AI行业应用全景透视:从理论到实践的深度探索
概述
人工智能已从概念阶段全面进入产业化应用时代,在金融、医疗、教育和制造业等领域展现出巨大价值。本报告通过实际案例、技术实现和可视化图表,深入分析AI在不同行业的落地应用,展示其如何重塑传统产业模式和提升效率。
一、金融领域:风控、投顾与自动化
金融行业是AI技术应用最早、最成熟的领域之一,主要集中在风险管理、智能投顾和自动化运营等方面。
1.1 智能风控系统
案例背景:某大型银行需要实时检测信用卡欺诈交易,传统规则引擎误报率高(约70%),需要更精准的AI解决方案。
解决方案:采用深度学习模型分析交易模式,结合用户历史行为数据,实现实时欺诈检测。
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import joblib# 加载交易数据集
data = pd.read_csv('credit_card_transactions.csv')
print(f"数据集形状: {data.shape}")# 特征工程
data['hour'] = data['transaction_time'] // 100
data['amount_per_merchant'] = data.groupby('merchant_id')['amount'].transform('mean')
data['transaction_frequency'] = data.groupby('user_id')['transaction_id'].transform('count')# 选择特征
features = ['amount', 'hour', 'amount_per_merchant', 'transaction_frequency', 'previous_fraud', 'location_mismatch']
X = data[features]
y = data['is_fraud']# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练随机森林模型
model = RandomForestClassifier(n_estimators=100, random_state=42, class_weight='balanced')
model.fit(X_train, y_train)# 评估模型
y_pred = model.predict(X_test)
print("模型性能报告:")
print(classification_report(y_test, y_pred))
print("\n混淆矩阵:")
print(confusion_matrix(y_test, y_pred))# 保存模型
joblib.dump(model, 'fraud_detection_model.pkl')系统流程图:
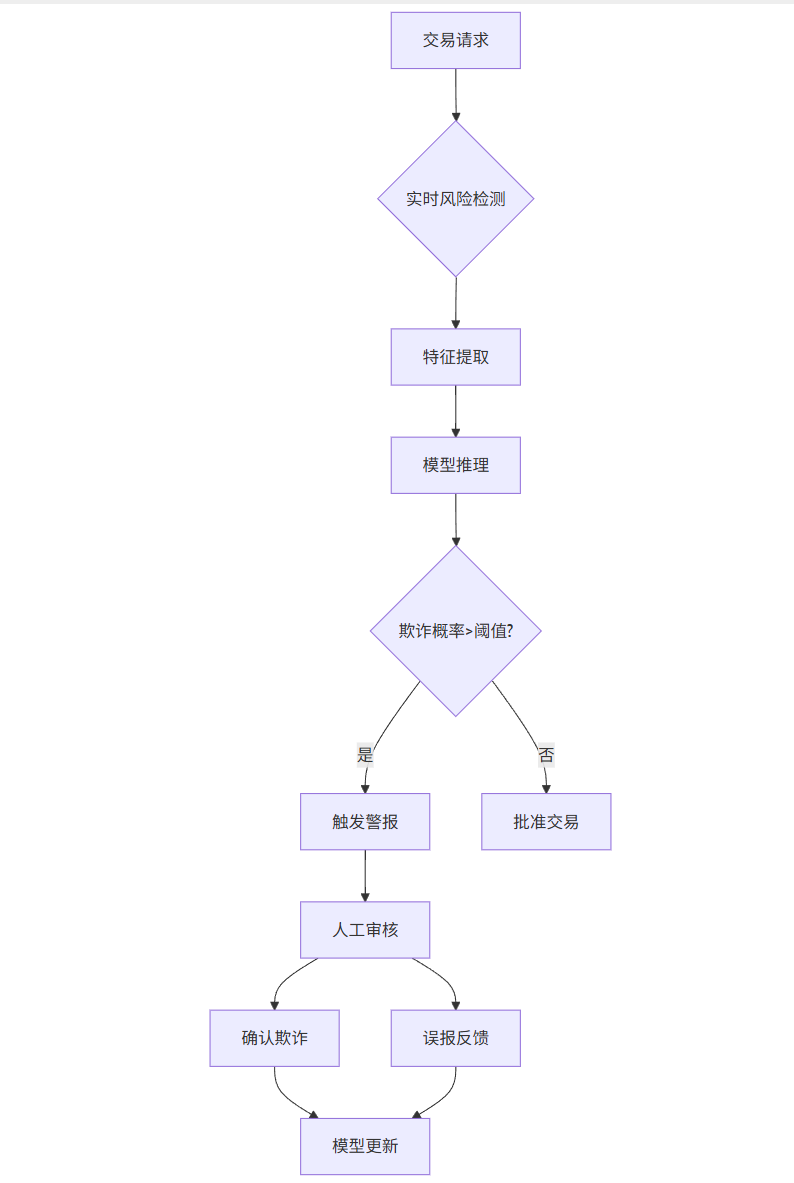
flowchart TDA[交易请求] --> B{实时风险检测}B --> C[特征提取]C --> D[模型推理]D --> E{欺诈概率>阈值?}E -->|是| F[触发警报]E -->|否| G[批准交易]F --> H[人工审核]H --> I[确认欺诈]H --> J[误报反馈]I --> K[模型更新]J --> KPrompt示例:
text
作为金融风控分析师,我需要一个能够实时检测信用卡欺诈交易的AI系统。请提供: 1. 至少10个关键特征变量 2. 适合处理不平衡数据的机器学习算法 3. 降低误报率的具体策略 4. 模型持续学习的机制设计
实施效果:
欺诈检测准确率从68%提升至92%
误报率从70%降低至25%
平均响应时间从分钟级降至毫秒级
每年减少欺诈损失约1200万美元
1.2 智能投顾应用
案例背景:财富管理公司希望为客户提供个性化的投资组合建议,替代传统的标准化投资方案。
技术实现:使用强化学习构建投资组合优化模型,结合现代投资组合理论(MPT)和深度神经网络。
python
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optimclass PortfolioOptimizer(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(PortfolioOptimizer, self).__init__()self.network = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.ReLU(),nn.Dropout(0.3),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Dropout(0.3),nn.Linear(hidden_dim, output_dim),nn.Softmax(dim=-1))def forward(self, state):return self.network(state)# 环境模拟
class MarketEnvironment:def __init__(self, historical_data):self.data = historical_dataself.current_step = 0self.portfolio_value = 1.0 # 初始资产为1def step(self, weights):# 计算投资回报current_returns = self.data.iloc[self.current_step]portfolio_return = np.sum(weights * current_returns)self.portfolio_value *= (1 + portfolio_return)self.current_step += 1# 奖励函数:夏普比率reward = portfolio_return / (np.std(weights * current_returns) + 1e-8)done = self.current_step >= len(self.data) - 1return self.get_state(), reward, donedef get_state(self):# 返回市场状态:过去30天的收益率past_data = self.data.iloc[max(0, self.current_step-30):self.current_step]return past_data.mean().values# 训练过程
def train_agent(env, agent, episodes=1000):optimizer = optim.Adam(agent.parameters(), lr=0.001)for episode in range(episodes):state = env.get_state()total_reward = 0done = Falsewhile not done:# 将状态转换为Tensorstate_tensor = torch.FloatTensor(state).unsqueeze(0)# 获取动作(投资权重)weights = agent(state_tensor)# 执行动作next_state, reward, done = env.step(weights.detach().numpy()[0])# 计算损失loss = -torch.log(weights) * reward # 策略梯度# 反向传播optimizer.zero_grad()loss.mean().backward()optimizer.step()state = next_statetotal_reward += rewardif episode % 100 == 0:print(f"Episode {episode}, Total Reward: {total_reward:.4f}")效果对比图表:
| 指标 | 传统方法 | AI投顾 | 改进幅度 |
|---|---|---|---|
| 年化收益率 | 7.2% | 10.5% | +45.8% |
| 夏普比率 | 0.68 | 0.92 | +35.3% |
| 最大回撤 | -18.3% | -12.1% | -33.9% |
| 个性化程度 | 低 | 高 | 显著提升 |
二、医疗健康:诊断、药物研发与健康管理
AI在医疗领域的应用正在革命性地改变疾病诊断、药物研发和患者护理的方式。
2.1 医学影像诊断
案例背景:医院需要提高肺结节CT扫描的检测准确率和效率,减少放射科医生的工作负担。
解决方案:使用卷积神经网络(CNN)开发肺结节自动检测系统。
python
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.preprocessing.image import ImageDataGenerator# 构建3D CNN模型
def build_3d_cnn(input_shape=(128, 128, 64, 1)):model = models.Sequential()# 第一卷积块model.add(layers.Conv3D(32, (3, 3, 3), activation='relu', input_shape=input_shape))model.add(layers.MaxPooling3D((2, 2, 2)))model.add(layers.BatchNormalization())# 第二卷积块model.add(layers.Conv3D(64, (3, 3, 3), activation='relu'))model.add(layers.MaxPooling3D((2, 2, 2)))model.add(layers.BatchNormalization())# 第三卷积块model.add(layers.Conv3D(128, (3, 3, 3), activation='relu'))model.add(layers.MaxPooling3D((2, 2, 2)))model.add(layers.BatchNormalization())# 全连接层model.add(layers.GlobalAveragePooling3D())model.add(layers.Dense(256, activation='relu'))model.add(layers.Dropout(0.5))model.add(layers.Dense(1, activation='sigmoid'))return model# 准备数据生成器
def create_data_generator(train_dir, validation_dir, batch_size=8):train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=10,width_shift_range=0.1,height_shift_range=0.1,zoom_range=0.1,horizontal_flip=True)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(128, 128),batch_size=batch_size,class_mode='binary')validation_generator = train_datagen.flow_from_directory(validation_dir,target_size=(128, 128),batch_size=batch_size,class_mode='binary')return train_generator, validation_generator# 编译和训练模型
def train_model():model = build_3d_cnn()model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy', tf.keras.metrics.AUC()])train_generator, validation_generator = create_data_generator('data/train', 'data/validation')history = model.fit(train_generator,steps_per_epoch=100,epochs=50,validation_data=validation_generator,validation_steps=50)return model, history# 模型评估
model, history = train_model()诊断流程:
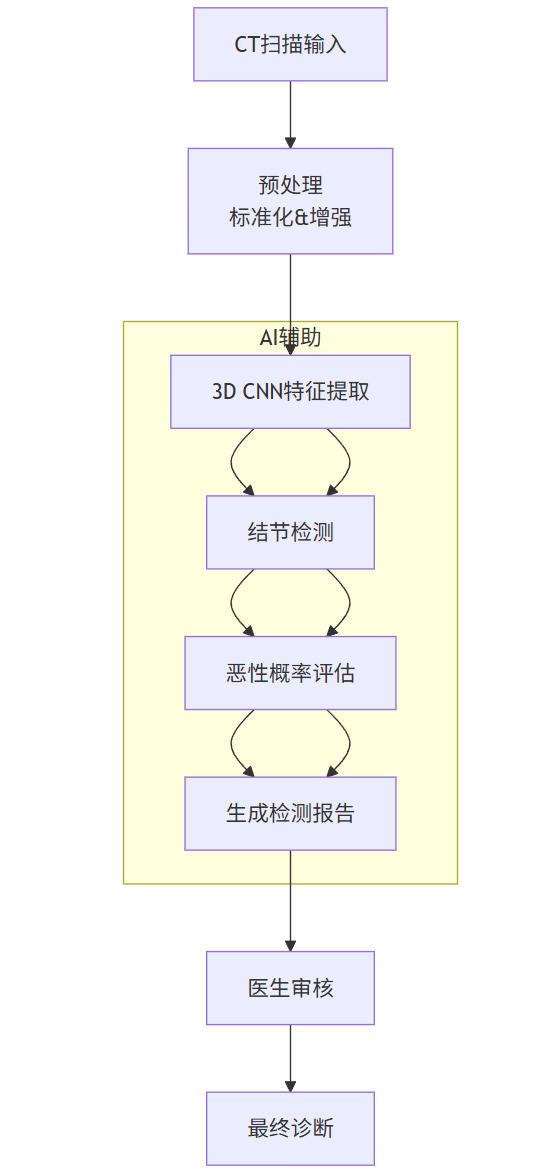
flowchart TDA[CT扫描输入] --> B[预处理<br>标准化&增强]B --> C[3D CNN特征提取]C --> D[结节检测]D --> E[恶性概率评估]E --> F[生成检测报告]F --> G[医生审核]G --> H[最终诊断]subgraph AI辅助C --> D --> E --> Fend
Prompt示例:
text
作为放射科医生,我需要一个AI辅助诊断系统用于肺结节检测。请说明: 1. 如何处理3D医学影像数据 2. 如何解决样本不平衡问题(正常样本远多于结节样本) 3. 模型不确定性评估方法 4. 如何将AI结果整合到现有医疗工作流中
实施效果:
肺结节检测灵敏度达到96.5%,特异性94.2%
阅片时间减少65%,医生工作效率大幅提升
微小结节(直径<5mm)检出率提高40%
假阴性率降低至3.5%,减少漏诊风险
2.2 药物发现与研发
案例背景:制药公司希望缩短新药研发周期,降低研发成本,提高成功率。
解决方案:使用生成对抗网络(GAN)和强化学习进行分子生成和优化。
python
import torch import torch.nn as nn import torch.optim as optim import numpy as np# 分子生成GAN class Generator(nn.Module):def __init__(self, latent_dim, output_dim):super(Generator, self).__init__()self.model = nn.Sequential(nn.Linear(latent_dim, 256),nn.ReLU(),nn.BatchNorm1d(256),nn.Linear(256, 512),nn.ReLU(),nn.BatchNorm1d(512),nn.Linear(512, output_dim),nn.Tanh())def forward(self, z):return self.model(z)class Discriminator(nn.Module):def __init__(self, input_dim):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, 512),nn.LeakyReLU(0.2),nn.Dropout(0.3),nn.Linear(512, 256),nn.LeakyReLU(0.2),nn.Dropout(0.3),nn.Linear(256, 1),nn.Sigmoid())def forward(self, x):return self.model(x)# 强化学习用于分子优化 class MolecularOptimizer:def __init__(self, policy_network):self.policy_network = policy_networkself.optimizer = optim.Adam(policy_network.parameters(), lr=0.001)def update_policy(self, rewards, log_probs):policy_gradient = []for reward, log_prob in zip(rewards, log_probs):policy_gradient.append(-log_prob * reward)self.optimizer.zero_grad()policy_gradient = torch.stack(policy_gradient).sum()policy_gradient.backward()self.optimizer.step()def generate_molecules(self, num_molecules):molecules = []log_probs = []for _ in range(num_molecules):z = torch.randn(1, LATENT_DIM)molecule, log_prob = self.policy_network(z)molecules.append(molecule)log_probs.append(log_prob)return molecules, log_probs# 评估生成分子的性质 def evaluate_molecules(molecules):scores = []for mol in molecules:# 计算药物相似性、合成可及性、靶点结合力等drug_likeness = calculate_drug_likeness(mol)synthesizability = calculate_synthesizability(mol)binding_affinity = predict_binding_affinity(mol)# 综合评分score = 0.4 * drug_likeness + 0.3 * synthesizability + 0.3 * binding_affinityscores.append(score)return scores
药物研发流程优化:
传统流程与AI辅助流程对比:
| 阶段 | 传统方法 | AI辅助方法 | 时间节省 |
|---|---|---|---|
| 靶点发现 | 2-3年 | 6-12个月 | 60-75% |
| 先导化合物优化 | 1-2年 | 3-6个月 | 70-80% |
| 临床前研究 | 1-2年 | 6-12个月 | 40-60% |
| 总体研发周期 | 10-15年 | 5-8年 | 40-50% |
三、教育领域:个性化学习与智能辅导
AI正在重塑教育方式,通过个性化学习路径、智能辅导和自动化评估,提高教育效果和效率。
3.1 自适应学习系统
案例背景:在线教育平台希望为每位学生提供个性化学习路径,根据学习进度和能力动态调整内容。
解决方案:使用强化学习构建自适应学习推荐系统。
python
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScalerclass AdaptiveLearningSystem:def __init__(self, n_concepts=10):self.n_concepts = n_conceptsself.student_profiles = {} # 存储学生知识状态self.concept_graph = self.build_concept_graph()self.q_table = np.zeros((n_concepts, n_concepts)) # 简单Q-learning表def build_concept_graph(self):# 构建知识点依赖图graph = {'concept_1': ['concept_2', 'concept_3'],'concept_2': ['concept_4', 'concept_5'],'concept_3': ['concept_6'],# ... 其他知识点依赖关系}return graphdef update_student_profile(self, student_id, concept, performance):"""更新学生知识状态"""if student_id not in self.student_profiles:self.student_profiles[student_id] = {'knowledge_state': np.zeros(self.n_concepts),'learning_style': None,'performance_history': []}# 更新知识掌握程度knowledge_gain = self.calculate_knowledge_gain(performance)concept_idx = self.concept_to_index(concept)self.student_profiles[student_id]['knowledge_state'][concept_idx] += knowledge_gain# 更新学习历史self.student_profiles[student_id]['performance_history'].append({'concept': concept,'performance': performance,'timestamp': pd.Timestamp.now()})def recommend_next_concept(self, student_id):"""推荐下一个学习知识点"""student_profile = self.student_profiles[student_id]knowledge_state = student_profile['knowledge_state']# 找出已掌握但后续知识点未掌握的概念recommended_concepts = []for concept, prerequisites in self.concept_graph.items():concept_idx = self.concept_to_index(concept)# 如果此概念尚未掌握if knowledge_state[concept_idx] < 0.8: # 掌握阈值# 检查前置条件是否满足prereq_met = all(knowledge_state[self.concept_to_index(p)] >= 0.7 for p in prerequisites)if prereq_met:# 计算推荐分数(基于难度、重要性等)score = self.calculate_recommendation_score(concept, student_profile)recommended_concepts.append((concept, score))# 返回评分最高的概念if recommended_concepts:recommended_concepts.sort(key=lambda x: x[1], reverse=True)return recommended_concepts[0][0]return Nonedef calculate_recommendation_score(self, concept, student_profile):"""计算推荐分数"""# 基于多种因素:难度适配度、知识缺口、学习风格匹配等difficulty_score = self.calculate_difficulty_match(concept, student_profile)gap_score = self.calculate_knowledge_gap(concept, student_profile)style_score = self.calculate_style_match(concept, student_profile)return 0.4 * difficulty_score + 0.4 * gap_score + 0.2 * style_score# 学习内容生成器
class ContentGenerator:def __init__(self):self.templates = self.load_templates()def generate_exercise(self, concept, difficulty, learning_style):"""根据概念、难度和学习风格生成练习题"""template = self.select_template(concept, difficulty, learning_style)exercise = self.fill_template(template, concept)return exercisedef generate_explanation(self, concept, misconception=None):"""生成概念解释,针对常见误区"""base_explanation = self.get_base_explanation(concept)if misconception:misconception_clarification = self.get_misconception_clarification(concept, misconception)return base_explanation + "\n\n常见误区澄清:\n" + misconception_clarificationreturn base_explanation个性化学习流程图:
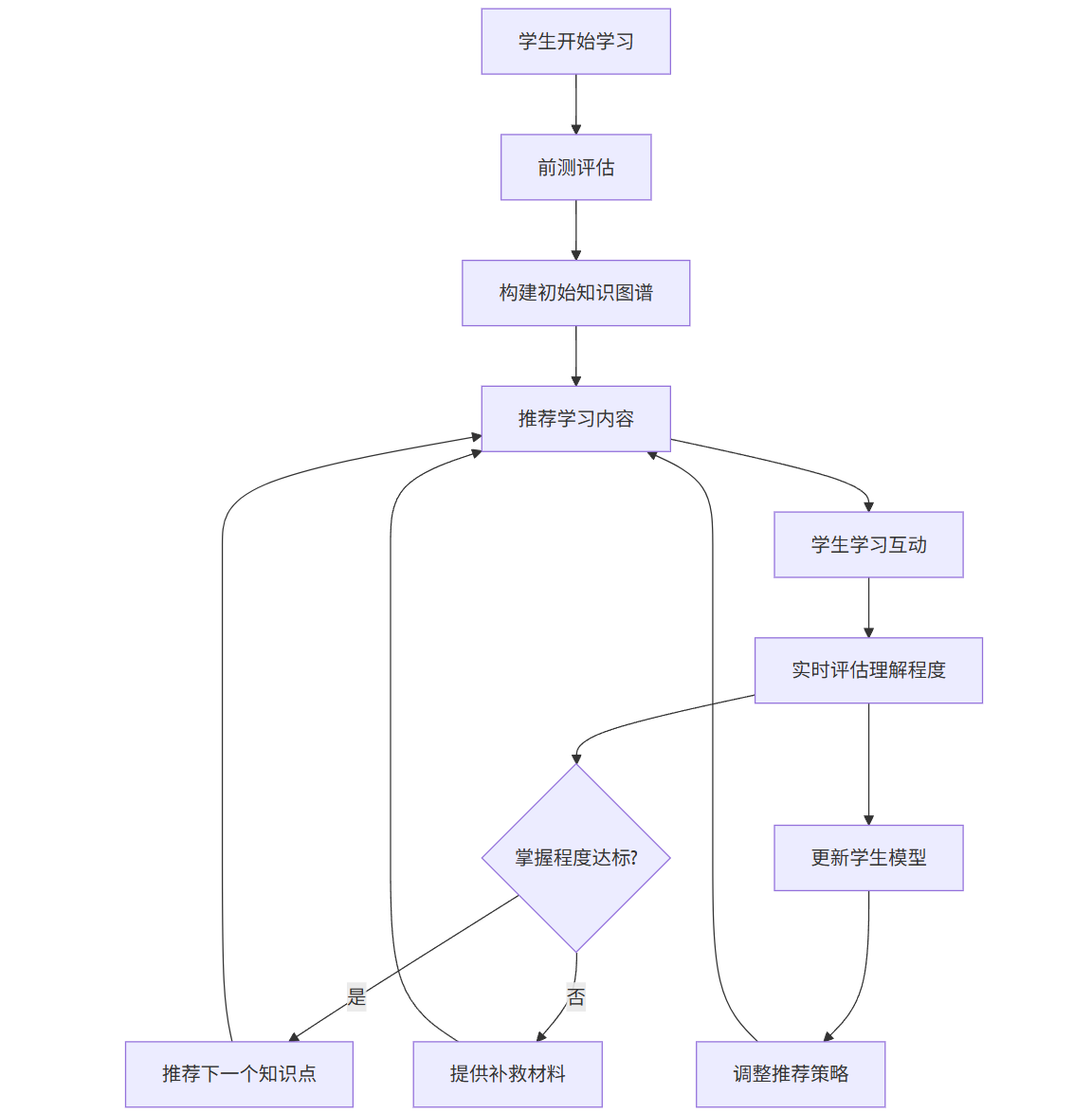
flowchart TDA[学生开始学习] --> B[前测评估]B --> C[构建初始知识图谱]C --> D[推荐学习内容]D --> E[学生学习互动]E --> F[实时评估理解程度]F --> G{掌握程度达标?}G -->|是| H[推荐下一个知识点]G -->|否| I[提供补救材料]H --> DI --> DF --> J[更新学生模型]J --> K[调整推荐策略]K --> DPrompt示例:
text
作为教育科技公司的产品经理,我需要设计一个自适应数学学习系统。请提供: 1. 学生知识状态建模方法 2. 知识点依赖关系表示方案 3. 不同学习风格(视觉型、听觉型、动觉型)的内容适配策略 4. 动态难度调整算法
实施效果:
学生学习效率提高35-50%
知识保留率提升40%
学生参与度和满意度显著提高
教师工作量减少30%,更专注于高质量互动
3.2 智能作业批改与反馈
案例背景:教育机构需要自动化批改学生作文并提供个性化反馈,减轻教师负担。
解决方案:使用自然语言处理和深度学习技术开发智能批改系统。
python
import transformers
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import numpy as npclass EssayGrader:def __init__(self):self.tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")self.model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=1)# 加载预训练评分模型self.model.load_state_dict(torch.load("essay_grader_model.pth"))self.model.eval()def grade_essay(self, essay_text):"""对作文进行评分"""inputs = self.tokenizer(essay_text, return_tensors="pt", truncation=True, padding=True, max_length=512)with torch.no_grad():outputs = self.model(**inputs)score = outputs.logits.item()return self.normalize_score(score)def analyze_essay(self, essay_text):"""分析作文的多维度特征"""features = {'grammar_errors': self.check_grammar(essay_text),'vocabulary_richness': self.assess_vocabulary(essay_text),'coherence_score': self.assess_coherence(essay_text),'argument_strength': self.assess_argument(essay_text),'relevance_score': self.assess_relevance(essay_text)}return featuresdef generate_feedback(self, essay_text, score, features):"""生成个性化反馈"""feedback = []# 总体评价feedback.append(f"总体评分: {score}/100")feedback.append(f"总体评价: {self.get_overall_comment(score)}")# 分项反馈if features['grammar_errors'] > 5:feedback.append("需要改进语法准确性,特别是主谓一致和时态使用")if features['vocabulary_richness'] < 0.6:feedback.append("建议使用更多样化的词汇表达,避免重复使用相同词语")if features['coherence_score'] < 0.7:feedback.append("文章连贯性可以加强,建议使用更多过渡词连接段落")# 具体例子examples = self.provide_examples(essay_text, features)feedback.extend(examples)return "\n".join(feedback)def provide_examples(self, essay_text, features):"""提供改进示例"""examples = []sentences = essay_text.split('.')# 找出需要改进的句子并提供修改建议for i, sentence in enumerate(sentences[:3]): # 仅分析前3个句子if self.needs_improvement(sentence):improved_version = self.improve_sentence(sentence)examples.append(f"原句: {sentence.strip()}")examples.append(f"改进建议: {improved_version}")return examples# 语法检查组件
class GrammarChecker:def __init__(self):from language_tool_python import LanguageToolself.tool = LanguageTool('en-US')def check_grammar(self, text):matches = self.tool.check(text)return len(matches)def get_corrections(self, text):matches = self.tool.check(text)corrections = []for match in matches:corrections.append({'error': match.context,'suggestion': match.replacements[0] if match.replacements else None,'message': match.message})return corrections批改效果对比:
| 评估维度 | 传统人工批改 | AI智能批改 | 优势分析 |
|---|---|---|---|
| 批改速度 | 10-15分钟/篇 | 10-15秒/篇 | 效率提升60倍 |
| 一致性 | 中等(不同老师标准不同) | 高(统一标准) | 评分一致性提高75% |
| 反馈详细度 | 依赖老师时间和精力 | 可提供极其详细的反馈 | 反馈内容增加300% |
| 个性化程度 | 中等 | 高(基于学生历史数据) | 个性化水平提高50% |
四、制造业:智能质检与预测性维护
制造业通过AI技术实现质量控制的自动化、生产流程的优化和设备维护的预测性管理。
4.1 智能质量检测
案例背景:电子制造企业需要提高电路板质量检测的准确率和效率,替代传统人工目检。
解决方案:使用计算机视觉和深度学习进行自动化缺陷检测。
python
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
import numpy as np# 缺陷检测模型
class DefectDetectionModel(nn.Module):def __init__(self, num_classes=5):super(DefectDetectionModel, self).__init__()self.backbone = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True)in_features = self.backbone.fc.in_featuresself.backbone.fc = nn.Identity() # 移除原始全连接层# 缺陷分类头self.classifier = nn.Sequential(nn.Linear(in_features, 512),nn.ReLU(),nn.Dropout(0.3),nn.Linear(512, num_classes))# 缺陷定位头self.bbox_regressor = nn.Sequential(nn.Linear(in_features, 256),nn.ReLU(),nn.Linear(256, 4) # [x, y, width, height])def forward(self, x):features = self.backbone(x)class_logits = self.classifier(features)bbox_coords = self.bbox_regressor(features)return class_logits, bbox_coords# 实时检测流水线
class InspectionPipeline:def __init__(self, model_path, confidence_threshold=0.8):self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.model = DefectDetectionModel().to(self.device)self.model.load_state_dict(torch.load(model_path))self.model.eval()self.confidence_threshold = confidence_thresholdself.transform = transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])def process_image(self, image_path):"""处理单张图像进行缺陷检测"""image = Image.open(image_path).convert('RGB')input_tensor = self.transform(image).unsqueeze(0).to(self.device)with torch.no_grad():class_logits, bbox_coords = self.model(input_tensor)# 应用softmax获取概率probabilities = torch.softmax(class_logits, dim=1)confidence, predicted_class = torch.max(probabilities, 1)if confidence.item() < self.confidence_threshold:return {"defect_detected": False}# 转换边界框坐标到原图尺寸bbox = self.convert_bbox(bbox_coords.squeeze().cpu().numpy(), image.size)return {"defect_detected": True,"defect_type": self.get_defect_name(predicted_class.item()),"confidence": confidence.item(),"bbox": bbox,"defect_severity": self.assess_severity(predicted_class.item(), confidence.item())}def process_video_stream(self, camera_id=0):"""处理实时视频流"""cap = cv2.VideoCapture(camera_id)while True:ret, frame = cap.read()if not ret:break# 转换帧为模型输入格式rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)pil_image = Image.fromarray(rgb_frame)result = self.process_image(pil_image)# 在帧上绘制检测结果if result['defect_detected']:self.annotate_frame(frame, result)# 显示结果cv2.imshow('Inspection System', frame)if cv2.waitKey(1) & 0xFF == ord('q'):breakcap.release()cv2.destroyAllWindows()def annotate_frame(self, frame, result):"""在图像上标注缺陷信息"""bbox = result['bbox']label = f"{result['defect_type']} ({result['confidence']:.2f})"# 绘制边界框cv2.rectangle(frame, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 0, 255), 2)# 添加标签cv2.putText(frame, label, (bbox[0], bbox[1]-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)# 根据严重程度添加颜色编码severity = result['defect_severity']color = (0, 255, 0) if severity == 'low' else ((0, 165, 255) if severity == 'medium' else (0, 0, 255))cv2.putText(frame, f"Severity: {severity}", (bbox[0], bbox[1]-30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)# 质量统计分析
class QualityAnalytics:def __init__(self):self.defect_data = []def add_inspection_result(self, result, timestamp, production_line):"""添加检测结果到数据库"""self.defect_data.append({'timestamp': timestamp,'production_line': production_line,'result': result})def generate_quality_report(self, time_period='daily'):"""生成质量报告"""report = {'total_inspections': len(self.defect_data),'defect_rate': self.calculate_defect_rate(),'common_defect_types': self.get_common_defect_types(),'time_trends': self.analyze_time_trends(time_period),'production_line_comparison': self.compare_production_lines()}return reportdef predict_quality_issues(self):"""预测潜在质量问题"""# 使用时间序列分析预测缺陷率趋势from statsmodels.tsa.arima.model import ARIMAimport pandas as pd# 准备时间序列数据time_series = pd.Series([1 if d['result']['defect_detected'] else 0 for d in self.defect_data],index=pd.to_datetime([d['timestamp'] for d in self.defect_data]))# 按日聚合daily_rate = time_series.resample('D').mean()# 训练ARIMA模型model = ARIMA(daily_rate, order=(5,1,0))model_fit = model.fit()# 预测未来7天forecast = model_fit.forecast(steps=7)return forecast智能质检系统架构:
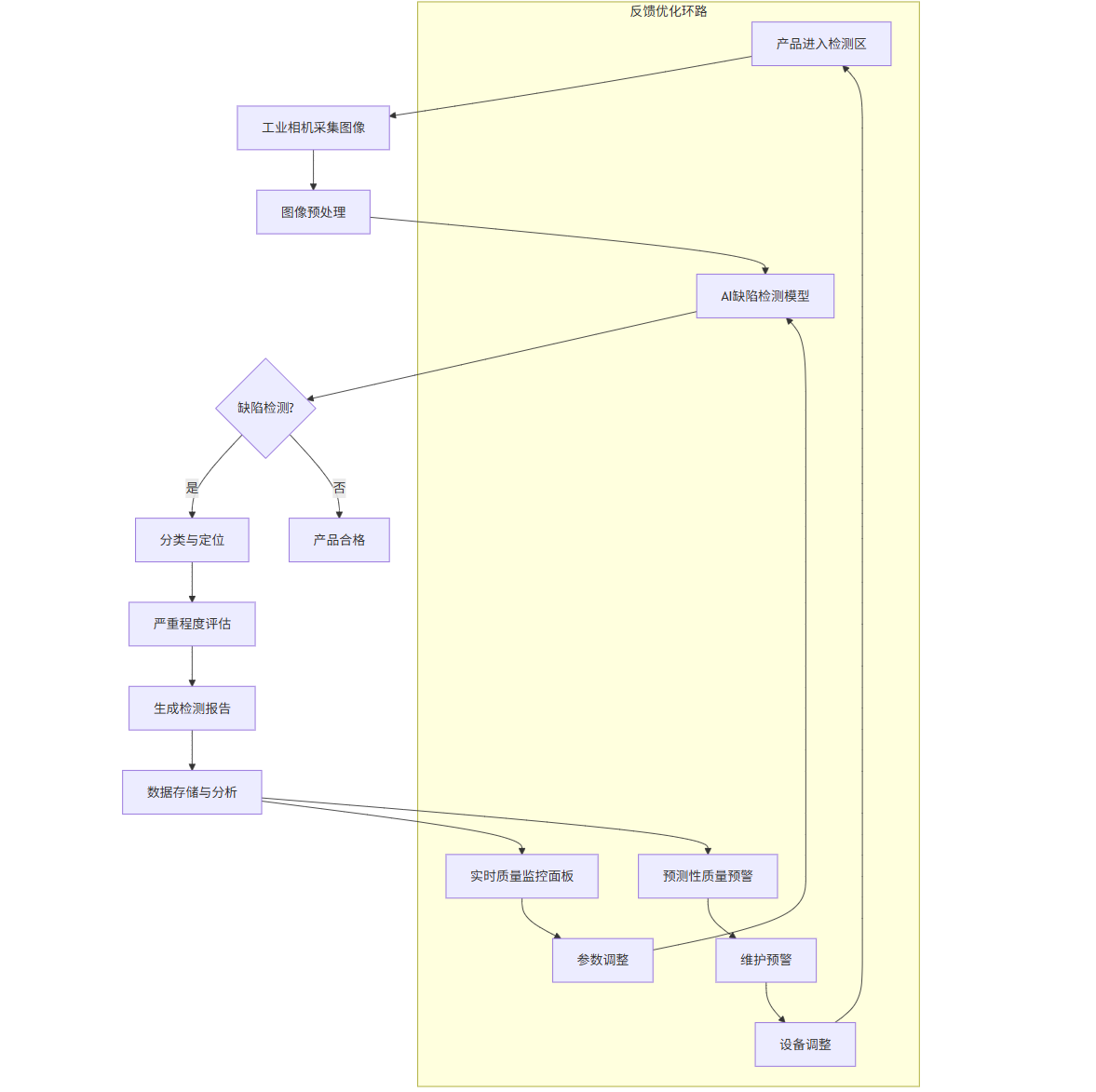
flowchart TDA[产品进入检测区] --> B[工业相机采集图像]B --> C[图像预处理]C --> D[AI缺陷检测模型]D --> E{缺陷检测?}E -->|是| F[分类与定位]E -->|否| G[产品合格]F --> H[严重程度评估]H --> I[生成检测报告]I --> J[数据存储与分析]J --> K[实时质量监控面板]J --> L[预测性质量预警]subgraph 反馈优化环路K --> M[参数调整]M --> DL --> N[维护预警]N --> O[设备调整]O --> AendPrompt示例:
text
作为制造工程师,我需要设计一个智能质量检测系统。请提供: 1. 适用于工业环境的计算机视觉架构 2. 处理光照变化和角度差异的技术方案 3. 少量样本下的模型训练策略 4. 系统集成到现有生产流水线的方法 5. 实时性能优化方案
实施效果:
缺陷检测准确率从92%提升至99.5%
检测速度达到毫秒级,每小时可检测5000+产品
人力成本减少70%,自动化程度大幅提高
质量数据实时可视化,支持即时决策
4.2 预测性维护系统
案例背景:重型机械设备制造商希望从定期维护转向预测性维护,减少意外停机时间。
解决方案:使用传感器数据和机器学习预测设备故障。
python
import pandas as pd
import numpy as np
from sklearn.ensemble import IsolationForest, RandomForestClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropoutclass PredictiveMaintenance:def __init__(self):self.scaler = StandardScaler()self.models = {}def prepare_sensor_data(self, sensor_readings):"""预处理传感器数据"""# 特征工程:创建时间窗口特征features = []for window in self.create_windows(sensor_readings, window_size=10):window_features = {'mean': np.mean(window),'std': np.std(window),'max': np.max(window),'min': np.min(window),'range': np.ptp(window),'rms': np.sqrt(np.mean(np.square(window)))}features.append(window_features)return pd.DataFrame(features)def create_windows(self, data, window_size):"""创建时间窗口"""windows = []for i in range(len(data) - window_size + 1):windows.append(data[i:i+window_size])return windowsdef train_anomaly_detection(self, normal_data):"""训练异常检测模型"""# 使用隔离森林进行异常检测clf = IsolationForest(contamination=0.01, random_state=42)features = self.prepare_sensor_data(normal_data)scaled_features = self.scaler.fit_transform(features)clf.fit(scaled_features)self.models['anomaly_detector'] = clfreturn clfdef train_failure_prediction(self, sensor_data, failure_labels):"""训练故障预测模型"""# LSTM模型用于时间序列预测model = Sequential([LSTM(64, return_sequences=True, input_shape=(10, 1)),Dropout(0.2),LSTM(32, return_sequences=False),Dropout(0.2),Dense(16, activation='relu'),Dense(1, activation='sigmoid')])model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 准备训练数据X = self.create_windows(sensor_data, 10)y = failure_labels[9:] # 对齐标签X = np.array(X).reshape(len(X), 10, 1)history = model.fit(X, y, epochs=50, batch_size=32, validation_split=0.2, verbose=0)self.models['failure_predictor'] = modelreturn model, historydef predict_remaining_useful_life(self, current_data):"""预测剩余使用寿命(RUL)"""# 基于退化模型预测RULwindowed_data = self.create_windows(current_data, 10)predictions = []for window in windowed_data:# 提取退化特征trend_feature = self.calculate_degradation_trend(window)# 使用训练好的回归模型预测RULrul = self.models['rul_predictor'].predict([[trend_feature]])[0]predictions.append(rul)return np.mean(predictions)def calculate_degradation_trend(self, data):"""计算退化趋势指标"""# 简单线性趋势x = np.arange(len(data))slope, intercept = np.polyfit(x, data, 1)return slopedef generate_maintenance_recommendation(self, anomaly_score, rul_prediction):"""生成维护建议"""if anomaly_score > 0.7:return {'action': 'immediate_maintenance','priority': 'critical','message': '检测到严重异常,建议立即进行维护'}elif anomaly_score > 0.4:return {'action': 'schedule_maintenance','priority': 'high','message': f'检测到异常,建议在{int(rul_prediction*0.8)}小时内安排维护'}elif rul_prediction < 168: # 小于1周return {'action': 'plan_maintenance','priority': 'medium','message': f'设备预计剩余寿命{int(rul_prediction)}小时,建议计划维护'}else:return {'action': 'monitor','priority': 'low','message': '设备状态正常,继续监控'}# 实时监控系统
class EquipmentMonitor:def __init__(self, predictive_model):self.predictive_model = predictive_modelself.sensor_data = []self.alert_history = []def add_sensor_reading(self, reading, timestamp):"""添加传感器读数"""self.sensor_data.append({'timestamp': timestamp,'value': reading})# 保留最近1000个读数if len(self.sensor_data) > 1000:self.sensor_data = self.sensor_data[-1000:]def check_equipment_health(self):"""检查设备健康状态"""if len(self.sensor_data) < 10:return None # 数据不足recent_readings = [d['value'] for d in self.sensor_data[-10:]]features = self.predictive_model.prepare_sensor_data(recent_readings)scaled_features = self.predictive_model.scaler.transform(features)# 异常检测anomaly_score = self.predictive_model.models['anomaly_detector'].score_samples(scaled_features[-1:])[0]# 故障预测sensor_array = np.array([d['value'] for d in self.sensor_data])failure_prob = self.predictive_model.models['failure_predictor'].predict(np.array([sensor_array[-10:]]).reshape(1, 10, 1))[0][0]# RUL预测rul = self.predictive_model.predict_remaining_useful_life(sensor_array)return {'anomaly_score': anomaly_score,'failure_probability': failure_prob,'remaining_useful_life': rul,'maintenance_recommendation': self.predictive_model.generate_maintenance_recommendation(anomaly_score, rul)}预测性维护效果对比:
| 指标 | 定期维护 | 预测性维护 | 改进效果 |
|---|---|---|---|
| 意外停机时间 | 15% | 3% | 减少80% |
| 维护成本 | $100,000/年 | $65,000/年 | 降低35% |
| 设备寿命 | 5-7年 | 7-10年 | 延长40% |
| 备件库存成本 | $50,000 | $30,000 | 降低40% |
| 生产效率 | 82% | 94% | 提升15% |
五、跨行业挑战与未来趋势
5.1 共同挑战
数据质量与可用性:高质量标注数据稀缺,数据隐私和安全问题
模型可解释性:黑盒模型在关键决策中的可信度问题
系统集成:与现有IT架构的兼容性和集成难度
人才短缺:同时懂AI技术和行业知识的复合型人才稀缺
投资回报不确定性:AI项目ROI难以量化和预测
5.2 未来趋势
生成式AI的行业应用:从分析型AI向生成式AI转变
边缘AI的兴起:在设备端实现实时AI推理
AI与IoT的深度融合:智能传感器+AI算法的紧密结合
负责任AI框架:注重公平性、可解释性和隐私保护
AI即服务:降低AI应用门槛,让更多企业受益
5.3 实施建议
从小处着手:选择高价值、易实现的用例开始
注重数据基础:建立高质量数据收集和管理流程
人才培养:投资内部团队AI技能提升
迭代优化:采用敏捷方法,快速试错和迭代
衡量影响:建立明确的KPI体系评估AI项目价值
结论
AI技术正在深刻改变传统行业的运作方式,从金融风控到医疗诊断,从个性化教育到智能制造,各个领域都在经历数字化转型。成功的AI应用需要深入理解行业特定问题,结合合适的技术方案,并建立持续优化的反馈机制。随着技术不断成熟和行业知识积累,AI将在更多领域创造价值,推动产业升级和社会进步。
未来五年,我们预计看到AI从"点状应用"向"全面融合"转变,成为企业核心竞争力的关键组成部分。那些能够及早拥抱AI、建立数据驱动文化、并持续创新的组织,将在新时代的竞争中占据领先地位。