基于目标导向扩散模型与影响函数的EHR数据生成方法
目录
一、理论支撑:扩散模型基础
1.前向过程
2. 反向过程
二、TarDiff方法框架
1. 影响函数的定义
2. 梯度引导的逆向扩散
3. 实施流程
三、实验验证与性能分析
1. 数据替代测试(TSTR)
2. 数据增强测试(TSRTR)
3. 处理类别不平衡的能力
4. 生成样本可视化对比
四、计算效率分析
五、结论与贡献
文献名称:Target-Oriented Diffusion Guidance for Synthetic Electronic Health Record Time Series Generation
作者:Bowen Deng , Chang Xu , Hao Li , Yuhao Huang , Min Hou , Jiang Bian
发表会议:2025KDD
电子健康记录(EHR)数据蕴含着巨大的医疗价值,然而传统生成模型在合成此类数据时,通常侧重于学习其统计分布和时间依赖性,未能充分考虑生成数据对下游任务性能的优化作用。EHR数据普遍存在分布不均衡问题,传统生成模型仅基于数据分布合成样本,在遇到罕见病症时,由于缺乏对这些少数模式的学习,生成能力受限。此外,尽管传统方法能够保证生成数据的统计保真度,却难以确保其在特定下游任务(如疾病预测或分类模型)中带来性能提升。
针对上述局限性,本研究将合成数据生成的指导思想从传统的“保真度优先”转变为“效用性优先”。我们引入了“影响函数”(Influence Function)的概念,用以生成能显著提升下游任务性能的样本,特别是对改善模型在少数类样本上表现至关重要的数据。本文提出的TarDiff(Target-oriented Diffusion)框架,其核心思想是将数据生成的目标从单纯模仿数据分布,转化为优化生成数据在下游任务中的性能。它通过影响函数量化引入新生成样本后下游任务损失的减少量,并将该影响梯度作为引导信号注入到反向去噪过程,从而生成能更好提升下游任务性能的样本。
一、理论支撑:扩散模型基础
扩散模型包括前向加噪和反向去噪两个过程.
1.前向过程
逐步向数据中添加高斯噪声。设原始数据为,则在时间步t时有:
其中 βt∈(0,1)是噪声调度参数。通过重参数化技巧,可写为:
这使得采样过程可导,便于梯度优化。
2. 反向过程
学习一个去噪模型:
通常固定方差,均值由神经网络预测。训练目标是最小化预测噪声与真实噪声之间的均方误差:
条件扩散模型(如Classifier Guidance)可通过附加信息(如标签 y)引导生成:
二、TarDiff方法框架
TarDiff的核心思想是:将生成目标从模仿数据分布转变为优化下游任务性能。通过影响函数量化合成样本对任务损失的影响,并以此指导扩散过程。
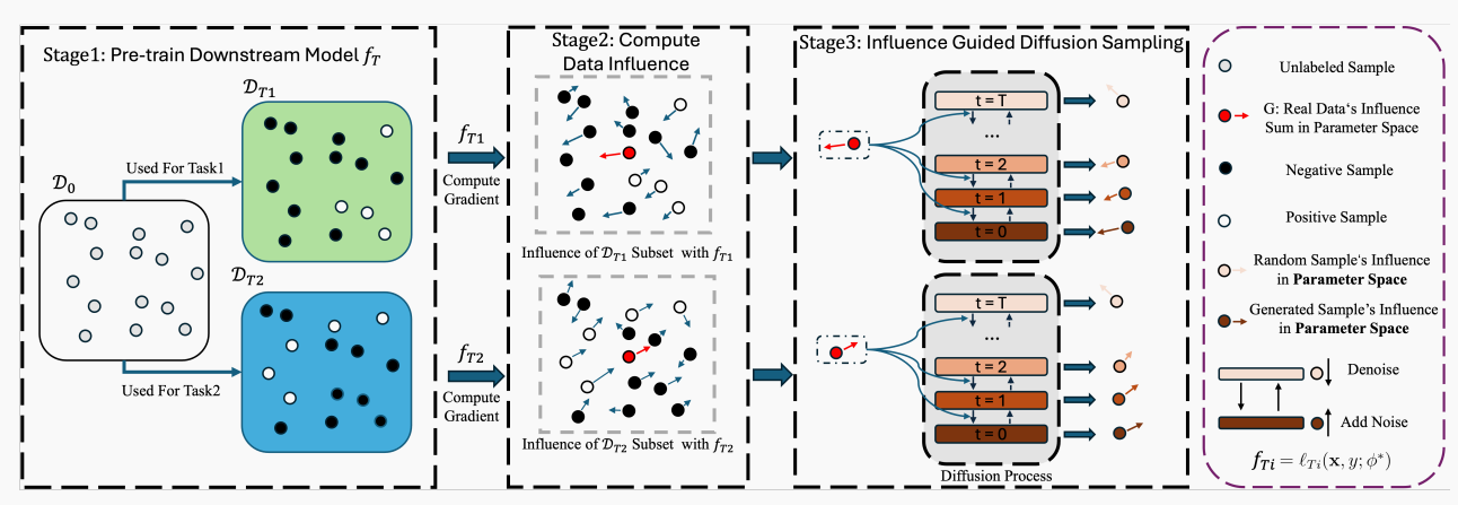
图1 影响指导扩散框架
1. 影响函数的定义
设下游任务 T的损失函数为 ,训练集为
。若加入合成样本
,重新训练模型得到参数
,则其于指导集
上的损失变化为:
目标为生成使 ΔLT(z^)最大的样本。
2. 梯度引导的逆向扩散
在每一步去噪中,TarDiff 不仅依赖标签条件,还引入影响梯度作为引导:
其中。通过链式法则与梯度缓存机制,实际计算时使用:
其中是指导集梯度的聚合向量。
3. 实施流程
TarDiff 分为三个阶段:
Stage 1:预训练下游模型
在上训练任务模型
,得到最优参数
。
Stage 2:计算影响梯度
对指导集中每个样本计算梯度
,聚合并归一化得到 G。
Stage 3:引导扩散采样
在逆向扩散的每一步中,计算引导项J,更新均值:
采样,最终得到合成样本
。
三、实验验证与性能分析
TarDiff 在六个公开医疗数据集(包括 MIMIC-III、eICU 及多种生理信号数据集)上进行了评估,结果显示其在不同下游任务(如死亡率预测、ICU 停留时间预测)中均达到最先进性能。
1. 数据替代测试(TSTR)
模型仅使用合成数据训练,在真实测试集上评估。验证合成数据能否代替真实数据进行训练。
| Method | MIMIC-III Mortality (AUROC) | eICU Mortality (AUROC) |
|---|---|---|
| TimeGAN | 0.5144 | 0.6238 |
| Real Data | 0.6350 | 0.6869 |
| TarDiff | 0.6373 | 0.6308 |
表1 MIMICIII和eICU数据集上合成数据生成方法的性能比较
TarDiff 合成数据训练出的模型性能接近甚至超过使用真实数据训练的基线。
2. 数据增强测试(TSRTR)
将合成数据与真实数据按不同比例混合训练模型,验证合成的数据对训练效果的提升能力(即数据增强能力)。TarDiff 在多数比例下均优于基线方法。
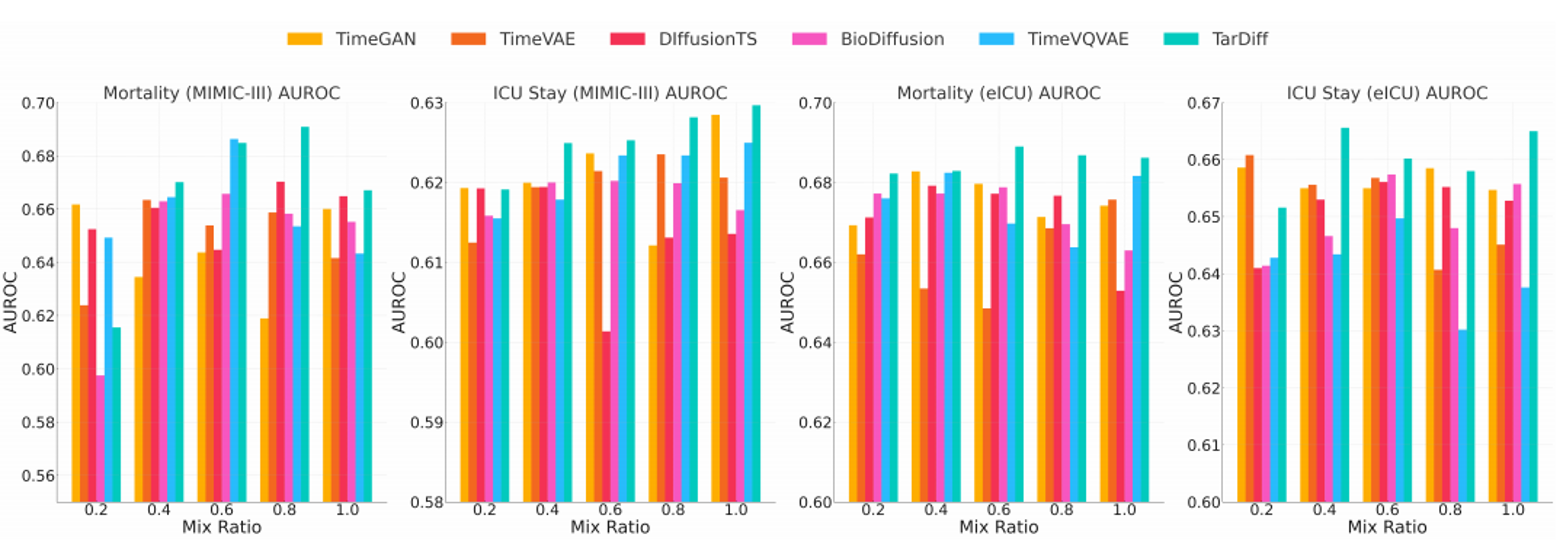
图2 MIMIC-III与eICU数据集死亡率及ICU停留时间预测的AUROC比较
3. 处理类别不平衡的能力
梯度分析表明,少数类样本的梯度范数显著大于多数类(如表3所示)。TarDiff 通过影响引导自然聚焦于少数类,无需额外加权机制即可提升其分类性能:
| Guidance Type | MIMIC-III Minority F1 |
|---|---|
| All Samples | 0.108 |
| Minority-only | 0.163 |
| Majority-only | 0.066 |
表3 具有类别特定指导的少数类F1
4. 生成样本可视化对比
下图展示了不同方法生成的正负样本对比,TarDiff 生成的序列在形态学和趋势上更接近真实数据:
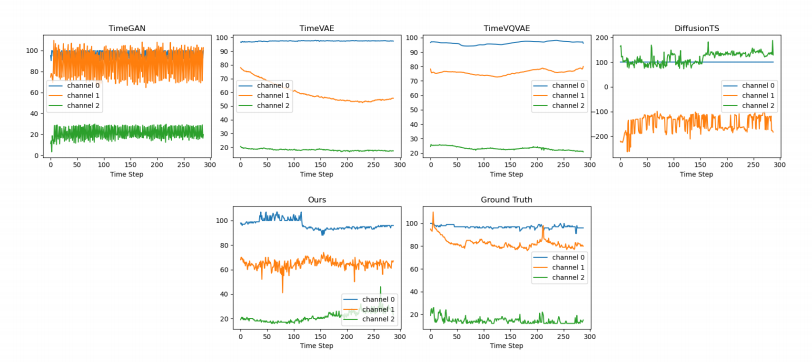
图3 eICU上不同方法生成的ICU-Stay阴性样本可视化
四、计算效率分析
尽管引入了梯度引导机制,TarDiff 的额外计算开销主要集中于:
一阶段:下游模型训练与梯度缓存(10–167秒,依赖数据集规模);
采样阶段:每步仅增加 lightweight的向量运算,整体采样速度仍优于多数扩散基线方法(如 BioDiffusion、DiffusionTS)。
五、结论与贡献
TarDiff 通过将影响函数与条件扩散模型相结合,成功实现了从“保真度驱动”到“效用驱动”的生成范式转变。其不仅能生成高质量、高保真的医疗时间序列数据,还能显著提升下游临床任务的性能,特别是在处理类别不平衡和罕见病例识别方面表现突出,并为隐私保护下的数据共享提供了新思路。