20250925问答课题-多标签分类模型
1.(简略)调查关键词手工标注后,如何通过模型自动识别,提升关键词的生成效果;
2. 多标签引入:
a.考虑不是一个问题多行的方式,改成cvs文件中一行,用逗号等特殊符号隔开;
b.考虑多标记问题的模型训练,调研基准模版、深度学习模型,做个报告。
1. 关键词
pointer-generator network:是一种融合了 seq2seq 和 pointer network 的神经网络模型,主要用于文本摘要任务。它可以通过指针机制从源文本中复制单词,同时保留生成新单词的能力,是一种生成式方法。pointer-generator network 可以看作是抽取式和生成式方法的平衡。
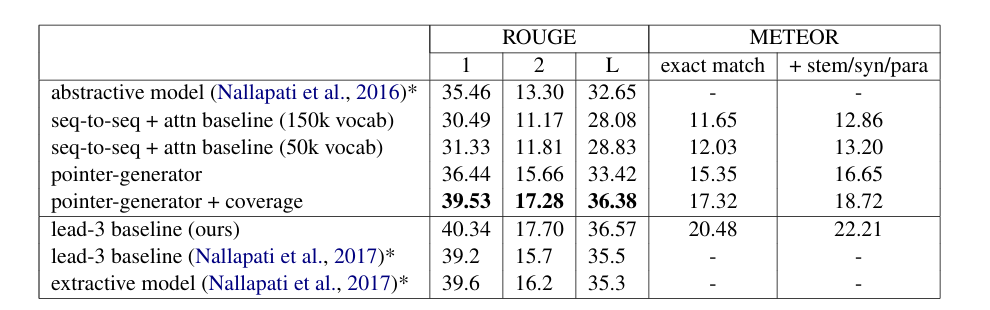
上面的是生成式方式,下面的是抽取式方法。本文提出的方法pointer - generator + coverage表现不如抽取式lead-3的方法
- lead-3方法:从源文里面的前三个句子中抽取重要信息,然后拼接成摘。
作者提出两个解释,解释一,重要的信息通常在文章的开头。解释二,是文本摘要生成这个任务本质决定的,像文本摘要生成这种任务,天然就比较偏向于从源文摘取信息,所以从得分的表现来说,生成式的不如摘取式的。
参考论文:Get To The Point: Summarization with Pointer-Generator Networks
2017.04
2. 多标签引入
a. cvs文件格式
使用“,”分隔问题、答案、标签组合三列
使用“;”分隔不同的标签组
问题,答案,标签组合
道家的思想是什么?,道家的思想。,修行/道家;道理/人生
b. 多标记问题的模型--HiAGM
Hierarchical Attention Graph Network,分层注意力图网络
参考论文:Hierarchy-Aware Global Model for Hierarchical Text Classification
在这篇论文中,将层次结构表述为一个有向图,并利用标签依赖的先验概率来聚合节点信息 —— 一个层次感知全局模型HiAGM——通过标签结构特征增强文本信息。
该模型的整体结构如下图所示:
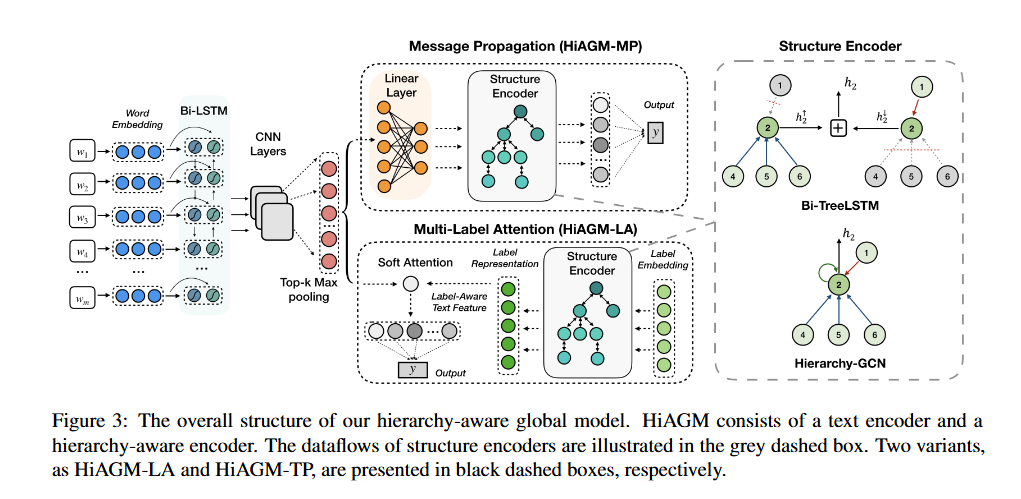
结构编码器的数据流在灰色虚线框中展示
两种变体
HiAGM-LA和HiAGM-TP分别以黑色虚线框呈现
- 给定一个文档序列
x = (w1, w2, . .),使用一个双向GRU层对该序列的token embedding提取文本上下文特征,再经过多个CNN提取n元特征,经过最大池化层过滤提取关键信息。最后通过reshape得到一个连续的文本表征S = (s, . . . , s)。
ⅰ. 先验层次信息
HiAGM利用关于预先定义的层次结构和语料库中标签相关性的先验知识,将标签之间依赖关系的先验概率作为先验层次结构信息,如下图所示:
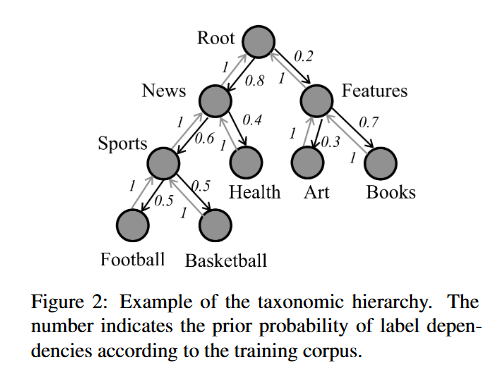
节点Uj是节点Ui的子节点,则节点之间的先验概率计算公式如下,即父节点到子节点的先验概率为在先验知识中,父节点发生的情况下子节点出现的概率。相应地,子节点到其父节点的概率为子节点发生的情况下其父节点出现的概率,很明显每个子节点到其父节点的概率都为1。
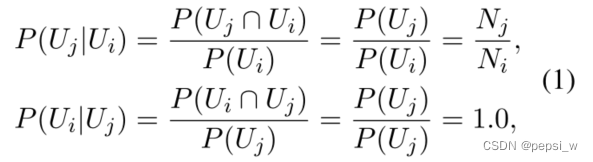
ⅱ. 结构编码器(Structure Encoder)
基于不同的结构编码器来对细粒度的层次信息进行建模,本文中使用两个structure encoder:Bidirectional Tree-LSTM和Hierarchy-GCN。
1. Bidirectional Tree-LSTM
在该结构编码器中,节点更新公式如下,其中hĸ和cĸ分别表示节点k的隐藏状态和记忆元状态:
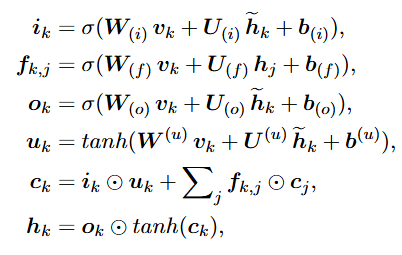
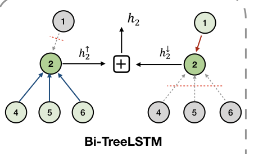
为了得到标签的相关性,HiAGM采用了一个双向的Tree-LSTM
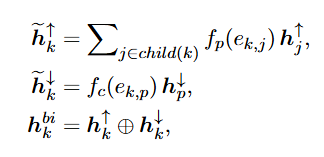
a. LSTM
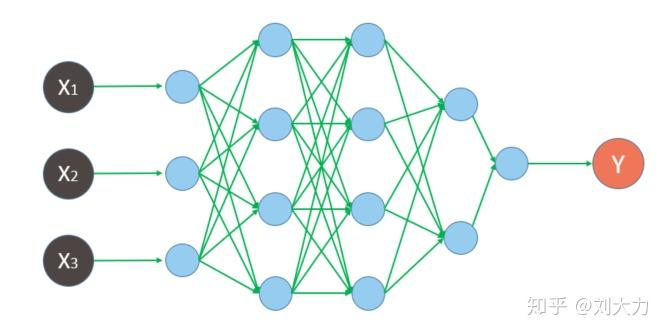
RNN
- 引入时间概念——
t称为时间步time_step,每个t称为1步,t1-t5为1个周期 - 引入记忆概念——把上一个时间步产生的结果(
Yt-1)同X一起输入进去 - 在反复的
tanh变换和矩阵乘法中,当序列很长时,梯度(用于更新网络权重的信号)在反向传播时会变得非常小(梯度消失)或非常大(梯度爆炸)——传话游戏
LSTM
- 在
RNN基础上引入一个名为 “细胞状态” 的新结构和三个“门”来完美解决长期依赖问题
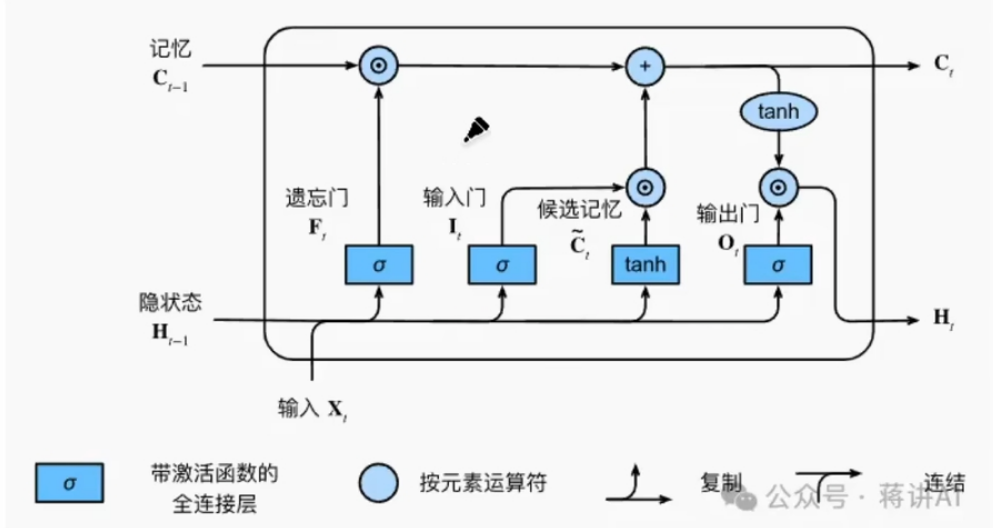
输入门input Gate、遗忘门forget Gate、输出门output Gate分别计算如下:
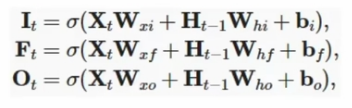
- 查看
ht−1和xt,为细胞状态Ct−1中的每一个维度产生一个信号。接近0意味着“忘记这个信息”,接近1意味着“保留这个信息”
在记忆元“转正”之前,要先成为候选记忆元,它的计算与使用tanh作为激活函数,计算如下
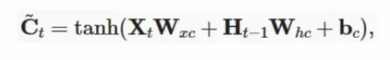
真正的记忆元Ct,它由两个门来控制,输入门决定有多少信息来自候选记忆元,遗忘门决定有多少信息来自过去的记忆元Ct-1,它们本质上都是向量,各自使用按元素乘法
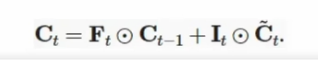
- 遗忘:将旧的细胞状态
Ct−1乘以遗忘门的输出ft,故意忘记一些东西。 - 添加:加上输入门的输出
iti乘以候选值C~t,添加新的信息。
- 得到了新的、更新后的长期记忆
Ct,使得梯度在反向传播时更容易流动,避免了梯度消失、溢出。
b. Bi-LSTM
结合了双向模型和LSTM的门控机制,由2个独立的LSTM网络构成。当Bi-LSTM处理序列数据时,输入序列会分别以正序和逆序输入到2个LSTM网络中进行特征提取,并将2个输出向量(提取后的特征向量)拼接后形成的输出向量作为该时间步的最终输出
设计理念是使t时刻所获得特征数据同时拥有过去和将来之间的信息;Bi-LSTM中的2个LSTM网络参数是相互独立的,它们只共享同一批序列数据。
2. Hierarchy-GCN
使用一个简单的层次GCN来获得细粒度层次结构信息,如图所示:
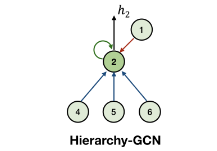
GCN汇集从上到下、从下到上和自循环这三个边数数据流。
ⅲ. HiAGM-LA
Hierarchy-Aware Multi-Label Attention是HiAGM基于多标签注意力的一个变种。标签表征通过双向层次信息得到增强,这种局部的结构信息使得能在一个模型中学习不同层次的标签特征。
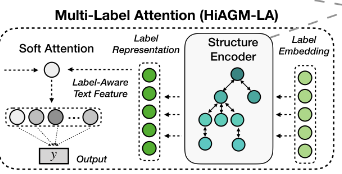
节点k的label embedding进行随机初始化为Lk,然后作为结构编码器的输入,输出的隐藏状态h代表层次敏感的标签特征。对于文本表征S,Hi-AGM使用以下公式计算其标签注意力值。
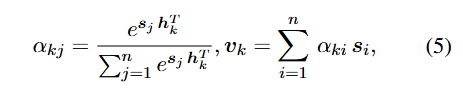
其中ɑĸi表示第i个文本特征向量对第k个标签的相关性,基于多标签注意力,就能得到与标签对齐的文本特征V,将该文本特征用于预测;也可以直接使用结构编码器的隐藏状态作为预训练的标签表征,更轻量级。
ⅳ. HiAGM-TP
Hierarchical text feature propagation第二个变体(HiAGM-TP)基于演绎法获得获得label-wise的文本特征,主要进行文本特征的传播。直接将文本特征S作为节点输入,并通过结构编码器对文本信息进行更新。
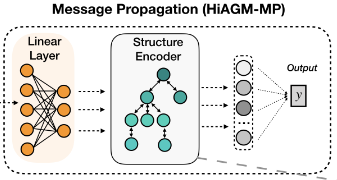
节点输入V由文本特征S通过一个线性变换得到,在给定的结构下,每个样本在同一个整体的分类层次中更新它的文本信息。一个小批量中,将初始节点表征V送到结构编码器中,输出的隐藏状态h表示层次敏感的文本特征,作为分类器的最终输入。
和HiAGM-LA相比,该变体的转换是在文本信息上进行的,没有进行标签embedding的融合。结构编码器在训练和推理阶段都会被激活,以便在层次结构中传递文本信息。该变体更容易收敛,但复杂度略高。
ⅴ. 实验
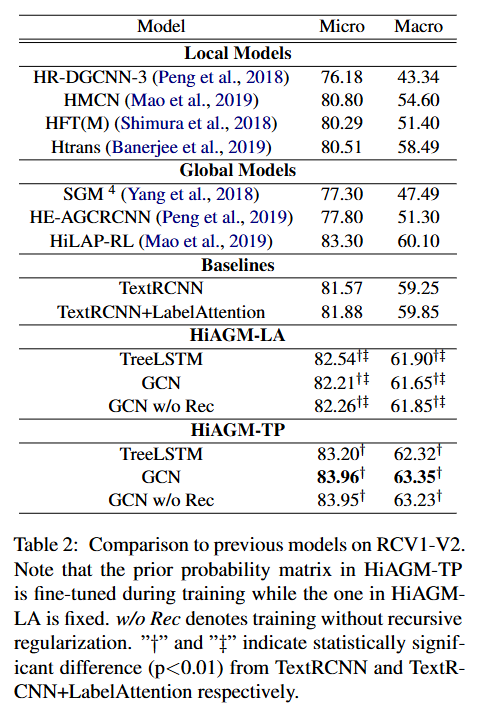
将该模型与之前的模型进行比较,实验结果如下:
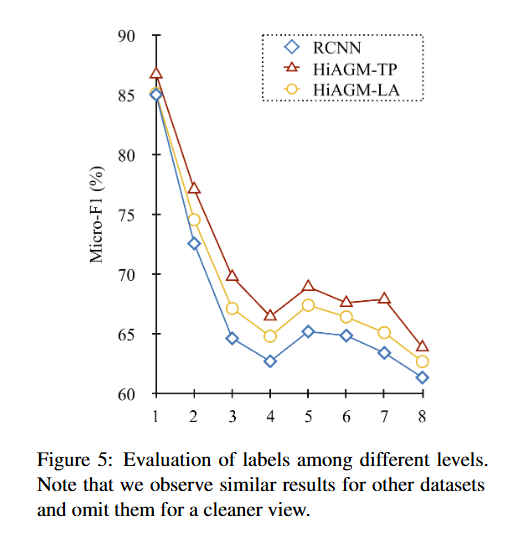
对不同层标签的划分结果进行实验,HiAGM-LA 、 HiAGM-TP 的 MicroF1 分数比baseline的表现更好,尤其是在较深的级别中。
MicroF1分数是一种多分类任务中的综合评价指标,体现所有类别样本的总体精确率(Precision)和召回率(Recall)
3. 总结
重新理顺系统逻辑结构,主要侧重于查找学习多标记问题的模型,调研了一些基准模版、深度学习模型,接着搜索到了HiAGM模型并发表阅读论文,认为他的变种模型HiAGM-TP比较适合当前的多层次多标签的系统。在完成多标记问题后,开始搜索关键词的识别模型,了解到原先使用的TextRank为抽取式方法,如果要生成三级标签可能需要生成的能力,经查找找到了pointer - generator + coverage的相关论文,但发表时间为2017,接下来需要查找更新的模型。