return true;
}bool Parser::WriteToTargetFile()
{std::ofstream out;try {// 确保目录存在auto parent_path = Targetpath_.parent_path();if (!parent_path.empty()) {fs::create_directories(parent_path);}// 设置缓冲区(使用更大的缓冲区可能更好)const size_t buffer_size = 128 * 1024; // 128KBstd::unique_ptr<char[]> buffer(new char[buffer_size]);// 创建文件流并设置缓冲区out.rdbuf()->pubsetbuf(buffer.get(), buffer_size);// 打开文件out.open(Targetpath_.string(), std::ios::binary | std::ios::trunc);if (!out) {Log(LogModule::ERROR) << "Cannot open file: " << Targetpath_.string()<< " - " << strerror(errno);return false;}// 写入数据if (!output_.empty()) {out.write(output_.data(), output_.size());if (out.fail()) {Log(LogModule::ERROR) << "Write failed: " << Targetpath_.string()<< " - " << strerror(errno);return false;}}// 显式刷新out.flush();if (out.fail()) {Log(LogModule::ERROR) << "Flush failed: " << Targetpath_.string()<< " - " << strerror(errno);return false;}Log(LogModule::INFO) << "Written " << output_.size() << " bytes to " << Targetpath_.string();} catch (const fs::filesystem_error& e) {Log(LogModule::ERROR) << "Filesystem error: " << e.what();return false;} catch (const std::exception& e) {Log(LogModule::ERROR) << "Unexpected error: " << e.what();return false;}// 确保文件关闭(RAII会处理,但显式关闭更好)if (out.is_open()) {out.close();}return true;
}
Parser.h
#pragma once
// 包含公共头文件,可能包含一些全局定义、类型别名或常用工具函数
#include "common.h"
// 包含Boost文件系统库相关头文件,用于文件和目录操作
#include "boost/filesystem.hpp"
#include <boost/filesystem/directory.hpp>
#include <boost/filesystem/path.hpp>
// 包含vector容器头文件,用于存储路径和HTML信息列表
#include <vector>// 为boost::filesystem定义别名别名fs,简化代码书写
namespace fs = boost::filesystem;// HTML信息结构体,用于存储解析后的HTML文档关键信息
typedef struct HtmlInfo
{std::string title_; // 存储HTML文档的标题std::string content_; // 存储HTML文档的正文内容(去标签后)std::string url_; // 存储HTML文档的URL或来源路径}HtmlInfo_t; // 定义结构体别名HtmlInfo_t,方便使用class Parser
{private:// 解析HTML内容,提取标题并存储到title指针指向的字符串// 参数:fdata-HTML原始数据,title-输出的标题字符串指针// 返回值:bool-解析成功返回true,失败返回falsebool ParseTitle(std::string& fdata, std::string* title);// 解析HTML内容,提取正文(去除标签后)并存储到content指针指向的字符串// 参数:fdata-HTML原始数据,content-输出的正文内容字符串指针// 返回值:bool-解析成功返回true,失败返回falsebool ParseContent(std::string& fdata, std::string* content);// 将解析后的HTML信息写入目标文件(内部实现)// 返回值:bool-写入成功返回true,失败返回falsebool WriteToTargetFile();public:// 构造函数,初始化原始数据路径和目标存储路径// 参数:Datap-原始HTML文件所在路径,Targetp-解析后数据的存储路径Parser(fs::path Datap, fs::path Targetp);// 初始化函数:加载HTML路径→解析HTML数据→分割写入数据→记录URL// 整合了整个解析流程的入口函数// 返回值:bool-初始化成功返回true,失败返回falsebool Init();// 加载所有HTML文件的路径到htmlpaths_容器中// 返回值:bool-加载成功返回true,失败返回falsebool LoadHtmlPath();// 解析HTML文件:读取文件内容,提取标题、正文和URL// 将解析结果存储到htmlinfos_容器中// 返回值:bool-解析成功返回true,失败返回falsebool ParseHtml();// 对外接口:将解析后的HTML信息写入目标文件(调用内部WriteToTargetFile)// 返回值:bool-写入成功返回true,失败返回falsebool WriteToTarget();// 解析文件路径p,生成对应的URL信息并存储到out指针指向的字符串// 参数:p-文件路径,out-输出的URL字符串指针// 返回值:bool-解析成功返回true,失败返回falsebool ParseUrl(fs::path p, std::string* out);// 默认析构函数,无需额外资源释放~Parser() = default;private:std::vector<fs::path> htmlpaths_; // 存储所有待解析的HTML文件路径std::vector<HtmlInfo_t> htmlinfos_; // 存储解析后的所有HTML信息std::string output_; // 可能用于临时存储输出数据fs::path Orignalpath_; // 原始HTML文件所在的根路径fs::path Targetpath_; // 解析后数据的目标存储路径
};
Search.hpp
#pragma once
#include "Log.hpp"
#include "Util.hpp"
#include "common.h"
#include "Index.hpp"
#include <algorithm>
#include <cctype>
#include <cstddef>
#include <cstdio>
#include <ctime>
#include <jsoncpp/json/json.h>
#include <string>
#include <unistd.h>
#include <unordered_map>
#include <vector>namespace ns_search
{//查找关键词文档归总typedef struct DocSumup{size_t doc_id_ = 0;size_t weight_ = 0;std::vector<std::string> words_;}DocSumup_t;class Search : NonCopyable{public:Search() : index(ns_index::Index::GetInstance()){index->BulidIndex();}bool SearchBy(std::string keywords, std::string& out){//分词std::vector<std::string> Segmentation;ns_util::JiebaUtile::CutPhrase(keywords, Segmentation);//查找std::vector<DocSumup_t> inverted_elem_all;std::unordered_map<size_t, DocSumup_t> doc_map;//debug// for(auto& e : Segmentation)// {// cout << e << " - " ;// }//cout << endl;//debugfor(auto& word : Segmentation){static size_t t = 0;ns_index::InvertedList* list = index->QueryByWord(word);if(list == nullptr){//Log(LogModule::DEBUG) << word << "-not find!";//sleep(1);continue;}//cout << t << "次循环," << word << "-找到" << endl;for(ns_index::InvertedElem e : *list){doc_map[e.doc_id_].doc_id_ = e.doc_id_;doc_map[e.doc_id_].weight_ += e.weight_;doc_map[e.doc_id_].words_.push_back(e.word_);}}//哈稀表的内容插入整体数组for(auto& e : doc_map){inverted_elem_all.push_back(std::move(e.second));}//判断是否找到if(inverted_elem_all.empty()){Log(LogModule::INFO) << "-" << keywords << "-Not Find!";return false;}else{Log(LogModule::DEBUG) << "已找到" << inverted_elem_all.size() << "个文件相关!" ;}//权重排序std::sort(inverted_elem_all.begin(), inverted_elem_all.end(),[](DocSumup_t i1, DocSumup_t i2)-> bool{return i1.weight_ == i2.weight_ ? i1.doc_id_ < i2.doc_id_ : i1.weight_ > i2.weight_;});//写入json串for(DocSumup_t& e : inverted_elem_all){Json::Value tempvalue;tempvalue["doc_id"] = e.doc_id_;tempvalue["weight"] = e.weight_;ns_index::Forword_t* ft = index->QueryById(e.doc_id_);if(!ft){Log(DEBUG) << e.doc_id_ << "-id not find!";//sleep(1);continue;}tempvalue["url"] = ft->url_;tempvalue["title"] = ft->title_;tempvalue["desc"] = ExtractDesc(ft->content_, e.words_[0]);tempvalue["word"] = keywords;root.append(tempvalue);}//写入字符串带出参数Json::StyledWriter writer;out = writer.write(root);// 每次搜索完,都把这个root的内容清空一下root.clear();return true;}private:std::string ExtractDesc(std::string& content, std::string word){auto it = std::search(content.begin(),content.end(),word.begin(),word.end(),[](char a, char b)->bool{return std::tolower(a) == std::tolower(b);});if(it == content.end()){Log(LogModule::DEBUG) << "ExtractDesc fail!";return "NONE!";}const int pre_step = 50;const int back_step = 100;int pos = it - content.begin();int start = pos - pre_step > 0 ? pos - pre_step : 0;int end = pos + back_step >= content.size() ? content.size() - 1 : pos + back_step;return content.substr(start, end - start) + std::string("...");}public:~Search() = default;private:Json::Value root;ns_index::Index* index;};
};
Util.hpp
#pragma once
#include "Log.hpp"
#include "common.h"
#include "cppjieba/Jieba.hpp"
#include <boost/algorithm/string/classification.hpp>
#include <boost/algorithm/string/split.hpp>
#include <fstream>
#include <sstream>
#include <string>
#include <unordered_map>
#include <vector>
namespace ns_util
{class FileUtil : public NonCopyable{public:static bool ReadFile(std::string path, std::string* out){std::fstream in(path, std::ios::binary | std::ios::in);if(!in.is_open()){Log(LogModule::DEBUG) << "file-" << path << "open fail!";return false;}std::stringstream ss;ss << in.rdbuf();*out = ss.str();in.close();return true;}};class StopClass{public:StopClass(){std::ifstream in(STOP_WORD_PATH, std::ios::binary | std::ios::in);if(!in.is_open()){Log(LogModule::DEBUG) << "stop words load fail!";in.close();return;}std::string line;while(std::getline(in, line)){stop_words[line] = true;}in.close();}std::pmr::unordered_map<std::string, bool> stop_words;};class JiebaUtile : public NonCopyable{public:static cppjieba::Jieba* GetInstace(){static cppjieba::Jieba jieba_(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);return &jieba_;}static bool CutPhrase(std::string& src, std::vector<std::string>& out){try{GetInstace()->CutForSearch(src, out, true);for(auto s = out.begin(); s != out.end(); s++){if(stop_.stop_words.find(*s) != stop_.stop_words.end()){out.erase(s);}}}catch (const std::exception& e){Log(LogModule::ERROR) << "CutString Error!" << e.what();return false;}catch (...){Log(ERROR) << "Unknow Error!";return false;}return true;}static bool CutDoc(std::string& filestr, std::vector<std::string>& out){try{boost::split(out, filestr, boost::is_any_of("\3"));}catch (const std::exception& e){Log(LogModule::ERROR) << "std Error-" << e.what();return false;} catch(...){Log(LogModule::ERROR) << "UnKnown Error!";return false;}return true;}private:JiebaUtile() = default;~JiebaUtile() = default;private:static StopClass stop_;};inline StopClass JiebaUtile::stop_;
};
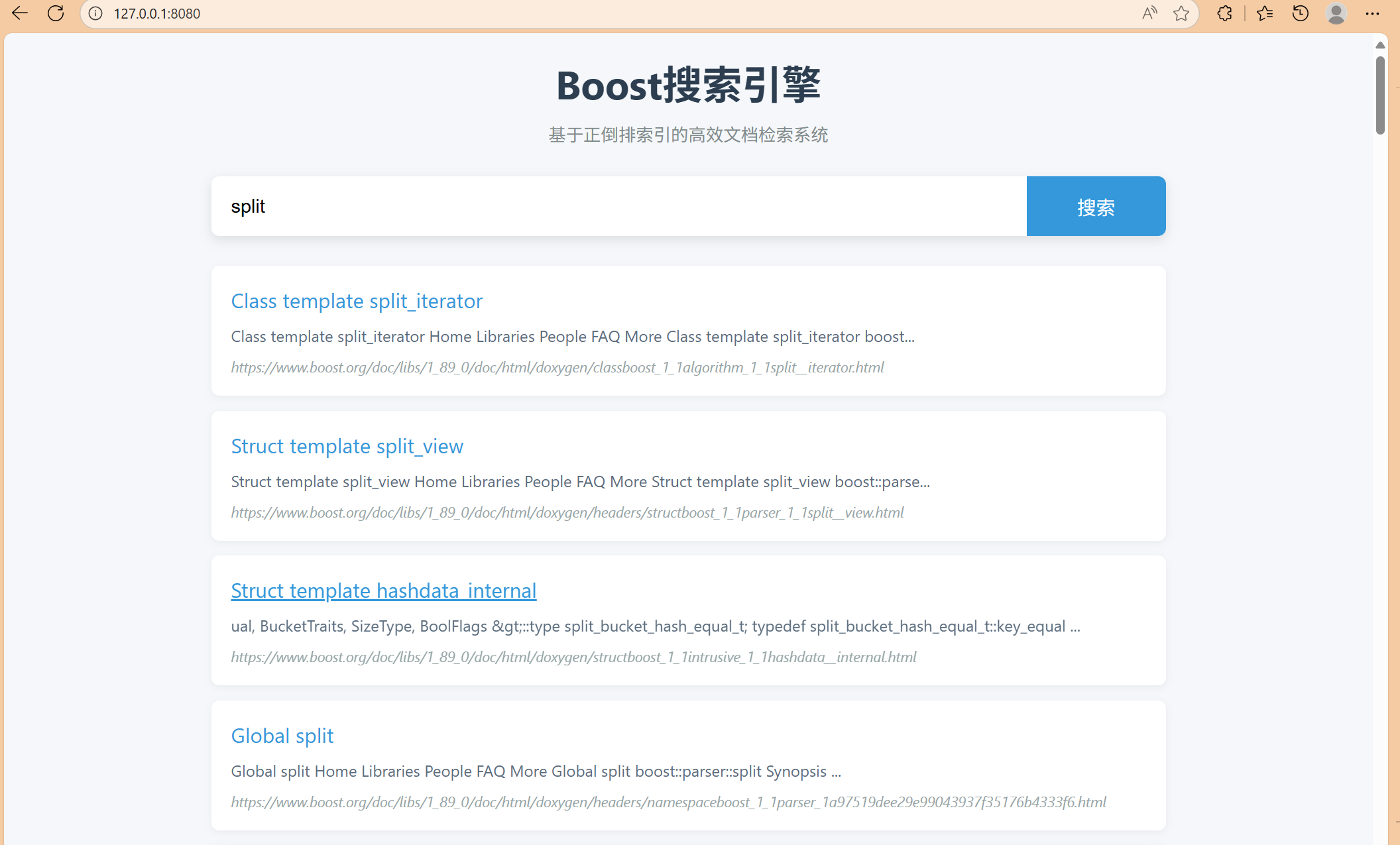
结果展示