Day29_【深度学习(8)—循环神经网络RNN】
一、NLP背景知识
自然语言处理(Nature language Processing, NLP)
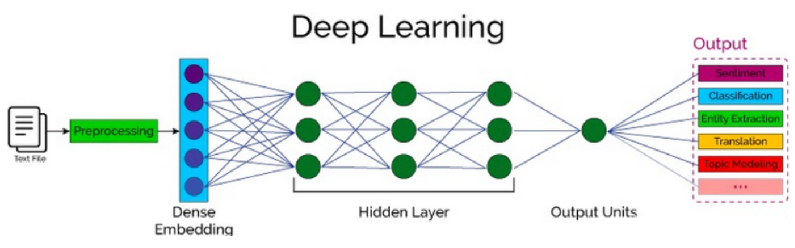
作用:让计算机读懂并生成人类语言
流程:
文本数据-->数据预处理层(分词,去重、构建词表)-->词嵌入层-->得到固定大小的词向量
-->神经网络-->结果
专有名词:
- 一个句子 = 一个样本 = 1条语料
- 所有样本 = 1个训练集 = 1个语料库
- 1个词 = 一个token
- 词向量:词用固定维度的向量表示
- 词向量矩阵:由所有词向量组成
- 词表:分词再去重的词语列表
- 时间步:一个时间步送一个token
- 向量的维度 = 向量的长度 = 特征数
1.分词
jieba分词器:是一个非常流行的 中文分词库,由 Python 编写,广泛应用于中文自然语言处理(NLP)任务中。
1.1 安装:
pip install jieba -i https://pypi.mirrors.ustc.edu.cn/simple/1.2 API:
jieba.lcut(text) #直接返回列表(推荐使用)
jieba.cut(text) #返回生成器(需用 list 转换)
jieba.cut_for_search(text) #搜索引擎模式
jieba.lcut_for_search(text) #搜索引擎模式 + 返回列表
jieba.load_userdict("dict.txt") #加载自定义词典
jieba.add_word("新词") #动态添加新词
jieba.del_word("词") #删除词2.词嵌入层
2.1 作用
将输入的词(token)转换为固定维度的词向量
将文本数据映射为数值向量
2.2 应用代表算法
RNN、LSTM、GRU
2.3 区别于one-hot
词嵌入层 vs One-Hot 编码 对比表
特性 词嵌入层(Embedding Layer) One-Hot 编码 向量类型 低维稠密向量 高维稀疏向量 “低维”含义 维度远小于词汇表大小(如 50、100、300) —— 维度设置 由 embedding_dim超参数决定维度 = 词汇表大小(如 10,000) 稠密性 ✅ 稠密:向量中所有元素都可能为非零值 ❌ 稀疏:只有一个元素为 1,其余全为 0 向量示例 [0.2, -0.1, 0.8, 0.3](4维)[0, 0, 1, 0, 0](5维)语义表达 ✅ 能捕捉词语之间的语义相似性(如“猫”和“狗”相近) ❌ 无法表达语义关系,所有词正交 存储效率 高:参数少,适合深度学习模型 低:占用空间大,尤其词汇表大时 是否可训练 ✅ 可作为神经网络的一部分进行训练和优化 ❌ 固定编码,不可训练 典型应用 RNN、LSTM、Transformer、文本分类等 基础编码、简单模型、特征工程
2.4 API
# num_embeddings:表示词的数量
# embedding_dim:表示用多少维的向量来表示每个词
nn.Embedding(num_embeddings=10, embedding_dim=4)二、RNN
作用:RNN是专门处理序列数据的神经网络
序列数据:后面的数据跟前面的数据有关系
1. 原理
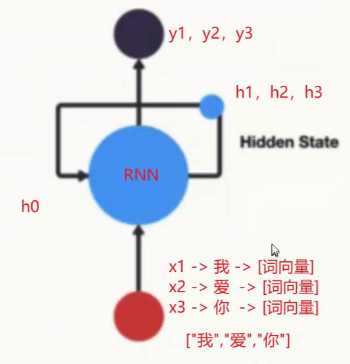
拆开来看: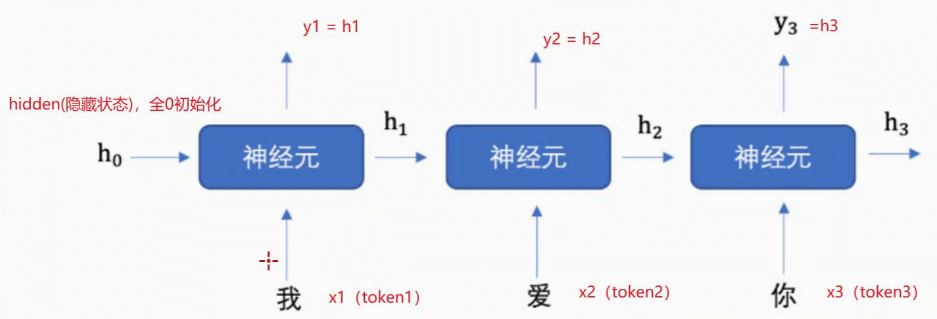
1.h表示隐藏状态,具有记忆功能:每次学习到上一个神经元的结果、规律(上下文语意信息),保存序列数据中的历史信息,并将这些信息传递给下一个时间步
2.每次输入两个值:上一个时间步的隐藏状态h0、当前状态的输入值input。
每次输出两个值:输出当前时间步的隐藏状态hn、当前时间步的预测结果output。
2. RNN神经元内部计算
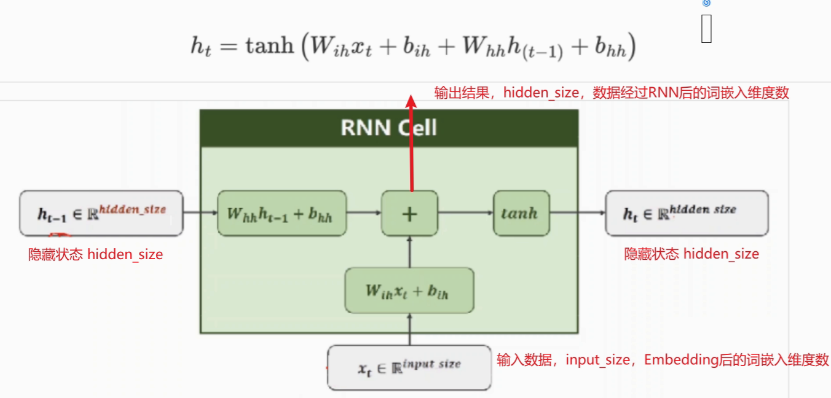

3. API
# input_size:输入数据的维度,一般设为词向量的维度
# hidden_size:隐藏层h的维度,也是当前层神经元的输出维度
# num_layers: 隐藏层h的层数,默认为1
RNN = nn.RNN(input_size, hidden_size,num_layers)# input的表示形式:[seq_len, batch_size, input_size],
# 即[句子的长度,batch的大小,词向量的维度]=[词语个数,句子的个数,词向量的维度]
# h0的表示形式:[num_layers, batch_size, hidden_size],
# 即[隐藏层的层数,batch的大小,隐藏层h的维度]output, hn = RNN(input, h0)