Notepad文本编辑器正则替换查询使用指南
日常工作中总少不了和各种文本打交道,不管是处理代码里的变量名、注释,还是从日志文件里提取关键信息,又或是对大量数据进行格式规整,文本处理的场景无处不在。但很多时候,面对那些重复性高、规律性强的文本处理任务,常规的查找替换方法就显得力不从心,效率低下,让人抓狂。
不过别担心,今天就给大家介绍一个超级强大的工具 —— 正则替换,它堪称一款秘密武器,Notepad等记事本工具自带功能。只要掌握了正则替换,那些看似繁琐复杂的文本处理难题,都能轻松迎刃而解,帮你大幅提升工作效率,节省大把时间。
了解 Notepad 文本编辑器的正则语法
1、什么是正则表达式?
正则表达式,听着好像挺高深,其实理解起来并不难。简单来说,它就是用一些特定的字符和规则,组合成一个 “字符串模板”,用来在文本里查找、匹配符合特定模式的内容。比如,想要在一堆文本里找出所有的邮箱地址,或者提取出所有的电话号码,又或是把特定格式的日期统一修改,这些都能借助正则表达式来实现 。
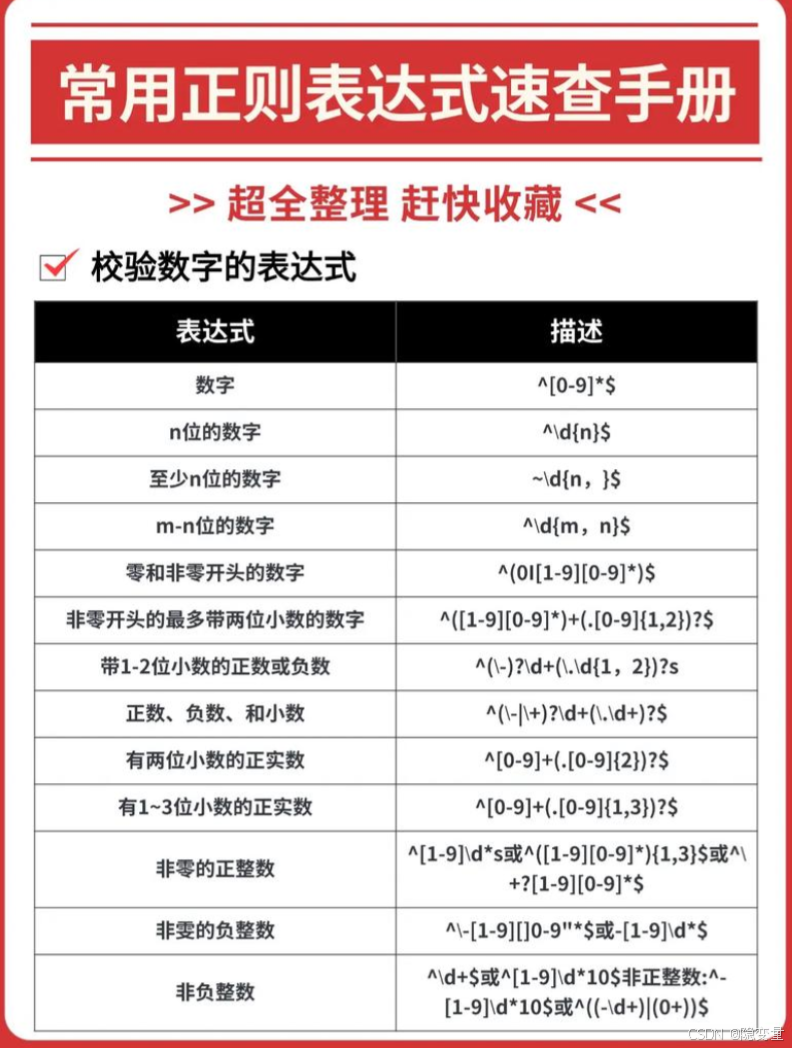
正则表达式里有一些特殊的字符,被称为 “元字符”,它们各自有着独特的含义和作用。像 “.” 能匹配除换行符之外的任意单个字符;“*” 表示它前面的字符可以出现 0 次或者多次;“\d” 专门匹配数字;“^” 用来匹配字符串的开头;“$” 则匹配字符串的结尾。比如 “\d {3}-\d {2}-\d {4}” 这个正则表达式,它能匹配类似 “123 - 45 - 6789” 这样格式的内容,常用来验证美国社会安全号码格式 。
正则表达式匹配文本的原理,有点像我们在玩拼图游戏。它从文本的开头开始,一个字符一个字符地按照我们设定的规则去比对,就像拼图时一块一块地去找合适的拼图块。一旦发现某个部分和我们设定的正则表达式模式完全吻合,那就找到了匹配的内容。要是一直比对到文本末尾都没找到符合的,那就说明这次匹配失败了。举个例子,用 “abc” 这个简单的正则表达式去匹配 “abcdef”,从开头的 “a” 开始,依次比对 “b” 和 “c”,发现完全一致,就匹配成功啦;要是去匹配 “defabc”,因为开头不匹配,就会匹配失败。
2、Notepad 文本记事本正则替换功能使用
Notepad 文本记事本作为一款超实用的文本编辑工具,自然也支持强大的正则替换功能。下面就来详细看看怎么在 Notepad 里使用这个功能。
首先,打开 Notepad,加载好我们需要处理的文本文件。
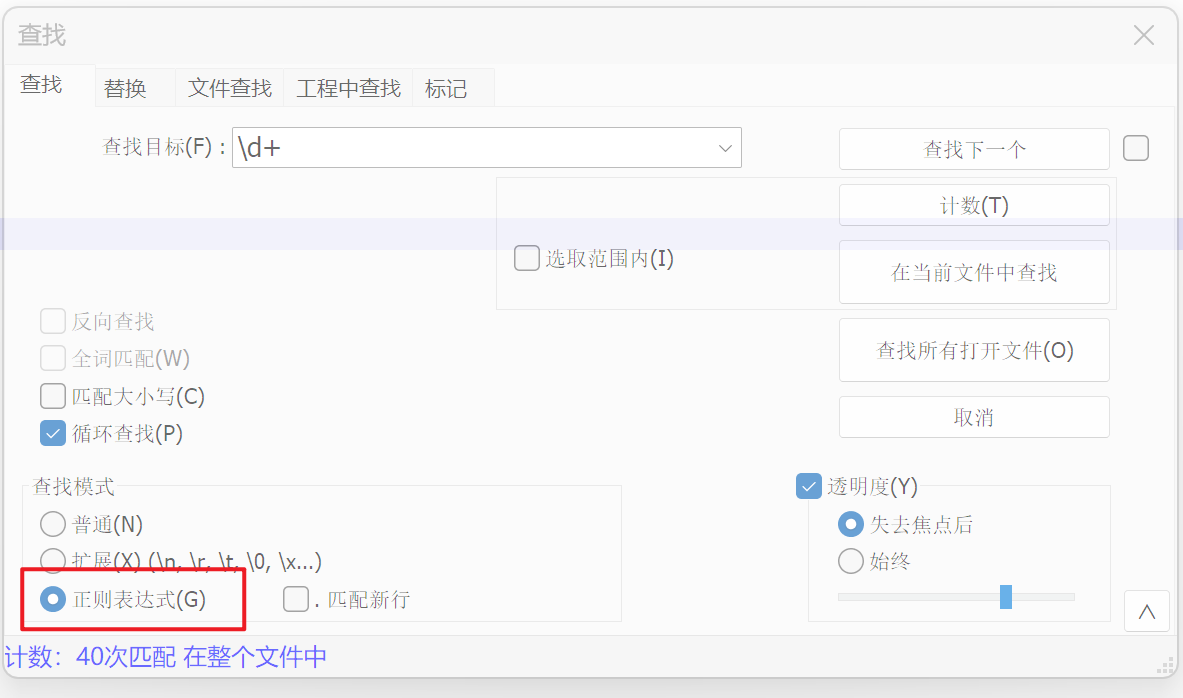
2.1、正则查询
然后,按下快捷键 “Ctrl + F,这时候就会弹出 “查询” 对话框。在这个对话框里,有几个关键的部分:
正则表达式” 勾选框:这个一定得勾选上,只有勾选了它,Notepad 才会按照正则表达式的规则去处理文本。要是没勾选,就只是进行普通的字符串查找替换。
点击查找、计数
2.2、正则替换
然后,按下快捷键 “Ctrl + H”,这时候就会弹出 “替换” 对话框。在这个对话框里,有几个关键的部分:
“查找内容” 输入框:这里用来填写我们的正则表达式,也就是设定要查找的文本模式。比如想找出所有数字,就在这里输入 “\d+”。
“替换为” 输入框:填写替换后的内容。假设要把找到的数字都替换成 “[数字]”,就在这里输入 “[数字]”。
“正则表达式” 勾选框:这个一定得勾选上,只有勾选了它,Notepad 才会按照正则表达式的规则去处理文本。要是没勾选,就只是进行普通的字符串查找替换。
比如,有一段文本 “苹果 1 个,香蕉 2 根,橙子 3 个”,现在想把里面的数字都提取出来,放在括号里。我们就在 “查找内容” 里输入 “(\d+)”,“替换为” 里输入 “([\1])”,勾选 “正则表达式”,然后点击 “全部替换”,就能得到 “苹果 [1] 个,香蕉 [2] 根,橙子 [3] 个” 。这里的 “(\d+)” 表示匹配一个或多个数字,并且把匹配到的数字作为一个组保存起来;“[\1]” 中的 “\1” 就代表前面保存的第一个组,也就是我们匹配到的数字,这样就能实现把数字用括号括起来的效果。
实战演练:正则替换的神奇应用
光说不练假把式,接下来就通过几个实际的例子,带大家感受一下正则替换在 Notepad 文本记事本中的强大威力。
应用一:批量修改代码变量名
假设我们有一段 Python 代码,里面定义了很多变量,现在需求是把所有以 “old” 开头的变量名,都改成以 “new” 开头,同时保留原来变量名的后半部分。比如 “old_variable1” 要改成 “new_variable1”。原代码示例如下:
old_variable1 = 10 old_variable2 = "hello" result = old_variable1 + len(old_variable2) print(result)
在 Notepad 中,打开这段代码文件,按下 “Ctrl + H” 打开替换对话框。在 “查找内容” 输入框中填写正则表达式:old(\w+),这里 “old” 是我们要匹配的固定前缀,“(\w+)” 表示匹配一个或多个字母、数字或下划线字符,并且把这部分内容作为一个组保存起来 ,也就是我们要保留的变量名后半部分。在 “替换为” 输入框中填写:new\1,“new” 是新的前缀,“\1” 代表前面保存的第一个组,也就是原来变量名的后半部分。勾选 “正则表达式”,然后点击 “全部替换”。替换后的代码如下:
new_variable1 = 10 new_variable2 = "hello" result = new_variable1 + len(new_variable2) print(result)
通过这样简单的操作,就快速完成了所有符合条件变量名的修改,要是手动一个个改,不仅耗时费力,还容易出错 。
应用二:清理日志文件中的冗余信息
在日常开发和运维中,经常会遇到日志文件,而这些日志文件里往往包含很多冗余信息,比如时间戳、日志级别等,我们只关心关键的业务信息,这时候就可以用正则替换来清理冗余。假设日志文件内容如下:
2024 - 01 - 01 12:00:00 INFO [main] This is a log message 1 2024 - 01 - 01 12:01:00 ERROR [thread - 1] This is an error log message 2
这里的时间戳(2024 - 01 - 01 12:00:00)和日志级别(INFO、ERROR)以及线程信息([main]、[thread - 1])对我们分析业务逻辑可能不是很重要,我们想把这些冗余信息去掉,只保留关键的日志消息。在 Notepad 的替换对话框中,“查找内容” 输入:\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2} \w+ \[.?\] ,这个正则表达式的含义是:\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}匹配时间戳格式,\w+匹配日志级别(INFO、ERROR 等单词),\[.?\]匹配中括号里的线程信息,其中.*?表示非贪婪匹配,尽可能少地匹配字符,直到遇到下一个中括号 。“替换为” 输入框留空,勾选 “正则表达式”,点击 “全部替换”。清理后的日志内容就变成了:
This is a log message 1 This is an error log message 2
这样日志文件变得简洁明了,更便于我们快速定位和分析关键信息。
应用三:转换数据格式
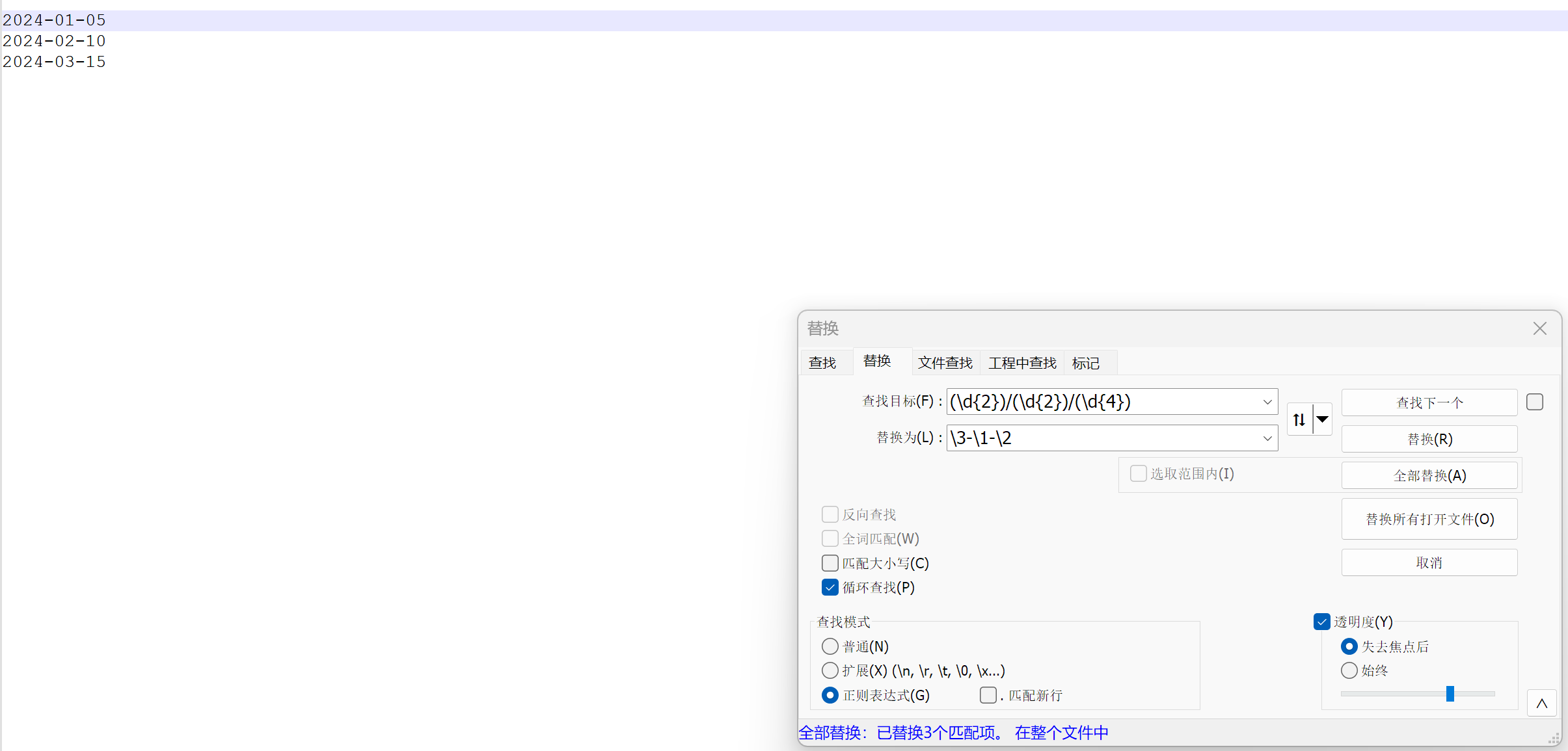
在数据处理中,经常会遇到需要转换数据格式的情况。比如,有一批日期数据,格式是 “MM/dd/yyyy”,现在要把它转换成 “yyyy - MM - dd” 的格式,方便后续的数据处理和分析。假设原始数据如下:
01/05/2024 02/10/2024 03/15/2024
在 Notepad 的替换对话框中,“查找内容” 输入:(\d{2})/(\d{2})/(\d{4}),这里三个括号分别捕获了月、日、年的部分 。“替换为” 输入:\3-\1-\2,表示把捕获到的年、月、日按照新的格式重新组合。勾选 “正则表达式”,点击 “全部替换”。转换后的日期格式如下:
2024 - 01 - 05 2024 - 02 - 10 2024 - 03 - 15
通过正则替换,轻松实现了日期格式的转换,提高了数据处理的效率和规范性。
正则替换进阶技巧与注意事项
巧用捕获组和反向引用
在正则表达式里,捕获组是个很重要的概念,它允许我们把正则表达式里的一部分子表达式括起来,当作一个整体进行处理,还能在后续的匹配或替换中引用这部分匹配到的内容 。捕获组用小括号 “()” 来表示,从左到右,按照左括号出现的顺序,依次编号为 1、2、3…… 比如 “(\d {4})-(\d {2})-(\d {2})” 这个正则表达式,就定义了三个捕获组,分别捕获年份、月份和日期。
反向引用则是在替换或后续匹配时,引用之前捕获组匹配到的内容。在 Notepad 的正则替换中,用 “\ 数字” 的形式来表示反向引用,“数字” 对应捕获组的编号 。比如在前面批量修改代码变量名的例子里,“old(\w+)” 中 “(\w+)” 是第一个捕获组,在替换时 “new\1” 里的 “\1” 就引用了这个捕获组匹配到的变量名后半部分。
再举个更复杂点的例子,假设我们有一段 HTML 代码,里面有很多图片标签,现在想给所有图片标签添加一个固定的 class 属性 “img - class”。原始 HTML 代码如下:
<img src="image1.jpg"> <img src="image2.jpg">
在 Notepad 的替换对话框中,“查找内容” 输入:,这里 “(.*?)” 是一个捕获组,用来捕获图片的 src 属性值 ,采用非贪婪匹配,确保只捕获到第一个双引号内的内容。“替换为” 输入:,“\1” 引用前面捕获组匹配到的 src 属性值,这样就能实现给每个图片标签添加 class 属性的效果,替换后的代码如下:
<img class="img - class" src="image1.jpg"> <img class="img - class" src="image2.jpg">
解决常见问题
在使用正则替换时,难免会遇到各种各样的问题,下面就给大家列举一些常见问题及对应的解决方法。
正则表达式错误:
语法错误:这是最常见的问题,比如括号不匹配、元字符使用不当等。比如想匹配一个数字,写成 “\d”(少了一个反斜杠),这就是语法错误。解决办法是仔细检查正则表达式语法,多参考正则表达式语法文档。也可以借助一些在线正则表达式测试工具,像 Regex101、RegExr 等,在这些工具里输入正则表达式和测试文本,能直观地看到匹配结果和错误提示 。
匹配错误:有时候正则表达式语法没错,但就是匹配不到想要的内容,或者匹配到的内容不符合预期。比如想匹配邮箱地址,用了简单的 “[a - z]+@[a - z]+.com”,可能会匹配到一些不符合邮箱格式规范的字符串。这时候就需要细化正则表达式,比如改成 “\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*”,让匹配更精确。
性能问题:
表达式复杂度过高:如果正则表达式里有大量的嵌套、分支或者使用了贪婪匹配,可能会导致匹配速度变慢,特别是处理大文本时,性能问题会更明显。比如 “.” 这种贪婪匹配,会尽可能多地匹配字符,容易造成不必要的回溯,影响性能。可以尽量使用非贪婪匹配 “.?”,或者简化表达式结构,减少不必要的嵌套和分支。
多次重复匹配:如果在循环里多次使用同一个正则表达式进行匹配,每次都编译正则表达式会很耗费性能。在 Notepad 中虽然没有像编程语言中那样可以显式预编译正则表达式的操作,但我们可以尽量避免不必要的重复替换操作。如果确实需要多次执行相同的正则替换,可以先在小范围文本上测试好,确保无误后再应用到整个大文本中 。
.与
.?的区别是什么?正则表达式中,
.匹配任意单个字符(除换行符外),且是贪婪匹配;而.?中的?是量词,表示匹配前面的元素(即.)0 次或 1 次,是惰性匹配,最多匹配一个任意字符。简单说:
.一定会匹配一个字符,.?则可能匹配 0 个或 1 个字符(尽可能少地匹配)。例如,对字符串 "abc":
a.c会匹配 "abc"(.匹配了 "b")a.?c也会匹配 "abc"(.?匹配了 "b")对字符串 "ac",
a.c无法匹配,但a.?c可以匹配(.?匹配了 0 个字符)
附:正则表达式语法
1、特殊字符(元字符):
.:匹配任意单个字符(除换行符,可通过模式修正符改变)^:匹配字符串开始位置$:匹配字符串结束位置*:匹配前面元素 0 次或多次(贪婪模式)+:匹配前面元素 1 次或多次?:匹配前面元素 0 次或 1 次;或用于非贪婪模式(跟在*/+/?后)|:匹配左右任意一个表达式(如a|b匹配 "a" 或 "b")():分组,将表达式组成子模式,可用于捕获或限定范围
2、预定义字符集:
\d:匹配数字(等价[0-9])\D:匹配非数字(等价[^0-9])\w:匹配字母、数字、下划线(等价[a-zA-Z0-9_])\W:匹配非单词字符\s:匹配空白字符(空格、制表符等)\S:匹配非空白字符
3、字符集:
[abc]:匹配 a、b、c 中的任意一个[^abc]:匹配除 a、b、c 外的任意字符[a-z]:匹配任意小写字母(同理[A-Z]、[0-9])
4、量词:
{n}:匹配前面元素恰好 n 次{n,}:匹配至少 n 次{n,m}:匹配 n 到 m 次(包含两端)
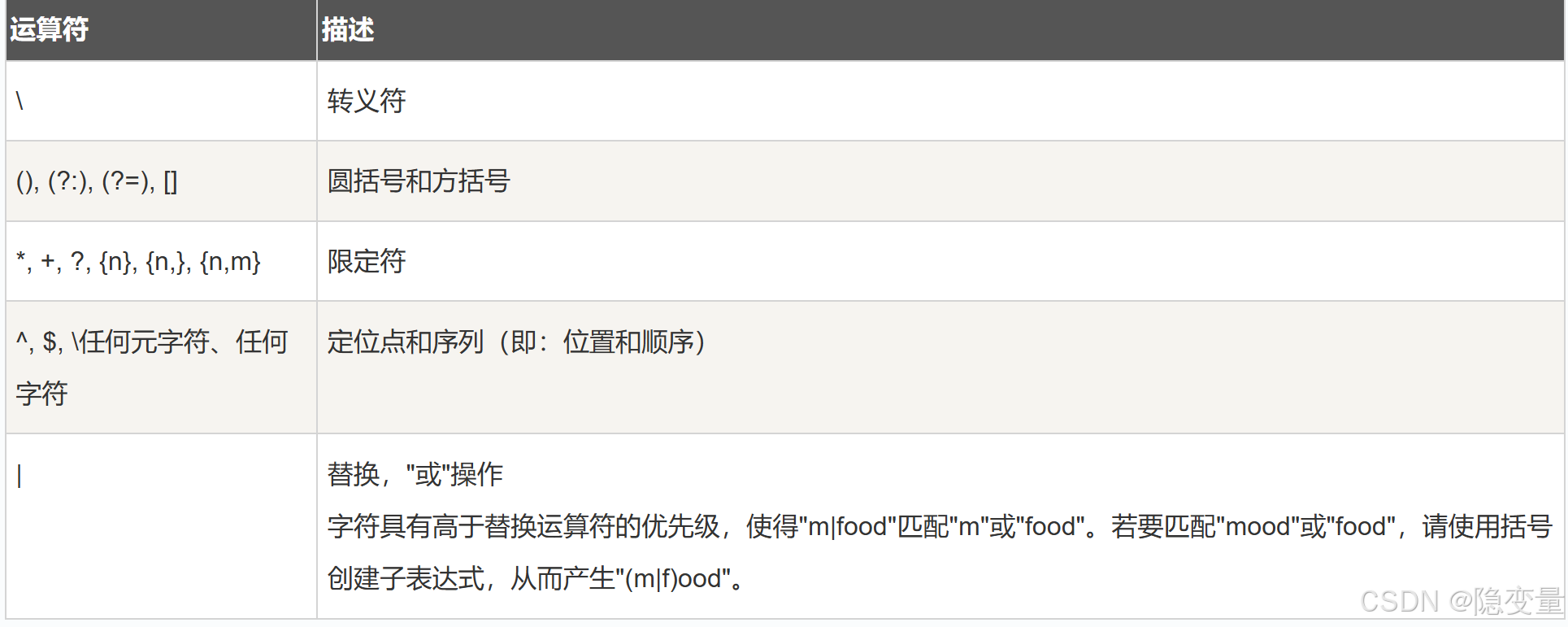
5、运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
其他正则表示公式组合参考: