Ceph 测试环境 PG_BACKFILL_FULL
现象
出现异常
[WRN] PG_BACKFILL_FULL: Low space hindering backfill (add storage if this doesn’t resolve itself): 1 pg backfill_toofull
pg 32.314 is active+remapped+backfill_wait+backfill_toofull, acting [84,23,65,49,8,39]
背景:前几天ceph 集群出现full,刚清空数据
排查
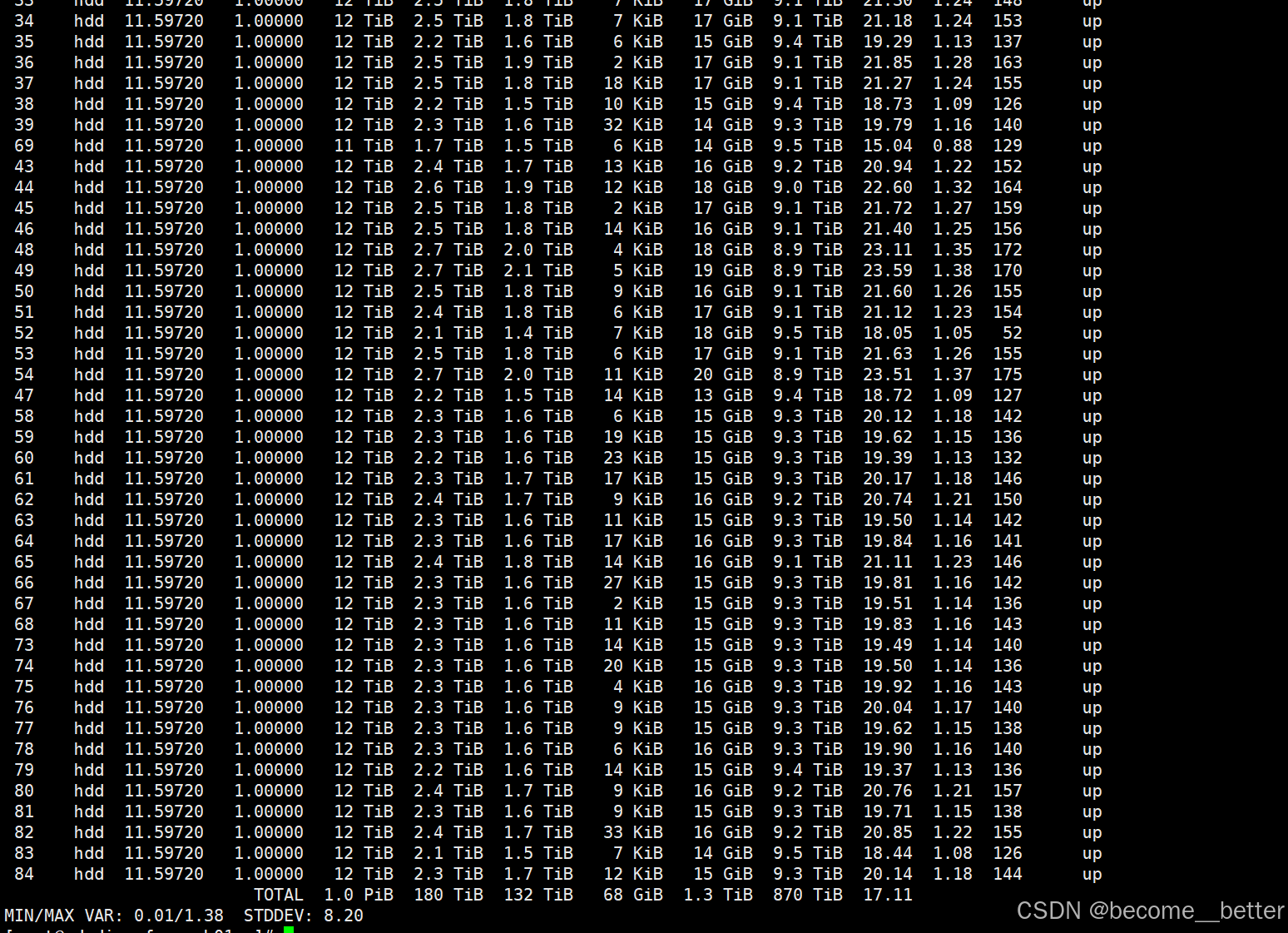
进行ceph osd df,发现相关osd 还存在9 Tib空间,总空间 12 Tib,使用ceph pg 32.314 query ,查看 pg 大小为 53 GB,不存在剩余空间不足问题。
ceph osd df
ceph pg query
怀疑是 pg的状态机因为之前的集群full 事件卡在了某个状态,不能自动还原。
ceph在执行完peer后进行recovery和backfill。
void PrimaryLogPG::on_activate_complete()
{// all clean?if (needs_recovery()) {dout(10) << "activate not all replicas are up-to-date, queueing recovery" << dendl;queue_peering_event(PGPeeringEventRef(std::make_shared<PGPeeringEvent>(get_osdmap_epoch(),get_osdmap_epoch(),PeeringState::DoRecovery())));} else if (needs_backfill()) {dout(10) << "activate queueing backfill" << dendl;queue_peering_event(PGPeeringEventRef(std::make_shared<PGPeeringEvent>(get_osdmap_epoch(),get_osdmap_epoch(),PeeringState::RequestBackfill())));} else {dout(10) << "activate all replicas clean, no recovery" << dendl;queue_peering_event(PGPeeringEventRef(std::make_shared<PGPeeringEvent>(get_osdmap_epoch(),get_osdmap_epoch(),PeeringState::AllReplicasRecovered())));}
}
backfill 先后进行 LocalBackfillReserved和 RemoteBackfillReserved ,在RemoteReservationRejectedTooFull时,会出现PG_STATE_BACKFILL_TOOFULL 状态。理论上PG状态会在 WaitLocalBackfillReserved, WaitRemoteBackfillReserved,NotBackfilling 三个状态中一直循环,直到 集群正常。不知为啥卡在某个状态,因为当时日志级别较低,没有相关日志。
DECLARE_LOCALS; // 声明局部变量,用于状态机上下文```boost::statechart::result
PeeringState::WaitRemoteBackfillReserved::react(const RemoteReservationRejectedTooFull &evt)
{DECLARE_LOCALS;ps->state_set(PG_STATE_BACKFILL_TOOFULL); //hereretry();return transit<NotBackfilling>();
}恢复
手动 ceph pg repeer 32.314,重启状态转换,发现异常消失。
不要执行ceph pg force-backfill , 会因为PG_STATE_BACKFILL_TOOFULL 状态,直接return。