【机器学习】搭建对抗神经网络模型来实现 MNIST 手写数字生成
【机器学习】搭建对抗神经网络模型来实现 MNIST 手写数字生成
简介
本文将从 GAN 的核心原理出发,结合完整的 TensorFlow 代码实现,从零搭建一个能生成 MNIST 手写数字的 GAN 模型。
模型介绍
2014 年由 Ian Goodfellow 提出的 GAN,凭借其独特的 “对抗训练” 思想,彻底改变了生成式模型的发展格局。它通过两个神经网络的动态博弈 —— 一个负责 “造假” 的生成器,一个负责 “鉴假” 的判别器 —— 最终让 AI 学会生成足以以假乱真的数据。
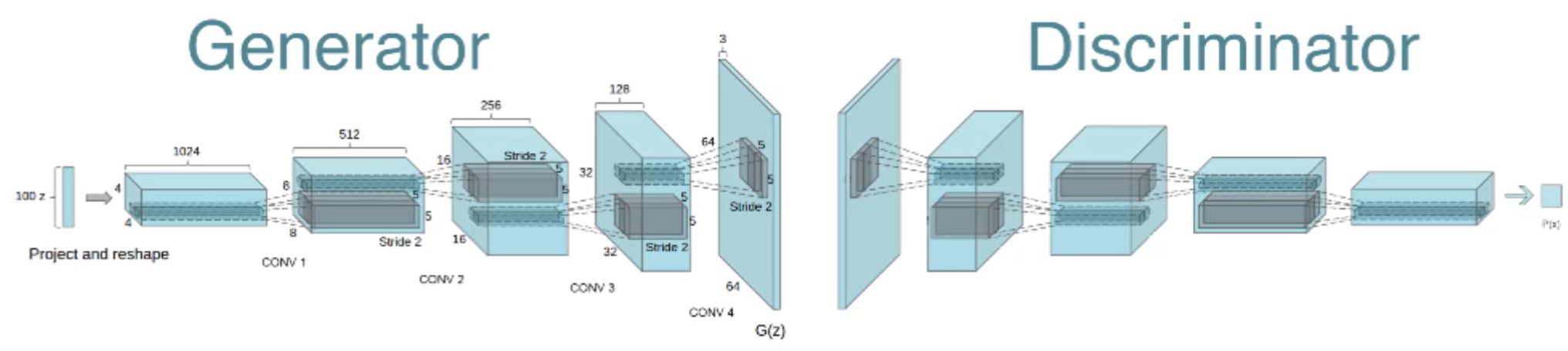
GAN的本质是两个神经网络的对抗性训练过程,其核心逻辑如下:
1. 两大核心角色
①.生成器(Generator):输入随机噪声向量,通过神经网络的层层处理,生成试图模仿真实数据的 “假样本”(本文中为手写数字图像)。
②.判别器(Discriminator):输入图像(真实样本或生成器造的假样本),输出该图像为 “真实数据” 的概率,本质是一个二分类模型。
2. 对抗训练流程
GAN 的训练过程就是一场持续升级的博弈:
①.初始状态:生成器生成的图像模糊不清,判别器也难以准确区分真假。
②.第一轮博弈:判别器学习区分 “真实 MNIST 图像” 和 “生成器的劣质假图像”,能力逐渐提升。
③.第二轮博弈:生成器根据判别器的 “反馈”(损失值)调整参数,生成更逼真的图像试图欺骗判别器。
④.循环迭代:两者交替优化,直到生成器能生成判别器难以分辨的假图像,达到 “纳什均衡” 状态。
3. 损失函数设计
对抗训练的核心是通过损失函数引导两个网络进化:
①.生成器损失:希望判别器将假图像判定为 “真实”(标签为 1),用交叉熵损失衡量 “欺骗成功率”。
②.判别器损失:希望准确区分真实图像(标签为 1)和假图像(标签为 0),总损失为 “误判真实图像” 和 “误判假图像” 的损失之和。
数据集来源
选用经典的 MNIST 手写数字数据集,它包含 60000 张 28×28 的灰度训练图像和 10000 张测试图像,数据规模小且易于训练,非常适合 GAN 入门。
导入库与初始化参数
首先导入必要的工具库,并定义模型训练的核心超参数:
# 忽略警告信息
import warnings
warnings.filterwarnings("ignore")
# 导入核心库
import tensorflow as tf
from tensorflow.keras import Model, layers
import numpy as np
import matplotlib.pyplot as plt
# 数据相关参数
num_features = 784 # 28×28×1,MNIST图像展平后的特征数
# 训练超参数
lr_generator = 0.0002 # 生成器学习率
lr_discriminator = 0.0002# 判别器学习率
training_steps = 20000 # 总训练步数
batch_size = 128 # 批次大小
display_step = 500 # 每500步展示一次训练进度
# 生成器输入:随机噪声向量维度
noise_dim = 100
数据加载与预处理
加载MNIST数据集并进行标准化处理,确保数据分布与生成器输出匹配:
# 加载MNIST数据集
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据类型转换:转为float32以适配TensorFlow计算
x_train, x_test = np.array(x_train, np.float32), np.array(x_test, np.float32)
# 归一化:将像素值从[0,255]缩放到[0,1]
x_train, x_test = x_train / 255., x_test / 255.
# 构建TensorFlow数据管道:支持批量加载、打乱和预取
train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# 重复迭代+打乱数据+按批次划分+预取1批数据加速训练
train_data = train_data.repeat().shuffle(10000).batch(batch_size).prefetch(1)
构建生成器(Generator)
生成器的任务是将 100 维随机噪声转换为 28×28 的灰度图像,核心使用转置卷积(Conv2DTranspose) 实现 “上采样”(从低分辨率到高分辨率):
class Generator(Model):def __init__(self):super(Generator, self).__init__()# 全连接层:将100维噪声映射为7×7×128的特征向量self.fc1 = layers.Dense(7 * 7 * 128)self.bn1 = layers.BatchNormalization() # 批归一化:加速收敛并稳定训练# 转置卷积1:将7×7×128放大为14×14×64(步长2实现翻倍)self.conv2tr1 = layers.Conv2DTranspose(64, 5, strides=2, padding='SAME')self.bn2 = layers.BatchNormalization()# 转置卷积2:将14×14×64放大为28×28×1(最终图像尺寸)self.conv2tr2 = layers.Conv2DTranspose(1, 5, strides=2, padding='SAME')def call(self, x, is_training=False):# 前向传播:从噪声到图像x = self.fc1(x)x = self.bn1(x, training=is_training) # 训练时启用批归一化更新x = tf.nn.leaky_relu(x) # LeakyReLU:避免ReLU的梯度消失问题# 重塑为4D张量(批次大小, 高, 宽, 通道数)x = tf.reshape(x, shape=[-1, 7, 7, 128])# 第一次上采样:7×7→14×14x = self.conv2tr1(x)x = self.bn2(x, training=is_training)x = tf.nn.leaky_relu(x)# 第二次上采样:14×14→28×28x = self.conv2tr2(x)x = tf.nn.tanh(x) # tanh激活:输出范围[-1,1],与后续数据处理匹配return x
构建判别器(Discriminator)
判别器是一个二分类卷积神经网络,通过下采样卷积提取图像特征,最终判断输入是“真实图像”还是“生成图像”:
class Discriminator(Model):def __init__(self):super(Discriminator, self).__init__()# 卷积1:28×28×1→14×14×64(步长2实现下采样)self.conv1 = layers.Conv2D(64, 5, strides=2, padding='SAME')self.bn1 = layers.BatchNormalization()# 卷积2:14×14×64→7×7×128self.conv2 = layers.Conv2D(128, 5, strides=2, padding='SAME')self.bn2 = layers.BatchNormalization()self.flatten = layers.Flatten() # 展平特征为一维向量# 全连接层:提取高层特征self.fc1 = layers.Dense(1024)self.bn3 = layers.BatchNormalization()self.fc2 = layers.Dense(2) # 输出层:2个神经元对应二分类(真假)def call(self, x, is_training=False):# 前向传播:从图像到真假判断# 重塑输入为4D张量(适配卷积层)x = tf.reshape(x, [-1, 28, 28, 1])# 第一次下采样与特征提取x = self.conv1(x)x = self.bn1(x, training=is_training)x = tf.nn.leaky_relu(x)# 第二次下采样与特征提取x = self.conv2(x)x = self.bn2(x, training=is_training)x = tf.nn.leaky_relu(x)# 展平后通过全连接层x = self.flatten(x)x = self.fc1(x)x = self.bn3(x, training=is_training)x = tf.nn.leaky_relu(x)# 不使用激活函数:后续在损失函数中结合softmaxreturn self.fc2(x)
# 创建网络模型
generator = Generator() # 创建生成器
discriminator = Discriminator() # 创建判别器
定义损失函数与优化器
根据GAN的对抗逻辑设计损失函数,并为生成器和判别器分别配置优化器:
# 生成器损失:希望判别器将假图像判为真实(标签1)
def generator_loss(disc_fake):gen_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=disc_fake, labels=tf.ones([batch_size], dtype=tf.int32)))return gen_loss# 判别器损失:真实图像判为1,假图像判为0
def discriminator_loss(disc_fake, disc_real):# 误判真实图像的损失disc_loss_real = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=disc_real, labels=tf.ones([batch_size], dtype=tf.int32)))# 误判假图像的损失disc_loss_fake = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=disc_fake, labels=tf.zeros([batch_size], dtype=tf.int32)))return disc_loss_real + disc_loss_fake# 优化器:使用Adam,GAN训练常用β1=0.5(注释中保留常用配置)
optimizer_gen = tf.optimizers.Adam(learning_rate=lr_generator)#, beta_1=0.5)
optimizer_disc = tf.optimizers.Adam(learning_rate=lr_discriminator)#, beta_1=0.5)
实现对抗训练逻辑
GAN的训练需要交替优化判别器和生成器:先训练判别器区分真假样本,再训练生成器欺骗判别器。使用tf.GradientTape记录梯度计算过程:
def run_optimization(real_images):# 数据对齐:将真实图像从[0,1]转为[-1,1],匹配生成器输出real_images = real_images * 2. - 1.# 生成生成器的输入噪声(正态分布)noise = np.random.normal(-1., 1., size=[batch_size, noise_dim]).astype(np.float32)# 第一步:训练判别器with tf.GradientTape() as g:# 生成假图像fake_images = generator(noise, is_training=True)# 判别器分别判断假图像和真实图像disc_fake = discriminator(fake_images, is_training=True)disc_real = discriminator(real_images, is_training=True)# 计算判别器损失disc_loss = discriminator_loss(disc_fake, disc_real)# 计算梯度并更新判别器参数gradients_disc = g.gradient(disc_loss, discriminator.trainable_variables)optimizer_disc.apply_gradients(zip(gradients_disc, discriminator.trainable_variables))# 第二步:训练生成器(重新生成噪声,避免依赖上一轮噪声)noise = np.random.normal(-1., 1., size=[batch_size, noise_dim]).astype(np.float32)with tf.GradientTape() as g:fake_images = generator(noise, is_training=True)disc_fake = discriminator(fake_images, is_training=True)# 计算生成器损失gen_loss = generator_loss(disc_fake)# 计算梯度并更新生成器参数gradients_gen = g.gradient(gen_loss, generator.trainable_variables)optimizer_gen.apply_gradients(zip(gradients_gen, generator.trainable_variables))return gen_loss, disc_loss
训练模型
循环执行训练,每500步输出一次损失值,便于观察模型收敛情况:
# 实例化生成器和判别器
generator = Generator()
discriminator = Discriminator()# 开始迭代训练
for step, (batch_x, _) in enumerate(train_data.take(training_steps + 1)):# 第0步:计算初始损失(未训练状态)if step == 0:noise = np.random.normal(-1., 1., size=[batch_size, noise_dim]).astype(np.float32)gen_loss = generator_loss(discriminator(generator(noise)))disc_loss = discriminator_loss(discriminator(batch_x), discriminator(generator(noise)))print(f"初始状态 - 生成器损失: {gen_loss:.6f}, 判别器损失: {disc_loss:.6f}")continue# 执行一次优化gen_loss, disc_loss = run_optimization(batch_x)# 定期输出进度if step % display_step == 0:print(f"步骤 {step} - 生成器损失: {gen_loss:.6f}, 判别器损失: {disc_loss:.6f}")
运行结果
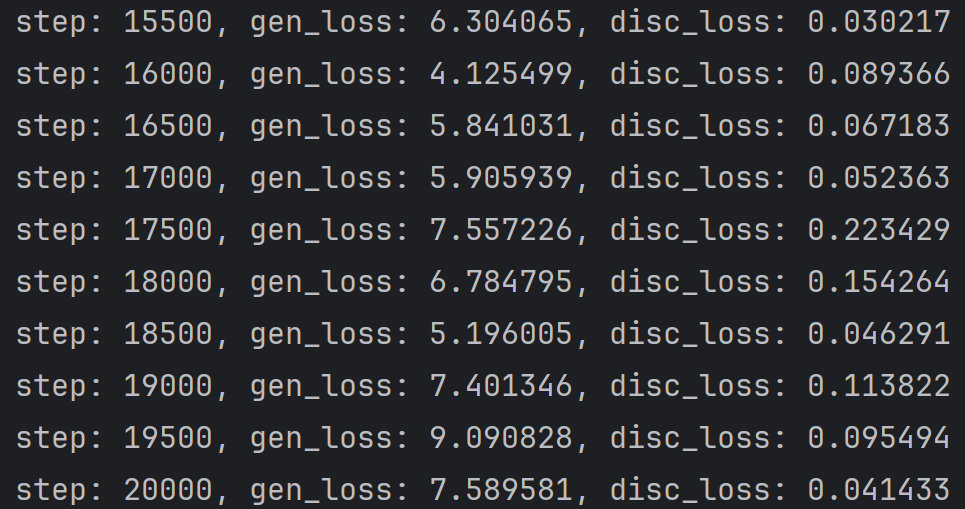
整体趋势总结:
- 判别器损失从初始的 1.36 快速下降至 0.1 以下,后期稳定在 0.02-0.2 区间,说明判别器对 “真假图像” 的区分能力持续增强。
- 生成器损失从 0.7 波动上升至 9.09,整体呈上升趋势,表明生成器 “欺骗” 判别器的难度越来越大。
| 训练阶段 | 生成器损失(gen_loss | 判别器损失(disc_loss) | 核心特征 |
|---|---|---|---|
| 初始状态(step 0) | 0.699429 | 1.362350 | 损失接近理论初始值 |
| 早期阶段(step 500-2500) | 2.16-3.12 | 0.26-0.36 | 判别器快速占据优势 |
| 中期阶段(step 3000-10000) | 2.32-5.13 | 0.08-0.34 | 生成器损失波动上升 |
| 后期阶段(step 10500-20000) | 3.54-9.09 | 0.02-0.22 | 生成器损失持续走高,判别器损失逼近 0 |
可视化效果展示
# 生成6×6的图像网格
n = 6
canvas = np.empty((28 * n, 28 * n)) # 画布大小:6*28 × 6*28for i in range(n):# 生成随机噪声z = np.random.normal(-1., 1., size=[n, noise_dim]).astype(np.float32)# 生成假图像generated_images = generator(z).numpy()# 图像还原:从[-1,1]转为[0,1]generated_images = (generated_images + 1.) / 2# 反转颜色:匹配MNIST黑底白字风格generated_images = 1 - generated_images# 拼接图像到画布for j in range(n):canvas[i*28:(i+1)*28, j*28:(j+1)*28] = generated_images[j].reshape(28, 28)# 显示结果
plt.figure(figsize=(n, n))
plt.imshow(canvas, origin="upper", cmap="gray")
plt.axis("off") # 隐藏坐标轴
plt.title("GAN生成的MNIST手写数字", fontsize=14)
plt.show()
效果展示
