初识seatunnel
seatunnel的中文文档https://seatunnel.apache.org/zh-CN/docs/2.3.12/about/
一、seatunnel简介
SeaTunnel 是一款开源的高性能、分布式数据集成平台,主要用于解决多源数据的同步、转换和集成问题,支持批处理和流处理两种模式。它的核心目标是简化复杂数据场景下的 ETL(抽取、转换、加载)流程,帮助企业快速构建数据管道。SeaTunnel 是一款开源的高性能、分布式数据集成平台,主要用于解决多源数据的同步、转换和集成问题,支持批处理和流处理两种模式。它的核心目标是简化复杂数据场景下的ETL(抽取、转换、加载)流程,帮助企业快速构建数据管道。
核心特点
- 多源多目标支持
内置丰富的连接器(Connector),可对接数十种数据源和目标系统,包括:
-
- 关系型数据库:MySQL、PostgreSQL、Oracle、SQL Server 等;
- 大数据存储:HDFS、Hive、HBase、Iceberg、Doris、ClickHouse 等;
- 消息队列:Kafka、RabbitMQ 等;
- 文件类型:CSV、JSON、Parquet 等。
- 批流一体
统一的架构支持批处理(BATCH)和流处理(STREAMING),无需为两种模式单独开发任务,降低维护成本。 - 高性能与可扩展性
-
- 基于分布式计算框架(支持 Flink、Spark 或 SeaTunnel 自研引擎),可横向扩展以处理海量数据;
- 支持并行读写、数据分片、批量提交等优化,提升同步效率。
- 易用性
-
- 采用 YAML 配置文件定义数据同步任务,无需编写代码,降低使用门槛;
- 提供 SQL 转换能力,支持用 SQL 进行数据清洗、过滤、聚合等操作。
- 可靠性
支持数据一致性保障(如事务、Checkpoint 机制),确保数据同步过程中不丢失、不重复。
核心组件
- Source:数据输入组件,负责从各类数据源读取数据(如 MySQL、Kafka 等)。
- Transform:数据转换组件,对读取的数据进行清洗、转换、过滤等操作(如 SQL 转换、字段映射、类型转换等)。
- Sink:数据输出组件,将处理后的数据写入目标系统(如 Doris、Hive 等)。
- Engine:执行引擎,负责任务的调度和运行(支持 Flink、Spark 或 SeaTunnel Engine)。
典型应用场景
- 数据同步:将业务数据库(如 MySQL)的数据同步到数据仓库(如 Doris、ClickHouse);
- 多源数据集成:合并来自数据库、文件、消息队列的异构数据,构建统一数据视图;
- 实时数据管道:通过流处理模式,实时同步 Kafka 数据到数据湖或实时数仓;
- 数据清洗与转换:在同步过程中完成数据脱敏、格式转换、字段补全等操作。
优势对比
相比传统 ETL 工具(如 DataX、Sqoop),SeaTunnel 的优势在于:
- 支持批流一体,适应更多场景;
- 内置 SQL 转换能力,无需编写复杂代码;
- 基于分布式架构,性能可扩展,适合海量数据场景;
- 社区活跃,连接器丰富且持续更新。
二、具体同步实现
1、seatunnel数据库同步的实现
env {parallelism = 3job.mode = "BATCH"log.level = "INFO"
}source {Jdbc {url = "jdbc:oracle:thin:@localhost:1521/rptdb"driver = "oracle.jdbc.OracleDriver" # Oracle驱动类(固定值)username = "ledrpt" # Oracle账号password = "ledrpt" # Oracle密码query = "SELECT * FROM EDH.OM_ZZJGCJ_BU22_TODAY"fetch_size = 1000}
}transform {}sink {Jdbc {# MySQL JDBC连接信息url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"driver = "com.mysql.cj.jdbc.Driver" # MySQL 8.0+驱动类(固定值)username = "root" # MySQL账号password = "123456" # MySQL密码# 目标库表信息database = "test" # MySQL目标数据库名table = "test_table111" # MySQL目标表名(无需手动创建)# 核心配置:自动创建MySQL表(若不存在)create_table_if_not_exists = true # 开启自动建表(关键参数)table_engine = "InnoDB" # 表引擎(默认InnoDB,支持事务)table_charset = "utf8mb4" # 字符集(支持emoji,避免乱码)# 写入配置generate_sink_sql = true # 自动生成插入SQL(无需手动写)write_mode = "append" # 写入模式:append(追加)/ replace(替换)/ update(更新)batch_size = 1000 # 批量写入大小(减少数据库交互)}
}2、编写udf函数在transform中实现数据清洗的功能
字符拼接官方demo
package org.example;import com.google.auto.service.AutoService;
import org.apache.seatunnel.api.table.type.BasicType;
import org.apache.seatunnel.api.table.type.SeaTunnelDataType;
import org.apache.seatunnel.transform.sql.zeta.ZetaUDF;import java.util.List;@AutoService(ZetaUDF.class)
public class ExampleUDF implements ZetaUDF {@Overridepublic String functionName() {System.out.println("ExampleUDF loaded");return "EXAMPLE";}@Overridepublic SeaTunnelDataType<?> resultType(List<SeaTunnelDataType<?>> argsType) {System.out.println("ExampleUDF argsType: " + argsType);return BasicType.STRING_TYPE;}@Overridepublic Object evaluate(List<Object> args) {System.out.println("ExampleUDF 已经加载 " + args);String arg = (String) args.get(0);if (arg == null) return null;return "UDF: " + arg;}
}手机号码脱敏
package org.example;import com.google.auto.service.AutoService;
import org.apache.seatunnel.api.table.type.BasicType;
import org.apache.seatunnel.api.table.type.SeaTunnelDataType;
import org.apache.seatunnel.transform.sql.zeta.ZetaUDF;import java.util.List;@AutoService(ZetaUDF.class)
public class PhoneDesensitizeUDF implements ZetaUDF {@Overridepublic String functionName() {System.out.println("PhoneDesensitizeUDF loaded");return "PHONE_DESENSITIZE";}@Overridepublic SeaTunnelDataType<?> resultType(List<SeaTunnelDataType<?>> argsType) {System.out.println("PhoneDesensitizeUDF argsType: " + argsType);// 确保输入是字符串类型if (argsType.size() != 1 || !(argsType.get(0) instanceof BasicType &&((BasicType<?>) argsType.get(0)).getTypeClass() == String.class)) {throw new IllegalArgumentException("PHONE_DESENSITIZE requires one string argument");}return BasicType.STRING_TYPE;}@Overridepublic Object evaluate(List<Object> args) {System.out.println("PhoneDesensitizeUDF evaluating: " + args);// 检查输入参数if (args == null || args.size() != 1 || args.get(0) == null) {return null;}String phone = args.get(0).toString();// 简单的手机号校验和脱敏处理if (phone.matches("^1[3-9]\\d{9}$")) {return phone.substring(0, 3) + "****" + phone.substring(7);}// 非标准手机号格式不做处理,直接返回原内容return phone;}
}
数据运算
package org.example;import com.google.auto.service.AutoService;
import org.apache.seatunnel.api.table.type.BasicType;
import org.apache.seatunnel.api.table.type.SeaTunnelDataType;
import org.apache.seatunnel.transform.sql.zeta.ZetaUDF;import java.util.List;@AutoService(ZetaUDF.class)
public class IncomeSumUDF implements ZetaUDF {@Overridepublic String functionName() {System.out.println("IncomeSumUDF loaded");return "INCOME_SUM";}@Overridepublic SeaTunnelDataType<?> resultType(List<SeaTunnelDataType<?>> argsType) {System.out.println("IncomeSumUDF argsType: " + argsType);// 确保输入是两个数值类型if (argsType.size() != 2) {throw new IllegalArgumentException("INCOME_SUM requires two numeric arguments");}// 改为返回长整型类型,适配BIGINTreturn BasicType.LONG_TYPE;}@Overridepublic Object evaluate(List<Object> args) {System.out.println("IncomeSumUDF evaluating: " + args);// 检查输入参数if (args == null || args.size() != 2) {return null;}// 将输入转换为Long进行计算(适配BIGINT)Long salary = toLong(args.get(0));Long wage = toLong(args.get(1));if (salary == null || wage == null) {return null;}// 计算总和并返回return salary + wage;}// 辅助方法:将对象转换为Longprivate Long toLong(Object obj) {if (obj == null) {return null;}if (obj instanceof Long) {return (Long) obj;} else if (obj instanceof Number) {return ((Number) obj).longValue();} else if (obj instanceof String) {try {return Long.parseLong((String) obj);} catch (NumberFormatException e) {System.err.println("Invalid number format: " + obj);return null;}}return null;}
}
如果在服务器上运行需要install之后讲jar包上传到对应的lib下面
如果在本地运行的话就是自动加载到maven仓库中了,可以直接调用对应的自定义函数
配置文件为
env {job.mode = "BATCH"
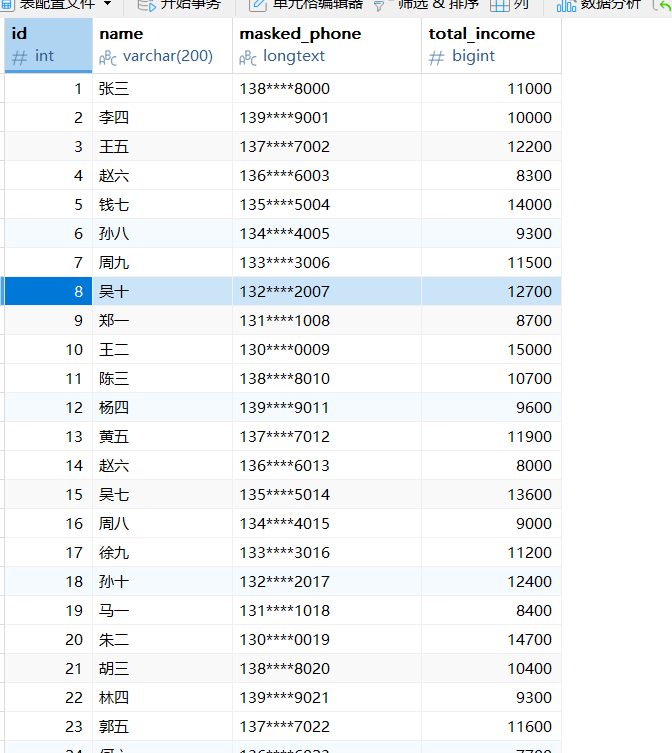
}source {Jdbc {plugin_output = "fake"url = "jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2b8&useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"driver = "com.mysql.cj.jdbc.Driver"connection_check_timeout_sec = 100username = "root"password = "123456"query = "select * from employees"}}transform {Sql {plugin_input = "fake"plugin_output = "fake1"query = "select id,name,PHONE_DESENSITIZE(phone) as masked_phone, INCOME_SUM(salary, wage) as total_income from employees"}
}sink {Jdbc {plugin_input = "fake1"# MySQL JDBC连接信息url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"driver = "com.mysql.cj.jdbc.Driver" # MySQL 8.0+驱动类(固定值)username = "root" # MySQL账号password = "123456" # MySQL密码# 目标库表信息database = "test" # MySQL目标数据库名table = "newemployee2" # MySQL目标表名(无需手动创建)# 核心配置:自动创建MySQL表(若不存在)create_table_if_not_exists = true # 开启自动建表(关键参数)table_engine = "InnoDB" # 表引擎(默认InnoDB,支持事务)table_charset = "utf8mb4"# 写入配置generate_sink_sql = true # 自动生成插入SQL(无需手动写)write_mode = "append" # 写入模式:append(追加)/ replace(替换)/ update(更新)batch_size = 1000}
}
一个问题:
在单一数据源、单一转换、单一输出的简单场景中,plugin_input和plugin_output确实不是必须显式配置的,SeaTunnel 会使用默认规则自动衔接数据流。
SeaTunnel 的默认数据流规则
当不配置plugin_input和plugin_output时,SeaTunnel 会按组件的顺序和类型自动建立数据连接:
source的输出会默认传递给第一个 transform(如果有);transform的输出会默认传递给下一个组件(可能是另一个 transform 或 sink);sink会默认接收最后一个 transform 的输出(如果没有 transform,则直接接收 source 的输出)。
在以下情况必须显式配置:
- 多组件串联:当有多个 transform 时(如
transform1 → transform2),需要用标签明确衔接; - 分支数据流:当数据需要 “分流”(如一部分数据写入表 A,另一部分写入表 B),需要用标签区分不同流向;
- 多源数据合并 / 关联:当有多个 source 时(如同时读取 MySQL 和 PostgreSQL),需要用标签指定 “哪个数据给哪个组件处理”。
参考示例:source是输入,sink是结束的输入
env {job.mode = "BATCH"
}source {# 数据源1:MySQL表Jdbc {plugin_output = "mysql_data"url = "jdbc:mysql://mysql-host:3306/db1"driver = "com.mysql.cj.jdbc.Driver"username = "user"password = "pass"query = "select id, name, create_time, salary from mysql_employees"}# 数据源2:PostgreSQL表Jdbc {plugin_output = "pg_data"url = "jdbc:postgresql://pg-host:5432/db2"driver = "org.postgresql.Driver"username = "user"password = "pass"query = "select uid, username, reg_date, income from pg_staff"}
}transform {# 处理MySQL数据:类型转换 + 字段映射Sql {plugin_input = "mysql_data"plugin_output = "mysql_processed"query = "select CAST(id AS BIGINT) as user_id, -- 整数(INT)转长整数(BIGINT)CAST(name AS VARCHAR) as user_name, -- 确保字符串类型统一CAST(create_time AS DATETIME) as event_time, -- 统一时间类型CAST(salary AS DECIMAL(10,2)) as total_income, -- 小数类型统一'mysql' as data_source -- 补充数据源标识from mysql_data"}# 处理PostgreSQL数据:类型转换 + 字段映射Sql {plugin_input = "pg_data"plugin_output = "pg_processed"query = "select CAST(uid AS BIGINT) as user_id, -- 保持与MySQL一致的ID类型CAST(username AS VARCHAR) as user_name, -- TEXT转VARCHARCAST(reg_date AS DATETIME) as event_time, -- DATE转DATETIME(补全时分秒)CAST(income AS DECIMAL(10,2)) as total_income, -- FLOAT转DECIMAL(避免精度丢失)'postgresql' as data_source -- 补充数据源标识from pg_data"}# 合并两个处理后的数据源(结构已完全一致)Union {plugin_input = ["mysql_processed", "pg_processed"] # 接收两个标准化后的数据流plugin_output = "merged_data" # 合并后的输出}
}sink {# 写入Doris(字段结构已统一,可直接写入)Doris {plugin_input = "merged_data"fenodes = "doris-fe-host:8030"username = "doris_user"password = "doris_pass"database = "doris_db"table = "unified_employees"create_table_if_not_exists = true # 自动创建表(基于合并后的结构)write_mode = "append"}
}