LLM的MTP论文阅读
论文原文:https://arxiv.org/abs/2404.19737
1.思路
让语言模型一次性预测多个后续标记(token),可显著提升样本效率。具体而言,在训练语料的每个位置,要求模型使用 n 个独立的输出头(共享同一个模型主干)来同时预测接下来的 n 个标记。
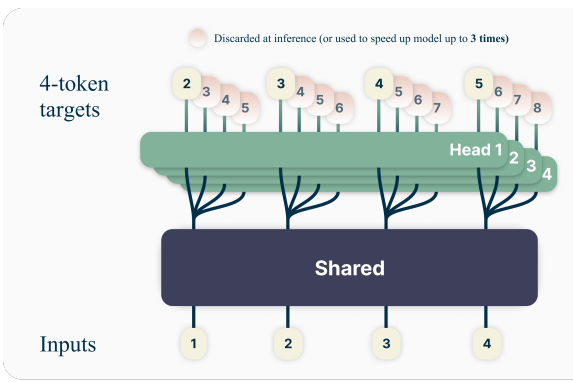
1.共享骨架:模型有一个共用的 “主干”(类似通用的文字理解模块),负责处理输入的文字,提炼出核心信息。
2.多个预测头:在 “主干” 后面接多个独立的 “预测头”(比如要一次预测 4 个词,就配 4 个),每个 “头” 专门负责预测未来第 1、2、3、4 个词,彼此并行工作。
2.公式
标准的ntp公式
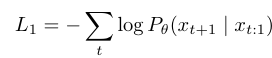
为了一次预测未来多个token,公式演变为
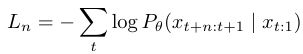

3.训练过程