微服务配置中心高可用设计:从踩坑到落地的实战指南(二)
四、容错防护层:用 “熔断降级 + 故障自愈” 解决容错问题(🔧 落地方案)
即使部署和同步做好了,仍会遇到 “网络抖动”“节点临时故障”,此时需要容错机制。
1. 服务端容错:熔断 + 限流(📊 架构图 + 代码)
1.1 容错架构(基于 Resilience4j)

1.2 核心代码:熔断 + 限流配置(💻 基于 Spring Boot)
/\*\*\* 配置中心服务端容错配置(Resilience4j)\*/@Configurationpublic class ConfigServerFaultToleranceConfig {/\*\*\* 1. 限流配置(每秒最多处理1000个请求)\*/@Beanpublic RateLimiter configServerRateLimiter() {RateLimiterConfig config = RateLimiterConfig.custom().limitRefreshPeriod(Duration.ofSeconds(1)) // 刷新周期1秒.limitForPeriod(1000) // 每个周期最多1000个请求.timeoutDuration(Duration.ofMillis(500)) // 请求等待超时500ms.build();return RateLimiter.of("configServerRateLimiter", config);}/\*\*\* 2. 熔断配置(失败率>50%时熔断,熔断后5秒尝试恢复)\*/@Beanpublic CircuitBreaker configServerCircuitBreaker() {CircuitBreakerConfig config = CircuitBreakerConfig.custom().failureRateThreshold(50) // 失败率阈值50%.slidingWindowSize(100) // 滑动窗口大小100个请求.minimumNumberOfCalls(10) // 至少10个请求才计算失败率.waitDurationInOpenState(Duration.ofSeconds(5)) // 熔断打开状态持续5秒.permittedNumberOfCallsInHalfOpenState(5) // 半开状态允许5个请求测试.build();return CircuitBreaker.of("configServerCircuitBreaker", config);}/\*\*\* 3. 全局异常处理(熔断/限流后的降级响应)\*/@RestControllerAdvicepublic class FaultToleranceExceptionHandler {@ExceptionHandler(RateLimiterFullException.class)public ResponseEntity\<ErrorResponse> handleRateLimiter(RateLimiterFullException e) {ErrorResponse response = new ErrorResponse(429, "配置中心限流,请稍后再试");return new ResponseEntity<>(response, HttpStatus.TOO\_MANY\_REQUESTS);}@ExceptionHandler(CircuitBreakerOpenException.class)public ResponseEntity\<ErrorResponse> handleCircuitBreaker(CircuitBreakerOpenException e) {ErrorResponse response = new ErrorResponse(503, "配置中心临时不可用,请稍后再试");return new ResponseEntity<>(response, HttpStatus.SERVICE\_UNAVAILABLE);}}// 错误响应实体@Data@AllArgsConstructorpublic static class ErrorResponse {private int code;private String message;}}
1.3 实战案例:熔断降级的效果(📌 某出行项目)
问题:配置中心因网络抖动,导致部分请求超时(失败率达 60%)。
未熔断前:服务大量超时,导致调用方(如打车派单服务)线程池满,服务熔断。
熔断后:
-
失败率达 50% 时,配置中心自动熔断,返回降级响应;
-
派单服务收到降级响应后,使用本地缓存的旧配置继续运行;
-
5 秒后配置中心进入半开状态,测试 5 个请求均成功,自动恢复正常。
-
最终影响:派单服务无感知,用户打车无延迟。
2. 客户端容错:本地兜底 + 故障自愈(💻 代码 + 流程)
2.1 客户端容错流程(📊 流程图)
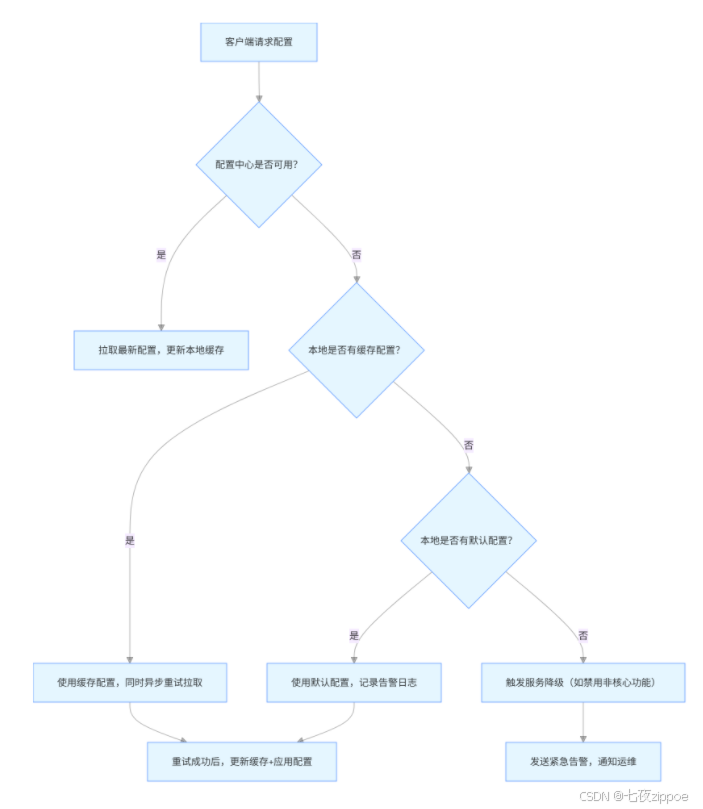
2.2 核心代码:客户端故障自愈(💻 重试 + 告警)
/\*\*\* 配置中心客户端故障自愈组件\*/@Componentpublic class ConfigClientSelfHealingComponent {// 配置中心客户端(如NacosClient)@Resourceprivate ConfigService configService;// 本地缓存(Caffeine)@Resourceprivate LoadingCache\<String, String> localConfigCache;// 告警服务(接入钉钉/企业微信)@Resourceprivate AlertService alertService;// 重试参数(最多5次,间隔1/2/4/8/16秒,指数退避)private static final int MAX\_RETRY\_COUNT = 5;private static final int INITIAL\_RETRY\_DELAY = 1000;/\*\*\* 拉取配置(带故障自愈)\*/public String getConfigWithSelfHealing(String dataId, String group) {try {// 1. 尝试正常拉取(1次)String config = configService.getConfig(dataId, group, 5000);if (config != null) {// 拉取成功,更新本地缓存localConfigCache.put(buildCacheKey(dataId, group), config);return config;}} catch (Exception e) {log.error("拉取配置失败,dataId:{}, group:{}, 开始重试", dataId, group, e);// 2. 重试拉取(指数退避)String config = retryPullConfig(dataId, group);if (config != null) {localConfigCache.put(buildCacheKey(dataId, group), config);return config;}// 3. 重试失败,走兜底逻辑return fallbackConfig(dataId, group);}// 4. 配置为空,走兜底return fallbackConfig(dataId, group);}/\*\*\* 指数退避重试拉取\*/private String retryPullConfig(String dataId, String group) {for (int i = 0; i < MAX\_RETRY\_COUNT; i++) {try {// 重试延迟:1s→2s→4s→8s→16slong delay = INITIAL\_RETRY\_DELAY \* (1 << i);Thread.sleep(delay);log.debug("第{}次重试拉取配置,dataId:{}, 延迟:{}ms", i+1, dataId, delay);String config = configService.getConfig(dataId, group, 5000);if (config != null) {return config;}} catch (Exception e) {log.error("第{}次重试拉取失败,dataId:{}", i+1, dataId, e);// 最后一次重试失败,发送告警if (i == MAX\_RETRY\_COUNT - 1) {alertService.sendAlert("配置拉取重试失败",String.format("dataId:%s, group:%s, 原因:%s", dataId, group, e.getMessage()));}}}return null;}/\*\*\* 兜底配置(本地缓存→默认配置→服务降级)\*/private String fallbackConfig(String dataId, String group) {String cacheKey = buildCacheKey(dataId, group);// 1. 尝试从本地缓存获取try {String cacheConfig = localConfigCache.get(cacheKey);if (cacheConfig != null) {log.warn("使用本地缓存配置,dataId:{}, 配置可能不是最新", dataId);return cacheConfig;}} catch (Exception e) {log.error("获取本地缓存失败,dataId:{}", dataId, e);}// 2. 尝试从本地默认配置获取String defaultConfig = getLocalDefaultConfig(dataId);if (defaultConfig != null) {log.warn("使用本地默认配置,dataId:{}, 请尽快修复配置中心", dataId);alertService.sendAlert("配置中心不可用,已使用默认配置",String.format("dataId:%s, group:%s", dataId, group));return defaultConfig;}// 3. 终极兜底:服务降级(返回空,触发业务降级)log.error("无任何兜底配置,触发服务降级,dataId:{}", dataId);alertService.sendAlert("配置中心完全不可用,已触发服务降级",String.format("dataId:%s, group:%s", dataId, group));return "";}private String buildCacheKey(String dataId, String group) {return group + ":" + dataId;}// 本地默认配置(可放在application-default.yml中)private String getLocalDefaultConfig(String dataId) {// 示例:从Spring环境获取默认配置ConfigurableEnvironment environment = SpringContextHolder.getApplicationContext().getEnvironment();return environment.getProperty("config.default." + dataId);}}
五、监控告警:提前发现问题,避免故障扩大(📊 监控面板 + 配置)
高可用设计的最后一环是 “监控告警”,需覆盖 “节点状态、同步延迟、配置读取成功率” 三大核心指标。
1. 核心监控指标(📊 指标说明)
| 指标类型 | 具体指标 | 正常阈值 | 告警阈值 |
|---|---|---|---|
| 节点状态 | 配置中心节点存活数 | = 部署节点数 | < 部署节点数的 80% |
| 同步延迟 | 跨节点配置同步耗时 | <100ms | >500ms(持续 30 秒) |
| 读取性能 | 配置读取成功率 | >99.9% | <99%(持续 10 秒) |
| 容错状态 | 熔断触发次数 | 0 次 / 分钟 | >10 次 / 分钟 |
| 缓存状态 | 本地缓存命中率 | >95% | <80%(持续 5 分钟) |
2. 监控配置(💻 Prometheus+Grafana)
2.1 Prometheus 指标暴露(基于 Spring Boot Actuator)
\<!-- pom.xml依赖 -->\<dependency>\<groupId>org.springframework.boot\</groupId>\<artifactId>spring-boot-starter-actuator\</artifactId>\</dependency>\<dependency>\<groupId>io.micrometer\</groupId>\<artifactId>micrometer-registry-prometheus\</artifactId>\</dependency>
\# application.yml配置management:endpoints:web:exposure:include: prometheus,health,info # 暴露Prometheus指标端点metrics:tags:application: config-center # 增加应用标签,方便区分endpoint:health:show-details: always # 显示详细健康状态
2.2 自定义监控指标(💻 代码)
/\*\*\* 配置中心自定义监控指标(基于Micrometer)\*/@Componentpublic class ConfigCenterMetrics {// Prometheus指标注册器private final MeterRegistry meterRegistry;// 配置同步延迟指标(直方图,单位:毫秒)private final Timer configSyncTimer;// 配置读取成功率指标(计数器)private final Counter configReadSuccessCounter;private final Counter configReadFailureCounter;@Autowiredpublic ConfigCenterMetrics(MeterRegistry meterRegistry) {this.meterRegistry = meterRegistry;// 1. 配置同步延迟指标(按机房标签区分)this.configSyncTimer = Timer.builder("config.center.sync.duration").description("配置跨节点同步耗时").tags("metric.type", "timer").register(meterRegistry);// 2. 配置读取成功计数器(按应用ID标签区分)this.configReadSuccessCounter = Counter.builder("config.center.read.success").description("配置读取成功次数").tags("metric.type", "counter").register(meterRegistry);// 3. 配置读取失败计数器this.configReadFailureCounter = Counter.builder("config.center.read.failure").description("配置读取失败次数").tags("metric.type", "counter").register(meterRegistry);}/\*\*\* 记录配置同步耗时\*/public \<T> T recordSyncDuration(Supplier\<T> supplier, String room) {// 增加机房标签(如beijing、shanghai)return configSyncTimer.tag("room", room).record(supplier);}/\*\*\* 记录配置读取结果\*/public void recordReadResult(boolean success, String appId) {if (success) {configReadSuccessCounter.tag("appId", appId).increment();} else {configReadFailureCounter.tag("appId", appId).increment();}}}
2.3 Grafana 监控面板(📊 示例)
推荐导入 Grafana 模板(ID:12856,Nacos 监控模板),核心面板包括:
-
节点存活状态:用 “绿色 / 红色” 标识节点是否在线;
-
配置同步延迟:用折线图展示实时延迟,超过阈值标红;
-
读取成功率:用仪表盘展示当前成功率,低于 99% 时告警;
-
熔断次数:用柱状图展示每分钟熔断次数,超过 10 次触发告警。
六、实战总结:配置中心高可用的 “333 原则”(✅ 核心提炼)
经过 3 个项目的落地验证,总结出配置中心高可用的 “333 原则”,确保方案可复用:
1. 3 层部署:基础设施层防单点
-
跨节点集群(3 + 奇数节点);
-
跨机房多活(至少 2 个机房);
-
数据库主从(避免数据存储单点)。
2. 3 个核心功能:数据一致 + 性能
-
推拉结合同步(推模式实时,拉模式兜底);
-
多级缓存(内存 + Redis,提升读取性能);
-
版本号校验(避免同步丢数据、重复同步)。
3. 3 重容错:故障不扩散
-
服务端熔断限流(保护配置中心不被打垮);
-
客户端本地兜底(缓存→默认配置→降级);
-
故障自愈(重试 + 告警,自动恢复)。
结尾:一个思考题(📌 引导实践)
如果你的配置中心需要支持 “10 万级服务节点同时拉取配置”,除了本文提到的方案,还需要优化哪些点?(提示:可从 “配置分片”“批量拉取”“CDN 加速” 三个方向思考,欢迎留言讨论。)