麒麟 Linux|深入解析 Linux 文件系统架构:理念、结构与工作机制
Linux 文件系统,是这套操作系统的“地基”和“血脉”。
与 Windows 的“C/D/E 盘”不同,Linux 坚持 单一树形结构 + 挂载机制的设计哲学,把本地磁盘、U 盘、网络存储、甚至虚拟设备都统一在一棵目录树下。
这种架构不仅简洁优雅,还让 文件访问、硬件交互、系统配置 全部走一套通用接口,真正体现了“一切皆文件”的思想。
本文将带你从理念入手,逐层拆解 Linux 文件系统的核心逻辑:三大设计原则、标准目录层级、文件类型分类、底层工作机制,并结合实操命令帮助你理解。
无论你是开发者、运维人员,还是 Linux 学习者,这份解析都能成为你的系统级参考指南。
01
Linux 文件系统的核心设计理念
Linux 继承了 Unix 的文件系统哲学,其架构设计遵循三大核心原则,这些原则是理解后续层级结构的基础:
1) 一切皆文件(Everything is a File)
这是 Linux 最经典的设计理念之一。
在 Linux 中,不仅普通文档、图片是文件,硬件设备(如硬盘、鼠标、打印机)、进程间通信接口(如管道、socket)、甚至目录本身,都被抽象为 “文件” 。
这种统一的抽象模型,让操作系统可以用一套相同的接口(如 open()、read()、write()、close() 等系统调用)处理所有资源,极大简化了底层逻辑与上层应用开发。
例如:
硬盘分区对应 /dev/sda1、/dev/nvme0n1p2 等 “设备文件”;
内存信息通过 /proc/meminfo 这一 “伪文件” 暴露给用户;
打印机设备对应 /dev/lp0 等 “字符设备文件”。
2)单一树形目录结构(Single Tree Hierarchy)
与 Windows 中 “C 盘、D 盘、E 盘” 的多根目录不同,Linux 只有一个根目录 \(正斜杠),所有存储设备(本地硬盘、U 盘、网络共享盘)都需通过 “挂载”(Mount)方式,关联到根目录下的某个子目录(如 /mnt/usb、/media/share),最终形成一个完整的、无分支的树形结构。
这种设计的优势在于:
资源路径统一:任何文件的路径都从根目录出发(如 /home/user/docs/report.pdf),无需区分 “盘符”;
跨设备访问透明:用户访问 /mnt/usb/photo.jpg 时,无需关心该文件实际存储在 U 盘中,操作系统会自动处理设备切换。
3)挂载机制(Mounting)
“挂载” 是 Linux 整合不同存储设备的核心手段。
本质上,它是将一个文件系统(如 U 盘的 FAT32、硬盘分区的 Ext4)与根目录下的某个 “挂载点”(Mount Point,即一个空目录)建立关联的过程。
挂载后,访问挂载点目录就等同于访问该设备的文件系统。
例如:
将 U 盘(设备文件 /dev/sdb1)挂载到 /mnt/usb 后,ls /mnt/usb 会显示 U 盘中的所有文件;
卸载(Umount)时,需先确保没有进程正在访问该挂载点,否则会提示 “设备忙”。
02
Linux 文件系统的层级结构与
关键目录功能
Linux 基金会通过 Filesystem Hierarchy Standard(FHS,文件系统层级标准) 规范了根目录下各子目录的功能,确保不同 Linux 发行版(如 Ubuntu、CentOS、Debian)的目录结构一致,提升兼容性。
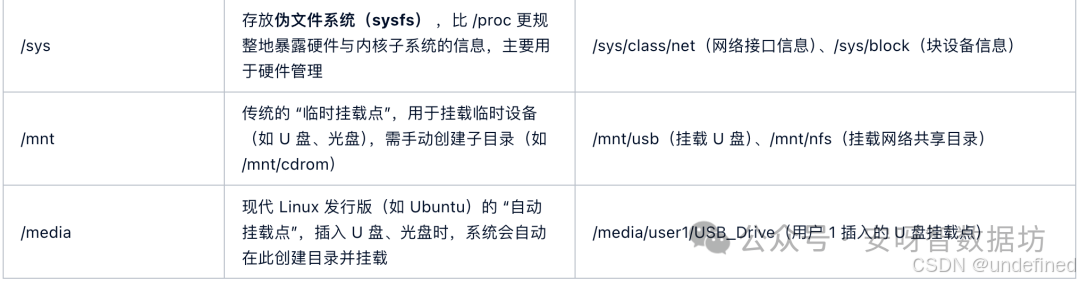
以下是根麒麟LINUX目录下核心目录的功能解析:

03
Linux 文件的类型分类
在 Linux 中,“文件” 并非仅指普通文档,而是根据功能分为多种类型,通过 ls -l 命令可查看文件类型(输出结果的第一个字符代表类型):
1)普通文件(-,Regular File)
最常见的文件类型,用于存储文本、二进制数据、图片、视频等。
例如:
文本文件:/etc/passwd、/home/user/note.txt;
二进制文件:/bin/ls(可执行命令)、/usr/bin/chrome(应用程序);
压缩文件:archive.tar.gz、image.zip。
验证命令:
file [文件路径]:显示文件的具体格式(如文本、ELF 二进制、压缩包);
stat [文件路径]:输出中 File type 字段明确标记为 regular file,且有完整的大小、修改时间等属性。
实操示例:
1. 验证文本文件(/etc/passwd)
$ file /etc/passwd
/etc/passwd: ASCII text # 明确为ASCII文本文件$ stat /etc/passwdFile: /etc/passwdSize: 2655 Blocks: 8 IO Block: 4096 regular file # File type 为 regular file
Device: 801h/2049d Inode: 131074 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2025-08-28 09:15:32.456789000 +0800
Modify: 2025-08-27 16:30:12.123456000 +0800
Change: 2025-08-27 16:30:12.123456000 +0800Birth: -2. 验证二进制文件(/bin/ls)
$ file /bin/ls
/bin/ls: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked # 明确为ELF可执行二进制
$ stat /bin/lsFile: /bin/lsSize: 143696 Blocks: 288 IO Block: 4096 regular file # 仍为 regular file
Device: 801h/2049d Inode: 131102 Links: 1
Access: (0755/-rwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)2)目录文件(d,Directory)
用于存储其他文件或子目录的 “容器”,本质是记录文件名与对应 inode 编号的列表。
例如/home、/etc 均为目录文件,ls -l 输出的第一个字符为 d。
验证命令:
file [目录路径]:直接标记为 directory;
stat [目录路径]:File type 字段为 directory,且 Links 数通常大于 2(目录默认包含 . 和 .. 两个隐藏链接)。
实操示例:
# 验证 /home 目录
$ file /home
/home: directory # 直接识别为目录$ stat /homeFile: /homeSize: 4096 Blocks: 8 IO Block: 4096 directory # File type 为 directory
Device: 801h/2049d Inode: 131072 Links: 3 # Links=3(包含 .、.. 和 1 个子目录)
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)# 注:目录的权限位第一位为 d(如 drwxr-xr-x),与普通文件的 -(如 -rw-r--r--)区分3)链接文件(l,Symbolic Link / 硬链接)
链接文件类似 “快捷方式”,分为软链接(符号链接,Symbolic Link) 和硬链接(Hard Link)。
软链接(l)
独立的文件,存储目标文件的路径,若目标文件删除,软链接会失效(显示 “broken link”);例如 ln -s /home/user/docs /tmp/docs_link 创建软链接;
验证命令:
file [软链接路径]:显示 symbolic link to [目标路径];
stat [软链接路径]:File type 为 symbolic link,且 Size 为目标路径的字符长度(非目标文件大小)。
实操示例:
# 1. 先创建软链接:ln -s /etc/passwd /tmp/passwd_link
$ ln -s /etc/passwd /tmp/passwd_link# 2. 验证软链接
$ file /tmp/passwd_link
/tmp/passwd_link: symbolic link to /etc/passwd # 明确为软链接,且显示目标路径$ stat /tmp/passwd_linkFile: /tmp/passwd_link -> /etc/passwd # 箭头指向目标文件Size: 11 Blocks: 0 IO Block: 4096 symbolic link # File type 为 symbolic link
Device: tmpfs_inodefsd Inode: 1234 Links: 1
Access: (0777/lrwxrwxrwx) Uid: ( 1000/ user) Gid: ( 1000/ user)
# 注:软链接权限为 lrwxrwxrwx(第一位 l),但实际权限由目标文件决定硬链接
与目标文件共享同一个 inode(文件的唯一标识),本质是 “同一个文件的多个名字”,若目标文件删除,硬链接仍可访问文件内容,仅当所有硬链接都删除时,文件数据才会被释放。
验证命令:
file [硬链接路径]:显示结果与目标文件完全一致(无法直接识别为硬链接);
stat [硬链接路径]:Inode 编号与目标文件相同,Links 数比目标文件多 1(硬链接会增加 inode 的链接计数)。
实操示例:
# 1. 先创建硬链接:ln /etc/passwd /tmp/passwd_hardlink
$ ln /etc/passwd /tmp/passwd_hardlink# 2. 验证硬链接(file 无法区分,需对比 inode)
$ file /tmp/passwd_hardlink
/tmp/passwd_hardlink: ASCII text # 与目标文件 /etc/passwd 的 file 结果一致# 3. 对比目标文件与硬链接的 inode
$ stat -c "%i %n" /etc/passwd /tmp/passwd_hardlink
131074 /etc/passwd # 目标文件 inode=131074
131074 /tmp/passwd_hardlink # 硬链接 inode 与目标完全相同# 4. 查看链接数:目标文件的 Links 从 1 变为 2
$ stat /etc/passwd | grep Links
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)4)设备文件(b /c,Block / Character Device)
用于与硬件设备交互的文件,分为块设备文件(b) 和字符设备文件(c)。
块设备文件(b)
用于存储设备(如硬盘、U 盘),以 “块” 为单位读写数据,支持随机访问;例如 /dev/sda1(硬盘分区)、/dev/mmcblk0(SD 卡);
验证示例:
# 验证硬盘分区 /dev/sda1
$ file /dev/sda1
/dev/sda1: block special file # block special file 即块设备$ stat /dev/sda1File: /dev/sda1Size: 0 Blocks: 0 IO Block: 4096 block special file # File type 为 block special
Device: 6h/6d Inode: 504 Links: 1 Device type: 8,1 # Device type (8,1) 为块设备编号
Access: (0660/brw-rw----) Uid: ( 0/ root) Gid: ( 6/ disk)字符设备文件(c)
用于输入输出设备(如键盘、鼠标、打印机),以 “字符” 为单位顺序读写数据;例如 /dev/tty1(终端)、/dev/input/mouse0(鼠标)。
验证示例:
# 验证终端设备 /dev/tty1
$ file /dev/tty1
/dev/tty1: character special file # character special file 即字符设备$ stat /dev/tty1File: /dev/tty1Size: 0 Blocks: 0 IO Block: 4096 character special file # File type 为 character special
Device: 6h/6d Inode: 497 Links: 1 Device type: 4,1 # Device type (4,1) 为字符设备编号
Access: (0620/crw--w----) Uid: ( 0/ root) Gid: ( 5/ tty)5)管道文件(p,Pipe)
用于进程间通信(IPC)的临时文件,分为匿名管道(由 | 符号创建,如 ls | grep txt)和命名管道(由 mkfifo 命令创建,如 mkfifo my_pipe),数据写入管道后,被另一个进程读取后会立即删除。
匿名管道无实体路径,无法用 file/stat 直接查看,此处以 命名管道 为例验证:
# 1. 先创建命名管道:mkfifo /tmp/my_pipe
$ mkfifo /tmp/my_pipe# 2. 验证命名管道
$ file /tmp/my_pipe
/tmp/my_pipe: fifo (named pipe) # fifo 即命名管道$ stat /tmp/my_pipeFile: /tmp/my_pipeSize: 0 Blocks: 0 IO Block: 4096 fifo # File type 为 fifo
Device: tmpfs_inodefsd Inode: 5678 Links: 1
Access: (0644/prw-r--r--) Uid: ( 1000/ user) Gid: ( 1000/ user)
# 注:权限位第一位为 p(如 prw-r--r--),代表 pipe6)套接字文件(s,Socket)
用于网络通信或本地进程间通信的文件,支持 TCP、UDP 等协议,常见于 /var/run 目录(如 /var/run/mysqld/mysqld.sock,MySQL 服务的本地通信套接字)。
验证示例:
# 验证 MySQL 本地套接字(若 MySQL 已启动)
$ file /var/run/mysqld/mysqld.sock
/var/run/mysqld/mysqld.sock: socket # 直接识别为 socket$ stat /var/run/mysqld/mysqld.sockFile: /var/run/mysqld/mysqld.sockSize: 0 Blocks: 0 IO Block: 4096 socket # File type 为 socket
Device: tmpfs_inodefsd Inode: 7890 Links: 1
Access: (0660/srw-rw----) Uid: ( 112/ mysql) Gid: ( 118/ mysql)
# 注:权限位第一位为 s(如 srw-rw----),代表 socket04
Linux 文件系统的工作机制
Linux 文件系统的工作流程涉及 “目录项(dentry)”“索引节点(inode)”“超级块(super block)” 三个核心概念,它们共同协作实现文件的查找、读取与写入:
1)核心概念解析
超级块(Super Block)
存储文件系统的 “元信息”,如文件系统类型(Ext4、XFS)、总块数、空闲块数、inode 总数、挂载时间等,是文件系统的 “总览表”,每个文件系统(如 /dev/sda1)都有一个超级块,通常备份在多个位置以防损坏。
索引节点(inode)
存储文件的 “属性信息”,如文件大小、创建时间(ctime)、修改时间(mtime)、访问权限(rwx)、所属用户 / 组、数据块的位置(即文件数据在硬盘上的存储地址),每个文件对应唯一的 inode 编号(通过 ls -i 命令查看)。
注意:inode 不存储文件名,文件名由目录文件管理。
目录项(dentry)
存储 “文件名与 inode 编号的映射关系”,是目录文件的核心内容。
例如,/home/user/docs 目录下有一个 report.pdf 文件,该目录的 dentry 会记录 report.pdf -> 12345(12345 为该文件的 inode 编号)。
2) 文件查找与读取流程
以 “用户执行 cat /home/user/docs/report.pdf 命令读取文件” 为例,Linux 系统的处理流程如下:
解析路径
从根目录 / 开始,逐个解析路径中的目录(home → user → docs);
查找目录
读取根目录的 inode(固定编号为 2,Linux 约定),通过 inode 找到根目录的数据块,从中获取 home 目录的 inode 编号;
读取 home 目录的 inode,找到其数据块,获取 user 目录的 inode 编号;
重复上述步骤,直到找到 docs 目录的 inode,进而在其数据块中找到 report.pdf 对应的 inode 编号(如 12345);
验证权限
检查当前用户是否有读取 report.pdf 的权限(通过 inode 中的权限字段判断);
读取文件数据
通过 report.pdf 的 inode 找到其数据块在硬盘上的存储地址,内核将数据块加载到内存,最终通过 cat 命令输出给用户。
这一流程的关键在于:文件名仅用于查找 inode,实际的文件属性与数据存储依赖 inode,因此即使文件名被修改,只要 inode 不变,文件数据也不会丢失。
05
常见的 Linux 文件系统类型
Linux 支持多种文件系统类型,不同类型适用于不同场景(如本地硬盘、U 盘、日志存储、网络共享),以下是最常用的几种:
1)Ext 系列(Ext2 / Ext3 / Ext4)
Ext2(Second Extended Filesystem)
早期 Linux 主流文件系统,无日志功能,若突然断电可能导致数据损坏,适合小容量存储(如 U 盘);
Ext3
在 Ext2 基础上增加 “日志功能(Journal)”,先记录文件操作日志,再执行实际写入,降低断电数据损坏风险,兼容性好,但性能一般;
Ext4(Fourth Extended Filesystem)
目前大多数 Linux 发行版(如 kylin v10)的默认本地文件系统,优化了 Ext3 的性能,支持:
最大文件 size:16TB(理论支持 1EB);
最大分区 size:1EB;
延迟分配(Delayed Allocation):减少磁盘碎片;
在线碎片整理(Online Defragmentation)
2)XFS
特点:高性能日志文件系统,由 SGI 开发,后被 Linux 接纳,kylin v10,CentOS 8、RHEL 8 已将其作为默认文件系统;
优势:
支持超大容量:最大分区 size 18EB,最大文件 size 9EB,适合企业级存储(如数据库服务器、大数据集群);
并行 I/O 性能优异:通过 “分配组(Allocation Group)” 将磁盘分区划分为多个独立区域,支持多线程并行读写;
日志效率高:采用 “循环日志(Circular Log)”,减少磁盘 I/O 开销。
3)Btrfs(B-tree Filesystem)
特点:被称为 “下一代 Linux 文件系统”,设计目标是解决 Ext4 的局限性,支持 “写时复制(Copy-on-Write,CoW)” 技术;
核心功能:
快照(Snapshot):快速创建文件系统快照,用于备份与版本控制;
RAID 支持:原生支持 RAID 0/1/10,无需依赖硬件 RAID;
动态扩容 / 缩容:支持在线调整分区大小,无需卸载文件系统;
现状:目前在 Fedora、SUSE Linux 中应用较广,稳定性仍在持续优化,暂未成为主流发行版的默认选择。
4)其他常见类型
FAT32 / exFAT
适用于 U 盘、SD 卡等移动存储,兼容性好(支持 Windows、macOS、Linux),但 FAT32 最大支持 4GB 单个文件,exFAT 可突破此限制;
NTFS
Windows 默认文件系统,Linux 通过 ntfs-3g 驱动支持读写,适合跨系统共享硬盘;
NFS(Network File System)
网络文件系统,用于将远程服务器的目录挂载到本地,实现网络共享;
tmpfs
临时文件系统,数据存储在内存中,速度极快,/tmp 目录通常使用 tmpfs,系统重启后数据清空。
06
Linux 文件系统在 Postgre-
SQL(PG)数据库中的应用设计
PostgreSQL(简称 PG)作为开源关系型数据库的代表,其性能、稳定性与数据安全性高度依赖底层 Linux 文件系统的支撑。
PG 的数据存储、日志管理、并发控制等核心功能,需与 Linux 文件系统的特性(如日志机制、I/O 性能、权限控制)深度适配。
以下从 PG 数据库文件结构解析、Linux 文件系统特性适配、实际应用设计方案 三个维度,详细说明如何基于 Linux 文件系统优化 PG 部署。
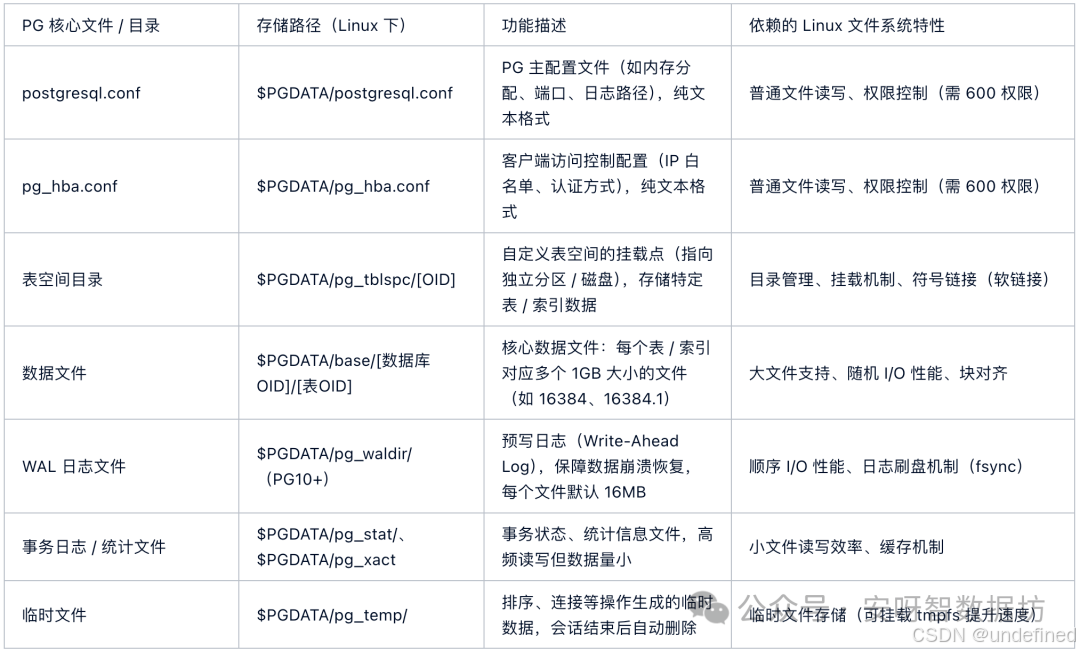
1)PostgreSQL 数据库的核心文件结构
(Linux 下的存储布局)
在 Linux 环境中,PG 数据库的所有数据、日志、配置文件均以文件形式存储在指定目录(默认路径为 /var/lib/postgresql/[版本号]/[实例名],如 /var/lib/postgresql/16/main),其核心文件结构与 Linux 文件系统的目录层级紧密关联,具体如下:
注意
$PGDATA 是 PG 数据库的核心数据目录,由 initdb 命令初始化时指定,所有与数据相关的文件均围绕此目录组织,其权限需设为 700(仅 postgres 用户可访问),依赖 Linux 文件系统的权限控制防止未授权访问。
2)Linux 文件系统特性与 PG 数据库的适配需求
PG 数据库的核心诉求(如数据一致性、高 I/O 性能、崩溃恢复),需 Linux 文件系统提供对应的特性支撑,以下是关键适配点:
日志机制:保障 PG 数据一致性(WAL 日志与文件系统日志协同)
PG 的 WAL 日志 是数据一致性的核心:所有数据修改先写入 WAL 日志,再刷盘到数据文件,即使数据库崩溃,也可通过 WAL 日志恢复未刷盘的数据。
这一机制需 Linux 文件系统的 日志功能 协同:
适配文件系统
Ext4(带日志模式)、XFS(默认日志),避免使用无日志的 Ext2(崩溃后可能导致 WAL 日志文件损坏);
关键参数
PG 的 wal_sync_method 参数(默认 fsync)依赖 Linux 文件系统的 fsync() 系统调用,确保 WAL 日志写入物理磁盘(而非缓存),而 XFS 的 “延迟日志刷盘” 特性可在保证一致性的前提下,比 Ext4 减少 fsync() 开销,提升 WAL 写入性能。
I/O 性能:匹配 PG 不同类型文件的 I/O 模式
PG 中不同文件的 I/O 模式差异极大,需 Linux 文件系统针对性优化:
WAL 日志
顺序写(按日志生成顺序持续写入),对文件系统的 “顺序 I/O 吞吐量” 敏感,XFS 的 “分配组(Allocation Group)” 特性可将日志文件存储在独立的磁盘区域,减少碎片,提升顺序写速度;
数据文件
随机写(查询 / 更新时随机访问表 / 索引数据块),依赖文件系统的 “随机 I/O 响应速度”,Ext4 的 “延迟分配(Delayed Allocation)” 可减少数据块碎片,XFS 的 “重定向写(Reflink)” 特性(需 PG 14+ 支持)可优化表备份时的 I/O 开销;
临时文件
高频读写 + 短期存储,将 $PGDATA/pg_temp 挂载到 tmpfs(内存文件系统),可避免磁盘 I/O 瓶颈,提升 PG 的排序、哈希连接等操作速度(需注意:tmpfs 依赖内存,需预留足够内存,避免 OOM)。
大文件与表空间:适配 PG 海量数据存储
PG 支持单个表数据文件超过 1GB(通过 “段文件” 自动拆分,如 16384、16384.1),且支持 表空间(Tablespace) 功能,可将不同表 / 索引存储到独立的 Linux 分区 / 磁盘,需文件系统满足:
大文件支持
Ext4(最大文件 16TB)、XFS(最大文件 9EB),均满足 PG 海量数据需求,企业级场景(如 TB 级表)优先选 XFS;
表空间挂载
通过 Linux 的 “挂载点” 机制,将独立磁盘分区(如 /dev/sdb1)格式化为 XFS/Ext4 后,挂载到 PG 的表空间目录(如 /var/lib/postgresql/16/main/pg_tblspc/12345),实现 “热点表独立存储”(如将高频访问的 user 表放在 SSD 分区,冷数据放在 HDD 分区)。
权限与安全:Linux 权限控制保障 PG 数据隔离
PG 数据库默认使用 postgres 系统用户运行,其数据目录 $PGDATA 的权限需严格控制,避免其他用户篡改数据,依赖 Linux 文件系统的权限机制:
目录权限
$PGDATA 设为 drwx------(700),仅 postgres 用户可进入;
文件权限
配置文件(postgresql.conf、pg_hba.conf)设为 -rw-------(600),避免敏感配置(如密码、IP 白名单)泄露;
设备权限
若 PG 数据存储在独立磁盘(如 /dev/sdb),需确保 postgres 用户对该磁盘设备文件(如 /dev/sdb)有读写权限(可将 postgres 加入 disk 用户组,/dev/sdb 权限为 brw-rw----)。
3)Linux 文件系统在 PG 数据库中的
实际应用设计方案
基于上述适配需求,结合企业级 PG 部署场景,给出 文件系统选型、分区规划、性能优化 三位一体的设计方案:
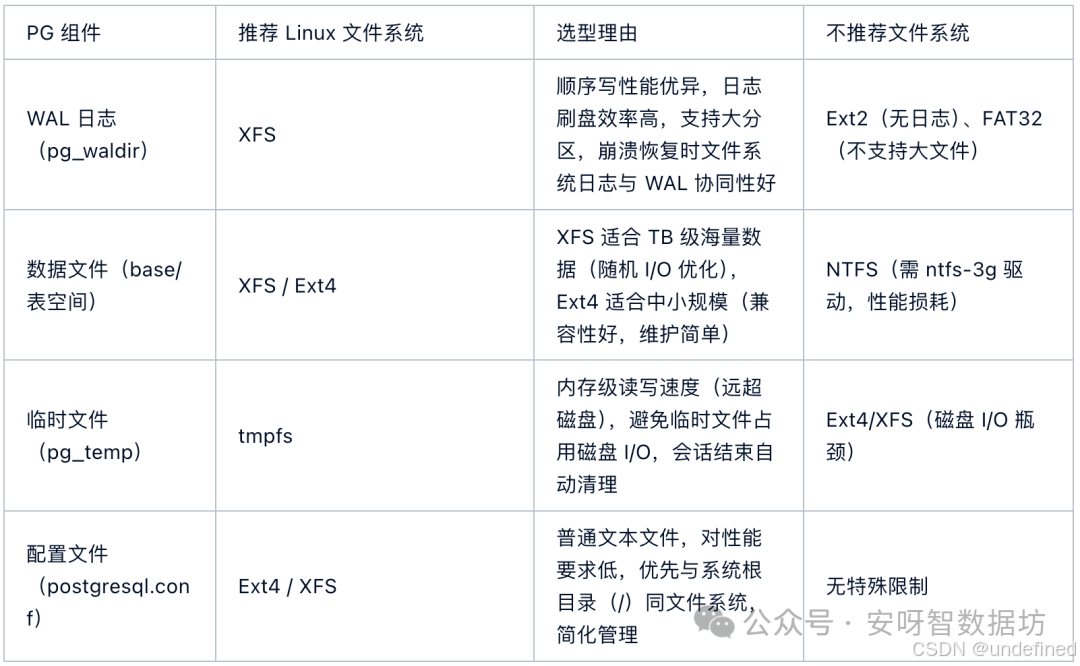
文件系统选型:按 PG 组件类型差异化选择
不同 PG 组件(WAL 日志、数据文件、临时文件)的 I/O 特性不同,需搭配不同的 Linux 文件系统:
企业级推荐
生产环境优先选择 XFS 作为 PG 数据文件与 WAL 日志的文件系统,尤其是当数据库规模超过 100GB 或并发写入较高时(如电商订单库、金融交易库),XFS 的性能优势更明显。
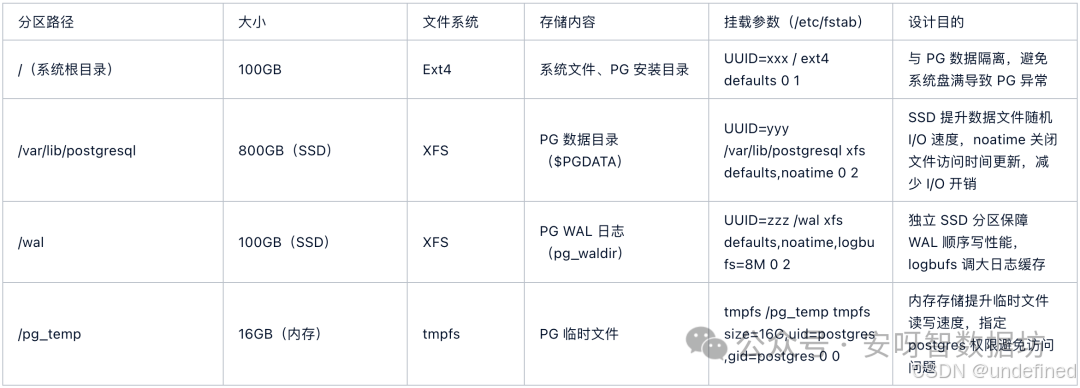
分区规划:按 PG 组件隔离存储,避免 I/O 竞争
Linux 分区规划的核心原则是 “组件隔离”:将 PG 的 WAL 日志、数据文件、临时文件分别放在独立分区,避免不同组件的 I/O 竞争(如 WAL 顺序写与数据文件随机写抢占磁盘带宽)。
以下是典型的分区方案(基于 1TB SSD + 4TB HDD 存储):
关键操作
将 PG 的 WAL 日志目录迁移到独立分区(如 /wal),需修改 postgresql.conf 中的 wal_directory = '/wal',并重启 PG 服务,确保权限正确(/wal 属主为 postgres:postgres,权限 700)。
性能优化:Linux 文件系统参数与 PG 配置协同调优
通过调整 Linux 文件系统参数与 PG 配置,进一步释放性能,关键优化点如下:
1)文件系统挂载参数优化(/etc/fstab)
noatime/nodiratime
关闭文件 / 目录的访问时间更新(PG 不依赖访问时间),减少磁盘 I/O(尤其是数据文件目录);
logbufs=8M(XFS 特有)
将文件系统日志缓存从默认 1M 调大到 8M,减少 WAL 日志写入时的 fsync() 次数;
discard
启用 TRIM 功能(仅 SSD 支持),释放已删除文件的磁盘空间,避免 SSD 性能衰减,需确保 PG 支持(PG 12+ 已适配)。
示例 fstab 配置(XFS 数据分区):
UUID=yyy /var/lib/postgresql xfs defaults,noatime,nodiratime,discard,logbufs=8M 0 22)PG 配置与文件系统特性协同
wal_sync_method
根据文件系统选择最优同步方式,XFS 推荐 open_datasync(比 fsync 减少一次 I/O),Ext4 推荐 fsync;
maintenance_work_mem
表空间创建、索引重建等维护操作的内存分配,若 pg_temp 挂载 tmpfs,可适当调大(如 64MB),减少临时文件写入;
checkpoint_completion_target
checkpoint 完成目标比例(默认 0.9),XFS 的高 I/O 性能可支持将此值调大到 0.95,平滑 checkpoint 期间的 I/O 峰值。
示例 PG 配置(postgresql.conf):
wal_sync_method = 'open_datasync' # XFS 最优同步方式
maintenance_work_mem = '64MB' # 结合 tmpfs 临时文件优化
checkpoint_completion_target = 0.95 # 平滑 checkpoint I/O
wal_buffers = '16MB' # WAL 缓存,匹配 XFS 日志缓存3)Linux 内核参数优化(/etc/sysctl.conf)
vm.dirty_ratio/vm.dirty_background_ratio
控制脏页(未刷盘的缓存数据)比例,推荐设为 20 和 10(默认 40 和 10),减少 PG 数据刷盘时的 I/O 阻塞;
fs.file-max
系统最大打开文件数,PG 每个连接 / 数据文件需占用一个文件句柄,推荐设为 1048576(默认 32768),避免 “too many open files” 错误。
示例内核参数配置:
vm.dirty_ratio = 20
vm.dirty_background_ratio = 10
fs.file-max = 1048576写在最后
Linux 文件系统架构不是冷冰冰的概念,而是一整套 优雅且实用的设计哲学:
统一抽象
一切皆文件,让资源访问方式高度一致;
单一目录树
不再区分“盘符”,挂载点让存储整合透明化;
灵活机制
FHS 标准目录、丰富的文件类型、强大的 inode/superblock 体系,共同保证了系统的扩展性和稳定性。
理解文件系统架构,不仅能帮你读懂 Linux 的“为什么这么设计”,更能在实际工作中快速定位问题、优化配置、避免误操作。
当你真正吃透 Linux 文件系统,你会发现:它不仅是数据的容器,更是整个操作系统的灵魂。