ICCV-2025 | 斯坦福人形机器人自主导航!LookOut:真实环境人形机器人第一人称视角导航
- 作者:Boxiao Pan, Adam W. Harley, C. Karen Liu, Leonidas J. Guibas
- 单位:斯坦福大学
- 论文标题:LookOut: Real-World Humanoid Egocentric Navigation
- 论文链接:https://arxiv.org/pdf/2508.14466v1
- 项目主页:https://sites.google.com/stanford.edu/lookout
主要贡献
- 引入了从第一人称视角视频预测未来6D头部姿态轨迹的挑战性任务,该任务要求在存在静态和动态障碍物的情况下进行预测,使模型能够学习规划无碰撞路径以及人类的信息收集行为。
- 提出模型:设计了通过时间聚合3D潜在特征来推理的框架LookOut,利用预训练的DINO特征编码器和无参数的反投影策略,有效解决了该任务,能够对环境的几何和语义约束进行建模,适用于环境的静态和动态部分。
- 贡献了使用Project Aria眼镜的数据收集流程,该流程简单易行,只需在每次录制会话开始时进行几秒钟的设置,即可收集到包含RGB视频、音频、眼动追踪、SLAM重建头部姿态和点云等多种数据模态的数据,为大规模数据收集提供了便利。
- 通过上述流程收集了一个包含4小时真实世界导航会话的数据集AND,涵盖了18个具有密集和多样化交通的地点,为学习真实世界的第一人称导航策略提供了宝贵的资源。
研究背景
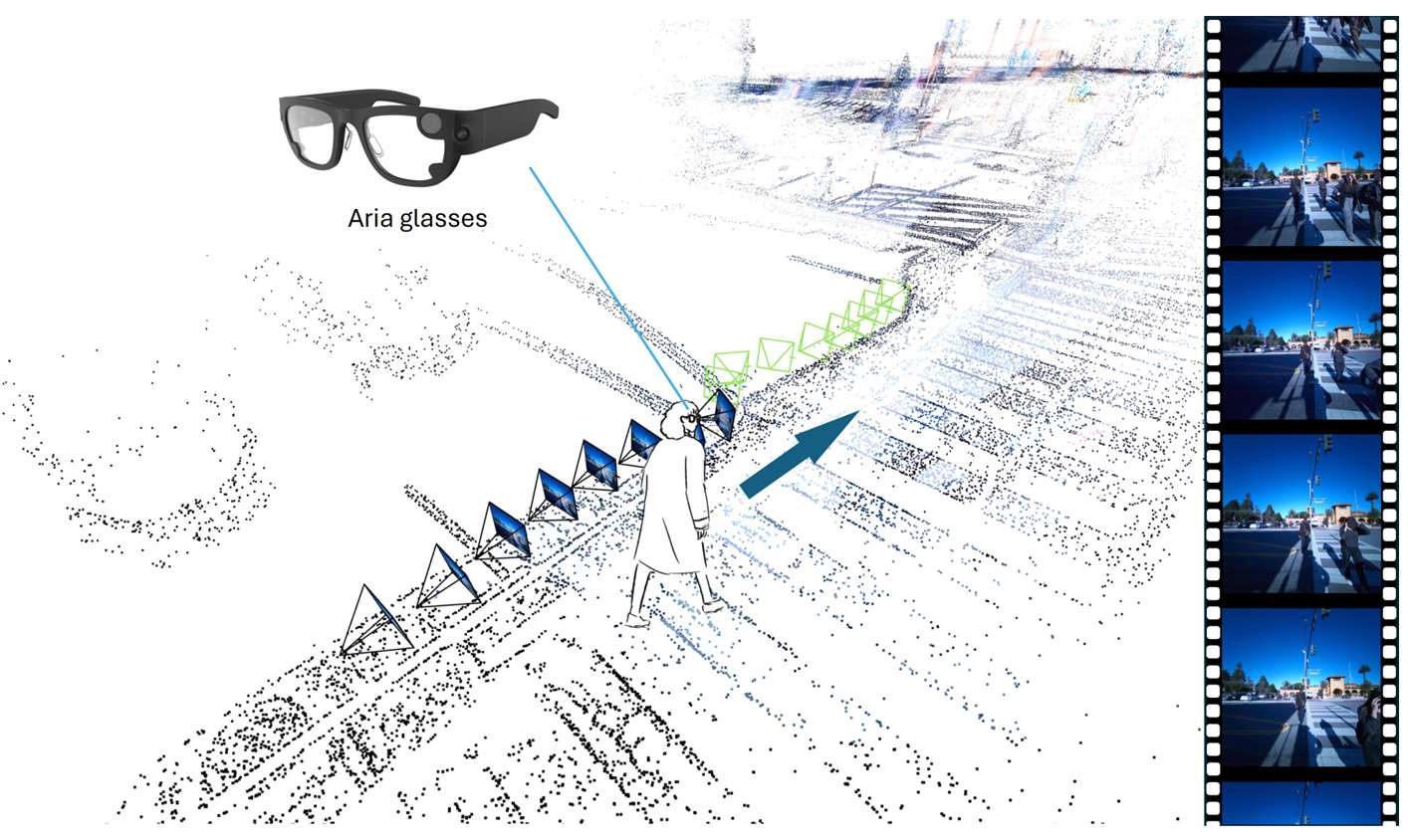
- 现实世界导航的重要性:人类能够基于第一人称视角安全地在现实世界中导航,但机器学习这一能力却极具挑战性,主要是因为现实场景中存在多样化和复杂的情况。这种导航能力对于人形机器人、虚拟现实/增强现实(VR/AR)以及辅助导航等众多应用都至关重要。
- 现有研究的局限性:尽管已有研究从不同角度探讨了这一问题,如视觉语言导航(VLN)、机器人社交导航以及针对人类的以自我为中心的导航等,但目前仍缺乏一个可在现实世界中部署的人形以自我为中心的导航策略。现有方法或假设环境静态,或忽略了人类通过头部转动主动收集信息这一重要导航行为,且难以大规模收集多模态标记训练数据。
方法
问题定义
- 目标:给定一个带有姿态的第一人称视频 X∈RT1×H×W×3X \in \mathbb{R}^{T_1 \times H \times W \times 3}X∈RT1×H×W×3 和对应的头部姿态序列 H1:T1={h1,h2,…,hT1}∈RT1×9H_{1:T_1} = \{h_1, h_2, \dots, h_{T_1}\} \in \mathbb{R}^{T_1 \times 9}H1:T1={h1,h2,…,hT1}∈RT1×9,目标是预测未来一段时间内的6D头部姿态序列 HT1+1:T1+T2={h^T1+1,h^T1+2,…,h^T1+T2}∈RT2×9H_{T_1+1:T_1+T_2} = \{\hat{h}_{T_1+1}, \hat{h}_{T_1+2}, \dots, \hat{h}_{T_1+T_2}\} \in \mathbb{R}^{T_2 \times 9}HT1+1:T1+T2={h^T1+1,h^T1+2,…,h^T1+T2}∈RT2×9。头部姿态包括平移部分 ttt_ttt 和旋转部分 rtr_trt,其中旋转部分采用6D连续旋转表示。
- 时间窗口:在实验中,T1=T2=8T_1 = T_2 = 8T1=T2=8,即模型基于过去8帧的输入预测未来8帧的头部姿态。
模型架构
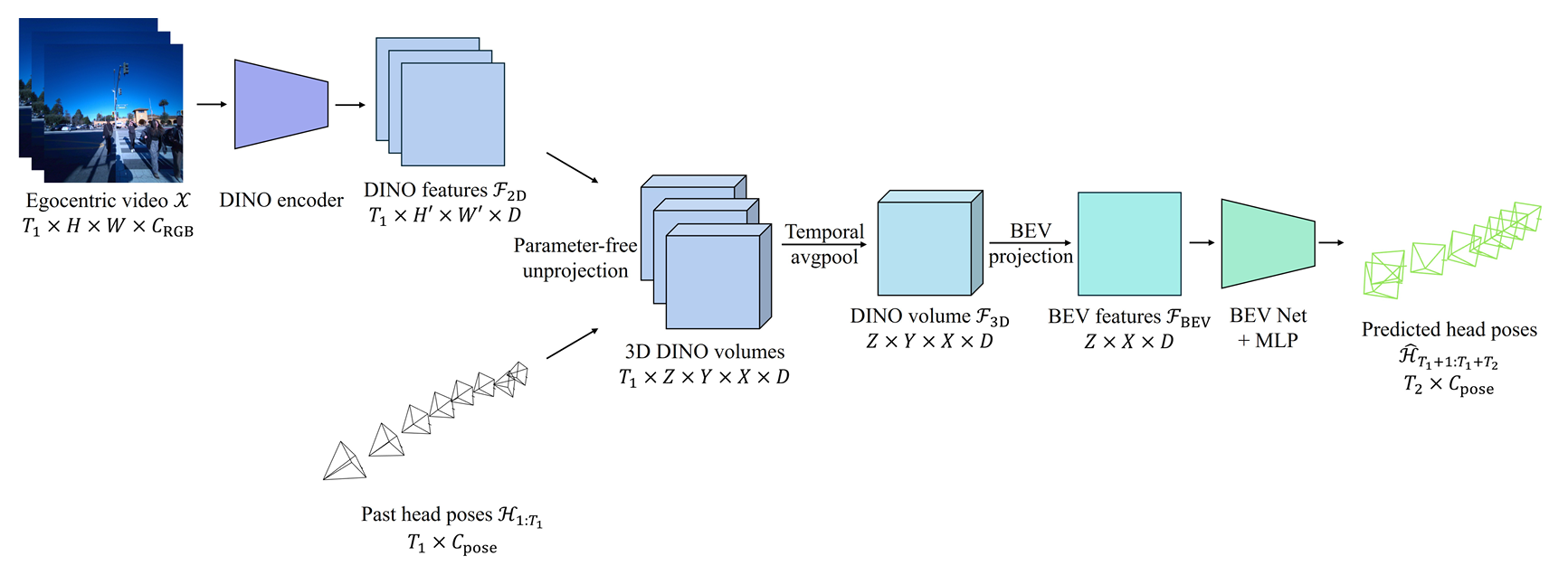
模型的核心目标是从单目视频流中提取周围环境的语义和几何信息,以实现无碰撞导航和信息收集行为。模型架构包括以下几个关键模块:
-
DINO特征编码:
- 使用预训练的DINO2模型(dinov2_vits14reg*)对每一帧输入图像进行编码,得到2D DINO特征序列 F2D∈RT1×16×16×384F_{2D} \in \mathbb{R}^{T_1 \times 16 \times 16 \times 384}F2D∈RT1×16×16×384。
- 输入图像在编码前会被下采样到224×224的分辨率。
-
无参数反投影:
- 定义一个以当前头部姿态为中心的规范帧中的体素网格,将这些点投影到每个输入帧的像素空间。
- 通过双线性插值2D DINO特征图,为每个3D坐标点获取特征编码,得到3D DINO特征体积序列。
- 将这些特征体积在时间上进行聚合,得到单一的3D特征体积 F3D∈RZ×Y×X×384F_{3D} \in \mathbb{R}^{Z \times Y \times X \times 384}F3D∈RZ×Y×X×384,其中 Z=X=96,Y=32Z = X = 96, Y = 32Z=X=96,Y=32。
- 时间聚合方法采用简单的平均池化。
-
BEV投影:
- 将3D特征体积投影到“鸟瞰图”(BEV),通过一个MLP将上轴(Y轴)压缩,得到BEV特征图 FBEV∈RZ×X×384F_{BEV} \in \mathbb{R}^{Z \times X \times 384}FBEV∈RZ×X×384。
- 这种投影方式可以降低计算成本,同时保留环境的几何和语义信息。
-
BEV网络:
- BEV网络由11个连续的BEV模块组成,每个模块包括2D卷积、LayerNorm和具有GELU激活的MLP。
- 隐藏维度从384开始,逐步加倍,最终达到1540,同时空间维度逐渐减小到 3×33 \times 33×3。
-
轨迹预测:
- 对BEV网络的输出进行空间平均池化,然后通过一个3层MLP得到预测的未来头部姿态序列 H^T1+1:T1+T2\hat{H}_{T_1+1:T_1+T_2}H^T1+1:T1+T2。
- 使用L1损失函数对平移和旋转进行监督,损失函数定义为:
L=1T2∑t=T1+1T1+T2(λtrans∥tt−t^t∥1+λrot∥RtR^t−I∥1) L = \frac{1}{T_2} \sum_{t=T_1+1}^{T_1+T_2} \left( \lambda_{\text{trans}} \| t_t - \hat{t}_t \|_1 + \lambda_{\text{rot}} \| R_t \hat{R}_t - I \|_1 \right) L=T21t=T1+1∑T1+T2(λtrans∥tt−t^t∥1+λrot∥RtR^t−I∥1)
其中,λtrans=λrot=1\lambda_{\text{trans}} = \lambda_{\text{rot}} = 1λtrans=λrot=1。
实现细节
- 头部中心规范帧:由于模型不输入过去的头部姿态(仅用于反投影过程),需要定义一个相对于当前头部姿态的规范帧。该规范帧与地面平行且面向前方,但以头部为中心,使模型能够在当前朝向方向的空间中操作,并以相对方式预测未来的头部姿态。
- 训练细节:
- 使用AdamW优化器,权重衰减设置为0.05(不包括偏置项)。
- 训练模型700k步,采用OneCycle学习率调度器,线性退火策略,pct_start设置为0.05。
- 批量大小为4,训练过程在单个NVIDIA RTX A6000 GPU上大约需要4天。
Aria导航数据集AND
数据集设计与收集流程
由于缺乏适合人形导航任务的数据集,论文设计了一个新的数据收集流程,旨在收集真实世界中人类导航场景的数据,涵盖静态和动态障碍物。
- 硬件:使用Project Aria眼镜作为数据收集工具,其优势在于轻便、不显眼、成本低且易于设置。
- 录制过程:
- 使用Aria Studio移动应用进行数据录制,激活RGB、SLAM(两个单色相机)和眼动追踪相机,以及IMU传感器、气压计和GPS。
- 摄像头帧率为20fps,人类受试者在行走时自然地进行导航行为演示,遵循特定的导航策略,如过马路前查看过往车辆。
- 数据处理:
- 原始数据以VRS格式存储,通过Aria机器感知服务(MPS)处理,得到6D头部姿态轨迹和场景点云。
- 对原始RGB帧进行去畸变处理,以适合作为模型输入。
- 将原始序列分割成固定长度的片段,每个片段覆盖4.5秒的导航数据。
- 对SLAM重建的点云进行过滤,去除动态物体上的点和噪声点。
- 隐私保护:遵循Project Aria研究指南,使用最先进的去识别算法对所有视频中的人脸进行模糊处理。
数据集统计
- 地点选择:选择了18个具有密集交通的地点,包括大学校园、城市中心和公园等,以捕捉真实世界导航场景中与静态和动态障碍物的碰撞避免行为。
- 数据规模:共录制了约4小时的数据,处理后得到274k RGB帧和36k个片段。
实验结果
定量评估
- 评估指标:
- 头部姿态预测精度:使用L1损失函数评估平移(L1_trans)和旋转(L1_rot)的预测精度。
- 碰撞避免性能:定义静态(Col_stt_k)和动态(Col_dyn_k)障碍物的非碰撞分数,测量预测头部姿态与障碍物之间的最小距离。非碰撞分数表示预测至少距离最近障碍物k厘米的百分比。
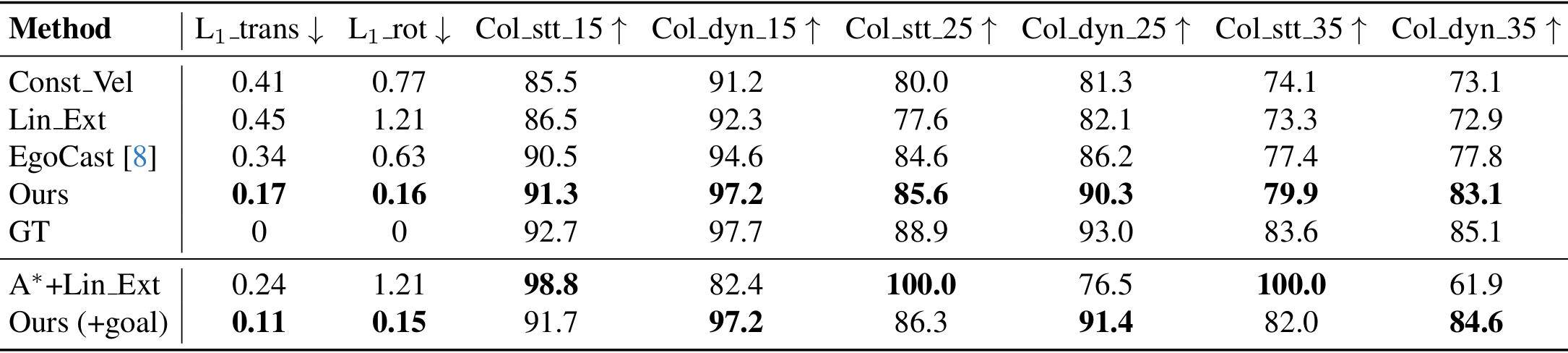
- 基线比较:
- 恒定速度(Const Vel):使用最后两步的线性和角速度外推未来头部姿态。
- 线性外推(Lin Ext):对过去的平移和旋转序列拟合线性回归模型,预测未来姿态。
- EgoCast:经过适应性修改,使用过去的头部姿态和第一人称视频预测未来头部姿态。
- A*+线性外推(A*+Lin Ext):对平移使用A*算法,对旋转使用线性外推。
- 结果分析:
- 在无目标设置下,LookOut模型在所有指标上均优于基线方法,能够准确预测头部姿态并可靠地避开静态和动态障碍物。
- 当提供目标位置时,A*+线性外推在避开静态障碍物方面表现接近完美,但在避开动态障碍物方面表现不佳。
定性评估

- 模型行为:
- 碰撞避免:模型能够预测出围绕静态和动态障碍物的无碰撞路径。
- 信息收集行为:模型学习到了人类在训练数据中展示的信息收集行为,例如在过马路时查看路况。
- 等待行为:在没有可行路径时,模型能够学习到等待行为。
- 路径适应:模型能够根据新观察到的视觉线索调整预测路径。

- 可视化:
- 通过将模型预测和真实值在2D图像上的投影进行可视化,展示了模型在真实世界导航场景中的多样化行为。
- 从鸟瞰图角度展示了模型预测的轨迹,进一步证明了模型预测结果符合环境约束。
失败案例与局限性
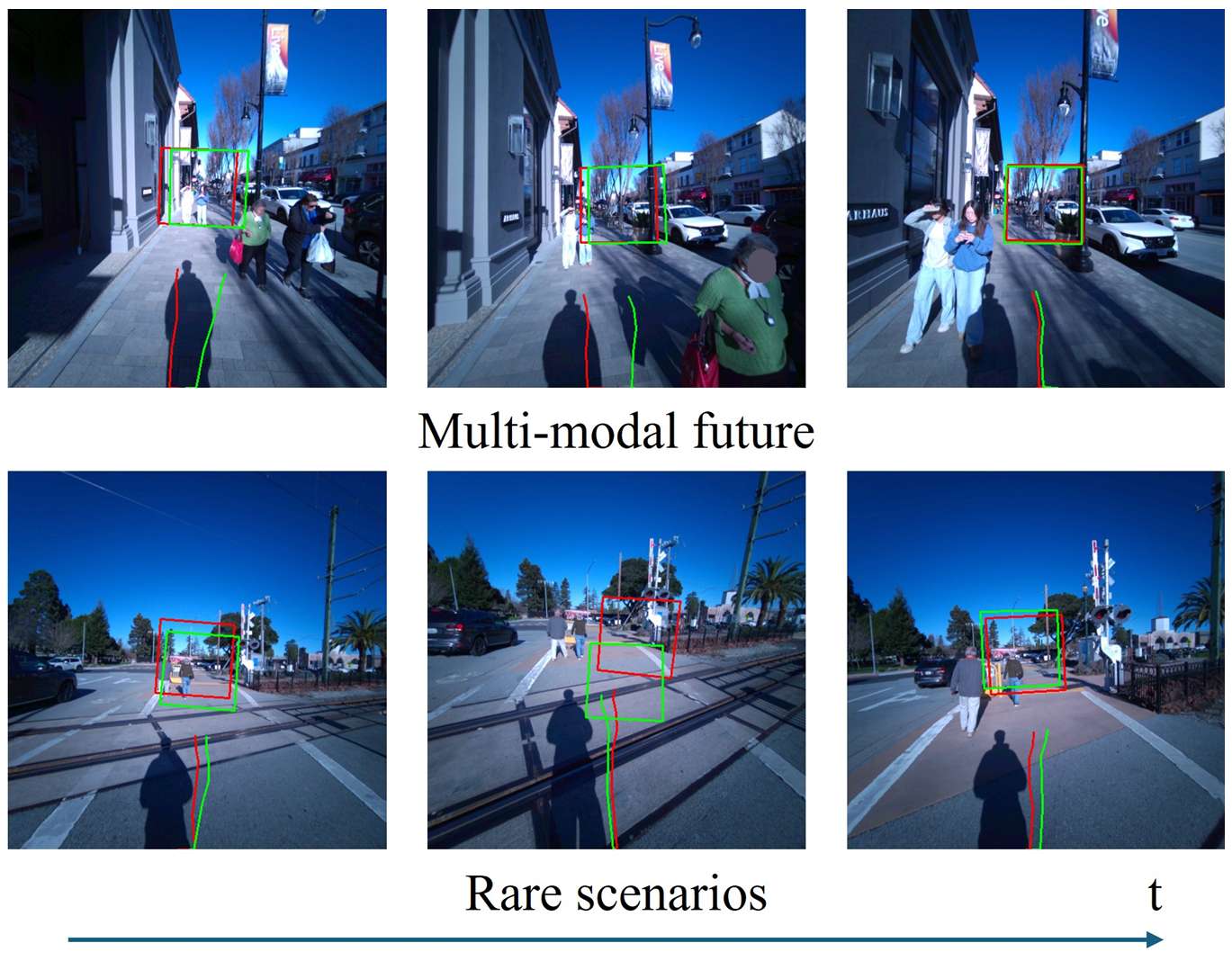
- 多模态未来:当存在多个可能的未来路径时,模型可能会回归到这些可能性的平均值,导致预测结果不够准确。
- 罕见场景:如果训练集中没有出现某些特定场景(如铁轨),模型就无法预测出人类在这种场景下的特定行为。
结论与未来工作
- 结论:
- 本文通过提出新任务、设计有效模型、构建数据收集流程和收集高质量数据集,为实现真实世界中可部署的人形导航策略迈出了重要一步。
- 实验结果表明,LookOut模型能够学习到对真实世界导航任务有用的多样化行为,并在各项指标上超越了基线方法。
- 未来工作:
- 未来可以探索利用生成模型来解决多模态未来预测问题,进一步扩大数据集以涵盖更多场景和行为,还可以考虑将模型应用于实际的人形机器人导航系统中,进行更广泛的现实世界测试和验证。
