【AI论文】在视觉运动策略中是否需要本体感觉状态?
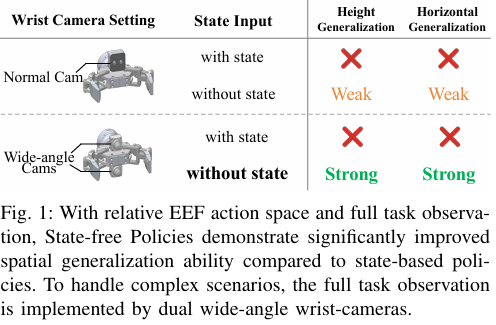
摘要:基于模仿学习的视觉运动策略已广泛应用于机器人操作领域,此类策略通常同时采用视觉观测数据和本体感觉状态信息,以实现精确控制。然而,本研究发现,这种常见做法会使策略过度依赖本体感觉状态输入,导致模型对训练轨迹产生过拟合,进而在空间泛化能力上表现欠佳。相反,我们提出了无状态策略(State-free Policy),该策略移除了本体感觉状态输入,仅基于视觉观测数据预测动作。无状态策略构建于相对末端执行器动作空间中,并需确保获取与任务相关的完整视觉观测信息(本研究通过双广角腕部摄像头实现)。实证结果表明,无状态策略的空间泛化能力显著优于基于状态的策略:在抓取放置、高难度衬衫折叠及复杂全身操作等真实世界任务中(涵盖多种机器人本体形态),无状态策略在高度泛化场景下的平均成功率从0%提升至85%,在水平泛化场景下的平均成功率从6%提升至64%。此外,该策略在数据利用效率和跨本体形态适应性方面也表现出优势,增强了其在实际场景中部署的实用性。Huggingface链接:Paper page,论文链接:2509.18644
研究背景和目的
研究背景:
随着机器人技术的快速发展,基于模仿学习的视觉运动策略(visuomotor policies)在机器人操作任务中得到了广泛应用。
这些策略通常结合视觉观测和本体感觉状态(proprioceptive states),如末端执行器姿态和关节角度,以实现精确控制。然而,这种依赖本体感觉状态输入的做法导致策略过度依赖于特定的训练轨迹,从而在空间泛化能力上表现不佳。具体来说,当机器人面对与训练数据中不同空间位置的任务相关对象时,基于状态的策略往往无法有效适应,导致性能显著下降。
此外,当前机器人学习数据收集的成本高昂,尤其是在需要广泛状态覆盖(即任务相关对象的多样化空间位置)的情况下,数据收集变得更加困难。
因此,如何提升视觉运动策略的空间泛化能力,减少对特定训练轨迹的依赖,并降低数据收集成本,成为当前机器人学习领域亟待解决的问题。
研究目的:
本研究旨在提出一种无状态策略(State-free Policy),通过移除本体感觉状态输入,仅基于视觉观测来预测动作,从而显著提升视觉运动策略的空间泛化能力。
具体而言,本研究希望验证以下假设:
- 无状态策略能否在多种机器人操作任务中实现更强的空间泛化能力。
- 无状态策略是否能够提高数据效率,减少对多样化训练数据的需求。
- 无状态策略是否能够增强跨机器人 embodiment 的适应能力,简化新机器人上的微调过程。
研究方法
策略设计:
本研究提出的无状态策略基于相对末端执行器动作空间(relative end-effector action space)和全任务观测(full task observation)。
具体而言,策略预测的是基于当前视觉观测的末端执行器相对位移,而非绝对位置。这种设计使得策略能够更好地适应不同空间位置的任务相关对象。同时,为了确保策略能够获取足够的任务相关信息,本研究采用双广角腕部摄像头(dual wide-angle wrist cameras)提供全任务观测,视野约为120°×120°。
实验设置:
本研究在多种真实世界任务和模拟环境中对无状态策略进行了广泛评估。真实世界任务包括“拿起并放置笔”(Pick Pen)、“拿起瓶子”(Pick Bottle)、“盖上瓶盖”(Put Lid)、“折叠衬衫”(Fold Shirt)和“从冰箱中取出瓶子”(Fetch Bottle)等,涵盖了多种机器人embodiment,如双臂人类似机器人、双臂Arx5机器人系统和全身机器人。
模拟环境则基于LIBERO基准测试。
数据收集与评估:
真实世界数据由专业数据收集人员通过远程操作收集,每个“拿起并放置”类任务收集300个轨迹片段,约5小时数据;而更具挑战性的“折叠衬衫”和“全身取瓶子”任务则收集10,000个轨迹片段,约80小时数据。
评估指标包括高度泛化能力和水平泛化能力,每个真实世界评估包含30次试验,仅当整个轨迹完成时才算成功。
研究结果
空间泛化能力:
实验结果表明,无状态策略在多种任务中显著提升了空间泛化能力。
例如,在“拿起笔”任务中,无状态策略在高度泛化上的成功率从0%提升至98%,在水平泛化上的成功率从0%提升至58%。类似地,在更具挑战性的“折叠衬衫”和“全身取瓶子”任务中,无状态策略也表现出显著更强的空间泛化能力。
数据效率:
无状态策略在数据效率方面也表现出优势。
即使在数据量减少的情况下,无状态策略仍能保持较高的成功率,而基于状态的策略则容易出现过拟合现象。例如,在“拿起笔”任务中,使用较少的数据进行微调时,无状态策略的成功率显著高于基于状态的策略。
跨embodiment适应能力:
无状态策略在跨embodiment适应方面也表现出色。
由于无状态策略仅依赖于视觉输入,并在相对末端执行器动作空间中预测动作,因此它们不需要针对不同的状态空间进行额外适应。实验结果表明,在将策略从Arx5机器人适应到人类似机器人时,无状态策略能够更快地适应新环境,并实现更高的成功率。
研究局限
尽管无状态策略在空间泛化、数据效率和跨embodiment适应方面表现出色,但本研究仍存在一定局限性。
首先,纯视觉策略可能对背景变化敏感,当机器人和桌子的位置发生变化时,可能需要额外的微调来恢复性能。其次,在双臂设置中,如果仅使用一只手臂进行工作,未使用手臂的视觉输入分布变化可能会偶尔导致意外动作。此外,本研究主要在特定类型的机器人任务中进行了验证,未来需要在更多样化的任务和环境中进一步验证无状态策略的有效性和鲁棒性。
未来研究方向
针对本研究的局限性,未来研究可以从以下几个方面展开:首先,可以探索更先进的视觉处理技术,以提高纯视觉策略对背景变化的鲁棒性。
例如,结合注意力机制或对象检测算法,使策略能够更好地关注任务相关对象,忽略背景干扰。其次,可以研究跨模态学习策略,将视觉、触觉和听觉等多种传感器信息融合起来,以进一步提升策略的适应性和泛化能力。此外,未来研究还可以关注无状态策略在实际应用中的部署和效果评估,通过与行业合作伙伴合作,共同推动无状态策略在机器人操作任务中的广泛应用。
同时,未来研究还可以探索无状态策略与其他先进机器人学习技术的结合使用。
例如,可以将无状态策略与强化学习结合,通过试错学习进一步优化策略性能;或者将无状态策略与元学习结合,使策略能够快速适应新任务和新环境。此外,随着多模态大模型技术的发展,未来还可以探索将无状态策略与多模态大模型结合,通过利用大规模多模态数据进一步提升策略的泛化能力和适应性。
总之,本研究提出的无状态策略为提升视觉运动策略的空间泛化能力提供了新的思路和方法。
未来研究可以在此基础上进一步探索和优化,推动机器人学习技术的不断发展和进步。