【数据工程】 10. 半结构化数据与 NoSQL 数据库
半结构化数据与 NoSQL 数据库
1. 什么是半结构化数据 (Semistructured Data)
在数据管理中,除了结构化(如关系型数据库表格)与非结构化数据(如纯文本、图片、视频),还存在 半结构化数据 (semistructured data)。典型的半结构化数据包括 HTML、XML 和 JSON。它们具有一定结构,但不如关系数据库严格。
特征
- 非刚性结构:没有严格固定的 schema。
- 属性缺失或冗余:不同对象可以有不同的属性。
- 嵌套 (nesting):文档是分层的、树形的。
- 数据类型不一致:不同对象可以有不同字段和类型。
- 异质集合:集合中的元素不必同构。
2. HTML 与 XML
- HTML:主要用于网页渲染和设计。
- XML:用于数据交换和企业数据集成,强调数据结构的自描述性。
- 共同点:都是标记语言(tag-based)。
- 区别:HTML 标签固定;XML 标签用户自定义。
3. XML 示例
<?xml version='1.0'?>
<bookstore><book genre="autobiography"><title>The Autobiography of Benjamin Franklin</title><author><first-name>Benjamin</first-name><last-name>Franklin</last-name></author><price>8.99</price></book>
</bookstore>
特点:层次化、树形结构、标签必须闭合。
文档逻辑结构
- XML将其对象称为元素
- 最上面的元素称为根元素或文档元素。
- 元素由标签绑定:
- 每个开始标签必须有匹配的结束标签
- 标签名称“区分大小写”
- 标签不能重叠;例如:以下情况是不允许的:
< A > < B >…< /A >…< / B > - 空元素的标签有特殊的语法
4. XML 逻辑结构与 DTD
- 元素 (Element):XML 对象
- 根元素 (Root element):顶层元素
- 规则:每个开始标签必须有结束标签,标签名区分大小写,不能交错,空元素有
<AUD/>形式。
Document Type Definition (DTD)
XML用用户定义的标签定义一般的语法属性。
DTD 示例
XML 允许用户自定义标签,那么问题是:
一个 XML 文档到底允许哪些标签?
→ 通过 DTD (Document Type Definition) 来约束。
定义 XML 文档的“语法规则”
类似 schema,但不完全相同
基于 BNF 文法,定义了元素的结构、属性和内容
示例:Bookstore DTD
<!ELEMENT bookstore (book)*>
<!ELEMENT book (title,author+,price?)>
<!ATTLIST book genre CDATA #REQUIRED>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (name | (first-name,last-name))>
<!ELEMENT price (#PCDATA)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT first-name (#PCDATA)>
<!ELEMENT last-name (#PCDATA)>
5. XML 合规性
Well-formed 文档:
满足 XML 基本语法(标签成对、不能交叉等)
Valid 文档:
除了 well-formed,还必须满足 DTD 或 Schema 定义的约束
6. XML 查询方式
XML 是一棵树,因此查询方式主要有:
DOM (Document Object Model)
把 XML 文档加载为树结构,逐节点导航
XPath
用表达式查询节点、子树或属性
XQuery
基于 XPath,声明式查询一组 XML 文档(更强大)
CSS 选择器
更常用于 HTML,而非 XML
| 特性 | DOM | XPath |
|---|---|---|
| 类型 | 树形对象模型 | 查询语言 |
| 风格 | 命令式、操作节点 | 声明式、选择节点 |
| 操作 | 可修改节点、增删改查 | 只能查询节点或值,不修改文档 |
| 内存使用 | 需要加载整个文档到内存 | 通常也需要文档树,但表达式更简洁 |
| 复杂性 | 需要写循环和判断 | 使用路径表达式即可选择复杂节点 |
7. 半结构化数据 vs 结构化数据
关系型数据库 (Structured / Relational)
-
模式优先(schema-first)
-
丰富的类型系统
-
强约束(完整性约束)
-
第一范式(1NF):属性必须是原子值
-
需要通过多表和 join 来表示复杂关系
半结构化数据
-
自描述数据,灵活结构
-
嵌套模型(树)
-
可选属性
-
语法、模式和词汇不严格固定
JSON 与 XML 对比
JSON
更简洁,开销更小(less verbose)
适合 Web API,现代应用广泛采用
XML
标签更多,结构更严格
更常见于传统企业应用和标准化数据交换
JSON 示例:
{"name": "John Smith","address": {"street": "1 Cleveland Street","city": "Sydney","state": "NSW","zipcode": 2006},"phoneNumbers": [{ "type": "work", "number": "9351 0000" },{ "type": "fax", "number": "9351 3838" }]
}
特点:轻量、嵌套结构、易于解析,常用于 API。
8. 存储半结构化数据
文件存储示例
CSV 存储 HTML 表格:
import pandas as pd
import requests
from bs4 import BeautifulSouppage = requests.get("https://www.health.nsw.gov.au/infectious/diseases/Pages/covid-19-latest.aspx")
content = BeautifulSoup(page.text, 'html5lib')data = content.find_all("table")
df = pd.read_html(str(data))[0]
df.to_csv('covid_stats_nsw.csv')
JSON API 响应存储:
import requests, json, pandas as pdbase_url = 'https://nominatim.openstreetmap.org/search'
my_params= {'q': '1 Cleveland Street,Darlington,Australia','format':'json'}
whoami = {'User-Agent': ''}response = requests.get(base_url, params=my_params, headers=whoami)
results = response.json()with open("locations_all.json", "w", encoding="utf-8") as f:json.dump(results, f)df = pd.json_normalize(results[0])
df.to_json("location.json")
9. 数据库存储
-
RDBMS:PostgreSQL 支持 JSON/JSONB
-
JSON vs JSONB:
JSON:原始文本存储JSONB:二进制存储,查询更快
CREATE TABLE StudentJSON (sid INTEGER,details JSONB
);INSERT INTO StudentJSON(sid, details)
VALUES(12345, '{"name": {"first": "Bob", "last": "Smith"},"degree": "BSc(CS)","crsTake": {"crsCode":"INFO1003","semester":"2017sem1"},"crsTake": {"crsCode":"INFO1103","semester":"2016sem2"}
}');SELECT sid, details->'name'->'first' AS name
FROM StudentJSON
WHERE details->'degree' ? 'BSc(CS)';
10. NoSQL 数据库
背景
- 传统关系型数据库功能强大,但依赖昂贵服务器(scale-up)。
- 云计算推动水平扩展(scale-out)。
- NoSQL 放弃部分关系功能以换取灵活性和高性能。
分类
- 文档数据库:MongoDB、CouchDB
- 列存储:BigTable、HBase
- 键值存储:Redis、DynamoDB
- 图数据库:Neo4J
Schema-first vs Schema-late
- RDBMS:schema-first,数据必须符合预定义模式。
- NoSQL:schema-late 或 schema-on-read,可存储任意 JSON/XML。
11. MongoDB
数据模型
- JSON 文档集合(collection)
- 文档可嵌套
- 每个文档
_id主键 - 关系通过嵌套或引用
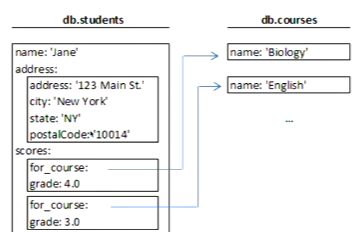
RDBMS vs MongoDB 对照
| RDBMS | MongoDB |
|---|---|
| Database | Database |
| Table | Collection |
| Row | Document |
| Column | Field |
| Schema-first | Flexible schema |
| Normalised | Denormalised (可嵌套) |
MongoDB 处理速度更慢
CRUD 示例
db.users.insertOne({ name: "sue", age: "26", status: "pending" }
);db.users.find({ age: { $gt: 26 } }, { name:1, address:1 }).sort({name:1});
MongoDB 查询模型
隐式等值匹配 & AND
复杂查询需 gt、gt、gt、or 等运算符。
db.students.find(); // SELECT * FROM Students
db.students.find({name: "Jane"});
db.students.find({name: "Jane", "address.city": "Sydney"});
db.students.find({name: "Jane", age: {$gt: 20}});
db.courses.find({ $or: [ {name: "Jane"}, {name: "Joe"} ] });
db.courses.find().sort({name: -1});当通过MongoDB shell (JavaScript接口)进行交互时,类JSON对象不需要引号键,因为它是JavaScript对象语法,而不是严格的JSON。
当直接使用JSON文件时(例如使用mongoimport或通过MongoDB Compass导入数据),键必须引用,遵循严格的JSON规则。
MongoDB 聚合与分布式
聚合 (Aggregation Framework):类似 Unix 管道,多阶段数据处理。
自动分片 (Sharding):水平分区,分布到多台机器。
复制 (Replication):单主节点异步复制,保证可用性。
MongoDB:可伸缩性
- 自动数据分区
- 大集合的“自动分片”
- 以保持顺序的方式在多台机器之间划分数据。
- 均值:每个“表”的水平范围分区
- Single-Leader 复制
- 在一个“shard”内异步单leader复制
- 单个领导者接收更新
- 主要目标:可用性
- 可选:查询追随者,但只有“最终一致性”
- Load Balance
12. Graph Databases
Tree structure data is a special graph structure data
数据模型
- 节点 (Node):实体,如用户、产品
- 边 (Edge):节点间关系,如好友、交易
- 属性 (Property):节点或边的元数据
优势
- 高效处理复杂关系(多对多)
- 灵活:schema-less
- 快速遍历和查询关联数据
RDBMS vs 图数据库对比
| 特性 | RDBMS | Graph Database |
|---|---|---|
| 数据模型 | 表格 | 节点、边、属性 |
| Schema | 固定 | 灵活/无固定 |
| 查询语言 | SQL | Cypher (Neo4j)、Gremlin、SPARQL |
| 性能 | 事务、复杂 join | 遍历关系优化 |
| 扩展性 | 垂直扩展 | 水平扩展 |
| 用例 | 传统事务系统 | 社交网络、推荐、欺诈检测 |
Neo4j
-
开源图数据库
-
使用 Property Graph 模型
-
特性:
- ACID 支持
- 高可用
- 灵活 Schema
- Cypher 查询语言
Cypher 示例
MATCH (p:Person {name: 'Alice'})-[:FRIENDS_WITH]->(friend)
RETURN friend.name;
高级功能
- 索引与约束
- 全文搜索
- 内置图算法(最短路径、PageRank、社区检测)
- 可视化工具(Neo4j Bloom)
13. 总结
- 半结构化数据(HTML、XML、JSON)广泛应用于现代数据处理。
- 可存储在文件系统、RDBMS(支持 JSON/XML)、NoSQL 数据库中。
- RDBMS:schema-first,严格约束。
- NoSQL:schema-late,灵活,可扩展。
- MongoDB、Neo4j 等系统在可扩展性、灵活性和关系处理能力上优势明显。