从零开始搭建深度学习大厦系列-4.Transformer生成式大语言模型
最近在学习文本预处理(分词与词和位置嵌入)、自注意力机制(Self-Attention)、多头自注意力机制、Transformer Block和GPT-2、GPT-3的基本架构。
本文是相关内容的第一篇文章,主要讲解大模型的基础架构和代码构建过程;后续文章将着重讲解大模型的预训练、指令微调、奖励模型构建和强化学习(RLHF)过程。
相关源代码完全可运行,并按照构建分步-代码分块的流程设计,完整代码已经上传个人空间,可以免费下载调试,代码运行环境为配备了Python 3.10虚拟环境的Trae CN(字节跳动开发的国内AI代码编写助手)。
说明:
(1)在本文的讲解和分析过程中,只会贴出关键的代码部分;
(2)对于代码实现部分的很多细节,如有疑问或见解可以直接在评论区讨论。
目录
一、文本预处理
1.1 分词与词嵌入
1.2 位置嵌入
1.3 滑动窗口(对于训练和推理都尤为重要)
1.4 大语言模型(GPT为例)的输入与输出
二、自注意力机制
三、多头自注意力机制
四、Transformer Block基本架构
LayerNorm层规范化模块
Masked multi-head attention多头注意力模块
(内嵌在nn.MultiheadAttention类内)Dropout随机丢弃模块(防止深层大模型网络在较小的数据集上过拟合overfitting)
Residual Block模块
FF前馈神经网络模块
五、GPT-2基本架构与可训练参数估计
六、“傻瓜”大模型推理展示
一、文本预处理
文本预处理是把语句拆分成词,而后把词的语义空间唯一映射到数学表达的向量空间的过程(附:在线性代数中,即同时满足单射和满射),总体包括分词和词(位置)嵌入两步。
1.1 分词与词嵌入
英文分词可以使用Re内置库,通过正则表达式对输入语句字符串进行过滤,因此词与词之间必须要有空格作为划分;中文分词可以使用第三方jieba库,输入语句不需要有空格也符合中文语句书写习惯。

图 1 使用re库进行英文分词

图 2 使用jieba库进行中文分词
分词之后进行一个空间映射,注意这个映射关系是可以进行训练的,但是训练周期比较长,现在工程一般延用训练好的大模型的嵌入数据,如果是体验流程不追求优质效果可以使用torch.randn()进行0-1随机高斯初始化。
词嵌入矩阵的行数对应词汇表的容量,GPT-2词汇表大小50257;列数对应词嵌入向量维度。
更好、更集成统一的选择是使用GPT-2的Bytes-Pair Encoding(BPE)库,这个库除了使用映射固定的标准的分词机制外,还可以针对不在GPT-2 50257个单词构成的词库中的单词进行进一步可能的拆分,当然更简单粗暴的解决方案是设置一个类似<|endoftext|>的标识符比如<|unknown|>。

![]()
![]()
比如输入的sunlit(阳光明媚的)、terrace(梯田)、someunknownPlace(未知地点)并不在
词库中,BPE进行词语拆分之后得到sun、lit、terr、aces、some、unknown、Place。英文逗号对应的索引是11。
后面也会说到的nn.Embedding网络层设置参数里的padding_idx对应一个固定位置索引,这个索引可能一般在词库的0索引位置,训练的时候不会进行参数更新,相当于空占位字符。
1.2 位置嵌入
类似词嵌入,可以使用torch.randn()进行位置嵌入矩阵的随机初始化。同样可以被训练,矩阵的行数对应输入文本的令牌数或者词数,列数对应词嵌入的维度数,GPT2-small嵌入维度768维,本实验使用3维向量作为示例。

1.3 滑动窗口(对于训练和推理都尤为重要)
滑动窗口的设置直接决定大模型训练和推理的输入与输出关系。使用typing库进行类型约束,默认步长为1,也就是输出是输入整体右移一个单词之后在全局文本中的视野。

1.4 大语言模型(GPT为例)的输入与输出
在GPT的实现中,一般使用(B,T,V)表示输入的嵌入后向量尺寸,(B,T,D)表示输出的概率张量。B代表批量大小,T代表批量中最长的样本对应的词语数量(其他padding补齐),D代表词嵌入维度,V代表词汇表大小。
在经过文本预处理-丢弃层-N x Transformer Block-Final LayerNorm之后,数据尺寸仍然是(B,T,V),此时需要通过一个FC全连接层加上softmax处理得到(B,T,D)的概率预测矩阵。
二、自注意力机制
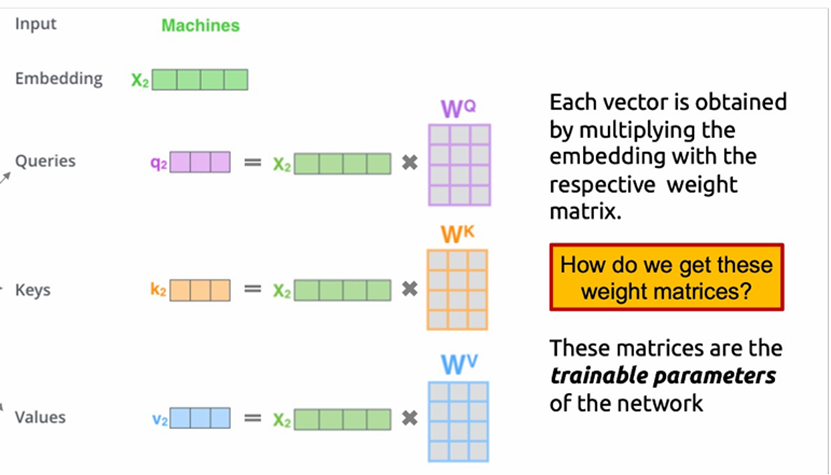
(单头)自注意力是Transformer Block的核心结构中的核心,关键就是Q、K、V——查询向量、键向量、值向量。通过Wq、Wk、Wv三个对应的矩阵和词嵌入向量做矩阵乘法(权重矩阵在右),得到同维度的向量,为了问题描述的简便性,这里假设批量维度B=1并不考虑这一维度;因此三维张量当作二维矩阵考虑。 对于这个输入矩阵的任意两两行向量(i,j)(对应每一个单词,T维度),QiKjT乘法后除以词嵌入维度的0.5次方(防止基于softmax函数特性的梯度消失现象,据说乘法结果的分布方差统计属性和词嵌入维度基本上是正相关的关系)得到查询结果,经过因果对角矩阵的掩膜和随机丢弃的掩膜处理(图4图5),再通过一层softmax转换为0-1的注意力分数。不难发现注意力分数矩阵的尺寸是(B,T,T)。注意力分数越高,代表两个词的语义关联性越强。

图 3 注意力分数的可视化
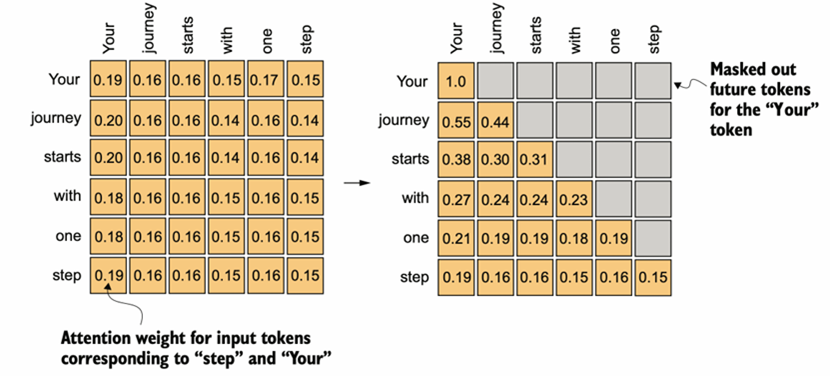
图 4 因果下三角矩阵掩膜处理,每个词语根据“实际语境”只和前面的文本有语义关系(Decoder-Only),BERT大模型是另一种思路(Encoder-Only)
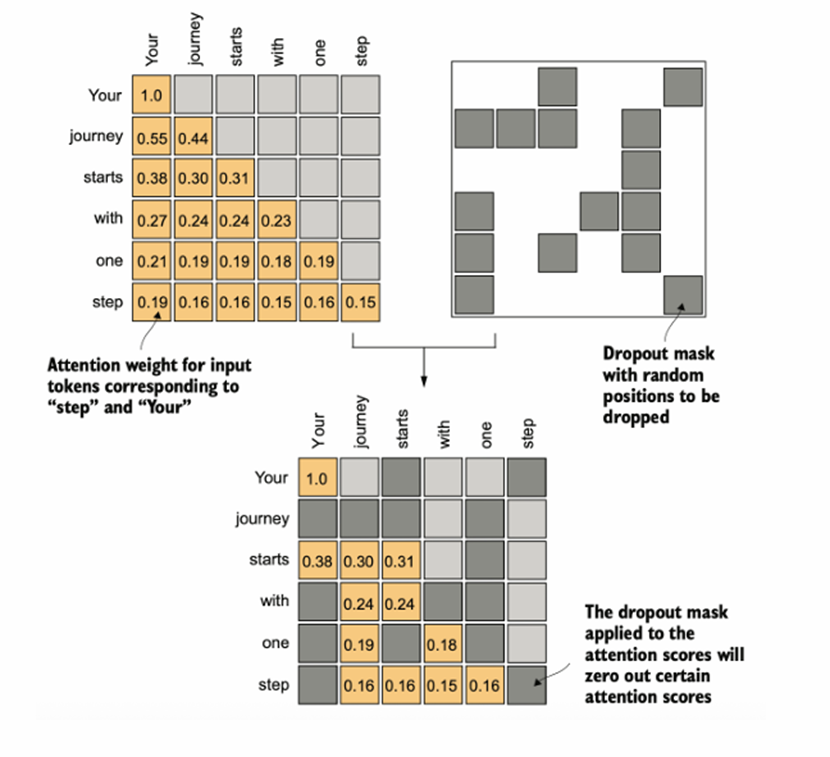
图 5 随机全局丢弃层处理
此时就只有V-值向量没有被使用,和值向量构成的矩阵(T,V)对批量中的每一个样本做乘法,得到(B,T,V)的输出。
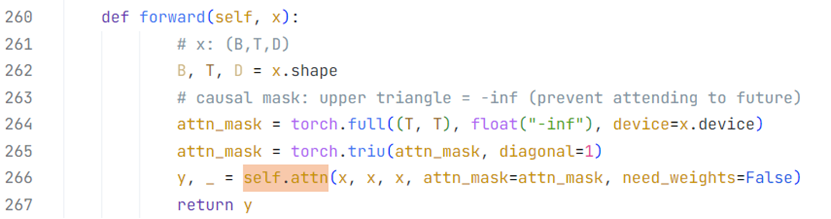
说明:在代码实现过程中,torch.nn库也提供了MultiheadAttention网络模块,前向计算指定need_weights参数为False可以不返回注意力分数矩阵,减少内存开销。
三、多头自注意力机制
在自注意力机制的基础上,通过设置多个独立的自注意头,对应关注不同的语义空间,我的理解是有点类似现实中看待问题的不同角度,有的可能更关注客观理性,有的则可能关注感性和情绪;具体的权重动态占比下文会简略说明,学习到的结果主要就看数据集的性质,如果你给这个大模型喂的数据都是科研大佬或者理工男写的文章,那么总体来说这个大模型的输出就会比较理性,“理性语义空间”的注意头更胜一筹;反之亦然,但并没有绝对的好坏之分。
然而具体需要的头数和指代的语义空间并不明晰,这也是深度学习和神经网络被称为“黑匣子科学”的原因之一,不具备较强的可解释性。
多头自注意力的实现方式包括通过时间延长和循环的单头注意力叠加、多个注意头的并行计算(具体实现可能用到四维张量和torch.matmul并制定乘法运算的维度),一般使用后者,因为在GPU上训练和推理可以大大提升速度。
这里有一个很关键的机制——多头注意力融合,N头注意力按照单头注意力的流程之后理论上可以得到N个Attention矩阵的输出,即(N,B,T,T),通过一个(N,T,T)多头融合矩阵右乘运算得到(B,T,T)的Mixed Attention矩阵,后续步骤一致。
多头融合矩阵同样可以进行参数更新和训练。
四、Transformer Block基本架构
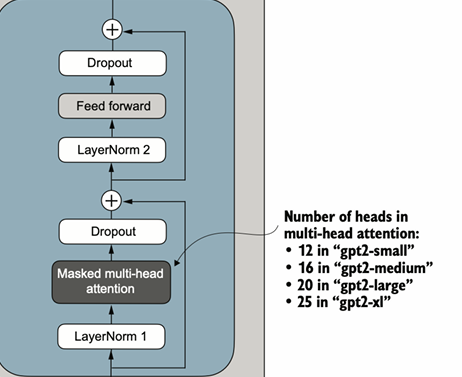
图 6 Transformer Block组成成分
一图以蔽之,所谓的Transformer Block主要有借鉴自何恺明等AI先辈提出的ResNet的Residual Block模块、随机丢弃模块、因果多头自注意力模块、FF前馈模块、LayerNorm层规范化模块这5大板块,只需要按顺序实现即可构建出完整的Transformer Block。
LayerNorm层规范化模块
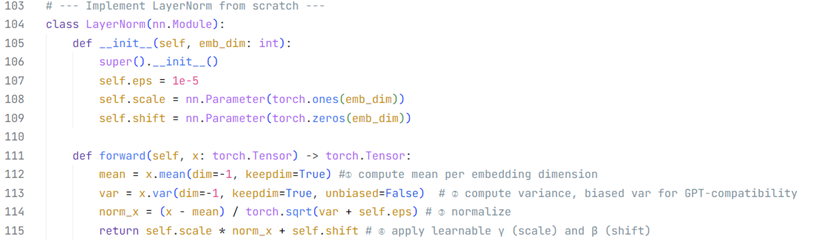
LayerNorm规范的是(B,T,V)中的最后一个维度——词嵌入维度。
Masked multi-head attention多头注意力模块
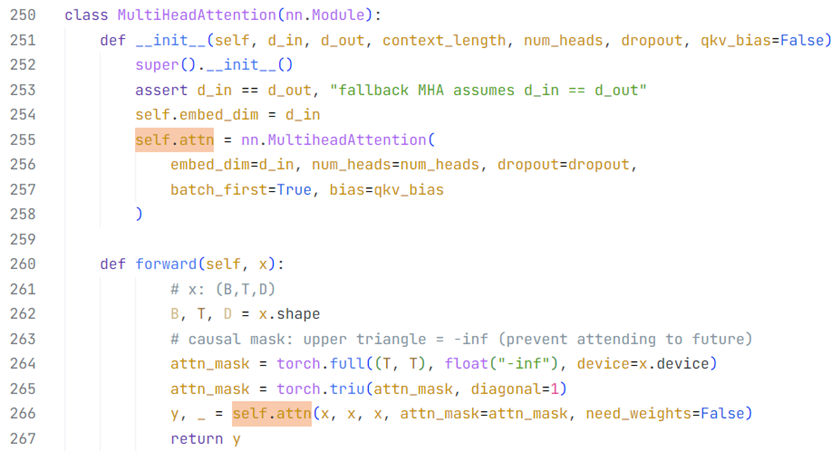
(内嵌在nn.MultiheadAttention类内)Dropout随机丢弃模块(防止深层大模型网络在较小的数据集上过拟合overfitting)

上图是手编实现的多头注意力模块的前向计算(函数重载);注意是在softmax处理之后使用,选定位置的注意力分数置0,其余位置分数不做更改,总注意力分数的范数减小,因此不容易过拟合(不代表一定不会)。
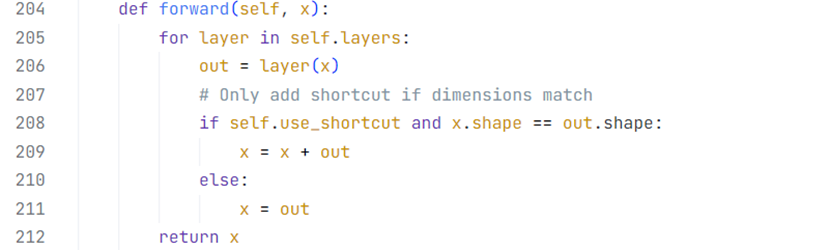
Residual Block模块

FF前馈神经网络模块
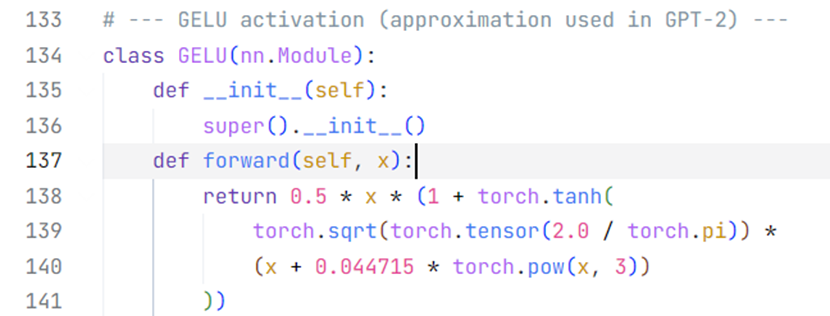

在GPT-2的架构中,使用GELU函数作为激活函数,只有一层隐藏层,4倍于输入层的节点数量。
五、GPT-2基本架构与可训练参数估计
在前四部分的基础上,堆叠N个Transformer Block并和头尾(见1.4标蓝字体)连接起来,就得到了GPT-2的雏形,四个版本的GPT-2乃至GPT-3大体架构完全一致,变数只有3个:Transformer Block的堆叠个数、多头自注意力里注意力头的个数、词嵌入向量的维度。
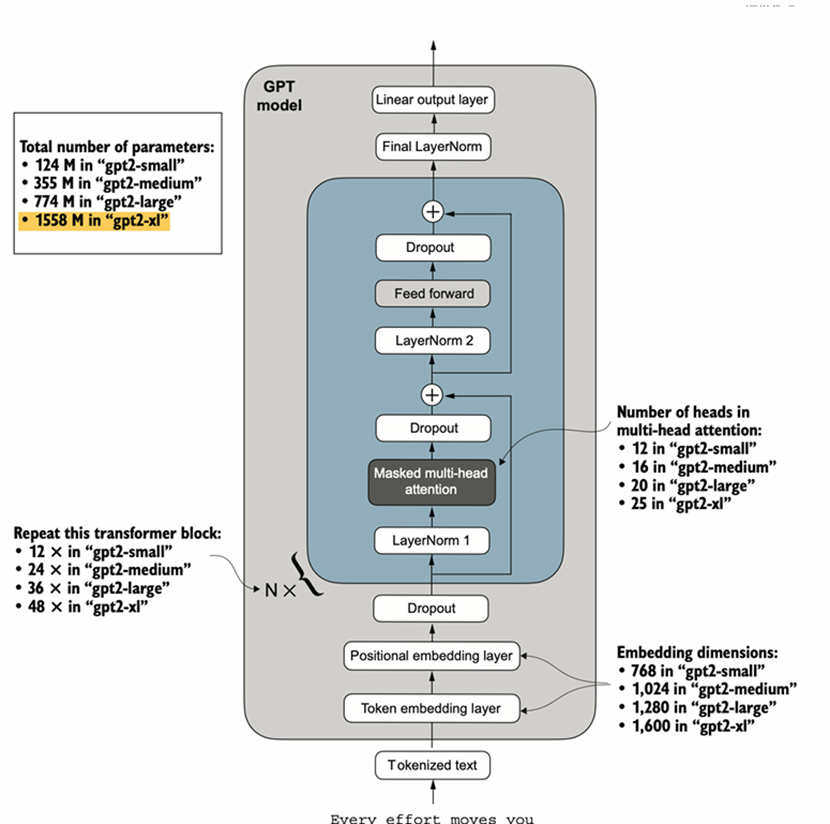
图 7 GPT-2大模型网络架构和参数统计

本地代码搭建并运行GPT2-small,模型大小621.80兆字节,如果考虑最终FC层和输入词嵌入矩阵(词汇表矩阵)的参数绑定(实际操作中如此,互为矩阵转置关系而非矩阵乘法结果为单位矩阵),模型大小大概496兆字节。
六、“傻瓜”大模型推理展示
在没有经过任何训练的情况下,大模型的输出毫无章法。

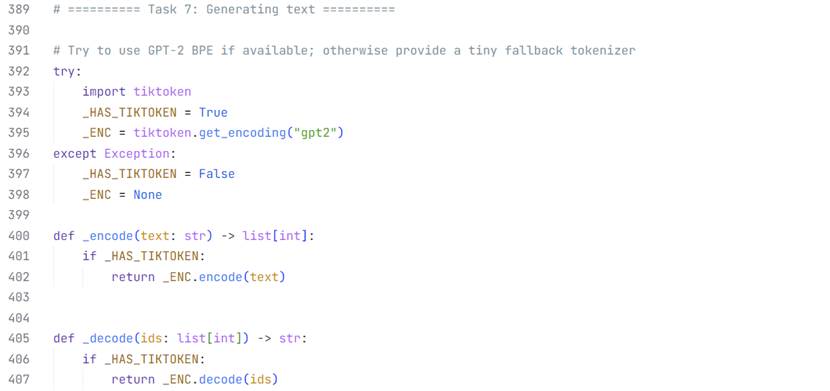
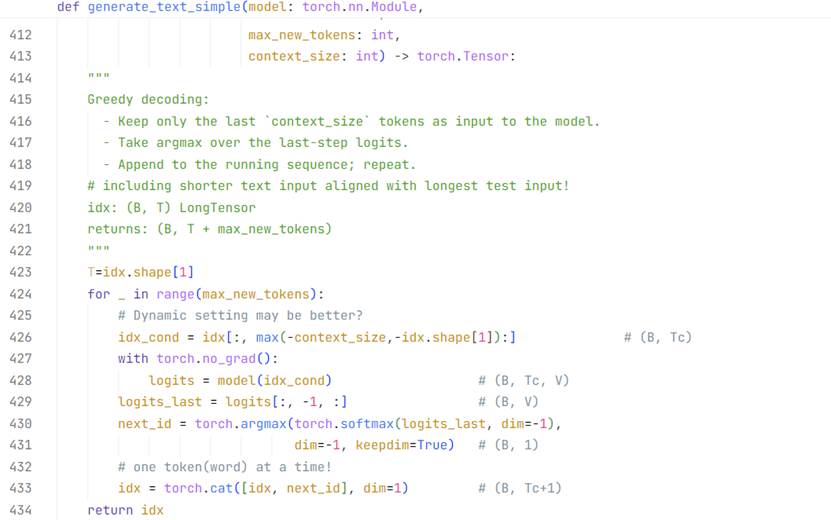
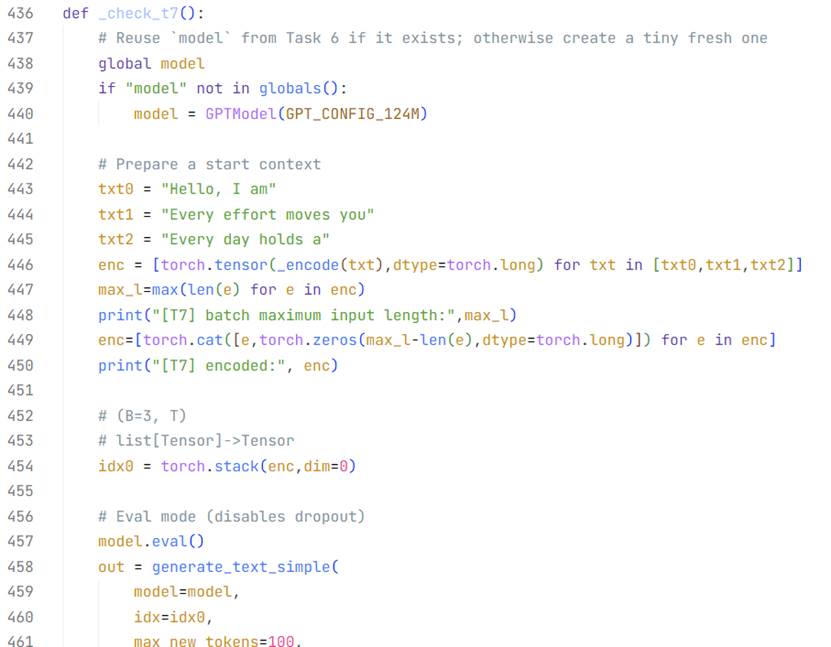
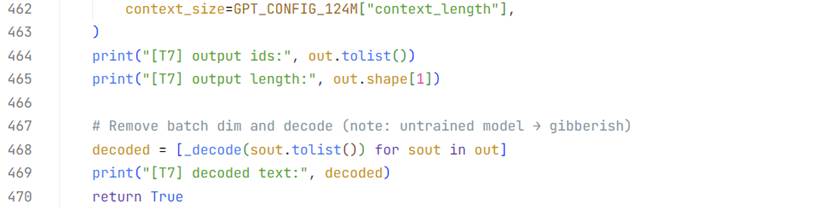
在最后的FC全连接层处理得到(B,T,D)的词汇概率预测矩阵之后,
对于D维度:top-k等参数决定的是从概率最高的前k个词汇里面随机选择一个词汇作为输出,显然k越大输出越灵活多样但也越容易忽略用户的细节需求,最终此维度降为1;
对于维度T:最终只能从里面选取最后一个加入到输出中,也就是(B,T)的输入文本拼接一个(B,1)的单次推理输出。
推理迭代的步骤参考1.3滑动窗口部分的讲解。
笔者人工制作了(3,4)(B,T)的输入文本批量,让未经训练的“傻瓜”大模型生成100个新词,也就是得到(3,104)的输出,推理前后效果如下:


是不是真的很“傻瓜”?不过不要小看眼前这个大模型,它学习起来效率不低,只需要一些高算力的GPU和优质且完备的数据集,在几个月的时间里就可以掌握超越99%的人类掌握的正确的有价值的知识!