大模型操作SQL查询Text2SQL
一、背景
在企业级应用场景中,往往存在海量结构化数据,这类数据通常存储于传统关系型数据库内。对于这类数据的查询操作,最便捷的方式并非将其转化为向量,而是让数据留存于数据库中,直接通过 SQL 语句执行查询。由于 SQL 本身是一种编程语言,若需以自然语言实现等效于 SQL 的查询能力,则需依托大模型构建 Text-to-SQL 功能,进而打造数据库的 SQL 查询引擎,具体架构如图所示。
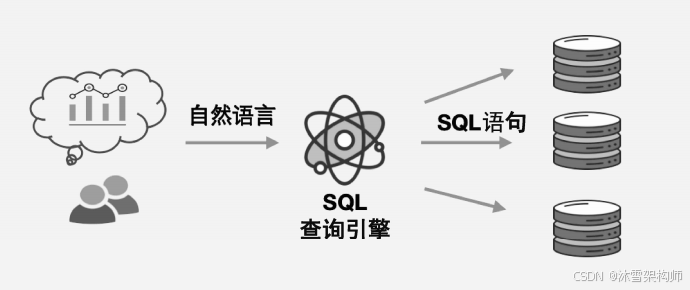
二、测试表和数据
我们使用本地的一个 Postgres 数据库来进行测试,user_search_history表和chat_session表,结构如下:
user_search_history表(用户的搜索记录表)结构:
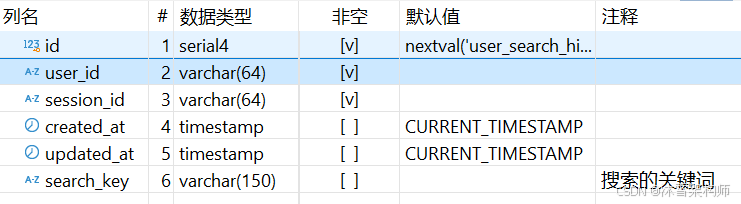
chat_session表(多轮对话会话表)结构:
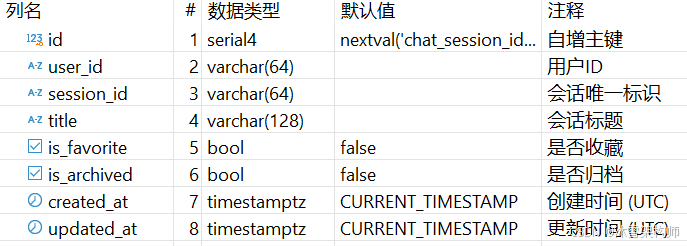
三、 使用 NLSQLTableQueryEngine 组件
NLSQLTableQueryEngine 是 LlamaIndex(以前叫 GPT-Index)里的一个组件,用来把人类的自然语言查询 (“哪个城市人口最多?”、“给我过去一周销售额最高的产品”等)转换为 SQL 查询语句,然后执行这些 SQL,从数据库里取出结构化结果,最后把结果返回给用户。
(一)、功能 & 用处
自然语言 → SQL
用户可以用普通语言发问,NLSQLTableQueryEngine 将其“翻译 (synthesize)”成 SQL 查询。这样你就不用写 SQL,也不用熟悉数据库 schema 的细节。执行结构化查询
翻译出的 SQL 可以在真实的数据库上执行,从表中读取准确的数据,比如最大、最小、平均、排序、过滤等操作。节省学习成本,简化接口
对于非数据库专家,或者只想快速应用数据的人来说,不用写 SQL 是大好事。这样系统变得更友好,也更容易集成到聊天机器人、BI 工具、Dashboard 模块等。可指定表以控制上下文
在创建这个引擎时,可以指定哪些表 (“tables”) 是此次查询可用的。这样引擎只加载这些表的 schema(结构信息),避免把所有表拉进 prompt(提示)里导致上下文窗口(context window)过大,性能或成本崩掉。
(二)、实例代码
完整的代码如下:
# ================== 初始化 大模型 Langfuse ==================
from common.model_loader import model_loaders
import common.langfuse_init_client
# ================== 初始化大模型 Langfuse end ==================from sqlalchemy import create_engine
from llama_index.core.query_engine import NLSQLTableQueryEngine
from llama_index.core import SQLDatabase# 构造 SQL 查询引擎
db_url = "postgresql://PGUserName:PGPwd@PGUri:PG/PGTableName?sslmode=require"
engine = create_engine(db_url)# 构造 SQLDatabase 对象
sql_database = SQLDatabase(engine , include_tables=["user_search_history", "chat_session"])# 构造 SQLTable 查询引擎:sql_database、tables、llm 参数
query_engine = NLSQLTableQueryEngine(sql_database=sql_database,# tables=["user_search_history", "chat_session"],# 若不指定,则从SQLDatabase中include_tables中取表信息# llm=llm_openai,verbose=True, # 显示详细的日志
)
# 测试
#query_str="那么,昨天一共有几次查询历史呢?"
# query_str="请列举出用户id是36的查询历史的会话标题"
query_str="每个用户的查询统计"
response = query_engine.query(query_str)
print(response)
结果如下:
...
> Table Info: Table 'chat_session' has columns: id (INTEGER): '自增主键', user_id (VARCHAR(64)): '用户ID', session_id (VARCHAR(64)): '会话唯一标识', title (VARCHAR(128)): '会话标题', is_favorite (BOOLEAN): '是否收藏', is_archived (BOOLEAN): '是否归档', created_at (TIMESTAMP): '创建时间 (UTC)', updated_at (TIMESTAMP): '更新时间 (UTC)', with comment: (多轮对话会话表) .
> Table Info: Table 'user_search_history' has columns: id (INTEGER), user_id (VARCHAR(64)), session_id (VARCHAR(64)), created_at (TIMESTAMP), updated_at (TIMESTAMP), search_key (VARCHAR(150)): '搜索的关键词', with comment: (用户的搜索记录表) .
> Table desc str: Table 'chat_session' has columns: id (INTEGER): '自增主键', user_id (VARCHAR(64)): '用户ID', session_id (VARCHAR(64)): '会话唯一标识', title (VARCHAR(128)): '会话标题', is_favorite (BOOLEAN): '是否收藏', is_archived (BOOLEAN): '是否归档', created_at (TIMESTAMP): '创建时间 (UTC)', updated_at (TIMESTAMP): '更新时间 (UTC)', with comment: (多轮对话会话表) .Table 'user_search_history' has columns: id (INTEGER), user_id (VARCHAR(64)), session_id (VARCHAR(64)), created_at (TIMESTAMP), updated_at (TIMESTAMP), search_key (VARCHAR(150)): '搜索的关键词', with comment: (用户的搜索记录表) .
> Predicted SQL query: SELECT user_id, COUNT(*) AS search_count FROM user_search_history GROUP BY user_id ORDER BY search_count DESC;
根据查询结果,以下是每个用户的搜索统计数据,按搜索次数从高到低排序:1. 用户ID: 36- 搜索次数: 4 次2. 用户ID: 911- 搜索次数: 2 次这意味着用户ID为36的用户进行了最多的搜索,共4次;而用户ID为911的用户进行了2次搜索。
采用该方法时,需预先准备三类参数:一是 SQLDatabase 对象,二是待查询的目标数据表,三是所选用的大模型。参数就绪后,可直接完成查询引擎的构造。引擎搭建完毕,用户便能以自然语言与数据库交互,即便不掌握 SQL 语句,也可对数据库内的数据执行查询、统计乃至分析操作。
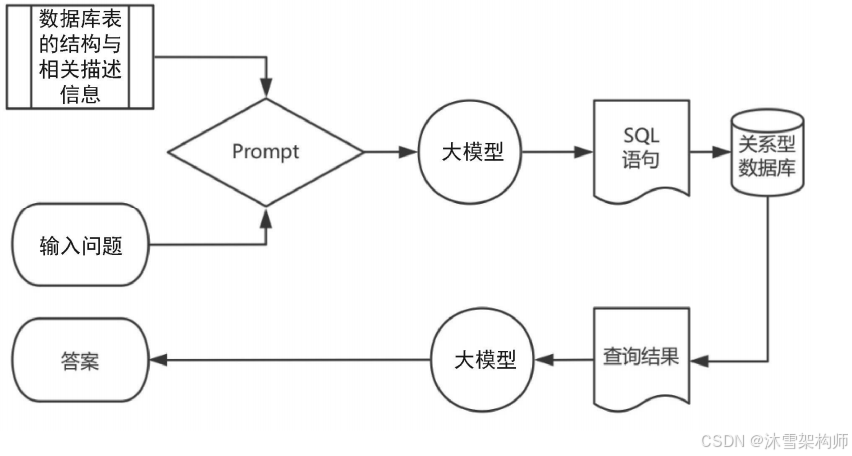
SQL 查询引擎的技术原理是:将用户输入的问题与数据库表的结构及相关描述信息整合为 Prompt,输入大模型;借助大模型的理解与生成能力,将其转换为关系数据库可执行的 SQL 语句并运行;最终对执行结果进行总结后输出答案。
(三)局限 &风险
上下文窗口 / 提示长度限制
如果数据库中表太多或者每个表 schema 很复杂,把所有的 schema 放进 prompt 会把语言模型的上下文搞爆。LLM 输入限制一满就可能出错或者生成不准确的 SQL。指定表或做动态检索表模式是必要策略。SQL 安全 / 注入风险
因为生成的 SQL 是自动的,如果不加限制就可能被滥用。例如用户问的问题可能被“引导”生成恶意查询或破坏数据库的查询。通常建议只用只读权限、受限制角色、审查生成 SQL、避免执行危险操作。LLM 出错或「幻觉性回答」
LLM 有可能误解自然语言意图、生成无效的 SQL、引用表/列名错误、漏掉过滤条件等。引擎本身不是完美的“语义理解器”;对于复杂 query,尤其是涉及多个表 JOIN、嵌套子查询等,错误率会上升。要有验证机制。效率问题
每次自然语言查询都要生成 SQL 并执行数据库访问,这在大表、大数据量或高频查询场景下可能慢或成本高。要注意缓存、索引、查询优化等常规数据库性能调优。
四、基于实时表检索的查询引擎
大型数据库支持 SQL 查询时,需为所有数据表配置参数。但表过多可能导致大模型上下文溢出,这是因 NLSQLTableQueryEngine 组件需将表的 Schema 信息(结构及描述)整合到 Prompt 中实现 Text-to-SQL。 因此,可在 Text-to-SQL 前先根据问题检索所需表,再基于这些表生成 SQL,即每次仅用相关 Schema,以节约空间、减少干扰。
通过框架的 SQLTableRetrieverQueryEngine 组件可实现这一功能,传入 object_index 参数即可检索相关 SQLTableSchema 对象。
示例代码:
# ================== 初始化 大模型 Langfuse ==================
from common.bedrock_model_loader import model_loaders
import common.langfuse_init_client
# ================== 初始化大模型 Langfuse end ==================
from sqlalchemy import (create_engine, MetaData)
from llama_index.core import SQLDatabase
from llama_index.core.indices.struct_store.sql_query import SQLTableRetrieverQueryEnginefrom llama_index.core.objects import (SQLTableNodeMapping, SQLTableSchema, ObjectIndex)
from llama_index.core import VectorStoreIndexdb_url = "postgresql://PGUserName:PGPwd@PGUri:PG/PGTableName?sslmode=require"
engine = create_engine(db_url)# 1- 创建 SQLDatabase 实例:用 SQLAlchemy 的 engine 初始化 SQLDatabase,并指定要包含的表名
sql_database = SQLDatabase(engine, include_tables=["user_search_history", "chat_session","chat_history"])# 2-构建表结构索引:用 SQLTableNodeMapping 生成表结构节点,再用 ObjectIndex.from_objects 创建表结构索引(可批量处理多表)。
table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [SQLTableSchema(table_name="user_search_history"),SQLTableSchema(table_name="chat_session"),SQLTableSchema(table_name="chat_history")
]obj_index = ObjectIndex.from_objects(table_schema_objs,table_node_mapping,#VectorStoreIndex,
)# 调用 retriever 方法来查看检索出的 Schema 信息,
table_retriever = obj_index.as_retriever(similarity_top_k=1)
# tables = table_retriever.retrieve("在用户的查询历史表中,今年一共有多少条记录数据记录?")
# print(tables)
# print("-" * 30)# 3-初始化 SQLTableRetrieverQueryEngine:将 SQLDatabase 和 ObjectIndex 的检索器传入,得到 query_engine
query_engine = SQLTableRetrieverQueryEngine(sql_database, table_retriever,verbose=True
)
# 引擎会自动检索相关表结构,生成 SQL 并执行,返回结果
response = query_engine.query("我在问一个问题啊,在用户的查询历史表中,今年一共有多少条记录数据记录?")
print(response)
可见输出结果与第三章示例的输出结果一致。在执行查询前,你也可直接调用 retriever 方法查看检索到的 Schema 信息,以此验证检索结果的准确性。
# 调用 retriever 方法来查看检索出的 Schema 信息,
table_retriever = obj_index.as_retriever(similarity_top_k=1)
tables = table_retriever.retrieve("在用户的查询历史表中,今年一共有多少条记录数据记录?")
print(tables)这段代码的底层使用Embedding大模型,找到最接近的一个表名。这样在后面的查询时候只需要1个表的schema信息即可。
五、防护建议
安全风险:text to SQL 最大隐患是 prompt injection 和 SQL 注入。LLM 可能被诱导生成如 DROP/DELETE/UPDATE 等危险语句,导致数据丢失或泄露。即使只允许 SELECT,攻击者也可能通过构造查询窃取敏感信息。社区已披露多例实际攻击案例,官方建议务必限制数据库账号权限、只开放只读视图、在生产环境中严格审查和过滤 LLM 生成的 SQL 语句。
准确性与可控性:LLM 生成 SQL 受 prompt、表结构、上下文窗口等影响,复杂查询(如多表 join、嵌套子查询、权限过滤)容易出错或遗漏条件,可能导致数据误用或越权访问。建议对 LLM 生成的 SQL 进行二次校验(如正则限制只允许 SELECT),或采用 sql_only=True 先人工审核再执行。
防护建议:
- 数据库层面:只用只读账号,限制权限,必要时只暴露视图。
- 应用层面:对 LLM 生成的 SQL 做白名单校验(如只允许 SELECT),可用正则或 AST 解析。
- 业务层面:对敏感表/字段做脱敏或隐藏,避免 LLM 生成涉及敏感信息的 SQL。
- 交互层面:对用户输入和 LLM 输出都做内容安全检测,防 prompt injection。
- 审计与监控:记录所有 SQL 执行日志,及时发现异常操作。