机器学习-NLP中的微调
自监督预训练
- NLP有大量的无标注的数据集
- 大量无标注的文档
- 自监督预训练
1、产生“伪标签”,使用监督学习完成预训练
2、通常NLP任务
语言模型(LM):预测下一个词
带掩码的语言模型(MLM):随机掩盖的单词的预测
常见预训练的模型
- 词嵌入(Word embeddings):对每个词www学习两个嵌入uw,vwu_w,v_wuw,vw
1、可以根据文本词x1,...,xnx_1,...,x_nx1,...,xn预测掩盖的词yyy(y应该在x1x_1x1和xnx_nxn的中间),通过
argmaxyuyT∑ivxiargmax_yu^T_y\displaystyle\sum_i v_{x_i}argmaxyuyTi∑vxi(CBOW)
2、嵌入uuu可用在其他应用中 - 基于Transformer的预训练的模型
1、BERT:一个transformer编码器(使用带掩码的词预测和下一句的预测)
2、GPT:一个transformer解码器
3、T5:一个transformer编码器-解码器
BERT
- 预训练任务:掩码词的预测,下一句的预测
- 在Wikipedia和BookCorpus(>3B)预训练
- 多个版本
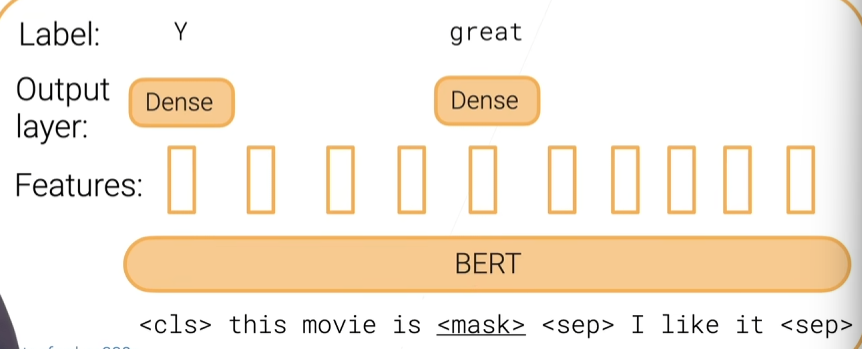
- 多个变种(ALBERT,ELECTRA,RoBERTa)
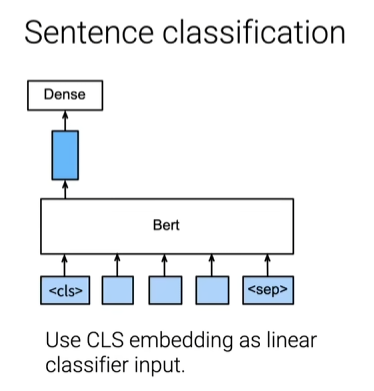
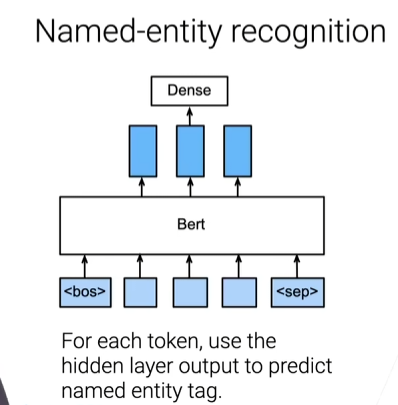
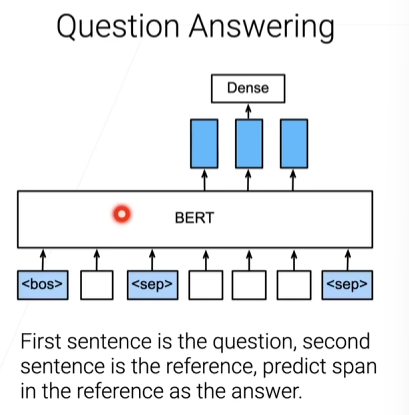
BERT微调
- 随机初始化最后一层,小的学习率训练几次
- 下游任务示例
常用网站
HuggingFace:一系列预训练好的transforemer库