华为HCCL集合通信库AllGather算子全流程解析

简介
华为集合通信库HCCL(Huawei Collective Communication Library)是基于昇腾AI处理器的高性能集合通信库,提供单机多卡以及多机多卡间的数据并行、模型并行集合通信方案。
HCCL支持AllReduce、Broadcast、AllGather、ReduceScatter、AlltoAll等通信原语,Ring、Mesh、Halving-Doubling(HD)等通信算法,基于HCCS、RoCE和PCIe高速链路实现集合通信。
支持的产品型号
Atlas A3 训练系列产品/Atlas A3 推理系列产品
Atlas A2 训练系列产品
Atlas 训练系列产品
Atlas 300I Duo 推理卡
HCCL在系统中的位置
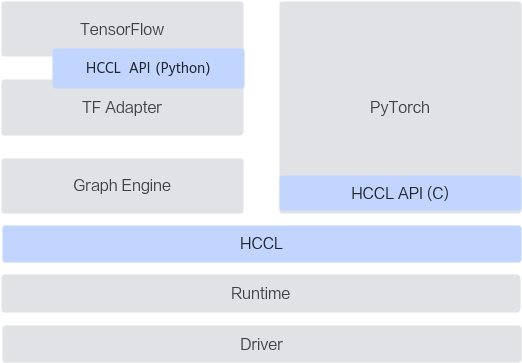
HCCL提供了C与Python两种语言的接口,其中C语言接口用于实现单算子模式下的框架适配,例如HCCL单算子API嵌入到PyTorch后端代码中,PyTorch用户直接使用PyTorch原生集合通信API,即可实现分布式能力;Python语言的接口用于实现图模式下的框架适配,例如TensorFlow网络基于HCCL的Python API实现分布式优化。
单算子模式与图模式都是神经网络模型的运行模式,其中
- 单算子模式的特点是每个计算操作依次下发,并立即执行。
- 图模式的特点是所有计算操作构造成一张图,以图的粒度下发执行。
HCCL软件架构
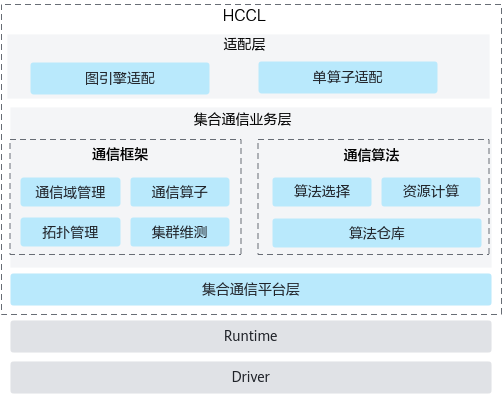
集合通信库软件架构分为三层:
- 适配层,图引擎与单算子适配,提供通信域管理及通信算子接口。
- 集合通信业务层,包含通信框架与通信算法两个模块:
- 通信框架:负责通信域管理,通信算子的业务串联,协同通信算法模块完成算法选择,协同通信平台模块完成资源申请并实现集合通信任务的下发。
- 通信算法:作为集合通信算法的承载模块,提供特定集合通信操作的资源计算,并根据通信域信息完成通信任务编排。
- 集合通信平台层,提供NPU之上与集合通信关联的资源抽象,并提供集合通信的相关维护、测试能力。
集合通信流程
分布式场景中,HCCL提供了服务器间高性能集合通信功能,其通信流程如图所示。
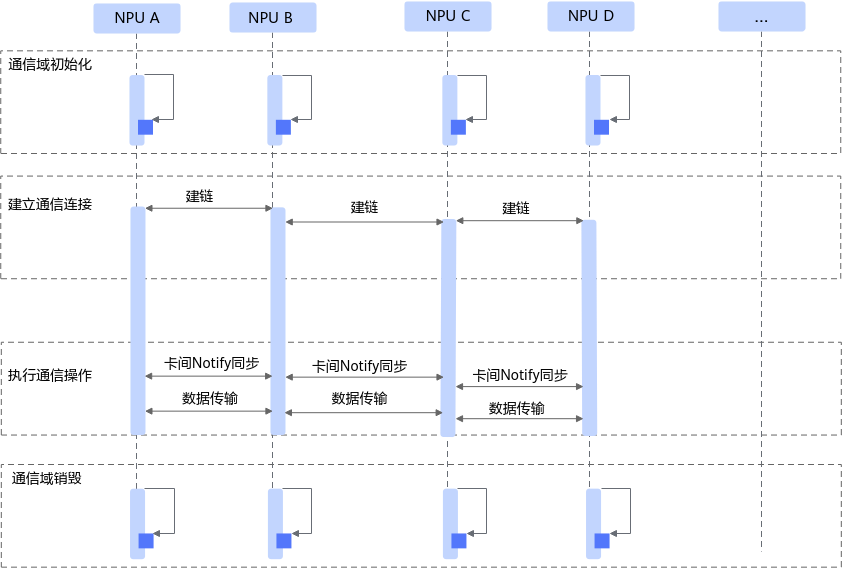
服务器间通信过程分为四个阶段:
- 通信域初始化:获取必要的集合通信配置参数并初始化通信域。
- 建立通信连接:建立socket连接并交换通信两端的通信参数和内存信息。
建立通信连接阶段,HCCL根据用户提供的集群信息并结合网络拓扑与其他NPU设备建链,交换用于通信的参数信息。如果在建链超时时间内未得到其他NPU设备的及时响应,会上报建链超时错误并退出业务进程。
- 执行通信操作:通过“等待-通知”机制同步设备执行状态,传递内存数据。
通信操作执行阶段,HCCL会将通信算法编排、内存访问等任务通过Runtime下发给昇腾设备的任务调度器,设备根据编排信息调度并执行任务。
- 通信域销毁:销毁通信域,释放通信资源。
集合通信算法概念介绍
针对同一个通信算子,随着网络拓扑、通信数据量、硬件资源等变化,往往会采用不同的通信算法,从而最大化集群通信性能。以AllGather算子举例,HCCL实现了Mesh、Ring、Recursive Halving-Doubling(RHD)、NHR(Nonuniform Hierarchical Ring)、NB(Nonuniform Bruck)等多种算法用于Server内和Server间的集合通信,通信操作执行时,HCCL会根据输入条件从算法仓中自动选择性能最佳的算法。
通信域
集合通信发生在一组通信对象上(比如一个NPU就是一个通信对象)。通信域是集合通信算子执行的上下文,管理对应的通信对象和通信所需的资源。
Rank
通信域中的每个通信对象称为一个Rank。
Memory
集合通信执行所需要的各种Buffer资源。
- Input Buffer:集合通信算子输入数据缓冲区。
- Output Buffer:集合通信算子输出数据缓冲区,存放算法计算结果。
- CCL Buffer:一组地址固定的Buffer,可被远端访问。单算子模式下,通信对象通过CCLBuffer来实现跨Rank的数据交换。CCL buffer和通信域绑定,通信域初始化的时候创建两块CCL buffer,分别称为CCL_In和CCL_Out。CCL_In和CCL_Out默认大小是200M Byte,可以通过环境变量HCCL_BUFFSIZE进行修改。同一个通信域内执行的集合通信算子都复用相同的CCL Buffer。
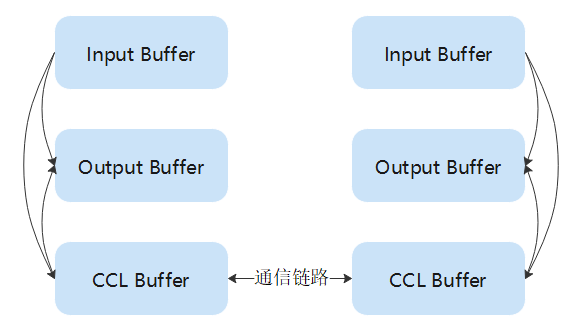
- Scratch Buffer:除了CCLBuffer,有些算法计算过程中需要额外的存储空间,这部分额外的存储空间,称为Scratch Buffer。
流
流(Stream)是NPU上的一种硬件资源,承载了待执行的Task序列。Task可以是一个DMA操作、一个同步操作或者一个NPU算子等。同一个流上的Task序列按顺序执行,不同流上的Task序列可并发执行。
- 主流:由Pytorch等训练框架调用集合通信API传入的stream对象称为主流。
- 从流:为了实现集合通信算法所需要的并行性而额外申请的stream对象称为从流。

上图展示了一条主流和一条从流,主从流之间通过Post/Wait这一组Task进行同步。主从流之间没有依赖关系时,Task可并行执行。如上图主流的TaskA、TaskB和从流的TaskX、TaskY可以是并行执行的。Post/Wait的具体含义会在后文给出。
Notify
Notify是NPU上的硬件资源,用来做同步。在集合通信中主要有两种作用:1)Rank内主从流之间的同步;2)跨Rank数据收发的同步。
和Notify有关的Task有两种:1)Post;2)Wait。
Post操作给对应的notify寄存器置1,并返回。如果对应的notify值已经是1,则不产生变化,直接返回。
Wait操作会等待对应的notify值变为1。条件满足后,将对应的notify值复位为0,并继续执行后续的Task。
- Rank内主从流同步示例:主流通知从流,实质是将notify1置位为1。从流通知主流,实质是将notify2置位为1。

- 跨Rank数据收发同步示例:与Rank内主从流同步类似,跨Rank的数据收发也需要同步。比如向远端Rank写数据前,得知道远端是否准备好接受数据的Buffer。关于跨Rank的同步,可参考下面关于Transport链路的章节。
Transport链路
要完成Rank间的数据通信需要先建立Transport链路,Transport链路分两种:1)SDMA链路,对应到HCCS/UB硬件连接;2)RDMA链路,对应到RoCE硬件连接。
- SDMA Transport链路的两端各有两种类型的notify,分别称为Ack、DataSignal;
- RDMA Transport链路的两端各有三种类型的notify,分别称为Ack、DataSiganl、DataAck;
每条Transport链路会申请各自的notify资源,不同的Transport之间不会复用notify。SDMA链路会申请四个notify,每端各两个;RDMA链路会申请六个notfy,每端各三个。
- SDMA数据收发同步:一次SDMA数据收发需要两组同步,如下图所示,分别使用了Ack和DataSignal两个notify。为了避免同一条链路上多次收发数据相互影响,同步需以Ack开始,以DataSignal结束。
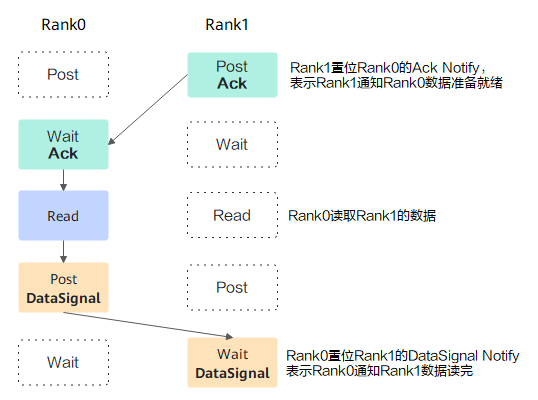
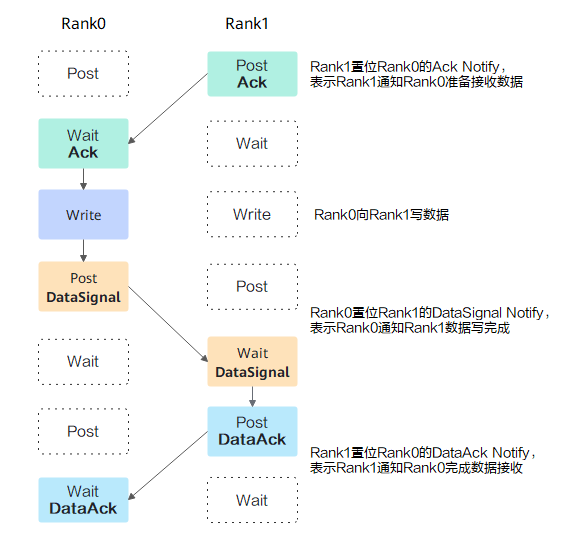
- RDMA数据收发同步:一次RDMA数据收发需要三组同步信号,如下图所示。这是因为RDMA操作在流上是异步执行的,所以Rank 0执行完Write和Post DataSignal之后,并不知道数据什么时候写完,因此需要Rank1 Wait DataSignal满足条件后,再给Rank 0发送一个DataAck同步信号,通知Rank0数据已经写完了。为了避免同一条链路上多次收发数据相互影响,同步需以Ack开始,以DataAck结束。
算法编写
算法注册与选择
- Executor 层注册(必须): Executor 是算法的执⾏⼊⼝和“总管”,负责资源计算和任务编排。任何⼀个新算法 都必须实现并注册其对应的 Executor ,否则框架将⽆法找到它。
- Template 层注册(可选): Template 层⽤于封装具体、可复⽤的通信模式(如Ring、Mesh)。算法的核⼼逻辑可以: 直接在 Executor 中实现。 封装成⼀个独⽴的 Template 类,再由 Executor 调⽤。
算法注册流程
第⼀步:Executor层⽂件创建与注册
创建Executor⽂件:
- coll_all_gather_new_executor.cc :实现⽂件
- coll_all_gather_new_executor.h :头⽂件
编译配置:
set(src_list
# ... 其他文件
${CMAKE_CURRENT_SOURCE_DIR}/coll_all_gather_new_executor.cc
)Executor注册:
REGISTER_EXEC("AllGatherNewExecutor", AllGatherNew, CollAllGatherNewExecutor);- 第⼀个参数:Executor的注册名称(字符串),该名称将在算法选择时使⽤。
- 第⼆个参数:算法类型标识符。
- 第三个参数:具体的Executor类名。
第⼆步:Template层⽂件创建与注册
创建Template⽂件:
- all_gather_new.cc :实现⽂件
- all_gather_new.h :头⽂件
编译配置:
set(src_list_pub
# ... 其他文件
${CMAKE_CURRENT_SOURCE_DIR}/all_gather_new.cc
)Template注册:
REGISTER_TEMPLATE(TemplateType::TEMPLATE_ALL_GATHER_NEW, AllGatherNew);- 第⼀个参数:模板类型枚举值(需要在 alg_template_base_pub.h 中定义)。
- 第⼆个参数:具体的Template类名。
第三步:模板类型定义
enum TemplateType {
// ... 现有的模板类型
TEMPLATE_ALL_GATHER_NEW = 126, // 新增的AllGatherNew模板类型
// ... 其他模板类型
};注册宏详解
REGISTER_EXEC 宏:
- ⽤于向Executor注册器中注册算法执⾏器。
- 使得框架能够通过算法名称(即注册的第⼀个参数)查找并创建对应的Executor实例。
- 在算法选择阶段,框架会根据 SelectAlg 函数返回的名称匹配相应的Executor。
REGISTER_TEMPLATE 宏:
- ⽤于向Template注册器中注册算法模板。
- Executor 在执⾏时,可以通过模板类型枚举值(如 TEMPLATE_ALL_GATHER_NEW )从注册器中获取对应的Template 实例,进⽽调⽤其实现的具体算法逻辑。
算法选择机制
AllGather算法选择
核⼼修改步骤:
- 定位SelectAlg函数:找到 AllGatherOperator::SelectAlg() 函数(约第36⾏)。
- 修改选择逻辑:为了调试和验证,我们可以暂时屏蔽掉原有的复杂选择逻辑,强制其返回我们新算法的名称。
HcclResult AllGatherOperator::SelectAlg(const std::string& tag, const OpParam& param,
std::string& algName, std::string& newTag)
{
// 单卡场景保持原有逻辑
if (userRankSize_ == 1 && (workflowMode_ ==
HcclWorkflowMode::HCCL_WORKFLOW_MODE_OP_BASE)) {
algName = "AllGatherSingleExecutor";
return HCCL_SUCCESS;
}
// 直接指定自定义算法(关键修改点)algName = "AllGatherNewExecutor"; // 此处必须与REGISTER_EXEC宏的第一个参数完全一致// 保留newTag生成逻辑
if (workflowMode_ == HcclWorkflowMode::HCCL_WORKFLOW_MODE_OPS_KERNEL_INFO_LIB) {
newTag = tag;
} else if (deviceType_ == DevType::DEV_TYPE_310P3) {
newTag = tag + algName;
} else {
AlgTypeLevel1 algType1 = algType_.algoLevel1;
auto level1Iter = HCCL_ALGO_LEVEL1_NAME_MAP.find(algType1);
CHK_PRT_RET(level1Iter == HCCL_ALGO_LEVEL1_NAME_MAP.end(), HCCL_ERROR("level1:
algType1[%u] is invalid.",
algType1), HCCL_E_INTERNAL);
newTag = tag + level1Iter->second + algName;
}
newTag += (param.aicpuUnfoldMode ? "_device" : "_host");
return HCCL_SUCCESS;
}选择流程总结:
算法选择请求 → Operator::SelectAlg() → [AllGather: SelectAlgforAllGather()] → 返回算法名称 → 框架查找对应Executor → 创建执行实例
Executor层
Executor层次结构
CollExecutorBase (最基础的基类)↓CollCommExecutor (通信执行器基类)↓CollAllGatherExecutor (AllGather算子基类)↓CollAllGatherMeshExecutor (具体的Mesh算法Executor实现)
各层的职责分⼯:
- CollAllGatherExecutor (基类):为所有AllGather算法提供了⼀个通⽤的执⾏框架。它实现了顶层的 Orchestrate() 函数,负责处理不同的⼯作流模式,并定义了所有派⽣类都需要实现的公共接⼝(纯虚函数) 和数据结构。
- CollAllGatherMeshExecutor (派⽣类):⼀个具体的算法Executor实现。它继承⾃
- CollAllGatherExecutor ,并专注于实现Mesh算法特有的逻辑,如资源计算、算法执⾏和 Template 选择。
基类实现分析
- 算法编排⼊⼝ ( Orchestrate ):统⼀的执⾏⼊⼝,开发者通常⽆需关⼼其内部复杂的模式判断。
- 公共⼯具函数:提供了数据切⽚计算、循环执⾏逻辑等常⽤功能。
- 统⼀接⼝定义:通过纯虚函数,为所有具体的AllGather算法实现定义了⼀套必须遵循的接⼝规范。
class CollAllGatherExecutor : public CollCommExecutor {
protected:
// 资源计算相关
virtual HcclResult CalcStreamNum(u32& streamNum) = 0;
virtual HcclResult CalcCommInfo(std::vector<LevelNSubCommTransport>& opTransport) = 0;
// 算法执行相关
virtual HcclResult KernelRun(const OpParam ¶m, ExecMem &execMem) = 0;
virtual u64 CalcLoopMaxCount(const u64 cclBuffSize, const u32 unitSize) = 0;
// 算法模板选择
virtual HcclResult SelectTempAlg(std::unique_ptr<AlgTemplateBase> &tempAlg, u32
rankSize) = 0;
};
具体算法实现分析
资源计算部分
// Stream数量计算
HcclResult CalcStreamNum(u32& streamNum) override {
u32 totalStreamNum = topoAttr_.deviceNumPerAggregation > 1U ?
topoAttr_.deviceNumPerAggregation - 1U : 1U;
streamNum = totalStreamNum - 1U; // Mesh算法使用 (设备数-1) 个从流
return HCCL_SUCCESS;
}
// 通信链路计算
HcclResult CalcCommInfo(std::vector<LevelNSubCommTransport>& opTransport) override {
// 设置内存类型
TransportMemType inputType, outputType;
CHK_RET(CalcTransportMemType(inputType, outputType));
算法执⾏部分
算法模板选择部分
// 计算Level0和Level1的通信信息
CHK_RET(CalcLevel0CommInfo(inputType, outputType, opTransport)); // Mesh连接
CHK_RET(CalcLevel1CommInfo(inputType, outputType, opTransport)); // 跨服务器连接
return HCCL_SUCCESS;
}算法执⾏部分
HcclResult KernelRun(const OpParam ¶m, ExecMem &execMem) override {
// 第一步:数据初始化 - 将input数据拷贝到output对应位置
// ...内存拷贝逻辑
// 第二步:Level0 Mesh算法执行
std::unique_ptr<AlgTemplateBase> level0TempAlg;
level0TempAlg = AlgTemplateRegistry::Instance().GetAlgTemplate(
TemplateType::TEMPLATE_ALL_GATHER_MESH, dispatcher_);
CHK_RET(RunTemplate(level0TempAlg, level0CommInfo));
// 第三步:Level1算法执行 (跨服务器)
std::unique_ptr<AlgTemplateBase> level1TempAlg;
CHK_RET(SelectTempAlg(level1TempAlg, level1RankSize));
CHK_RET(RunTemplate(level1TempAlg, level1CommInfo));
return HCCL_SUCCESS;
}算法模板选择部分
HcclResult SelectTempAlg(std::unique_ptr<AlgTemplateBase> &level1TempAlg, u32
level1RankSize) override {
if (level1RankSize > 1) {
if (algType_.algoLevel1 == AlgTypeLevel1::ALG_LEVEL1_RING) {
level1TempAlg = AlgTemplateRegistry::Instance().GetAlgTemplate(
TemplateType::TEMPLATE_ALL_GATHER_RING, dispatcher_);
} else if (algType_.algoLevel1 == AlgTypeLevel1::ALG_LEVEL1_NHR) {
level1TempAlg = AlgTemplateRegistry::Instance().GetAlgTemplate(
TemplateType::TEMPLATE_ALL_GATHER_NHR, dispatcher_);
} else {
// 默认使用Halving-Doubling算法
level1TempAlg = AlgTemplateRegistry::Instance().GetAlgTemplate(
TemplateType::TEMPLATE_ALL_GATHER_RECURSIVE_HALVING_DOUBLING, dispatcher_);
}
return HCCL_SUCCESS;
}
return HCCL_E_UNAVAIL;
}调⽤关系总结
Operator::SelectAlg()↓ 返回算法名称Framework查找并创建Executor实例↓CollAllGatherExecutor::Orchestrate() (基类统一入口)↓ 根据工作流模式选择执行路径CollAllGatherNewExecutor::KernelRun() (具体算法实现)↓ 调用Template执行具体算法AlgTemplate::RunAsync() (底层算法模板)↓底层通信接口 (link->TxAsync/RxAsync)
Template层
Template层组织结构
alg_template/├── alg_template_base.h/.cc # Template基类定义├── alg_template_base_pub.h # Template基类公共接口├── alg_template_register.h/.cc # Template注册机制├── temp_all_gather/ # AllGather算法模板│ ├── all_gather_mesh.cc/.h # Mesh算法实现│ ├── all_gather_ring.cc/.h # Ring算法实现│ └── ... # 其他AllGather变体├── temp_all_reduce/ # AllReduce算法模板└── ... # 其他算子的模板
Template基类结构
class AlgTemplateBase { // AlgTemplateBase是ExecutorBase的别名
public:
// 构造函数
explicit ExecutorBase(const HcclDispatcher dispatcher);
// 异步执行接口(核心纯虚函数)
virtual HcclResult RunAsync(const u32 rank, const u32 rankSize,
const std::vector<LINK> &links) = 0;
// 多种Prepare重载接口,用于从Executor接收参数
virtual HcclResult Prepare(DeviceMem &inputMem, DeviceMem &outputMem,
DeviceMem &scratchMem, const u64 count, const HcclDataType dataType,
const Stream &stream, const HcclReduceOp reductionOp, const u32 root,
const std::vector<Slice> &slices, const u64 baseOffset);
// Mesh算法专用Prepare接口
virtual HcclResult Prepare(std::vector<Stream> &meshStreams,
std::vector<std::shared_ptr<LocalNotify>> &meshSignal,
std::vector<std::shared_ptr<LocalNotify>> &meshSignalAux,
u32 userRank, HcomCollOpInfo *opInfo, u32 interRank, u32 interRankSize);
protected:
// 基础属性
DeviceMem inputMem_; // 输入内存
DeviceMem outputMem_; // 输出内存
DeviceMem scratchMem_; // 暂存内存
u64 count_; // 数据元素数量
HcclDataType dataType_; // 数据类型
Stream stream_; // 执行流
std::vector<Slice> slices_; // 数据切片信息
u64 baseOffset_; // 基址偏移
const HcclDispatcher dispatcher_; // 任务派发器
};Executor与Template调⽤关系
// 在CollAllGatherMeshExecutor::KernelRun中的调用示例
HcclResult CollAllGatherMeshExecutor::KernelRun(const OpParam ¶m, ExecMem &execMem) {
// 第一步:从注册器中获取算法模板实例
std::unique_ptr<AlgTemplateBase> level0TempAlg;
if (topoAttr_.deviceType == DevType::DEV_TYPE_910B) {
level0TempAlg = AlgTemplateRegistry::Instance().GetAlgTemplate(
TemplateType::TEMPLATE_ALL_GATHER_MESH_ATOMIC, dispatcher_);
} else {
level0TempAlg = AlgTemplateRegistry::Instance().GetAlgTemplate(
TemplateType::TEMPLATE_ALL_GATHER_MESH, dispatcher_);
}
// 第二步:通过Prepare接口为Template设置执行所需的环境和参数
CHK_RET(level0TempAlg->Prepare(algResResp_->slaveStreams, algResResp_->notifiesMain,
algResResp_->notifiesAux, topoAttr_.userRank, nullptr, commIndex, level0RankSize));
CHK_RET(level0TempAlg->Prepare(currentOutputMem, currentOutputMem, execMem.inputMem,
execMem.count * level0RankSize, param.DataDes.dataType, param.stream,
HCCL_REDUCE_RESERVED, LEVEL0_BRIDGE_RANK_ID, dataSegsSlice, baseOffset));
// 第三步:调用RunTemplate,最终会执行到Template的RunAsync函数
CHK_RET(RunTemplate(level0TempAlg, level0CommInfo));
return HCCL_SUCCESS;
}AllGather Mesh算法模板分析
类定义
class AllGatherMesh : public AlgTemplateBase {
public:
explicit AllGatherMesh(const HcclDispatcher dispatcher);
~AllGatherMesh();
// Mesh算法专用准备接口
HcclResult Prepare(std::vector<Stream> &meshStreams,
std::vector<std::shared_ptr<LocalNotify>> &meshSignal,
std::vector<std::shared_ptr<LocalNotify>> &meshSignalAux,
u32 userRank, HcomCollOpInfo *opInfo, u32 interRank, u32 interRankSize) override;
// 异步执行接口
HcclResult RunAsync(const u32 rank, const u32 rankSize,
const std::vector<LINK> &links) override;
private:
// 核心通信函数
HcclResult Tx(const LINK &link, const Slice &txSlice, const Slice &dstSlice, Stream
stream);
HcclResult Rx(const LINK &link, const Slice &srcSlice, const Slice &rxSlice, Stream
stream);
// AllGather算法实现
HcclResult RunAllGather(const std::vector<LINK> &links,
const std::vector<Slice> &outputSlices, const std::vector<Slice> &inputSlices);
// Mesh算法特有属性
std::vector<Stream> meshStreams_; // 多流并行执行
std::vector<std::shared_ptr<LocalNotify>> *meshSignal_; // 主流同步信号
std::vector<std::shared_ptr<LocalNotify>> *meshSignalAux_; // 从流同步信号
u32 interRank_; // 算法内rank
u32 interRankSize_; // 算法内rank总数
u32 userRank_; // 用户层rank
};核⼼算法实现
HcclResult AllGatherMesh::RunAllGather(const std::vector<LINK> &links,
const std::vector<Slice> &outputSlices, const std::vector<Slice> &inputSlices) {
Stream subStream;
HcclResult ret = HCCL_SUCCESS;
// Mesh算法:每轮与一个邻居交换数据
for (u32 round = 1; round < interRankSize_; round++) {
u32 dstRank = BackwardRank(interRank_, interRankSize_, round);
// 流选择:最后一轮使用主流,其他轮使用从流
subStream = (round == interRankSize_ - 1) ? stream_ : meshStreams_[round - 1];
// 1. 握手同步
CHK_RET(links[dstRank]->TxAck(subStream)); // 发送握手信号
CHK_RET(links[dstRank]->RxAck(subStream)); // 接收握手确认
// 2. 数据传输
CHK_RET(Tx(links[dstRank], inputSlices[interRank_], outputSlices[interRank_],
subStream));
CHK_RET(Rx(links[dstRank], inputSlices[dstRank], outputSlices[dstRank], subStream));
// 3. 完成同步
CHK_RET(ExecuteBarrier(links[dstRank], subStream));
CHK_RET(links[dstRank]->RxWaitDone(subStream));
CHK_RET(links[dstRank]->TxWaitDone(subStream));
}
return HCCL_SUCCESS;
}数据传输函数
// 发送数据
HcclResult AllGatherMesh::Tx(const LINK &link, const Slice &txSlice,
const Slice &dstSlice, Stream stream) {
DeviceMem srcMem = outputMem_.range(txSlice.offset, txSlice.size);
return link->TxAsync(UserMemType::OUTPUT_MEM, baseOffset_ + dstSlice.offset,
srcMem.ptr(), txSlice.size, stream);
}
// 接收数据
HcclResult AllGatherMesh::Rx(const LINK &link, const Slice &srcSlice,
const Slice &rxSlice, Stream stream) {
DeviceMem rcvMem = outputMem_.range(rxSlice.offset, rxSlice.size);
return link->RxAsync(UserMemType::OUTPUT_MEM, baseOffset_ + srcSlice.offset,
rcvMem.ptr(), rxSlice.size, stream);
}Template与Executor的协作总结
- 作为算法的“总指挥”,负责整体编排和分层调⽤。
- 计算资源、管理内存。
- 根据需求选择要执⾏的 Template 。
- 作为算法的“执⾏者”,实现具体的通信逻辑。
- 处理底层的数据传输和同步细节。
协作流程图:
Executor::KernelRun()↓ 获取Template实例AlgTemplateRegistry::GetAlgTemplate()↓ 设置执行参数AlgTemplate::Prepare()↓ 执行算法Executor::RunTemplate()↓AlgTemplate::RunAsync()↓底层通信接口 (link->TxAsync/RxAsync)