亚马逊云科技重磅推出 Amazon S3 Vectors:首款大规模支持原生向量的云存储服务
海量向量数据存储不再是难题,Amazon S3 Vectors 为 AI 创新提供无限可能
在人工智能技术飞速发展的今天,向量数据已成为支撑众多AI应用的核心要素。从推荐系统到语义搜索,从欺诈检测到药物发现,向量嵌入(vector embeddings)正在重新定义我们处理和分析复杂数据的方式。然而,如何高效存储和检索海量向量数据,一直是开发者面临的重要挑战。
行业痛点:向量数据存储的困境
传统的向量存储方案通常面临两难选择:要么使用专门的向量数据库,但受限于存储容量和成本;要么自行构建解决方案,却要承担运维复杂性和可扩展性挑战。随着AI应用规模的不断扩大,这些限制变得越来越突出。
许多企业不得不维护两套独立的存储系统:一套用于传统数据(如图片、视频、文档),另一套专门用于向量数据。这种架构不仅增加了系统复杂度和成本,还导致了数据一致性和管理上的困难。
破局之作:Amazon S3 Vectors 横空出世
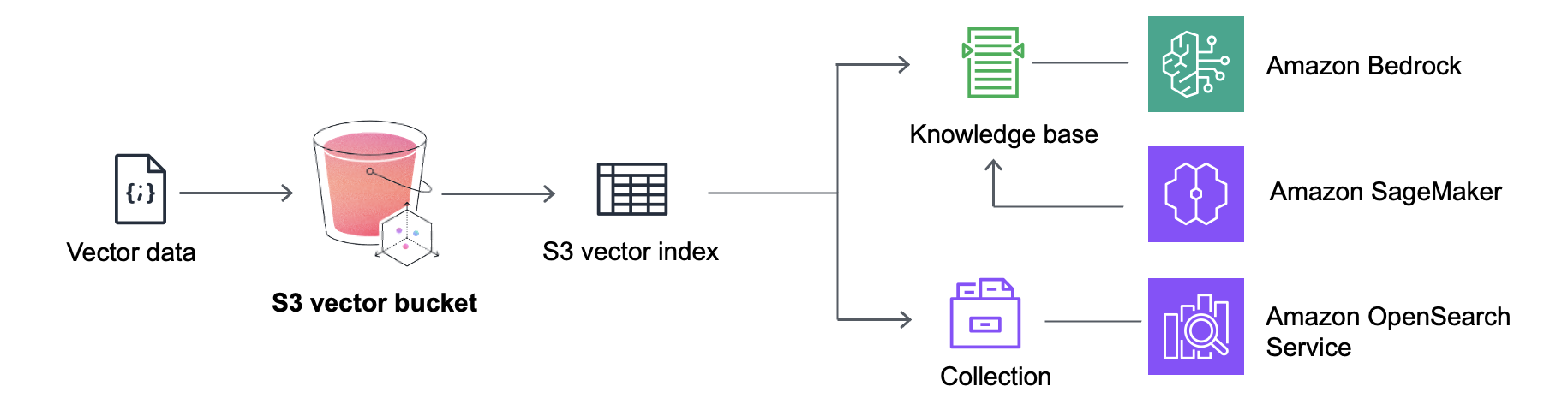
亚马逊云科技再次引领创新潮流,推出Amazon S3 Vectors(预览版)——业界首款大规模支持原生向量存储和检索的云存储服务。这一突破性产品将向量能力直接集成到Amazon S3中,让开发者能够在全球最受欢迎的对象存储服务中直接处理向量数据。
核心特性一览
原生向量支持
Amazon S3 Vectors 在对象级别原生支持向量数据,允许您将向量与原始数据(如图像、文档)存储在一起,无需维护两套独立的存储系统。
大规模扩展
借助S3久经考验的可扩展架构,Amazon S3 Vectors可轻松处理数万亿个向量,满足最大规模的AI工作负载需求。
统一存储架构
现在您可以使用单一的S3存储桶同时存储原始数据和其对应的向量表示,简化数据架构,确保数据一致性。
高性能检索
内置的向量相似性搜索功能,支持毫秒级响应时间,即使面对海量数据也能保持高性能。
成本效益
无需为专门的向量数据库支付高昂费用,享受S3一贯的经济实惠和按使用量付费的模式。
技术实现:简单而强大
Amazon S3 Vectors 的使用极其简单,只需通过API调用即可实现向量的存储和检索:
import boto3
from numpy import array# 初始化S3客户端
s3_client = boto3.client('s3')# 存储向量数据
vector_data = array([0.1, 0.5, 0.8, ...]).tobytes()
s3_client.put_object(Bucket='my-bucket',Key='my-vector',Body=vector_data,Metadata={'vector-dimensions': '512','vector-type': 'float32'}
)# 执行相似性搜索
response = s3_client.search_vectors(Bucket='my-bucket',QueryVector=[0.2, 0.4, 0.7, ...],MaxResults=10,SimilarityThreshold=0.8
)应用场景:无限可能
增强的推荐系统
存储用户和商品的向量表示,实时检索最相关的推荐内容,大幅提升推荐准确性和用户体验。
智能语义搜索
超越关键字匹配,实现真正理解用户意图的语义搜索,适用于文档检索、产品搜索等各种场景。
多模态AI应用
统一存储文本、图像、音频的向量表示,构建跨模态的搜索和检索能力。
大语言模型增强
为LLMs提供外部知识库的快速向量检索,增强模型的知识和能力边界。
异常检测
实时比较数据点与正常模式的向量相似性,快速识别异常行为或交易。
开发者优势:更快、更简单、更经济
对于开发团队而言,Amazon S3 Vectors 带来了多重好处:
简化架构:减少系统组件数量,降低架构复杂度
加速开发:专注于业务逻辑而非基础设施管理
降低成本:避免专门的向量数据库开销
无缝集成:与现有的AWS服务和无服务器计算无缝配合
企业级能力:继承S3的所有企业特性,包括版本控制、访问控制、加密和合规性认证
展望未来
Amazon S3 Vectors 的推出标志着云存储进入了一个新时代——存储不再只是被动的数据保管者,而是能够主动理解数据内容的智能平台。这一创新将为AI应用开发带来革命性变化,让开发者能够更轻松地构建下一代智能应用程序。
目前Amazon S3 Vectors正处于预览阶段,我们邀请广大开发者抢先体验,探索向量存储的无限可能性。相信随着服务的正式推出,我们将见证一波全新的AI创新浪潮。