C++学习记录(11)继承详解
一、继承的概念与相关语法
继承是面向对象程序设计的一大特点,为代码复用提供了新的层次。它允许我们在已有类型的基础上,设计新的成员变量和成员函数,所产生的新的类型叫做派生类(子类),原来的类型叫做基类(父类)。
1.新的认知
在过去我们对于代码复用的层次是这么成长的:
C语言阶段对于某些常用的操作,或者对标STL库的常用操作,我们常常用函数封装起来,这样大大节省了代码的体积;
在C++阶段我们学习了模板,于是进一步将函数逻辑的复用从单个的类型解耦出来,也就是适用于所有类型,进一步实现了代码的复用。
但是上面这两种做法都解决不了,我们在编程中遇到的这种情况:

假设现在我们要面向大学校园写一个管理系统,记录大学中所有人员的基本信息,并且实现基本行为。
按照我们之前的认知
假如现在轮到设计去食堂吃饭:

一个校园卡里面存放的信息差不多就是这样。
假设设计去图书馆借阅书籍:

假设去学校体育馆:

假设就这么多场景,不难观察到,几乎每个场景我们都为学生、食堂阿姨、保安大叔、老师设计成一个个类的话,有很多信息存储起来是重复的,比如说姓名、性别、学号、身份证号、手机号、院系、年级等,很多属性都是重复的,但是我们又不得不每个场景都设置一下,因为每个场景的行为都不一样,用到的属性可能有区别。
这样设计也有很大的弊端,正常情况下,就说姓名、性别、学号这些玩意都不会变,那手机号总有可能改变吧,如果按照这么设计,一个手机号的更改需要我们针对好几个场景进行修改,非常不便捷。
针对上述情况,我们渴求一种解决方案。
2.继承的思想和语法格式
既然有很多重复的属性,为什么不把它们都封装起来,谁用谁调呢?
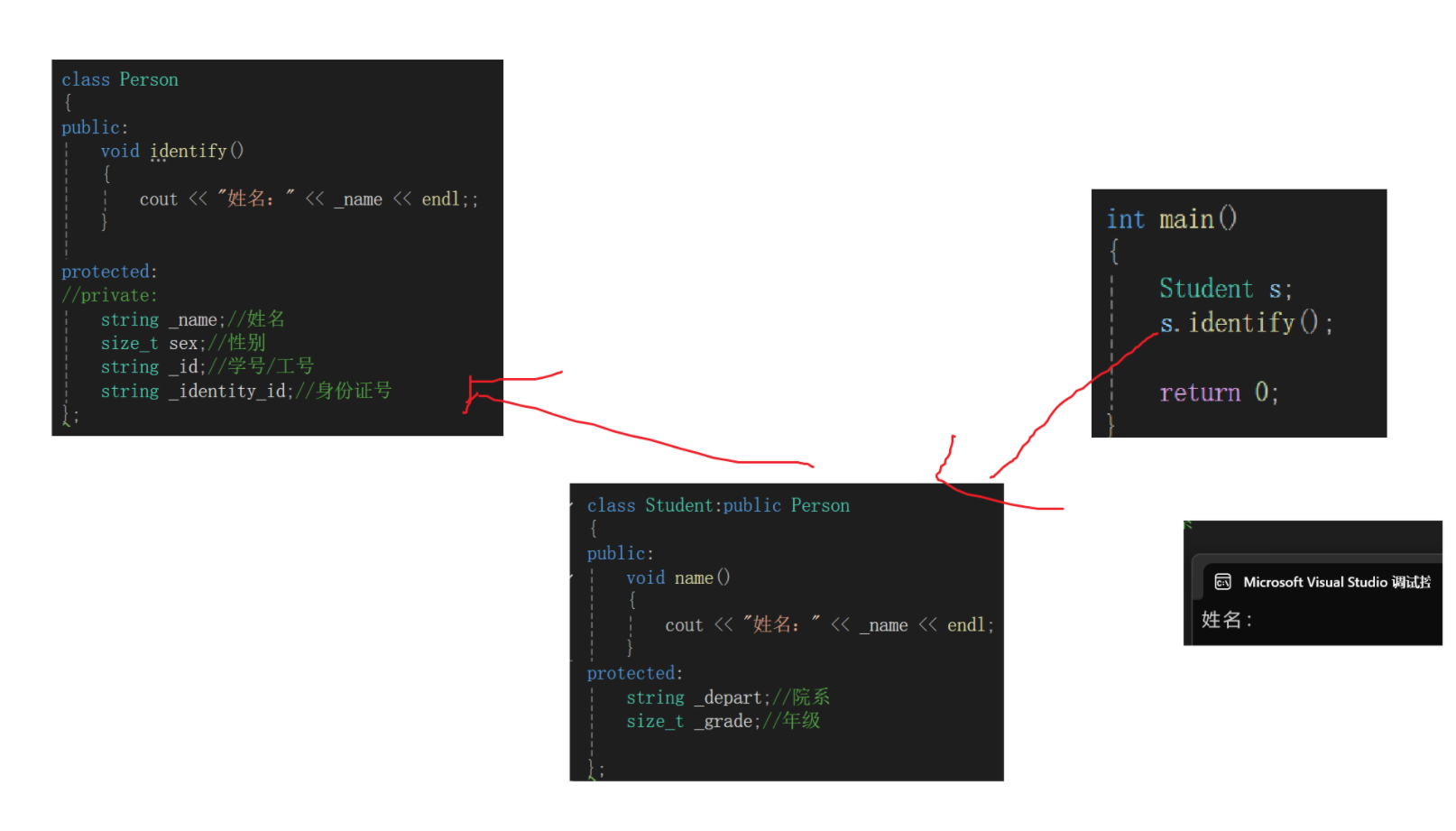
class Person
{
public:void identify(){cout << "姓名:" << _name << endl;;}protected:string _name;//姓名size_t sex;//性别string _id;//学号/工号string _identity_id;//身份证号
};class Student:public Person
{protected:string _depart;//院系size_t _grade;//年级
};
比如上面这里,既然每个学校人员都有姓名、性别等属性,那为什么不单独封装起来,谁用谁调呢?
Student类用就让Student类继承Person类。
先不管语法格式,先想想这个思想:

Person类中定义的_name属性、_sex属性等我都想用啊,自己定义实在是一种资源的浪费,索性我直接从Person继承过来,颇有继承家产的感觉(没房没车,不想努力了,直接从父母那里继承过来)。
语法格式就是
class 派生类名(子类名): 继承方式 基类名(父类名)
3.疑问
我不知道其他人有没有这样的疑问,我个人看到这个方式第一感觉是用适配器模式不完了,直接把
想要用的类型搞成成员变量不行吗?
class Student
{protected:Person _p;string _depart;//院系size_t _grade;//年级};也就是这样,这样不也行嘛,存什么姓名了,性别了都甩到这个_p里面,用的时候也用_p,结果顺着这里想着想着,我就意识到了一个问题:
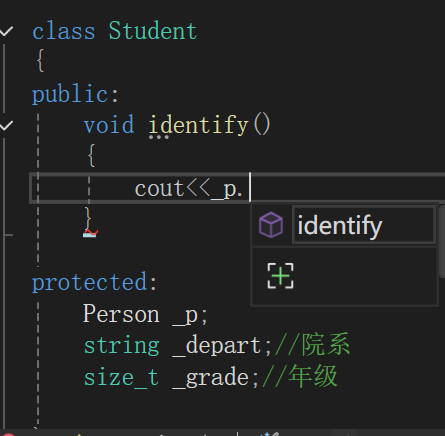
能在类外访问类的protected成员吗?
很明显是不可能的,我也动过歪心思,直接搞成struct类,类外能访问多好,但有很多类我们不能写成struct,就写成class,否则将会非常危险。
类比适配器模式是不行的,因为适配器模式可没有说去访问底层容器的成员变量了,只是用用底层容器的成员函数而已。
对比继承:
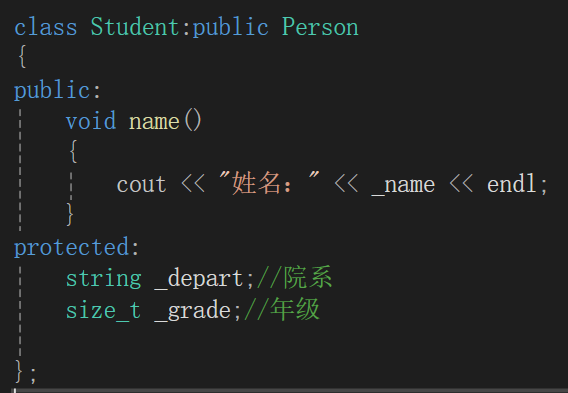
继承首先不再写对象,并且最最重要的特点就是即使在成员变量里没有写,因为继承过了,我们用起来就好像我们自己已经在成员变量里声明了一样,浑然天成。
至于成员函数也是可以继承的,但是在这里就不展示了,因为可能涉及到作用域一些麻烦事,下面慢慢说。
所以看了这么多,继承确实是我们之前代码复用的升级,既能访问到父类的方法,又能复用父类声明的成员变量。
4.继承体系中的访问修饰符
可能心细的人已经注意到了,我之前写代码都是顺手直接private修饰成员变量,但是在这里由于要继承,我用的是:
为什么要这么写呢?
在类与对象的学习,不涉及继承的程度,我们认为private和protected的属性是一样的,也就是从private/protected开始,直至下一个访问修饰符或者类末尾,这中间包裹的所有成员变量和成员函数都是不能从类外访问或者就说被实例化对象访问的(因为一般调用成员变量就是通过实例化对象,很少说直接通过类域+类访问操作符访问成员变量,当然,我们讲的静态成员变量除外,这里我们说的就是一般的成员变量)。
在继承体系我们就要对这两个操作符进行区分,直接说结论:
public > protected > private
- public修饰的是在类内类外都能随便访问
- protected修饰的在类外不能访问,在本类和继承类中可以访问
- private修饰的在类外不能访问,且由其继承产生的子类也不能访问
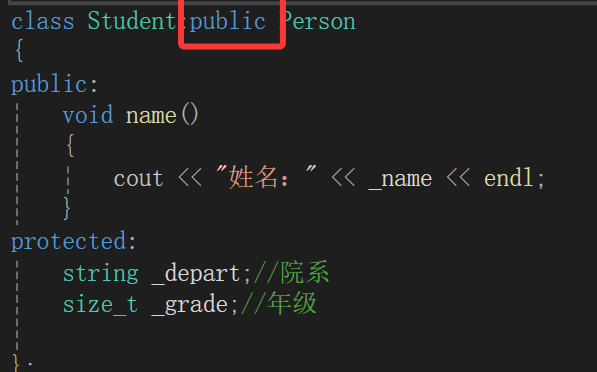
也就是,上面我们这里不是:
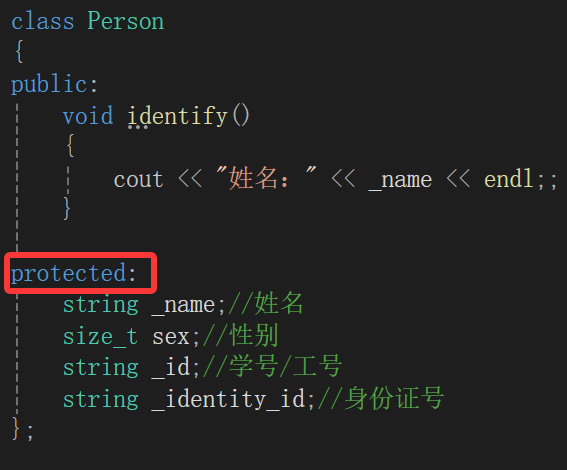
class Person
{
public:void identify(){cout << "姓名:" << _name << endl;;}protected:string _name;//姓名size_t sex;//性别string _id;//学号/工号string _identity_id;//身份证号
};
class Student:public Person
{
public:void name(){cout << "姓名:" << _name << endl;}
protected:string _depart;//院系size_t _grade;//年级};父类成员变量是protected访问的,所以在父类可以访问,子类中(public继承)也就可以随意用。
但是如果:
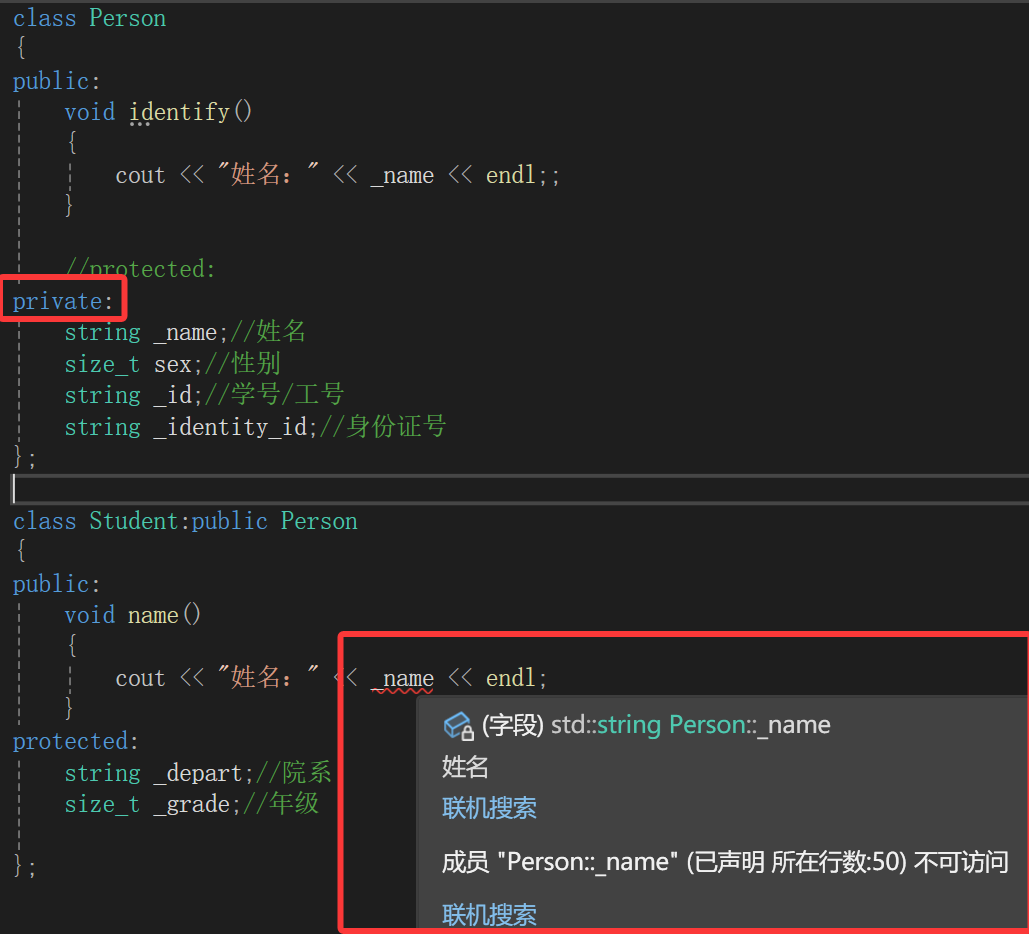
private修饰的只有它自己能用,子类就算继承(就算public继承)也不能用。
当然,直接用不行,还能间接用,毕竟Student类不止是继承Person类的成员变量,成员函数也继承了,利用Student类调用继承过来的访问Person类成员变量的函数也行啊:
当然,我们Person类没搞构造,所以_name走的是string的默认构造,也就是空字符串,所以啥内容都没有。
之前不区分protected和private是因为根本没有这样的场景,之前哪有继承这个事,没有继承这个事就没有访问父类访问子类的事。
5.继承关系
在讨论访问限定符区别的时候,我们提到了继承方式,因为访问修饰符除了在类内用,很明显,继承的时候也有,而且也是这三个:
也就是:

简单的排列组合3 * 3 = 9,一共9种组合方式,所以我们常常在C++的教材或者讲解中常见到:
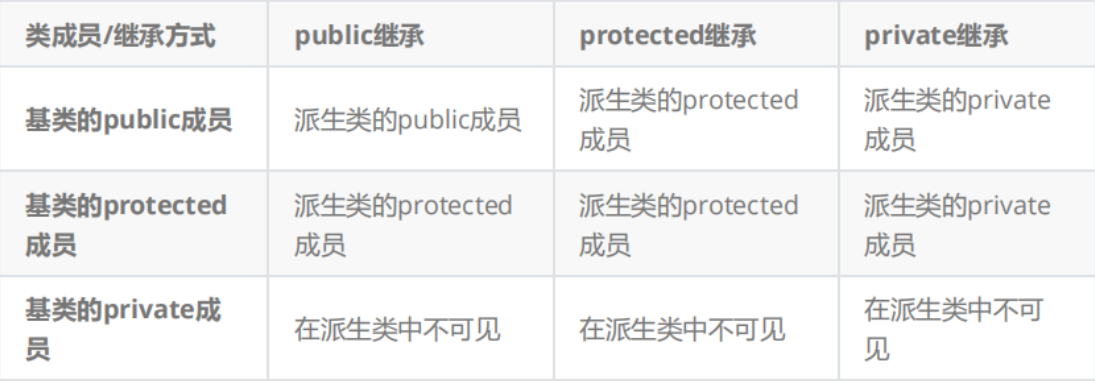
这个玩意也不用死记:
- private修饰的父类的成员,不管用public、protected、private继承,继承以后就好像没有继承一样,因为不能直接访问
- 除了private外,理解起来就是Min{继承方式,父类成员修饰符}
还有一个不成文的规定:
如果父类的成员我们不想让子类访问,肯定直接private了,不管咋继承都没用了,一般不会说private继承,那不是脱裤子放屁嘛,所以剩下的情况:
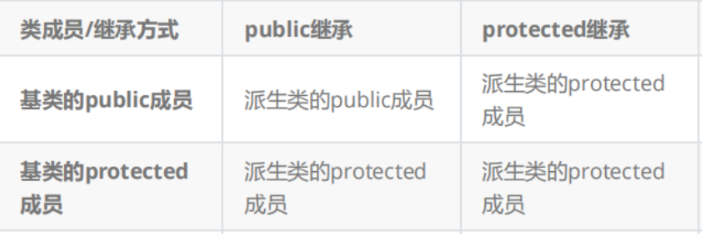
直接就其实压根不用动脑子了,一般编程就直接使用publlic继承。
综上,父类不想让子类访问的直接private修饰;在剩下的情况下继承也就直接public继承,public继承后父类的成员如果是public到子类还是public,如果是protected到子类还是protected。
补充
- class类不写,默认的继承方式是private;struct类不写,默认的继承方式是public
public继承是 C++ 中实现接口复用和运行时常多态的基石。它使得代码层次清晰、易于扩展和维护
protected和private继承破坏了接口继承,扼杀了多态,并且导致继承链断裂,使得代码僵硬、难以理解和发展。它们要解决的问题,几乎都可以通过更安全、更灵活的组合(Composition) 模式来更好地实现
后面这两点我问的ai,因为protected和private继承没必要深入理解,所以就放这里仅作了解。
6.继承类模板
给出继承类模板的一个例子:
namespace xx
{template<class T>class stack : public std::vector<T>{public:void push(const T& x){vector<T>::push_back(x);}void pop(){vector<T>::pop_back();}const T& top(){return vector<T>::back();}bool empty(){return vector<T>::empty();}};
}继承的对象是类模板的时候有几点需要注意:
- 继承的对象是类模板时注明其命名空间
- 继承的对象是类模板时填好模板参数实例化
- 继承的对象是类模板时调用方法注明类域
最后一点讲起来有点麻烦:
可以注意到stack类中所有的操作均指名了类域,不指明类域不行吗?
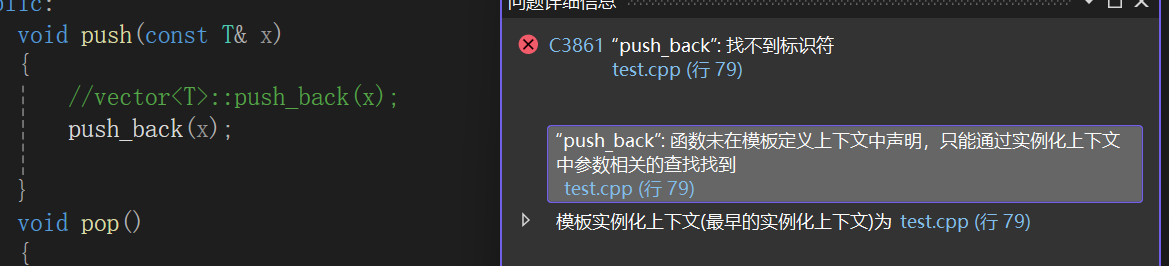
编译器找不到push_back是啥,不应该啊,我实例化好stack以后,vector应该也被实例化了,子类调用父类的方法,很合理啊。
原来,编译器在这里的优化导致了这个问题,模板在实例化的时候不是全部实例化,而是按需实例化。

不注明类域的话,编译器默认你这个push_back是stack类自己就实现的,所以就不给vector<T>实例化push_back方法,下面这么多方法都注明了类域,表明用的就是这个父类的方法,你必须给我实例化。
这也就导致了编译器在stack里找找不到push_back方法,在vector里找由于没有实例化也没找到。
显示类域实例化即可解决问题。
二、基类和派生类之间的转换
为了下面的内容学的通畅,在这里提前讲一下基类和派生类之间的转换。
1.回顾
一般场景:
int main()
{//1int x = 1;double d = x;//2//int x = 1;//double& d = x;//3string str = "xxxxx";//4//string& str = "xxxxx";return 0;
}第一个场景,C语言支持的内置类型的隐式类型转换;
第二个场景,通过这个场景,我们认识到,隐式类型转换不是直接执行的,而是x先生成一个double类型的临时对象,临时对象具有常性,非引用绑定常量不被允许,必须用const引用;
第三个场景,C++支持的隐式类型转换进行了升级,即自定义类型如果有对应的构造函数存在,那么就支持两种类型的隐式类型转换,这里实际上也是经构造函数用c-str构造出来一个string的临时对象,再经拷贝构造,将临时对象的值赋给str(当然,现代编译器一般觉得构造+拷贝构造没必要,太浪费,常常优化成直接构造);
第四个场景,由于这里是引用,所以c-str产生的临时对象不再拷贝构造给str,而是让str去引用,但是还是那个道理,临时对象具有常性,非const对象不能引用const对象。
这是我们之前学到的不同类型的转换,非要补充什么就是能够转换的对象间肯定存在一定相似性,比如int和double,int -> c-str就是走投无路不可能的。
父类和之类的对象之间能否进行转换呢?
转换的细节是什么呢?
2.基类与派生类
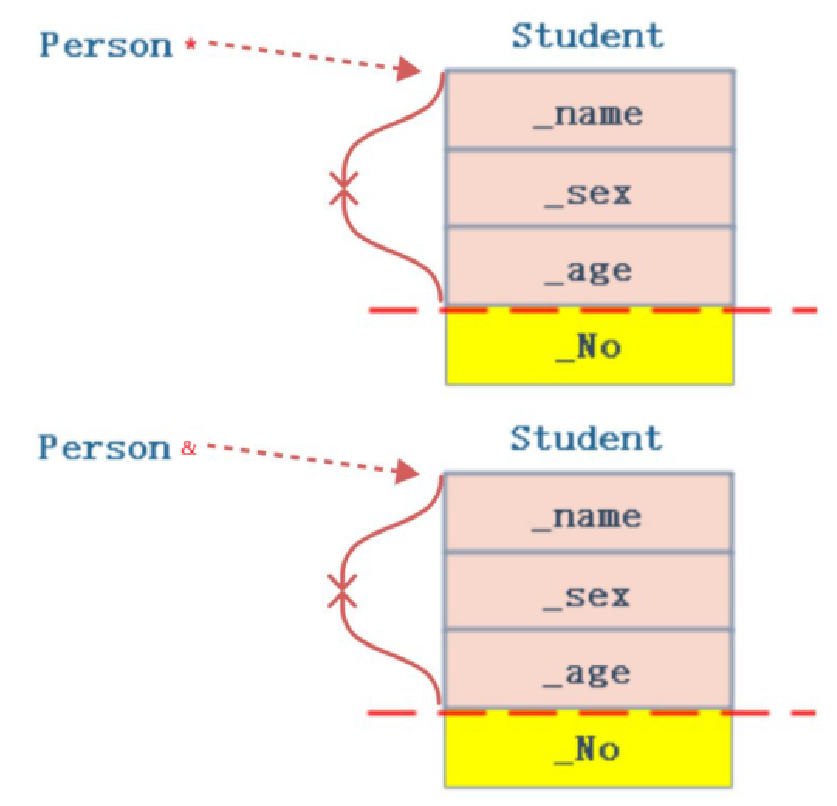
- public继承的派生类对象可以赋值给基类的引用/指针,一般这种行为称为切片,这里的引用和指针指向的是派生类中的基类成员,如下图:
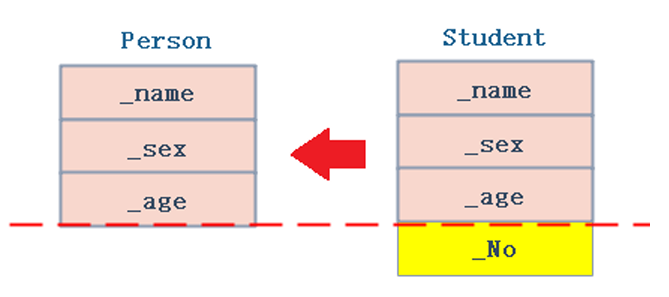
- 派生类对象赋值给基类对象是通过基类的拷贝构造/赋值运算符重载完成的,这个过程也是切片,具体细节后面讲到会说
- 基类的指针或者引用可以通过强制类型转换赋值给派生类的指针或者引用,但是必须是基类的指针指向派生类对象时才安全。这里基类如果是多态类型,可以用RTTI的dynamic_cast来进行识别后进行安全转换(复制粘贴的,我也看不懂啥意思,反正感觉基类赋给派生类确实不安全,毕竟万一你用这个指针访问基类没有的派生类有的成员呢)

三、继承中的作用域
- 在继承体系中,基类和派生类都有独立的作用域
- 在派生类和基类中存在同名的成员变量,派生类将屏蔽基类对同名函数的直接访问,这种现象称为隐藏(破解的办法就是明确用类域::同名变量访问)
- 如果是成员函数同名,只要同名就构成屏蔽
- 继承体系中不推荐用重名的成员
1.同名成员变量
例如,化简过的Person类和Student类:
class Person
{
protected:string _name = "张三";int _num = 111;//身份证号
};class Student : public Person
{
public:void Print(){cout << "姓名:" << _name << endl;cout << "身份证号:" << _num << endl;cout << "学号:" << _num << endl;}protected:int _num = 222;//学号
};int main()
{Student s;s.Print();return 0;
}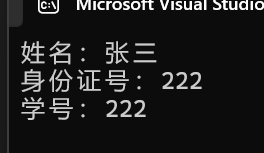
可以看到如果不注明类域且存在同名对象,只能找到派生类的成员。
大概说一下这个隐藏为什么存在:

老早之前我们就已经确定了一个大方向,那就是就近原则,编译器会先在局部域中找,如果类内的话上下都会找,找到就直接用,因为这里是派生类,找不到就去父类里找一找,再找不到就该去找全局变量了。
所以如果不注明类域,同名变量只能找到子类里的。
注明类域:

2.同名成员函数
再来一个成员函数的例子:
class Person
{
public:void fun(){cout << "fun()" << endl;}
protected:string _name = "张三";int _num = 111;//身份证号
};class Student : public Person
{
public:void Print(){cout << "姓名:" << _name << endl;cout << "身份证号:" << _num << endl;cout << "学号:" << _num << endl;}void fun(int x){cout << "fun(int x)" << endl;}
protected:int _num = 222;//学号
};int main()
{Student s;//s.Print();s.fun(1);s.fun();return 0;
}如果我没有说隐藏这个机制,那么大多数人看见这个,一看:
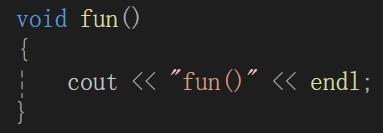

也不管俩人是不是一个作用域的了,直接张口就是构成重载,认为先输出个:fun(int x)再输出个:
fun()。但是我已经强调过了,作用域或者说查找机制会造成隐藏。
所以:
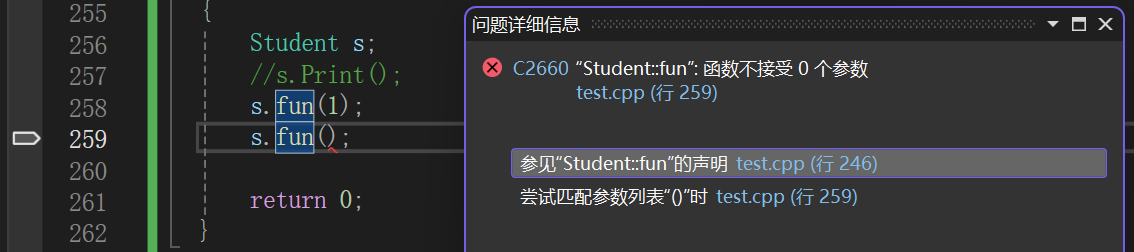
为什么这样呢?
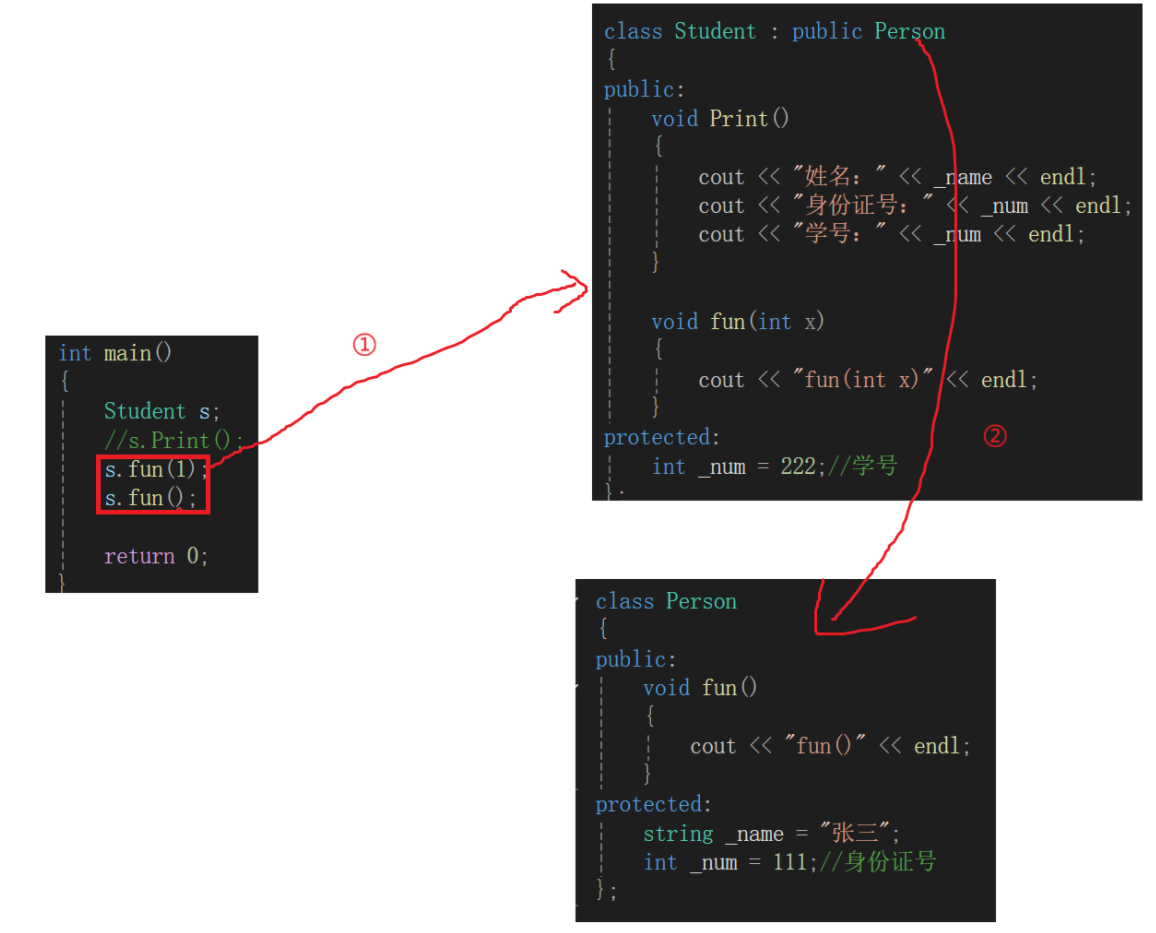
编译器找的就是函数名,子类对象肯定是先从子类中找啊,一找找到了fun,不过肯定是传一个int的fun,找到了肯定就不去找了,实在找不到才会去父类里找,因此构成不了重载,所以也就错误。
这里就得对重载加深理解了,早在C++入门抄重载的概念的时候已经明确说过了,C++允许在同一作用域内写同名函数,但是形参必须不同,也就是函数重载必须在同一个作用域中才能实现。
3.两道面试题

第一个问题不用多说,不是同一个作用域构不成重载,且因为编译器的查找习惯,很明显构成隐藏关系;
第二个问题也能想到,运行报错大概率是指针引用方面的,比如野指针、空指针的解引用、野引用等等,因为只能找到子类的fun函数,必须传一个int参数,传参不够,因此编译报错。
四、派生类的默认成员函数
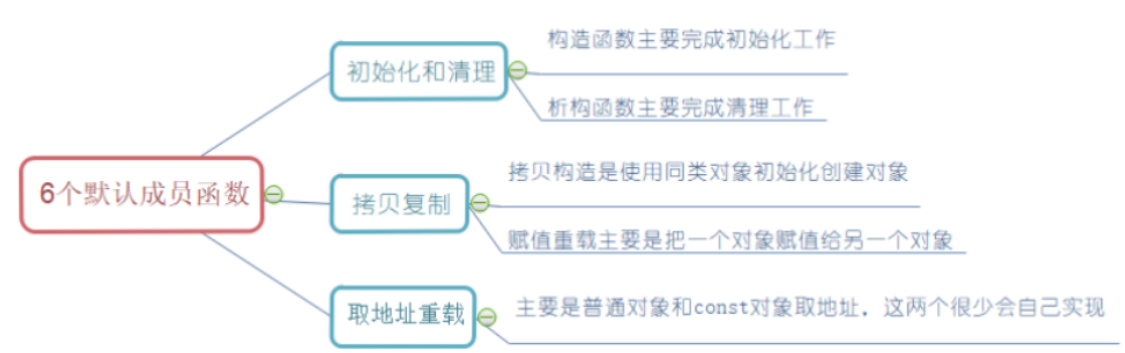
默认成员函数依旧是这几个,重点就是对前四个:构造、析构、拷贝构造、赋值重载的掌握。
依旧是类似于学习类与对象的学习要求:
- 弄清楚编译器自动生成的默认形式的行为是什么样的
- 什么情况下我们需要显式写这些函数
- 怎么显式写这些函数
只有弄清楚了编译器默认生成的函数的行为,我们才能知道什么时候用写什么时候不用写,并且还得写对(清楚深拷贝浅拷贝要求,适时实现)。
以下讲解均借助:
class Person
{
public:Person(const char* name = "张三"): _name(name){cout << "Person()" << endl;}Person(const Person & p): _name(p._name){cout << "Person(const Person& p)" << endl;}Person& operator=(const Person & p){cout << "Person operator=(const Person& p)" << endl;if (this != &p)_name = p._name;return *this;} ~Person(){cout << "~Person()" << endl;}
protected:string _name; //姓名
};
class Student : public Person
{
public: protected:int _num; //学号
};1.构造函数
构造函数需要构造的对象有父类的成员变量以及子类的成员变量。
①编译器默认行为
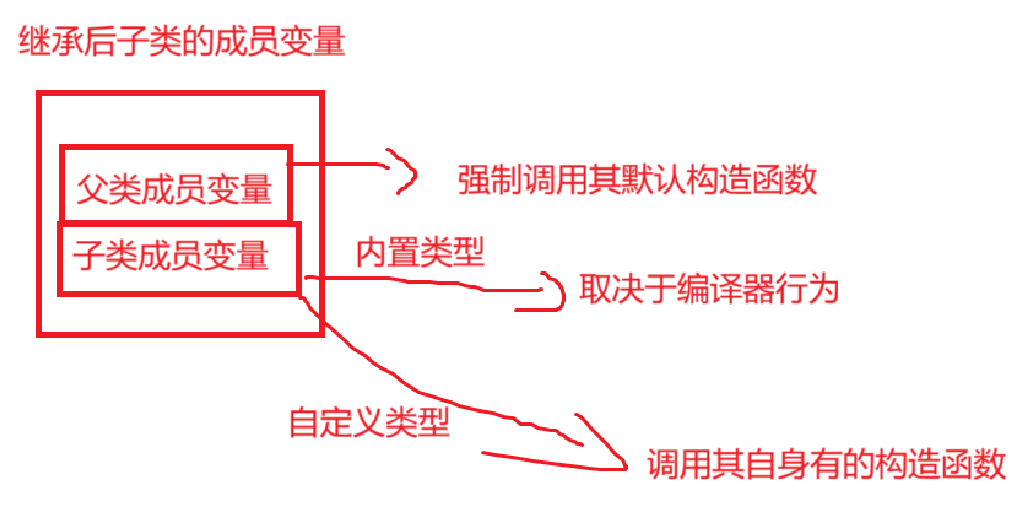
不管是自己写的还是编译器默认生成的构造,对于子类本来就有的成员变量和父类的成员变量做以下处理:
将父类成员变量和子类成员变量分离开初始化,并且强制要求父类成员不能一个一个去初始化,必须调用父类的构造函数初始化。
比如现在,我们有上面的Person类和下面继承出来的Student类,Student类的成员函数一个都没写,我们现在先研究构造函数,编译器默认行为也是将成员变量分为两类初始化:
父类有string类对象_name,且有对应构造函数,直接调用:
Person(const char* name = "张三")
: _name(name)
{
cout << "Person()" << endl;
}
还剩子类的变量未初始化,并且因其并没有显示写:
对于内置类型的变量来说,没有明确规定,所以编译器可能对其不做处理,也可能初始化为0,0.0这些值,具体肯定取决于变量类型;
对于自定义类型来说,调用其对应的默认构造,没有对应的默认构造函数将会编译报错。
所以总结来说,编译器默认生成的派生类的构造函数的行为是:
明白了默认行为以后,就发现int类型其实必须去初始化,否则一个随机值说不准整出来啥幺蛾子。(虽然一般构造函数必须写,基本99.99%情况都得写,因为存放的值必须有意义)
展示默认行为:

②实现构造函数
class Student : public Person
{
public: Student(int num):Person("张小三"),_num(num){}protected:int _num; //学号
};需要观察的点:
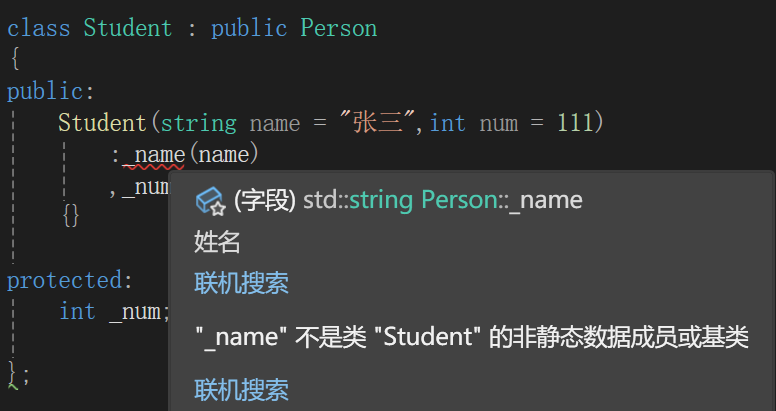
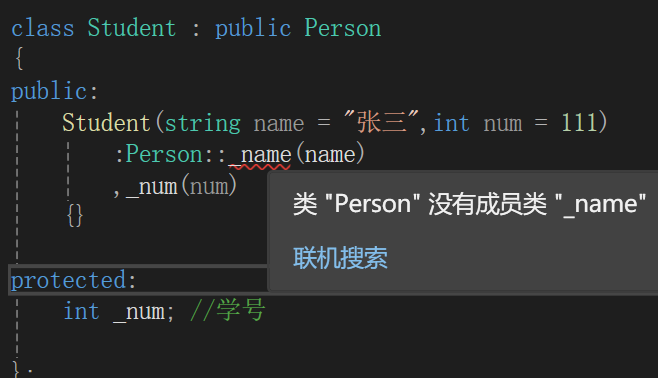
必须走父类的构造函数初始化,想要一个一个变量初始化根本不允许。
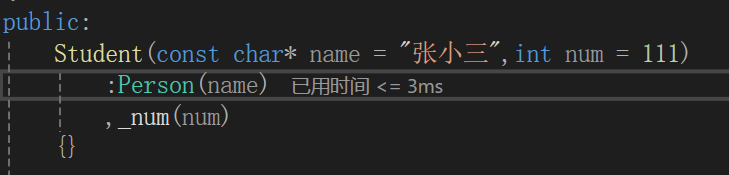
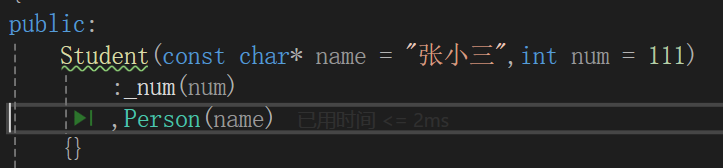
子类构造函数首先调用父类的构造函数初始化从父类继承过来的成员变量,无论声明的顺序是什么。
③构造函数细节解释
我们大可死记住,调用父类的构造函数初始化,然后再对子类的成员初始化。
但是有好几个疑问都会因此而带过。
- 为什么对于父类的成员我们必须走它的构造函数初始化而不是一个一个初始化,毕竟大部分时候都是父类protected,public继承?
我思考了这种行为,大概率是为了保护封装性,比如最狠的,父类private,如果想要对其一个一个变量初始化显然是做不到的事情,但是一个类的构造函数肯定是public修饰(构造函数不public就不能对成员变量设置,那类的成员变量也会失去意义)。
即使可以一个一个成员初始化,但是走构造函数更能保护封装性。
- 为什么在构造在实行的过程中始终都是先走父类的构造?
我个人认为这是一种约定俗成的规则,其内涵在于,子类是建立在父类之上的类型,就好像房子与地基的关系一样,不打好地基,就不能盖房子,在编程里首先对父类的成员进行初始化,我认为也是存在类似于这样的情况,有时候子类的成员变量需要根据父类的成员变量初始化。
2.拷贝构造
拷贝构造的逻辑类似于构造函数。
①编译器默认行为
无论是编译器默认生成的拷贝构造还是我们自己写的拷贝构造,所做的依然是将成员变量分为父类和子类分开处理,并且父类的拷贝必须显式或者隐式的调用父类的拷贝构造,子类自己处理。
编译器对于父类默认行为就是调用其拷贝构造;
编译器对于子类默认行为,对于内置类型直接浅拷贝,一个字节一个字节拷贝过去;对于自定义类型调用其对应的拷贝构造。
浅拷贝即可完成任务。
②实现拷贝构造
什么时候需要实现拷贝构造呢?
父类的成员不管有没有资源,我们直接就是调用其对应拷贝构造,如何处理是父类的问题;
那么就剩下来子类的成员,子类的成员如果是内置类型,我们要求的就是值拷贝赋值,写不写都一样,编译器的默认行为其实就相当于直接赋值了;自定义类型其实也不用管,编译器直接就调用它的拷贝构造去了;
剩下来几种情况:
子类成员存在资源、引用类型、const常量、没有默认构造的自定义类型。
有这些情况存在,必须显式写拷贝构造。
存在资源浅拷贝不行,否则会出现指向同一块内存空间,牵一发而动全身;同时出现析构两次的情况。
拷贝构造也是构造,引用类型、const常量、没有默认构造的自定义类型成员这些必须走初始化列表显式初始化(或者你弄个缺省值啥的),否则这些玩意走初始化列表直接就炸了。
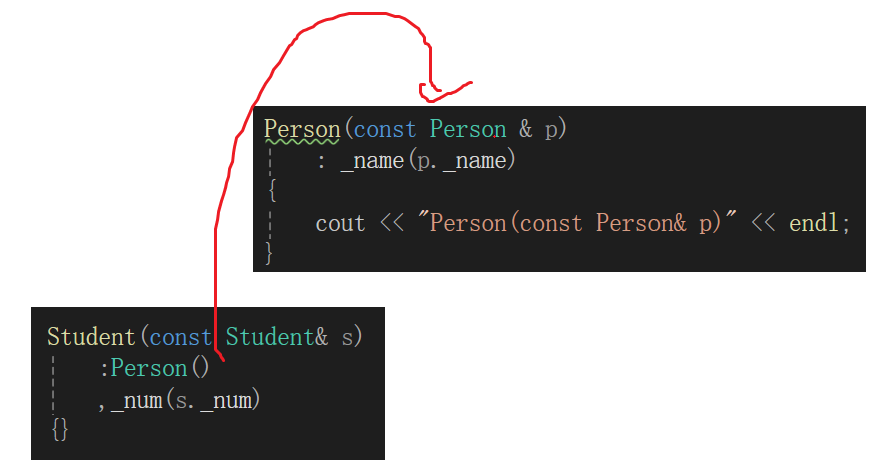
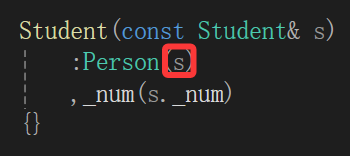
但是尝试着去写就发现问题了,一个类的拷贝构造我们很自然的就写成const 类型&的类型,因为拷贝构造只需要一个存在的对象的值,只读用const保护,并且这样可以拷贝const对象的值;至于引用不用多说,拷贝构造这里不写引用会造成无穷调用,而且自定义类型不写引用,自定义类型的拷贝代价也是非常大的。
但是显式调用父类的拷贝构造需要传一个父类的对象,我去哪整一个父类的对象呢?
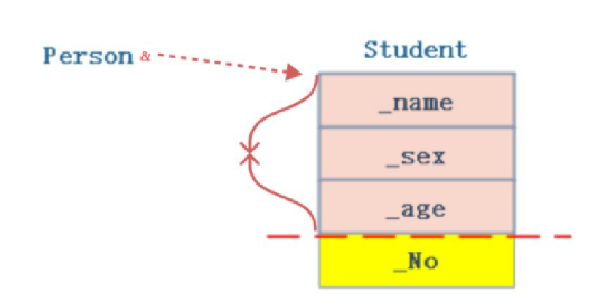
其实不用那么麻烦,刚说过,子类的对象可以直接赋给父类的指针/引用类型而不产生临时对象,就好像划分领土给了Person&一样,应用到实践中直接:
3.赋值运算符重载
道理同上。
①编译器默认行为
父类不用管,编译器自己调父类赋值运算符重载;
子类道理同拷贝构造,编译器默认对内置类型浅拷贝;对自定义类型调用其赋值运算符重载。
②实现赋值重载
父类直接调用,不多解释;
子类如果有资源还是得老实点,自己写赋值重载。
细节问题
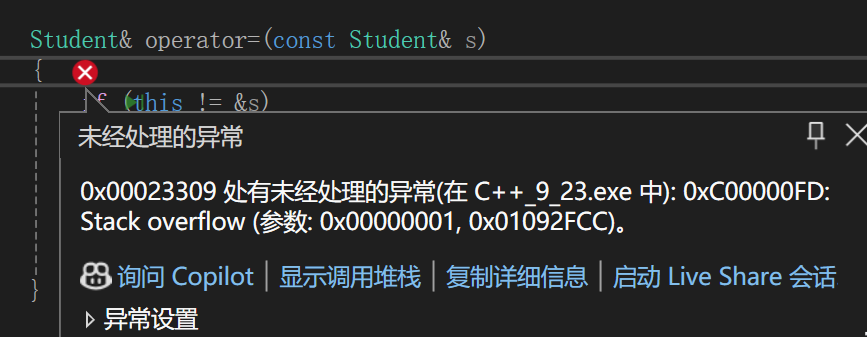
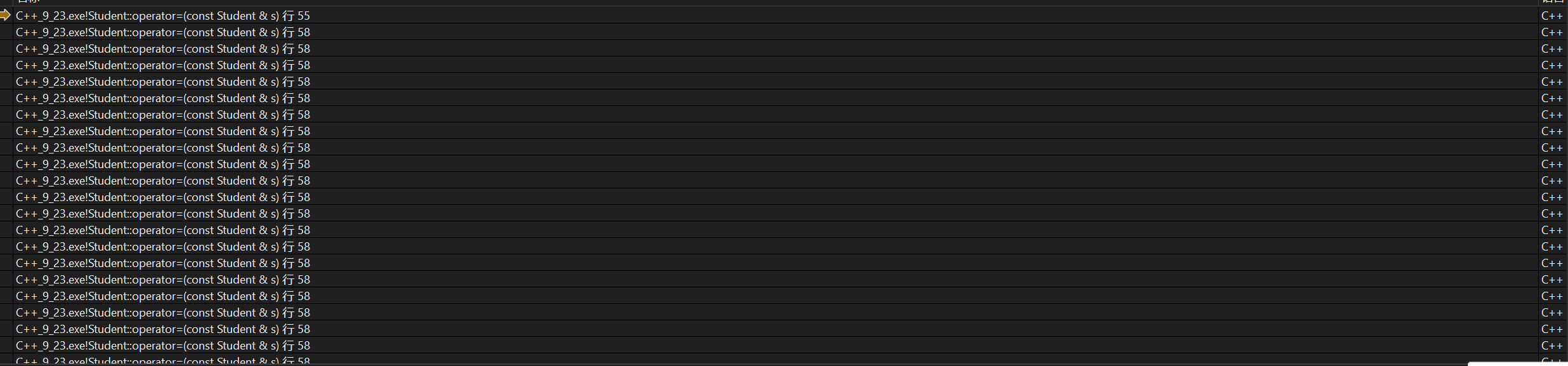
Student& operator=(const Student& s){if (this != &s){operator=(s);_num = s._num;}return *this;}下意识的可能就直接这么写了,因为父类的赋值重载不是被继承了嘛,但是还是作用域的问题,编译器上来只会去类内找,类内找只能找到我们写的这个operator=这么搞下去,理论上一辈子都调用不完,当然,因为栈内存有限,等到栈内存耗干也就结束了。
所以指明类域:
Student& operator=(const Student& s){if (this != &s){Person::operator=(s);_num = s._num;}return *this;}4.析构函数
析构前面三个有点差别。
主要体现在,其它三个都是在盖房子、装修房子,必须实现从父类到子类,也就是盖好地基盖房子,但是析构其实相当于拆房子,拆房子难道能先拆地基再拆房子吗?所以父类的析构反而要晚于子类的析构。
①编译器默认行为
父类后析构,并且肯定是调用父类的析构;
子类先析构,对于内置类型不做处理;对于自定义类型调用其自身的析构。
②实现析构
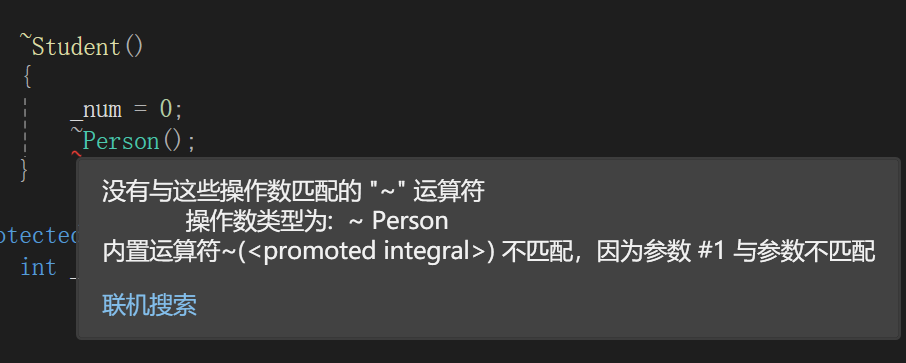
按照我们上面的逻辑写析构函数,结果编译器跟我说没这个玩意。
这是怎么回事呢?
经查:
析构函数名字因为后续多态(重写)章节原因,所有类的析构会被处理成destructor,所以派生类和基类析构构成隐藏关系
因此如果想要调用还得指明类域:
~Student(){_num = 0;Person::~Person();}但是还别先高兴:
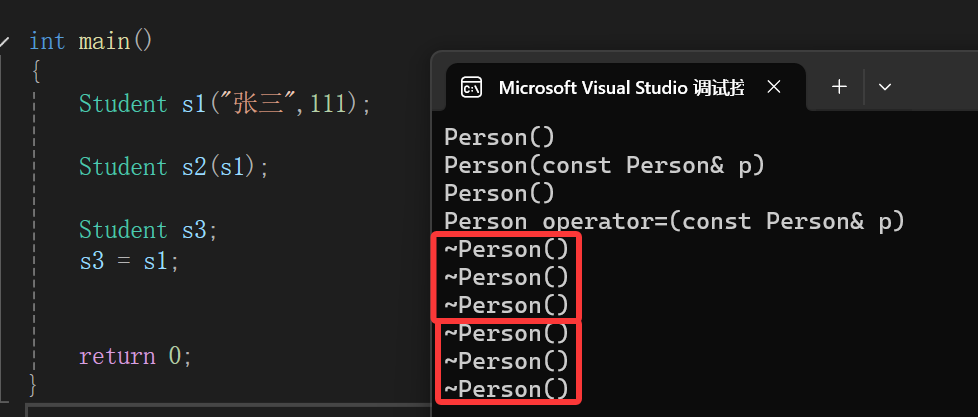
拢共就三个对象,你搞了六个析构,我们这里没啥资源释放,不然就释放两次资源,实在是太危险了。
原来:
子类析构调用后,会自动调用父类析构,所以自己实现析构时不需要显示调用
等于子类析构自己显式写的时候不用管父类对象,它自己会去调用。
~Student(){_num = 0;}//最后自动调用父类析构五、实现一个不能被继承的类
1.基类构造函数私有
大概逻辑就是私有一个类的构造函数,这样的话如果有类想要继承,那就会面临private成员继承,这样在派生类中的构造函数就不能调用基类的构造函数,那么派生类写不出来构造函数也就无法实例化对象。
//基类构造函数私有化防止被继承
class Base
{
private:Base(){cout << "Base()" << endl;}
};class Derived : public Base
{
public:Derived(){cout << "Derived()" << endl;}
};

2.C++11新增关键字final,在类后加就可直接禁止被继承
第一种禁止继承其实很麻烦,你得了解派生类构造函数的底层机制,还得了解修饰符在类中和继承方式中的机制。
所以这里直接搞一个final就省去了麻烦:
//final关键字禁止被继承
class Base final
{
public:Base(){cout << "Base()" << endl;}
};class Derived : public Base
{
public:Derived(){cout << "Derived()" << endl;}
};
六、继承与友元
直接说结论,基类的友元关系不能被派生类继承。
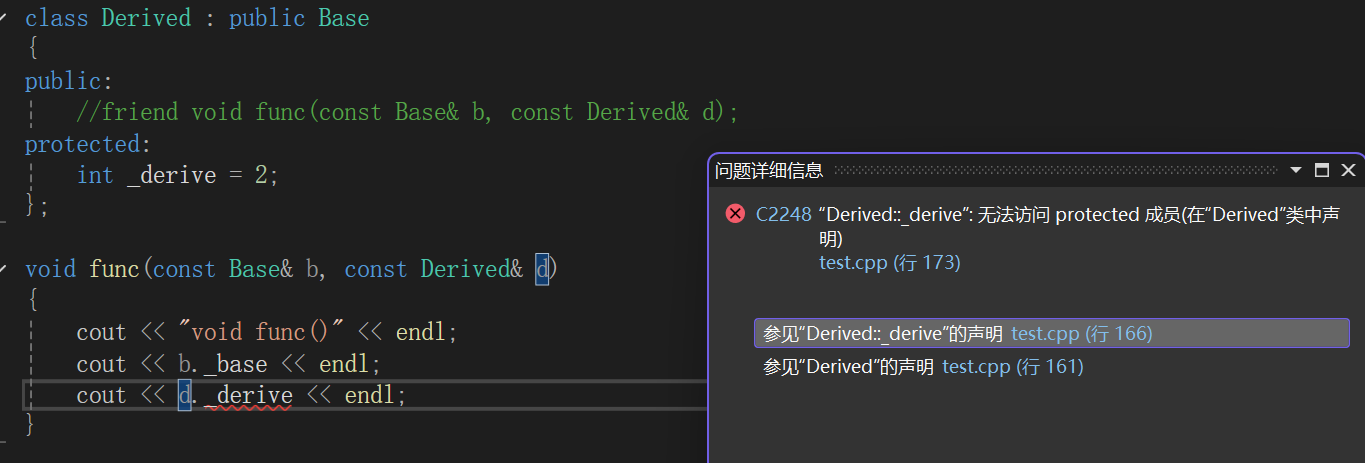
class Derived;class Base
{
public:friend void func(const Base& b, const Derived& d);
protected:int _base = 1;
};class Derived : public Base
{
public://friend void func(const Base& b, const Derived& d);
protected:int _derive = 2;
};void func(const Base& b, const Derived& d)
{cout << "void func()" << endl;cout << b._base << endl;cout << d._derive << endl;
}有几个要点:
- Base的友元仅仅准许func在类外访问Base对象的成员
- Base的友元声明前必须加Derived类的声明,因为编译器只会向上找,但Derived是Base类的派生类,相对位置一定在Base后
有了这些条件以后:
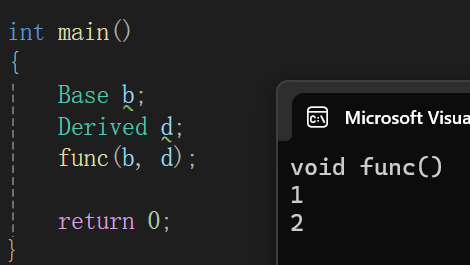
如果你还想让func函数既友元基类又友元派生类,仍需手动友元一下:
class Derived;class Base
{
public:friend void func(const Base& b, const Derived& d);
protected:int _base = 1;
};class Derived : public Base
{
public:friend void func(const Base& b, const Derived& d);
protected:int _derive = 2;
};void func(const Base& b, const Derived& d)
{cout << "void func()" << endl;cout << b._base << endl;cout << d._derive << endl;
}int main()
{Base b;Derived d;func(b, d);return 0;
}
七、继承与静态成员
如果基类中有静态成员,那么无论继承多少次,静态成员都只会有一份属于基类,只不过派生类也可以调用。
class Person
{
public:string _name;static int _count;
};int Person::_count = 0;class Student : public Person
{
public:int _id;
};int main()
{Person p;Student s;cout << &p._name << endl;cout << &s._name << endl;cout << &p._count << endl;cout << &s._count << endl;return 0;
}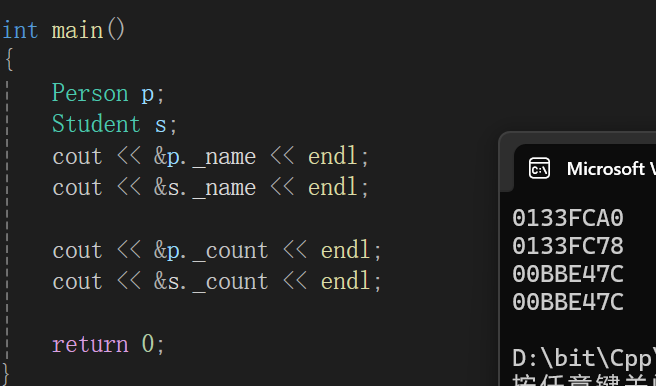
静态成员怎么继承始终都只有那一份。
八、多继承和菱形继承问题
单继承:一个派生类只有一个直接基类称为单继承。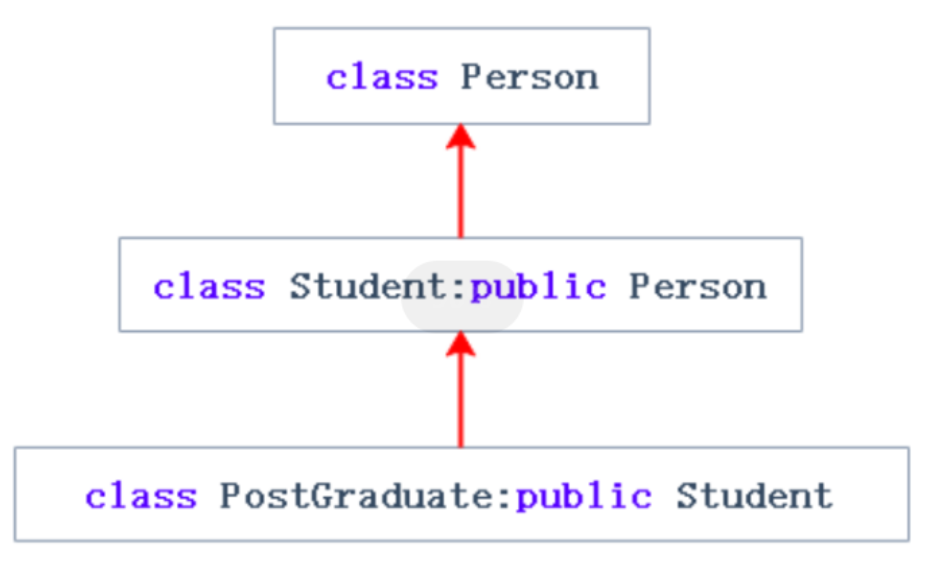
多继承:一个派生类有两个或两个以上的基类称为多继承。
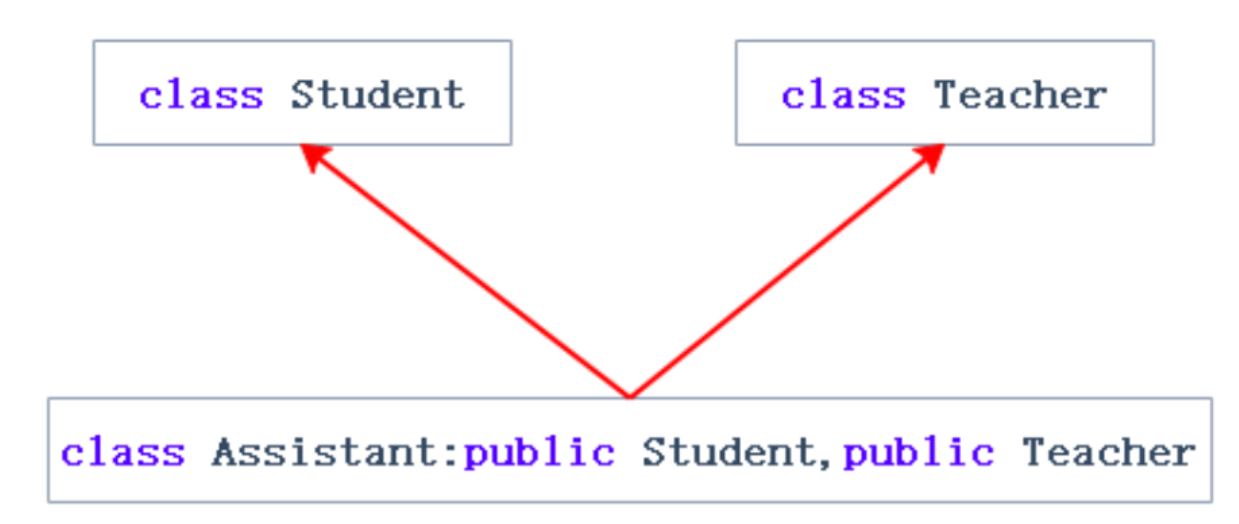
1.多继承分析
其实乍一听,感觉没啥区别啊,毕竟说起来,继承一个类的也是继承,继承多个类的也是继承啊,有啥问题?
那是因为其实我们空想是站在的我们正常生活的角度,但是一旦到编程:
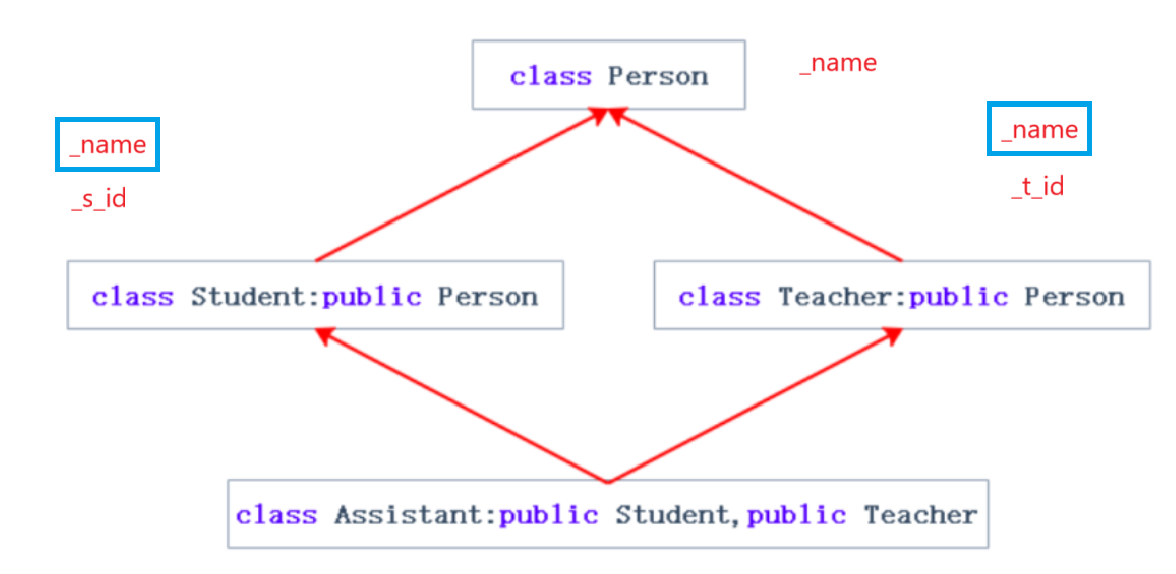
假设在这样的场景,Person类就说有一个变量_name,Student类和Teacher类都是人吧,那就可以继承啊,那就还是如图所示的场景。
那么接下来继续继承怎么办?
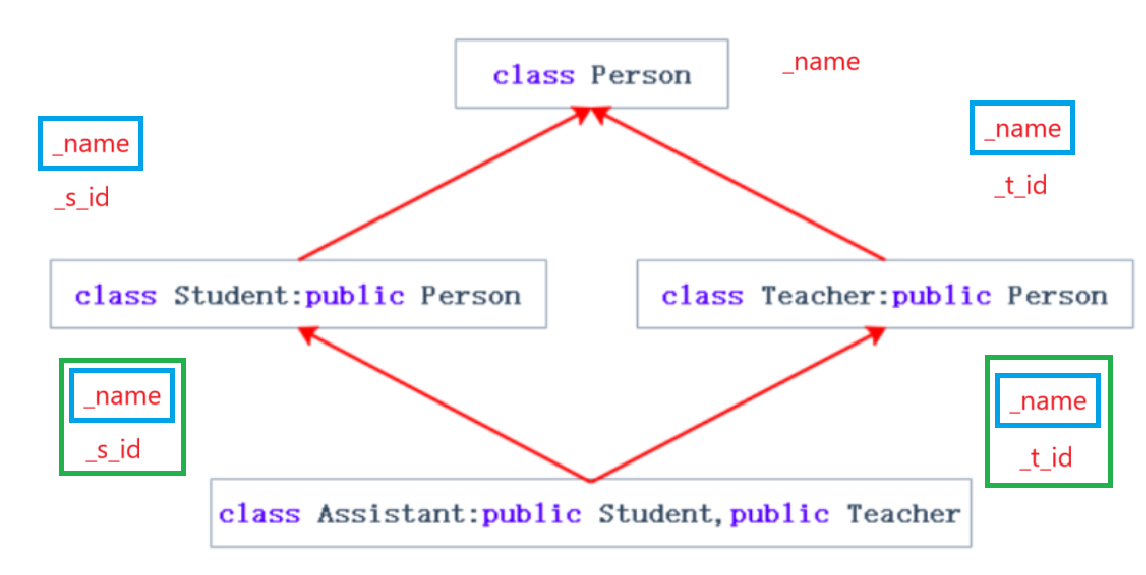
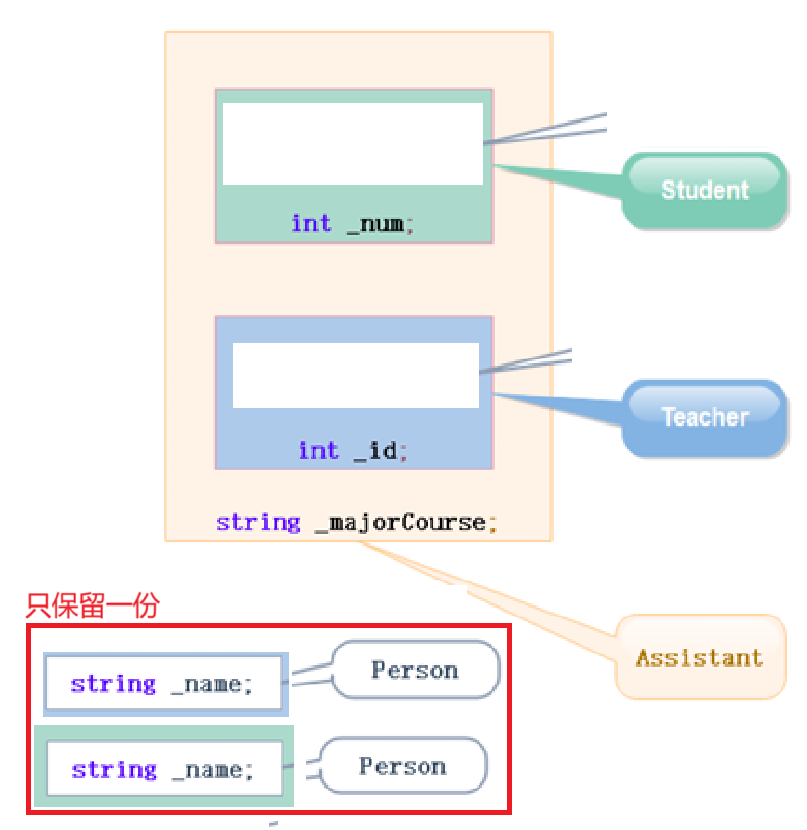
等到了Assistant类就会成上面这个样子,本来说如果派生类和基类不建议有同名成员,真没办法有了也要注意隐藏的问题,到这里,好家伙,你继承过来两个同名的_name,那么接下来还不乱套了。
这就是多继承隐藏的二义性和数据冗余的问题。
class Person
{
public:string _name;
};class Student :public Person
{
protected:int _num;
};
class Teacher : public Person
{
protected:int _id;
};class Assistant: public Student,public Teacher
{
protected:string _major_course;
};如果在这些代码的基础上:
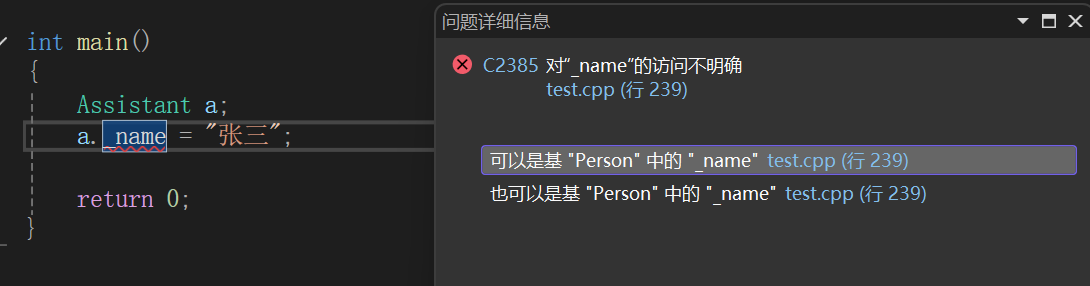
道理也简单,我两边多继承过来个_name,你跟我说让我给你访问哪个?
不过依旧可以指定类域解决:

虽然指明类域可以说很好的解决了二义性的问题,但是数据冗余的问题并没有解决,也就是说,一个人不管是以老师身份还是学生身份,假如学校给它发校园卡的话难道还往上写个张老师吗?你打印校园卡,或者就说身份证,肯定是原原本本把你户口本上的名字写上去,因此我们仍旧希望只保留一个_name变量。
2.虚继承
多继承的存在导致了菱形继承的问题,菱形继承的问题又待解决,因此又产生了虚继承的语法。
虚拟继承的语法思路大致是这样的:
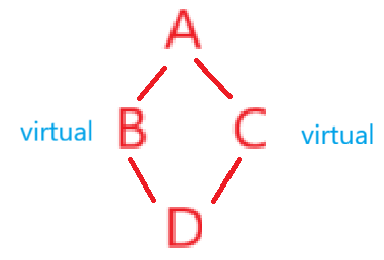
D的成员变量二义性和冗余问题就是由于B C都是继承A的,给B C带上虚继承解决。
也就是基类的直接派生类需要加virtual关键字进行虚继承。
语法格式:
class Person
{
public:string _name;
};class Student : virtual public Person
{
protected:int _num;
};
class Teacher : virtual public Person
{
protected:int _id;
};class Assistant: public Student,public Teacher
{
protected:string _major_course;
};int main()
{Assistant a;a._name = "张三"; //a.Student::_name = "张三";//a.Teacher::_name = "张老师";return 0;
}
这就是利用虚继承解决问题大致格式。
虚继承大致设计就是这样的:
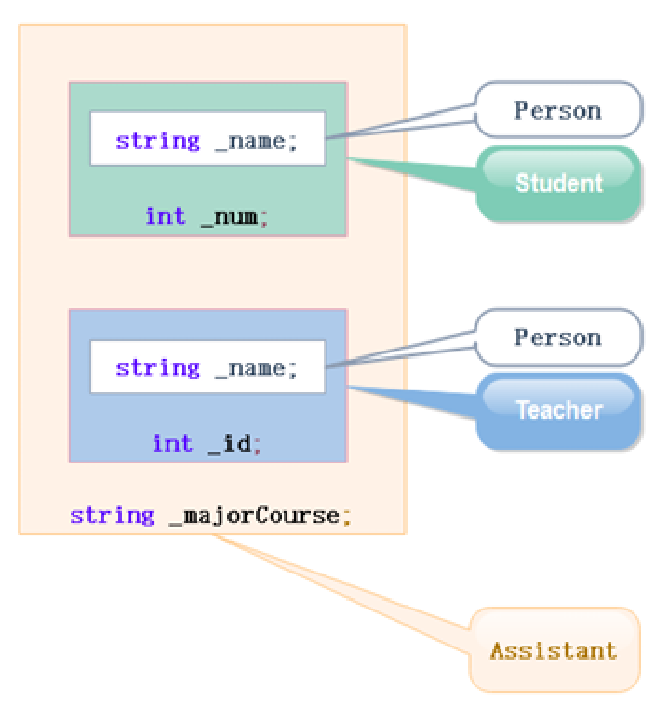
菱形继承不是这样的嘛,所以虚继承就将基类的对象独立出来,至多拿出来一份,也就是:
Assistant的实例化对象的内存中等于说只有_num,_id,_name这三个变量,在调试窗口其实也能看到:
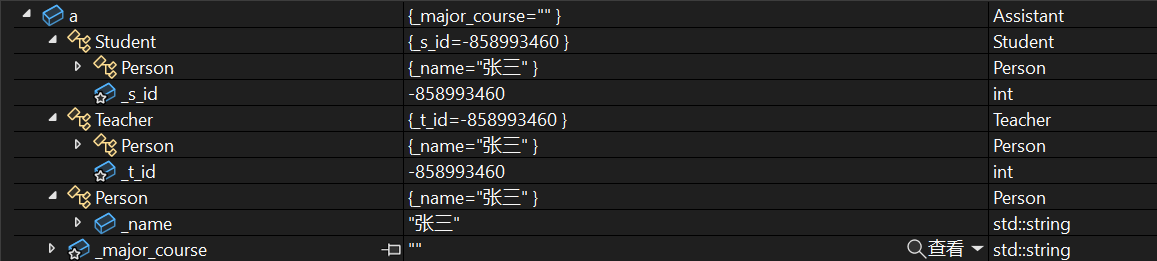
其实可以说VS这个监视窗口展示出来的Student和Teacher类中的Person其实都只是引用最下面那一坨Person来的。
3.菱形继承并用虚继承解决的场景
class Person
{
public:Person(const char* name):_name(name) {}string _name; //姓名
};
class Student : virtual public Person
{
public:Student(const char* name, int num):Person(name), _num(num){}
protected:int _num; //学号
};
class Teacher : virtual public Person
{
public:Teacher(const char* name, int id):Person(name), _id(id){}
protected:int _id; //职⼯编号
};class Assistant : public Student, public Teacher
{
public:Assistant(const char* name1, const char* name2, const char* name3):Person(name3),Student(name1, 1),Teacher(name2, 2){}
protected:string _majorCourse; // 主修课程
};int main()
{Assistant a("张三", "李四", "王五");return 0;
}请问最终a被虚继承处理过后保留的_name是张三李四还是王五。
根据我们刚讲过的内容,最终的类出现重复后被虚继承处理那就只保留一份Person类的成员作为最终类的成员,根据初始化列表的内容是name3,也就是王五。

其实细细品这段代码有很多地方让人很恼火:
- 最显而易见的问题就是我还得懂菱形继承造成的问题,以及虚继承怎么解决才能推导出来是实例化对象中存的到底是谁
- 实际上Student和Teacher类的_name的初始化根本没有什么作用,那我直接删了呗,但是继承体系中构造函数语法告诉我们不行,如果不能隐式调用(即使用默认构造函数),必须显式调用父类的构造函数初始化
- 既然Stuednt和Teacher类中没有默认构造,那干脆不显式写了,直接让编译器自然生成算了呗,Assistant类不就不用管这俩类了,你这样这构造的问题是解决了,那我问你,Student难道不能自己直接用吗?如果这样的话请问Student实例化对象没有构造可用怎么办
都是非常麻烦的问题,所以现实应用中可以用多继承,但是千万要避开菱形继承的问题,避免潜在问题。
4.多继承指针指向问题
class Base1 { public: int _b1; };
class Base2 { public: int _b2; };
class Derive : public Base1, public Base2 { public: int _d; };
int main()
{Derive d;Base1* p1 = &d;Base2* p2 = &d;Derive* p3 = &d;return 0;
}对于上面的代码,正确答案是:
A:p1 == p2 == p3
B:p1 < p2 < p3
C:p1 == p3 != p2
D:p1 != p2 != p3
用到的语法就是,编译器会根据先父后子的初始化方式存放变量,如果有多个父亲就会根据继承时的声明的顺序存放变量,所以最后大致就是:
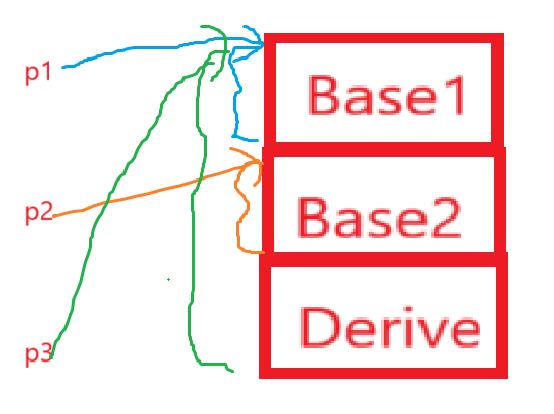
根据我们学习的切片(其实也就是派生类对象赋值给基类指针/引用的行为),就是如图所示,所以答案也就呼之欲出了——C。
5.IO库的菱形继承
其实看见这个小标题就知道,其实菱形继承也不是说完全用不到,当然,编写IO库的大佬们用用就行了,我这种小乐色就别沾边了,小心引火上身。
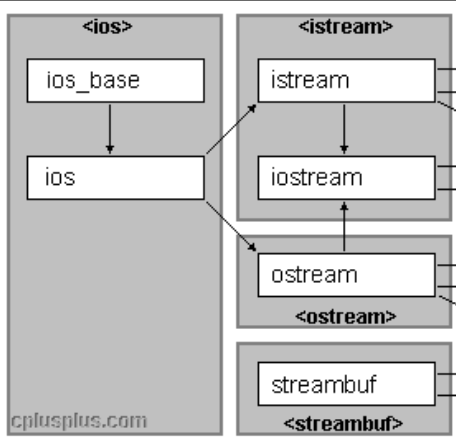
画成竖着的就是:
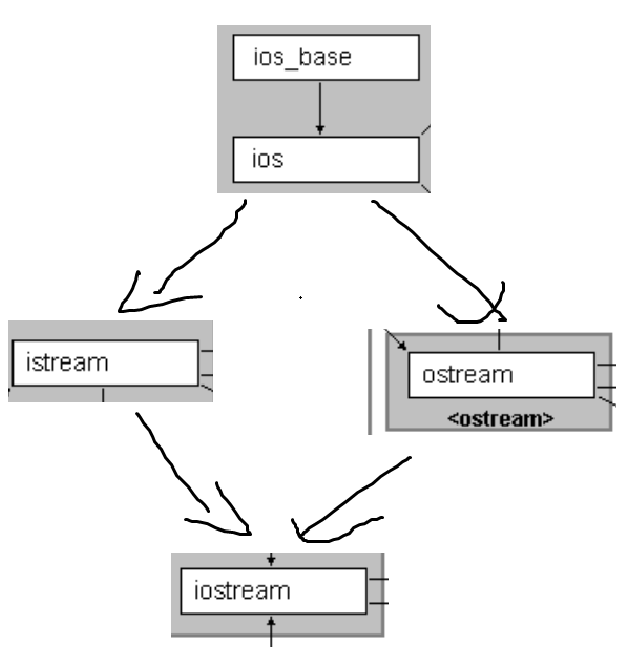
瞻仰瞻仰,知道真有人用到实践中就行。
八、继承和组合
特性 | 继承 (Inheritance) | 组合 (Composition) |
|---|---|---|
关系类型 | "is-a" (是一个) | "has-a" (有一个) / "uses-a" (用一个) |
耦合度 | 高耦合:子类与父类紧密绑定,父类改动可能影响所有子类 | 低耦合:通过接口交互,内部实现变化不影响使用者 |
复用类型 | 白箱复用:子类知晓父类的实现细节(包括 protected 成员) | 黑箱复用:仅通过公共接口交互,不关心内部实现 |
灵活性 | 较差:编译时确定,静态。派生类无法在运行时替换基类行为 | 较高:可在运行时动态替换组合的对象,行为可变 |
多态支持 | 天然支持:通过虚函数实现运行时多态 | 不直接支持:需通过接口或抽象类间接实现类似效果 |
封装性 | 破坏封装:基类的保护(protected)成员对派生类可见 | 保持封装:只能通过公共接口访问被组合对象,内部细节被隐藏 |
借助一段代码我们来大致说一下这两种方式:
// Tire(轮胎)和Car(⻋)更符合has - a的关系
class Tire {
protected:string _brand = "Michelin";//品牌size_t _size = 17;//尺⼨
};
class Car {
protected:string _colour = "⽩⾊";//颜色 string _num = "豫ABIT00";//车牌号 Tire _t1;//轮胎Tire _t2;//轮胎Tire _t3;//轮胎Tire _t4;//轮胎
};
class BMW : public Car {
public:void Drive() {cout << "好开操控" << endl; }};// Car和BMW/Benz更符合is - a的关系
class Benz : public Car {
public:
void Drive() {cout << "好坐舒适" << endl; }
};
template<class T>
class vector
{};
// stack和vector的关系,既符合is - a,也符合has - a
template<class T>
class stack : public vector<T>
{};
template<class T>
class stack
{
public:vector<T> _v;
};
int main()
{return 0;
}
大概看几眼其实就明白了啥叫继承啥叫组合,比如一个轮胎类一个车类,肯定是车有轮胎,总不能说车是轮胎;到后面也有那几个牌子肯定是车,不能说有车;至于stack和vector之间其实两种关系都有但是总的来说其实还是组合用起来更合适。
耦合性
关于继承的高耦合大概发生在,一般来说子类能够访问父类所有的protected和public成员,public成员就不说了,但是protected成员如果是变量的话,意味着子类可能借助变量完成一些操作;如果是函数的话,那么父类的参数类型了、参数个数了、返回类型了一旦发生变化,因为基本上子类和父类的方法通用嘛,子类的方法复用了父类方法,父类方法的改变就可能导致牵一发动全身。
与之对比,组合就没有这样的烦恼,它不访问内部不想暴露的操作,只保留有限的接口,而且我们往往用起来只用接口的行为,不与底层实现掺和。
至于其他的性质,看看知道就行,多态马上学习。