深度学习-PyTorch 模型
一、PyTorch 搭建模型的 “两大核心工具”
在 PyTorch 中,所有神经网络的构建都围绕两个核心工具展开 ——nn.Module和nn.functional。它们分工明确,就像 “建筑工人” 和 “工具包”,共同完成模型的搭建任务。

1. nn.Module:带 “参数管理” 的 “重量级” 模块
nn.Module是 PyTorch 中所有神经网络模块的 “基类”,无论是现成的全连接层、卷积层,还是我们自定义的完整模型,都需要继承它。它的核心优势在于自动管理可学习参数(比如全连接层的权重weight和偏置bias),无需开发者手动定义和跟踪。
打个比方,nn.Module就像 “智能积木”:每个积木(如nn.Linear全连接层、nn.Conv2d卷积层)自带 “参数芯片”,拼在一起后,框架能自动识别所有芯片并统一优化。比如用nn.Linear(784, 300)创建全连接层时,框架会自动初始化 784×300 的权重矩阵和 300 维的偏置向量,后续训练中还能自动计算梯度、更新参数。
它的适用场景很明确:所有带可学习参数的层或完整模型,比如卷积层、全连接层、Dropout 层,以及我们自定义的手写数字识别模型、ResNet 模型等。
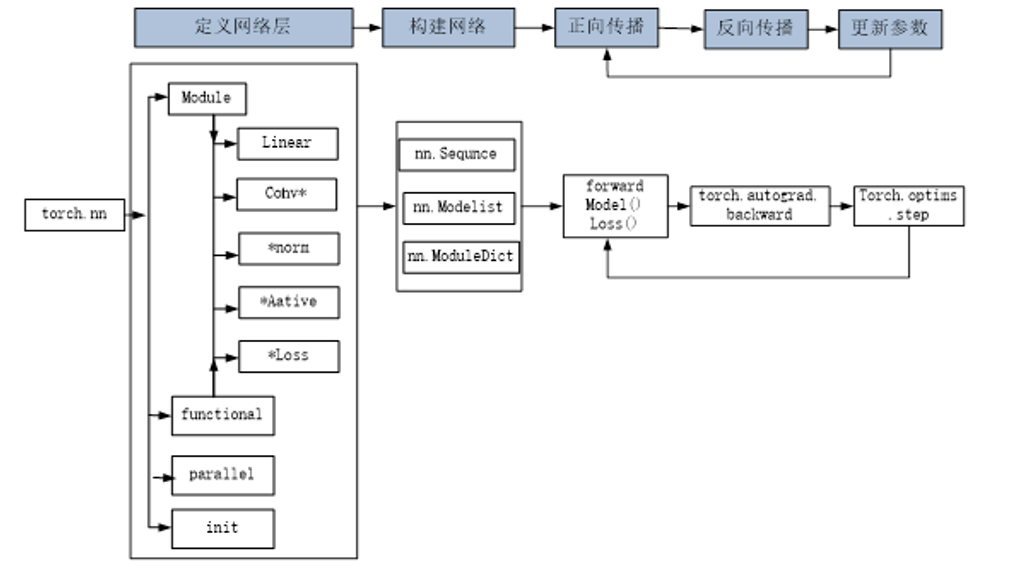
2. nn.functional:无 “参数负担” 的 “轻量级” 函数库
如果说nn.Module是 “智能积木”,那nn.functional就是 “手动工具包”。它提供了一系列无参数的 “纯功能函数”,比如激活函数(ReLU、Softmax)、池化操作(最大池化、平均池化)等,仅负责对数据做特定变换,不涉及参数的管理。
举个例子,用nn.functional.relu(x)对数据做激活时,只需传入输入张量x,函数会直接输出变换后的结果,无需初始化任何参数。但它也有局限:如果涉及带参数的操作(比如全连接层),需要开发者手动定义和传入权重、偏置,不利于代码复用;而且像 Dropout 这类需要区分 “训练 / 测试” 状态的操作,用nn.functional.dropout时,还得手动切换状态,不如nn.Dropout(nn.Module类)自动切换方便。
简单来说,nn.functional更适合无参数的基础功能,比如激活函数、池化操作;而nn.Module更适合带参数的核心层和完整模型,两者搭配使用,能兼顾灵活性和开发效率。
二、搭建模型的 “三大经典方式”:从简单到灵活
PyTorch 没有 “唯一正确” 的模型搭建方式,而是提供了三种主流思路,分别对应不同复杂度的场景。选择哪种方式,核心取决于模型的结构特点和开发需求。
1. 纯nn.Module手写层:灵活应对复杂逻辑
这是最基础也最灵活的方式,核心思路是 “在模型类中手动定义每一层,并编写数据流动逻辑”。具体来说,就是先继承nn.Module基类,在初始化函数(__init__)中定义所有需要的层(如展平层、全连接层、归一化层),再在forward方法中描述数据如何在这些层之间流动。
这种方式就像 “量身定制服装”,可以根据需求自由设计细节。比如在处理手写数字识别时,我们可以在forward方法中灵活添加数据预处理、分支逻辑(如多路径特征融合)、特殊激活方式等。哪怕是像 ResNet 这样有 “残差连接” 的复杂模型,也能通过手动编写前向传播逻辑,清晰实现 “输入与输出相加” 的核心机制。
它的优势是灵活性拉满,适合所有复杂模型和特殊业务场景;唯一的 “缺点” 是需要手动编写前向传播流程,对初学者来说需要稍多的代码组织能力。
2. nn.Sequential堆叠层:快速构建线性结构
如果模型是 “线性结构”—— 层与层之间依次连接,没有分支、跳转等复杂逻辑(比如简单的全连接网络、基础 CNN),那么nn.Sequential就是最高效的选择。它是 PyTorch 提供的 “模型容器”,能像 “叠积木” 一样按顺序堆叠多个层,自动完成数据的前向传播,无需手动编写forward方法。
比如搭建一个手写数字识别的全连接网络,只需按 “展平层→全连接层→归一化层→激活层→输出层” 的顺序,把这些层依次放进nn.Sequential中,框架就会自动让数据从第一层流到最后一层。而且它还支持给每层命名(通过add_module方法或OrderedDict),方便后续调试时查看某一层的输出结果。
这种方式就像 “组装标准化家具”,所有零件(层)都是现成的标准件,只需按说明书顺序拼接,省时又省力。它的适用场景很明确:线性结构的简单模型,追求代码简洁性和开发效率。
3. nn.Module+ 模型容器:模块化构建复杂架构
当模型既有 “线性堆叠” 的子模块,又有 “自定义逻辑” 时,就需要结合nn.Module和模型容器(nn.Sequential、nn.ModuleList、nn.ModuleDict),用 “模块化” 思路搭建。
比如构建一个多分支网络时,我们可以先把每个分支的 “线性层 + 归一化层” 用nn.Sequential封装成独立子模块(如block1、block2),再在nn.Module的初始化函数中引入这些子模块,最后在forward方法中编写 “多分支特征融合” 的自定义逻辑。这样一来,模型结构被拆分成多个子模块,既避免了代码冗余,又让整体逻辑清晰易懂。
除了nn.Sequential,还有nn.ModuleList和nn.ModuleDict两种容器:nn.ModuleList像 “层的列表”,适合动态添加不定数量的层(如根据超参数决定隐藏层数量);nn.ModuleDict像 “层的字典”,适合按名称动态调用不同层(如根据输入类型选择不同的特征提取模块)。
这种方式兼顾了灵活性和模块化,是工业界开发中等复杂度模型(如多任务学习模型、轻量化 CNN)的常用思路,既能应对复杂逻辑,又保证了代码的可维护性。
三、模型搭建的 “核心原则”:从功能到架构的思考
掌握了工具和方式后,搭建模型时还需要遵循几个核心原则,让模型不仅能完成任务,还具备良好的扩展性和可读性。
1. 先明确 “任务需求”,再设计 “层的组合”
搭建模型的第一步,永远是根据任务确定核心需求。比如做手写数字识别(简单分类任务),用 “全连接层 + 归一化层 + 激活层” 的组合即可;做图像分割(复杂空间任务),则需要引入卷积层、池化层、上采样层等专门处理空间信息的模块。
不同任务对层的需求差异很大:分类任务注重 “全局特征提取”,输出层常用 Softmax;回归任务注重 “连续值预测”,输出层无需激活;生成任务注重 “特征生成能力”,可能需要引入反卷积层、注意力机制等。只有先明确任务目标,才能选择合适的层和组合方式。
2. 用 “模块化” 思维拆分复杂结构
面对复杂模型(如 ResNet、Transformer),切忌 “从头到尾一锅粥” 式编写,而是要像 “拆拼图” 一样,把模型拆分成多个独立子模块。比如 ResNet 的核心是 “残差块”,我们可以先把 “卷积层 + 归一化层 + 激活层” 封装成基础残差块,再通过堆叠不同数量的残差块,构建出 ResNet18、ResNet50 等不同深度的模型。
模块化设计的好处很明显:每个子模块可以单独调试、复用(比如把残差块用到其他网络中),后续修改某部分逻辑时,也不会影响整体架构,大大降低了开发和维护成本。
3. 平衡 “灵活性” 与 “简洁性”
PyTorch 提供了多种搭建方式,并非越灵活越好。比如简单的线性模型,用nn.Sequential只需 3-5 行代码,若强行用纯nn.Module手写,反而会增加不必要的代码量;而像多分支、多任务的复杂模型,用纯nn.Sequential无法实现,必须通过nn.Module+ 容器的方式搭建。
开发中需要根据模型复杂度 “按需选择”:简单线性结构优先用nn.Sequential追求效率;复杂逻辑用纯nn.Module或 “nn.Module+ 容器” 保证灵活性。记住,好的模型代码不仅要能跑通,还要让别人能快速看懂结构 —— 这也是 PyTorch 设计的核心理念之一。
四、总结:PyTorch 模型搭建的 “学习路径”
从工具到方式,PyTorch 模型搭建的逻辑其实很清晰:先掌握nn.Module和nn.functional的分工,再根据模型复杂度选择合适的搭建方式,最后用模块化思维优化架构。