学习优秀的项目 —— MST++
今天要学的这个项目是重建高光谱图像的项目。
整个项目代码规范,分为了数据集,训练,测试三个大的单独的文件夹。
从三个文件夹依次讲起:
训练文件夹(train_code)
在train_code中,放置train文件,dataset加载文件,utils工具文件,模型文件夹,exp下是保存的模型和训练日志。
architecture文件夹:
在train_code的architecture文件中,分开放置多个model构建的.py文件,并通过_init_.py文件中的模型加载函数model_generator()进行加载管理,根据传过来的文件名用 if 判断进行加载(比如model=mst_plus_plus().cuda()),
同时,如果有预训练的模型,想继续训练,那么在_init_.py中,通过torch.load(.pth文件路径)加载(反序列化)对应的.pth模型文件,取出字典里为state_dict键名的值,就是模型各个层的参数,即加载了预训练模型。
.pth文件里面是被序列化的字典,在训练过程保存模型时会首先保存成state字典,字典有四项:epoch ,iteration, state_dict(model各个层的权重偏置参数),optimizer(优化器的状态(学习率,梯度)),再通过touch.save()序列化字典后保存到.pth文件中。
train.py:
在train.py核心训练代码文件中,代码编写流程如下:
1、添加命令行参数:
首先添加一系列的命令行参数(每一条命令行参数指令需要添加该参数的名称,接收的参数类型以及默认值),然后通过opt = parser.parse_args()解析所有传入的命令行参数并将其存储在变量 opt 中,后面可以通过该变量(如opt.data_root)获取参数。
2、加载图像数据集:
调用同级下hdi_dataset.py里写好的两个类(训练集类和验证集类)分别加载训练集和验证集。写成类是因为在里面需要封装几个函数。
hdi_dataset.py中的TrainDadaset类中有__init__()初始化方法(加载图像文件,并对图像进行裁剪,划分patch,像素值归一化),argument()方法(对图像进行数据增强),__getitem__()方法调用前面的方法,如果有数据增强,调用argument方法,__len__求数据集处理后总长度方法,ValidDataset类中的方法类似,只是不再需要argument数据增强方法。
注:前后带有下划线的方法在python中的魔法方法,简单理解为这些方法是具有特殊含义的方法,用于实现类的特定行为。
读取图像,首先指定统一的存放文件的文件夹路径,然后读取时再循环读取通过文件夹路径+图像的列表索引,如果duquRGB图像,需要通过cv2库转化为BGR格式读取。
每一轮的interation是训练集总的图像个数,完整的图像有897张,每张图像划分为2205个patch,那么一轮总的图像数为2205*897保存模型。
3、实例化损失函数
这里的损失函数是较为简单的误差损失函数MRAE等,损失函数在utils中被写成了像模型一样的类( __int__()和 __forward__() )
4、初始化模型
通过前面提到的model_generater()方法初始化模型。
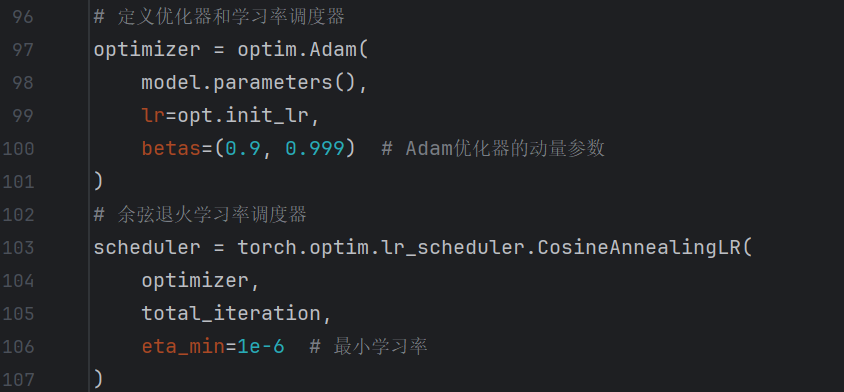
5、定义优化器和学习率调度器
这里采用Adam优化器,batas=(0.9,0.999)一般不做修改,余弦退火学习率调度器,(动态调整学习率,学习率会从初始值开始,随着训练迭代逐步下降,最终稳定在一个最小学习率附近,形成类似余弦曲线的变化趋势)。
6、初始化日志记录器

7、正式训练
main函数正式开始训练,循环得取出train_loader中的一个批次的训练图像和标签images和labels,获取当前的学习率,清空梯度,前向传播得到output,用labels和output 计算损失,反向传播,更新参数,更新学习率,更新损失记录,迭代次数➕1,设置一些打印信息,每隔20个iteration打印一次训练信息,每当模型迭代1000次(1000次iteration)时,在验证集上进行验证。
具体的验证方法:
调用验证函数validate()(写在main函数后面),把当前模型和验证数据集传入验证函数,
测试MRAE是否下降,如果是就保存模型,并更新当前最佳的MRAE,或者达到了5000次迭代,固定保存模型,并记录损失信息到训练日志train_log中。
最后需写一个程序入口: