hive架构及搭建
1. 什么是hive
Apache Hive 是基于Hadoop的数据仓库工具,它可以使用SQL来读取、写入和管理存在分布式文件系统中的海量数据。在Hive中,HQL默认转换成MapReduce程序运行到Yarn集群中,大大降低了非Java开发者数据分析的门槛,并且Hive提供命令行工具和JDBC驱动程序,方便用户连接到Hive进行数据分析操作。
Hive有如下特点:
- Hive是基于Hadoop的数仓工具,底层数据存储在HDFS中。
- Hive提供标准SQL功能,支持SQL语法访问操作数据;
- Hive适合OLAP数据分析场景,不适合OLTP数据处理场景,所以适合数据仓库构建;
- HQL默认转换成MapReduce任务执行,也可以配置转换成Apache Spark、Apache Tez任务运行;
- Hive中支持定义UDF、UDAF、UDTF函数扩展功能;
Hive官网地址:http://hive.apache.org。
2 数据仓库和数据库的区别
数据库:传统关系型数据库的主要应用是OLTP(On-Line Transaction Processing),主要是基本的、日常的事务处理,例如银行交易。主要用于业务类系统,主要供基层人员使用,进行一线业务操作。
数据仓库:数仓系统的主要应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。OLAP数据分析的目标是探索并挖掘数据价值,作为企业高层进行决策的参考。
| 功能 | 数据库 | 数据仓库 |
|---|---|---|
| 数据范围 | 当前状态数据 | 存储历史、完整、反应历史变化数据 |
| 数据变化 | 支持频繁的增删改查操作 | 可增加、查询,无更新、删除操作 |
| 应用场景 | 面向业务交易流程 | 面向分析、支持侧重决策分析 |
| 处理数据量 | 频繁、小批次、高并发、低延迟 | 非频繁、大批量、高吞吐、有延迟 |
| 设计理论 | 遵循数据库三范式、避免冗余 | 违范式、适当冗余 |
| 建模方式 | ER实体关系建模(范式建模) | 范式建模+维度建模 |
3. hive架构
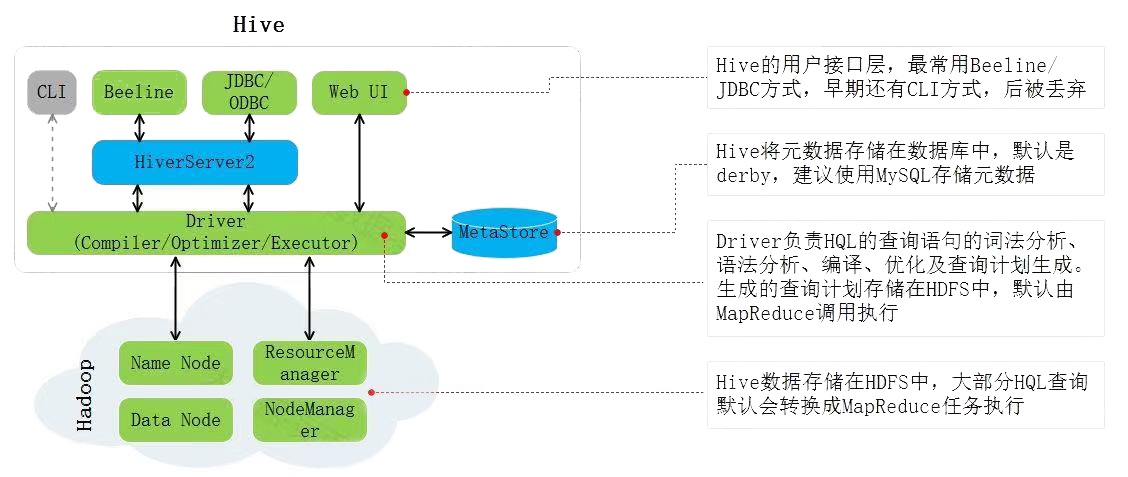
- Hive用户接口
访问Hive可以通过CLI、Beeline、JDBC/ODBC、WebUI几种方式。在Hive早期版本中可以使用Hive CLI来操作Hive,Hive CLI并发性能差、脚本执行能力有限并缺乏JDBC驱动支持,从Hive 4.x版本起废弃了Hive CLI推荐使用Beeline。Beeline是一个基于JDBC的Hive客户端,支持并发环境、复杂脚本执行、JDBC驱动等,在Hive集群内连接Hive可以使用Beeline方式。在Hive集群外,通过代码或者工具连接操作Hive时可以通过JDBC/ODBC方式。通过WebUI方式可以通过浏览器查看到Hive集群的一些信息。
- HiveServer2服务
HiveServer2服务提供JDBC/ODBC接口,主要用于代理远程客户端对Hive的访问,是一种基于Thrift协议的服务。例如通过JDBC或者Beeline连接访问Hive时就需要启动HiveServer2服务,就算Beeline访问本机上的Hive服务也需要启动HiveServer2服务。
HiveServer2代理远程客户端对Hive操作时会涉及到操作HDFS数据,就会有操作权限问题,那么操作HDFS中数据的用户是启动HiveServer2的用户还是远程客户端的用户需要通过“hive.server2.enable.doAs”参数决定,该参数默认为true,表示HiveServer2操作HDFS时的用户为远程客户端用户,如果设置为false表示操作HDFS数据的用户为启动HiveServer2的用户。
- MetaStore服务
MetaStore服务负责存储和管理Hive元数据,为HiverServer2提供元数据访问接口。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(表拥有者、是否为外部表等),表的数据所在目录等。Hive MetaStore可以将元数据存储在mysql、derby数据库中。
- Hive Driver
Driver中包含解释器(SQL Parser)、编译器(Compiler)、优化器(Optimizer),负责完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有执行器(Executor)调用MapReduce执行。注意:Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
4. 安装和部署
4.1 mysql安装
无需多言
4.2 hive部署
4.2.1 上传解压hive安装包
将Hive安装包“apache-hive-4.0.0-bin.tar.gz”上传到hadoop101节点/opt/software目录下并解压。
[root@hadoop101 software]# tar -zxvf ./apache-hive-4.0.0-bin.tar.gz -C /opt/module
[root@hadoop101 software]# cd /opt/module
[root@hadoop101 module]# mv apache-hive-4.0.0-bin hive-4.0.0
[root@hadoop101 module]# ls
hive-4.0.0
4.2.2 配置hive环境变量
修改/etc/profile.d/my_env.sh
#vim /etc/profile.d/my_env.sh
... ...
#HIVE_HOME
export HIVE_HOME=/opt/module/hive-4.0.0/
export PATH=$PATH:$HIVE_HOME/bin
... ...#source 生效
[root@hadoop101 software]# source /etc/profile
4.2.3 配置HiveServer2服务代理用户
默认Hive4.x后取消了Hive CLI方式访问Hive,建议使用Beeline方式连接Hive,Beeline方式连接Hive需要启动HiveServer2服务。默认HiveServer2代理远程用户操作HDFS,允许一个用户代理为另一个用户执行HDFS操作依赖于Hadoop 的代理用户(proxy user)机制,需要将如下代理用户设置为HiveServer2的启动用户。在各个HDFS 节点的core-site.xml中加入如下配置。
... ...
<!-- 配置代理访问用户 -->
<!-- 配置所有节点上,HiveServer2启动用户root作为代理用户 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property> <!-- 配置HiveServer2启动用户root代理的组为任意组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property> <!-- 配置HiveServer2启动用户root代理的用户为任意用户 -->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
... ...将以上配置文件发送到其他Hadoop其他节点上。
4.2.4 Hive服务端配置hive-site.xml
在hadoop101节点配置$HIVE_HOME/conf/hive-site.xml(第一次没有hive-site.xml可以直接创建),该配置文件中配置Hive存储数据路径、元数据存储MySQL信息、HiveServer2节点,metastore及端口信息。hive-site.xml中写入如下信息:
<configuration><!-- Hive表数据存储在HDFS路径 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><!-- MySQL信息 --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop101:3305/metastore?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><!-- 指定HiveServer2 所在host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop101</value></property><!-- 指定HiveServer2 端口 --><property><name>hive.server2.thrift.port</name><value>10000</value></property><!-- Hive MetaStore服务 --> <property><name>hive.metastore.uris</name><value>thrift://hadoop101:9083</value></property></configuration>连接数据库路径后面加上&useSSL=false,代表的是连接mysql不使用SSL连接。allowPublicKeyRetrieval设置为true表示允许公钥检索,MySQL8默认使用了更加安全的密码认证机制(caching_sha2_password),而JDBC驱动在默认配置下不允许检索服务器的公钥来进行身份验证。hive中 & 符号使用& 来表示。
4.2.5 将MySQL驱动包放在Hive服务端和客户端对应的lib目录下
将“mysql-connector-j-8.3.0.jar”上传至hadoop101的$HIVE_HOME/lib目录中。
4.2.6 初始化Hive
在Hive服务端初始化Hive,即初始化Hive的元数据库,如下命令执行后,可以在MySQL中看到相应的库会创建。注意:如果之前初始化过Hive,需要在MySQL中先删除创建的hive数据库,以及HDFS中的表数据目录。
[root@hadoop101 software]# schematool -dbType mysql -initSchema4.2.7 重启hadoop集群
#启动hadoop集群
[root@hadoop101 ~]# start-all.sh4.2.8 启动HiveServer2和MetaStore服务
在/root/bin目录下,编写一个hive服务的启停脚本
#!/bin/bash# ==============================================================================
# Hive 服务启停脚本 (hive-service.sh)
# 适用于 Hive 4.0.0,安装目录: /opt/module/hive-4.0.0
# 功能: 一键启动/停止 Hive Metastore 和 HiveServer2 服务
# ==============================================================================# --- 基础配置 ---
HIVE_HOME="/opt/module/hive-4.0.0"
HIVE_CONF_DIR="${HIVE_HOME}/conf"# 检查 Hive 安装目录是否存在
if [ ! -d "${HIVE_HOME}" ]; thenecho "错误:Hive 安装目录 ${HIVE_HOME} 不存在。请检查脚本或你的安装。"exit 1
fi# --- 函数定义 ---# 打印分隔线
print_separator() {echo "------------------------------------------------------------"
}# 检查进程是否运行
# 参数: $1 - 进程名 (例如: RunJar)
# 参数: $2 - 用于识别的关键字 (例如: hive.metastore)
check_process() {local PROCESS_NAME=$1local KEYWORD=$2# 使用 pgrep 查找进程,并通过 grep 过滤特定关键字,避免匹配到脚本自身pgrep -f "${PROCESS_NAME}" | xargs -I{} ps -p {} -o command= | grep -w "${KEYWORD}" > /dev/null 2>&1
}# 启动服务
start_service() {local SERVICE_NAME=$1local CLASS_NAME=$2local LOG_FILE="${HIVE_HOME}/logs/${SERVICE_NAME}.log"echo "正在启动 Hive ${SERVICE_NAME}..."# 创建 logs 目录(如果不存在)mkdir -p "${HIVE_HOME}/logs"# 使用 nohup 在后台启动服务,并将日志输出到文件nohup ${HIVE_HOME}/bin/hive --service ${SERVICE_NAME} > "${LOG_FILE}" 2>&1 &# 记录进程IDecho $! > "${HIVE_HOME}/${SERVICE_NAME}.pid"# 等待服务启动sleep 5# 验证服务是否成功启动if check_process "java" "${CLASS_NAME}"; thenecho "成功:Hive ${SERVICE_NAME} 已启动。"echo "日志文件: ${LOG_FILE}"elseecho "失败:Hive ${SERVICE_NAME} 启动失败。请查看日志: ${LOG_FILE}"fiprint_separator
}# 停止服务
stop_service() {local SERVICE_NAME=$1local CLASS_NAME=$2local PID_FILE="${HIVE_HOME}/${SERVICE_NAME}.pid"echo "正在停止 Hive ${SERVICE_NAME}..."# 尝试通过 PID 文件停止if [ -f "${PID_FILE}" ]; thenlocal PID=$(cat "${PID_FILE}")if check_process "java" "${CLASS_NAME}"; thenkill "${PID}" > /dev/null 2>&1sleep 3if ! check_process "java" "${CLASS_NAME}"; thenecho "成功:Hive ${SERVICE_NAME} (PID: ${PID}) 已停止。"rm -f "${PID_FILE}"elseecho "警告:无法正常停止 ${SERVICE_NAME} (PID: ${PID}),将尝试强制停止。"kill -9 "${PID}" > /dev/null 2>&1rm -f "${PID_FILE}"echo "Hive ${SERVICE_NAME} (PID: ${PID}) 已强制停止。"fielseecho "警告:${SERVICE_NAME} 进程不存在,但 PID 文件存在。已清理 PID 文件。"rm -f "${PID_FILE}"fielse# 如果 PID 文件不存在,尝试通过关键字查找并停止if check_process "java" "${CLASS_NAME}"; thenlocal PID=$(pgrep -f "java.*${CLASS_NAME}")kill "${PID}" > /dev/null 2>&1sleep 3echo "成功:Hive ${SERVICE_NAME} (PID: ${PID}) 已停止。"elseecho "信息:Hive ${SERVICE_NAME} 未运行或已停止。"fifiprint_separator
}# --- 主程序 ---# 检查传入的参数
if [ $# -ne 1 ]; thenecho "用法: $0 {start|stop|restart|status}"echo " start - 启动 Hive Metastore 和 HiveServer2"echo " stop - 停止 Hive Metastore 和 HiveServer2"echo " restart - 重启 Hive Metastore 和 HiveServer2"echo " status - 查看 Hive Metastore 和 HiveServer2 的运行状态"exit 1
fiCOMMAND=$1case "${COMMAND}" instart)print_separatorstart_service "metastore" "org.apache.hadoop.hive.metastore.HiveMetaStore"start_service "hiveserver2" "org.apache.hive.service.server.HiveServer2";;stop)print_separatorstop_service "hiveserver2" "org.apache.hive.service.server.HiveServer2"stop_service "metastore" "org.apache.hadoop.hive.metastore.HiveMetaStore";;restart)print_separatorecho "正在重启 Hive 服务..."$0 stop$0 start;;status)print_separatorecho "Hive 服务运行状态:"if check_process "java" "org.apache.hadoop.hive.metastore.HiveMetaStore"; thenecho " [运行中] Hive Metastore"elseecho " [已停止] Hive Metastore"fiif check_process "java" "org.apache.hive.service.server.HiveServer2"; thenecho " [运行中] HiveServer2"elseecho " [已停止] HiveServer2"fiprint_separator;;*)echo "无效的命令: ${COMMAND}"echo "用法: $0 {start|stop|restart|status}"exit 1;;
esacexit 0启动
[root@hadoop101 hive-4.0.0]# hive-service.sh start
------------------------------------------------------------
正在启动 Hive metastore...
成功:Hive metastore 已启动。
日志文件: /opt/module/hive-4.0.0/logs/metastore.log
------------------------------------------------------------
正在启动 Hive hiveserver2...
成功:Hive hiveserver2 已启动。
日志文件: /opt/module/hive-4.0.0/logs/hiveserver2.log
------------------------------------------------------------4.2.9 使用hive
#进入Hive,输入hive会直接进入beeline客户端
[root@node3 ~]# hive#通过beeline连接hive
beeline> !connect jdbc:hive2://hadoop101:10000
Connecting to jdbc:hive2://hadoop101:10000
Enter username for jdbc:hive2://hadoop101:10000: 用户名最好填写root
Enter password for jdbc:hive2://hadoop101:10000: 密码可以不填#查看数据库
0: jdbc:hive2://hadoop101:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
+----------------+