大数据电商流量分析项目实战:Flume 数据采集及ETL入仓(五)


✨博客主页: https://blog.csdn.net/m0_63815035?type=blog
💗《博客内容》:大数据、Java、测试开发、Python、Android、Go、Node、Android前端小程序等相关领域知识
📢博客专栏: https://blog.csdn.net/m0_63815035/category_11954877.html
📢欢迎点赞 👍 收藏 ⭐留言 📝
📢本文为学习笔记资料,如有侵权,请联系我删除,疏漏之处还请指正🙉
📢大厦之成,非一木之材也;大海之阔,非一流之归也✨

前言&课程重点
大家好,我是程序员小羊!接下来一周,咱们将用 “实战拆解 + 技术落地” 的方式,带大家吃透一个完整的大数据电商项目 ——不管你是想靠项目经验敲开大厂就业门,还是要做毕业设计、提升技术深度,这门课都能帮你 “从懂概念到能落地”。
毕竟大数据领域不缺 “会背理论” 的人,缺的是 “能把项目跑通、能跟业务结合” 的实战型选手。咱们这一周的内容,不搞虚的,全程围绕 “电商业务痛点→数据解决方案→技术栈落地” 展开,每天聚焦 1 个核心模块,最后还能输出可放进简历的项目成果。
进入正题:
本项目是一门实战导向的大数据课程,专为具备Java基础但对大数据生态系统不熟悉的同学量身打造。你将从零开始,逐步掌握大数据的基本概念、架构原理以及在电商流量分析中的实际应用,迅速融入当下热门的离线数据处理技术。
在这门课程中,你将学会如何搭建和优化Hadoop高可用环境,了解HDFS存储、YARN资源调度的核心原理,为数据处理打下坚实的基础。同时,你将掌握Hive数据仓库的构建和数仓建模方法,了解如何将海量原始数据经过层次化处理,转化为高质量的数据资产。
课程还将引领你深入Spark SQL的世界,通过实际案例学习如何利用Spark高效计算PV、UV以及各类衍生指标,提升数据分析效率。此外,你还将学习Flume的安装与配置,实现Web日志的实时采集和ETL入仓,确保数据传输的稳定与高效。
为了贴近企业实际运作,本项目还包括定时任务的设置和自动化数据管道构建,教你如何编写Shell脚本并利用crontab定时调度Spark作业,让数据处理过程实现自动化与智能化。最后,通过可视化展示模块,你将学会用FineBI等工具将数据分析结果直观呈现
总之,这是一门集大数据基础、系统搭建、数据处理与智能分析于一体的全链路实战课程。无论你是初入大数据领域的新手,还是希望提升数据处理能力的开发者,都将在这里收获满满,掌握最前沿的大数据技术。
课程计划:
| 天数 | 主题 | 主要内容 |
|---|---|---|
| Day 1 | 大数据基础+项目分组 (ZK补充) | 大数据概念、数仓建模、组件介绍、分组;简单介绍项目。 |
| Day 2 | Hadoop初认识+ HA环境搭建 | 初认识Hadoop,了解HDFS 基本操作,YARN 资源调度,数据存储测试等,并且完成Hadoop高可用的环境搭建。 |
| Day 3 | Hive 数据仓库 | Hive SQL 基础、表设计、加载数据,搭建Hive环境并融入Hadoop实现高可用 |
| Day 4 | Spark SQL 基础 | 讲解Spark基础,DataFrame & SQL 查询,Hive 集成和环境的搭建 |
| Day 5 | Flume 数据采集及ETL入仓 | 安装Flume高可用,学习基础的Flume知识并且使用Flume 采集 Web 日志,存入 HDFS;数据格式解析,数据传输优化 |
| Day 6 | 数据入仓 & 指标计算 | 解析 PV、UV 计算逻辑,Hive 数据清洗、分层存储(ODS → DWD) |
| Day 7 | Spark 计算 & 指标优化 | 使用 Spark SQL 计算 PV、UV 及衍生指标(如跳出率、人均访问时长等) |
| Day 8 | 定时任务 & 数据管道 | 编写 Shell 脚本,使用 crontab 实现定时任务,调度 Spark SQL |
| Day 9 | 可视化 & 数据分析 | 搭建一个简单的项目使用 FineBI 进行数据展示,分析趋势。 |
| Day 10 | 项目答辩 | 小组演示分析结果,可以后台联系程序员小羊点评 |
今日学习重点(flume采集):
你已经搭建好环境,现在要实现 Flume → Hive 入仓 → Spark 处理 的完整流程,并提取时间戳中的 小时 作为一个指标。下面是详细的步骤:
flume是什么
Flume 是一个分布式、可靠且可扩展的日志采集系统,专门设计用于高吞吐量的日志数据传输。它能够将来自不同来源(如 Web 服务器、应用服务器)的日志数据实时传输到存储系统,如 HDFS 或 Hive。在这里,他要帮我们处理典型的日志数据,将数据入仓。
特点:高可靠性,高扩展性、高灵活性、高实时,典型用于日志文件采集、监控数据传输、业务指标实时统计等。
Flume 的核心架构由 Source(数据源)、Channel(通道) 和 Sink(数据目的地) 三部分组成,每个组件在整个数据流中都发挥着关键作用:
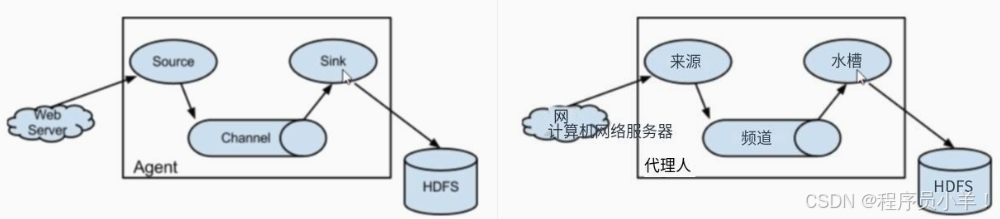
日志文件(服务器) --> Source (采集日志) --> Channel (临时缓冲) --> Sink (输出到 HDFS) --> Hive(外部表映射)
Agent(核心):
在每一个采集任务中,无论是实时的数据采集还是离线的批量数据采集,都有一个任务的核心,通常我们定义为 Agent,在创建项目的时候我们也要配置 例如 a1.xxx 作为核心的配置
Source(数据源):
从外部数据源(如日志文件、系统命令输出)中读取数据。常用的类型包括:TailDir(实时监控目录下文件)、Exec(执行命令并采集输出)等。
Channel(通道):
作为数据的临时存储区域,连接 Source 和 Sink。常见类型有内存队列和文件队列,保证数据的缓冲和传递安全。
Sink(数据目的地):
将数据输出到指定存储系统中,如 HDFS、Hive、Kafka 等。对于日志数据入仓 Hive,通常会将数据先写入 HDFS,再由 Hive 建立外部表进行映射和查询。
安装Flume
接下来我们开始安装Flume,首先请先准备 apache-flume-1.11.0-bin.tar.gz 文件,并确保打开集群的三个节点(node01 node02 node03)。
- 将 Flume 安装包上传至服务器并解压
[root@node01 ~]# tar -zxvf apache-flume-1.11.0-bin.tar.gz -C /opt/yjx/
- 修改环境配置脚本文件
flume-env.sh:
[root@node01 ~]# cd /opt/yjx/apache-flume-1.11.0-bin/conf
[root@node01 conf]# cp flume-env.sh.template flume-env.sh
[root@node01 conf]# vim flume-env.sh>>>>在文件末尾添加下面内容export JAVA_HOME=/usr/java/jdk1.8.0_351-amd64
# 设置使用内存大小
export JAVA_OPTS="-Xms512m -Xmx1024m -Dcom.sun.management.jmxremote"
- 删除内置的Guava包,将
apache-flume-1.11.0-bin/lib目录下的guava-11.0.2.jar包删除以兼容 Hadoop。
[root@node01 ~]# ls /opt/yjx/apache-flume-1.11.0-bin/lib/guava*/opt/yjx/apache-flume-1.11.0-bin/lib/guava-11.0.2.jar
[root@node01 ~]# rm /opt/yjx/apache-flume-1.11.0-bin/lib/guava-11.0.2.jar -rf
- 将 node01 配置好的 Flume 拷贝至 node02 和 node03。
[root@node02 ~]# scp -r root@node01:/opt/yjx/apache-flume-1.11.0-bin/ /opt/yjx/
[root@node03 ~]# scp -r root@node01:/opt/yjx/apache-flume-1.11.0-bin/ /opt/yjx/
- 修改三个机器环境变量,修改环境变量
vim /etc/profile,在文件末尾添加以下内容
export FLUME_HOME=/opt/yjx/apache-flume-1.11.0-bin
export PATH=$FLUME_HOME/bin:$PATH
修改完成后source /etc/profile重新加载环境变量。
- 校验安装是否成功
[root@node01 ~]# flume-ng version
Flume 1.11.0
Source code repository: https://git.apache.org/repos/asf/flume.git
Revision: 1a15927e594fd0d05a59d804b90a9c31ec93f5e1
Compiled by rgoers on Sun Oct 16 14:44:15 MST 2022
From source with checksum bbbca682177262aac3a89defde369a37
Flume介绍
Flume 在大数据生态系统中扮演着数据流动的关键角色。它将分散在各个业务系统中的海量日志数据高效、实时地汇聚到大数据平台中,为后续的数据存储、处理与分析提供了坚实的基础。
通过灵活的 Source、Channel 和 Sink 架构,Flume 能够无缝对接 Hadoop、Hive、Kafka 等系统,确保数据从生成到入仓的全过程既稳定又高效。其高扩展性和可靠性,使得在面对不断增长的数据量和复杂业务场景时,Flume 成为支撑大数据平台的重要一环,为企业决策和业务优化提供了实时数据支撑。
如果我们要使用这个首先安装完成之后你需要创建一个 xxx.conf 的文件,一般建议放置在 Flume 根目录下的 conf/ 文件夹,运行时只需要使用 -f 参数指定配置文件 即可。
运行:bin/flume-ng agent -n <agent_name> -c conf -f conf/<xxx.conf>
演示:bin/flume-ng agent -n a1 -c conf -f conf/flume-nginx.conf
source机制
Flume 的 Source 负责从外部数据源获取数据,并将数据转换为 Event(事件) 传递给 Channel。常见的数据源包括 日志文件、执行命令输出、消息队列、网络流数据等。Flume 支持多种 Source 类型,每种 Source 适用于不同的应用场景。
多个 Source 可以组成 Source 组,同时采集不同来源的数据,并通过 Channel 统一管理。
通过灵活的参数配置,你可以让 Flume 适应各种业务需求,比如监听远程日志、处理文件流式数据、接收 HTTP 请求等。
source的多种数据源:
| Source 类型 | 描述 | 适用场景 | 主要配置参数 |
|---|---|---|---|
| Exec | 通过执行 shell 命令获取数据 | 监控日志文件(如 tail -F)或运行自定义脚本 | command(要执行的命令) |
| Spooling Directory | 监控指定目录下的新文件 | 采集应用程序生成的日志文件 | spoolDir(目录路径) |
| Netcat | 监听 TCP/UDP 端口 | 从远程服务器推送日志数据 | bind(监听 IP)、port(端口) |
| Syslog | 监听 syslog 协议日志 | 采集系统日志(支持 TCP/UDP) | port(监听端口)、protocol(tcp/udp) |
| Kafka | 订阅 Kafka 消息队列 | 采集分布式日志数据 | kafka.bootstrap.servers(Kafka 地址)、kafka.topics(订阅的主题) |
| Avro | 监听 Avro RPC 请求 | 适用于 Flume 与 Flume 之间的数据传输 | bind(监听地址)、port(端口) |
| HTTP | 通过 HTTP 接口接收数据 | 处理 Web 应用的日志上报 | port(监听端口) |
Source端的基本配置
在 Flume 的配置文件中,我们可以按照 a1.source = r1 创建一个单一的Source源并且给他配置source的类型和对应类型要绑定的参数来声明一个source。
同时source必须要绑定一个channel,这边我们简单提一嘴,后续在channel你会了解到。
# 定义 Source
a1.source = r1
a1.sources.r1.type = <Source 类型>
a1.sources.r1.<参数名> = <参数值># a1 代表 Flume agent 的名称
# r1 代表 Source 的名称# 绑定 Channel
a1.sources.r1.channels = c1
Source的多数据源采集
如果你的数据来源于 多个机器、多种数据源,Flume 允许你定义多个 Source,并使用 Source 组(Source Groups) 来协调它们。你可以这样配置他们
# 组一个 Source 组
a1.sources = r1 r2# 定义多个 Source并 用不同的方案连接
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/app1.log
a1.sources.r1.channels = c1a1.sources.r2.type = netcat
a1.sources.r2.bind = 0.0.0.0
a1.sources.r2.port = 4444
a1.sources.r2.channels = c1
多Soure数据采集
# 定义多个 Source
agent.sources = source1 source2 source3# source1 - 从本地日志文件读取
agent.sources.source1.type = exec
agent.sources.source1.command = tail -F /var/log/syslog
agent.sources.source1.channels = memoryChannel# source2 - 从远程 TCP 端口接收日志数据
agent.sources.source2.type = netcat
agent.sources.source2.bind = 0.0.0.0
agent.sources.source2.port = 44444
agent.sources.source2.channels = memoryChannel# source3 - 从 Kafka 订阅数据
agent.sources.source3.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.source3.kafka.bootstrap.servers = kafka1:9092,kafka2:9092
agent.sources.source3.kafka.topics = log_topic
agent.sources.source3.channels = fileChannel
多Source源采集的案例实战
# 定义 Flume agent
a1.sources = r1 r2 r3
a1.channels = c1# 监听 Nginx 访问日志(Exec Source)
# 该 Source 通过 tail -F 持续监控 Nginx 访问日志的变化
# 适用于本地日志文件不断追加的场景,例如 Web 服务器日志
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/nginx/access.log
a1.sources.r1.channels = c1# 监听 文件夹
a1.sources.r1.type = spooldir
# 监控的目录路径(必填)
a1.sources.r1.spoolDir = /var/log/flume/spooldir
# 处理完成后文件后缀(可选,默认.completed)
a1.sources.r1.fileSuffix = .DONE# 监听 Kafka 主题(Kafka Source)
# 该 Source 从 Kafka 主题 "app_logs" 订阅日志数据
# 适用于分布式日志收集架构,与 Spark/Flink 流式计算结合
a1.sources.r3.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r3.kafka.bootstrap.servers = kafka01:9092,kafka02:9092
a1.sources.r3.kafka.topics = app_logs
a1.sources.r3.channels = c1# 定义 Channel(Memory Channel)
# 该 Channel 作为数据缓冲区,存储采集到的日志数据
# 内存 Channel 适用于对实时性要求高的场景
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
这个案例展示了几个常见的source连接器的配置,如果你有不同的数据源你就可以借鉴这个配置。
拦截器机制 interceptors
拦截器(Interceptor) 是位于 Source 和 Channel 之间的插件式组件,用于在事件(Event)进入 Channel 之前,对其进行修改、过滤或增强。每个拦截器仅处理其所属 Source 接收到的事件,且可以根据需要自定义拦截器的功能。
Flume 允许为一个 Source 配置多个拦截器,这些拦截器按照配置顺序依次对事件进行处理,形成拦截器链。
常见用途:拦截器对 Source 接收到的事件进行处理,包括修改事件内容、添加或修改事件头信息,甚至根据特定条件过滤掉某些事件。
内置拦截器类型
-
时间戳拦截器(Timestamp Interceptor): 将当前时间戳插入到事件的头信息中,方便后续基于时间的处理。
-
主机拦截器(Host Interceptor): 在事件头中添加主机名或 IP 地址,帮助识别事件来源。
-
静态拦截器(Static Interceptor): 向事件头中插入预定义的键值对,用于标识事件类别或其他静态信息。
-
正则过滤拦截器(Regex Filtering Interceptor): 使用正则表达式匹配事件内容,过滤掉不符合条件的事件。
通常情况下内置的拦截器不符合我们的使用需求,我们可以自定义拦截器或者不做处理把这个处理交给ods之后的层。
自定义拦截器
开发者可以根据特定需求,实现自定义拦截器,以满足复杂的事件处理逻辑。自定义拦截器需要实现 org.apache.flume.interceptor.Interceptor 接口,并在 Flume 配置中进行相应的配置。
Channel机制和溢写
在 Flume 的数据流动过程中,Channel(通道) 充当了 Source(数据源) 和 Sink(数据目标) 之间的 缓冲区,起到了数据存储和传输调度的作用。Flume 提供了多种 Channel 机制,同时还具备 溢写(Overflow) 机制,以防止数据丢失。
Channel的和核心机制
Channel 主要负责两项关键任务:①数据缓冲:Source 采集的数据会先存入 Channel,Sink 再从 Channel 读取数据并写入最终存储系统。②事务机制:Flume 采用事务模型,确保数据传输的可靠性,防止数据丢失或重复消费。
Source 采集到数据时,会开启一个put 事务,将数据存入 Channel。如果数据写入成功,事务提交(commit);否则回滚(rollback)。
Sink 从 Channel 读取数据时,会开启一个 take 事务。只有当数据成功发送到目标存储(HDFS/Kafka等),事务才会提交(commit);否则回滚(rollback)。
[Source] ---> [PUT事务] ---> [Channel] ---> [TAKE事务] ---> [Sink]
这种 双端事务机制 确保数据不会因网络异常或节点故障而丢失或重复消费。
Channel的类型
Flume 提供了多种 Channel,每种适用于不同场景:
| Channel 类型 | 适用场景 | 特点 | 事务支持 |
|---|---|---|---|
| Memory | 低延迟、高吞吐的数据采集 | 速度快、存储在内存中,但断电丢失数据 | ✅ 支持 |
| File | 需要持久化的日志存储 | 速度较慢,但数据不会因 Flume 进程重启而丢失 | ✅ 支持 |
| Kafka | 分布式日志收集,适用于大规模数据传输 | 直接将数据发送到 Kafka,解耦数据流 | ✅ 支持 |
| JDBC | 需要存入数据库(如 MySQL)作为缓冲 | 依赖数据库,适用于事务性数据 | ✅ 支持 |
溢写机制
当 Channel 达到容量上限,Flume 可能无法再接收新的数据。为避免数据丢失,Flume 提供了 溢写(Overflow) 机制,允许数据溢写到 备用存储(如磁盘),或采取流量调节措施。
Flume Channel 在管理数据缓冲时,通常遵循以下 几个核心规则 来控制数据的存储、刷新和溢写:
| 规则 | 作用 | 适用于 |
|---|---|---|
| 容量限制(capacity) | Channel 最多存储的数据条数,达到上限后会触发溢写或阻塞 Source | Memory Channel、File Channel |
| 事务批次(transactionCapacity) | 每个事务批量处理的事件数,影响吞吐量 | 所有 Channel |
| 溢写块(checkpoint 机制) | 在 File Channel 中,数据会以批量(chunk)方式存储,避免逐条写入影响性能 | File Channel |
| 超时阈值(rollInterval) | 如果数据在 Channel 中存在超过设定时间(单位:秒),会强制刷入 Sink | HDFS Sink、Kafka Sink |
Flume 在 File Channel 里会把数据按块(Chunk)存储,每个 Chunk 代表 一批事务提交的数据,防止数据逐条写入导致性能下降。例如:
a1.channels.c1.type = file
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 1000
a1.channels.c1.checkpointDir = /var/log/flume-checkpoint
a1.channels.c1.dataDirs = /var/log/flume-data# capacity=100000:最多存储 10 万条数据,达到后触发溢写
# transactionCapacity=1000:每次最多取 1000 条数据到 Sink
# checkpointDir:保存 Chunk 索引,防止崩溃后数据丢失
Sink机制
Sink(数据目标) 是 Flume 负责将数据从 Channel 取出,并写入最终存储系统的组件。Flume 提供了多种 Sink 类型,可用于写入 HDFS、Kafka、Elasticsearch、JDBC、HBase 等存储系统。
Sink中的机制有三个:① 事务机制,用Take保证数据的一致和安全。 ② batchSize(批量大小) 控制 Sink 每次从 Channel 读取的事件数量。根据不同的延迟场景使用。 ③ 如果一个 Sink 失败,Flume 提供 Sink Processor 机制 进行故障转移或负载均衡。
批量(Batch):Sink 不会逐条写入数据,而是批量处理,以减少 I/O 操作,提高吞吐量,批量大小(batchSize) 决定了每次 Sink 从 Channel 取出多少数据进行提交。
Sink的类型
Flume 提供了多种 Sink,以下是几种常见的 Sink 及其用途:
| Sink 类型 | 作用 | 主要参数 | 示例 |
|---|---|---|---|
| HDFS Sink | 写入 HDFS | hdfs.path,hdfs.fileType | /logs/%Y-%m-%d/ |
| Kafka Sink | 写入 Kafka 主题 | kafka.bootstrap.servers,topic | logs_topic |
| Elasticsearch Sink | 写入 ES | hostNames,indexName | logs_index |
| HBase Sink | 写入 HBase | table,columnFamily | table=access_logs |
| JDBC Sink | 写入数据库 | driver,url | INSERT INTO logs (...) |
常见的sink的配置案例
HDFS Sink用于将日志数据存储到 HDFS,支持 时间分区、压缩、文件滚动 等功能。
a1.sinks = k1
a1.sinks.k1.type = hdfs# HDFS 目标路径
a1.sinks.k1.hdfs.path = hdfs://hdf-yjx/logs/dt=%{dt}/
# 文件格式(DataStream / CompressedStream / SequenceFile)
a1.sinks.k1.hdfs.fileType = DataStream
# 多少秒滚动生成新文件
a1.sinks.k1.hdfs.rollInterval = 60
# 多少条数据滚动生成新文件
a1.sinks.k1.hdfs.rollCount = 10000
# 绑定 Channel
a1.sinks.k1.channel = c1# hdfs.path:日志存储路径,支持日期变量 %Y-%m-%d 进行分区存储。
# rollInterval:每 60 秒 生成一个新文件。
# rollCount:每 10000 条日志 生成一个新文件。
Kafka Sink用于将日志数据直接写入 Kafka 主题,适合 流式计算 场景(如 Flink、Spark Streaming)。
a1.sinks = k1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink# Kafka 服务器地址
a1.sinks.k1.kafka.bootstrap.servers = kafka01:9092,kafka02:9092
# 目标 Kafka 主题
a1.sinks.k1.kafka.topic = logs_topic
# 批量大小
a1.sinks.k1.batchSize = 1000
# Kafka 生产者确认机制
a1.sinks.k1.kafka.producer.acks = all
# 绑定 Channel
a1.sinks.k1.channel = c1# kafka.bootstrap.servers:Kafka Broker 地址。
# topic:目标 Kafka 主题。
# batchSize:每次写入 1000 条数据,提高吞吐量。
# acks:all 表示数据必须被所有 Kafka 副本确认,提高可靠性。
Sink负载均衡
在 Flume 中,Sink 负载均衡 允许一个 Channel 同时连接多个 Sink,并通过不同策略将数据 分配到多个存储目标(如多个 HDFS 目录、多个 Kafka 主题、多个数据库实例等)。
Flume 提供了 LoadBalancingSinkProcessor,用于在多个 Sink 之间分配数据。它支持三种策略:
轮询策略(Round Robin):Sink 之间 依次轮流 处理数据,负载均匀,适用于 多个 Sink 性能一致 的情况。配置:selector = round_robin
随机策略(Random):随机选择 一个 Sink 进行数据写入。适用于 不关心数据分布 的情况。配置:selector = random
回退策略(Backoff): 当某个 Sink 失败时,减少向其发送数据,优先使用其他可用的 Sink。配置:backoff = true
# 定义多个 Sink
a1.sinks = s1 s2
a1.sinkgroups = g1# 负载均衡 Sink 组
a1.sinkgroups.g1.sinks = s1 s2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.selector = round_robin
a1.sinkgroups.g1.processor.backoff = true# Sink 1 - HDFS
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path = hdfs://namenode:9000/logs1/# Sink 2 - Kafka
a1.sinks.s2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.s2.kafka.bootstrap.servers = kafka01:9092
a1.sinks.s2.kafka.topic = logs_topic# 绑定 Channel
a1.sinks.s1.channel = c1
a1.sinks.s2.channel = c1# processor.type = load_balance:启用负载均衡策略。
# round_robin:轮流使用多个 Sink
# backoff = true:失败时减少流量,避免影响正常 Sink
Sink批的计算管理参数有哪些
Sink 不会逐条写入数据,而是批量处理,以减少 I/O 操作,提高吞吐量。
批量大小(batchSize) 决定了每次 Sink 从 Channel 取出多少数据进行提交。
| 参数 | 作用 | 适用 Sink |
|---|---|---|
batchSize | 每次从 Channel 读取的事件数 | 所有 Sink |
transactionCapacity | Channel 每次最多提交多少事件 | 所有 Channel |
rollInterval | 在 HDFS 中,强制多久创建一个新文件(秒) | HDFS Sink |
rollSize | 在 HDFS 中,文件大小超过该值时创建新文件(字节) | HDFS Sink |
rollCount | 在 HDFS 中,写入多少条日志后创建新文件 | HDFS Sink |
常见 Sink 配置参数
| 参数 | 作用 | 适用 Sink | 示例 |
|---|---|---|---|
type | Sink 类型 | 所有 Sink | hdfs、kafka、es |
channel | 绑定的 Channel | 所有 Sink | channel = c1 |
batchSize | 每次处理的事件数 | 所有 Sink | batchSize = 500 |
transactionCapacity | Channel 提交批次大小 | 所有 Sink | transactionCapacity = 1000 |
rollInterval | HDFS Sink 超过多少秒滚动新文件 | HDFS Sink | rollInterval = 60 |
rollSize | HDFS 文件超过多少字节滚动新文件 | HDFS Sink | rollSize = 10485760 |
rollCount | HDFS 多少条日志后滚动新文件 | HDFS Sink | rollCount = 10000 |
kafka.bootstrap.servers | Kafka 服务器地址 | Kafka Sink | kafka.bootstrap.servers = kafka01:9092 |
kafka.topic | Kafka 目标主题 | Kafka Sink | topic = logs_topic |
kafka.producer.acks | Kafka 生产者确认模式 | Kafka Sink | acks = all |
hostNames | Elasticsearch 服务器 | Elasticsearch Sink | hostNames = es01:9200,es02:9200 |
indexName | ES 索引名称 | Elasticsearch Sink | indexName = logs_index |
table | HBase 表名称 | HBase Sink | table = access_logs |
columnFamily | HBase 列族 | HBase Sink | columnFamily = cf1 |
分布式采集数据
我们可以在多台机器上安装和配置 Flume,以实现分布式日志数据采集。Flume 作为一个分布式、可靠且高可用的系统,支持在多个节点上部署 Agent,以满足大规模日志收集的需求。
注意分布式 Flume 采集并不是多个 Flume Agent 共同采集同一个地方的数据,而是将数据采集任务分配给不同的 Flume Agent,各自采集不同的数据源,最后汇聚到一个 Sink 或 Channel 进行统一处理。
首先我们需要在在每台机器上安装 Flume;
配置每个 Flume Agent:在每个 Agent 的配置文件中,指定数据源(Source)、传输通道(Channel)和数据目的地(Sink)。
最后使用 Flume 提供的脚本依次启动 Agent,指定相应的配置文件。
例如第一台机器上:
# 定义 Source、Channel 和 Sink
a1.sources = r1
a1.channels = c1
a1.sinks = s1# 配置 Source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /path/to/logs
a1.sources.r1.channels = c1# 配置 Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 配置 Sink
a1.sinks.s1.type = avro
a1.sinks.s1.channel = c1
a1.sinks.s1.hostname = machine2
a1.sinks.s1.port = 4141
第二个机器上
# 定义 Source、Channel 和 Sink
a1.sources = r1
a1.channels = c1
a1.sinks = s1# 配置 Source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /path/to/logs
a1.sources.r1.channels = c1# 配置 Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 配置 Sink
a1.sinks.s1.type = avro
a1.sinks.s1.channel = c1
a1.sinks.s1.hostname = machine2
a1.sinks.s1.port = 4141
这样的配置相当于我们把数据放在了一个机器上的avro了,借助avro我们还可以把集中的数据再写一个conf把最后的结果聚合成为一个数据,这样就相当于这些不同机器上的数据完成了共享channel。
将任务均分出来更适合大量数据的采集,效率更高效。适用于大型企业级日志数据收集
故障转移和故障转移组
为什么需要故障转移?在生产环境中,数据流可能会因为 网络异常、存储系统宕机、目标服务不可用 等原因导致 Sink 端写入失败。如果没有故障转移机制,Flume 可能会:
-
数据丢失(Memory Channel 的数据丢失)
-
数据堆积(File Channel 长时间无法清空)
-
影响实时性(数据长时间无法入库)
为了解决这个问题,Flume 提供 故障转移(Failover)机制,可以在 主 Sink 失败时,自动切换到备用 Sink,保证数据的持续传输。
定义多个 Sink,按优先级顺序排列。如果主 Sink(Primary)出现问题,Flume 自动切换到备用 Sink(Backup)。支持回退(Backoff),降低失败 Sink 的使用频率,优先使用健康的 Sink。
关键参数解析
| 参数 | 作用 |
|---|---|
processor.type = failover | 启用 故障转移机制 |
processor.priority.s1 = 10 | 设置 例如HDFS Sink (s1) 优先级最高 |
processor.priority.s2 = 5 | 设置 例如Kafka Sink (s2) 作为备用 Sink |
processor.maxpenalty = 30000 | 30 秒后 重新尝试失败的 Sink |
例如下面的案例:
# 定义 Flume Agent
a1.sources = r1
a1.channels = c1
a1.sinks = s1 s2
a1.sinkgroups = g1# 定义 Source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/nginx/access.log
a1.sources.r1.channels = c1# 定义 Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000# 定义 Sink 组
a1.sinkgroups.g1.sinks = s1 s2
a1.sinkgroups.g1.processor.type = failover
# HDFS 作为主 Sink,优先级最高
a1.sinkgroups.g1.processor.priority.s1 = 10
# Kafka 作为备选 Sink,优先级较低
a1.sinkgroups.g1.processor.priority.s2 = 5
# 30 秒后重试失败的 Sink
a1.sinkgroups.g1.processor.maxpenalty = 30000# Sink 1:HDFS(主 Sink)
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path = hdfs://namenode:9000/logs/%Y-%m-%d/
a1.sinks.s1.hdfs.fileType = DataStream
a1.sinks.s1.hdfs.rollInterval = 60
a1.sinks.s1.hdfs.rollSize = 10485760
a1.sinks.s1.channel = c1# Sink 2:Kafka(备用 Sink)
a1.sinks.s2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.s2.kafka.bootstrap.servers = kafka01:9092,kafka02:9092
a1.sinks.s2.kafka.topic = backup_logs
a1.sinks.s2.batchSize = 1000
a1.sinks.s2.channel = c1
正常情况下,所有数据写入 HDFS (s1)。如果 HDFS (s1) 挂了(如 Namenode 故障、磁盘满),Flume 自动切换到 Kafka (s2),并继续传输数据。Flume 每 30 秒重新尝试恢复 HDFS (s1),如果恢复成功,自动切回主 Sink。如果 Kafka (s2) 也失败,则数据暂存于 Channel,直到恢复。
如何编写一个完美的conf文件
要编写一个高效且可靠的 Flume 配置文件,建议遵循以下步骤和最佳实践:
1. 明确数据流需求:
-
确定数据源(Source): 例如,日志文件、系统命令输出、网络端口等。
-
选择合适的通道(Channel): 根据数据可靠性和性能需求,选择内存通道(Memory Channel)或文件通道(File Channel)。
-
确定数据目的地(Sink): 如 HDFS、Kafka、HBase 等。
2. 组件命名:
- 为每个 Agent 的 Source、Channel 和 Sink 赋予有意义的名称,便于管理和维护。
3. 配置文件结构:
-
定义组件: 列出 Agent 下的所有 Source、Channel 和 Sink。
-
配置组件属性: 为每个组件设置必要的属性,如类型、连接信息等。
-
建立组件关系: 指定 Source 与 Channel,Channel 与 Sink 之间的连接关系。
对于复杂的配置的编写:
模块化配置: 将复杂的配置拆分为多个部分,分别定义不同的 Agent,每个 Agent 负责特定的任务。
配置多路复用(Multiplexing): 根据事件的特定属性,将数据路由到不同的 Channel 或 Sink。
在部署前,使用小规模数据对配置进行测试,确保其符合预期。检查日志输出,确保没有错误或警告信息最为可靠。
-
案例练习改版
自定义拦截器
虽然内置拦截器能够覆盖大部分场景,但在某些特殊情况下,你可能需要根据业务逻辑进行更精细的处理。这时,就需要编写自定义拦截器。
自定义拦截器允许开发者实现自己的数据处理逻辑,其主要步骤如下(下面案例针对没有dt根据采集时间 -1 天反推):
- 创建一个Maven项目,Java版本选择JDK1.8。

- 配置 pom.xml 依赖 需要添加 flume-ng-core 和 flume-ng-api。案例如下:
<dependencies><!-- Flume API --><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-sdk</artifactId><version>1.11.0</version></dependency><!-- 如果需要 flume-ng-core 中的类 --><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.11.0</version></dependency><!-- 日志依赖 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.25</version></dependency></dependencies>
- 创建拦截器类 在项目中创建包(例如:
com.yjxxt.flume.interceptor),在该包下创建类DtInterceptor.java。此类要实现接口org.apache.flume.interceptor.Interceptor或者也可以继承AbstractInterceptor以简化代码。
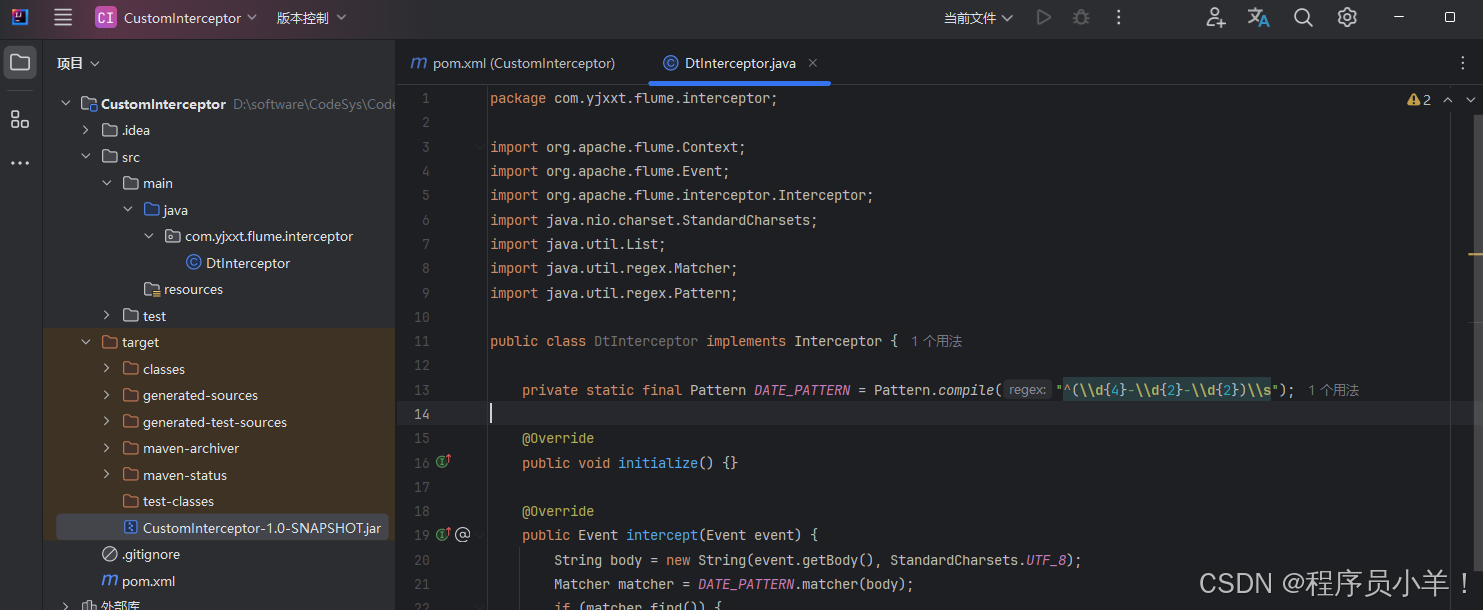
- 重写实现此类抽象的四个方法
initialize():初始化方法。
intercept(Event event):处理单个事件,返回修改后的事件或 null(过滤掉该事件)。
intercept(List<Event> events):批量处理事件,可逐个调用单个事件处理方法。
close():关闭拦截器时释放资源。
示例处理数据如下:
你需要把这个数据保存在 /root/script/ 下 名为 opt.log
示例处理数据:
Properties files
2024-03-01 12:00:01 INFO User login success user_id=123
2024-03-01 12:05:10 ERROR Database connection failed db_id=456
2024-03-01 12:10:45 WARN Disk space running low server_id=789
2024-03-02 14:30:33 INFO User logout user_id=123
2024-03-02 15:00:12 ERROR Payment transaction failed order_id=1001
package com.yjxxt.flume.interceptor;import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class DtInterceptor implements Interceptor {// 配置正则表达式规则private static final Pattern DATE_PATTERN = Pattern.compile("^(\\d{4}-\\d{2}-\\d{2})\\s");@Override//初始化方法。 不需要实现public void initialize() { }@Overridepublic Event intercept(Event event) {// 将event的body转换为UTF-8编码的字符串String body = new String(event.getBody(), StandardCharsets.UTF_8);// 使用DATE_PATTERN正则表达式匹配bodyMatcher matcher = DATE_PATTERN.matcher(body);// 如果匹配成功if (matcher.find()) {// 将匹配到的日期放入event的headers中event.getHeaders().put("dt", matcher.group(1));} else {// 如果匹配失败,将默认日期放入event的headers中event.getHeaders().put("dt", "default");}// 返回eventreturn event;}@Override// 重写intercept方法,参数为Event类型的Listpublic List<Event> intercept(List<Event> events) {// 遍历events中的每一个Eventfor (Event event : events) {// 调用intercept方法,参数为Eventintercept(event);}// 返回eventsreturn events;}@Overridepublic void close() { }public static class Builder implements Interceptor.Builder {@Overridepublic Interceptor build() {return new DtInterceptor();}@Overridepublic void configure(Context context) {}}
}
首先配置了一个静态正则表达式DATE_PATTERN,用来匹配数据中的时间规则(YYYY-MM-DD);
-
使用 Maven 命令将项目打包为 jar 文件
mvn clean package打包后的 jar 文件通常位于target/目录下,例如Custom-interceptor-1.0-SNAPSHOT.jar。 -
将打包好的 jar 文件复制到 Flume 安装目录的 lib 目录下,如果是 Flume 集群环境,确保所有 Flume Agent 节点的
$FLUME_HOME/lib/都包含此 jar 文件。 -
在 Flume 的配置文件中,指定拦截器类型为自定义拦截器的全限定类名,例如:
# Interceptor:自定义日期拦截器 (从日志提取日期存入header的dt)
a1.sources.r1.interceptors = dt
a1.sources.r1.interceptors.dt.type = com.yjxxt.flume.interceptor.DtInterceptor$Builder
CustomInterceptor-1.0-SNAPSHOT.jar
2.数据采集和准备 运行
首先我们先生成数据,我们创建一个名为 411log2hdfs.conf 的文件,采用自定义拦截器并且是动态引入的方式进行dt自动分区的处理。
下面用到的自定义拦截器来自于上面 自定义拦截器的案例 3.4.3
a1.sources = r1
a1.channels = c1
a1.sinks = hdfsSink# Source:监控日志文件夹
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = fg1
a1.sources.r1.filegroups.fg1 = /root/script/.*\.log
a1.sources.r1.positionFile = /var/flume/position.json
a1.sources.r1.channels = c1# Interceptor:自定义日期拦截器 (从日志提取日期存入header的dt)
a1.sources.r1.interceptors = dt
a1.sources.r1.interceptors.dt.type = com.yjxxt.flume.interceptor.DtInterceptor$Builder# Channel:文件型 Channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /var/flume/checkpoint
a1.channels.c1.dataDirs = /var/flume/data
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 10000# Sink:HDFS Sink(动态分区)
a1.sinks.hdfsSink.type = hdfs
a1.sinks.hdfsSink.channel = c1# HDFS动态分区存储路径(按日志日期动态分区)
a1.sinks.hdfsSink.hdfs.path = hdfs://hdfs-yjx/yjx/logs/dt=%{dt}
a1.sinks.hdfsSink.hdfs.filePrefix = logdata-
a1.sinks.hdfsSink.hdfs.fileSuffix = .log# 滚动策略(推荐)
a1.sinks.hdfsSink.hdfs.rollInterval = 600
a1.sinks.hdfsSink.hdfs.rollSize = 134217728
a1.sinks.hdfsSink.hdfs.rollCount = 10000
a1.sinks.hdfsSink.hdfs.fileType = DataStream# Hive可直接识别的文件名规则(可选)
a1.sinks.hdfsSink.hdfs.useLocalTimeStamp = false
将上述配置文件内容保存为 411log2hdfs.conf 文件,并上传到 $FLUME_HOME/job/ 目录下;在 Flume 安装目录下,使用以下命令启动 Agent(假设 Agent 名称为 a1,配置文件目录为 conf,配置文件位于 job 文件夹下):
bin/flume-ng agent -n a1 -c conf/ -f job/411log2hdfs.conf -Dflume.root.logger=INFO,console
当 Flume Agent 正常运行后,系统会采集 /var/log/myapp/ 下的日志文件,并经过拦截器提取出日志开头的日期(dt 字段)。HDFS Sink 将数据写入到 HDFS 路径中,其中路径中包含动态分区字段 %{dt}。例如,如果日志中提取到的日期为 2025-03-03、2025-03-04、2025-03-05,那么数据会写入到以下目录中:
hdfs://hdfs-yjx/yjx/logs/dt=2025-03-03/part-000……
hdfs://hdfs-yjx/yjx/logs/dt=2025-03-04/part-000……
hdfs://hdfs-yjx/yjx/logs/dt=2025-03-05/part-000……
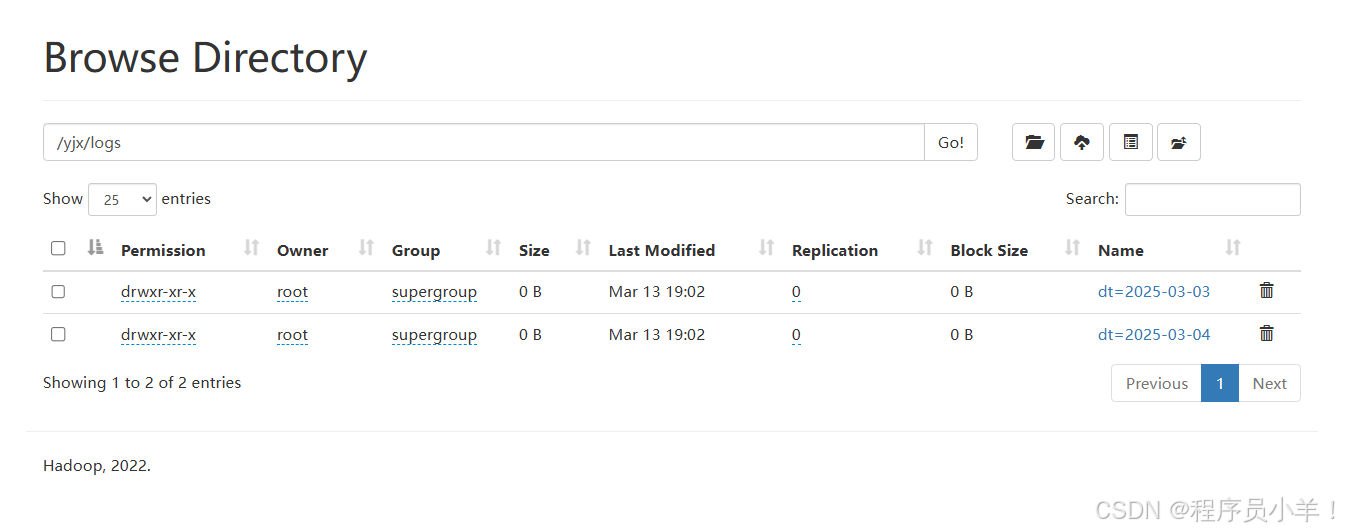
案例练习
Flume 采集 Linux 文件日志 /opt/test.log 并存储到 HDFS,Hive 读取。本案例实现以下目标:①Flume 采集 /opt/test.log 日志数据 ②将数据写入 HDFS,按照 dt=YYYY-MM-DD 进行分区 ③Hive 外部表读取 HDFS 数据,按照 dt 分区建表
① 首先,我们需要一个模拟的日志文件,在 /opt/ 目录下创建 test.log。此日志包含 时间戳、日志级别、描述信息,模拟真实业务日志。
# 复制下面的代码直接粘贴在node01即可mkdir -p /opt/
cat <<EOF > /opt/test.log
2024-03-01 12:00:01 INFO User login success user_id=123
2024-03-01 12:05:10 ERROR Database connection failed db_id=456
2024-03-01 12:10:45 WARN Disk space running low server_id=789
2024-03-02 14:30:33 INFO User logout user_id=123
2024-03-02 15:00:12 ERROR Payment transaction failed order_id=1001
EOF
②Flume 配置文件 flume-hdfs.conf。写完之后上传到conf文件夹中
# 定义 Source
a1.sources = r1
a1.channels = c1
a1.sinks = s1# Source:监听 /opt/test.log
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/test.log
a1.sources.r1.channels = c1# 添加拦截器:
a1.sources.r1.interceptors = i1 i2# 时间戳拦截器(可选,防止部分日志没有时间信息)
a1.sources.r1.interceptors.i1.type = timestamp# 正则提取拦截器:从日志提取 YYYY-MM-DD 作为 `dt`
a1.sources.r1.interceptors.i2.type = regex_extractor
a1.sources.r1.interceptors.i2.regex = "(\\d{4}-\\d{2}-\\d{2}) .*"
a1.sources.r1.interceptors.i2.serializers = s1
a1.sources.r1.interceptors.i2.serializers.s1.type = org.apache.flume.interceptor.RegexExtractorInterceptorPassThroughSerializer
# 这里的 `dt` 就是 header 里的键
a1.sources.r1.interceptors.i2.serializers.s1.name = dt# Channel:使用内存通道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100# Sink:HDFS 按 `dt` 进行分区存储
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path = hdfs://192.168.100.101:8020/user/hive/warehouse/logs/dt=%{dt}/
a1.sinks.s1.hdfs.fileType = DataStream
a1.sinks.s1.hdfs.writeFormat = Text
a1.sinks.s1.hdfs.rollInterval = 30
a1.sinks.s1.hdfs.rollSize = 1342177
a1.sinks.s1.hdfs.rollCount = 100
a1.sinks.s1.channel = c1
上面Flume 配置中,使用了 regex_extractor 拦截器 来提取日志中的 YYYY-MM-DD 日期,并将其作为 dt 变量,存入 HDFS 的分区目录。
首先连接器规则:正则提取拦截器(regex_extractor)从日志内容中提取 YYYY-MM-DD 格式的日期,存入 Flume 事件头部(Event Header)。Flume 后续可以引用 headers.dt 变量,将数据写入 dt=YYYY-MM-DD/ 目录。
a1.sources.r1.interceptors = i1 i2将拦截器组配置到sources。a1.sources.r1.interceptors.i2.serializers = s1 定义序列化器给那个sink的 headers,serializers.s1.name = dt:存储的键名为 dt
# 最终 Flume 事件数据
{"headers": {"dt": "2024-03-01"},"body": "2024-03-01 12:00:01 INFO User login success user_id=123"
}
a1.sinks.s1.hdfs.path = hdfs://namenode:8020/user/hive/warehouse/logs/dt=%{dt}/
这个路径是 Flume 将日志存入 HDFS 的目标目录%{dt} 是 headers.dt 的值,这里会被替换成日志的 YYYY-MM-DD。
其余配置:
| 配置项 | 作用 |
|---|---|
regex_extractor | 从日志内容提取 YYYY-MM-DD |
headers.dt | 将提取的日期存入 Event Header |
hdfs.path = hdfs://namenode:8020/user/hive/warehouse/logs/dt=%{dt}/ | 按 dt=YYYY-MM-DD 自动分区 |
hdfs.rollInterval = 60 | 每 60 秒滚动新文件 |
hdfs.rollSize = 128MB | 单文件最大 128MB |
hdfs.rollCount = 10000 | 每 10000 行创建新文件 |
hdfs.rollInterval = 60 | 以 文本格式 写入 HDFS |
③运行前应该保证你的目录上有 /user/hive/warehouse/logs/ 目录如果没有可能会出现报错
hdfs dfs -mkdir -p hdfs://192.168.100.101:8020/user/hive/warehouse/logs/
hdfs dfs -chmod -R 777 hdfs://192.168.100.101:8020/user/hive/warehouse/logs/
启动flume bin/flume-ng agent -n a1 -c conf -f conf/flume-hdfs.conf;如果 Flume 运行正常,HDFS 目录 结构应该如下:
/user/hive/warehouse/logs/dt=2024-03-01/part-00000
/user/hive/warehouse/logs/dt=2024-03-02/part-00000
...
④ 在 Hive 中创建外部表 由于数据是按 dt=YYYY-MM-DD 存储的,需要手动添加 Hive 分区
CREATE EXTERNAL TABLE IF NOT EXISTS logs (log_time STRING,log_level STRING,message STRING
)
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
STORED AS TEXTFILE
LOCATION 'hdfs://namenode:8020/user/hive/warehouse/logs/';-- log_time STRING:日志时间戳
-- log_level STRING:日志级别(INFO/ERROR/WARN)
-- message STRING:日志内容
-- dt STRING:动态分区(dt=YYYY-MM-DD)
-- LOCATION 指向 HDFS 目录,与 Flume hdfs.path 一致。-- 手动加载分区 这样 Hive 就能自动发现 dt=2024-03-01、dt=2024-03-02 等分区。
MSCK REPAIR TABLE logs;
现在你查询数据就会发现,数据可以查到并且按照dt的动态规则自动分类。
结尾:
本课程是一门以电商流量数据分析为核心的大数据实战课程,旨在帮助你全面掌握大数据技术栈的核心组件及其在实际项目中的应用。从零开始,你将深入了解并实践Hadoop、Hive、Spark和Flume等主流技术,为企业级电商流量项目构建一个高可用、稳定高效的数据处理系统。
在课程中,你将学习如何搭建并优化Hadoop高可用环境,熟悉HDFS分布式存储和YARN资源调度机制,为大规模数据存储与计算奠定坚实基础。随后,通过Hive数据仓库的构建与数仓建模,你将掌握如何将原始日志数据进行分层处理,实现数据清洗与结构化存储,从而为后续数据分析做好准备。
借助Spark SQL的强大功能,你将通过实战案例学会快速计算和分析关键指标,如页面浏览量(PV)、独立访客数(UV),以及通过数据比较获得的环比、等比等衍生指标。这些指标将帮助企业准确洞察用户行为和流量趋势,为优化营销策略提供科学依据。
同时,本课程还包含Flume数据采集与ETL入仓的实战模块,教你如何采集实时Web日志数据,并利用ETL流程将数据自动导入HDFS和Hive,确保数据传输和处理的高效稳定。
总体来说,这门课程面向希望提升大数据应用能力的技术人员和企业项目团队,紧密围绕公司电商流量项目的实际需求展开。通过系统的理论讲解与动手实践,你不仅能够构建从数据采集、存储、处理到可视化展示的完整数据管道,还能利用PV、UV、环比、等比等关键指标,全面掌握电商流量数据分析的核心技能。
今天这篇文章就到这里了,大厦之成,非一木之材也;大海之阔,非一流之归也。感谢大家观看本文
