【Java八股文】13-中间件面试篇
【Java八股文】13-中间件面试篇
- RabbitMQ
- 什么是消息队列 (MQ)?为什么要使用消息队列?
- 同步通信和异步通信有什么区别?
- RabbitMQ 是什么?它有哪些核心组件?
- 如何保证消息的可靠性?
- RabbitMQ的事务机制
- MQ怎么避免重复消费?
- 什么是死信队列 (DLX)?它有什么作用?
- 什么是延时队列/延迟队列?如何实现延时队列?
- 什么是惰性队列?它解决了什么问题?
- 如何保证Canal+MQ同步消息的顺序性?
- Kafka
- 你说说 Kafka 为什么是高性能的?
- Kafka的使用场景,是否有消息丢失的情况
- RocketMQ、Kafka 和 RabbitMQ
- Elasticsearch
- 什么是 Elasticsearch?它与 MySQL 有什么区别?
- 什么是倒排索引?在 Elasticsearch 中作用?
- 倒排索引构建过程
- Elasticsearch 中什么是索引 (Index)?文档 (Document)?
- 如何保证 MySQL 和 Elasticsearch 数据同步?
- Canal+MQ如何同步商品信息到ES中?
- Docker
- Docker和传统虚拟机有什么区别?
- Docker 和 k8s 之间是什么关系?
- Dockerfile和DockerCompose
- Git
- git使用工作流程
- git merge 、git rebase、 git fetch的区别
RabbitMQ
什么是消息队列 (MQ)?为什么要使用消息队列?
消息队列 (Message Queue - MQ) 是一种异步通信机制,允许不同的应用程序或服务通过消息进行解耦和通信。 使用 MQ 的主要原因包括:
- 解耦 (Decoupling): 服务之间不再需要直接依赖,降低系统耦合度。
- 异步 (Asynchronous): 发送者无需等待接收者处理完成,提高系统响应速度和吞吐量。
- 削峰填谷 (Buffering/Peak Shaving): 应对突发流量,避免系统过载。
- 可靠性 (Reliability): 确保消息传递的可靠性,即使接收者暂时不可用。
- 流量整形 (Traffic Shaping): 控制消息处理速度,避免下游服务被压垮。
同步通信和异步通信有什么区别?
- 同步通信 (Synchronous): 请求发出后,发送者必须等待接收者响应才能继续执行。类似于打电话,需要对方接听并回应。 问题: 阻塞等待,效率低,依赖性强。
- 异步通信 (Asynchronous): 请求发出后,发送者无需等待接收者响应,可以继续执行其他任务。接收者会在稍后处理请求并通知发送者 (通常通过回调或消息)。类似于发短信,发送后无需等待回复。 优点: 高效,解耦,非阻塞。
RabbitMQ 是什么?它有哪些核心组件?
RabbitMQ 是一个开源的消息队列中间件,基于 AMQP (高级消息队列协议) 实现。 核心组件包括:
- Broker: RabbitMQ 服务本身,负责接收、存储和路由消息。
- Exchange (交换机): 接收生产者发送的消息,并根据路由规则将消息路由到一个或多个队列。
- Queue (队列): 存储消息的地方,等待消费者来消费。
- Binding (绑定): Exchange 和 Queue 之间的关联关系,定义了消息如何被路由到队列。
- Producer (生产者): 发送消息到 Exchange 的应用程序。
- Consumer (消费者): 从 Queue 接收消息并进行处理的应用程序。
- Virtual Host (vhost): 虚拟主机,用于逻辑隔离 RabbitMQ 实例,可以创建多个 vhost,每个 vhost 拥有独立的 Exchange、Queue 和 Binding。
如何保证消息的可靠性?
消息可靠性通常从生产者、MQ Broker 和消费者三个方面考虑:
- 生产者消息确认机制 (Producer Confirmation):
- Publisher Confirm (发布确认): 生产者发送消息后,MQ Broker 返回确认 (ACK) 或拒绝 (NACK),生产者根据结果判断消息是否成功发送到 Broker。
- Publisher Returns (发布回退): 当消息成功到达 Exchange,但 Exchange 无法路由到任何队列时,Broker 会将消息退回给生产者 (需要设置 mandatory 参数)。
- 消息持久化 (Message Persistence):
- 队列持久化: 声明队列时设置为持久化,即使 RabbitMQ 重启,队列元数据也不会丢失。
- 消息持久化: 发送消息时设置为持久化,消息会被写入磁盘,即使 RabbitMQ 服务崩溃重启,消息也不会丢失 (但会牺牲一些性能)。
- 消费者确认机制 (Consumer Acknowledgement - ACK):
- 手动 ACK (Manual Acknowledgement): 消费者在成功处理消息后,手动发送 ACK 给 RabbitMQ Broker。 如果消费者在处理消息过程中崩溃或未发送 ACK,Broker 会将消息重新投递给其他消费者或重回队列。
- 自动 ACK (Auto Acknowledgement): 消费者接收到消息后,RabbitMQ Broker 立即认为消息已被成功消费 (存在消息丢失风险,不推荐用于高可靠场景)。
- 失败重试机制 (Retry Mechanism): 消费者消费消息失败时,可以进行重试。
RabbitMQ的事务机制
RabbitMQ 的事务是通过 Channel 的事务性 (Transactional Channel) 来实现的。 我们可以通过以下步骤开启和使用事务:
- 将 Channel 设置为事务模式: 通过 channel.txSelect() 命令将当前的 Channel 设置为事务模式。
- 执行消息发布操作: 在事务模式下,我们像正常一样使用 channel.basicPublish() 发布消息。
- 提交事务或回滚事务:
- channel.txCommit(): 如果消息发布成功,并且我们希望提交事务,就调用 txCommit()。 这会告知 Broker 提交当前事务内的所有操作 (例如,消息发布)。
- channel.txRollback(): 如果在消息发布过程中发生任何错误,或者我们想取消本次发布,就调用 txRollback()。 这会告知 Broker 回滚当前事务内的所有操作。
MQ怎么避免重复消费?
- 需要保证MQ消费消息的幂等性。使用数据库的唯一约束去控制。添加唯一索引保证添加数据的幂等性
- 使用token机制发送消息时给消息指定一个唯一的ID,发送消息时将消息ID写入Redis消费时根据消息ID查询Redis判断是否已经消费,如果已经消费则不再消费。
什么是死信队列 (DLX)?它有什么作用?
死信队列 (Dead Letter Exchange - DLX) 是一种特殊的 Exchange,用于接收无法被正常消费的消息 (死信消息)。 死信消息通常是因为以下原因产生的:
- 消息被拒绝 (basic.reject 或 basic.nack) 且 requeue=false
- 消息 TTL (Time-To-Live) 过期
- 队列达到最大长度
作用: DLX 可以用来处理消费失败的消息,例如:
- 消息重试: 将死信消息重新投递到另一个队列进行重试。
- 错误日志记录和分析: 将死信消息存储到数据库或日志系统,进行后续分析和排查问题。
- 补偿机制: 对于一些关键业务消息,消费失败后可以进行人工干预或补偿处理。什么是延时队列/延迟队列?如何实现延时队列?
什么是延时队列/延迟队列?如何实现延时队列?
延时队列/延迟队列 (Delayed Queue) 是一种消息在发送后不会立即被消费,而是延迟一段时间后才被消费的队列。 常用于实现定时任务、订单超时取消等功能。
实现方式 (根据 outline):
- TTL + DLX (Time-To-Live + Dead Letter Exchange):
- 声明一个 延迟队列 (设置消息 TTL)。
- 声明一个 死信交换机 (DLX) 和 死信队列 (DLQ)。
- 将 延迟队列 的 死信交换机 设置为 DLX, 死信路由键 设置为 DLQ 的路由键。
- 生产者发送消息到 延迟队列,并设置消息的 TTL。
- 当消息 TTL 过期 后,RabbitMQ 会将消息 投递到 DLX,DLX 根据路由键将消息 路由到 DLQ。
- 消费者 监听 DLQ,接收延迟消息并进行处理。
- RabbitMQ Delay Exchange Plugin: RabbitMQ 官方提供的 Delay Exchange 插件,提供了更方便的延时队列实现。 可以通过设置消息头来指定消息的延迟时间。
什么是惰性队列?它解决了什么问题?
惰性队列 (Lazy Queue) 是 RabbitMQ 提供的一种 特殊的队列类型,用于解决 消息堆积问题。
问题: 默认的 RabbitMQ 队列 (经典队列) 会将消息尽可能地 保存在内存中,以提高性能。 当队列中消息堆积过多时,会 占用大量内存,可能导致 RabbitMQ 性能下降甚至崩溃。
惰性队列的特点: 惰性队列会将 消息尽可能地写入磁盘,只有在消费者需要消费时才加载到内存中。
- 优点: 可以 存储大量消息,减少内存占用,避免内存溢出。
- 缺点: 消息存取性能会下降,吞吐量降低。
如何保证Canal+MQ同步消息的顺序性?
Canal解析binlog日志信息按顺序发到MQ的队列中。现在是要保证消费端如何按顺序消费队列中的消息。
解决方法:
- 多个jvm进程监听同一个队列保证只有消费者活跃,即只有一个消费者接收消息。
- 队列需要增加x-single-active-consumer参数,值为true,表示否启用单一活动消费者模式。
- 消费队列中的数据使用单线程。
- 在监听队列的java代码中指定消费线程为1
Kafka
你说说 Kafka 为什么是高性能的?
- 顺序写入:它将消息按顺序写入磁盘,避免了随机写入带来的性能瓶颈。
- 零拷贝:Kafka 使用零拷贝技术,直接从磁盘传输数据到网络,减少了内存复制,提高了效率。
- 分区并行:数据分成多个分区,多个消费者可以并行读取,提升处理速度。
- 批量处理:Kafka 支持批量消息写入和读取,减少了网络和磁盘操作的开销。
Kafka的使用场景,是否有消息丢失的情况
- 实时数据流处理:Kafka 常用于处理实时数据流,如日志收集、监控数据传输、点击流分析等。
- 日志聚合:它可以收集来自不同系统的日志,统一传输到中心化的日志存储或分析系统。
- 事件源架构:用于在微服务架构中传递事件,确保不同服务之间的通信。
- 消息队列:作为高吞吐量、高可用性的消息队列,支持异步消息处理。
- 数据管道:Kafka 作为流数据平台,通常用于将数据从一个系统传输到另一个系统,像数据库同步、ETL等。
RocketMQ、Kafka 和 RabbitMQ
- Kafka:Kafka 是基于 分区(Partition)和 副本(Replication)设计的分布式消息队列。它使用一个 发布-订阅 模型,生产者将消息写入到主题(Topic)中的分区,消费者可以根据分区消费消息。只支持 发布-订阅 模式。
- 优点:超高吞吐量,适合大规模数据流和实时处理。
- 适用场景:日志聚合、流处理、大数据分析。
- 缺点:不支持复杂的路由机制,消息顺序只保证在分区内。
- RocketMQ:RocketMQ 也采用分布式架构,支持 主题(Topic) 和 队列(Queue)。消息可以被多个消费者消费,也支持严格的 顺序消息、事务消息 和 定时消息。支持 发布-订阅 和 点对点 两种模式,允许同一个消息被多个消费者消费,适合广播消息。
- 优点:支持事务消息、顺序消息、消息精确一次投递。
- 适用场景:金融、电商等需要高可靠性、顺序消费和事务的场景。
- 缺点:性能稍逊于 Kafka,配置较复杂。
- RabbitMQ:RabbitMQ 使用 AMQP(Advanced Message Queuing Protocol) 协议,采用 交换机(Exchange) 和 队列(Queue) 的模式,消息通过交换机路由到队列,消费者从队列中获取消息。支持 发布-订阅、点对点 和 工作队列 等多种消息模型,适用于各种灵活的消息传递场景。
- 优点:支持多种协议,灵活的消息路由(如交换机),适合多种消费模式。
- 适用场景:小到中规模应用,微服务架构,复杂路由需求。
- 缺点:吞吐量和性能不如 Kafka 和 RocketMQ,延迟稍高。
Elasticsearch
什么是 Elasticsearch?它与 MySQL 有什么区别?
Elasticsearch (ES) 是 分布式、RESTful 的搜索和分析引擎,基于 Lucene 构建。 与 MySQL 的区别:
- 数据结构: MySQL 结构化 (行/列),ES 半/非结构化 (JSON 文档)。
- 主要用途: MySQL 事务数据、结构化查询;ES 搜索、分析、日志。
- 索引: MySQL B-tree 索引;ES 倒排索引 (全文搜索快)。
- 扩展性: MySQL 垂直扩展为主;ES 水平扩展 (分布式) 容易。
- 查询语言: MySQL SQL;ES DSL (JSON, RESTful API)。
什么是倒排索引?在 Elasticsearch 中作用?
倒排索引是 词 (Term) 到文档的映射。
- 传统索引: 文档 -> 词列表 (找包含词的文档 - 慢)。
- 倒排索引: 词 -> 文档列表 (找文档中的词 - 快)。
ES 中的作用:
- 分析文档: 索引时分析文本字段 (分词等)。
- 建倒排索引: 词指向包含它的文档 ID 列表。
- 快速全文搜索: 搜索时查倒排索引快速找文档。
倒排索引(Inverted Index)是搜索引擎中常用的一种数据结构,目的是为了高效地进行文本搜索。具体到 Elasticsearch(ES),倒排索引用于存储文档中各个词项(词语)及其出现位置,以便快速查找包含某个词的文档。
倒排索引的基本原理:
- 词项(Term):文档中的每个单词或短语。
- 文档(Document)

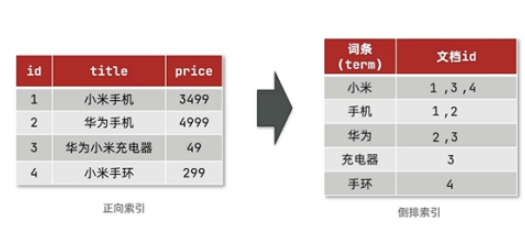
倒排索引构建过程
- 文档索引:每个文档被拆分成多个词项,这些词项会被映射到文档上。
- 查询:当你执行查询时,ES 会通过倒排索引找到包含查询词项的文档,快速返回搜索结果。
- 反向分析:ES 在搜索时,首先将查询的词进行分析和分词,然后用倒排索引查找匹配的文档。
Elasticsearch 中什么是索引 (Index)?文档 (Document)?
- 索引 (Index):
- 文档的逻辑分组,类似 MySQL 的数据库或表。
- 定义文档的 Mapping (schema)。
- 文档 (Document):
- JSON 对象,存储在索引中,类似 MySQL 的行。
- 包含字段 (键值对),值可以是不同数据类型。
- 同索引的文档结构可以略有不同 (灵活 Schema)。
如何保证 MySQL 和 Elasticsearch 数据同步?
常用 消息队列 (MQ) - RabbitMQ 同步数据:
- MySQL 变更 -> 事件: MySQL 数据变动时生成事件 (触发器、Debezium 或程序逻辑)。
- 发布事件到 MQ (RabbitMQ): 事件发到 RabbitMQ 队列。
- ES 消费者服务: 专门服务消费 MQ 消息。
- 更新 Elasticsearch: 消费者服务处理事件,更新 ES 文档。
MQ 同步优势: 异步、可靠、可扩展。
Canal+MQ如何同步商品信息到ES中?
- 首先在Elasticsearch中创建商品的索引结构,包括商品的spu信息、sku信息,这样输入关键字可以根据商品的spu去搜索也可以根据商品的sku去搜索。
- 在MySQL中创建一张商品信息同步表,当修改商品信息时同时修改商品信息同步表,商品信息同步表的结构与Elasticsearch中的商品索引是一致的。
- Canal会读取商品信息同步表的binlog日志,解析日志的内容写入MQ。
- 同步程序监听MQ,收到商品的信息后写入Elasticsearch,这样就完成了同步商品信息到ES中。
Docker
Docker和传统虚拟机有什么区别?
- 架构:
- 虚拟机:虚拟机在物理服务器上运行一个完整的操作系统,每个虚拟机都有自己的操作系统(包括内核)。
- Docker:Docker 是基于容器的,容器共享宿主操作系统的内核,但它们运行自己的用户空间。
- 资源利用:
- 虚拟机:虚拟机需要分配一部分硬件资源(如 CPU、内存、硬盘等)给每个虚拟机操作系统
- Docker:Docker 容器利用宿主机的操作系统内核,资源消耗相对较少。
- 启动时间:
- 虚拟机:启动虚拟机需要加载完整的操作系统,通常需要几分钟时间。
- Docker:Docker 容器利用宿主操作系统内核,启动速度非常快,通常只需要几秒钟。
- 隔离性:
- 虚拟机:虚拟机提供更强的隔离性,因为每个虚拟机都有独立的操作系统和内核。
- Docker:Docker 容器提供了相对较弱的隔离性,因为容器共享宿主机的内核,但容器之间通过命名空间和控制组进行隔离。
- 灵活性和可移植性:
- 虚拟机:虚拟机的迁移和部署较为复杂,因为每个虚拟机都是一个完整的操作系统,迁移时需要确保目标主机的资源和配置匹配。
- Docker:Docker 容器是独立于操作系统的,它们可以在任何支持 Docker 的平台上运行,极大地提高了应用的可移植性和灵活性。
- 使用场景:
- 虚拟机:适用于需要完全隔离的环境,或者需要不同操作系统的场景。常用于数据中心、虚拟化环境。
- Docker:适用于微服务架构、开发和测试环境。由于 Docker 容器更轻便,广泛应用于 DevOps、持续集成/持续部署(CI/CD)等场景。
Docker 和 k8s 之间是什么关系?
Docker 和 Kubernetes(K8s)是密切相关的,但它们的功能不同:
- Docker:是一个容器化平台,用于打包、分发和运行应用。它提供了创建、管理和运行容器的工具。容器可以理解为轻量级的虚拟机,但它们共享宿主操作系统的内核。
- Kubernetes(K8s):是一个容器编排平台,用于自动化容器的部署、扩展和管理。它可以帮助管理多个 Docker 容器,处理容器的生命周期、调度、负载均衡等任务。
Docker 是 K8s 使用的容器运行时(container runtime)。也就是说,K8s 管理和调度的是 Docker 容器的实例。K8s 可以启动、停止和扩展 Docker 容器,但它不提供容器创建的功能,那个是由 Docker 提供的。
Docker 用于创建和运行容器,K8s 用于管理多个 Docker 容器的集群。
Dockerfile和DockerCompose
- Dockerfile就是一个文本文件,其中包含一个个的指令(Instruction),用指令来说明要执行什么操作来构建镜像。每一个指令都会形成一层Layer。
FROM指定基础镜像From Ubuntu:22.04ENV指令用来设置环境变量。这些环境变量将在容器中运行时保持有效。COPY:将本地文件复制到镜像中。RUN:用于执行命令,通常用于安装软件包或者执行其他操作来构建镜像。EXPOSE:声明容器需要开放的端口。ENTRYPOINT指令用于设置容器启动时默认执行的命令。
# 指定基础镜像
FROM java:8-alpine
# # 配置环境变量,JDK的安装目录
# ENV JAVA_DIR=/usr/local# # 拷贝jdk和java项目的包
# COPY ./jdk8.tar.gz $JAVA_DIR/ # # 安装JDK
# RUN cd $JAVA_DIR \
# && tar -xf ./jdk8.tar.gz \
# && mv ./jdk1.8.0_144 ./java8# # 配置环境变量
# ENV JAVA_HOME=$JAVA_DIR/java8
# ENV PATH=$PATH:$JAVA_HOME/binCOPY ./docker-demo.jar /tmp/app.jar# 暴露端口
EXPOSE 8090
# 入口,java项目的启动命令
ENTRYPOINT java -jar /tmp/app.jar
- Docker Compose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器!Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。
version: "3.2"services:nacos:image: nacos/nacos-serverenvironment:MODE: standaloneports:- "8848:8848"mysql:image: mysql:5.7.25environment:MYSQL_ROOT_PASSWORD: 123sjbsjbvolumes:- "$PWD/mysql/data:/var/lib/mysql"- "$PWD/mysql/conf:/etc/mysql/conf.d/"userservice:build: ./user-serviceorderservice:build: ./order-servicegateway:build: ./gatewayports:- "10010:10010"Git
git使用工作流程
工作流程步骤:
- 从
master分支创建一个新的功能分支
git checkout -b feature-branch
- 在功能分支上进行开发和提交
git add . # 添加更改
git commit -m "feature: add new feature" # 提交更改
- 保持功能分支与
master分支同步在功能开发过程中,定期将 master分支的最新更改合并到功能分支,以防止冲突。
git checkout master # 切换到主分支
git pull origin master # 拉取最新的 master
git checkout feature-branch
git merge master # 将 master 的更新合并到 feature 分支
- 功能完成后将功能分支合并到
master分支
git checkout master
git merge feature-branch
- 推送到远程仓库并删除功能分支
git push origin master # 推送更新到远程仓库
git branch -d feature-branch # 删除本地功能分支
git push origin --delete feature-branch # 删除远程功能分支
优点:每个功能开发都在独立的分支中进行,避免了不同功能的代码干扰。
缺点:需要频繁合并,管理多个分支可能稍显复杂。
git merge 、git rebase、 git fetch的区别
| 命令 | 作用 | 特点 |
|---|---|---|
git merge | 将两个分支的更改合并 | 保留分支历史,产生合并提交 |
git rebase | 将一个分支的提交重放到另一个分支上 | 重写历史,产生线性历史 |
git fetch | 从远程仓库拉取最新的提交和元数据 | 不修改本地工作区,只更新远程跟踪分支 |
- 使用
git merge时,你的分支历史会保留原样,适合保留不同开发路径的痕迹。 - 使用
git rebase时,历史会变得更整洁,适合在合并前清理历史。 - 使用
git fetch时,只有从远程仓库拉取数据,并不会对本地分支产生直接影响。