清华最新发布 | 大型推理模型的强化学习综述
 文章链接:https://arxiv.org/pdf/2509.08827
文章链接:https://arxiv.org/pdf/2509.08827
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/PZfNehkjJQpPmd5O2NM6Jw
https://mp.weixin.qq.com/s/PZfNehkjJQpPmd5O2NM6Jw
一、导读
本文系统阐述了强化学习(RL)如何驱动大语言模型(LLMs)实现复杂推理能力的突破性进展。文章的核心论点是:传统的预训练数据缩放范式在应对数学、编程等复杂任务时面临瓶颈,而基于可验证奖励的强化学习(RLVR) 通过优化模型的“思考过程”(即测试时计算),为能力提升开辟了全新维度。以DeepSeek-R1、OpenAI o1为代表的新一代模型正是借此实现了规划、反思与自我修正等高级认知功能。
技术核心在于对三大基础组件的深度剖析:
-
奖励设计:超越简单的正确性判断,发展出过程奖励(提供步骤级反馈)与生成式奖励(模型自我批判生成奖励),以提供更精细、可解释的学习信号。
-
策略优化:对比了有评论家算法(如PPO,稳定但复杂)与无评论家算法(如GRPO,高效且简单)的优劣,并引入离线策略优化与正则化技术来平衡探索与利用。
-
采样策略:强调通过动态难度调整与结构化采样(如树状搜索)来提升数据效率,让模型在最具价值的“体验”中学习。
文章没有回避当前的核心争议,而是进行了深度辨析。它探讨了RL究竟是“激发”已有能力还是“创造”新能力(锐化vs.发现),比较了RL与监督微调(SFT)在泛化性与记忆性上的本质差异,并分析了从不同能力的基模型(强/弱先验)开始训练的深远影响。最后,全面总结了支撑RL训练的资源生态,包括静态语料库(如数学、代码数据集)、动态环境(代码沙箱、游戏引擎等交互平台)及基础设施(如分布式训练框架),并展望了其在代码生成、科学发现、具身智能等领域的广泛应用前景。
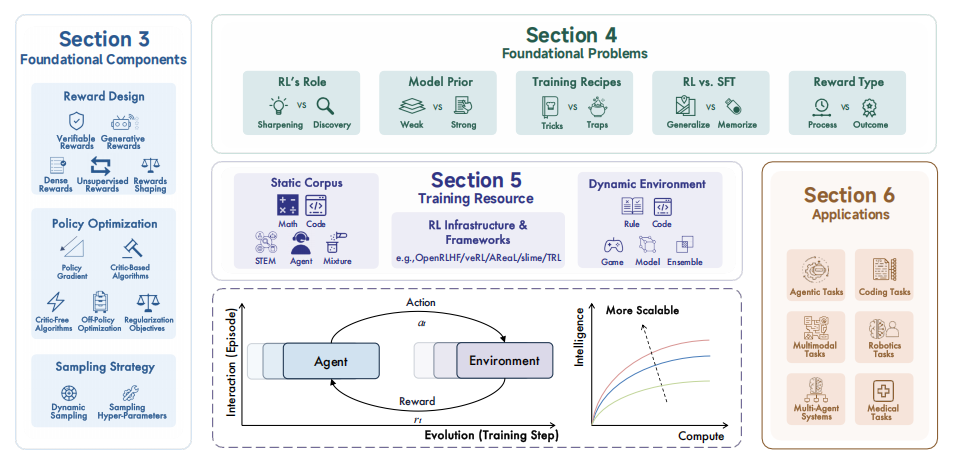
综述概述图
二、奖励设计:从结果评判到过程引导的演进
奖励机制是强化学习的引擎,本文深刻剖析了其从简单二元判断向多层次、可解释反馈系统的演进。核心在于解决奖励稀疏性和信用分配难题。
传统依赖最终答案正确性的“稀疏奖励”存在明显局限,容易导致模型学习捷径或陷入局部最优。为此,研究转向了过程奖励(Dense Rewards),即在推理的中间步骤提供反馈。例如,在数学推理中,不仅看答案是否正确,还对每一步的推导逻辑进行评分;在代码生成中,除了通过单元测试,还对代码风格、效率进行评价。
更进一步的是生成式奖励(Generative Rewards) 的引入。它利用模型自身或另一个“评审模型”生成自然语言评语(如“这一步的推论合理,但忽略了XX条件”),再将评语转化为量化分数。这不仅提供了奖励,更提供了可解释的学习信号,指明了改进方向。
为应对不同场景,奖励设计呈现出多元化融合态势:
-
可验证奖励:依赖规则引擎(如符号计算、代码执行)提供客观、可扩展的反馈,是数学和代码任务的基石。
-
模型批判奖励:在缺乏明确规则的任务(如开放域推理)中,由模型扮演“批判者”提供主观质量评估。
-
奖励塑形(Reward Shaping):通过组合多个奖励信号(如正确性+简洁性+格式)来引导模型行为,平衡不同目标。
三、策略优化:效率与稳定性的平衡艺术
策略优化是将奖励信号转化为模型能力更新的算法核心。本文揭示了该领域从依赖价值函数的复杂方法向无模型的高效方法演进的主流趋势,核心是在稳定性与训练效率之间寻求最佳平衡。
-
基于有评论家(Critic-based) 算法 如PPO,它们引入一个独立的“价值模型”来预测每个状态的长期回报,以更精确地计算优势函数(Advantage)。这类方法虽稳定,但需额外训练并维护一个模型,计算开销巨大,且价值模型的估计偏差会直接影响策略优化。
-
无评论家(Critic-free) 算法 如GRPO及其变体。它们摒弃了价值模型,直接使用序列级奖励(如整个推理过程最终是对是错)并通过群体相对归一化(在同一个问题的多个回答间比较)来估计优势。其最大优势是极大地简化了训练架构,降低了内存和计算成本,使大规模训练更具可行性。
-
离线策略优化 它允许重复利用过去的经验数据(存入回放缓冲区)进行训练,打破了当前策略与采样数据必须一致的约束,显著提升了样本利用效率。此外,各种正则化技术是保障稳定性的关键。例如,通过KL散度控制来防止新策略相对旧策略或基础模型“漂移”过远;通过熵增正则来鼓励探索,避免策略过早收敛到次优解。
四、采样策略:从被动接受到主动探索的范式转变
采样策略决定了模型与“环境”如何交互以产生训练数据,其核心范式已从静态、均匀的抽样转变为动态、结构化的课程学习,目标是最大化每次交互的信息增益。
-
动态采样(Dynamic Sampling) 它不再随机或均匀地选择问题,而是根据实时训练反馈(如模型在某类问题上的成功率、优势值)来自适应地分配采样预算。例如,持续淘汰已完全掌握的问题,将算力集中于模型当前“努努力就能解决”的中等难度问题,或主动采样不确定性高的难题以鼓励探索。
-
结构化采样(Structured Sampling) 它控制的不只是“采样什么”,更是“如何采样”。例如,树状搜索采样将单次序列生成变为一个树形探索过程,允许模型在关键决策点进行分支探索,并在回溯时通过节点级奖励进行更精细的信用分配。共享前缀采样则通过复用已生成的公共前缀的KV缓存,来高效地并行生成多个后续分支,极大地提升了采样效率。
这些先进的采样策略共同作用,使RL训练从一个被动接受数据的过程,转变为一个主动寻求信息的过程,从而以更低的成本、更快的速度引导模型走向更高的性能峰值。
五、资源体系
强化学习(RL)在大语言模型中的规模化应用依赖于一个多层次、协同进化的资源生态体系。该体系为RL训练提供了从数据原料、交互环境到计算支撑的全栈式支持,是推动模型从静态知识存储向动态推理智能跃迁的关键基础。
1. 数据资源:高质量与可验证的训练原料
数据是RL训练的基石。针对不同的推理任务,形成了多样化的数据供给体系:
-
数学推理数据:涵盖从基础计算到竞赛数学的广泛题型,如BigMath、NuminaMath等数据集,提供大量附有分步解答和验证答案的问题-答案对。这些数据强调逻辑严谨性和可验证性,是训练模型数学思维的核心燃料。
-
代码生成与修复数据:包括竞争编程题库(如Codeforces)、真实项目代码(如GitHub Commit)及合成代码数据(如通过代码变换生成缺陷-修复对)。数据集如SWE-bench、CodeRL专注于软件工程任务,提供单元测试作为天然的可验证奖励信号。
-
多模态与具身数据:结合视觉、语言和动作的跨模态数据,如视觉问答(VQA)、机器人操作轨迹(如Open X-Embodiment)及GUI操作序列。这类数据通过像素、指令和动作的多模态对齐,支持更复杂的感知-推理-行动循环训练。
2. 环境平台:交互式与可评估的仿真空间
环境为RL训练提供了交互接口和评估反馈,是其区别于传统监督学习的关键:
-
代码执行环境:代码沙箱(如Docker容器)和单元测试框架(如PyTest)构成了代码RL的核心环境。它们允许安全地执行生成代码,并返回通过/失败、错误信息、输出结果等精确的奖励信号。
-
逻辑与推理环境:形式化系统(如Lean、Coq)提供了定理证明的交互环境,模型生成的每一步推导都可被严格验证;合成谜题环境(如PuzzleJAX、Logic-Gym)可以程序化生成无穷的逻辑谜题,并自动判定正误,支持可控难度的课程学习。
-
具身与多模态环境:机器人仿真平台(如MuJoCo、Isaac Gym)提供物理真实的训练场;虚拟世界(如ALFWold、ScienceWorld)则提供了基于文本的交互式环境,支持长期规划与语言 grounding。
3. 基础设施:规模化训练的技术底座
基础设施是将算法、数据和环境整合并实现高效训练的系统级支撑:
-
分布式训练框架:专为RLHF/RLVR设计的训练框架,如OpenRLHF、DeepSpeed RL、TRL等,提供了一套完整的解决方案,包括:分布式经验采样(Rollout)、奖励模型服务、策略优化和模型托管,实现了从数据生成到模型更新的自动化流水线。
-
高效推理与服务:为了应对RL中大量的模型采样(推理)需求,集成了高性能推理引擎,如vLLM(通过PagedAttention优化吞吐)、TensorRT-LLM(GPU极致优化)和SGLang(针对复杂推理结构优化),极大提升了生成效率并降低了成本。
-
资源调度与编排:利用Kubernetes、Slurm或Ray等集群管理工具,对异构计算资源(CPU for rollout, GPU for training)进行统一调度和弹性伸缩,以满足长时间、大规模RL训练任务的需求。
六、应用场景
1. 复杂数学与算法推理
RL训练的模型在解决需要严格符号操作和证明链的复杂数学问题上展现出显著优势。其应用已从计算题解答延伸至竞赛数学(如AMC、IMO题型)和形式化定理证明(如与Lean、Co0等交互式定理证明器协同工作)。模型不仅能生成答案,更能输出人类可读的、逻辑严密的推导过程,并通过过程奖励进行自我验证和修正。在算法领域,模型在竞争性编程平台(如Codeforces、LeetCode)上的表现不断提升,能够解决需要复杂数据结构和动态规划技巧的题目,展示了将非形式化问题转化为可执行算法的能力。
2. 软件工程与代码生成
代码生成从单函数补全升级为整个软件生命周期的辅助。RL训练的代码模型在以下场景表现突出:
代码修复与漏洞检测:分析代码库,识别潜在错误、安全漏洞或性能瓶颈,并生成修复补丁。其奖励信号来源于测试用例的通过率、静态分析工具的输出或安全规则的符合性。
跨语言代码迁移与重构:将代码从一种编程语言(如Python)转换为另一种(如Rust或C++),同时保持功能等价性并适配目标语言的惯用法和性能特性。
仓库级别的代码生成与理解:处理涉及多个文件、模块和复杂依赖关系的项目级任务,如根据自然语言需求生成新特性代码或解读大型开源项目的整体架构。
3. 具身智能与多模态推理
视觉-语言-动作循环:作为机器人或虚拟智能体的“大脑”,模型接收视觉观察(如图像或视频帧)和自然语言指令,通过多步推理生成物理动作序列(如抓取、导航),并在仿真环境(如Isaac Gym)或真实世界中执行,完成长期任务。
交互式决策与规划:在复杂、动态的环境中(如模拟家居、自动驾驶场景)进行实时决策,需要模型理解环境状态、预测其他智能体行为并制定安全高效的长期规划策略。
七、总结
本文系统阐述了强化学习(RL)如何成为推动大型语言模型(LLMs)实现复杂推理能力突破的核心驱动力。通过引入可验证奖励机制(RLVR),模型如DeepSeek-R1和OpenAI o1展现出规划、反思与自我修正等高级认知功能,标志着从传统预训练数据缩放向测试时计算优化的范式转变。技术核心围绕三大支柱展开:奖励设计从稀疏结果评判演进为提供步骤级反馈的过程奖励与生成式奖励;策略优化从有评论家算法转向高效的无评论家架构(如GRPO),兼顾稳定性与效率;采样策略通过动态难度调整与结构化探索(如树搜索)最大化数据价值。报告同时辨析了RL与SFT的互补性、“锐化已有能力”与“创造新策略”的争议,并扫描了支撑规模化训练的数据、环境及基础设施生态。最终,RL为LLMs在数学证明、代码生成、科学发现及具身智能等领域的应用开辟了新路径,清晰勾勒出通向通用推理智能的技术蓝图。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/PZfNehkjJQpPmd5O2NM6Jw
https://mp.weixin.qq.com/s/PZfNehkjJQpPmd5O2NM6Jw