【Redis】缓存击穿、缓存穿透、缓存雪崩的解决方案
【Redis】缓存击穿、缓存穿透、缓存雪崩的解决方案
- 缓存击穿:高并发下热点 Key 失效
- 1. 方案一:互斥锁(分布式锁)
- 执行流程:
- 优缺点:
- 2. 方案二:逻辑过期
- 执行流程:
- 优缺点:
- 3. 方案三:中间件/框架方案
- 缓存穿透:不存在的 Key 冲击数据库
- 1. 方案一:请求参数校验与拦截
- 2. 方案二:缓存空值
- 执行流程:
- 注意事项:
- 3. 方案三:布隆过滤器(Bloom Filter)
- 核心原理:
- 优缺点:
- 缓存雪崩:大量 Key 失效或 Redis 宕机
- 1. 针对“大量 Key 同时过期”的解决方案
- 方案一:过期时间加随机值
- 方案二:核心数据永不过期
- 方案三:热点数据缓存预热
- 2. 针对“Redis 整体不可用”的解决方案
- 方案一:Redis 高可用架构
- 方案二:多机房容灾
- 方案三:服务兜底措施
- 总结
在高并发业务中,Redis 缓存虽能大幅减轻数据库压力,但也会面临“缓存击穿”“缓存穿透”“缓存雪崩”三大典型问题——一旦爆发,可能导致数据库瞬间过载甚至宕机。
缓存击穿:高并发下热点 Key 失效
缓存击穿的核心场景是:某个被高并发访问的“热点 Key”突然过期失效,此时大量请求会绕过缓存直接冲击数据库,导致数据库压力骤增,甚至被压垮。
1. 方案一:互斥锁(分布式锁)
通过分布式锁保证“同一时间只有一个请求能访问数据库并更新缓存”,其他请求需等待锁释放后再从缓存获取数据,本质是“限流削峰”。
执行流程:
- 请求查询缓存,若 Key 失效(缓存 miss),则尝试获取分布式锁(如 Redis 的
SET NX命令); - 若获取锁成功:访问数据库查询数据,将数据写入缓存(并设置新的过期时间),最后释放锁;
- 若获取锁失败:短暂休眠(如 50ms)后重新查询缓存,循环直到获取到数据;
- 优化:加入“双重检测”——获取锁后再次检查缓存是否已存在数据,避免因锁等待期间其他请求已更新缓存导致的重复操作。
优缺点:
- 优势:数据一致性强(数据库更新后立即同步缓存),逻辑简单;
- 劣势:存在锁等待阻塞,高并发下可能增加请求延迟,且需处理分布式锁的死锁、释放异常等问题。
2. 方案二:逻辑过期
不设置缓存 Key 的实际过期时间(让 Key 永不过期),而是在缓存数据内部嵌入“逻辑过期时间”。请求时通过判断逻辑时间决定是否异步更新缓存,避免阻塞。
执行流程:
- 缓存热点数据时,在 Value 中加入
expireTime(如{data: "xxx", expireTime: 1699999999}),且 Key 不设置过期时间; - 请求查询缓存时,先判断
expireTime是否过期:- 若未过期:直接返回数据;
- 若已过期:尝试获取分布式锁,获取成功后开启异步线程(如线程池),去数据库更新数据并刷新缓存的
expireTime,同时释放锁; - 未获取到锁:直接返回旧数据(牺牲短暂一致性,保证性能)。
优缺点:
- 优势:无请求阻塞,性能极高,适合对数据一致性要求不严格的场景(如商品销量、实时榜单);
- 劣势:数据存在“短暂不一致”(过期后到异步更新完成前,返回旧数据)。
3. 方案三:中间件/框架方案
部分大厂会通过定制化中间件或框架,优化锁的性能开销,典型案例如下:
-
某手 Cache Setter:
基于“一致性哈希”将相同 Key 的请求路由到同一台 Cache Setter 服务器,服务器内部用ConcurrentHashMap维护“Key-CountDownLatch”映射。当某 Key 首次缓存 miss 时,创建 CountDownLatch 并存储到 Map,同时去数据库更新缓存;后续请求查询到该 Key 对应的 Latch 时,会调用await()阻塞,直到第一个请求更新完缓存后调用countDown(),所有阻塞请求唤醒并从缓存获取数据。
核心优势:避免分布式锁的网络开销,用本地锁+Latch 实现“单节点内串行更新”,性能更优。 -
某东 Jd HotKey:
通过专门的热点 Key 检测系统,实时识别业务中的热点 Key,将这些 Key 同步到应用本地缓存(如 Caffeine)。当请求到来时,优先查询本地缓存,避免 Redis 热点 Key 失效后的数据库冲击。
核心优势:本地缓存无网络延迟,且绕开了 Redis 层面的 Key 失效问题。
缓存穿透:不存在的 Key 冲击数据库
缓存穿透的核心场景是:请求查询的 Key 在缓存和数据库中都不存在(如恶意构造的无效 ID、不存在的用户信息),导致所有请求直接穿透缓存访问数据库,长期积累可能压垮数据库。
1. 方案一:请求参数校验与拦截
在请求到达缓存/数据库前,通过“网关层”或“业务层”拦截无效请求,从源头减少穿透。
- 参数合法性校验:对请求参数做规则校验(如用户 ID 必须为正整数、订单号格式必须符合规则),非法参数直接返回 400;
- IP/用户限流/黑名单:对高频发送无效请求的 IP 或用户(如每秒请求超 100 次),通过网关限流(如 Sentinel、Nginx 限流)或加入黑名单,短期内禁止其访问。
核心逻辑:在“缓存前”拦截无效请求,避免无效流量进入后续链路。
2. 方案二:缓存空值
对数据库中不存在的 Key,在缓存中存储“空值”(如 null、""),并设置较短的过期时间(如 5-10 分钟),避免后续相同请求重复穿透。
执行流程:
- 请求查询 Key,缓存 miss 后访问数据库;
- 若数据库查询结果为空(数据不存在),则在缓存中写入
Key -> 空值,并设置短期过期时间; - 后续相同 Key 的请求会从缓存获取空值,直接返回,无需访问数据库。
注意事项:
- 过期时间不能过长:避免数据库后续新增该 Key 时,缓存的空值导致“数据不一致”;
- 需区分“真空”和“业务空”:如“用户未下单”属于业务空,可缓存;“参数非法”属于无效请求,应直接拦截,无需缓存。
3. 方案三:布隆过滤器(Bloom Filter)
当请求的“不存在 Key”数量极多(如恶意构造百万级无效 ID),缓存空值会导致缓存膨胀,此时需用布隆过滤器做“前置存在性判断”——仅允许“可能存在”的数据进入缓存/数据库链路。
核心原理:
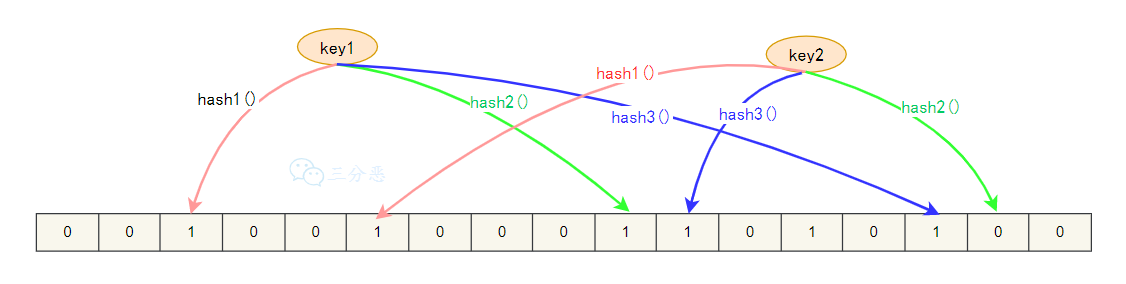
- 写入阶段:数据库新增数据时,将 Key 通过多个哈希函数计算出多个哈希值,对应到布隆过滤器的“比特数组”中,将这些位置的比特位设为 1;
- 查询阶段:请求到来时,先将 Key 通过相同哈希函数计算,若所有对应比特位均为 1,说明 Key“可能存在”(允许继续查缓存/数据库);若有任一比特位为 0,说明 Key“一定不存在”(直接返回,无需穿透)。
优缺点:
- 优势:占用内存极小(比特级存储),判断速度快(O(k),k 为哈希函数个数),适合海量 Key 的存在性判断;
- 劣势:存在“误判率”(可能将不存在的 Key 判断为存在),且不支持删除操作(删除一个 Key 会影响其他 Key 的判断)。
缓存雪崩:大量 Key 失效或 Redis 宕机
缓存雪崩的核心场景有两类:
- 大量 Key 同时过期:同一时间大量缓存 Key 失效,请求集中冲击数据库;
- Redis 整体不可用:Redis 宕机、内存溢出导致热点数据被淘汰,或机房故障等不可抗力,导致缓存完全失效,所有请求回源数据库。
1. 针对“大量 Key 同时过期”的解决方案
方案一:过期时间加随机值
在设置 Key 的固定过期时间(如 1 小时)基础上,额外叠加一个随机值(如 0-300 秒),让 Key 的实际过期时间分散在“1 小时 ~ 1 小时 5 分钟”之间,避免大量 Key 同一时间失效。
示例代码逻辑:
// 固定过期时间 3600 秒,叠加 0-300 秒随机值
int baseExpire = 3600;
int randomExpire = new Random().nextInt(300);
redisTemplate.opsForValue().set(key, value, baseExpire + randomExpire, TimeUnit.SECONDS);
方案二:核心数据永不过期
对“几乎不变化的核心数据”(如城市列表、商品分类、配置信息),不设置过期时间,避免过期失效问题。若需更新数据,通过“异步线程”主动删除旧缓存并写入新数据(如数据库更新后,发送 MQ 消息触发缓存更新)。
方案三:热点数据缓存预热
在业务高峰到来前(如电商大促、直播带货开始前),通过脚本或后台任务提前将“预知的热点数据”(如热门商品、活动页面数据)加载到缓存中,并设置合理的过期时间(确保高峰期间不过期),避免高峰时缓存 miss。
2. 针对“Redis 整体不可用”的解决方案
方案一:Redis 高可用架构
通过“主从复制+哨兵”或“Redis Cluster 集群”保证 Redis 服务的可用性,避免单点故障:
- 主从复制:主节点负责写操作,从节点负责读操作,主节点故障时从节点可切换为主节点;
- 哨兵(Sentinel):实时监控主从节点健康状态,主节点宕机时自动完成故障转移;
- Redis Cluster:将数据分片存储在多个节点,单个节点故障不影响整体服务,且支持水平扩容。
方案二:多机房容灾
对核心业务,采用“同城双活+异地灾备”架构:
- 同城双活:同一城市部署两个机房的 Redis 集群,数据实时同步,单个机房故障时,流量可切换到另一个机房;
- 异地灾备:不同城市部署灾备集群,定时同步数据(如每 5 分钟),极端情况下(如主城市机房被毁)可从灾备集群恢复服务。
方案三:服务兜底措施
即使 Redis 不可用,也要通过“服务降级、限流、熔断”避免数据库和业务服务被打垮:
- 降级:缓存失效时,返回“默认数据”(如商品默认库存、历史推荐列表)或“服务暂时不可用”提示,减少数据库请求;
- 限流:通过网关(如 Sentinel、Gateway)限制单位时间内的请求量(如每秒最多 1000 次请求到数据库),避免数据库过载;
- 熔断:当数据库请求错误率超过阈值(如 50%)时,暂时熔断数据库访问(如 30 秒内不允许请求数据库),避免数据库雪上加霜,熔断后返回降级数据。
总结
缓存三大问题的本质都是“缓存失效导致请求回源数据库”,解决方案的核心思路可归纳为三类:
- 限流:通过锁、中间件控制访问数据库的请求数(如击穿的互斥锁、雪崩的限流);
- 拦截:在请求到达数据库前过滤无效流量(如穿透的参数校验、布隆过滤器);
- 高可用:保证缓存服务稳定+数据不集中失效(如雪崩的高可用架构、过期时间随机化)。
实际业务中,需结合“数据一致性要求”“并发量”“业务场景”选择合适方案(如金融场景优先互斥锁,直播场景优先逻辑过期),必要时可组合多种方案(如布隆过滤器+缓存空值应对穿透),最大化保障系统稳定性。