性能怪兽:GPT-5-Codex三大核心进化,重新定义AI编程
近期,OpenAI放出的关于 GPT-5-Codex 的一系列内部评测数据,揭示了这款专为编程而生的新模型在三个核心维度上实现了根本性突破。它不仅在基准测试中超越了前代最强者,更引入了革命性的“动态调整”机制和大师级的代码审查能力,预示着AI编程正从“辅助工具”向“可靠的工程伙伴”迈进。
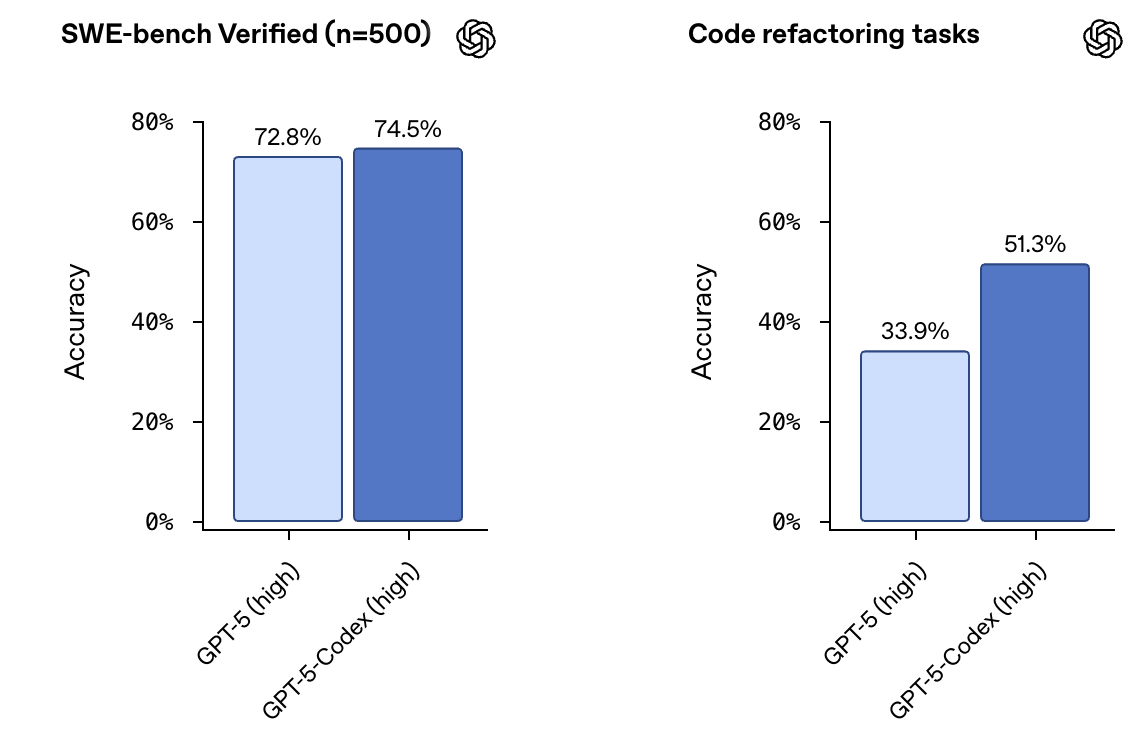
一、性能霸权:基准测试与代码重构,全面超越
最直观的提升体现在硬实力上。在多个权威基准测试中,GPT-5-Codex 的表现均超越了当前最顶尖的 GPT-5-high 模型。
尤其是在代码重构这一极具现实意义的场景中,GPT-5-Codex 的优势被展现得淋漓尽致:
- GPT-5-Codex 准确率:
51.3% - GPT-5-high 准确率:
33.9%
近 17.4个百分点 的巨大领先,意味着它在理解现有代码逻辑、优化结构和修复深层问题上的能力已达到新的高度,这对于维护复杂项目和提升代码质量至关重要。
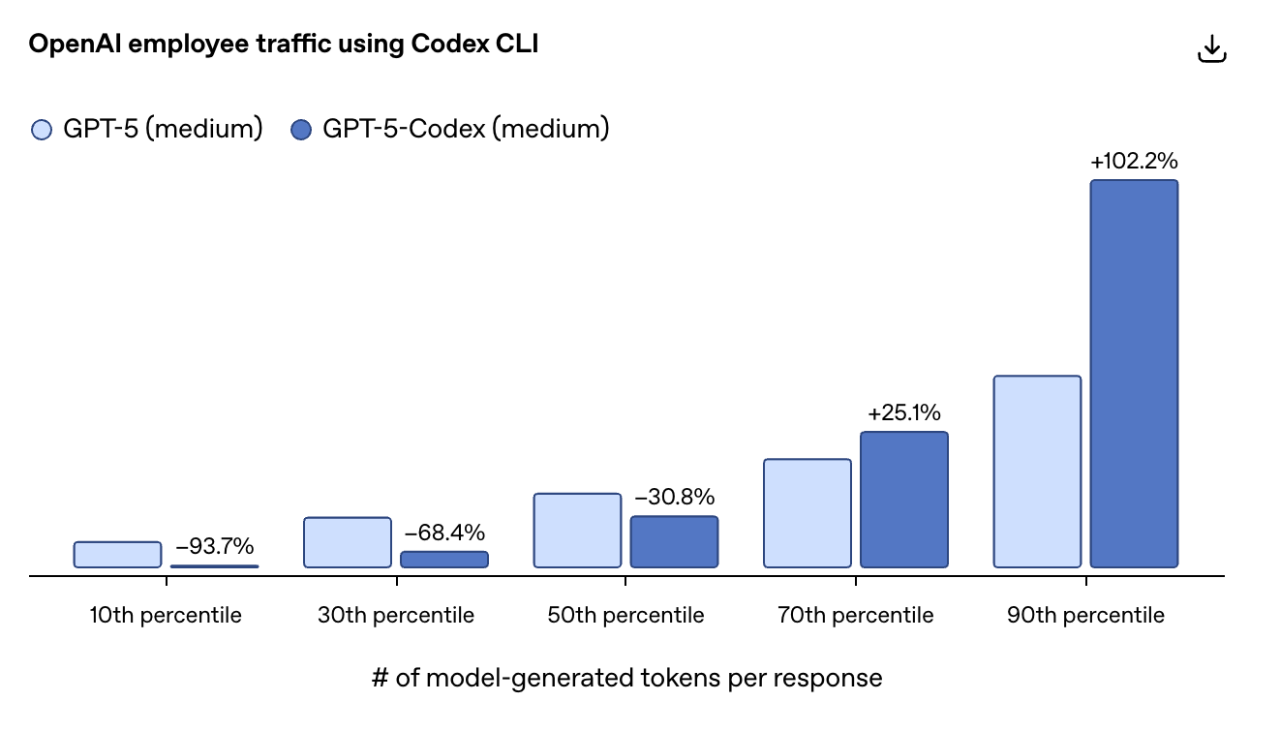
二、智能核心:革命性的“动态资源调整”
本次更新最关键的特性,莫过于赋予了模型“会思考、懂节约”的动态资源调整能力。它能根据任务的复杂度,智能地分配算力,堪称AI界的“能效大师”。
- 对于简单任务(后10%用户请求): 它极度高效。GPT-5-Codex 的Token消耗量(包含所有推理和输出)比 GPT-5 暴降
93.7%。这意味着执行简单、重复性的编码任务时,成本和延迟将大幅降低。 - 对于复杂任务(前10%用户请求): 它则“全力以赴”。模型会投入高达两倍的思考时间,进行更深度的代码推理、编辑、测试和迭代。这意味着在攻克技术难题时,它不再浅尝辄止,而是会进行更深入的分析与尝试。
这种“该省则省,该花则花”的智能机制,完美平衡了效率与效能,让每一次交互都物有所值。
三、工程灵魂:从“码农”到“代码审查专家”
GPT-5-Codex 经过专门的严格训练,其代码审查(Code Review)能力发生了质变,更加贴近资深工程师的思维模式,强调“高影响力”和“聚焦关键”。
数据显示,由它生成的代码审查评论:
- “不正确评论”显著降低: 从
13.7%降至4.4%,废话和误导性建议更少。 - “高影响力评论”显著增加: 从
39.4%提升到52.4%,更能一针见血地指出核心问题。 - 更“聚焦关键重点”: 平均每个PR(Pull Request)提出的评论数从
1.32条降至0.93条。评论虽少,但每一条都更具分量。
这种“此消彼长”的变化,意味着 GPT-5-Codex 正在摆脱早期AI编程工具那种漫无目的、有时甚至干扰性的“Vibe Coding”模式,向着严肃、严谨的工程化编程实践大步迈进。
获取与体验
如此强大的 GPT-5-Codex 现已通过以下渠道提供:
- 官方集成: 模型已集成于 ChatGPT Plus、Pro、Business、Edu 及 Enterprise 订阅计划中。
- API 服务: 计划很快通过 API 对外提供。
- 第三方平台尝鲜: 如 https://open.xiaojingai.com/register?aff=xeu4 等平台已迅速接入了最新的
gpt-5-codex和gpt-5-codex-high模型,并提供免费试用额度,开发者可前往体验。
总而言之,GPT-5-Codex 的发布,是AI编程领域的一个里程碑。它不仅仅是性能的堆砌,更是AI对“如何高效、智能、深入地辅助软件工程”这一问题的全新回答。