【多尺度/局部-全局融合与优化 】涉及的工业异常检测论文摘要整理
【CVPR2023】WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
摘要:
- 研究重点: 视觉异常分类与分割 + 研究领域:工业质量检测 +之前的研究重点:为每个质量检测任务训练自定义模型(需要特定任务的图像和注释)
- 贡献1: 不需要为每个质量检测任务训练自定义模型 + 零样本和少正常样本的异常分类和分割
- 研究模型:视觉-语言模型CLIP + 优点:有竞争性的零/少样本性能 + 缺点:在异常分类和分割任务上效果不佳
- 提出新模型:基于窗口的CLIP (WinCLIP)
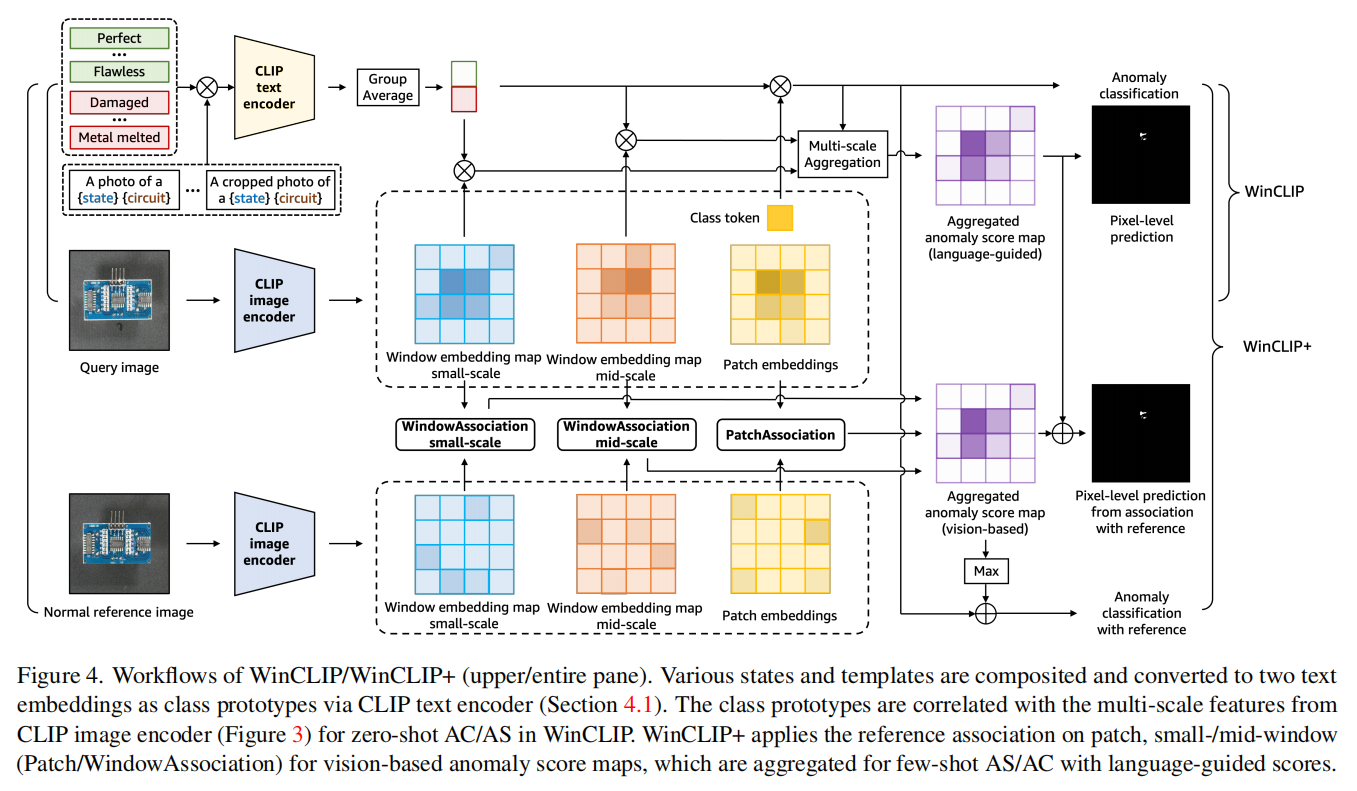
1.对状态词和提示模板的组合集成
2.提取和聚合与文本对齐的窗口/补丁/图像级特征
3.提出少样本设置,利用普通图像的互补信息
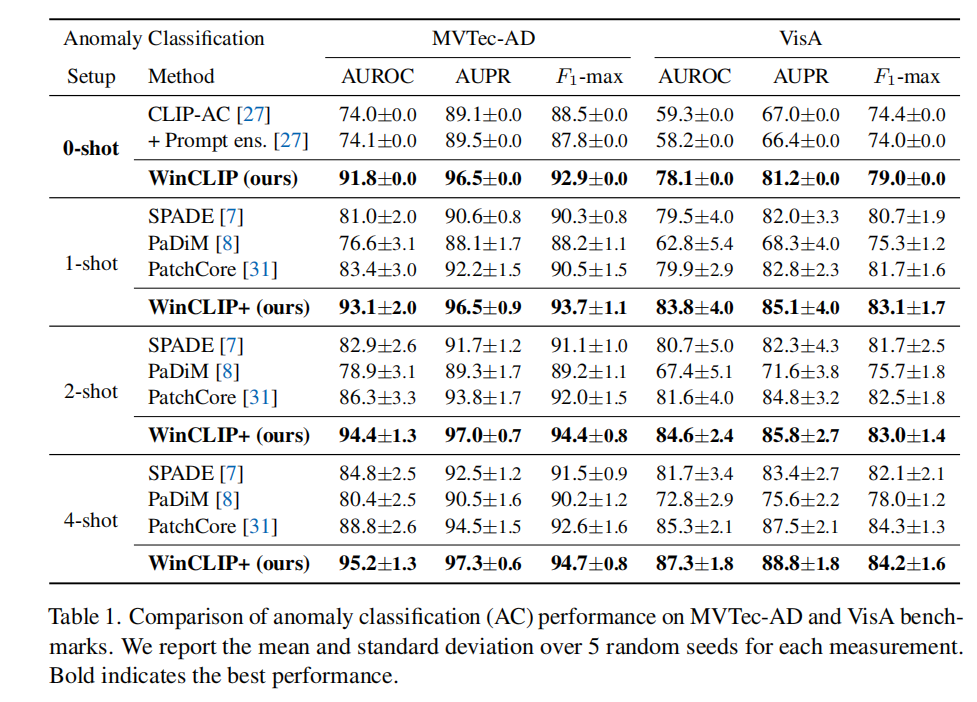
- 实验结果: 数据集:MVTec-AD 和 VisA 指标:AUROC, AUPR, F1-max 结果:比当时最好的方法指标要高
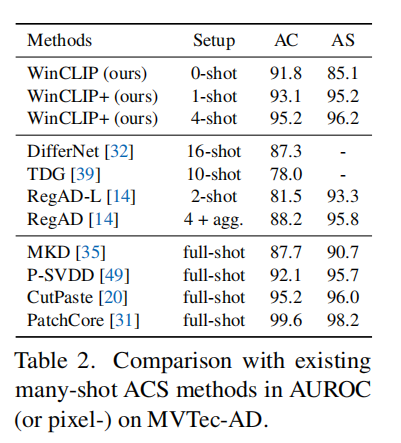
跟多样本的方法相比
代码:https://github.com/caoyunkang/WinClip
【ICLR 2024】ANOMALYCLIP: OBJECT-AGNOSTIC PROMPT LEARNING FOR ZERO-SHOT ANOMALY DETECTION
摘要:
- 研究领域:零样本异常检测(Zero-shot anomaly detection, ZSAD) + 介绍:在目标数据集中没有任何训练样本的情况下,需要使用辅助数据训练的检测模型来检测异常
- 挑战性:模型需要泛化到不同域的异常(前景对象的外观、异常区域和背景特征:不同产品/器官上的缺陷/肿瘤),不同产品的异常可能会有较大差异
- 研究模型:预训练视觉-语言模型(vlm)CLIP + 优点:有强大的零样本识别能力 +缺点:ZSAD性能较弱-》分析原因:VLMs更多地关注于建模前景物体的类语义,×图像中的异常/正常现象
- 提出新模型:AnomalyCLIP【自适应CLIP实现跨不同域的准确ZSAD】
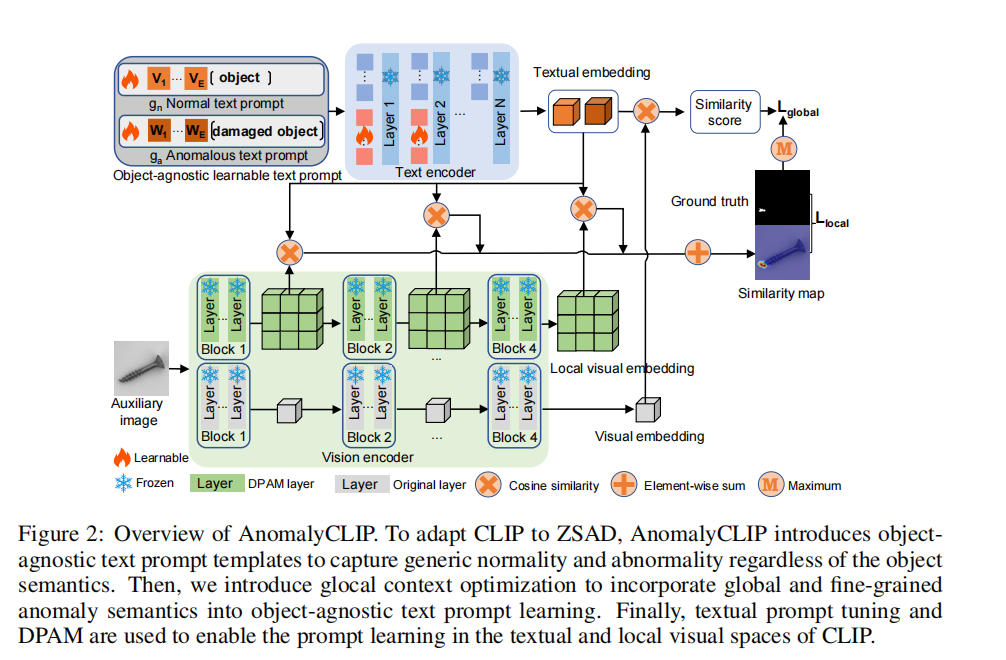
1.学习与对象无关的文本提示:无论前景对象如何,都能捕捉图像中的一般正常和异常-》专注于异常图像区域(×目标语义)+ 对不同类型的目标进行泛化的正常和异常识别
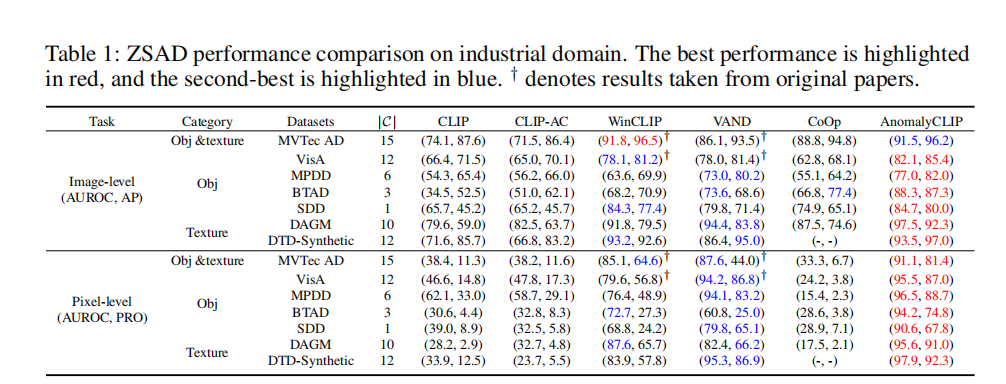
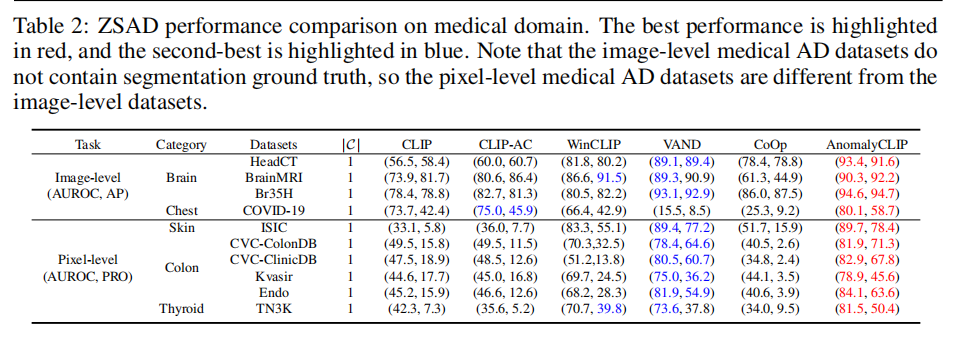
- 实验结果:
比较方法: CLIP, CLIP-AC, WinCLIP , VAND, and CoOp
指标:I(AUROC, AP),P(AUROC, PRO)
工业数据集: MVTec AD ,VisA, MPDD , BTAD, SDD, DAGM, and DTD-Synthetic . In medical imaging, we consider skin cancer detection dataset
医学数据集:
ISIC, CVC-ClinicDB , CVC-ColonDB , Kvasir , and Endo , TN3k ,HeadCT , BrainMRI , Br35H , and
COVID-19
代码:https://github.com/zqhang/AnomalyCLIP
【ACM MM 2024】FiLo: Zero-Shot Anomaly Detection by Fine-Grained Description and High-Quality Localization
摘要:
- 研究领域:零样本异常检测(ZSAD) + 介绍:在不事先访问目标类别内已知的正常或异常样本的情况下检测异常
- 目前研究情况:1.依赖于预训练的多模态模型 2.计算手工制作的表示“正常”或“异常”语义的文本特征与图像块特征之间的相似性 -》检测异常 + 不足:1.对“异常”的一般描述往往无法精确匹配不同对象类别的不同类型的异常 2.计算单个补丁的特征相似性很难确定各种大小和规模的异常的具体位置
- 提出新模型:FiLo【ZSAD方法】
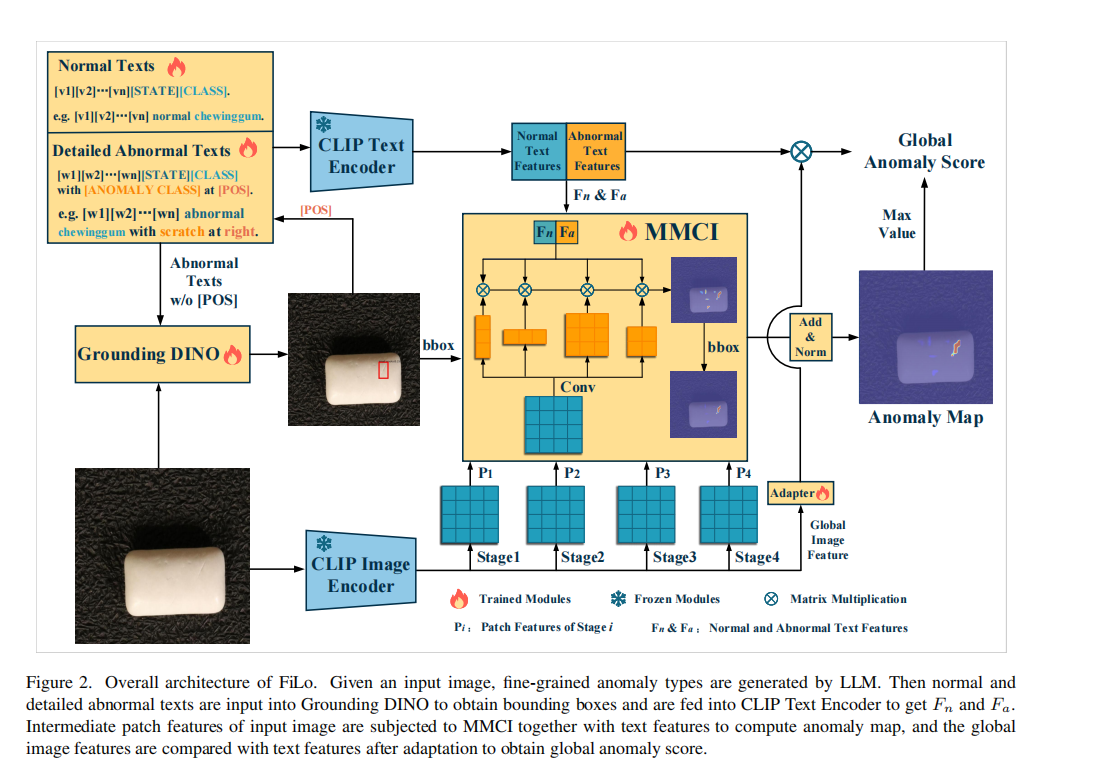
(1)自适应学习的细粒度描述(FG-Des):利用大型语言模型(LLMs)为每个类别引入细粒度的异常描述 + 采用自适应学习的文本模板
(2)位置增强的高质量定位(HQ-Loc):利用DINO初步定位、位置增强的文本提示
(3)多尺度多形状跨模态交互(Multi-scale Multi-shape Cross-modal Interaction, MMCI)模块 :有利于更准确地定位不同大小和形状的异常
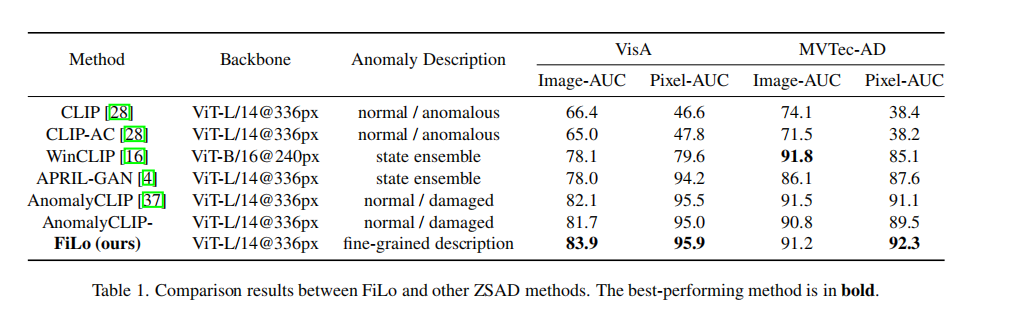
- 实验结果: 数据集:MVTec和VisA 指标: Image-AUC, Pixel-AUC
代码:https://github.com/CASIA-IVA-Lab/FiLo