Agent开发02-关键思想(ReAct、ReWOO、Reflexion、LLM Compiler等)
前言
前文概述了Agent开发定义和一些基本概念,本文目的是概述目前Agent开发的一些关键论文和思想。
| 年份 | 标题 |
|---|---|
| 2022 | ReAct: Synergizing Reasoning and Acting in Language Models |
| 2023 | ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models |
| 2023 | Reflexion: Language Agents with Verbal Reinforcement Learning |
| 2023 | REST MEETS REACT: SELF-IMPROVEMENT FOR MULTI-STEP REASONING LLM AGENT |
| 2024 | Self-Reflection in LLM Agents: Effects on Problem-Solving Performance |
| 2024 | An LLM Compiler for Parallel Function Calling |
研究进展
ReAct:推理 + 动作结合
论文标题:ReAct: Synergizing Reasoning and Acting in Language Models
作者:Shinn et al., 2022
- 核心贡献:将“Chain-of-Thought”推理与动作(工具调用)结合。
- 场景:开放问答、Web搜索、Wikipedia浏览等。
- 适用:知识密集型问答、需要多步交互和决策、工具链式依赖
- 架构:Thought-Action-Observation 循环,支持工具使用。
- Thought:LLM 在输出时“自言自语”,写下自己当前的推理过程。
- Action: LLM 根据思考决定调用某个工具或执行动作。
- Observation:工具执行后返回结果,作为下一步推理的输入。
- 优点:
- 支持多步推理与交互,动态适应性极强,能够根据实时的环境观察灵活调整其行动计划,有效应对不确定性和突发情况。
- 其显式的推理轨迹使得整个决策过程高度可解释,这不仅便于开发者进行调试,也增强了用户对Agent的信任度。
- 缺点:
- 每次工具调用都需要进行一次LLM推理,导致执行速度相对较慢,并会产生高昂的Token消耗。
- 由于其每次只规划下一步,可能导致Agent陷入局部最优解,而无法找到全局最优的行动路径。
- 长链调用中可能会陷入反复调用和幻觉中。
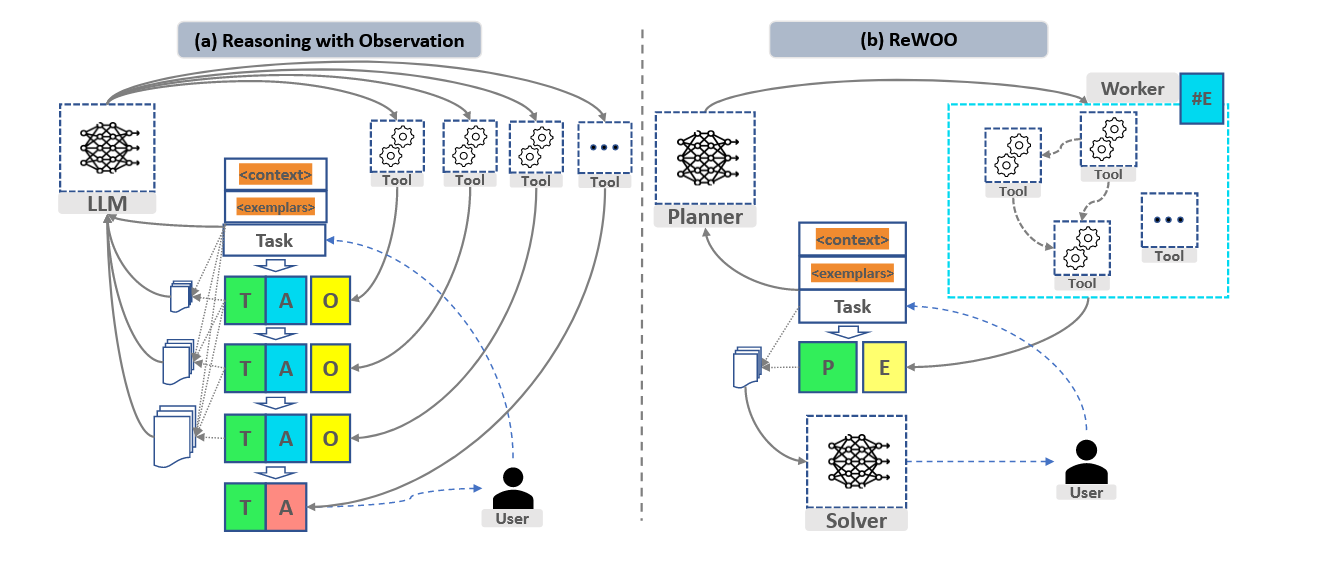
下图展示了两个领域(问答、游戏)的回复方式(直接回复、仅推理、仅调用工具、推理+调用工具)的对比


ReWOO:推理过程与工具调用解耦
论文标题:ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
作者:Xu B, Peng Z, Lei B, et al. 2023
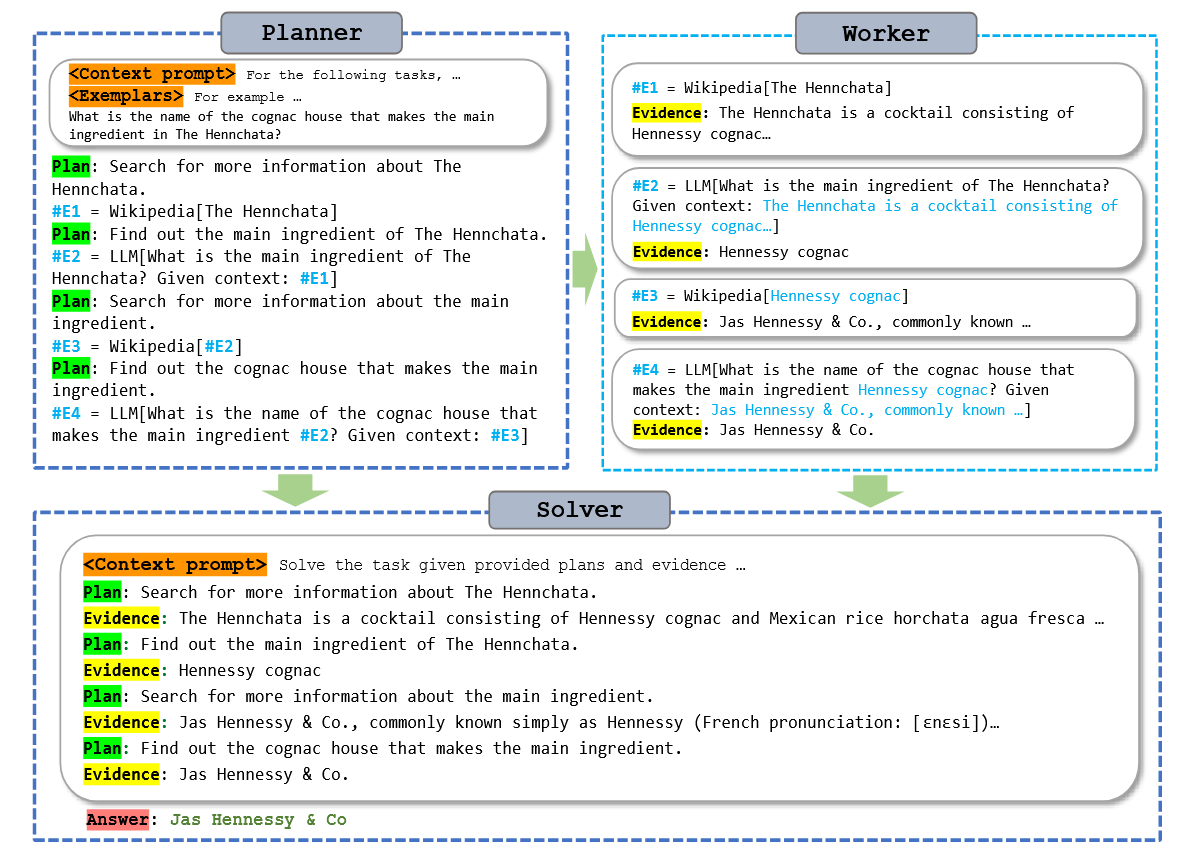
- 核心贡献: ReAct 每一步都需要 Observation 不同,ReWOO 先让 LLM 生成一个完整的推理/依赖图,再一次性或并行获取 Observation。
- 场景:大规模知识问答、检索增强生成(RAG)、需要多个工具协同的复杂推理任务。
- 适用:强调并行工具调用、减少循环交互开销的场景,例如大模型问答系统、代码生成与验证、需要快速推理的在线应用。
- 架构:无思考循环,有工程重试
- Planner:生成带有工具调用占位符的推理计划(中间表示)。(自身可能会迭代几次,直到生成合格的推理计划)
- Workers:执行计划中的工具调用,可并行化。(如果 Worker 执行失败,可能需要 Planner → Worker → Solver 重新走一轮)
- Solver:接收结果,填充到推理计划,再产出最终答案。
- 优点:
- 工具调用可并行化,减少 token 使用,避免 ReAct 那种“逐步等待”带来的冗余。
- 避免了 ReAct 中的长链误差传播(每步依赖上一步 Observation)
- 中间推理图易于人类检查与干预。
- 缺点:
- **计划正确性强依赖:**依赖 LLM 一次性写好合理的推理图,计划质量决定最终效果。
- 灵活性不足:相比 ReAct 的逐步推理,ReWOO 不太适合需要动态探索或交互式调整的任务。
ReWOO示例:
ReAct和ReWOO区别图:
Reflexion:反思式学习智能体
论文标题:Reflexion: Language Agents with Verbal Reinforcement Learning
作者:Mialon et al., 2023
- 核心贡献:
- 模型在失败后能够进行 语言层级“反思”(self-reflection),生成改进策略以优化后续行为。
- 通过自监督方式,让 LLM 从自己的错误中学习,提高任务完成能力。
- 场景:
- 代码生成:如 Python 编程题或算法实现。
- 数理推理:数学题、多步推理问题。
- 其他复杂任务:需要多步决策或连续尝试的场景。
- 特点:
- 自我监督学习:利用 LLM 自身生成的反馈改进策略,无需人工标注大量数据。
- 记忆 + 自我调整:模型可记忆历史失败及反思,并在下一次尝试中调整策略。
- 可解释性强:反思生成文本可解释模型决策。
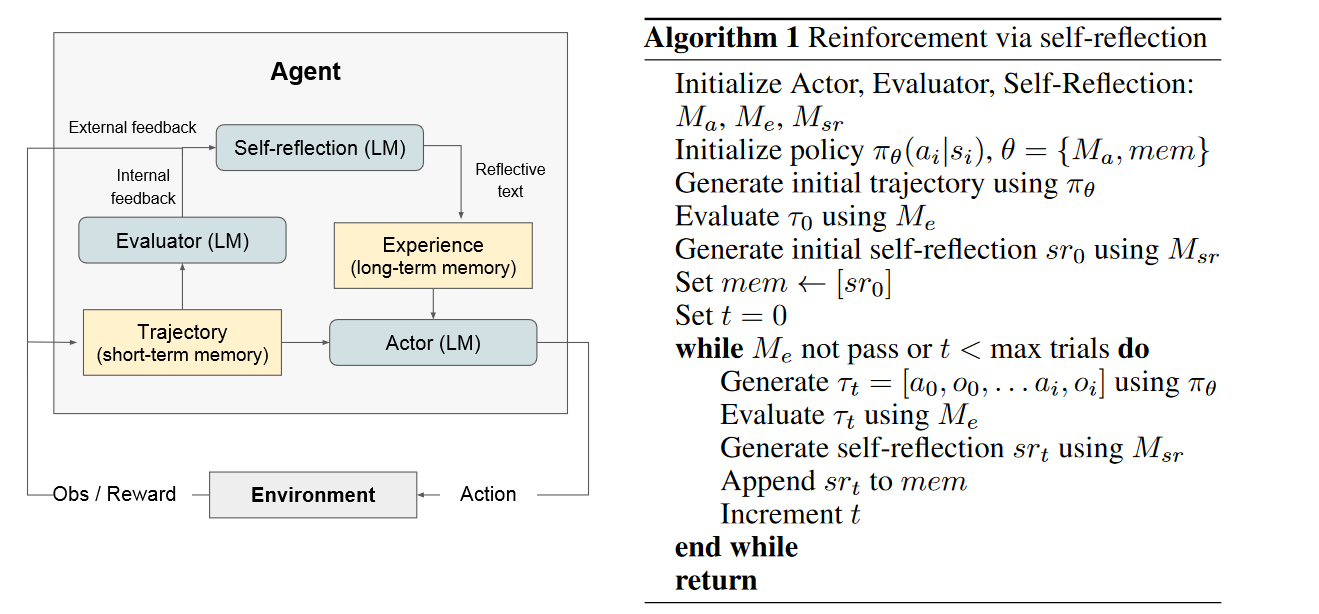
- 架构
- Actor (LM)
- 执行任务动作(Action),生成初步输出。
- 与环境交互,接收观察(Obs)和奖励(Reward)。
- Evaluator (LM)
- 对 Actor 的输出轨迹(Trajectory)进行评估,判断是否成功。
- 提供内部反馈(Internal feedback)给 Self-Reflection 模块。
- Self-Reflection (LM)
- 根据 Evaluator 的反馈以及外部反馈生成 反思文本(Reflective text)。
- 提供给 Actor,用于改进下一轮任务执行策略。
- Trajectory / Experience
- 短期记忆(Trajectory):存储当前任务的执行轨迹。
- 长期记忆(Experience):存储历史反思和成功经验,供未来任务使用。
- Environment
- 提供任务环境,接受 Actor 的动作并返回观察和奖励。
- Actor (LM)
- 优点:
- 加入了显式的自主反思与自我改进,可减少重复错误,提高长期任务性能
- 通过存储历史思考和结果,使模型能够利用过去的经验进行推理,而不是每次从零开始。
- 缺点:
- 复杂性增加,融入任何一个规划推理架构都会增加Token消耗
- 对于短小、单步或高实时性任务,反思机制带来的收益有限,反而增加延迟。
- 效果高度依赖之前的反思质量,如果初始策略或反思机制有偏差,可能会积累错误经验。
- 为了反思和自我改进,必须存储大量的任务历史和内部日志。

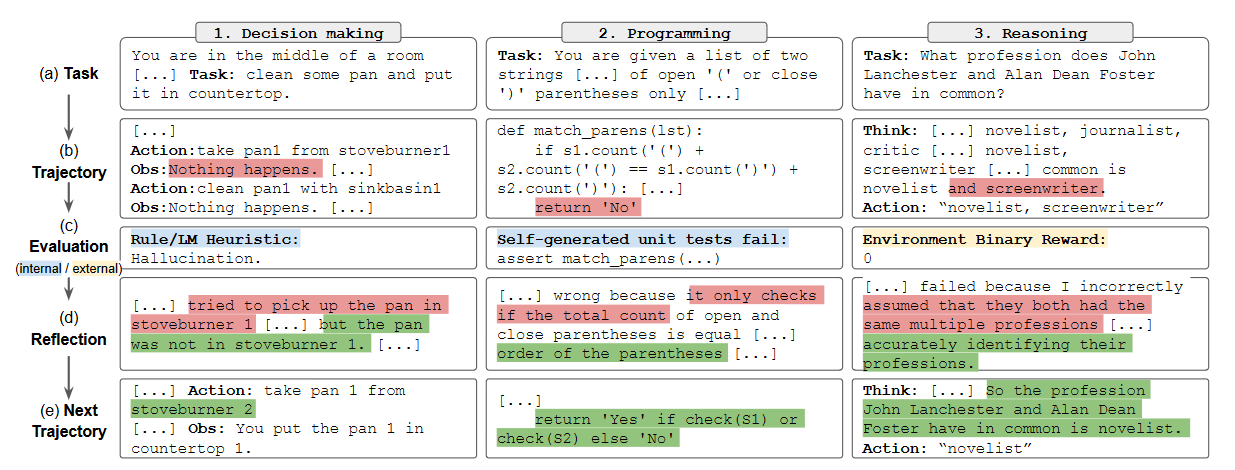
ReAct + ReST:通过 AI 反馈训练增强推理
论文标题:REST MEETS REACT: SELF-IMPROVEMENT FOR MULTI-STEP REASONING LLM AGENT
作者:Aksitov R, Miryoosefi S, Li Z, et al. 2023
- 贡献:
- 构建了一种具有自我批判能力的ReAct Agent
- 定义了一个基于Bamboogle和BamTwoogle数据集的agent代理评价指标,重点强调了自动评价
- 证明通过对智能体的推理轨迹进行Rest风格的迭代微调,可以有效地提高智能体的性能
- 作为这个迭代过程的一部分而产生的合成数据可以用于将智能体提取到一个或两个数量级较小的模型中,其性能与预训练的教师智能体相当
- 架构/方法
- Relevance Self-Check:验证答案是否与原问题相关。
- Grounding Self-Check:检查答案是否基于检索到的片段。
- 优点
- 在多步推理任务中,比纯 ReAct 更稳健,错误率更低。
- 通过自我批判,智能体可以“学习如何更好地思考”,而不是单次执行。
- 产生的反思数据不仅提升当前模型,还能用于 蒸馏小模型,降低部署成本。
- 不依赖人工标注,大幅降低实验和迭代成本。
- 缺点
- 需要额外生成批判性反思和修正,消耗更多Token。
- 如果自我批判阶段出现偏差,可能导致 错误被放大,影响后续训练。
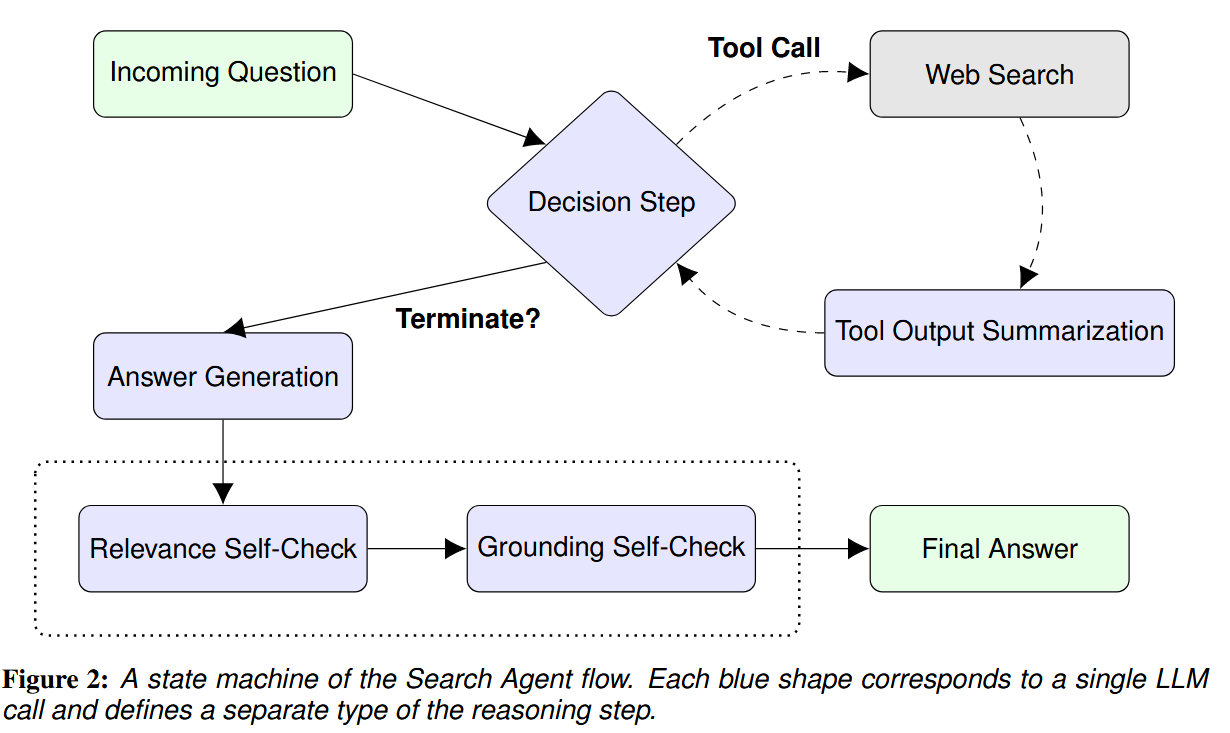
Self-Reflection:自我反思类型
论文标题:An LLM Compiler for Parallel Function Calling
作者:Kim S, Moon S, Tabrizi R, et al. 2024
- 贡献:
- 确定自我反思的哪些方面最有利于提高LLM Agent在问题解决任务上的表现。将自我反思的过程分解为若干组成部分,并确定每个组成部分如何有助于Agent整体性能的提高。
- 对哪种类型的LLM和问题域从每种类型的自我反思中受益最大的洞察力。
- 架构/方法:
- 将反思类型分为8类
- Baseline- -没有自我反思能力。
- Retry- -告知它回答错误,并简单地再次尝试。
- Keywords- -每类错误的关键词列表。
- Advice- -一般性的改进建议列表。
- Explanation- -解释它为什么犯了错误。
- Instructions- -如何解决问题的指令列表/步骤指南。
- Solution- -问题的逐步解决(提供一步步的正确解答)。
- Composite- -综合所有六类自我反思。
- Unredacted- -所有六类没有被编辑的答案。(反思内容中不隐藏正确答案,即答案未被遮蔽)
- 实验流程
- 第一轮:所有题 Baseline 回答 → 得到正确与错误集。
- 对于错题,每个 self-reflection agent 根据其类型生成反思。反思利用“正确答案 + 错误回答 + 问题”的上下文来反思。对于 Unredacted 类型,反思中包含正确答案;其它类型通常隐藏正确答案或部分信息。
- 然后这些 agent 用反思结果作为提示,再次回答这些错题(只重做错题,而正确题保留 Baseline 的得分)
- 将反思类型分为8类
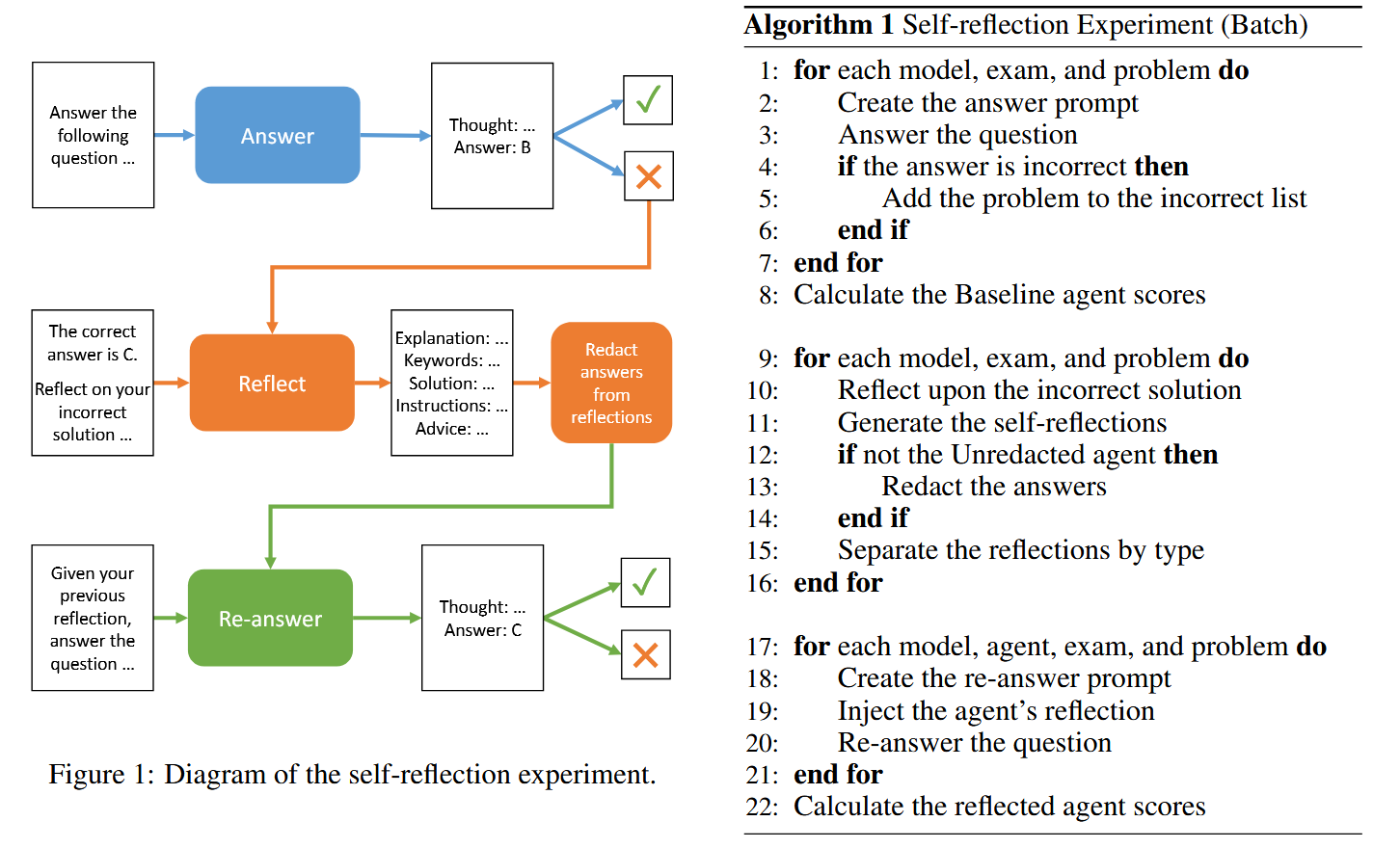
- 结果:
- 结构化反思(Explanation, Instructions, Solution) 在逻辑推理和多条件约束题中最有帮助。
- 简单反思(Retry, Keywords, Advice) 在知识密集或常识类任务中几乎没有优势,因为关键问题不在于推理链条,而在于知识缺口。
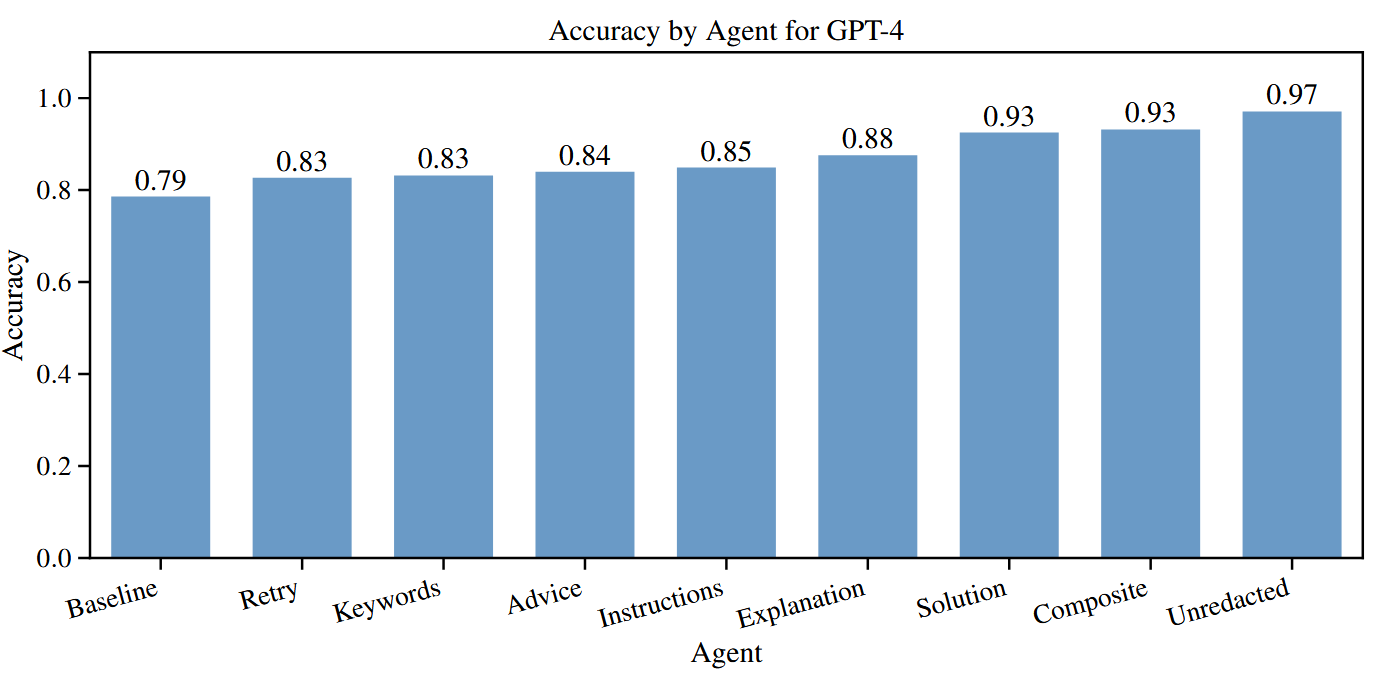
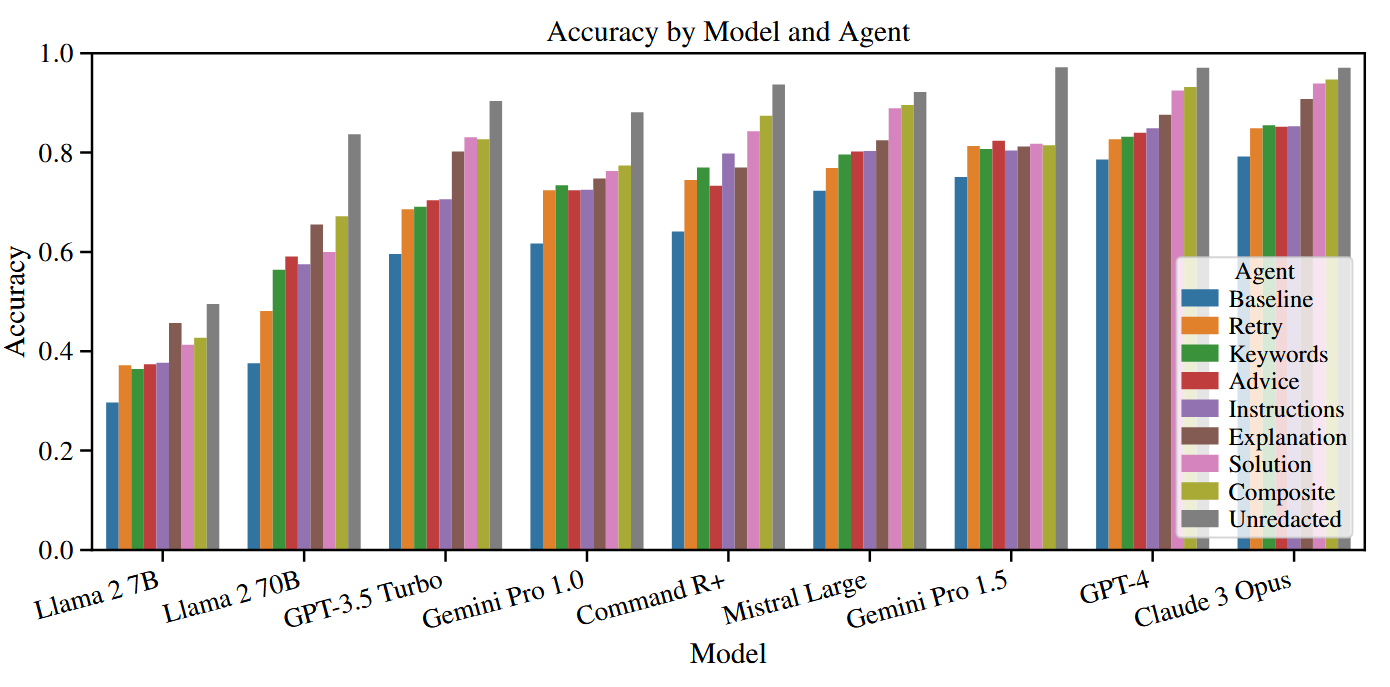
自我反思在 逻辑性强、易遗漏条件的推理任务 (如 LSAT Analytical Reasoning) 中提升最大;在 知识密集 / 常识类任务 (如 MedQA, PubMedQA, CommonsenseQA) 中提升有限(如果模型本身缺乏相关知识,反思只能在已有的错误推理上改进,无法补充缺失的知识);难度越高、基线越低的任务,反思收益越大。
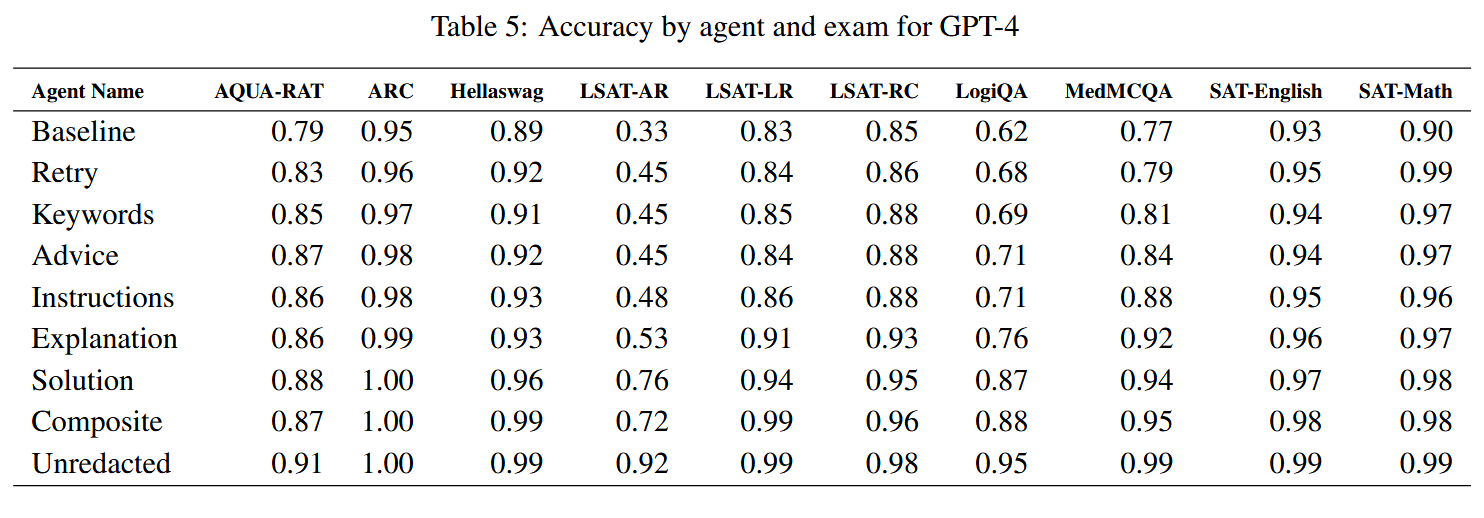
- 不足:
- 只做单步问题:所有题目都是 MCQA(多选题),并非多步推理 /行动选择型(agent 行动),限制了对复杂 agent 场景的直接推广。
- 反思信号用了正确答案 /外部反馈:反思部分是基于知道正确答案的情况,这在实际使用中可能难以获取。即反思是在“有反馈”的前提下进行。若无正确答案或无反馈,效果可能不同。
- 未考虑成本 /延迟:实验以 batch 模式进行,不考虑实际 agent 的延迟或互动流程中反思所需的时间/用户体验成本。
LLM Compiler:并行调用工具
论文标题:An LLM Compiler for Parallel Function Calling
作者:Kim S, Moon S, Tabrizi R, et al. 2024
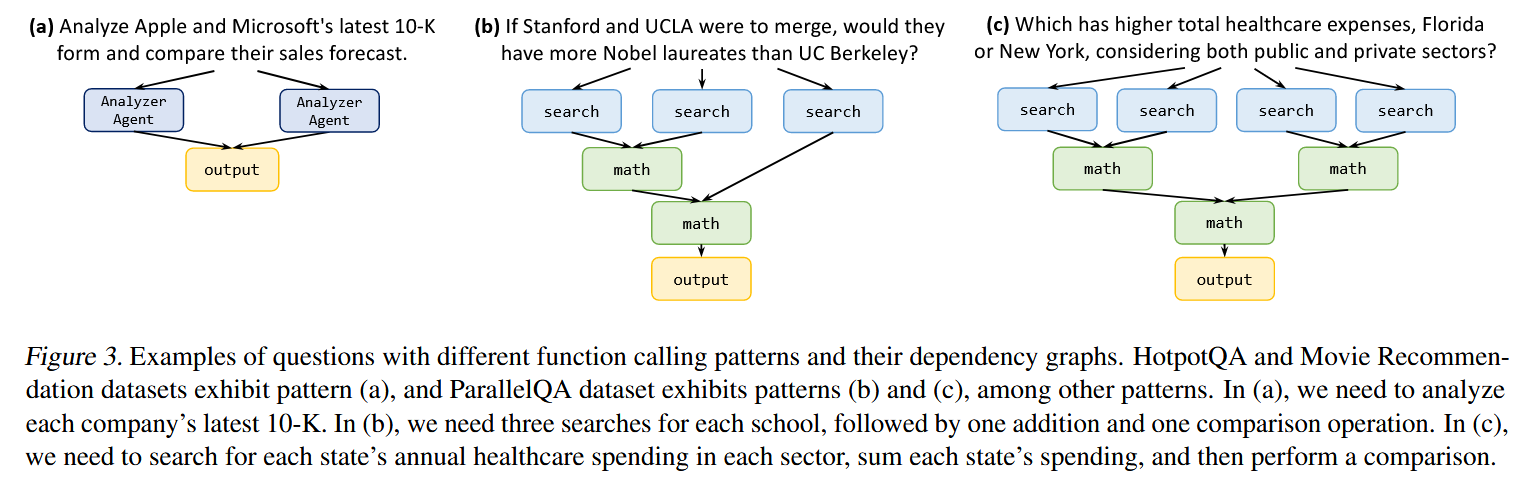
- 贡献: LLM Compiler架构被设计为进一步提升任务执行速度,其核心思想是让Planner生成一个任务的有向无环图(DAG),而非简单的列表 。这个任务图清晰地定义了所有任务、所需的工具、参数以及任务间的依赖关系。一个独立的任务调度单元会根据这个DAG,自动并行执行所有依赖已满足的任务,从而实现最大化的并发执行,提供显著的速度提升 。
- 架构:
- Function Calling Planner: 函数调用规划器负责生成一系列待执行的任务以及它们之间的依赖关系。例如,图2中的任务 $1 和 $2 是两个独立的搜索,可以并行执行。然而,Task $3对第一次和第二次搜索的结果具有依赖性。因此,规划器的作用是利用LLMs复杂的推理能力,自动识别必要的任务及其输入参数以及它们之间的依赖关系,本质上形成了一个任务依赖关系的有向无环图。如果一个任务依赖于前一个任务,那么它包含了一个占位变量,如图2中任务3中的 $1,它将被前一个任务的实际输出所代替。
- Task Fetching Unit: 任务获取单元受现代计算机体系结构中指令获取单元的启发,根据贪婪策略,在任务准备好(并行)执行后,立即将任务获取给执行器。另一个关键的功能是用前面任务的实际输出替换变量,这些变量最初被Planner设置为占位符。以图2为例,将Task $ 3中的变量$ 1和$ 2替换为微软和苹果的实际市场占有率。这可以通过一个简单的取货和排队机制来实现,而不需要专门的LLM。
- Executor: 执行者异步执行从任务获取单元获取的任务。由于任务获取单元保证了分发给执行器的所有任务都是独立的,所以它可以简单地并行执行。执行者配备用户提供的工具,并将任务委托给相关联的工具。这些工具可以是简单的函数,如计算器、维基百科搜索或API调用,甚至可以是为特定任务量身定做的LLM代理。正如图2的Executor模块所描述的,每个任务都有专用的内存来存储它的中间结果,这类似于典型的序列框架在将观测聚合为单个提示时的做法。 当任务完成后,最终结果作为输入转发给依赖它们的任务。
- 动态重规划(Dynamic Replanning):
- Executor 执行当前任务:并行或顺序执行函数调用 DAG 中的任务。
- 收集中间结果:将中间结果发送回 Function Calling Planner。
- Planner 生成新的任务 DAG:根据中间结果重新分析依赖关系、可并行性,可能产生新的任务集合。
- 发送任务给 Task Fetching Unit → Executor:新的任务集进入下一轮执行。
- 循环继续:直到生成最终结果,可以交付给用户。
* 在很多任务中,**中间结果在事前未知**,会影响后续函数调用的顺序或依赖关系。* 类比编程中的 **分支执行(branching)**:if-else 条件在运行时才决定哪条路径被执行。* 对 LLM 的函数调用也会遇到类似情况:某些函数输出可能决定下一步要调用哪些函数。* 简单分支:可以在编译阶段静态生成 DAG,根据中间结果选择分支路径即可。* 复杂分支:静态 DAG 无法涵盖所有可能性,需要 动态重规划 / 重新编译任务图
- 优点:
- 显著提升效率: 并行调用多个函数 / 工具,减少整体执行时间(延迟)相比 ReAct 等顺序执行方法有明显优势。
- 支持复杂任务与多步推理: 动态重规划(Dynamic Replanning)允许根据中间结果调整任务 DAG,适应复杂、分支多的任务场景。
- 提高准确率和可靠性: 并行与重规划结合,减少顺序调用的上下文干扰,保证多步推理或多函数调用的正确性。
- 缺点:
- 规划开销高: Planner 需要分析任务、建立 DAG 并决定可并行性,对于任务复杂或子任务数量多时,会带来额外计算成本。
- 受限于可并行性: 如果任务高度串行或依赖密集,并行优化效果有限,收益可能不明显。
- **动态重规划复杂度高:**中间结果引起的 replanning 会增加系统复杂性,需要处理 DAG 更新、任务调度、异常重试等问题。
- 最慢任务成为瓶颈: 并行执行总体延迟仍受最长执行子任务限制,存在“最长任务阻塞”问题。
- 仍然存在错误传播风险: 如果 Planner 生成的任务图不正确,或中间结果导致依赖判断出错,可能引发整个执行流程错误。
- 实现和工程成本高: 对系统集成、资源调度、并行一致性、异常处理要求高,不适合轻量或实时性强的场景。
和ReAct的区别的图示:
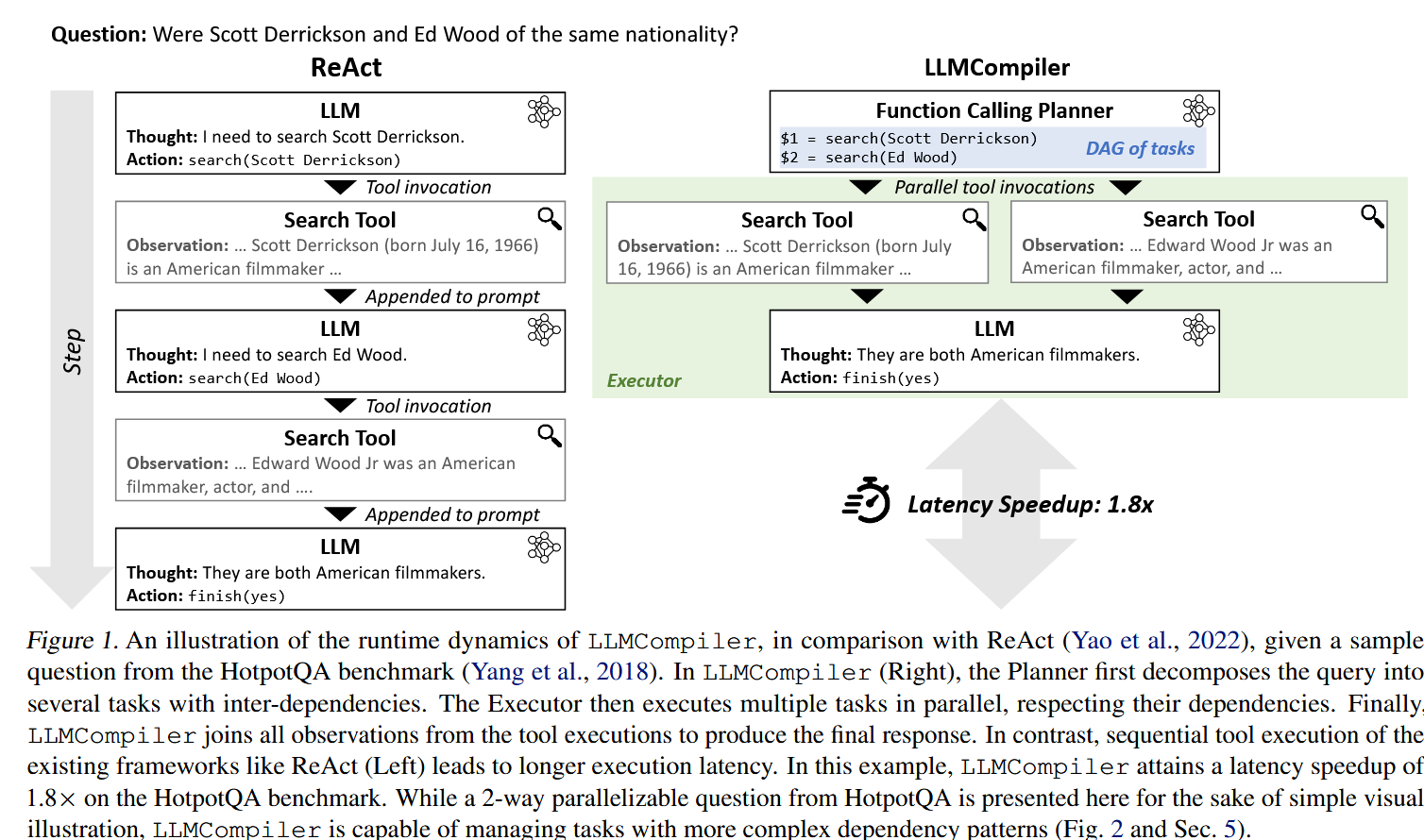
实际流程
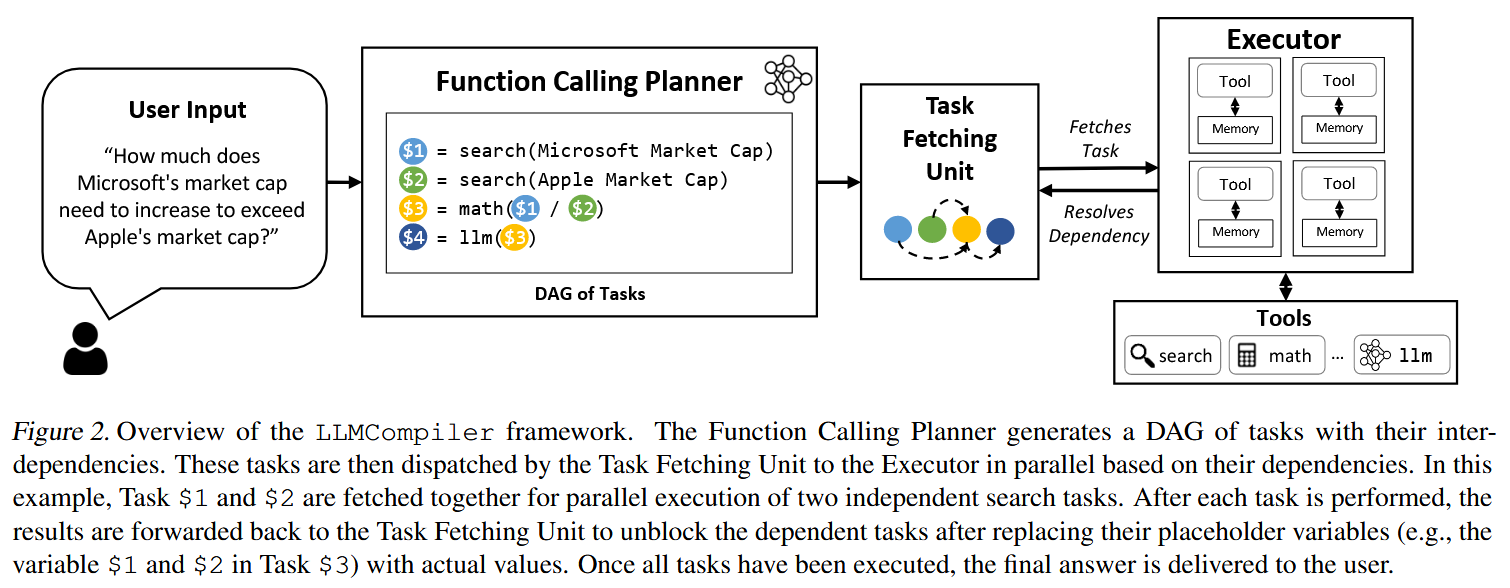
具有不同函数调用模式的试题及其依赖图的示例。