34、模型微调技术实战 - LoRA参数高效微调全流程
核心学习目标:掌握大模型微调的核心技术,实现LoRA等参数高效微调方法,理解微调过程的关键技术细节,建立在有限资源下适配大模型的能力。
模型微调是将预训练的大模型适配到特定任务的关键技术。LoRA(Low-Rank Adaptation)作为参数高效微调的代表方法,通过低秩矩阵分解大幅减少可训练参数数量,在保持性能的同时显著降低计算和存储成本。
34.1 LoRA技术原理:低秩适配的数学基础
这个渲染有点问题,我用我本地的渲染一下
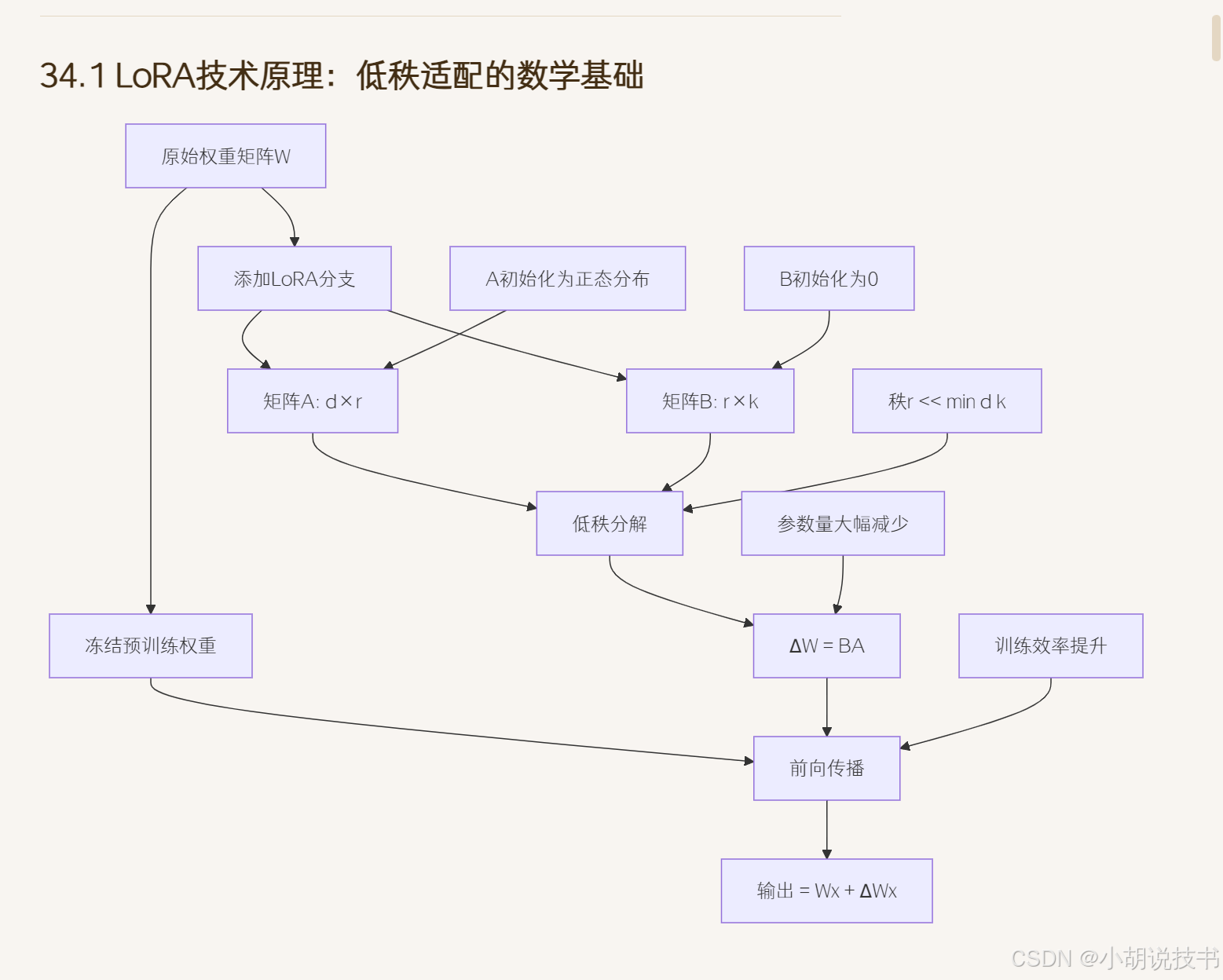
> LoRA的数学原理与设计思想
低秩分解的理论基础建立在大模型权重矩阵的内在秩结构假设之上。对于一个d×k的权重矩阵W,LoRA假设其微调时的权重更新ΔW具有低秩结构,可以分解为ΔW = B×A,其中A是d×r矩阵,B是r×k矩阵,r<<min(d,k)是秩参数。这种分解将原本需要d×k个参数的更新降至r×(d+k)个参数,当r远小于d和k时,参数量大幅减少。
秩参数r的选择策略直接影响微调效果和计算效率的平衡。r值越小,参数量越少,训练越快,但表达能力有限;r值越大,表达能力强,但参数量增加。经验上,r=4-64在多数任务上效果良好。最优r值通常与任务复杂度、数据规模、原模型大小相关。可以通过网格搜索或逐步增加r值的方式找到最佳平衡点。
缩放参数α的作用机制控制LoRA分支对原始输出的贡献程度。最终输出为:output = Wx + (α/r)×ΔW×x,其中α是可调节的缩放因子。α/r的比值决定了LoRA更新的影响强度。较小的α值使微调更保守,保留更多预训练知识;较大的α值使微调更激进,更快适应新任务。典型设置α=r或α=2r。
参数初始化的数学考量确保训练开始时LoRA分支不改变原模型输出。标准做法是A矩阵使用高斯随机初始化A~N(0,σ²),B矩阵初始化为零矩阵B=0。这样初始时ΔW=BA=0,保证微调开始时输出与原模型完全一致。σ的选择遵循Xavier或He初始化原则,通常σ=1/√r。
34.2 微调数据准备:高质量数据的构建流程
> 微调数据构建的关键环节
数据清洗与预处理是构建高质量微调数据集的基础环节。原始数据通常包含重复内容、格式错误、编码问题等噪声。去重处理需要考虑精确匹配和近似匹配,使用哈希算法检测完全重复,使用编辑距离或语义相似度检测近似重复。文本清洗包括HTML标签移除、特殊字符处理、编码统一等步骤。标准化处理涉及大小写统一、标点符号规范、数字格式化等操作。
质量过滤的多维度标准确保训练数据的高质量。长度过滤设置合理的最短和最长限制,过短的文本信息不足,过长的文本可能包含多个主题。质量评分可以基于困惑度、语法正确性、信息密度等指标。主题相关性检查使用关键词匹配、文本分类或语义相似度确保数据与目标任务匹配。语言质量评估检测语法错误、拼写错误、表达流畅性等问题。
数据格式转换的任务适配将原始文本转换为模型可直接使用的训练格式。对话任务需要构建轮次结构,区分用户输入和助手回复。问答任务需要明确问题和答案的边界,添加适当的分隔符。摘要任务需要配对原文和摘要,确保长度比例合理。指令跟随任务需要构建指令-输入-输出的三元组结构。特殊token的添加要遵循模型的预训练格式。
负样本构造的策略设计提升模型的判别能力和鲁棒性。困难负样本通过修改正样本的关键信息生成,如改变事实、调换逻辑关系、插入错误信息等。对比样本展示相似但不同的场景,帮助模型学习细粒度区分。错误示例通过引入常见错误模式训练模型避免类似问题。负样本的比例和难度需要careful调节,过多或过难的负样本可能影响训练稳定性。
34.3 微调训练优化:参数调节与训练策略
> 微调训练的参数优化策略
学习率调度的精细设计是微调成功的关键因素。微调的学习率通常比预训练小1-2个数量级,典型范围在1e-5到1e-3之间。预热阶段从零或很小的学习率线性增加到目标值,持续steps通常为总训练steps的5%-10%,避免初期梯度过大破坏预训练权重。衰减策略可选择余弦退火、指数衰减或多步衰减,余弦退火在微调中表现通常最佳。层级学习率对不同层设置不同的学习率,一般越靠近输出层学习率越大,体现任务相关性的梯度。
批大小配置的内存与效果平衡影响训练稳定性和收敛速度。较大的批大小提供更稳定的梯度估计,但消耗更多内存。微调中batch_size通常设置为8-32,比预训练更小。梯度累积技术在内存受限时模拟大批训练:将多个小批的梯度累积后再更新参数,累积步数通常为2-8。动态batch_size根据序列长度自动调整,长序列用小批大小,短序列用大批大小。
正则化技术的过拟合防护在小数据集微调中尤为重要。权重衰减系数通常设置为1e-4到1e-2,比预训练更强,防止过拟合。Dropout比例可能需要调整,任务相关层的dropout可以略微增加。早停机制监控验证集性能,连续N个epoch(通常3-5个)无改善时停止训练。标签平滑和数据增强等技术也有助于提升泛化能力。
训练轮数的动态控制平衡充分学习与过拟合风险。微调通常需要较少的训练轮数,1-10个epoch即可。小数据集需要更多轮数充分学习,大数据集可能1-2轮就足够。学习率衰减和验证集监控帮助确定最优停止点。渐进式微调策略从浅层到深层逐步解冻模型参数,可以提升微调效果。
34.4 微调效果分析:全面评估微调性能
> 微调效果的多维度评估体系
定量指标的全面对比提供微调效果的客观衡量。任务特定指标如分类任务的准确率、召回率、F1分数,生成任务的BLEU、ROUGE分数等。通用指标包括困惑度变化、损失函数下降曲线、收敛速度统计。基线对比包括原始模型性能、全参数微调效果、其他PEFT方法对比。统计显著性检验确保性能提升的可靠性,通过多次运行计算置信区间。
定性效果的深入分析揭示微调对模型行为的具体影响。样本质量检查通过人工评估或自动评估工具分析生成文本的流畅性、相关性、准确性。错误案例分析识别微调后的典型失败模式,如过拟合特定模式、灾难性遗忘、偏见放大等问题。生成多样性评估检查微调是否降低了输出的多样性,避免模型过度专门化。
参数效率的量化分析体现PEFT方法的核心优势。可训练参数比例计算LoRA参数占总参数的百分比,通常在0.1%-1%之间。训练时间对比包括每个epoch的训练时长、总训练时间、收敛所需步数等。内存消耗分析涵盖峰值内存使用、平均内存占用、相比全参数微调的节省比例。推理速度测试确保微调不会显著影响模型的推理效率。
收敛性分析与稳定性评估监控训练过程的健康状况。损失曲线分析检查是否存在震荡、平台期、突然上升等异常现象。梯度范数统计监控梯度是否稳定,避免梯度爆炸或消失。参数更新幅度跟踪LoRA参数的变化程度,确保参数在合理范围内更新。多次运行的一致性检验评估微调过程的稳定性和可重复性。
34.5 多任务微调:知识共享与迁移学习
> 多任务微调的架构设计与训练策略
任务特定LoRA的参数组织实现高效的多任务适配。每个任务配备独立的LoRA参数组{A_i, B_i},共享相同的预训练backbone。任务路由机制根据输入的任务标识选择对应的LoRA参数。参数隔离确保不同任务的梯度更新不会相互干扰。共享参数在底层捕获通用语言特征,任务特定参数在高层处理专门化需求。
联合训练的批次调度策略平衡多任务的学习进度。交替训练策略在不同epoch中轮换任务,确保每个任务都得到充分训练。混合批次将不同任务的样本组合在同一批次中,需要careful处理不同任务的损失计算和归一化。任务采样权重可以根据数据量、任务难度、重要性等因素动态调整。
知识迁移与干扰的平衡机制是多任务学习的核心挑战。正向迁移通过共享特征提升相关任务的性能,负向干扰可能导致任务间相互影响。任务相似性分析帮助识别互补任务和冲突任务。梯度手术技术在冲突方向上修正梯度,减少负向干扰。任务权重自适应调整学习过程中各任务的重要性。
课程学习的渐进式训练从简单任务开始逐步增加复杂任务。任务难度排序可以基于数据复杂度、标注质量、学习曲线等指标。渐进式解冻策略先训练简单任务,再逐步加入复杂任务。辅助任务设计帮助主任务获得更好的特征表示。元学习框架学习如何快速适配新任务。
34.6 完整LoRA微调系统实现

import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
import json
import os
import logging
from typing import Dict, List, Optional, Tuple, Union
from dataclasses import dataclass
import math
from collections import defaultdict
import matplotlib.pyplot as plt# 设置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)@dataclass
class LoRAConfig:"""LoRA配置类"""r: int = 8 # LoRA秩,控制参数量和表达能力lora_alpha: float = 16 # LoRA缩放参数,通常设为r的1-2倍lora_dropout: float = 0.1 # LoRA层的dropout概率target_modules: List[str] = None # 应用LoRA的目标模块列表bias: str = "none" # 偏置处理策略: "none", "all", "lora_only"task_type: str = "CAUSAL_LM" # 任务类型标识def __post_init__(self):if self.target_modules is None:# 默认应用到注意力层的权重矩阵self.target_modules = ["q_proj", "k_proj", "v_proj", "o_proj"]class LoRALinear(nn.Module):"""LoRA线性层实现,在原始Linear层基础上添加低秩适配"""def __init__(self,in_features: int,out_features: int,r: int = 8,lora_alpha: float = 16,lora_dropout: float = 0.1,bias: bool = True):"""初始化LoRA线性层Args:in_features: 输入特征维度out_features: 输出特征维度 r: LoRA秩参数lora_alpha: 缩放参数lora_dropout: dropout概率bias: 是否使用偏置"""super().__init__()self.in_features = in_featuresself.out_features = out_featuresself.r = rself.lora_alpha = lora_alphaself.scaling = lora_alpha / r # 计算缩放因子# 原始线性层(权重冻结)self.base_layer = nn.Linear(in_features, out_features, bias=bias)# LoRA参数:A矩阵和B矩阵self.lora_A = nn.Parameter(torch.zeros(r, in_features))self.lora_B = nn.Parameter(torch.zeros(out_features, r))# LoRA专用的dropoutself.lora_dropout = nn.Dropout(lora_dropout)# 初始化LoRA参数self.reset_lora_parameters()# 冻结基础层参数for param in self.base_layer.parameters():param.requires_grad = Falselogger.debug(f"创建LoRA层: {in_features}->{out_features}, rank={r}, alpha={lora_alpha}")def reset_lora_parameters(self):"""初始化LoRA参数使用标准初始化策略:A~N(0,σ²), B=0"""# A矩阵使用Kaiming uniform初始化nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))# B矩阵初始化为零,确保初始时ΔW = B@A = 0nn.init.zeros_(self.lora_B)def forward(self, x: torch.Tensor) -> torch.Tensor:"""LoRA前向传播输出 = 基础层输出 + LoRA适配输出Args:x: 输入张量 [batch_size, ..., in_features]Returns:输出张量 [batch_size, ..., out_features]"""# 基础层的输出(冻结参数)base_output = self.base_layer(x)# LoRA分支的输出# x -> dropout -> A -> B -> scalinglora_output = self.lora_dropout(x) @ self.lora_A.T # (batch, r)lora_output = lora_output @ self.lora_B.T # (batch, out_features)lora_output = lora_output * self.scaling # 应用缩放return base_output + lora_outputdef get_lora_parameters(self) -> Dict[str, torch.Tensor]:"""获取LoRA参数字典"""return {'lora_A': self.lora_A,'lora_B': self.lora_B}def load_lora_parameters(self, state_dict: Dict[str, torch.Tensor]):"""加载LoRA参数"""self.lora_A.data.copy_(state_dict['lora_A'])self.lora_B.data.copy_(state_dict['lora_B'])class LoRAModel(nn.Module):"""支持LoRA微调的模型包装器"""def __init__(self, base_model: nn.Module, lora_config: LoRAConfig):"""初始化LoRA模型Args:base_model: 基础预训练模型lora_config: LoRA配置"""super().__init__()self.base_model = base_modelself.lora_config = lora_configself.lora_modules = {}# 应用LoRA到指定模块self._inject_lora_layers()# 计算参数统计self._compute_parameter_stats()logger.info(f"LoRA模型初始化完成,应用到{len(self.lora_modules)}个模块")def _inject_lora_layers(self):"""将指定的Linear层替换为LoRALinear层"""for name, module in self.base_model.named_modules():# 检查是否是目标模块if any(target in name for target in self.lora_config.target_modules):if isinstance(module, nn.Linear):# 创建对应的LoRA层lora_layer = LoRALinear(in_features=module.in_features,out_features=module.out_features,r=self.lora_config.r,lora_alpha=self.lora_config.lora_alpha,lora_dropout=self.lora_config.lora_dropout,bias=module.bias is not None)# 复制原始权重lora_layer.base_layer.weight.data.copy_(module.weight.data)if module.bias is not None:lora_layer.base_layer.bias.data.copy_(module.bias.data)# 替换模块parent_name = '.'.join(name.split('.')[:-1])child_name = name.split('.')[-1]parent_module = self.base_model.get_submodule(parent_name) if parent_name else self.base_modelsetattr(parent_module, child_name, lora_layer)self.lora_modules[name] = lora_layerlogger.debug(f"将{name}替换为LoRA层")def _compute_parameter_stats(self):"""计算参数统计信息"""total_params = sum(p.numel() for p in self.base_model.parameters())trainable_params = sum(p.numel() for p in self.base_model.parameters() if p.requires_grad)self.total_params = total_paramsself.trainable_params = trainable_paramsself.trainable_percentage = 100 * trainable_params / total_paramslogger.info(f"参数统计:")logger.info(f" 总参数: {total_params:,}")logger.info(f" 可训练参数: {trainable_params:,}")logger.info(f" 可训练比例: {self.trainable_percentage:.4f}%")def forward(self, *args, **kwargs):"""前向传播,直接调用基础模型"""return self.base_model(*args, **kwargs)def save_lora_weights(self, save_path: str):"""保存LoRA权重到文件Args:save_path: 保存路径"""lora_state_dict = {}for name, module in self.lora_modules.items():lora_params = module.get_lora_parameters()for param_name, param_tensor in lora_params.items():lora_state_dict[f"{name}.{param_name}"] = param_tensor.cpu()torch.save({'lora_state_dict': lora_state_dict,'lora_config': self.lora_config,'parameter_stats': {'total_params': self.total_params,'trainable_params': self.trainable_params,'trainable_percentage': self.trainable_percentage}}, save_path)logger.info(f"LoRA权重已保存到: {save_path}")def load_lora_weights(self, load_path: str):"""从文件加载LoRA权重Args:load_path: 加载路径"""checkpoint = torch.load(load_path, map_location='cpu')lora_state_dict = checkpoint['lora_state_dict']for name, module in self.lora_modules.items():module_params = {}for param_name in ['lora_A', 'lora_B']:key = f"{name}.{param_name}"if key in lora_state_dict:module_params[param_name] = lora_state_dict[key]if module_params:module.load_lora_parameters(module_params)logger.info(f"LoRA权重已从{load_path}加载")class FineTuningDataset(Dataset):"""微调数据集类"""def __init__(self,data: List[Dict],tokenizer,max_length: int = 512,task_type: str = "instruction_following"):"""初始化微调数据集Args:data: 数据列表,每个元素包含input和output字段tokenizer: 分词器max_length: 最大序列长度task_type: 任务类型"""self.data = dataself.tokenizer = tokenizerself.max_length = max_lengthself.task_type = task_type# 预处理数据self.processed_data = self._preprocess_data()logger.info(f"数据集初始化完成,包含{len(self.processed_data)}个样本")def _preprocess_data(self) -> List[Dict]:"""预处理数据,转换为训练格式"""processed = []for item in self.data:if self.task_type == "instruction_following":# 指令跟随格式:指令 + 输入 -> 输出instruction = item.get('instruction', '')input_text = item.get('input', '')output_text = item.get('output', '')if instruction:prompt = f"指令: {instruction}\n"if input_text:prompt += f"输入: {input_text}\n"prompt += "输出: "else:prompt = input_text if input_text else ""processed.append({'input_text': prompt,'target_text': output_text,'full_text': prompt + output_text})elif self.task_type == "conversation":# 对话格式处理messages = item.get('messages', [])conversation = ""for msg in messages:role = msg.get('role', 'user')content = msg.get('content', '')conversation += f"{role}: {content}\n"# 假设最后一条是目标回复if messages:target = messages[-1].get('content', '')input_text = conversation[:-len(f"{messages[-1]['role']}: {target}\n")]processed.append({'input_text': input_text,'target_text': target,'full_text': conversation})return processeddef __len__(self):return len(self.processed_data)def __getitem__(self, idx):"""获取单个训练样本Returns:包含input_ids, attention_mask, labels的字典"""item = self.processed_data[idx]# 编码完整文本full_encoding = self.tokenizer(item['full_text'],max_length=self.max_length,padding='max_length',truncation=True,return_tensors='pt')# 编码输入部分,用于确定labels的maskinput_encoding = self.tokenizer(item['input_text'],max_length=self.max_length,padding='max_length',truncation=True,return_tensors='pt')input_ids = full_encoding['input_ids'].squeeze(0)attention_mask = full_encoding['attention_mask'].squeeze(0)# 创建labels,只有目标输出部分计算损失labels = input_ids.clone()input_length = (input_encoding['attention_mask'].squeeze(0) == 1).sum().item()labels[:input_length] = -100 # 忽略输入部分的损失return {'input_ids': input_ids,'attention_mask': attention_mask,'labels': labels}class LoRATrainer:"""LoRA微调训练器"""def __init__(self,model: LoRAModel,train_dataset: Dataset,val_dataset: Optional[Dataset] = None,learning_rate: float = 1e-4,batch_size: int = 8,gradient_accumulation_steps: int = 1,warmup_steps: int = 100,max_steps: int = 1000,weight_decay: float = 0.01,logging_steps: int = 50,eval_steps: int = 200,save_steps: int = 500,output_dir: str = "./lora_output"):"""初始化LoRA训练器Args:model: LoRA模型train_dataset: 训练数据集val_dataset: 验证数据集learning_rate: 学习率batch_size: 批大小gradient_accumulation_steps: 梯度累积步数warmup_steps: 预热步数max_steps: 最大训练步数weight_decay: 权重衰减logging_steps: 日志记录间隔eval_steps: 评估间隔save_steps: 保存间隔output_dir: 输出目录"""self.model = modelself.train_dataset = train_datasetself.val_dataset = val_dataset# 训练参数self.learning_rate = learning_rateself.batch_size = batch_sizeself.gradient_accumulation_steps = gradient_accumulation_stepsself.warmup_steps = warmup_stepsself.max_steps = max_stepsself.weight_decay = weight_decay# 日志和保存参数self.logging_steps = logging_stepsself.eval_steps = eval_stepsself.save_steps = save_stepsself.output_dir = output_dir# 创建输出目录os.makedirs(output_dir, exist_ok=True)# 设置设备self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.model.to(self.device)# 创建数据加载器self.train_dataloader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=0)if val_dataset:self.val_dataloader = DataLoader(val_dataset,batch_size=batch_size,shuffle=False,num_workers=0)# 设置优化器和调度器self._setup_optimizer_and_scheduler()# 训练统计self.global_step = 0self.epoch = 0self.best_eval_loss = float('inf')self.training_logs = []logger.info("LoRA训练器初始化完成")logger.info(f"设备: {self.device}")logger.info(f"训练样本数: {len(train_dataset)}")logger.info(f"批大小: {batch_size}, 梯度累积: {gradient_accumulation_steps}")logger.info(f"有效批大小: {batch_size * gradient_accumulation_steps}")def _setup_optimizer_and_scheduler(self):"""设置优化器和学习率调度器"""# 只优化LoRA参数trainable_params = [p for p in self.model.parameters() if p.requires_grad]self.optimizer = optim.AdamW(trainable_params,lr=self.learning_rate,weight_decay=self.weight_decay,betas=(0.9, 0.999),eps=1e-8)# 线性预热 + 余弦退火调度器def lr_lambda(step):if step < self.warmup_steps:return step / self.warmup_stepselse:progress = (step - self.warmup_steps) / (self.max_steps - self.warmup_steps)return 0.5 * (1 + math.cos(math.pi * progress))self.scheduler = optim.lr_scheduler.LambdaLR(self.optimizer, lr_lambda)logger.info(f"优化器: AdamW, 学习率: {self.learning_rate}")logger.info(f"预热步数: {self.warmup_steps}, 总步数: {self.max_steps}")def train_step(self, batch: Dict[str, torch.Tensor]) -> float:"""执行单个训练步骤Args:batch: 训练批次数据Returns:损失值"""self.model.train()# 将数据移到设备input_ids = batch['input_ids'].to(self.device)attention_mask = batch['attention_mask'].to(self.device)labels = batch['labels'].to(self.device)# 前向传播outputs = self.model(input_ids=input_ids,attention_mask=attention_mask)# 计算损失(假设模型返回logits)if hasattr(outputs, 'logits'):logits = outputs.logitselse:logits = outputs# 计算交叉熵损失loss = F.cross_entropy(logits.view(-1, logits.size(-1)),labels.view(-1),ignore_index=-100)# 梯度累积loss = loss / self.gradient_accumulation_stepsloss.backward()return loss.item() * self.gradient_accumulation_stepsdef evaluate(self) -> Dict[str, float]:"""在验证集上评估模型Returns:评估指标字典"""if not self.val_dataset:return {}self.model.eval()total_loss = 0.0total_samples = 0with torch.no_grad():for batch in self.val_dataloader:input_ids = batch['input_ids'].to(self.device)attention_mask = batch['attention_mask'].to(self.device)labels = batch['labels'].to(self.device)outputs = self.model(input_ids=input_ids,attention_mask=attention_mask)if hasattr(outputs, 'logits'):logits = outputs.logitselse:logits = outputsloss = F.cross_entropy(logits.view(-1, logits.size(-1)),labels.view(-1),ignore_index=-100)total_loss += loss.item() * input_ids.size(0)total_samples += input_ids.size(0)avg_loss = total_loss / total_samplesperplexity = math.exp(avg_loss)return {'eval_loss': avg_loss,'eval_perplexity': perplexity}def train(self):"""主训练循环"""logger.info("开始LoRA微调训练...")self.model.train()accumulated_loss = 0.0while self.global_step < self.max_steps:for batch in self.train_dataloader:# 训练步骤step_loss = self.train_step(batch)accumulated_loss += step_loss# 梯度累积和参数更新if (self.global_step + 1) % self.gradient_accumulation_steps == 0:# 梯度裁剪torch.nn.utils.clip_grad_norm_([p for p in self.model.parameters() if p.requires_grad],max_norm=1.0)# 更新参数self.optimizer.step()self.scheduler.step()self.optimizer.zero_grad()# 记录日志if self.global_step % self.logging_steps == 0:avg_loss = accumulated_loss / self.logging_stepscurrent_lr = self.scheduler.get_last_lr()[0]logger.info(f"Step {self.global_step:6d} | "f"Loss: {avg_loss:.4f} | "f"LR: {current_lr:.2e} | "f"PPL: {math.exp(avg_loss):.2f}")self.training_logs.append({'step': self.global_step,'loss': avg_loss,'learning_rate': current_lr,'perplexity': math.exp(avg_loss)})accumulated_loss = 0.0# 评估if self.global_step % self.eval_steps == 0:eval_results = self.evaluate()if eval_results:logger.info(f"评估结果: {eval_results}")# 保存最佳模型if eval_results['eval_loss'] < self.best_eval_loss:self.best_eval_loss = eval_results['eval_loss']self.save_model(os.path.join(self.output_dir, "best_model.pt"))# 定期保存if self.global_step % self.save_steps == 0:self.save_model(os.path.join(self.output_dir, f"checkpoint_{self.global_step}.pt"))self.global_step += 1if self.global_step >= self.max_steps:break# 保存最终模型self.save_model(os.path.join(self.output_dir, "final_model.pt"))# 绘制训练曲线self.plot_training_curves()logger.info("LoRA微调训练完成!")def save_model(self, save_path: str):"""保存模型检查点"""self.model.save_lora_weights(save_path)logger.info(f"模型已保存到: {save_path}")def plot_training_curves(self):"""绘制训练曲线"""if not self.training_logs:returnsteps = [log['step'] for log in self.training_logs]losses = [log['loss'] for log in self.training_logs]lrs = [log['learning_rate'] for log in self.training_logs]ppls = [log['perplexity'] for log in self.training_logs]fig, axes = plt.subplots(2, 2, figsize=(15, 10))fig.suptitle('LoRA Fine-tuning Training Curves', fontsize=16)# 损失曲线axes[0, 0].plot(steps, losses)axes[0, 0].set_title('Training Loss')axes[0, 0].set_xlabel('Step')axes[0, 0].set_ylabel('Loss')axes[0, 0].grid(True)# 困惑度曲线axes[0, 1].plot(steps, ppls)axes[0, 1].set_title('Perplexity')axes[0, 1].set_xlabel('Step')axes[0, 1].set_ylabel('PPL')axes[0, 1].grid(True)# 学习率曲线axes[1, 0].plot(steps, lrs)axes[1, 0].set_title('Learning Rate')axes[1, 0].set_xlabel('Step')axes[1, 0].set_ylabel('LR')axes[1, 0].grid(True)# 损失平滑曲线if len(losses) > 10:window_size = min(50, len(losses) // 10)smoothed_losses = [sum(losses[max(0, i-window_size):i+1]) / min(i+1, window_size)for i in range(len(losses))]axes[1, 1].plot(steps, smoothed_losses)axes[1, 1].set_title(f'Smoothed Loss (window={window_size})')axes[1, 1].set_xlabel('Step')axes[1, 1].set_ylabel('Smoothed Loss')axes[1, 1].grid(True)plt.tight_layout()save_path = os.path.join(self.output_dir, 'training_curves.png')plt.savefig(save_path, dpi=150, bbox_inches='tight')logger.info(f"训练曲线已保存到: {save_path}")plt.show()# 演示代码
def demo_lora_fine_tuning():"""演示LoRA微调的完整流程"""logger.info("=== LoRA微调演示 ===")# 模拟基础模型(实际使用时替换为真实的预训练模型)class MockTransformer(nn.Module):def __init__(self, vocab_size=10000, d_model=512, nhead=8, num_layers=6):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model)self.transformer = nn.Transformer(d_model=d_model,nhead=nhead,num_encoder_layers=num_layers,num_decoder_layers=num_layers,batch_first=True)# 添加一些线性层用于LoRA演示self.q_proj = nn.Linear(d_model, d_model)self.k_proj = nn.Linear(d_model, d_model)self.v_proj = nn.Linear(d_model, d_model)self.o_proj = nn.Linear(d_model, d_model)self.lm_head = nn.Linear(d_model, vocab_size)def forward(self, input_ids, attention_mask=None):x = self.embedding(input_ids)# 简化的前向传播x = self.o_proj(self.v_proj(x))logits = self.lm_head(x)return logits# 创建基础模型base_model = MockTransformer()# 配置LoRAlora_config = LoRAConfig(r=8,lora_alpha=16,lora_dropout=0.1,target_modules=["q_proj", "k_proj", "v_proj", "o_proj"])# 创建LoRA模型lora_model = LoRAModel(base_model, lora_config)# 模拟分词器class MockTokenizer:def __init__(self, vocab_size=10000):self.vocab_size = vocab_sizedef __call__(self, text, max_length=512, padding='max_length', truncation=True, return_tensors='pt'):# 简单的mock编码tokens = [hash(char) % self.vocab_size for char in text[:max_length]]if padding == 'max_length':tokens = tokens + [0] * (max_length - len(tokens))return {'input_ids': torch.tensor([tokens], dtype=torch.long),'attention_mask': torch.tensor([[1] * len(text[:max_length]) + [0] * max(0, max_length - len(text))], dtype=torch.long)}tokenizer = MockTokenizer()# 创建模拟数据集train_data = [{'instruction': '翻译以下英文为中文','input': 'Hello, how are you?','output': '你好,你好吗?'},{'instruction': '总结以下文本','input': '这是一个很长的文本,需要总结...','output': '这是总结内容。'},{'instruction': '回答问题','input': '什么是人工智能?','output': '人工智能是计算机科学的一个分支...'}] * 50 # 重复创建更多样本# 创建数据集train_dataset = FineTuningDataset(data=train_data,tokenizer=tokenizer,max_length=256,task_type="instruction_following")# 创建训练器trainer = LoRATrainer(model=lora_model,train_dataset=train_dataset,learning_rate=1e-4,batch_size=4,gradient_accumulation_steps=2,warmup_steps=50,max_steps=500,logging_steps=25,eval_steps=100,save_steps=250,output_dir="./demo_lora_output")logger.info("开始演示训练(由于使用mock模型,实际效果有限)...")# 由于是演示,我们只运行几个步骤logger.info("参数统计:")logger.info(f"总参数: {lora_model.total_params:,}")logger.info(f"可训练参数: {lora_model.trainable_params:,}")logger.info(f"参数效率: {lora_model.trainable_percentage:.4f}%")logger.info("LoRA层信息:")for name, module in lora_model.lora_modules.items():logger.info(f" {name}: rank={module.r}, alpha={module.lora_alpha}")logger.info("=== 演示完成 ===")logger.info("在实际使用中,请替换为真实的预训练模型和数据集")if __name__ == "__main__":demo_lora_fine_tuning()
34.7 实战项目总结
通过本课程的学习,你已经掌握了LoRA微调的完整技术栈。这个实现不仅包含了LoRA的核心算法,还提供了完整的训练框架和效果分析工具。
核心技术要点回顾:
- LoRA通过低秩分解大幅减少可训练参数,实现参数高效微调
- 合理的参数初始化和缩放策略确保微调的稳定性和有效性
- 微调数据的质量直接影响最终效果,需要careful的预处理和质量控制
- 学习率调度和正则化技术帮助平衡微调效果与过拟合风险
- 全面的效果评估体系有助于理解和改进微调策略
工程实践经验:
- LoRA的秩参数r需要根据任务复杂度和数据规模调优
- 目标模块的选择影响微调效果,通常聚焦于注意力层
- 梯度累积技术在内存受限环境下实现大批量训练效果
- 定期的模型保存和效果监控确保训练过程的可控性