数据科学-损失函数
在机器学习领域,损失函数 (Loss Function) 是衡量模型预测结果与真实值之间差异的核心指标,它不仅指导模型参数的更新方向,还直接影响模型的泛化能力和性能表现。对于数据科学家而言,深入理解不同损失函数的原理、特性及适用场景,是构建高效、鲁棒模型的关键一步。
本文将系统介绍八种常见的损失函数:0-1 损失函数、平方错误函数、交叉熵损失、Hinge 损失、CRF 损失、KL 散度损失、RankNet 损失和 LambdaRank 损失。我们将从数学原理、代码实现和实际应用三个维度进行全面解析,帮助数据科学家在实际项目中能够根据具体问题选择最合适的损失函数。
0-1 损失函数
0-1 损失函数是分类任务中最直观的损失函数之一,主要用于衡量分类模型的错误率。其核心思想是:若预测结果与真实标签一致,则损失为 0;若不一致,则损失为 1。
数学定义
对于单个样本,0-1 损失函数定义为:
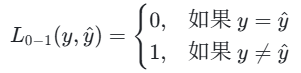
对于所有样本,0-1 损失是错误分类样本的占比:
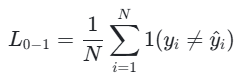
其中,1(⋅)是指示函数(条件满足时为 1,否则为 0),N是样本总数,yi是第i个样本的真实标签,y^i是模型的预测结果。
从数学角度看,0-1 损失函数计算的是预测结果与真实标签之间的汉明距离的平均值,它直接反映了分类错误率,即准确率 = 1 - 0-1 损失。
PyTorch 代码示例
虽然 PyTorch 没有内置的 0-1 损失函数,但我们可以很容易地自定义实现:
import torchdef zero_one_loss(y_pred, y_true):# y_pred是模型的预测结果(可以是logits或概率)# y_true是真实标签(整数类型)# 返回平均0-1损失# 将预测结果转换为类别标签_, predicted = torch.max(y_pred.data, 1)# 计算错误分类的样本数incorrect = (predicted != y_true).sum().item()# 返回平均损失return incorrect / y_true.size(0)# 示例用法
if __name__ == "__main__":# 示例数据:3个样本,5分类问题y_pred = torch.tensor([[1.2, 0.4, -0.5, 2.1, 0.3],[0.8, 1.9, -1.2, 0.4, 1.1],[-0.1, 2.4, 0.7, 1.5, -0.5]])y_true = torch.tensor([3, 1, 4])loss = zero_one_loss(y_pred, y_true)print(f"0-1 Loss: {loss:.4f}") # 输出示例: 0.0000(假设预测完全正确)优缺点分析与适用场景
优点:
- 直观性:直接反映分类错误率,易于理解和解释。
- 无参数依赖:仅关注分类结果的对错,不依赖预测概率的置信度。
- 计算简单:只需要比较预测标签和真实标签即可。
缺点:
- 不可微性:函数是离散的、非凸的,梯度几乎处处为 0 或不存在,无法通过梯度下降等算法直接优化模型参数。
- 对概率不敏感:即使预测概率接近真实标签(如正确类别概率为 0.51,错误类别为 0.49),只要最终分类错误,损失值仍为 1。
- 不提供置信度信息:无法反映模型对预测结果的置信程度。
适用场景:
- 理论分析:在理论研究中作为评估标准,但很少直接用于模型训练。
- 模型评估:作为模型最终性能的评估指标,特别是在需要准确分类结果的场景。
- 基准比较:作为简单的基准方法,与其他复杂损失函数的效果进行对比。
由于 0-1 损失的不可微性,实际应用中通常使用其他可微的替代损失函数(如交叉熵损失)来近似它,这些替代函数在优化过程中更容易处理,并且能够提供更丰富的训练信号。
平方错误函数(均方误差损失)
平方错误函数,也称为均方误差(Mean Squared Error, MSE),是回归任务中最常用的损失函数之一。它衡量的是预测值与真实值之间差异的平方的平均值。
数学定义
对于单个样本,平方错误损失定义为:
![]()
其中,N是样本总数,yi<referencetype="end"id=19>是第i个样本的真实值,y^i是模型的预测值。
从几何角度看,MSE 可以理解为预测值与真实值之间的欧氏距离的平方,然后取平均值。它是一种 L2 范数损失函数,对预测值与真实值之间的差异进行平方惩罚。
PyTorch 代码示例
PyTorch 提供了内置的 MSE 损失函数,可以方便地在回归任务中使用:
import torch
import torch.nn as nn# 创建MSE损失函数实例
mse_loss = nn.MSELoss()# 示例数据
y_true = torch.tensor([1.0, 2.5, 2.8], dtype=torch.float32)
y_pred = torch.tensor([1.5, 2.0, 3.2], dtype=torch.float32)# 计算损失
loss = mse_loss(y_pred, y_true)
print(f"MSE Loss: {loss.item():.4f}") # 输出: MSE Loss: 0.2967# 带reduction参数的MSE
mse_loss_sum = nn.MSELoss(reduction='sum') # 求和而非平均
loss_sum = mse_loss_sum(y_pred, y_true)
print(f"MSE Sum Loss: {loss_sum.item():.4f}") # 输出: MSE Sum Loss: 0.8900参数说明:
reduction:指定缩减方式,可选:
- 'mean'(默认):返回损失的平均值
- 'sum':返回损失的总和
- 'none':返回每个样本的损失
优缺点分析与适用场景
优点:
- 数学性质良好:处处可导,梯度计算高效,适合梯度下降优化。
- 计算简单:公式简单,易于实现和理解。
- 梯度更新方向明确:梯度随误差增大而增大,有利于梯度下降快速收敛。
- 统计无偏性:在某些条件下,MSE 是回归参数的无偏估计。
缺点:
- 对异常值敏感:平方运算会放大离群点的影响,导致模型过度拟合异常值。
- 收敛速度可能较慢:在接近最优解时,梯度变得很小,可能导致收敛速度变慢。
- 非鲁棒性:当数据中存在显著异常值时,MSE 可能导致模型性能下降。
适用场景:
- 数据噪声较小且分布均匀的回归任务:如温度预测、房价回归等。
- 数据分布相对稳定:当异常值较少且对模型影响较小时。
- 需要高精度预测的场景:如金融预测、科学模拟等对预测精度要求较高的领域。
在实际应用中,如果数据中存在较多异常值,可以考虑使用平均绝对误差 (MAE) 或 Huber 损失等更鲁棒的替代方案。
交叉熵损失
交叉熵损失(Cross-Entropy Loss)是分类任务中最常用的损失函数之一,尤其适用于多分类问题。它衡量的是两个概率分布之间的差异。
信息理论基础:
在信息论中,交叉熵是信息熵与 KL 散度的组合:
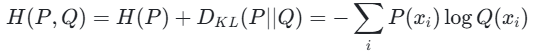
其中,H(P)是信息熵,DKL(P∣∣Q)是 KL散度,P是真实分布,Q是预测分布
在分类任务中,P是真实分布(通常为 one-hot 编码),Q是模型预测的概率分布。最小化交叉熵等价于最小化 KL 散度,因为真实分布的信息熵是一个常数。
数学定义
对于单个样本的多分类任务,交叉熵损失定义为:
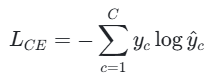
其中,yc<referencetype="end"id=52>是真实标签中类别c的概率(0 或 1),y^c是模型预测类别c的概率(经 Softmax 归一化)。
在实际应用中,通常将 Softmax 函数与交叉熵损失合并使用,形成 Softmax-CrossEntropy 损失,其计算公式为:
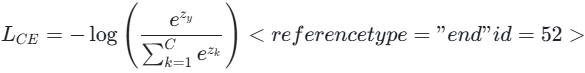
其中,zy是真实类别对应的未归一化得分(logits),C是类别总数。
PyTorch 代码示例
PyTorch 提供了内置的 CrossEntropyLoss 函数,该函数将 Softmax 和交叉熵损失合并在一起,使用非常方便:
import torch
import torch.nn as nn# 创建交叉熵损失函数实例
ce_loss = nn.CrossEntropyLoss()# 示例数据:3个样本,5分类问题
# 注意:输入不需要softmax,内部会自动处理
logits = torch.tensor([[1.2, 0.4, -0.5, 2.1, 0.3],[0.8, 1.9, -1.2, 0.4, 1.1],[-0.1, 2.4, 0.7, 1.5, -0.5]], dtype=torch.float32)# 每个样本的真实类别索引(0-4)
targets = torch.tensor([3, 1, 4], dtype=torch.long)# 计算损失
loss = ce_loss(logits, targets)
print(f"CrossEntropy Loss: {loss.item():.4f}") # 输出示例: 0.8765参数说明:
- weight(Tensor, 可选):给每个类别分配权重,用于处理类别不平衡问题
- ignore_index(int, 可选):指定一个被忽略的类别索引,其不会贡献损失
- reduction(str, 可选):指定缩减方式,可选 'mean'(默认)、'sum' 或 'none'
- label_smoothing<reference type="end" id=52>(float, 可选):标签平滑系数,0.0 表示不使用
优缺点分析与适用场景
优点:
- 梯度更新方向明确:提供清晰的梯度信号,有利于模型快速收敛。
- 计算效率高:与 Softmax 函数结合后,可以高效地计算梯度。
- 概率解释性:输出结果可以解释为概率分布,易于理解。
- 处理多分类问题:天然支持多分类场景,适用于各类分类任务。
缺点:
- 对类别不平衡敏感:当不同类别的样本数量差异较大时,模型可能偏向多数类。
- 需要概率校准:直接使用原始 logits 可能导致预测概率不准确,需要适当的校准。
- 计算复杂度:涉及指数运算,计算成本相对较高。
适用场景:
- 多分类任务:如图像识别、文本分类、语音识别等。
- 类别不平衡问题:结合加权或采样策略可以有效处理类别不平衡数据。
- 需要概率输出的场景:当需要模型输出预测概率而非简单标签时。
- 深度学习模型:广泛应用于神经网络,尤其是在最后一层使用 Softmax 激活函数的情况。
在实际应用中,交叉熵损失是分类问题的首选损失函数,其良好的数学性质和计算效率使其成为深度学习框架中的标准选择。
Hinge 损失
Hinge 损失(Hinge Loss)是支持向量机(SVM)中常用的损失函数,主要用于二分类和多分类问题。它的设计目标是最大化分类边界(Margin),要求正确类别的得分比其他类别至少高出一个固定边界值(通常为 1)。
数学定义
对于二分类任务,标签编码为yi∈{−1,1},模型输出为原始得分(未归一化),Hinge 损失定义为:
![]()
当正确类别的得分LaTex error时,损失为 0;否则损失随差距线性增加。
对于多分类问题,采用 "一对多"(One-vs-All) 策略,计算所有错误类别的损失并求和:
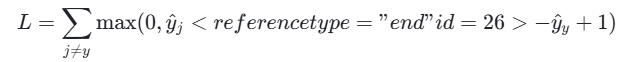
其中,y^y为正确类别的得分,y^j为其他类别的得分。
Hinge 损失的几何意义是最大化分类边界,即最大化正确类别得分与最近错误类别得分之间的差距,从而提高模型的泛化能力。
PyTorch 代码示例
PyTorch 提供了 HingeEmbeddingLoss 和 MultiMarginLoss 等函数来实现 Hinge 损失:
import torch
import torch.nn as nn# 二分类Hinge损失示例
def binary_hinge_loss(pred, target):# pred: 模型的原始输出(未经过激活函数)# target: 真实标签,-1或1return torch.mean(torch.clamp(1 - target * pred, min=0))# 多分类Hinge损失示例
def multi_class_hinge_loss(pred, target):# pred: 模型的原始输出,形状为[batch_size, num_classes]# target: 真实类别索引,形状为[batch_size]batch_size, num_classes = pred.shape# 计算正确类别的得分correct_scores = pred[torch.arange(batch_size), target]# 计算所有错误类别的得分与正确类别得分的差距margins = pred - correct_scores.view(-1, 1) + 1# 将正确类别的差距设为0,不参与损失计算margins[torch.arange(batch_size), target] = 0# 应用ReLU函数,取最大值0和差距hinge_loss = torch.clamp(margins, min=0)# 返回平均损失return hinge_loss.mean()# 示例用法
if __name__ == "__main__":# 二分类示例pred_binary = torch.tensor([2.0, -1.5, 3.0], dtype=torch.float32)target_binary = torch.tensor([1, -1, 1], dtype=torch.float32)loss_binary = binary_hinge_loss(pred_binary, target_binary)print(f"Binary Hinge Loss: {loss_binary.item():.4f}") # 输出示例: 0.1667# 多分类示例pred_multi = torch.tensor([[0.25, 0.20, 0.55],[0.55, 0.05, 0.40],[0.10, 0.30, 0.60],[0.90, 0.05, 0.05]], dtype=torch.float32)target_multi = torch.tensor([0, 1, 2, 0])loss_multi = multi_class_hinge_loss(pred_multi, target_multi)print(f"Multi-class Hinge Loss: {loss_multi.item():.4f}") # 输出示例: 0.9125优缺点分析与适用场景
优点:
- 边际最大化:通过惩罚机制促进决策边界的边际最大化,提高模型的泛化能力。
- 稀疏性:能够产生稀疏的支持向量,减少模型复杂度。
- 对噪声鲁棒:线性惩罚机制使其对离群点的敏感度低于平方损失。
- 明确的几何解释:损失函数的设计直接关联到分类边界的最大化,具有清晰的几何意义。
缺点:
- 不直接输出概率:Hinge 损失的输出是原始得分,而非概率,需要后处理(如 Platt Scaling)才能得到概率估计。
- 计算复杂度较高:对于多分类问题,需要计算所有错误类别的损失,时间复杂度为 O (n^2)。
- 非概率解释:无法提供预测结果的概率解释,这在某些应用中可能是一个限制。
- 对参数敏感:边际参数的选择对模型性能有较大影响,需要仔细调优。
适用场景:
- 支持向量机:Hinge损失是 SVM 的核心组成部分,特别适合线性可分的数据。
- 需要强分类边界的任务:当分类边界的明确性比概率估计更重要时。
- 数据量较小的场景:SVM 结合 Hinge 损失在小数据集上通常表现良好。
- 特征维度高的问题:如文本分类,SVM 在高维特征空间中表现出色。
- 在线学习:某些 Hinge 损失的变体支持在线学习和增量更新。
在实际应用中,Hinge 损失的边际最大化特性使其在数据量适中、特征维度高的分类问题中表现优异,特别是在需要清晰分类边界的场景。
CRF 损失
条件随机场损失(Conditional Random Field Loss, CRF Loss)是序列标注任务中常用的损失函数,它能够捕捉序列数据中的依赖关系,如词性标注、命名实体识别等。
数学定义
条件随机场(CRF)是一种概率无向图模型,其条件分布P(Y=y∣x)可表示为具有吉布斯分布的形式:
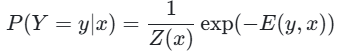
其中,E(y,x)表示能量函数,Z(x)代表配分函数,以确保P(Y=y∣x)是一个合法的概率分布。
在全连接成对 CRF 的情况下,能量函数可表示为:
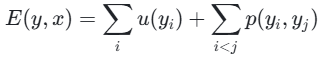
其中,i∑和i<j∑分别表示对所有补丁和补丁的成对组合进行求和。u(yi)表示与补丁i相关的一元势,衡量在给定补丁嵌入xi的情况下,补丁i采用标签yi的成本;p(yi,yj)表示补丁i和j之间的成对势,衡量在给定补丁嵌入xi和xj的情况下,同时为补丁j分配标签yi和yj的成本。
CRF 损失函数通常定义为负对数似然损失:
![]()
其中,E(Y∣X)是能量函数,Z(X)是配分函数。
PyTorch 代码示例
在 PyTorch 中,可以使用 torchcrf 库来实现 CRF 损失:
import torch
import torch.nn as nn
from torchcrf import CRFclass CRFModel(nn.Module):def __init__(self, num_tags):super(CRFModel, self).__init__()self.num_tags = num_tagsself.crf = CRF(num_tags, batch_first=True)# 假设使用一个简单的嵌入层和线性层作为特征提取器self.embedding = nn.Embedding(vocab_size, embedding_dim)self.fc = nn.Linear(embedding_dim, num_tags)def forward(self, x, tags=None):# x: 输入序列,形状为[batch_size, seq_length]# tags: 真实标签序列,形状为[batch_size, seq_length],可选# 提取特征并转换为标签空间emissions = self.fc(self.embedding(x)) # 形状为[batch_size, seq_length, num_tags]# 如果提供了标签,则计算损失if tags is not None:loss = -self.crf(emissions, tags)return loss# 否则进行预测else:return self.crf.decode(emissions)# 示例用法
if __name__ == "__main__":# 假设参数已定义vocab_size = 1000embedding_dim = 128num_tags = 5 # 假设5个标签model = CRFModel(num_tags)# 示例输入数据batch_size = 2seq_length = 10x = torch.randint(0, vocab_size, (batch_size, seq_length))tags = torch.randint(0, num_tags, (batch_size, seq_length))# 计算损失loss = model(x, tags)print(f"CRF Loss: {loss.item():.4f}") # 输出示例: 某个损失值优缺点分析与适用场景
优点:
- 捕捉序列依赖:能够有效建模序列数据中的长距离依赖关系,提高标注准确性。
- 全局最优:CRF 损失考虑整个序列的标签分配,而非独立地对每个位置进行预测,从而得到全局最优解。
- 灵活性:可以灵活设计不同的势函数来捕捉不同类型的依赖关系。
- 概率解释:输出是概率分布,可以提供每个标签分配的置信度。
缺点:
- 计算复杂度高:精确推断需要计算配分函数,时间复杂度为 O(n^2),对于长序列可能不适用。
- 训练时间长:由于需要计算梯度,训练 CRF 模型通常比独立标记模型更耗时。
- 参数估计困难:需要估计大量参数,包括一元势和成对势参数。
- 需要领域知识:设计有效的势函数可能需要领域特定的知识。
适用场景:
- 序列标注任务:如命名实体识别、词性标注、语义角色标注等。
- 结构化预测:当预测结果具有结构依赖时,如句法分析。
- 图像分割:CRF 也可应用于图像分割,捕捉像素间的空间关系。
- 自然语言处理:特别是在需要考虑上下文信息的 NLP 任务中。
在实际应用中,CRF 损失在序列标注任务中表现出色,尤其是在数据量有限的情况下,能够有效利用上下文信息提高标注准确性。
KL 散度损失
KL 散度损失(Kullback-Leibler Divergence Loss),也称为相对熵损失,用于衡量两个概率分布之间的差异。在机器学习中,它常用于生成模型、知识蒸馏和变分自编码器等任务。
数学定义
KL 散度衡量两个概率分布P和Q的差异,定义为:
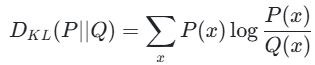
在连续情况下,求和变为积分:
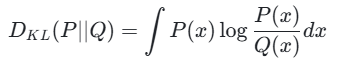
KL 散度具有非负性,且当且仅当P=Q时,DKL(P∣∣Q)=0。需要注意的是,KL 散度是不对称的,即DKL(P∣∣Q)<referencetype="end"id=52>DKL(Q∣∣P)。
在机器学习中,KL 散度损失通常定义为:
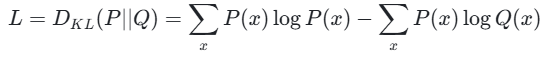
其中,P是真实分布或目标分布,Q是模型预测的分布。
PyTorch 代码示例
PyTorch 提供了 KLDivLoss 函数来计算 KL 散度损失:
import torch
import torch.nn as nn# 创建KL散度损失函数实例
kl_loss = nn.KLDivLoss(reduction='batchmean')# 示例数据
# 假设P是真实分布,Q是模型预测的分布
# 注意:输入通常是对数概率,因为KLDivLoss默认期望log probabilities作为输入
batch_size = 3
num_classes = 5# 真实分布P(例如,经过Softmax后的分布)
P = torch.tensor([[0.1, 0.2, 0.3, 0.4, 0.0],[0.0, 0.0, 1.0, 0.0, 0.0],[0.3, 0.3, 0.2, 0.1, 0.1]], dtype=torch.float32)# 模型预测的分布Q的对数概率(logits)
log_Q = torch.tensor([[1.2, 0.4, -0.5, 2.1, 0.3],[0.8, 1.9, -1.2, 0.4, 1.1],[-0.1, 2.4, 0.7, 1.5, -0.5]], dtype=torch.float32)# 计算KL散度损失
loss = kl_loss(log_Q, P)
print(f"KL Divergence Loss: {loss.item():.4f}") # 输出示例: 某个损失值# 知识蒸馏中的KL散度损失示例
def knowledge_distillation_loss(student_logits, teacher_logits, temperature=1.0):# 应用温度缩放p_teacher = nn.functional.softmax(teacher_logits / temperature, dim=1)log_p_student = nn.functional.log_softmax(student_logits / temperature, dim=1)# 计算KL散度损失并缩放loss = nn.functional.kl_div(log_p_student, p_teacher, reduction='batchmean') * (temperature ** 2)return loss# 示例用法
if __name__ == "__main__":teacher_logits = torch.tensor([[5.0, 1.0, 2.0], [3.0, 4.0, 0.5]])student_logits = torch.tensor([[4.5, 0.8, 2.2], [3.2, 3.8, 0.7]])loss_kd = knowledge_distillation_loss(student_logits, teacher_logits, temperature=2.0)print(f"Knowledge Distillation Loss: {loss_kd.item():.4f}") # 输出示例: 某个损失值优缺点分析与适用场景
优点:
- 分布差异度量:直接衡量两个概率分布的差异,提供了比简单距离度量更丰富的信息。
- 非负性:KL 散度始终非负,当且仅当两个分布完全相同时为零,这一特性使其成为衡量分布相似性的理想选择。
- 灵活性:可以用于各种概率模型,如生成模型、变分自编码器等。
- 梯度特性:提供了清晰的梯度信号,有利于优化。
缺点:
- 不对称性:KL 散度是不对称的,即DKL(P∣∣Q)not=DKL(Q∣∣P),这在某些应用中可能带来不便。
- 计算复杂度:需要计算整个概率分布的积分或求和,对于高维分布可能计算量很大。
- 对分布形状敏感:对分布的尾部差异特别敏感,这可能导致在某些情况下梯度不稳定。
- 非距离度量:不满足三角不等式,因此不是严格意义上的距离度量。
适用场景:
- 知识蒸馏:将教师模型的知识传递给学生模型,提高学生模型的性能。
- 生成模型:如变分自编码器(VAE)中,KL 散度用于衡量潜在分布与先验分布的差异。
- 分布匹配:在生成对抗网络(GAN)的某些变体中,用于匹配生成分布和真实分布。
- 异常检测:当正常数据和异常数据的分布差异较大时,可以使用 KL 散度进行检测。
- 信息检索:在文档排序模型中,用于精化模型的表示。
在实际应用中,KL 散度损失的非对称性需要特别注意,根据任务需求选择正确的方向。例如,在知识蒸馏中,通常使用D<referencetype="end"id=6>KL(Q∣∣P),其中P是教师模型的分布,Q是学生模型的分布。
RankNet 损失
RankNet 损失是一种用于排序任务的损失函数,它基于成对比较的思想,旨在学习文档之间的相对顺序。RankNet 最初由 Burges 等人在 2005 年提出,是学习排序(Learning to Rank)领域的重要方法。
数学定义
RankNet 的核心思想是将排序问题转化为成对分类问题。对于每对文档(di,dj),其中di的相关度高于dj(即yi>yj),RankNet 模型估计这对文档的正确排序概率:
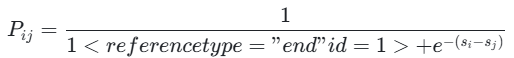
其中,si和sj是模型对文档di和dj的评分
RankNet 的损失函数基于交叉熵损失,定义为:
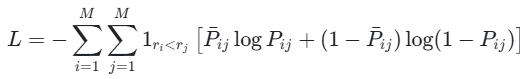
其中,Pˉij是期望的目标概率(通常Pˉij在yi>yj时为 1,否则为 0),1ri<rj是指示函数,当di的相关度低于dj时为 1,否则为 0。
PyTorch 代码示例
import torch
import torch.nn as nnclass RankNetLoss(nn.Module):def __init__(self):super(RankNetLoss, self).__init__()def forward(self, scores, labels):# scores: 模型对文档的评分,形状为[batch_size, 1]# labels: 文档的相关度标签,形状为[batch_size, 1]# 计算所有文档对的得分差score_diff = scores - scores.t() # 形状为[batch_size, batch_size]# 计算概率probabilities = torch.sigmoid(score_diff) # 形状为[batch_size, batch_size]# 创建目标矩阵,其中相关度高的文档对的目标概率为1,否则为0# 注意:这里假设标签是数值型的,越大表示相关度越高target = (labels > labels.t()).float() # 形状为[batch_size, batch_size]# 计算交叉熵损失loss = -torch.mean(target * torch.log(probabilities) + (1 - target) * torch.log(1 - probabilities))return loss# 示例用法
if __name__ == "__main__":# 示例数据:4个文档,每个文档的评分和标签scores = torch.tensor([[2.0], [1.5], [3.0], [0.8]], dtype=torch.float32)labels = torch.tensor([[3], [2], [4], [1]], dtype=torch.float32) # 标签越高表示相关度越高# 创建损失函数实例criterion = RankNetLoss()# 计算损失loss = criterion(scores, labels)print(f"RankNet Loss: {loss.item():.4f}") # 输出示例: 某个损失值优缺点分析与适用场景
优点:
- 成对比较:直接处理文档对之间的相对顺序,符合排序任务的本质需求。
- 灵活性:可以处理任何类型的特征和模型架构,只要能输出文档的评分。
- 对标签噪声鲁棒:对单个文档的绝对相关度标签不敏感,只关注文档对之间的相对顺序。
- 计算效率:相对于全排列方法,计算复杂度较低,适用于大规模数据集。
缺点:
- 计算复杂度高:需要处理O(n2)对文档,当文档数量较大时,计算量显著增加。
- 忽略位置信息:只关注文档对的相对顺序,不考虑它们在最终排序列表中的具体位置。
- 训练数据需求:需要大量的成对比较数据,这在某些场景下可能难以获取。
- 对极端情况敏感:当文档对的相关度差异很大时,可能导致梯度不稳定。
适用场景:
- 信息检索:如搜索引擎的结果排序、文档检索等。
- 推荐系统:对用户可能感兴趣的物品进行排序。
- 问答系统:对问题的候选答案进行排序。
- 自然语言处理:如句子排序、文本摘要等需要排序的 NLP 任务。
- 学习排序:作为其他排序算法(如 LambdaRank)的基础。
在实际应用中,RankNet 是学习排序领域的基础方法,其成对比较的思想为后续更复杂的排序算法提供了重要启发。虽然计算复杂度较高,但在文档数量适中的情况下,RankNet 仍然是一个有效的选择。
LambdaRank 损失
LambdaRank 损失是对 RankNet 损失的改进,它引入了特定的信息检索指标(如 NDCG)来调整梯度,从而直接优化这些指标。LambdaRank 由 Burges 等人在 2005 年提出,是学习排序领域的重要方法。
数学定义
LambdaRank 的核心思想是将信息检索指标(如 NDCG)的梯度融入到 RankNet 的损失函数中。对于每对文档(di,dj),其中di的相关度高于dj(即yi>yj),LambdaRank 计算梯度:
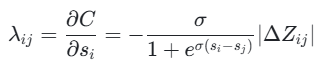
其中,σ=1,∣ΔZij∣是交换di和dj<referencetype="end"id=11>的排名位置而保持其他文档的排名位置不变时,信息检索指标Z的变化量。
在 LambdaRank 中,损失函数的梯度由λ<referencetype="end"id=1>ij决定,而非 RankNet 中的概率误差。这使得模型能够直接优化特定的检索指标,如 NDCG。
具体来说,LambdaRank 的梯度λi计算为:
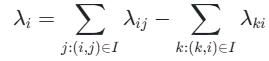
其中,I是有序对集合
PyTorch 代码示例
以下是一个简化的 LambdaRank 损失函数的 PyTorch 实现:
import torch
import torch.nn as nnclass LambdaRankLoss(nn.Module):def __init__(self, metric='ndcg'):super(LambdaRankLoss, self).__init__()self.metric = metric # 支持的指标:ndcg, map等def forward(self, scores, labels):# scores: 模型对文档的评分,形状为[batch_size, 1]# labels: 文档的相关度标签,形状为[batch_size, 1]# 计算所有文档对的得分差score_diff = scores - scores.t() # 形状为[batch_size, batch_size]# 计算梯度的基本部分(类似RankNet的梯度)gradient = torch.sigmoid(-score_diff) # 形状为[batch_size, batch_size]# 计算交换文档对的位置对指标的影响(简化实现,需根据具体指标实现)# 这里以NDCG为例,需实现具体的NDCG计算和delta计算# 注意:这是一个简化的示例,实际实现需要更复杂的计算delta_ndcg = self.calculate_delta_ndcg(scores, labels)# 将梯度与delta_ndcg相乘lambda_gradient = gradient * delta_ndcg# 计算最终的损失loss = torch.sum(lambda_gradient)return lossdef calculate_delta_ndcg(self, scores, labels):# 简化的delta NDCG计算示例# 实际实现需要根据具体指标进行详细计算# 返回形状为[batch_size, batch_size]的delta矩阵# 这里只是一个占位符,返回全1矩阵return torch.ones_like(scores - scores.t())# 示例用法
if __name__ == "__main__":# 示例数据:4个文档,每个文档的评分和标签scores = torch.tensor([[2.0], [1.5], [3.0], [0.8]], dtype=torch.float32)labels = torch.tensor([[3], [2], [4], [1]], dtype=torch.float32) # 标签越高表示相关度越高# 创建损失函数实例criterion = LambdaRankLoss(metric='ndcg')# 计算损失loss = criterion(scores, labels)print(f"LambdaRank Loss: {loss.item():.4f}") # 输出示例: 某个损失值优缺点分析与适用场景
优点:
- 直接优化指标:直接优化信息检索指标(如 NDCG),而非替代损失函数,这有助于提高模型在目标指标上的性能。
- 梯度调整:通过引入指标的梯度信息,LambdaRank 能够更有效地优化排序结果。
- 鲁棒性:对相关度标签的噪声具有一定的鲁棒性,因为它关注的是相对顺序而非绝对分数。
- 可扩展性:可以与各种排序指标结合,适应不同的应用需求。
缺点:
- 梯度不一致性:LambdaRank 的梯度可能存在不一致性,即一个高相关度文档可能获得比低相关度文档更小的梯度推动,这可能影响模型性能。
- 计算复杂度高:需要计算所有文档对的 delta 值,时间复杂度为 O (n^2),对于大规模数据集可能不适用。
- 实现难度大:需要针对每个目标指标实现复杂的 delta 计算,这增加了实现的难度。
- 超参数敏感性:对学习率和其他超参数较为敏感,需要仔细调优。
适用场景:
- 信息检索系统:如搜索引擎、文档检索等需要优化特定排序指标的场景。
- 推荐系统:对推荐结果进行排序,以优化用户体验指标。
- 广告排序:对广告进行排序,以最大化点击率或其他商业指标。
- 学术搜索:对学术论文进行排序,以优化相关度指标。
- 任何需要优化特定排序指标的场景:如基于用户反馈的排序优化。
在实际应用中,LambdaRank 是学习排序领域的重要方法,尤其在需要直接优化信息检索指标的场景中表现出色。尽管其实现复杂且计算量大,但在许多排序任务中,它仍然是最有效的方法之一。
损失函数对比与选择指南
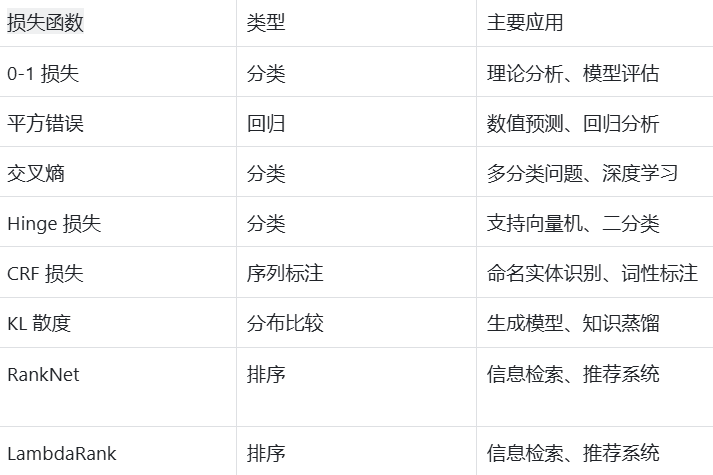
损失函数比较
下表对本文讨论的八种损失函数进行了全面比较:
选择指南
根据不同的任务类型和数据特点,以下是损失函数的选择建议:
回归任务:
- 数据噪声较小且分布均匀:选择均方误差(MSE)损失,其良好的数学性质和梯度特性使其成为回归问题的标准选择。
- 数据存在显著异常值:考虑使用平均绝对误差(MAE)或 Huber 损失,这些损失函数对异常值更鲁棒。
- 需要平衡异常值影响:使用 Huber 损失,它结合了 MSE 和 MAE 的优点,在误差较小时使用平方损失,误差较大时使用线性损失。
- 需要概率预测:可以使用高斯负对数似然损失,输出预测的均值和方差。
分类任务:
- 多分类问题:首选交叉熵损失,尤其是在使用深度学习模型时,其与 Softmax 函数的结合提供了良好的训练性能。
- 二分类问题:可以选择二元交叉熵损失或 Hinge 损失,后者在支持向量机中表现出色。
- 类别不平衡数据:使用加权交叉熵损失或焦点损失(Focal Loss),调整不同类别的权重。
- 需要最大化分类边际:选择 Hinge 损失,如在支持向量机中,它能够最大化分类边际。
- 需要概率输出:选择交叉熵损失,因为它可以自然地输出概率分布。
序列标注任务:
- 需要捕捉序列依赖:选择 CRF 损失,它能够建模序列中的长距离依赖关系。
- 简单序列标注:可以使用独立的交叉熵损失,但效果通常不如 CRF。
- 需要全局最优解:CRF 损失提供了全局最优的标签分配,而不是局部最优。
排序任务:
- 成对比较排序:选择 RankNet 损失,它基于成对比较,适合处理排序问题。
- 需要优化特定排序指标:选择 LambdaRank 损失,它直接优化信息检索指标,如 NDCG。
- 大规模数据排序:考虑更高效的近似方法,如 ListNet 或 ListMLE,以减少计算复杂度。
- 基于点击反馈的排序:可以使用 LambdaLoss 或其他基于梯度的排序损失。
分布比较任务:
- 生成模型:选择 KL 散度损失,如在变分自编码器(VAE)中。
- 知识蒸馏:使用 KL 散度损失,将教师模型的知识传递给学生模型。
- 分布匹配:可以使用 KL 散度或其他分布距离度量,如 JS 散度或 Wasserstein 距离。
- 异常检测:使用 KL 散度衡量正常分布与异常分布的差异。
实际应用中的选择建议
在实际应用中,选择损失函数应考虑以下因素:
- 任务类型:回归、分类、序列标注、排序等不同任务需要不同的损失函数。
- 数据特性:数据是否存在异常值、类别是否平衡、是否有序列结构等。
- 模型类型:不同的模型结构可能需要特定的损失函数,如循环神经网络适合序列损失。
- 计算资源:某些损失函数(如 CRF、LambdaRank)计算复杂度较高,需要考虑计算资源限制。
- 优化目标:是否需要优化特定指标(如 NDCG),或者是否需要概率输出。
- 领域知识:某些领域可能有标准的损失函数选择,如信息检索中的排序损失。
- 可解释性需求:某些损失函数(如 0-1 损失)更易于解释,而其他函数(如交叉熵)提供了更丰富的信息。
实用建议:
- 默认选择:对于大多数分类问题,交叉熵损失是默认选择;对于回归问题,均方误差是默认选择。
- 异常值处理:如果数据中存在显著异常值,考虑使用更鲁棒的损失函数变体。
- 计算效率:在资源有限的情况下,优先选择计算复杂度较低的损失函数。
- 组合使用:在某些情况下,可以组合多个损失函数以获得更好的性能,如结合交叉熵和 KL 散度。
- 验证与比较:在实际项目中,建议尝试多种损失函数,并通过验证集比较它们的性能。
- 关注最新进展:损失函数的研究不断发展,关注最新的研究成果,如自适应损失函数、混合损失函数等。