【论文阅读】MaskGIT: Masked Generative Image Transformer
CVPR 2022,一个用于高质量图像生成和编辑的Transformer架构。
现有方法的局限
GANs虽然能生成高质量图像,但训练不稳定(比如模式崩溃问题,导致样本多样性不够)。
生成式Transformer受到NLP成功启发,将图像当作一维序列处理(如VQGAN),但实际上:
图像不是天然的序列结构,“一维展平+顺序生成”不能充分利用图像的空间结构和上下文。
序列长度长(如一个512x512图像可能需要几千个token),导致建模和生成效率低下。
Autoregressive解码(逐步生成)速度慢且不易并行(比如生成一张图要花30秒)。
2. MaskGIT的核心创新
MaskGIT提出了一套与BERT类似的 “掩码学习”(masked token prediction)思路用于图像生成:
a. 训练阶段
把图像编码为离散的token。
随机掩盖一些token,Transformer需根据未被掩盖的token来预测被遮住(masked)的位置的内容(类似BERT的MLM)。
网络是双向自注意力(Bidirectional self-attention),可以同时用上下左右信息,增强空间建模。
b. 推理/生成阶段
区别传统方法(逐步生成),MaskGIT采用并行多步生成:
初始状态:所有位置为“未知”token(全mask)。
第一步:模型并行预测所有token,但只保留“置信度最高”的一部分。
后续步:继续掩盖“置信度低”的token、并行预测并更新直至全部token都确定。整个过程通常只需几步(如8步),远快于传统的数百步逐个生成。
解码速度优化:MaskGIT的解码是并行的,并且只用很少的迭代步,对于512x512图像,生成效率是autoregressive方法的64倍!
c. Bidirectional vs. Unidirectional
传统生成式Transformer只看已生成的token,MaskGIT可用全局信息预测token,能更好生成与图像上下文相关的内容。
d. 掩码调度(Mask Scheduling)
每一步掩盖的比例逐步减少,采用cosine schedule能提升生成质量(论文有消融实验对比)。
总结:
MaskGIT本质上是一种将BERT式掩码预测引入视觉生成领域的新范式。
并行、迭代掩码生成机制 在速度和质量上都有巨大优势。
Bidirectional attention让图像空间建模更强,局部修改更灵活。
不仅适合高质量生成,也能做复杂的图像编辑、补全、外推等任务,可谓通用型强。

Figure 1展示了MaskGIT已能做图像生成、对象替换、图像扩展等多种任务,且分辨率很高。
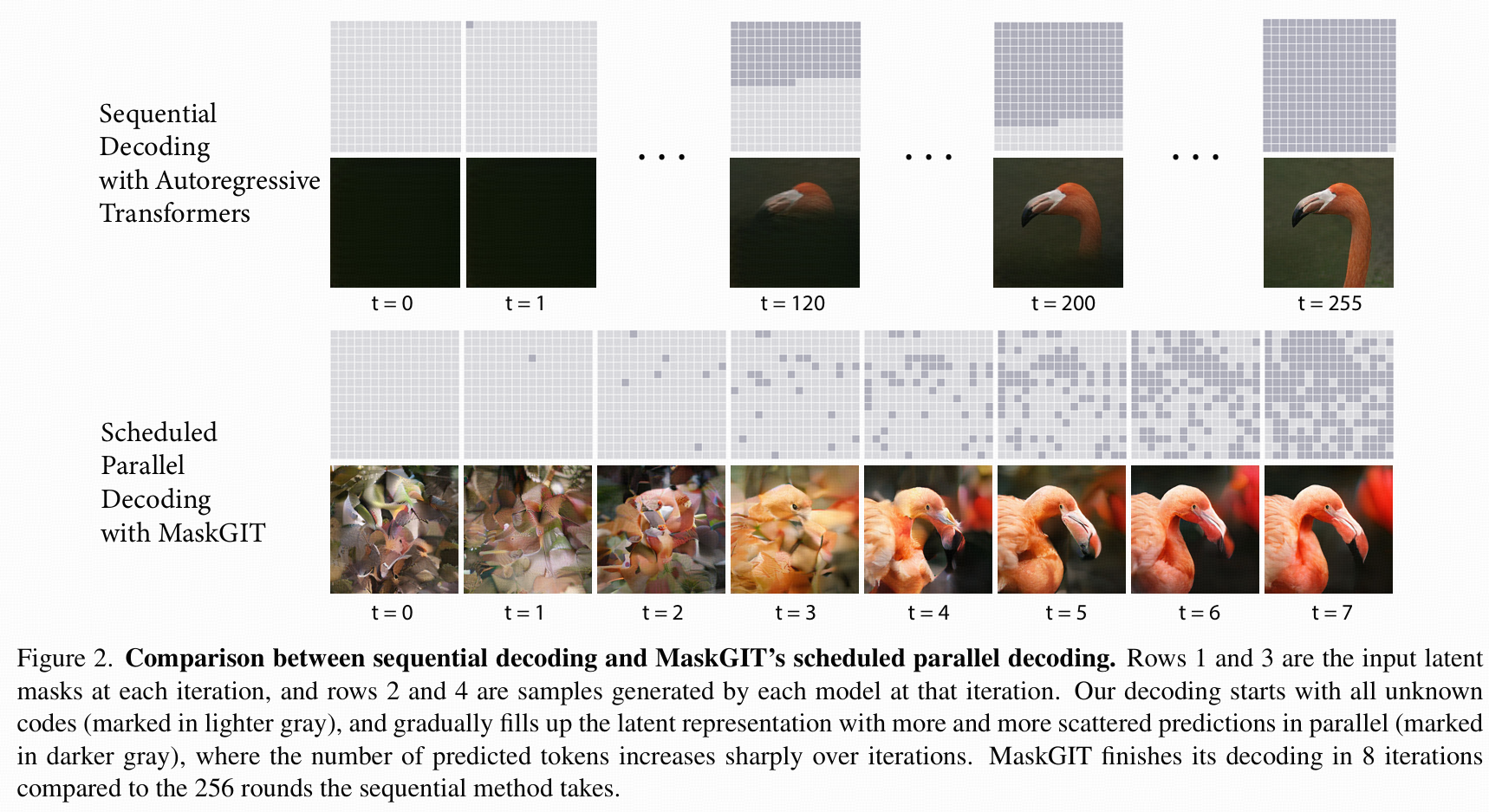
Figure 2对比了传统逐步生成与MaskGIT的并行掩码生成解码过程,8步搞定高分辨率图像,极大提升效率。
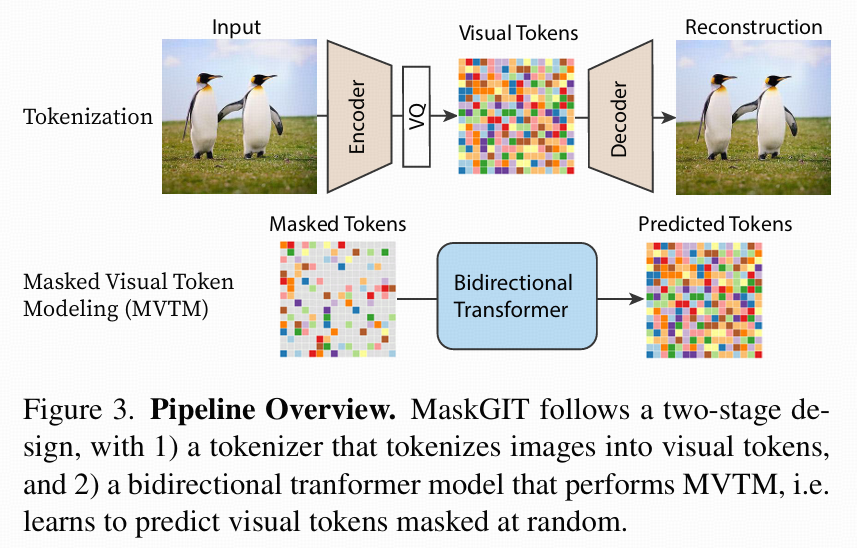
- Figure 3:方法全流程 Pipeline
两阶段设计(跟 VQGAN、VQVAE 类似):
Tokenizer(第一阶段)
输入图像 → VQGAN/VQ-VAE 编码器 → 离散化成“视觉 token”(即 codebook 索引)。图像大小 H×W 压缩成 h×w(h=H/16, w=W/16)token grid。
每个 token 是一个 codebook id(共有 1024 个 token,可视作“视觉单词”)。
Bidirectional Transformer(第二阶段)
训练目标是 MVTM(Masked Visual Token Modeling),即随机mask部分视觉token,让模型根据未masked token预测被mask掉的内容(类似BERT的MLM)。
跟之前自回归序列生成不同,Transformer是双向注意力,可以同时看到左、右、上、下的内容来猜mask位置。
3.1 MVTM 训练
假设原始token序列为:
Y={yi}i=1N
N表示token总数(h×w)。
mask向量 M={mi}i=1N ,m_i=1表示该token被mask替换为特殊符号[MASK],m_i=0表示原token保留。
mask比例γ(r):
从0到1采样一个比率,根据这个比率γ(r)×N随机挑token做mask。
(训练时随机,推理时按进度递减,下文3.3会细讲)损失函数:
只在mask位置计算交叉熵损失:Lmask=−EY∼Di:mi=1∑logp(yi∣YM)
其中 YM 是mask后的token序列。
核心差异:AR(自回归)只能看到过去token,预测未来token;MVTM可双向利用上下文(空间信息)来描绘mask位置。
3.2 Iterative Decoding
这是MaskGIT能快64倍的关键。
传统AR解码:
一次只生成1个token,要生成 N 个token就得跑 N 步 → 对高分辨率图非常慢(像32×32 token要 1024 步)。
MaskGIT解码(并行 & 多次迭代):
Step 0:所有token都mask,表示未知(初始画布是空的)。
每次迭代:
Predict:对所有“当前被mask”的位置同时预测概率分布(并行计算)。
Sample:在mask位置采样token,并赋予置信度(softmax概率)。
已确定位置置信度=1.0。
Mask Schedule:根据mask比例γ决定下一步要mask多少个token。mask掉当前低置信度的token,其他保留。
Repeat:重复直到所有token都不再mask。
T步完成整张图:论文实验中T=8即可搞定,比如:
第1步:填1个token
第2步:填更多
第8步:全部token填满 → 完成。
好处:
每步并行预测所有token → 提速;
中期可以修改错误 → 增强全局一致性;
仿佛画画:先大框架,后细节润色。
3.3 Masking Design
mask调度函数 γ(r) 定义每个迭代的mask比例(r在0~1表示进度)。
必须满足:
0 ≤ γ(r) ≤ 1;
随着 r(进度)增加,γ递减:γ(0)≈1(初始全mask),γ(1)≈0(最后无mask)。
三类函数:
Linear:每次减少相同数量token;
Concave(凹型):先少填,后期快速增加 → 类似人类画画流程(先大概,再密集细化)。包括cosine、平方、立方、指数等;
Convex(凸型):反过来,先大量确定token,后期少改动(逻辑不太符合图像细化规律)。
结论(实验4.4):
Cosine最好(略胜平方),性能稳定、FID最低(质量最高);
凹型函数普遍优于线性,线性优于凸型。
4 实验
4.2 类条件生成
(ImageNet 256×256, 512×512)
FID 同分辨率下直接碾压 VQGAN(6.18 vs 15.78 @ 256x256),速度快30~64倍。
超越 BigGAN 在某些指标(尤其FID512x512,降到 7.32)。
多样性(CAS、Recall)几乎新SOTA(在不损失precison的情况下Recall更高 → 输出更多样化)。
4.3 图像编辑能力
(无需改architecture)
类条件编辑(Class-conditional editing):某个bounding box内换成另一类,外部背景保持。AR方法几乎做不到,MaskGIT天然支持。
Inpainting(补洞):Places2数据集下超过DeepFillv2、HiFill,接近CoModGAN。
Outpainting(外延): 超越Boundless、InfinityGAN等GAN方法,FID&IS更优,还能采多种seed生成多样扩展。
归根到底,这灵活性来自“mask+双向注意力”的并行预测能力。
4.4 Ablation Mask Scheduling
凹型(Cosine/Square)普遍好 → 因为能训练难例,又符合“先粗后细”。
存在“sweet spot”迭代步数,T太多可能反而降低多样性,T=8~12最好。
总结方法优势
速度优势: 迭代8步,速度比自回归快最高64倍。
质量优势: FID/IS/CAS全面超SOTA。
灵活编辑: 天然支持局部生成(编辑/补全/外延)。
简单训练: 无需GAN对抗,稳定。
可扩展性: 同一tokenizer+transformer可直接迁移分辨率/任务。