【Redis】-- 缓存
文章目录
- 1. Redis应用--缓存
- 1.1 什么是缓存
- 1.2 使用Redis作为缓存
- 1.3 缓存的更新策略
- 1.3.1 定期生成
- 1.3.2 实时生成
- 1.3.2.1 内存淘汰策略
- 1.4 缓存预热
- 1.5 缓存穿透
- 1.6 缓存雪崩
- 1.7 缓存击穿
1. Redis应用–缓存
Redis有三个最主要的用途:
- 作为内存数据库存储数据。
- 缓存(Redis最常用的场景)。
- 消息队列。
1.1 什么是缓存
缓存是一个相对的概念,访问速度快的设备可以作为访问速度慢的设备的缓存。
CPU寄存器 > 内存 > 硬盘 > 网络。
缓存速度虽然快,但是空间小,缓存之所以有意义,是由于二八定律(20%的数据能够应对80%的请求)。
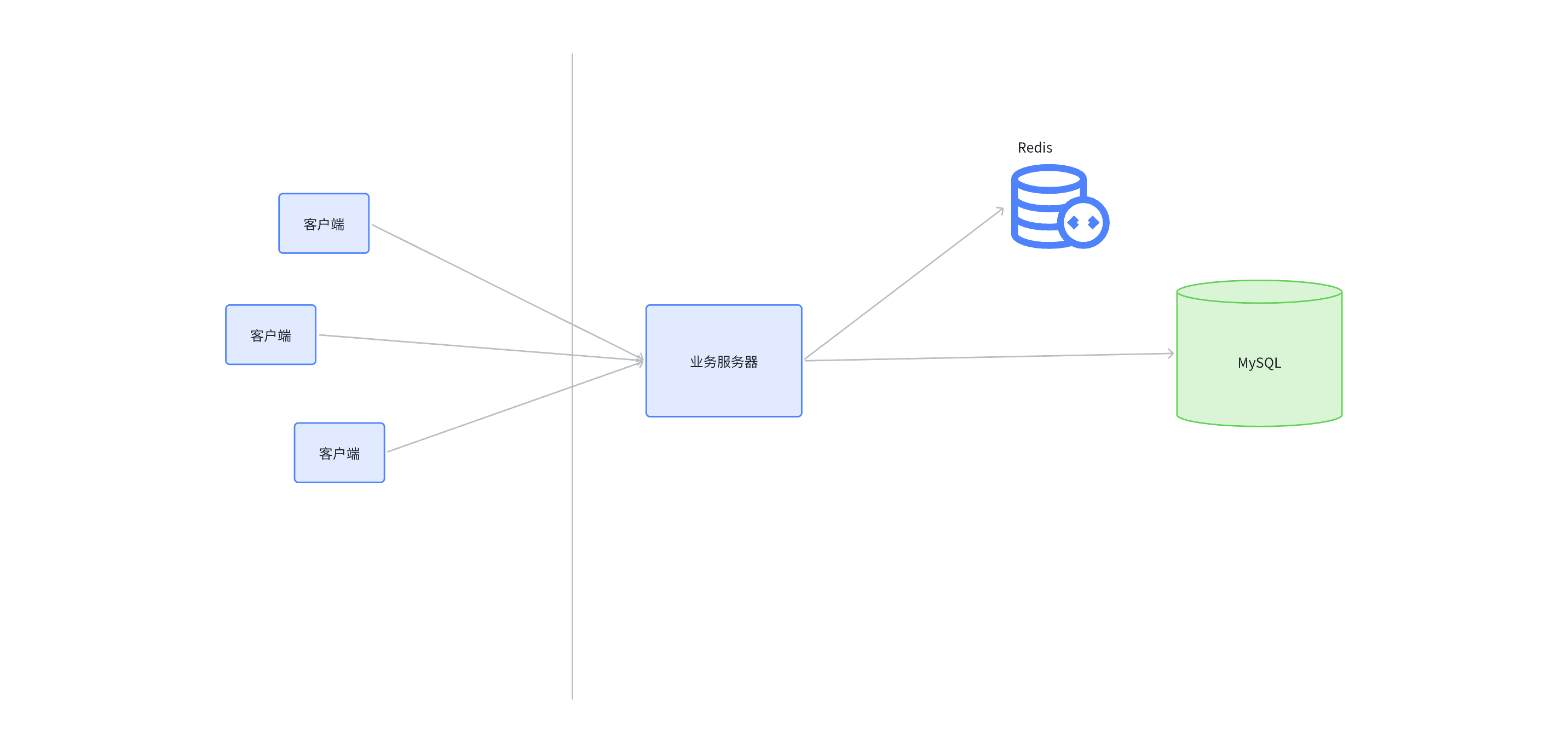
1.2 使用Redis作为缓存
通常是使用Redis作为数据库的缓存(MySQL)。
为什么关系型数据库性能不高?
- 数据库把数据存储到硬盘上,硬盘的IO速度并不快,尤其是随机访问。
- 如果查询不能命中索引,就需要进行表的遍历,会大大增加硬盘IO的次数。
- 关系型数据库对于SQL的执行会做一系列的解析、校验、优化工作。
- 如果是一些复杂的查询,比如联合查询,需要进行笛卡尔积操作,效率降低了很多。
为什么并发量高了就会宕机?
服务器每次处理一个请求,都要消耗一些硬件资源(CPU、内存、硬盘、网络)。任意一种资源的消耗超出了机器能提供的上限,机器就会很容易出现故障。
如何提高MySQL能够承担的并发量?
- 开源: 引入更多的机器,构成数据库集群.
- 节流: 引入缓存,就是典型的方案,把一些频繁读取的热点数据, 保存到缓存上,后续再查询数据的时候,如果 缓存中已经存在了.就不再访问mysql了.
1.3 缓存的更新策略
如何知道Redis中应该存储哪些数据呢?如何知道哪些数据是热点数据呢?
1.3.1 定期生成
定期生成策略会把访问的数据以日志的形式记录下来, 然后针对这些日志进行统计,统计一天/一月/一年每个词的出现频率, 再根据频率进行降序排序,取出前20%的词,就可以把这些词认为是热点词.
然后把这些热点词涉及到的搜索结果提前放到Redis这样的缓存中.
但是定期生成的热点数据的实时性不够,如果出现一些突发性事件,有些本来不是热词的内容,突然成了热词.新的热词就可能给后面的数据库带来较大的压力.
1.3.2 实时生成
每次用户查询的时候先再Redis中查询,如果查到了就直接返回;如果Redis中不存在就从数据库中查,同时把查到的结果写入Redis.
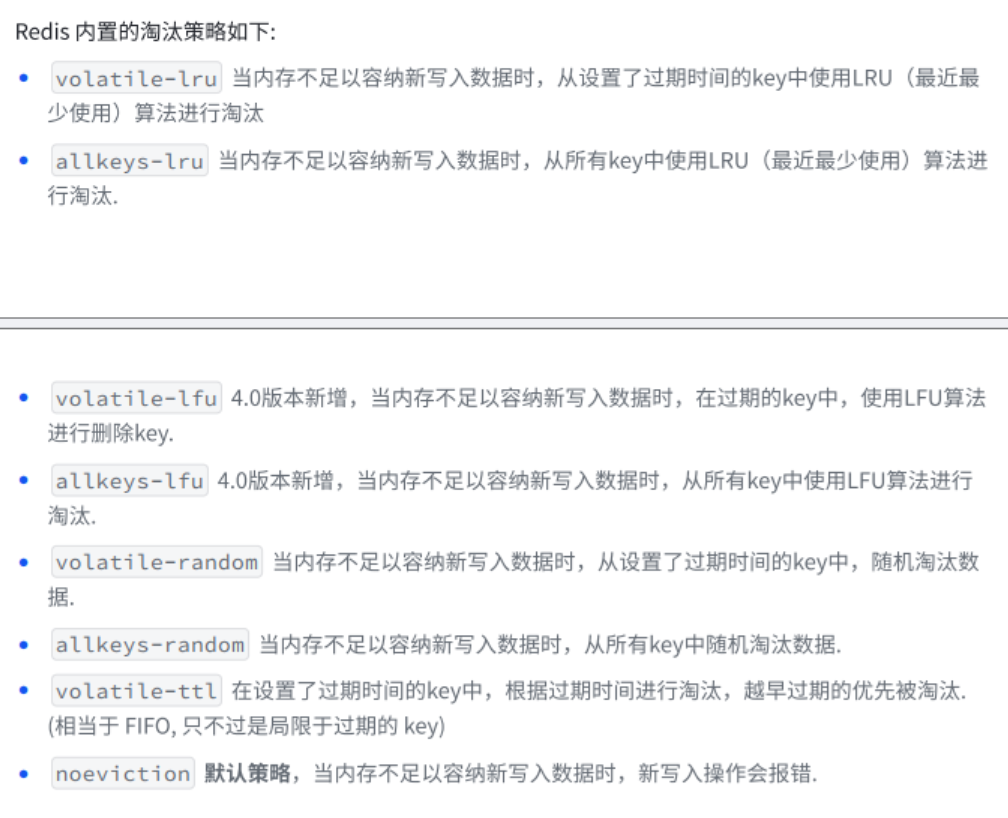
但是这样不断的往Redis缓存中写,就会使Redis的内存占用越来越多,逐渐达到上限.此时继续往里面插入数据就会触发问题.为了解决上述情况,Redis就引入了"内存淘汰策略".
1.3.2.1 内存淘汰策略
- FIFO先进先出: 把缓存中存在事件最久的淘汰掉.
- LUR淘汰最久未使用的: 记录每个key的最艰难访问时间, 把最近访问时间最老的key淘汰掉.
- LUF淘汰访问此时最少的: 记录每个key最近一段时间的访问次数,把访此时最少的淘汰掉.
- Random随机淘汰: 随机挑选幸运儿进行删除.
1.4 缓存预热
- 定期生成(不涉及预热).
- 实时生成.
Redis服务器首次接入之后,服务器里使没有数据的.此时所有的请求都会打给MySQL,随着时间的推移.Redis上的数据越积累越多,MySQL承担是压力就逐渐减小了.
缓存预热就是用来解决这个问题的,把定期生成和 实时生成结合一下,先通过离线的方式,通过一些统计的途径,先把热顶数据找到一批,导入到Redis中.此时导入的这批热点数据,就能棒MySQL承担很大的压力了.随着时间的推移,逐渐就使用新的热点数据淘汰掉旧的数据了.
1.5 缓存穿透
查询某个key, 在Redis中没有,在MySQL中也没有,这个key肯定也不会被更新到Redis中,那么这次查询查不到,下次查询也查不到…
如果存在很多这种查询不到的数据,并且后续还会反复查询,同样会给MySQL带来很大的压力.
解决方案:
1. 如果发现这个key,在Redis和MySQL上都不存在,仍然写入Redis中,value设成一个非法值(比如"").
2. 可以引入布隆过滤器,每次查询之前都先判定一下key是否在布隆过滤器上存在.
1.6 缓存雪崩
由于在短时间内,Redis上大规模的key失效,导致缓存命中率陡然下降,并且MySQL的压力迅速上升,甚至直接宕机
1. Redis直接挂了(Redis宕机/Redis集群模式下大量节点宕机).
2. Redis正常运行,但是可能之前短时间内设置了很多key给Redis,并且设置的过期时间是相同的.
解决方法:
1. 加强监控报警,加强Redis集群的可用性.
2. 不给key设置过期时间/设置过期时间的时候添加随机因子(避免同一时刻过期).
1.7 缓存击穿
针对热点数据,突然过期了,导致大量的请求直接访问到数据库上, 甚至引起数据库宕机.
如何解决?
1. 基于统计的方式发现热点 key, 并设置永不过期.
2. 进行必要的服务降级. 例如访问数据库的时候使⽤分布式锁, 限制同时请求数据库的并发数.