大模型agent综述:A Survey on Large Language Model based Autonomous Agents
大模型agent综述:A Survey on Large Language Model based Autonomous Agents
论文链接:https://link.springer.com/content/pdf/10.1007/s11704-024-40231-1.pdf
一、摘要
- 自主agent长期以来一直是学术和工业界的研究重点。以前的研究通常侧重于在孤立的环境中训练知识有限的agent,这与人类学习过程有很大不同,并使agent难以实现类人决策。最近,通过获取大量网络知识,大型语言模型 (LLM) 在人类水平的智能方面显示出潜力,导致基于 LLM 的自主agent的研究激增。在本文中,我们对这些研究进行了全面调查,从整体的角度对基于 LLM 的自主agent进行了系统的回顾。我们首先讨论了基于LLM的自主agent的构建,提出了一个包含许多先前工作的统一框架。然后,我们概述了基于LLM的自主agent在社会科学、自然科学和工程中的各种应用。最后,我们深入研究了用于基于llm的自主agent的评估策略。基于之前的研究,我们也在该领域提出了几个挑战和未来的方向。
二、介绍
-
大语言模型取得了显著成功,显示出实现类人智能(human-like intelligence)的巨大潜力。这种能力主要来源于:一是利用了大规模、全面的训练数据集,二是拥有庞大的模型参数数量。
-
基于大模型的能力,一个很好的想法是:使用LLM作为核心控制器(central controller)来构建自主智能体,从而实现更类人的决策能力。与传统的强化学习(Reinforcement Learning, RL)方法相比,基于LLM的智能体具有更强的内部世界知识(world knowledge),即便没有在特定领域数据上训练,也能做出明智的决策。此外,LLM还能提供自然语言交互接口,增强了人机互动的灵活性与解释性
-
这个想法的核心思想是:赋予LLM类似人类的能力,比如记忆(memory)和规划(planning),从而使其像人类一样完成复杂任务。目前已经开发出多种具有前景的相关模型,如下图所示:
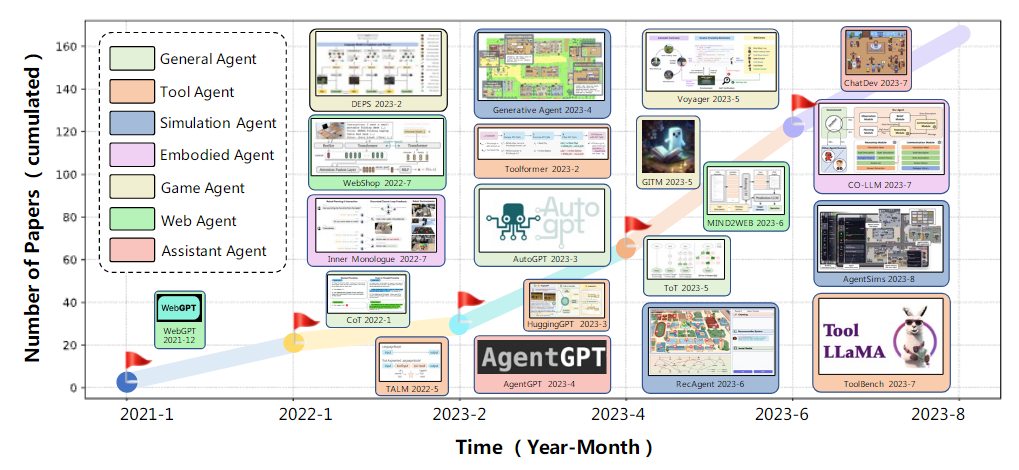
-
本文对基于LLM的自主智能体进行了全面的综述(comprehensive survey),围绕三个关键方面进行组织:构建(Construction)、应用(Application)和评估(Evaluation)。在智能体构建方面,我们聚焦于两个核心问题:
- 如何设计智能体架构,以便更好地利用LLM;
- 如何激发和增强智能体的能力,以完成不同的任务。
-
具体来说,第一个问题是构建硬件基础,而第二个问题则是为智能体提供软件资源。
-
对于第一个问题,本文提出了一个统一的智能体框架,能够覆盖绝大多数已有研究;
-
对于第二个问题,本文总结了常用的能力获取策略(capability acquisition strategies)。
-
除了讨论构建方面,本文还系统性地概述了LLM智能体在社会科学、自然科学和工程等领域的应用情况。
-
最后,本文深入探讨了LLM智能体的评估策略,包括主观评估与客观评估两类方法。
-
总而言之,本综述系统回顾了现有研究,并建立了一个全面的研究分类体系(taxonomy),涵盖了LLM自主智能体在构建、应用与评估等方面的研究进展。我们总结了当前领域面临的挑战,并讨论了未来的发展方向。
三、LLM自主agent的构建
- LLM 的自主代理有望通过利用 LLM 的类人能力来有效地执行不同的任务。为了实现这个目标,有两个重要方面:(1)应该设计哪种架构以更好地使用 LLM 和 (2) 给定设计的架构,如何使代理能够获得完成特定任务的能力。
3.1 Agent架构设计
- 构建自主Agent需要满足特定的角色并从环境中自主感知和学习以像人类一样进化自己。为了弥合传统LLM和自主代理之间的差距,一个关键的方面是设计合理的代理架构来帮助LLM最大化其能力。
- 本文提出了一个统一框架来总结这些模块。具体来说,框架的整体结构如下图所示,它由档案模块、记忆模块、规划模块和动作模块组成。档案模块的目的是识别代理的角色。记忆和规划模块将代理放置在动态环境中,使其能够回忆过去的行为并计划未来的行动。动作模块负责将代理的决策翻译成特定的输出。在这些模块中,档案模块影响记忆和规划模块,总的来说,这三个模块会影响动作模块。
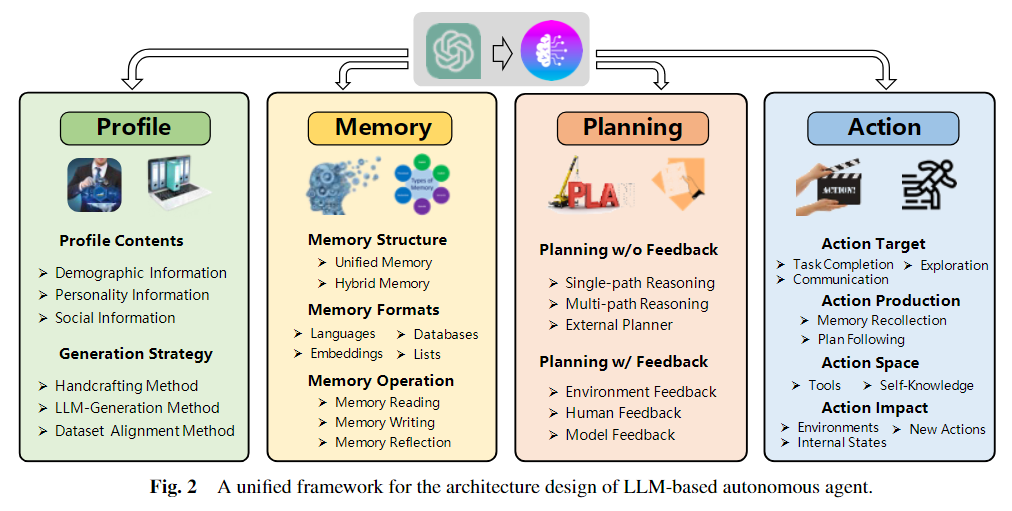
- 四大模块举例说明:
| 模块 | 核心内容 | 细分要素 | 示例说明 |
|---|---|---|---|
| Profile(档案) | 定义智能体的身份和个性 | 档案内容:人口学信息、个性信息、社会信息 - 生成策略:手工方法、LLM生成方法、数据集对齐方法 | 设定“医生助理”角色:职业=医疗助理、个性=理性分析、社交圈=医护人员 |
| Memory(记忆) | 存储和调用知识与经验 | 记忆结构:统一记忆、混合记忆 - 记忆形式:语言、数据库、向量、列表 - 记忆操作:读取、写入、反思 | 智能体记住用户每天早上要提醒喝水(长期记忆),在对话中记住最近一句话(短期记忆) |
| Planning(规划) | 制定完成任务的路径和方法 | 无反馈规划:单路径推理、多路径推理、外部规划器 - 有反馈规划:环境反馈、人类反馈、模型反馈 | 用户说“请更简洁”,模型在回答时立即调整表达(人类反馈) |
| Action(行动) | 执行具体操作并产生影响 | 行动目标:任务完成、探索、交流 - 行动生成:记忆回忆、计划执行 行动空间:工具调用、自我知识 - 行动影响:环境、内部状态、新动作 | 智能体接到“帮我订机票”:检索用户习惯(记忆),规划搜索航班,最后调用订票API完成任务 |
3.1.1 Profiling模块
- 自主智能体通常通过扮演特定角色来执行任务,例如程序员、教师以及领域专家等。档案(profiling)模块旨在明确这些代理角色的档案信息,这些信息通常会写入提示词(prompt)中,以影响大语言模型(LLM)的行为。
- 代理的档案信息主要包括三类:
- 基础信息:如年龄、性别、职业。
- 心理信息:体现个性、行为风格等心理变量。
- 社会信息:定义与其他智能体的关系或角色结构。
- 目前的档案有三种方法:
- 手工方法:由人类开发者直接撰写代理的角色设定和个性特征,使用自然语言提示,如“你是一个外向的人”或“你是一个内向的人”,以固定语言植入 LLM 的上下文。缺点是:耗时耗力,尤其在构建大规模代理系统时;缺乏自动化与扩展性。
- LLM 生成方法:利用大语言模型自动生成代理档案。具体步骤为:1.设定档案生成规则;2.提供少量种子档案作为示例(few-shot);3.调用 LLM 自动生成大量代理档案。缺点是:可控性差:生成结果可能偏离预期
- 数据集对齐方法:从现实世界的数据集中提取人口属性等信息,转化为自然语言提示,为agent建档。缺点:依赖数据集质量与多样性;涉及隐私与伦理问题;对数据处理与结构转化要求较高。
- 尽管上述三种策略在多数研究中被单独使用,组合使用可能更具价值。下表为三种方法的举例:
| 方法 | 定义 | 优点 | 缺点 | 示例 1 | 示例 2 |
|---|---|---|---|---|---|
| 手工方法 | 由开发者人工撰写代理的角色、个性与设定 | 精准可控、风格稳定、可解释性强 | 构建成本高、难以扩展 | 🧠 Generative Agents:设定姓名、职业、目标、人际关系等信息用于模拟小镇社会互动。 | 🧪 PTLLM:通过 IPIP-NEO 和 BFI 设定不同人格角色,引导 LLM 展现人格差异。 |
| LLM 生成方法 | 给出种子档案与规则,利用大模型批量生成代理档案 | 高效、自动化程度高,适合大规模生成 | 可控性弱,生成结果可能不一致 | 🎬 RecAgent:手动设定部分用户偏好,用 ChatGPT 批量生成电影推荐用的Agent档案。 | 🏫 虚拟教学场景:为数百名“虚拟学生”生成性格、兴趣、成绩档案,支持教育内容个性化测试。 |
| 数据集对齐方法 | 从真实世界数据集中提取人口或行为信息,并转为代理设定 | 贴近现实、可用于社会仿真、研究外推 | 数据依赖性强,需处理隐私与偏倚 | 🗳 ANES+GPT-3:用美国全国选举研究(ANES)中性别/年龄/族裔等数据设定Agent,分配角色,仿真选举行为。 | 🧍♂️ 健康行为建模:用真实健康调查数据(如饮食/运动/慢病情况)构建健康行为模拟Agent。 |
3.1.2 记忆模块
-
记忆模块是智能体架构中的核心组成部分,它具有以下关键功能:
- 存储来自环境的信息;
- 利用过去的经验影响未来行为;
- 提升行为的连贯性、合理性与效率;
- 支持智能体自我演化和长期适应复杂环境。
-
通过引入记忆模块,智能体不再是“无记忆的反应系统”,而是能“学习并逐步进化”的智能系统。
-
记忆结构是对“如何组织和区分记忆”的设计,灵感来源于人类记忆系统:
- 短期记忆(Short-term Memory):对应 LLM 的上下文窗口(Transformer context window);
- 长期记忆(Long-term Memory):外部存储,支持随时检索,类似人类记忆的“回忆机制”。
-
两种主流结构如下:
-
统一记忆: 仅模拟短期记忆,所有记忆信息直接写入提示(prompt),依赖上下文窗口。结构简单,部署容易;灵活支持上下文感知;容量受限,LLM 上下文长度有限(对话agent,具身agent,游戏agent,)。
-
**混合记忆:**同时模拟人类的短期与长期记忆,兼顾临时响应与长期积累。短期记忆:当前任务/状态的上下文;长期记忆:历史行为、经验、反思,存于向量库、数据库等结构中。支持复杂对话、多轮规划、大规模知识管理。
记忆格式
| 格式类型 | 描述 | 优点 | 示例系统 / 应用 | 示例内容(记忆条目) |
|---|---|---|---|---|
| 自然语言格式(Natural Language) | 以自然语言直接描述事件、经验、观察、技能等 | 表达灵活- 语义丰富- 易于调试 | ReflexionVoyager | Reflexion 中记录失败任务:“在尝试打开门时未携带钥匙,导致任务失败。”- Voyager 存储技能描述:“使用 pickaxe 挖掘石头时需要靠近目标并保持站立。” |
| 向量格式(Embeddings) | 将文本或状态信息编码为嵌入向量,便于检索 | 高效检索- 可扩展- 支持模糊匹配 | MemoryBankAgentSims | 一个记忆被编码为 768 维向量,用于表示:“用户喜欢早上运行健身程序。”当前查询通过计算相似度匹配与“健身相关”的记忆片段 |
| 数据库格式(Structured Databases) | 将记忆作为结构化数据项存储在 SQL 或 NoSQL 数据库中 | 可编程操作- 易与工具链集成 | ChatDB | 记忆以 SQL 表项形式记录:INSERT INTO memory_log VALUES ("2023-09-20", "用户查询天气", "回应:今日晴")- 支持 SQL 查询如:SELECT * FROM memory_log WHERE date = "2023-09-20" |
| 结构化列表格式(Structured Lists / Trees) | 用列表、树等层级结构组织目标、子任务、状态变化等 | 层级清晰- 适合计划推理 | GITMRETLLM | GITM 中的任务计划树:["主任务: 生火", ["子任务1: 收集木头", "子任务2: 准备火石", "子任务3: 点燃"]]- RETLLM 将语句转为三元组:("User", "wants", "coffee") |
| 组合格式(Hybrid Key-Value) | 结合嵌入与自然语言,key 用于检索,value 提供上下文 | -兼顾表达力与效率 | GITM(嵌入+NL)MemoryBank(变种) | 键(key):向量(由“用户询问是否可以远程办公”生成)值(value):“昨天用户提出关于远程办公政策的问题,表达了对灵活安排的兴趣。” |
- 自然语言格式适用于需要语义表达与人类可读性的场景;
- 向量格式适用于大规模信息的快速模糊检索;
- 数据库格式适用于需要结构化操作、可编程规则的系统;
- 结构化列表适用于任务型智能体中的任务分解与控制流程;
- 组合格式在真实系统中越来越常见,用于整合记忆语义表达与调用效率。
智能体内存操作
内存模块在智能体中扮演关键角色,帮助其从与环境的交互中获取、积累并利用大量知识。这种交互主要通过以下三种核心内存操作实现:
-
内存读取(Memory Reading)
-
内存写入(Memory Writing)
-
内存反思(Memory Reflection)
内存读取
-
内存读取的目标是从内存中提取有意义的信息,从而增强智能体的行为能力。例如,智能体可以利用先前成功执行的动作来达成类似目标。
-
内存读取的核心问题是:如何从历史行为中提取有价值的信息?
-
通常,有三种标准用于判断哪些信息值得提取:
- 新近性(Recency):信息是否是最近的?
- 相关性(Relevance):信息是否与当前任务相关?
- 重要性(Importance):信息是否对任务成功起关键作用?
- 这三项标准可通过下列公式进行量化建模:
m∗=argmaxm∈M(αsrec(q,m)+βsrel(q,m)+γsimp(m))m^* = \arg \max_{m \in M} \left( \alpha s^{rec}(q, m) + \beta s^{rel}(q, m) + \gamma s^{imp}(m) \right)m∗=argm∈Mmax(αsrec(q,m)+βsrel(q,m)+γsimp(m))
- qqq:当前的查询(例如当前任务或环境上下文)
- MMM:所有内存集合
- srec,srel,simps^{rec}, s^{rel}, s^{imp}srec,srel,simp:分别表示新近性、相关性、重要性的评分函数
- α,β,γ\alpha, \beta, \gammaα,β,γ:三个加权系数,控制这三项标准的权重
其中:
-
srel(q,m)s^{rel}(q, m)srel(q,m) 可以通过查询与内存的嵌入向量相似度计算得出;
-
simp(m)s^{imp}(m)simp(m)只与内存本身特性有关,与查询无关。
-
当 α=γ=0\alpha = \gamma = 0α=γ=0时,仅考虑相关性;
-
当 α=β=γ=1.0\alpha = \beta = \gamma = 1.0α=β=γ=1.0 时,三项标准等权重考虑
内存写入
-
内存写入的目的,是将智能体对环境的感知信息存入内存,为将来的信息检索提供依据,从而帮助其更高效、理性地做出行为决策。
-
内存写入面临两大挑战:
-
内存重复:重复信息会浪费内存。为解决这一问题:
- 当多次成功执行相同子目标的动作序列被记录时,可以通过 LLMs(大型语言模型)将其压缩成统一的计划表示;
- Augmented LLM 使用计数累积方法来整合重复信息,避免冗余存储。
-
内存溢出:内存空间有限,当容量达到上限时,需要删除旧信息:
-
ChatDB :通过用户命令明确删除;
-
RET-LLM :使用固定大小缓冲区,采用先进先出(FIFO)策略,自动覆盖最旧的信息。
-
-
内存反思
- 内存反思模拟了人类自我观察和评估自身认知、情绪、行为的能力。在智能体中,这一功能被赋予为:独立生成抽象和高层次知识的能力。内存反思举例:
你拥有一个科研助理型的智能体,它能够协助你进行论文写作、文献整理和时间安排管理。过去一段时间里,智能体记录了多个与你写作相关的细节:你在凌晨两点上传了一份未完成的草稿;最近三次写作任务你都是在截止日期前24小时才开始动笔;你在写作过程中多次遇到结构混乱的问题;写完之后常常来不及进行细致润色;而且几乎每次写作都没有事先列出提纲。起初,这些都是分散的、孤立的记忆片段,但当你又一次启动新写作任务时,智能体启动了它的“内存反思机制”。
它会主动检索与“写作”相关的记忆,并通过对比、归纳,从中总结出几条高层次的洞察:你在写作时间安排上存在明显的拖延倾向;缺乏前期结构规划往往会导致写作混乱;而深夜集中赶稿虽然可以应急,却往往牺牲了文章的整体质量。于是,当你下一次让它帮你撰写新论文时,它不再只是单纯地开始写草稿,而是先提醒你:建议先花20分钟列出写作提纲,这能帮助你在后续写作中更清晰地组织内容。同时,它还会提示你避免再次在深夜开始高强度工作,以保障文稿的整体质量。
通过这样的反思过程,智能体将过往的经验教训抽象为可复用的高阶策略,并将其转化为下一次行动的优化建议。这种机制极大地提升了智能体的适应性和行为合理性,也使得它在协助用户任务执行时,具有了类似人类“学习”和“成长”的能力。
3.1.3 计划模块
- 人类在面对复杂任务时,往往倾向于将其拆分为多个子任务并逐步解决。计划模块正是赋予智能体这种类人能力,使其行为更加合理、高效与稳定。本文根据智能体在计划过程中是否能接收反馈,将研究分为两类:无反馈计划和有反馈计划
无反馈计划
- 在这种方式中,智能体在执行动作后不会获得反馈信息,也就是说,过去的行为不会影响后续的计划行为。典型策略如下:单路径推理、多路径推理和外部规划器。具体描述如下:
| 策略名称 | 策略类别 | 核心思想 | 代表方法与特点 |
|---|---|---|---|
| Chain of Thought (CoT) | 单路径推理 | 用示例推理步骤引导模型逐步生成计划 | 示例引导;每步连接下一步;适用于复杂问题 |
| Zero-shot CoT | 单路径推理 | 不依赖示例,通过提示词(如“step by step”)引导推理 | 简洁、通用性强 |
| RePrompting | 单路径推理 | 检查每一步是否满足前提,不满足则返回错误并重生成 | 增加稳健性;可纠正错误步骤 |
| ReWOO | 单路径推理 | 独立生成多个子计划并结合观察结果生成最终答案 | 多轮调用LLMs;具备观察能力 |
| HuggingGPT | 单路径推理 | 拆分任务为子任务,调用多个专家模型协同解决 | 模块化执行;模型分工协作 |
| SWIFTSAGE | 单路径推理 | 模拟人类“快-慢”双通道认知结构进行规划 | SWIFT 快速反应 + SAGE 深度推理 |
| Self-consistent CoT (CoT-SC) | 多路径推理 | 同一个问题生成多个推理路径,取出现频率最高的答案 | 多样性推理;提高鲁棒性 |
| Tree of Thoughts (ToT) | 多路径推理 | 使用树结构组织“思维节点”,每步可多选,结合搜索策略 | 广度/深度优先搜索;每步需调用LLMs |
| RecMind | 多路径推理 | 利用历史被废弃信息启发新路径(自我激励机制) | 信息再利用;具备“反思”能力 |
| Graph of Thought (GoT) / AoT | 多路径推理 | 使用图结构或算法示例增强推理路径探索 | 更复杂路径结构;更少模型调用 |
| RAP / MCTS | 多路径推理 | 利用蒙特卡洛树搜索评估多个计划路径并聚合结果 | 模拟+搜索结合;策略更优化 |
| Zero-shot planners | 多路径推理 | 无需示例,直接生成完整路径 | 轻量级推理器;易集成 |
| LLM+P / LLM-DP / CO-LLM | 外部规划器 | 使用LLMs生成高阶任务,再由外部工具完成具体动作 | PDDL语言中间层;适用于低层任务控制 |
| Low-level planner | 外部规划器 | 将高层语言计划翻译为可执行的底层动作 | 弥补LLMs行动控制不足;提高计划可执行性 |
- 单路径推理和多路径推理如下所示:
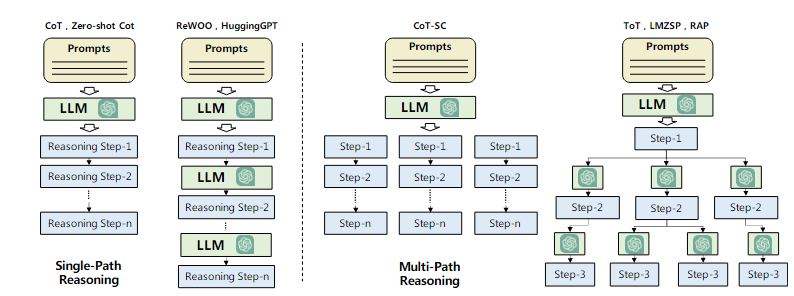
有反馈计划
- 在现实环境中,计划过程通常需要根据反馈不断修正。无反馈计划容易失败,原因包括:
- 初始计划往往不完美,缺乏对复杂前提条件的考虑;
- 执行中遇到动态环境变化,计划可能不再可行;
- 人类在计划复杂任务时,也会不断调整步骤。
- 因此,引入反馈的计划策略更贴近真实情境。反馈来源分为以下三类:
| 策略名称 | 反馈类型 | 核心思想 | 代表方法与特点 |
|---|---|---|---|
| ReAct | 环境反馈 | 使用“思维-动作-观察”三元组结构,让环境观察影响下一步 | 搜索结果影响后续行为;可适应外部环境变化 |
| Voyager / Ghost | 环境反馈 | 使用程序执行状态、报错、自检等三类反馈信号引导计划 | 帮助智能体生成更健壮策略 |
| SayPlan | 环境反馈 | 基于图结构模拟器不断检验和修正计划,直到收敛为有效方案 | 支持策略微调和多轮试错 |
| DEPS | 环境反馈 | 提供任务失败的详细原因,而不只是结果本身 | 可更准确地调整出错步骤 |
| LLM-Planner | 环境反馈 | 动态重构不可执行计划,通过规划器适配真实世界变化 | 高鲁棒性;能解决计划-现实偏差 |
| Inner Monologue (env) | 环境反馈 | 提供多种环境场景描述:是否成功、被动描述、主动描述 | 丰富语境反馈;使行为更自然 |
| Inner Monologue (human) | 人类反馈 | 将人类反馈嵌入到提示中,引导计划生成贴近人类偏好 | 结合人类主观偏好;可用于VR等交互环境 |
| Self-Refine | 模型反馈 | 自我输出、自评、精炼的反馈迭代过程 | 内部质量检查机制;高一致性 |
| SelfCheck | 模型反馈 | 自检推理路径并与目标比较修正错误 | 自动纠偏;提高鲁棒性 |
| InterAct | 模型反馈 | 使用多个语言模型分工协作,互相检查规避错误 | ChatGPT/InstructGPT 分工;提升效率 |
| ChatCoT | 模型反馈 | 用结构化评估模块监督推理过程质量 | 反馈更细致;提高合理性 |
| Reflexion | 模型反馈 | 结合语言反馈轨迹生成详细自然语言建议迭代改进 | 逐步语义反馈;支持复杂长任务 |
- 总的来说:无反馈计划更偏向静态推理与策略制定;有反馈计划具备动态调整、自我优化、外部适配能力。
- 无反馈计划实现简单,适合推理路径较短的任务;有反馈计划设计更复杂,但可处理更高难度、长距离推理任务,更贴近现实应用;综合利用多种反馈(环境、人类、模型)将显著提升智能体的计划能力。
3.1.4 行动模块
行动模块负责将智能体的决策转化为具体结果。它处于系统最下游的位置,直接与环境交互。该模块受配置文件(Profile)、记忆(Memory)、以及计划(Planning)模块的影响。行动模块包含四个部分:
- 行动目标(Action Goal):行为想达成什么目的?
- 行动生成(Action Production):如何生成这些行为?
- 行动空间(Action Space):有哪些可执行的行为?
- 行动影响(Action Impact):行为会带来什么后果?
其中,前两者属于行为前的考虑(before-action),第三个是行为中(in-action),第四个是行为后(after-action)。
行动目标
- 智能体的行为可服务于多种目标,这里列举三种典型类型:
- 任务完成(Task Completion)
- 如:在 Minecraft 中制作铁镐,或在软件开发中完成某个函数。
- 交流沟通(Communication)
- 与其他智能体或人类交流,如 ChatDev 中多智能体共同协作开发软件;Inner Monologue 中,智能体与人交互并根据反馈调整行为。
- 环境探索(Environment Exploration)
- 智能体探索陌生环境,寻找探索与利用的平衡。例如 Voyager会在探索中不断通过试错来优化技能调用。
- 任务完成(Task Completion)
行动生成
-
智能体的行为来源于不同策略,这里介绍两类:
-
基于记忆召回(via Memory Recollection)
- 例如:Generative Agent在每次行为前检索最相关的历史记忆作为行动依据。
- 在 GITM中,智能体会查询记忆中已成功执行过的任务来指导当前行动。
-
基于计划执行(via Plan Following)
-
如 DEPS:行为严格依照预先生成的计划,除非有明确失败信号。
-
GITM 中将任务分解为多个子目标,逐一执行。
-
-
行动空间
-
指智能体可以选择执行的所有可能行为。主要分为:
-
外部工具,虽然LLMs强大,但在专业知识领域仍需调用外部工具来增强行动能力。代表类型包括:
- APIs:如 HuggingGPT调用 HuggingFace 模型 API,WebGPT从网页获取内容;TPTU规划任务并调用工具;RestGPT使用 RESTful APIs 接入真实世界服务。
- 数据库与知识库(Databases & KBs):如 ChatDB查询结构化数据;ToolLLaMA融合数据采集和评估框架;TaskMatrix.AI整合多模态信息与 API。
- 外部模型(External Models):如 ViperGPT使用 Codex 编写 Python 并执行任务;ChemCrow用于化学合成;MM-REACT用于视频摘要、图像生成、音频处理等。
-
内部知识,LLMs 还可仅依靠自身知识执行行动,包括三种能力:
- 计划能力(Planning Capability)
- 拥有自动任务分解能力,例如 DEPS、GITM、Voyager均依赖该能力。
- 对话能力(Conversation Capability)
- 如 ChatDev中各智能体能围绕开发任务对话;RLP能与听众互动并调整行为。
- 常识理解能力(Common Sense Capability)
- 如 Generative Agent可理解情境、总结信息并做出类似人类的判断;RecAgent和 S3专注于社会行为模拟。
行动影响
- 指智能体行为的后果,常见影响包括:
- 改变环境状态(Changing Environments)
- 如 GITM、Voyager 中,通过“采集木头”等动作影响环境状态。
- 改变内部状态(Altering Internal States)
- 如 Generative Agent中执行行为后,记忆更新、形成新计划;SayCan更新对环境的理解。
- 触发后续行为(Triggering New Actions)
- 一项行为会引发另一项,如 Voyager 中“采集资源” → “触发建筑建设”。
3.2 Agent能力获取
Agent架构更像是智能体的“硬件”,仅靠硬件无法实现有效的任务执行,因为智能体可能缺乏必要的任务技能、经验和知识——这些可以看作是“软件”。
可以按是否需要微调(fine-tuning)LLMs,将能力获取方法分为两大类:
- 需要微调的能力获取(With Fine-tuning)
- 不需要微调的能力获取(Without Fine-tuning)
3.2.1 需要微调的能力获取
| 策略类别 | 子类别 | 核心方法 | 代表工作 / 示例 |
|---|---|---|---|
| 基于标注数据微调 | 人工标注数据(Human Annotated) | 构造人工任务场景,使用标注数据微调 LLM | CoH:将人类偏好转为自然语言比较 RET-LLM:自然语言 → 结构化记忆 WebShop:电商网站+13人行为数据 EduChat:教育问答、作文批改 |
| LLM生成数据(LLM Generated) | 使用 LLM 自动生成训练数据 | ToolBench:采集 API → 用 ChatGPT 生成任务 → 微调 LLaMA | |
| 基于真实世界数据微调 | Real-world Datasets | 直接使用真实网站或真实任务数据进行微调 | MIND2WEB:从137网站采集2000+任务 SQL-PaLM:使用Spider等大规模SQL数据集微调 PaLM-2 |
3.2.2 不需要微调的能力获取
| 策略类别 | 子类别 | 核心方法 | 代表工作 / 示例 |
|---|---|---|---|
| 提示工程(Prompt Engineering) | 无 | 通过构造精巧提示控制 LLM 行为 | CoT / ToT:提示中插入中间推理 RLP:将“自我认知”嵌入 Prompt Retroformer:将失败反思融入 Prompt |
| 机制工程(Mechanism Engineering) | 试错(Trial-and-error) | 预测动作 → 获取反馈 → 调整行为 | DEPS:失败后解释原因调整计划 RoCo:路径失败后生成新对话方案 PREFER:根据反馈进行行为迭代 |
| 群体共识(Crowd-sourcing) | 多个智能体协商后形成最终答案 | 设计智能体“辩论机制”整合意见 | |
| 经验积累(Experience Accumulation) | 将成功经验存入记忆供未来使用 | GITM:任务失败/成功均写入记忆 Voyager:技能库记录可执行代码 MemPrompt:存储用户反馈用于未来决策 | |
| 自我进化(Self-driven Evolution) | 智能体主动设定目标并学习成长 | LMA3:自主设定目标,自我学习 SALLMS:在多智能体中自我调整 CLMTWA:大模型做“教师”教小模型 NLSOM:多智能体协作解决超个体任务 |
3.3.3 各个时代能力获取
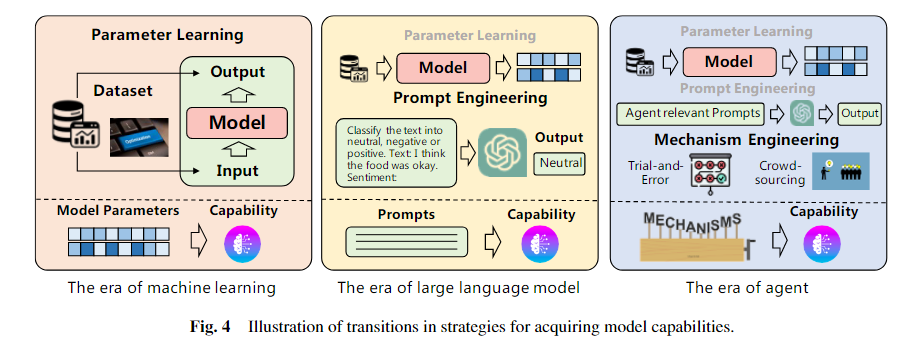
- 机器学习时代(Parameter Learning):通过训练模型参数从数据中获得能力,能力写死在模型权重里。
- 大语言模型时代(Prompt Engineering):通过提示词激活语言模型中已有能力,无需修改模型参数。
- 智能体时代(Mechanism Engineering):通过引入记忆、规划、反馈等机制组合模型能力,使智能体能持续学习和灵活适应任务。
四、基于LLM的自主Agent应用
由于大语言模型(LLM)具备强大的语言理解、复杂任务推理以及常识理解能力,基于LLM的自主智能体在多个领域展现出巨大的潜力。本节对现有研究进行了简要总结,并将其应用划分为三个不同的领域:社会科学、自然科学和工程学
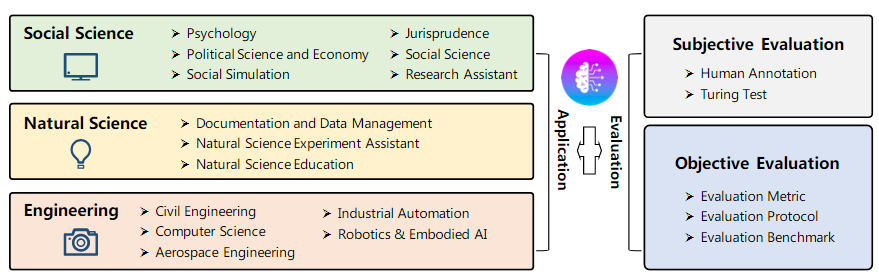
基于LLM的自主Agent应用一览表:
| 类别 | 应用方向 | 功能与应用场景 | 代表性系统 / 案例 |
|---|---|---|---|
| 🧠 社会科学 | 心理学 | 心理实验仿真、心理健康对话支持 | 个性化GPT实验、Reddit心理帖子分析 |
| 政治与经济 | 意识形态检测、政治演讲分析、消费者行为模拟 | 虚拟选民模拟、消费行为建模 | |
| 社会模拟 | 虚拟社会实验、谣言传播研究 | Generative Agents、CGMI、SocialAI School | |
| 法学 | 法律推理、判决模拟、案例检索 | ChatLaw、Blind Judgement | |
| 研究助手 | 摘要生成、关键词提取、研究脚本草拟 | 文献筛选、论文草稿协助 | |
| 🔬 自然科学 | 文献与数据管理 | 科学文献解析、实验参数提取 | ChatMOF(金属有机框架分析) |
| 实验助手 | 设计实验流程、自动运行代码、风险评估 | ChemCrow(集成17种化学工具) | |
| 科学教育 | 辅助学习科学方法、数学建模与推理 | EduChat、Math Agents、CodeX | |
| 🛠️ 工程学 | 计算机科学与软件工程 | 多智能体协作开发、自动生成代码、漏洞检测 | ChatDev、MetaGPT、LLIFT、ChatEDA |
| 工业自动化 | 与数字孪生系统集成、工业流程控制 | IELLM(石油天然气行业) | |
| 机器人与具身智能 | 任务规划、多模态感知、对象操作 | SayCan、TidyBot、TaPA |
五、LLM自主Agent的评估
与评估大语言模型(LLMs)本身类似,评估基于LLM的自主智能体的有效性同样是一个具有挑战性的任务。本节概述了两种主要评估方法:主观评估(subjective) 和 客观评估(objective)
5.1 主观评估
- 主观评估是指根据人类判断来衡量智能体能力,适用于缺乏标准化评估数据集,或难以设计量化指标的情况,例如:评估智能体的“智慧程度”或“用户友好度”。
| 评估策略 | 说明 | **代表案例 ** | 优势 | 劣势 |
|---|---|---|---|---|
| Human Annotation(人工打分) | 人类评估者对智能体输出进行打分或排序,用于衡量智能体在特定任务中的表现。 | 25个问题评估智能体的能力;评估智能体对社区规则发展的贡献。 | 贴近人类标准,直观,适合评估开放性任务 | 成本高、效率低、主观性强,易受偏见影响 |
| Turing Test(图灵测试) | 评估者需判断内容是否出自人类,无法区分则视为智能体“拟人化”。 | 在人类政见文本任务中,判断回答是人还是智能体生成。 | 可衡量智能体的“类人性”,具有代表性 | 不适用于非语言任务,难度控制不一 |
| LLM辅助评估(LLM-assisted Annotation) | 使用LLM模型(如GPT)作为中介参与评估,如自动打分、结构化辩论等。 | ChemCrow :GPT评估实验结果正确性;ChatEval:多个模型辩论打分。 | 减少人力成本,提升可扩展性 | 存在“模型评模型”的偏差叠加问题 |
| 总结性观点 | 主观评估体现人类标准,在评估用户体验、伦理、社会行为等方面尤为重要 | - | 更贴近人类需求 | 难以标准化,评估维度较抽象 |
5.2 客观评估
| 维度 | 评估策略 / 类型 | 说明 | 代表文献 / 平台 | 优势 | 劣势 |
|---|---|---|---|---|---|
| Metrics(指标) | Task Success | 任务完成率、奖励分数、执行正确率等 | 论文中展示 | 可量化,标准化强 | 忽视细节质量 |
| Human Similarity | 连贯性、流畅性、对话相似性、人类接受度等论文中展示 | 论文中展示 | 可模拟人类行为 | 难度主观化,不够客观 | |
| Efficiency | 开发成本、训练效率等资源指标 | 论文中展示 | 关注实际部署成本 | 不衡量质量,仅评成本 | |
| Protocols(协议) | Real-world Simulation | 游戏/仿真环境中测试任务完成和行为表现 | Minecraft, ALFWorld, IGLU 等 | 可复现真实交互环境 | 环境构建复杂,学习曲线陡 |
| Social Evaluation | 在模拟社会中测试协作、沟通、情绪、ToM等社交智能 | AgentSims, SoKET, SocialIQ | 可评估高阶社会行为 | 控制变量困难 | |
| Multi-task | 多领域任务泛化能力测试 | AgentBench, ToolBench | 衡量通用性强 | 实验设计复杂 | |
| Software Testing | Bug复现、测试用例生成、代码交互 | 论文中展示 | 实用性强 | 领域较窄 | |
| Benchmarks(基准集) | 平台评估 | 提供标准任务集、交互环境和工具集 | WebShop , ToolBench , GentBench , EmotionBench , E2E | 标准化、便于横向比较 | 需不断更新适应新模型能力 |
| 总结性观点 | 客观评估强调可重复性与可量化性,是评估通用能力的核心组成 | - | 科学性强,覆盖全面 | 无法捕捉创造性、伦理性维度 |
5.3 总结对比
| 评估方法 | 优势 | 劣势 |
|---|---|---|
| 主观评估 | 体现人类直观标准;适用于无标准任务 | 成本高、效率低、主观性强 |
| 客观评估 | 标准化、可重复、适用于自动评测 | 无法评估抽象/创造性/伦理维度 |
最终建议:两种方法应当联合使用,实现覆盖能力评估的广度与深度,正如文中所说:“主客观评估各有优劣,建议结合使用”。
六、挑战
虽然之前关于基于 LLM 的自主代理的工作已经取得了许多显着的成功,但该领域仍处于初级阶段,在开发中需要解决的几个重大挑战。
6.1 Role-playing Capability(角色扮演能力)
-
不同于传统的大语言模型(LLMs),自主智能体需要以特定角色(如程序员、研究人员、化学家等)来完成特定任务。因此,角色扮演能力极其关键。
-
虽然LLMs可以模拟如影评人等常见角色,但对一些不常见或新兴的角色(特别是心理学角色或网络上不常见的角色),则难以精确建模。这主要因为LLMs的训练数据主要来自公开网络,因此对冷门角色表现较弱。
解决方案:
- 收集真实的人类数据,用于微调模型以适配冷门角色;
- 精心设计 prompt 或智能体架构,提高模型角色扮演精度;
- 然而,Prompt/架构设计空间太大,难以寻优。
6.2 Generalized Human Alignment(通用人类对齐)
- 传统LLM多强调“对齐人类价值观”(如不能鼓励暴力),但自主智能体用于“真实世界仿真”时,还需具备模拟错误或负面人性的能力(例如模拟制定炸弹计划),以便探索和解决问题。当前主流LLMs(如ChatGPT、GPT-4)通常只对齐单一价值体系,无法描绘多元甚至负面的认知行为。
挑战要点
- 如何对齐不同人群的价值观(多元性 vs 安全性);
- 如何在保持模型安全性的同时,真实模拟“不可接受”的人类特征。
研究方向
- 设计更灵活的 Prompt 策略,实现多样化价值模拟和适配。
6.3 Prompt Robustness(Prompt 鲁棒性)
- 为了使智能体具备持续、可靠的行为,研究人员通常在 LLMs 中嵌入内存、计划等模块。但这也意味着智能体不再是“单一 prompt”,而是一个模块化 prompt 框架,各模块 prompt 会互相影响。
挑战要点
- Prompt 稍有改动可能导致行为差异;
- 不同模型对 prompt 的响应差异大;
- 当前缺乏统一且健壮的 Prompt 架构。
解决思路
- 手动设计并试错优化关键 prompt;
- 利用 GPT 自动生成可迁移的 prompt 模板。
6.4 Hallucination(幻觉现象)
- 幻觉是指模型在高置信度下输出错误信息,在自主智能体中尤其危险:
- 代码生成中可能导致错误代码、安全漏洞;
- 行为规划中可能导致误导性决策。
研究建议
- 将人类反馈引入智能体行为的交互循环(如RLHF);
- 增强多轮任务执行中的验证机制。
- 幻觉现象在面对简化指令时尤其严重。
6.5 Knowledge Boundary(知识边界问题)
- LLMs拥有超越人类个体的广泛网络知识,这使得在模拟“人类行为”时出现“过拟合”:表现得太聪明,反而不符合真实世界的普通人类行为。
挑战点
- 模拟人类用户行为时,模型可能使用了“用户本不应知道的信息”;
- 比如:用户未看过电影,但模型基于剧透内容做出“预测” → 不合理。
解决方向
- 构建知识屏蔽机制;
- 限制模型调用用户未知知识。
6.6 Efficiency(效率问题)
- 由于 LLMs 基于自回归结构,推理速度慢。但在自主智能体中,每个行动都可能需要:
- 检索记忆;
- 制定计划;
- 再执行行动。
- 这意味着单次任务需多轮调用 LLM,显著拖慢执行效率。
影响
- 限制了智能体在实时性要求高的环境中部署;
- 成为实现 Agent 实时交互的一大瓶颈。
6.7 总结
| 挑战类别 | 核心问题 | 关键影响 |
|---|---|---|
| Role-playing | 无法模拟冷门或专业角色 | 角色行为不真实,影响任务完成 |
| Human Alignment | 模拟人性片面,缺乏多样化对齐 | 无法覆盖复杂人类行为 |
| Prompt Robustness | Prompt设计复杂,结果不稳定 | 任务失败风险高 |
| Hallucination | 高置信错答,误导用户或任务 | 引发伦理与安全问题 |
| Knowledge Boundary | 模型“知道太多” | 模拟行为缺乏可信性 |
| Efficiency | 推理延迟,调用多次 | 交互反应慢,难部署实时系统 |