分布式专题——10.5 ShardingSphere的CosID主键生成框架
1 解决分布式主键生成导致的数据分片不均问题
-
来看一个案例;
-
将
course表数据分到两个库(m0、m1),每个库两张表(course_1、course_2),共四个分片;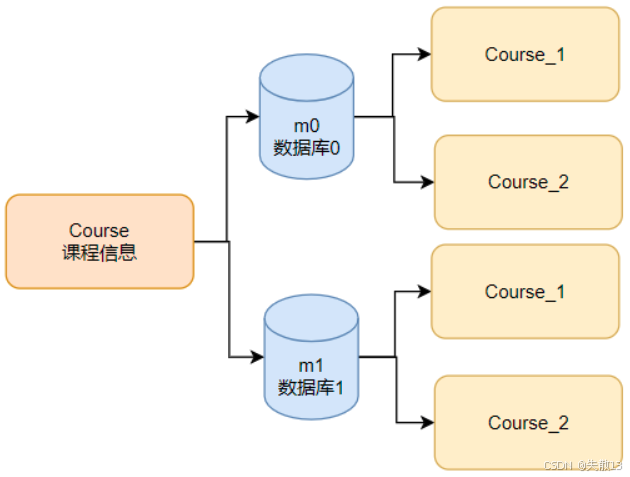
-
库分片:按
id奇偶,database = id % 2; -
表分片:如果简单按
id奇偶,table = (id % 2) + 1,这样只能分到m0.course_1和m1.course_2两张表,无法利用四个分片; -
改进表分片算法:
table = ((id + 1) % 4) / 2 + 1,理论上能均匀分到四个分片。代码验证如下: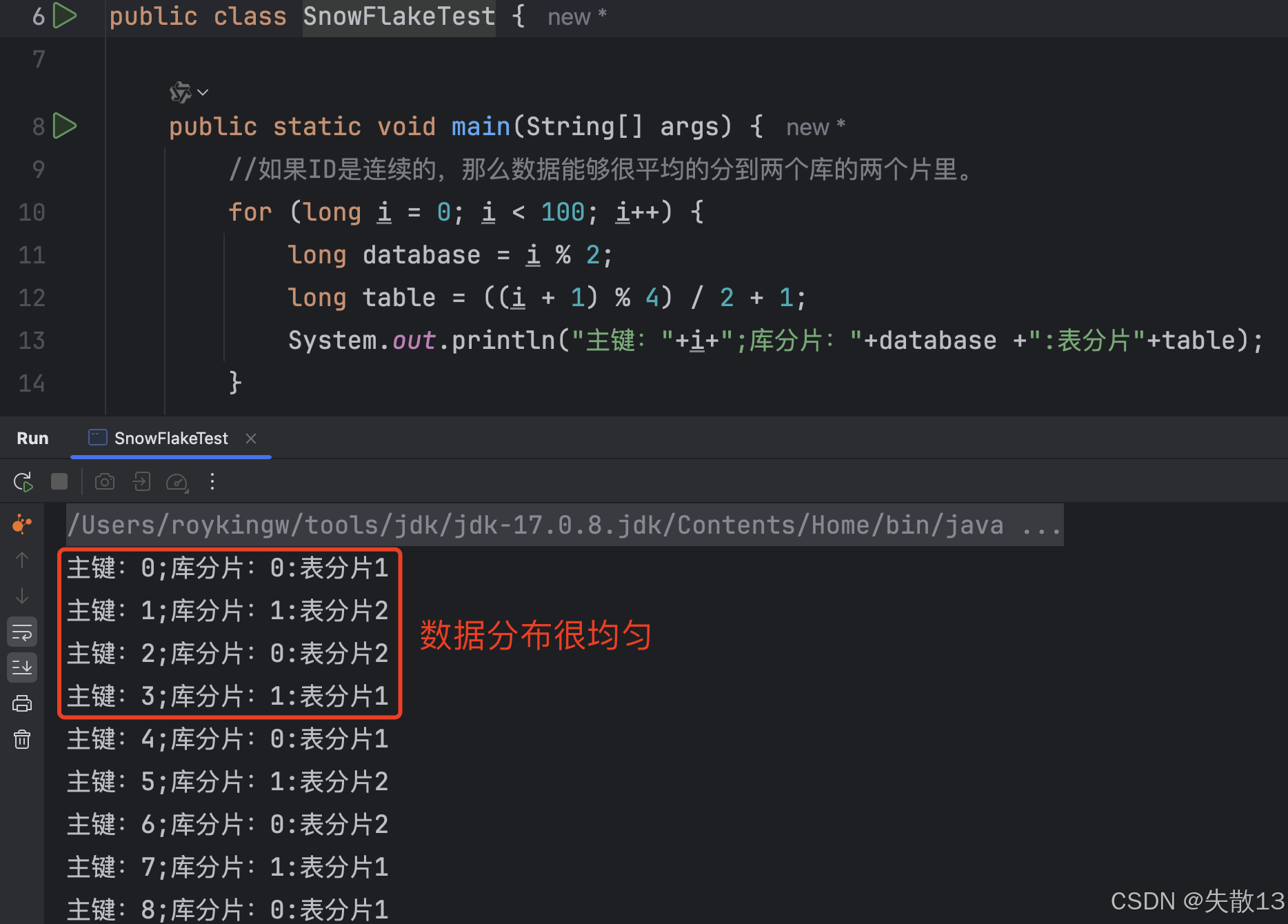
-
-
代码验证完成,接下来配置到 ShadingSphere 中使用一下。下面是示例配置:
# 启用SQL显示功能,在控制台输出实际执行的SQL语句,便于调试 spring.shardingsphere.props.sql-show = true # 允许Bean定义覆盖,避免与Spring Boot默认配置冲突 spring.main.allow-bean-definition-overriding = true# ---------------- 数据源配置 ---------------- # 定义数据源名称列表,多个数据源用逗号分隔 spring.shardingsphere.datasource.names=m0,m1# 配置第一个数据源m0 spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource # 使用Druid连接池 spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver # MySQL JDBC驱动 spring.shardingsphere.datasource.m0.url=jdbc:mysql://192.168.65.212:3306/shardingdb1?serverTimezone=UTC # 数据库连接URL spring.shardingsphere.datasource.m0.username=root # 数据库用户名 spring.shardingsphere.datasource.m0.password=root # 数据库密码# 配置第二个数据源m1 spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.m1.url=jdbc:mysql://192.168.65.212:3306/shardingdb2?serverTimezone=UTC spring.shardingsphere.datasource.m1.username=root spring.shardingsphere.datasource.m1.password=root# ----------------- 分布式序列算法配置 ----------------- # 配置雪花算法作为分布式主键生成器,用于生成Long类型的全局唯一ID spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE #spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=COSID_SNOWFLAKE # 设置雪花算法的worker-id,用于在分布式环境中区分不同的工作节点 spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.worker-id=1# 指定course表使用分布式主键生成策略 # 主键列名 spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.column=cid # 使用的生成器名称 spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.key-generator-name=alg_snowflake# ----------------- 配置实际数据节点 ----------------- # 定义course表的实际数据节点分布模式:2个数据库(m0,m1) × 2个表(course_1,course_2) spring.shardingsphere.rules.sharding.tables.course.actual-data-nodes=m$->{0..1}.course_$->{1..2}# ----------------- 数据库分片策略 ----------------- # 配置数据库分片策略:使用标准分片策略,按cid字段进行分库 # 分片字段 spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-column=cid # 分片算法名称 spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-algorithm-name=course_db_alg# 配置数据库分片算法:使用取模(MOD)算法,分成2个库 # 取模分片算法 spring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.type=MOD # 分片数量 spring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.props.sharding-count=2# ----------------- 表分片策略 ----------------- # 配置表分片策略:使用标准分片策略,按cid字段进行分表 # 分片字段 spring.shardingsphere.rules.sharding.tables.course.table-strategy.standard.sharding-column=cid # 分片算法名称 spring.shardingsphere.rules.sharding.tables.course.table-strategy.standard.sharding-algorithm-name=course_tbl_alg # 配置表分片算法:使用行表达式(INLINE)算法 spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=INLINE # 行表达式分片算法# 复杂的表分片算法表达式:将数据均匀分布到4个分片中 # 计算过程:((cid + 1) % 4).intdiv(2) + 1 # 1. cid + 1:对主键值加1(避免0值问题) # 2. % 4:取模4,得到0-3的值 # 3. .intdiv(2):整数除以2,将4个值映射为0或1 # 4. + 1:最终得到1或2,对应course_1或course_2表 # 这种算法可以解决雪花算法非严格递增导致的分布不均问题 spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{((cid+1)%4).intdiv(2)+1} -
测试插入:通过下面代码循环插入 10 条
course数据,发现库分片均匀,但表分片只能插入到m0.course_1和m1.course_2两张表,无法利用四个分片:@Test public void addcourse() {for (int i = 0; i < 10; i++) {Course c = new Course();// Course表的主键字段cid交由雪花算法生成。c.setCname("java");c.setUserId(1001L);c.setCstatus("1");courseMapper.insert(c);System.out.println(c);} } -
解决方案:将分布式主键生成算法类型从
SNOWFLAKE改为COSIID_SNOWFLAKE,即修改配置:#spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=COSID_SNOWFLAKE -
原理:在分库分表场景下,分布式主键的生成方式会影响数据分片的均匀性。
COSID_SNOWFLAKE能更好地适配分片算法,使得id生成更有利于按照分库分表规则均匀分布到四个分片表中,从而解决了之前表分片不均的问题; -
再次尝试后,
course表数据能均匀分配到四张表中。
2 雪花算法详解
2.1 简介
-
雪花算法是 Twitter 公司开源的 ID 生成算法;
- 它不需要依赖外部组件,算法简单,效率也高,是实际企业开发过程中,用得最为广泛的一种分布式主键生成策略;
- 采用一个 8 字节(因为 8 字节正好对应
Long类型变量)的二进制序列来生成一个主键。这样既保持足够的区分度,又能比较自然地与业务结合;
-
雪花算法生成的
Long型 ID 由以下几部分组成: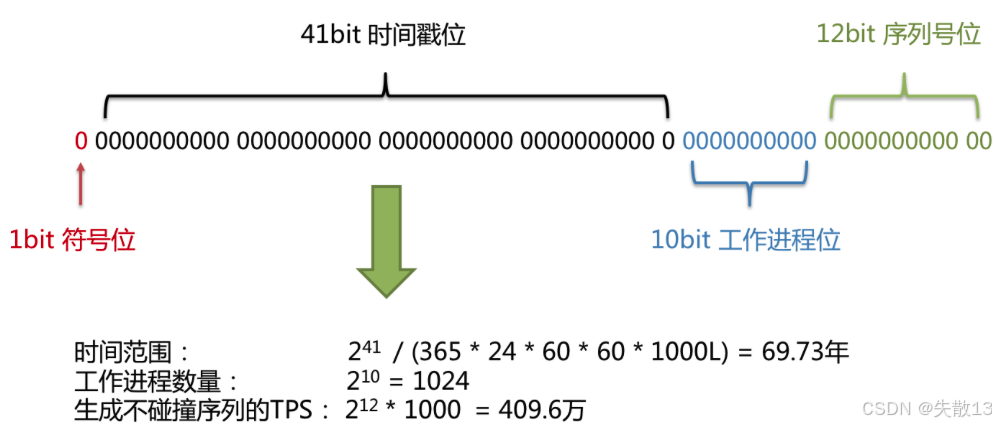
-
1bit 符号位:用于区分正负,一般为 0,表示生成的是正数 ID;
-
41bit 时间戳位:以毫秒为单位的时间戳,可计算出其能表示的时间范围为 (2^{41} / (365 * 24 * 60 * 60 * 1000L) \approx 69.73) 年,能满足较长时间的 ID 生成需求;
-
10bit 工作进程位:用于标识每一台机器(在实现时,这部分留给应用自行扩展,比如可拆分为数据中心标识和工作节点标识等),可支持的工作进程数量为 (2^{10} = 1024) 个;
-
12bit 序列号位:在同一毫秒内、同一工作进程下,用于区分不同的 ID,生成不碰撞序列的 TPS(Transactions Per Second,每秒事务数)可达 (2^{12} * 1000 = 409.6) 万,能应对高并发场景下的 ID 生成;
-
-
雪花算法的核心逻辑:将各部分唯一值拼接成一个整体唯一值;
- 从整体来说,时间戳是保证趋势递增的数字,所以放在最高位;
- 若有多个节点同时生成 ID,可能产生相同时间戳,此时拼接工作进程 ID 来区分;
- 若同一进程中有多个线程同时生成,还会产生相同 ID,就再加上严格递增的序列号,从而整体保证了全局 ID 的唯一性;
-
雪花算法的衍生:在标准雪花算法基础上,诞生了很多类似的实现。无非是对时间戳位、工作进程位等部分根据业务场景进行重组,比如缩短时间戳位,将工作进程位加长并拆分为数据中心和工作节点两个部分等,但核心逻辑万变不离其宗。
2.2 COSID_SNOWFLAKE如何解决取模分片数据不均匀的问题
-
回到前面说的取模分片数据不均匀的问题:
- 首先要知道一个数学规律:对于任何一个数字,其对 2 取模的结果,实际上就是取这个数字的二进制表达式的最后一位。对 4 取模的结果,就是取这个数字的二进制表达式的最后两位。依次类推;
- 回到问题上,要让数据均匀分到四个分片上,实际上是需要保证生成的一系列雪花算法ID,他们的二进制表达式的最后两位是连续递增的;
- 所以,接下来要做的,就是对比
SNOWFLAKE算法和COSID_SNOWFLAKE算法,他们生成的序列的最后一位有什么区别;
-
SNOWFLAKE对应的算法实现类是SnowflakeKeyGenerateAlgorithm:@Override public synchronized Long generateKey() {// 获取当前时间戳(毫秒)long currentMilliseconds = timeService.getCurrentMillis();// 如果需要,等待容忍时间差(处理时钟回拨问题)if (waitTolerateTimeDifferenceIfNeed(currentMilliseconds)) {// 重新获取当前时间戳currentMilliseconds = timeService.getCurrentMillis();}// 判断当前时间戳是否与上一次生成ID的时间戳相同if (lastMilliseconds == currentMilliseconds) {// 同一毫秒内生成多个ID:序列号加1// 使用位掩码确保序列号在指定范围内循环if (0L == (sequence = (sequence + 1) & SEQUENCE_MASK)) {// 如果序列号溢出(达到最大值),等待到下一毫秒currentMilliseconds = waitUntilNextTime(currentMilliseconds);}} else {// 时间戳更新(进入新的毫秒):重置序列号// 使用振动序列偏移避免序列号总是从0开始vibrateSequenceOffset();sequence = sequenceOffset;}// 更新最后使用的时间戳lastMilliseconds = currentMilliseconds;// 组合生成最终的64位ID:// 1. (currentMilliseconds - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS: 时间戳部分(高位)// 2. getWorkerId() << WORKER_ID_LEFT_SHIFT_BITS: 工作节点ID部分(中位)// 3. sequence: 序列号部分(低位)return ((currentMilliseconds - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS) | (getWorkerId() << WORKER_ID_LEFT_SHIFT_BITS) | sequence; }-
上面代码中,
sequence(序列号)在同一毫秒内若未冲突会自增,若毫秒数变化,sequence会重置。但在实际项目中,生成 ID 后还有写入数据库等操作,时间会往后推,导致对 4 取模时,结果常为 0 或 2,对应分片只能用到部分,无法均匀分布到 4 个分片。 -
临时解决方案:
-
查看
vibrateSequenceOffset()方法,默认情况下,它会让sequence在 0 和 1 之间震荡; -
可以在
props中添加一个配置参数max-vibration-offset=12,让sequence在 0 到 10 之间震荡,这在一定程度上解决数据不均,如下:spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.worker-id=1 spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.max-vibration-offset=12 -
但该配置缺乏官方资料说明,不够通用;
-
-
-
再来看
COSID_SNOWFLAKE算法生成雪花ID的过程:// me.ahoo.cosid.snowflake.AbstractSnowflakeId类中 @Override public synchronized long generate() {// 获取当前时间戳long currentTimestamp = getCurrentTime();// 检查时钟回拨:如果当前时间小于上次生成ID的时间,抛出异常if (currentTimestamp < lastTimestamp) {throw new ClockBackwardsException(lastTimestamp, currentTimestamp);}// ================ 基于序列重置阈值重置序列,优化分片不均匀问题 ================// 如果进入新的时间戳且序列号达到重置阈值,重置序列号为0// 这个优化可以避免序列号总是从0开始,改善数据分片均匀性if (currentTimestamp > lastTimestamp&& sequence >= sequenceResetThreshold) {sequence = 0L;}// 序列号递增,并使用位掩码确保不超出最大序列号范围// maxSequence通常是2的n次方减1(如4095),位操作相当于取模运算但效率更高sequence = (sequence + 1) & maxSequence;// 如果序列号溢出(归零),说明当前毫秒内的ID已用完,等待下一毫秒if (sequence == 0L) {currentTimestamp = nextTime();}// ================ 结束序列重置逻辑 ================// 更新最后时间戳记录lastTimestamp = currentTimestamp;// 计算相对于纪元时间的时间差long diffTimestamp = (currentTimestamp - epoch);// 检查时间戳溢出:如果时间差超过最大允许值,抛出异常if (diffTimestamp > maxTimestamp) {throw new TimestampOverflowException(epoch, diffTimestamp, maxTimestamp);}// 组合生成最终的64位ID:// 1. 时间戳部分左移到高位// 2. 机器ID左移到中间位// 3. 序列号放在低位return diffTimestamp << timestampLeft| machineId << machineLeft| sequence; }- 在上面代码中,当时间戳更新且序列号达到重置阈值时,
sequence重置为 0;序列号在达到maxSequence前直接递增。这样使得雪花 ID 的二进制最后几位(用于取模的部分)严格递增,保证了数据能均匀分布到各个分片; - 相比
SNOWFLAKE,COSID_SNOWFLAKE的序列号生成更简单直接,能让用于分片取模的二进制位分布更均匀,从而解决数据分片不均问题;
- 在上面代码中,当时间戳更新且序列号达到重置阈值时,
-
再来看雪花算法工作进程位的问题:
-
工作进程位的作用:雪花算法的工作进程位用于区分不同的工作进程(如分布式服务中的不同服务实例),确保不同实例生成的 ID 不冲突;
-
实际困难:
- 配置缺失:在
ShardingSphere等框架中,SNOWFLAKE的worker-id参数虽可配置,但官方文档缺乏说明,多数开发者不会专门为其单独设置; - 大规模服务难度大:对于大型分布式服务系统(几十个服务),手动保证每个服务的
worker-id不重复几乎不可能,容易引发 ID 冲突问题,而这一隐患此前常被忽略。
- 配置缺失:在
-
3 深入源码全面理解CosID框架
3.1 搭建CosID测试应用
-
虽然 CosID 已集成进 ShardingSphere,但 ShardingSphere 只集成了 CosID 的部分功能,因为 CosID 很多核心功能依赖外部存储系统,这增加了 ShardingSphere 集成的复杂性。所以通过单独搭建 CosID 测试应用,来深入理解 CosID;
-
在
10.2 ShardingSphere-JDBC分库分表实战与讲解的示例项目中增加CosIDDemo模块,在其pom.xml中配置依赖:- 注意 CosID 组件版本,不同版本有细微差异;
<properties><cosid.version>2.9.1</cosid.version> </properties><dependencies><dependency><groupId>me.ahoo.cosid</groupId><artifactId>cosid-spring-boot-starter</artifactId><version>${cosid.version}</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version><scope>test</scope></dependency> </dependencies> -
编写启动类
DistIdApp:@SpringBootApplication public class DistIDApp {public static void main(String[] args) {SpringApplication.run(DistIDApp.class, args);} } -
application.properties配置文件:# 设置 CosID 的命名空间 cosid.namespace=cosid-example # 启用 CosID cosid.enabled=true # 启用机器(工作进程)相关配置 cosid.machine.enabled=true # 指定机器 ID 分发方式为手动(manual),机器 ID 设为 1(对应雪花算法的工作进程位) cosid.machine.distributor.manual.machine-id=1 # 启用雪花算法生成 ID cosid.snowflake.enabled=true -
应用中生成主键:
@SpringBootTest @RunWith(SpringRunner.class) public class DistIDTest {@Resourceprivate IdGeneratorProvider provider;@Testpublic void getId(){// 循环 100 次生成并打印 IDfor (int i = 0; i < 100; i++) {System.out.println(provider.getShare().generate());}} } -
ShardingSphere 集成 CosID 也是通过封装
IdGeneratorProvider来获取主键;旧版本 CosID(如 1.14.1)在 ShardingSphere 集成时有小 Bug,需要在 Spring Boot 启动类添加:
@EnableConfigurationProperties({MachineProperties.class}) @ComponentScans(value = {@ComponentScan("me.ahoo.cosid")})而最新的 2.9.1 版本不需要;
-
CosID 框架主要集成了三种主键生成模式:
- SnowFlake(雪花算法);
- SegmentID(号段模式)和SegmentChainID(号段链模式):这两种思路一致,都属于号段模式,只是实现思路不同,主要用于生成严格递增的主键序列。不同的生成模式在应用层面统一由
IdGeneratorProvider提供服务,应用代码无需调整,只需修改相关配置,就能生成不同类型的分布式主键。
3.2 SnowFlake雪花算法
3.2.1 基本使用
-
3.1 搭建CosID测试应用中搭建的简单示例是雪花算法的使用示例:- 其中
machineID是雪花算法的工作进程位,但采用手动配置(manual方式),这种方式在大型项目中存在水土不服的问题; - 因为主键生成框架要生成唯一主键,却需先手动生成可能不唯一的
machineID,类似“鸡生蛋,蛋生鸡”的循环问题,所以需要自动生成machineID的方法;
- 其中
-
CosID 提供了多种
MachineID的实现形式,可查看其源码中的枚举类型Type,包含:// me.ahoo.cosid.spring.boot.starter.machine.MachineProperties public enum Type {MANUAL, // 手动分配STATEFUL_SET, // 与 Kubernetes(k8s)结合的状态机机制JDBC, // 基于 JDBC 方式MONGO, // 基于 MongoDB 方式REDIS, // 基于 Redis 方式ZOOKEEPER, // 基于 ZooKeeper 方式PROXY // 类似 ShardingSphere-Proxy,搭建第三方 CosID 服务分配 } -
使用 JDBC 方式配置
MachineID-
添加
cosid-jdbc扩展依赖包,并引入 JDBC 相关依赖:<dependency><groupId>me.ahoo.cosid</groupId><artifactId>cosid-jdbc</artifactId><version>${cosid.version}</version> </dependency> <dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.20</version><!-- 版本冲突 --><exclusions><exclusion><artifactId>spring-boot-autoconfigure</artifactId><groupId>org.springframework.boot</groupId></exclusion></exclusions> </dependency> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId><version>${spring.boot.version}</version> </dependency> <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.20</version> </dependency> -
在配置文件中进行如下配置:
# 设置 MachineID 分发类型为 JDBC cosid.machine.distributor.type=jdbc spring.datasource.type=com.alibaba.druid.pool.DruidDataSource spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://192.168.65.212:3306/test?serverTimezone=UTC spring.datasource.username=root spring.datasource.password=root -
接下来,需要创建对应的数据库,并且还需要在数据库中手动创建一张表。建表语句为:
create table if not exists cosid_machine (name varchar(100) not null comment '{namespace}.{machine_id}',namespace varchar(100) not null,machine_id integer unsigned not null default 0,last_timestamp bigint unsigned not null default 0,instance_id varchar(100) not null default '',distribute_time bigint unsigned not null default 0,revert_time bigint unsigned not null default 0,constraint cosid_machine_pkprimary key (name) ) engine = InnoDB;create index idx_namespace on cosid_machine (namespace); create index idx_instance_id on cosid_machine (instance_id); -
完成这些后,若依赖版本无冲突,就可运行单元测试案例获取分布式 ID 了。
-
3.2.2 重点机制剖析
-
下面聚焦于 CosID 中雪花算法的核心机制,尤其是
MachineID(机器 ID)的生成与相关组件的构建; -
编写单元测试:
public class SnowFlakeTest {@Resourceprivate MachineId machineId; // 提供机器位@Resourceprivate SnowflakeId snowflakeId; // 生成雪花 ID// 循环生成 100 个雪花 ID 并打印@Testpublic void snowflakeTest(){System.out.println("machineId:"+machineId.getMachineId());for (int i = 0; i < 100; i++) {System.out.println("snowflakeId: "+snowflakeId.generate());}} }- CosID 是通过注入
MachineId实例提供机器位,再由SnowflakeId实例引用生成雪花算法 ID,最终SnowflakeId也会被IdGeneratorProvider引用;
- CosID 是通过注入
-
源码剖析,雪花算法的 SnowFlakeId 示例的注入方式是这样的:
// me.ahoo.cosid.spring.boot.starter.snowflake.SnowflakeIdBeanRegistrar // 雪花算法ID生成器Bean注册器/*** 整体注册逻辑*/ public void register() {// 首先检查是否有自定义配置,若有则将其应用到 snowflakeIdProperties(雪花算法属性)上,实现属性的自定义调整if (customizeSnowflakeIdProperties != null) {customizeSnowflakeIdProperties.customize(snowflakeIdProperties);}// 获取共享的SnowflakeId配置定义SnowflakeIdProperties.ShardIdDefinition shareIdDefinition = snowflakeIdProperties.getShare();// 如果共享配置启用if (shareIdDefinition.isEnabled()) {// 调用 registerIdDefinition 方法将其注册到 IdGeneratorProvider(ID 生成器提供者)的共享部分registerIdDefinition(IdGeneratorProvider.SHARE, shareIdDefinition);}// 遍历 snowflakeIdProperties 中配置的所有提供者,为每个提供者调用 registerIdDefinition 方法,注册对应的 ID 生成器snowflakeIdProperties.getProvider().forEach(this::registerIdDefinition); }/*** 注册单个ID定义到指定的名称*/ private void registerIdDefinition(String name, SnowflakeIdProperties.IdDefinition idDefinition) {// 调用 createIdGen 方法// 根据传入的 IdDefinition(ID 定义)和 ClockBackwardsSynchronizer(时钟回拨同步器)创建 SnowflakeId 实例SnowflakeId idGenerator = createIdGen(idDefinition, clockBackwardsSynchronizer);// 调用 registerSnowflakeId 方法// 将创建好的 SnowflakeId 实例注册到 IdGeneratorProvider 中,同时在 Spring 应用上下文中注册为单例 Bean,方便后续获取使用registerSnowflakeId(name, idGenerator); }/*** 注册SnowflakeId到Spring容器和ID生成器提供者*/ private void registerSnowflakeId(String name, SnowflakeId snowflakeId) {// 先检查 IdGeneratorProvider 中指定名称的生成器是否存在if (idGeneratorProvider.get(name).isEmpty()) {// 若不存在则将 SnowflakeId 实例设置到该提供者中idGeneratorProvider.set(name, snowflakeId);}// 生成对应的 Bean 名称String beanName = name + "SnowflakeId";// 然后通过 Spring 应用上下文的 Bean 工厂,将 SnowflakeId 实例注册为单例 Bean,使得 Spring 容器能够管理该实例applicationContext.getBeanFactory().registerSingleton(beanName, snowflakeId); }/*** 构建SnowflakeId实例的核心方法*/ private SnowflakeId createIdGen(SnowflakeIdProperties.IdDefinition idDefinition,ClockBackwardsSynchronizer clockBackwardsSynchronizer) {// 获取纪元时间(雪花算法 ID 生成的起始时间点)long epoch = getEpoch(idDefinition);// 获取机器位数量,优先使用ID定义中的配置,否则使用机器属性中的默认值int machineBit = MoreObjects.firstNonNull(idDefinition.getMachineBit(), machineProperties.getMachineBit());// 获取命名空间,用于机器ID分配时的隔离String namespace = Namespaces.firstNotBlank(idDefinition.getNamespace(), cosIdProperties.getNamespace());// 通过 machineIdDistributor(机器 ID 分发器)根据命名空间、机器位数、实例 ID 和安全保护期限,分配唯一的机器 IDint machineId = machineIdDistributor.distribute(namespace, machineBit, instanceId, machineProperties.getSafeGuardDuration()).getMachineId();// 根据配置的时间单位创建不同的雪花算法实例SnowflakeId snowflakeId;if (SnowflakeIdProperties.IdDefinition.TimestampUnit.SECOND.equals(idDefinition.getTimestampUnit())) {// 创建秒级精度的雪花算法实例snowflakeId = new SecondSnowflakeId(epoch, idDefinition.getTimestampBit(), machineBit, idDefinition.getSequenceBit(), machineId, idDefinition.getSequenceResetThreshold());} else {// 创建毫秒级精度的雪花算法实例(默认)snowflakeId =new MillisecondSnowflakeId(epoch, idDefinition.getTimestampBit(), machineBit, idDefinition.getSequenceBit(), machineId, idDefinition.getSequenceResetThreshold());}// 若配置了时钟同步,就将 SnowflakeId 实例包装为 ClockSyncSnowflakeId,以处理时钟回拨问题if (idDefinition.isClockSync()) {snowflakeId = new ClockSyncSnowflakeId(snowflakeId, clockBackwardsSynchronizer);}// 获取ID转换器定义IdConverterDefinition converterDefinition = idDefinition.getConverter();// 获取时区配置final ZoneId zoneId = ZoneId.of(snowflakeIdProperties.getZoneId());// 使用装饰器模式添加ID转换功能,并返回经过装饰的 ID 生成器return new SnowflakeIdConverterDecorator(snowflakeId, converterDefinition, zoneId, idDefinition.isFriendly()).decorate(); }- 雪花算法依赖时间戳递增来保证 ID 递增性,但计算机时钟可能出现时间回拨问题(即下一刻产生的时间比上一刻的时间更早)。CosID 框架中,当要生成 ID 时,若发现当前时间比上一次生成 ID 的时间还早,会触发时钟回拨处理逻辑,通常是休眠一段时间,直到时间正常往后延续,才会重新生成 ID;
SecondSnowflakeId和MillisecondSnowflakeId因时间精度不同,在处理时钟回拨时的粒度和场景也会有所差异,秒级精度可能面对更长时间范围的时钟波动,毫秒级精度则更敏感于短时间内的时钟变化,但核心处理逻辑是一致的,都是为了保证 ID 生成的时序性和唯一性;
-
CosID 框架中,实际生成雪花算法的方法在
AbstractSnowflakeId的generate()方法中:- 作为雪花算法的抽象类,其
generate方法包含了雪花 ID 生成的核心逻辑:- 处理时钟回拨问题,若当前时间戳小于上次时间戳,抛出
ClockBackwardsException; - 重置序列号以优化分片不均问题,当时间戳更新且序列号达到重置阈值时,重置序列号;
- 组合并返回雪花 ID,雪花 ID 由时间戳、机器 ID、序列号等部分按位组合而成;
- 处理时钟回拨问题,若当前时间戳小于上次时间戳,抛出
//me.ahoo.cosid.snowflake.AbstractSnowflakeId @Override public synchronized long generate() {// 获取当前时间戳(通常以毫秒为单位)long currentTimestamp = getCurrentTime();// 检查时钟回拨:当前时间小于上次生成ID的时间戳,抛出异常if (currentTimestamp < lastTimestamp) {throw new ClockBackwardsException(lastTimestamp, currentTimestamp);}// 如果当前时间大于上次时间戳且序列号达到重置阈值,重置序列号。// 这有助于解决时间戳切换时序列号不均匀的问题(比如跨毫秒时重置序列号)if (currentTimestamp > lastTimestamp && sequence >= sequenceResetThreshold) {sequence = 0L;}// 序列号自增并与最大序列号掩码取模(防止溢出,循环回0)sequence = (sequence + 1) & maxSequence;// 如果序列号归零,表示当前毫秒内序列号已用完,等待下一毫秒if (sequence == 0L) {currentTimestamp = nextTime();}// 更新最后时间戳为当前使用的时间戳lastTimestamp = currentTimestamp;// 计算相对于初始时间(epoch)的偏移量long diffTimestamp = (currentTimestamp - epoch);// 检查时间戳溢出:如果偏移量超过最大允许值,抛出异常if (diffTimestamp > maxTimestamp) {throw new TimestampOverflowException(epoch, diffTimestamp, maxTimestamp);}// 组合生成最终的ID:// 1. 将时间戳偏移量左移到高位// 2. 将机器ID左移到中间位// 3. 最后拼接序列号到低位return diffTimestamp << timestampLeft| machineId << machineLeft| sequence; } - 作为雪花算法的抽象类,其
-
在上面代码中可以看到:最后组合雪花 ID 的时候,machineID 就是作为雪花算法的工作进程位被使用。而 machineID,又是通过注入到 Spring 容器中的 MachineID 对象获取的:
//me.ahoo.cosid.spring.boot.starter.machine.CosIdMachineAutoConfiguration @Bean @ConditionalOnMissingBean({MachineId.class}) // 仅当容器中不存在MachineId类型的bean时才创建 public MachineId machineId(MachineIdDistributor machineIdDistributor, InstanceId instanceId) {// 使用机器ID分发器分配机器ID:// 1. namespace: 命名空间,用于区分不同应用或环境// 2. machineBit: 机器ID的位数,决定机器ID的最大数量// 3. instanceId: 当前实例的唯一标识// 4. safeGuardDuration: 安全保护时长,用于处理机器ID的租约和回收int machineId = machineIdDistributor.distribute(this.cosIdProperties.getNamespace(), this.machineProperties.getMachineBit(), instanceId, this.machineProperties.getSafeGuardDuration()).getMachineId();// 创建并返回MachineId对象,包含分配到的机器IDreturn new MachineId(machineId); }- 所以,对于 MachineId 分配这个功能,在 CosId 框架中,都是通过
MachineIdDistributor接口的distribute()方法扩展出来的;
- 所以,对于 MachineId 分配这个功能,在 CosId 框架中,都是通过
-
如果要使用 JDBC 方式,
MachineIdDistributor接口的对象实例的注入方式如下代码所示,从而实现 MachineId 的分配;@AutoConfiguration // 标记为自动配置类,Spring Boot会自动处理 @ConditionalOnCosIdEnabled // 只有当CosId功能全局启用时才生效 @ConditionalOnCosIdMachineEnabled // 只有当CosId机器功能启用时才生效 @ConditionalOnClass({JdbcMachineIdDistributor.class}) // 只有当JdbcMachineIdDistributor类在classpath中存在时才生效 @ConditionalOnProperty( // 只有当配置文件中指定了特定的属性值时才生效value = {"cosid.machine.distributor.type"}, // 监听的配置属性havingValue = "jdbc" // 要求属性值为"jdbc" ) public class CosIdJdbcMachineIdDistributorAutoConfiguration {public CosIdJdbcMachineIdDistributorAutoConfiguration() {}@Bean@ConditionalOnMissingBean // 只有当容器中不存在JdbcMachineIdDistributor类型的bean时才创建public JdbcMachineIdDistributor jdbcMachineIdDistributor(DataSource dataSource, // 数据源,用于数据库连接MachineStateStorage localMachineState, // 本地机器状态存储ClockBackwardsSynchronizer clockBackwardsSynchronizer // 时钟回拨同步器) {// 创建基于JDBC的机器ID分发器实例return new JdbcMachineIdDistributor(dataSource, localMachineState, clockBackwardsSynchronizer);} } -
其他类型的机器ID生成器也都是类似的。例如,手动指定机器ID时,注入的
MachineIdDistributor接口实例是这样的:// me.ahoo.cosid.spring.boot.starter.machine.CosIdMachineAutoConfiguration @Bean @ConditionalOnMissingBean // 只有当容器中不存在ManualMachineIdDistributor类型的bean时才创建 @ConditionalOnProperty( // 条件属性配置:只有当满足特定属性条件时才创建该beanvalue = {"cosid.machine.distributor.type"}, // 监听的配置属性matchIfMissing = true, // 如果配置文件中缺少该属性,也视为匹配(默认行为)havingValue = "manual" // 要求属性值为"manual" ) public ManualMachineIdDistributor machineIdDistributor(MachineStateStorage localMachineState, // 本地机器状态存储组件ClockBackwardsSynchronizer clockBackwardsSynchronizer // 时钟回拨同步处理器 ) {// 从配置中获取手动分配相关的配置项MachineProperties.Manual manual = this.machineProperties.getDistributor().getManual();// 检查手动配置不能为空Preconditions.checkNotNull(manual, "cosid.machine.distributor.manual can not be null.");// 获取配置中指定的机器IDInteger machineId = manual.getMachineId();// 检查机器ID不能为空Preconditions.checkNotNull(machineId, "cosid.machine.distributor.manual.machineId can not be null.");// 检查机器ID必须大于等于0Preconditions.checkArgument(machineId >= 0, "cosid.machine.distributor.manual.machineId can not be less than 0.");// 创建手动机器ID分发器实例,使用配置的机器ID和依赖组件return new ManualMachineIdDistributor(machineId, localMachineState, clockBackwardsSynchronizer); } -
未来如果想要自己实现一个 MachineId 分配机制,其实也可以参照这种方式,往里面注入一个
MachineIdDistributor接口的实现类即可。
3.2.3 基于JDBC的工作进程ID分发机制实现分析
- 上层的这些接口其实还只是与 Spring 框架集成的一层入口。那么从
MachineIdDistributor接口往下的具体实现,才算是进入了 CosID 框架的核心。那么 CosID 是怎么实现机器位分配的呢? - CosID 定制了一套基础的机器位分发流程,与每种第三方服务结合时,都是按这一套相同的流程工作。 这个流程是什么样呢?下面从 JDBC 的实现机制开始讲解。
3.2.3.1 如何区分不同的工作进程?
- CosID 通过
InstanceId区分不同服务实例(工作进程),InstanceId的构成依赖两部分:-
命名空间:由配置参数
cosid.namespace指定,是 CosID 自定义的逻辑隔离标识; -
应用IP + 端口:IP 从应用直接读取,端口需通过参数配置(若应用未单独配置
instanceId,则默认用此方式);//me.ahoo.cosid.spring.boot.starter.machine.CosIdMachineAutoConfiguration @Bean @ConditionalOnMissingBean // 只有当容器中不存在InstanceId类型的bean时才创建 public InstanceId instanceId(HostAddressSupplier hostAddressSupplier) {// 获取是否启用稳定模式的配置(默认为true)boolean stable = Boolean.TRUE.equals(this.machineProperties.getStable());// 如果配置文件中明确指定了实例ID,则直接使用配置的实例IDif (!Strings.isNullOrEmpty(this.machineProperties.getInstanceId())) {return InstanceId.of(this.machineProperties.getInstanceId(), stable);} else {// 获取当前进程ID作为默认端口值int port = ProcessId.CURRENT.getProcessId();// 如果配置文件中指定了端口且端口大于0,则使用配置的端口if (Objects.nonNull(this.machineProperties.getPort()) && this.machineProperties.getPort() > 0) {port = this.machineProperties.getPort();}// 基于主机地址和端口创建实例IDreturn InstanceId.of(hostAddressSupplier.getHostAddress(), port, stable);} } -
上面代码中的还有
stable参数:用于标记服务是否“稳定”。若服务稳定(stable=true),其MachineId不会被回收;若不稳定,MachineId可被后续进程复用。
-
3.2.3.2 如何给不同工作进程分发不同的 MachineId?
先查本地缓存
-
分发时先查本地缓存(
localState):- 若缓存中有有效
MachineState(未过期、匹配命名空间等),直接返回缓存的MachineId,并更新缓存时间戳(保证有效性); - 若本地缓存无效,进入远程分发流程;
// me.ahoo.cosid.machine.AbstractMachineIdDistributor @Nonnull public MachineState distribute(String namespace, int machineBit, InstanceId instanceId, Duration safeGuardDuration) throws MachineIdOverflowException {// 参数校验:确保命名空间不为空,机器位数大于0,实例ID不为空Preconditions.checkArgument(!Strings.isNullOrEmpty(namespace), "namespace can not be empty!");Preconditions.checkArgument(machineBit > 0, "machineBit:[%s] must be greater than 0!", machineBit);Preconditions.checkNotNull(instanceId, "instanceId can not be null!");// 从本地存储中获取该命名空间和实例ID对应的机器状态MachineState localState = this.machineStateStorage.get(namespace, instanceId);// 如果本地存在有效的机器状态(不是NOT_FOUND)if (!MachineState.NOT_FOUND.equals(localState)) {// 进行时钟回拨同步,确保时间戳不会倒退this.clockBackwardsSynchronizer.syncUninterruptibly(localState.getLastTimeStamp());// 返回本地存储的机器状态(重用已有的机器ID)return localState;} else {// 本地没有找到机器状态,需要从远程分布式存储分配新的机器IDMachineState localState = this.distributeRemote(namespace, machineBit, instanceId, safeGuardDuration);// 检查分配到的机器状态的时间戳是否发生了时钟回拨if (ClockBackwardsSynchronizer.getBackwardsTimeStamp(localState.getLastTimeStamp()) > 0L) {// 如果检测到时钟回拨,进行同步等待直到时间恢复正常this.clockBackwardsSynchronizer.syncUninterruptibly(localState.getLastTimeStamp());// 使用当前时间更新机器状态的时间戳localState = MachineState.of(localState.getMachineId(), System.currentTimeMillis());}// 将分配到的机器状态保存到本地存储中this.machineStateStorage.set(namespace, localState.getMachineId(), instanceId);// 返回新分配的机器状态return localState;} }这个本地缓存就和前面的
stable参数(是否稳定)有关了;stable参数本质是在告诉 CosID:这个服务实例是否需要长期占用一个固定的MachineId- 当
stable=true(稳定服务):- CosID 会将
InstanceId与MachineId的映射关系,通过文件持久化存储(文件路径由cosid.machine.state-storage.local.state-location指定); - 即使应用停止、重启,甚至服务器断电,这个文件依然存在。重启时 CosID 会读取该文件,直接复用之前的
MachineId,避免重复分配; - 这就是 “稳定服务占用稳定
MachineId” 的原因 —— 文件记录了历史分配,保证唯一性和连续性;
- CosID 会将
- 当
stable=false(非稳定服务):- CosID 仅在内存中维护
MachineId的缓存,不写入文件; - 应用停止后,内存数据丢失,对应的
MachineId会被标记为“可回收”,后续新启动的进程可以复用这个MachineId; - 适合临时服务(如测试环境、短生命周期的任务),避免浪费
MachineId资源;
- CosID 仅在内存中维护
例:
-
假设服务 A 配置
stable=true,首次启动时分配到MachineId=5,并将InstanceId=xxx-ip:port与5的映射写入文件。即使服务 A 停机 1 小时,重启后 CosID 会读取文件,发现 “xxx-ip:port” 曾对应5,就直接复用5,不会重新申请新的MachineId; -
如果服务 B 配置
stable=false,分配到MachineId=6,但仅存在内存中。服务 B 停机后,内存中的记录消失,6会被释放。下次有新服务启动时,CosID 可能会把6分配给其他实例;
小结:
stable参数通过控制MachineId的存储介质(文件 / 内存),决定了其是否“可回收”:- 稳定服务(
stable=true)→ 文件存储 →MachineId长期占用,不回收; - 非稳定服务(
stable=false)→ 内存存储 →MachineId随应用销毁而释放,可复用。
- 若缓存中有有效
distributeRemote()方法
-
distributeRemote()方法就是交由各种具体实现类去扩展实现的抽象方法了,例如 JDBC 的分发方式是这样的:-
本地发(
distributeBySelf):尝试在本地(基于当前数据库连接)生成并保留MachineId。若成功,直接返回; -
回滚发(
distributeByRevert):若“本地发”失败,尝试回滚之前可能的残留分配,重新生成MachineId。若成功,返回; -
远程发(
distributeMachine):若前两步都失败,通过远程逻辑(跨进程/跨服务)强制分配MachineId;
//me.ahoo.cosid.jdbc.JdbcMachineIdDistributor @Override protected MachineState distributeRemote(String namespace, int machineBit, InstanceId instanceId, Duration safeGuardDuration) {// 记录分布式机器ID分配的日志信息if (log.isInfoEnabled()) {log.info("Distribute Remote instanceId:[{}] - machineBit:[{}] @ namespace:[{}].", instanceId, machineBit, namespace);}try (Connection connection = dataSource.getConnection()) {// 第一阶段:本地发放尝试 - 检查是否已经有本实例的分配记录MachineState machineState = distributeBySelf(namespace, instanceId, connection, safeGuardDuration);if (machineState != null) {return machineState; // 如果找到本实例的分配记录,直接返回}// 第二阶段:回滚发放尝试 - 检查是否有已过期的机器ID可以回收重用machineState = distributeByRevert(namespace, instanceId, connection, safeGuardDuration);if (machineState != null) {return machineState; // 如果回收到可用的机器ID,返回回收的ID}// 第三阶段:全新分配 - 前两种方式都失败时,分配一个新的机器IDreturn distributeMachine(namespace, machineBit, instanceId, connection);} catch (SQLException sqlException) {// 处理数据库异常,记录错误日志并抛出运行时异常if (log.isErrorEnabled()) {log.error(sqlException.getMessage(), sqlException);}throw new CosIdException(sqlException.getMessage(), sqlException);} } -
基本分发逻辑
-
虽然各种服务的具体实现各不相同,但是基本的分发逻辑都是这三个步骤:自己发布 >> 回滚发布 >> 远程发布;
-
自己发布(优先复用当前实例历史分配的
MachineId)-
执行 SQL:尝试获取**当前实例(
instance_id匹配)**过去分配过的MachineIdselect machine_id, last_timestamp from cosid_machine where namespace=? and instance_id=? and last_timestamp>?-
namespace=?:限定命名空间(逻辑隔离,不同命名空间MachineId独立); -
instance_id=?:匹配当前服务实例的唯一标识(如IP:端口); -
last_timestamp>?:通过时间戳做安全校验——仅获取在“安全时间”内分配的MachineId- 若服务是
stable=true(稳定服务):安全时间为0(即必须是最近分配的,保证强独占); - 若服务是
stable=false(非稳定服务):安全时间由cosid.machine.guard.safe-guard-duration配置(默认 5 分钟,超过则认为可回收);
- 若服务是
-
-
结果:
- 若查到记录:更新
last_timestamp(标记“最近使用”),并复用该MachineId; - 若未查到:进入回滚发布流程;
- 若查到记录:更新
-
-
回滚发布(尝试复用其他实例废弃/过期的
MachineId)-
执行 SQL:尝试获取无人认领或过期的
MachineId(即其他实例不再使用的MachineId)select machine_id, last_timestamp from cosid_machine where namespace=? and (instance_id='' or last_timestamp<?)-
namespace=?:同命名空间隔离; -
instance_id='':匹配无主的MachineId(可能是初始化时预留,或实例销毁后未被回收的); -
last_timestamp<?:匹配超过安全时间的MachineId(即使有instance_id,但长期未使用,视为可回收);
-
-
结果:
- 若查到记录:更新
instance_id(标记为当前实例占用)、last_timestamp(标记最近使用),并复用该MachineId; - 若未查到:进入远程发布流程;
- 若查到记录:更新
-
-
远程发布(分配全新的
MachineId)-
执行 SQL:当“自己发布”和“回滚发布”都失败时,分配一个全新的
MachineIdselect max(machine_id)+1 as next_machine_id from cosid_machine where namespace=?-
先查询当前命名空间下最大的
MachineId,然后+1得到新的MachineId; -
若表中无记录(首次分配),则
max(machine_id)为null,+1后得到1; -
分配新
MachineId后,会向cosid_machine表插入一条新记录(记录namespace、instance_id、last_timestamp等),供后续流程复用;
-
-
-
这三步是复用优先,新分配兜底的策略:
-
优先复用当前实例历史
MachineId(自己发布),保证本实例MachineId稳定; -
再复用其他实例废弃的
MachineId(回滚发布),减少新MachineId消耗; -
最后才分配新
MachineId(远程发布),确保极端情况下仍能获取 ID;
-
-
这种设计既提高了
MachineId复用率(减少数据库写入),又保证了分布式场景下MachineId的唯一性与可用性,且流程可移植到 MongoDB 等其他存储(只需替换 SQL 为对应查询语法)。
3.3 Segment号段模式
- 雪花算法生成的 ID 是趋势递增但不连续的,而 Segment 模式要生成连续增长的分布式主键 ID,同时通过预分配 ID 段减少与主键生成服务的交互频率。
3.3.1 Segment模式基础使用
-
修改配置启用 Segment 模式,以 JDBC 为例:
# 数据源配置 - 使用Druid连接池连接MySQL数据库 spring.datasource.type=com.alibaba.druid.pool.DruidDataSource spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://192.168.65.212:3306/test?serverTimezone=UTC spring.datasource.username=root spring.datasource.password=root# CosId全局配置 cosid.namespace=cosid-example # 命名空间,用于区分不同应用或环境 cosid.enabled=true # 启用CosId功能# 雪花算法配置 - 禁用雪花算法(不使用Snowflake ID生成方式) cosid.snowflake.enabled=false# 机器ID配置 - 启用机器ID管理(即使不用雪花算法也需要机器ID用于其他ID生成器) cosid.machine.enabled=true cosid.machine.distributor.type=jdbc # 使用JDBC方式分发机器ID(基于数据库)# Segment模式配置 - 启用Segment模式(号段模式)的ID生成 cosid.segment.enabled=true cosid.segment.mode=segment # 使用单Segment模式(非链式模式) cosid.segment.distributor.type=jdbc # 使用JDBC方式管理号段分配# JDBC表初始化配置 - 自动创建CosId所需的数据库表 cosid.segment.distributor.jdbc.enable-auto-init-cosid-table=true# 号段配置 # 安全距离配置(注释掉,使用默认值2)- 控制号段缓存的安全边界 #cosid.segment.chain.safe-distance=10# 步长配置 - 每个号段包含的ID数量(设置为100个ID) cosid.segment.share.step=100 -
改完配置之后,就可以运行单元测试案例获取分布式ID了:
@SpringBootTest @RunWith(SpringRunner.class) public class DistIDTest {@Resourceprivate IdGeneratorProvider provider; // 从Spring容器注入ID生成器提供者@Testpublic void getID() {for (int i = 0; i < 100; i++) {// 生成ID并打印,会得到1到100的连续ID// provider.getShare() 获取 Segment 模式的 ID 生成器,generate() 每次生成一个连续递增的 IDSystem.out.println(provider.getShare().generate());}} } -
执行代码后,CosID 会自动在 MySQL 中创建
cosid表,结构与数据含义如下: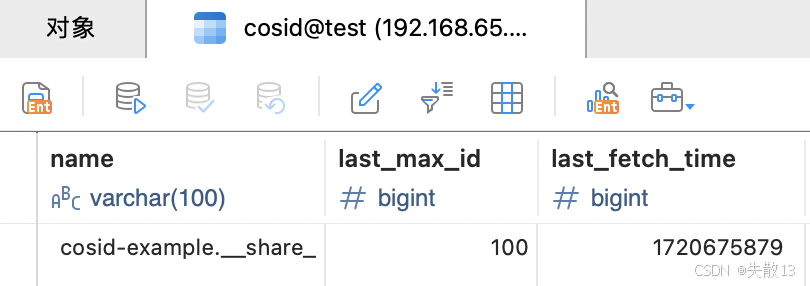
表字段 含义 示例数据解释 name命名空间(与配置的 cosid.namespace对应)示例中为 cosid-example.__share__,表示该命名空间下的共享 Segment 段last_max_id上一次分配后,该 Segment 段的最大 ID 示例中为 100,表示当前预分配的 ID 段是1~100last_fetch_time上一次获取 ID 段的时间戳 记录预分配的时间,用于后续判断 ID 段是否有效 -
核心逻辑:CosID 会**预分配一段连续的 ID(如示例中 1~100)**给应用。应用在这段 ID 用完前,无需再向 CosID 申请新段,直接从内存中分配,从而减少与数据库的交互次数,提升性能。
3.3.2 Segment模式的优化方案
-
Segment 模式的本质是预分配 ID 段 + 本地分发:
-
数据库表设计:用一张表(如下图中包含
biz_tag、max_id、step等字段)管理不同业务(biz_tag)的 ID 分配;
max_id:当前系统已分配的最大 ID;step:每个 Segment 段包含的 ID 数量;
-
分配流程:应用不是每次取 1 个 ID,而是一次性取一个“段”(连续的一批 ID)。例如:
- 订单服务首次申请时,
max_id从 0 增加到 2000(step=2000),则本次分配到0~2000的 ID 段; - 后续订单服务可在本地内存中从该段里分配 ID,无需每次请求数据库;
- 下一次申请时,
max_id再增加 2000,分配2001~4000的段,以此类推;
- 订单服务首次申请时,
-
-
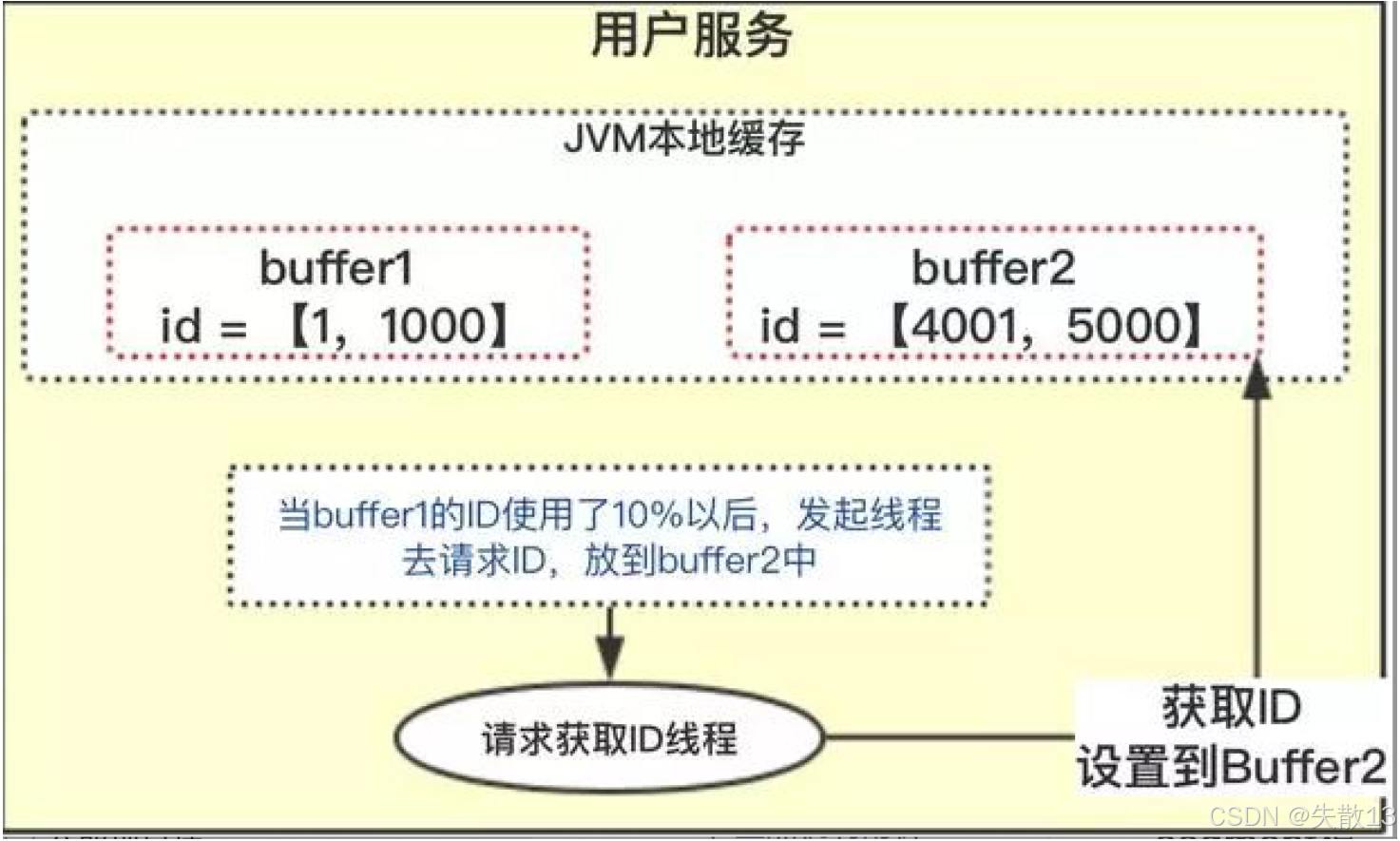
基础 Segment 模式有个缺陷:申请新 ID 段时需要网络请求,期间应用无法分配 ID(短暂不可用)。双 Buffer 优化通过双缓存交替解决这个问题:
-
缓存设计:应用同时维护两个 Buffer(如
Buffer1和Buffer2); -
预加载逻辑:
- 初始时,
Buffer1加载一段 ID(如1~1000),Buffer2加载下一段 ID(如4001~5000); - 当
Buffer1的 ID 用了 10% 左右时,异步发起请求,预加载新的 ID 段到Buffer2; - 等
Buffer1的 ID 用完,直接切换到Buffer2分配;同时,Buffer1再异步预加载新段,以此类推;
- 初始时,
-
效果:始终有一个 Buffer 存有可用 ID,保证应用在“申请新段”时也能持续分配 ID,避免服务中断;
- 这种方案被美团 Leaf、百度 Uid 等主流分布式 ID 框架采用;
-
-
双 Buffer 仍有局限,CosID 针对两个痛点做了优化:
-
痛点 1:强依赖数据库(DB)
- 基础方案中,ID 段的
max_id和step存在数据库,但数据库更适合存储核心业务数据,把“ID 生成”这种边缘服务强依赖 DB 不够灵活; - CosID 改进:支持多种存储介质(数据库、Redis、Zookeeper、MongoDB 等)。只需配置即可切换,不再绑定单一数据库,更灵活;
- 基础方案中,ID 段的
-
痛点 2:本地缓存容量有限(分配器挂了后支撑时间短)
- 双 Buffer 仅缓存 2 段 ID,若“ID 分配器(如存储介质)故障”,本地缓存很快会用完,应用仍会不可用;
- CosID 改进:将双 Buffer 升级为
SegmentChain(段链表)。用链表结构缓存多个 Segment 段(默认保留 10 个 Segment),且自动维护,保证链表中至少有 10 个段。效果:本地缓存的 ID 段更多,即使分配器故障,也能支撑更长时间,提升服务稳定性。
-
3.4 SegmentChain号段链模式
-
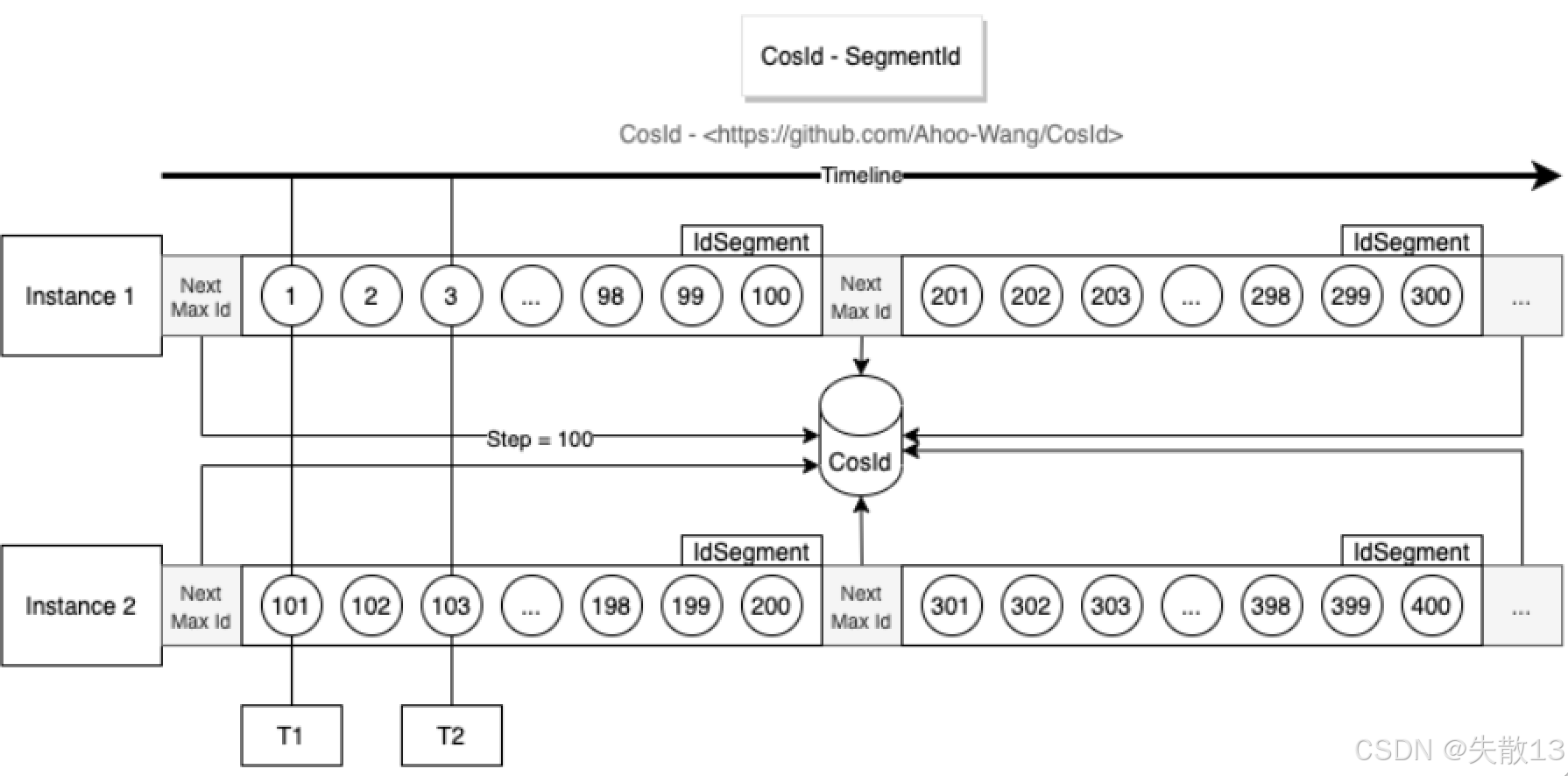
基础 Segment 模式是单段缓存 + 用完再申请:
-
每个实例(如
Instance 1、Instance 2)缓存一个连续的 ID 段(如Instance 1缓存1~100,Instance 2缓存101~200); -
当当前段用完,需要同步申请下一个段,此过程中服务会短暂不可用(因为没缓存可用 ID);
-
-
SegmentChain通过链表串联多个 ID 段,结合预加载解决基础模式的申请时不可用问题,核心逻辑如下:-
链结构设计。用链表(
SegmentChain)存储多个IdSegment(每个IdSegment是一个 ID 段):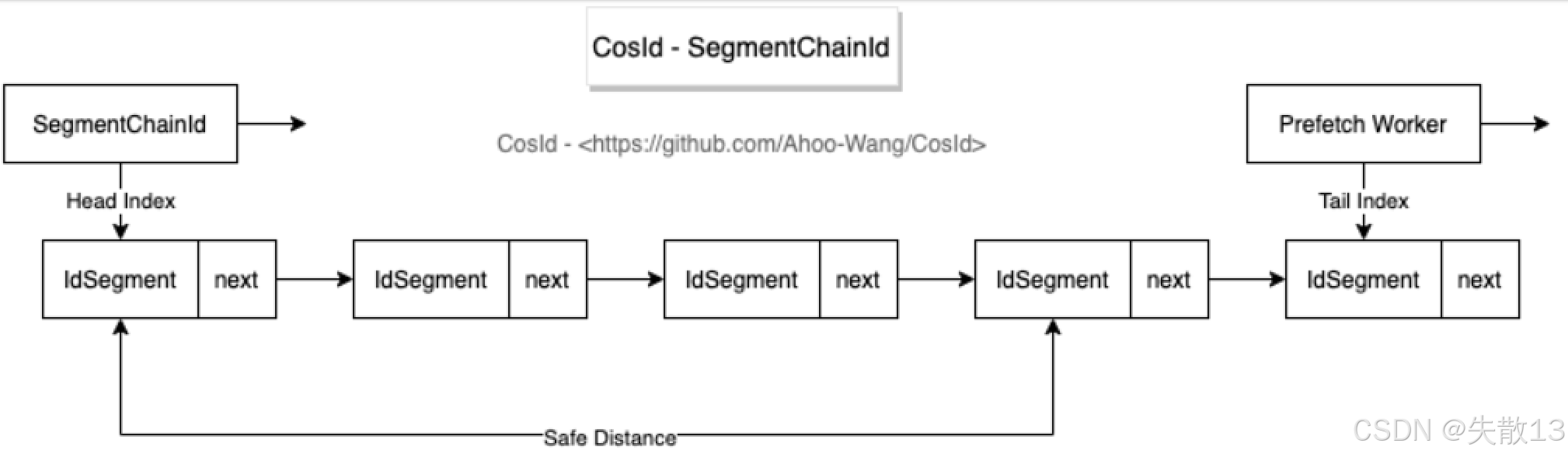
-
Head Index:当前正在分配 ID 的段(链表头);
-
Tail Index:链表尾部,用于预加载新段;
-
Pretch Worker:异步预加载线程,当链表中剩余段数少于“安全距离”时,自动申请新段添加到链表尾部;
-
-
核心参数:
-
NextMaxId:已分配的最大 ID(标记当前段的范围,如段1~100的NextMaxId是100); -
Step:每个IdSegment包含的 ID 数量(如示例中Step=100,则每个段有 100 个连续 ID); -
Safe Distance:“安全距离”,即链表中至少要保留的IdSegment数量(默认 10)。CosID 会保证链表中IdSegment数量不低于此值,避免预加载不及时;
-
-
-
使用起来很简单,只需修改一个配置即可切换到
SegmentChain模式:cosid.segment.mode=chain -
其他的单元测试和配置都不需要再做任何额外的改动,运行后就能同样拿到100个ID。不过在执行完 DistIDApp 的单元测试(
3.1 搭建CosID测试应用)后,CosID 表中的数据变成了这样: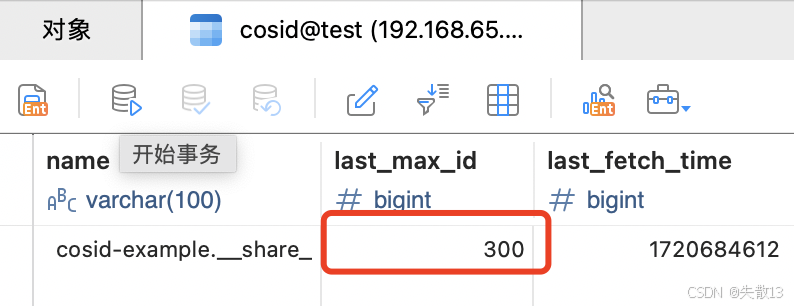
-
为什么
last_max_id=300?因为预加载了 3 个段(每个段Step=100,100×3=300),这两个参数也可以通过配置文件进行定制:# 安全距离,segment缓存数量(默认2) cosid.segment.chain.safe-distance=10 # 步数,每个segment里的ID数量(默认10) cosid.segment.share.step=100
-
3.5 Segment机制源码解析
-
CosID 框架是怎么实现 Segment 模式的呢?同样可以从一个简单的单元测试案例入手;
@Resource private SegmentId segmentId;@Test public void getId(){for (int i = 0; i < 100; i++) {System.out.println(segmentId.generate());} }- 也就是说,CosID 框架实现 Segment 模式的核心,是往 Spring 的 IOC 容器中注入的这个 SegmentID 实例;
-
接下来就来看看这个实例是怎么创建的:
//me.ahoo.cosid.spring.boot.starter.segment.SegmentIdBeanRegistrar private static SegmentId createSegment(SegmentIdProperties segmentIdProperties, SegmentIdProperties.IdDefinition idDefinition, IdSegmentDistributor idSegmentDistributor,PrefetchWorkerExecutorService prefetchWorkerExecutorService) {// 获取TTL(Time To Live)配置,优先使用ID定义中的TTL,否则使用全局默认TTLlong ttl = MoreObjects.firstNonNull(idDefinition.getTtl(), segmentIdProperties.getTtl());// 获取模式配置,优先使用ID定义中的模式,否则使用全局默认模式SegmentIdProperties.Mode mode = MoreObjects.firstNonNull(idDefinition.getMode(), segmentIdProperties.getMode());// 构建SegmentID实例SegmentId segmentId;if (SegmentIdProperties.Mode.SEGMENT.equals(mode)) {// 创建简单的Segment模式实例(单段模式)segmentId = new DefaultSegmentId(ttl, idSegmentDistributor);} else {// 创建SegmentChain模式实例(链式模式)SegmentIdProperties.Chain chain = MoreObjects.firstNonNull(idDefinition.getChain(), segmentIdProperties.getChain());segmentId = new SegmentChainId(ttl, chain.getSafeDistance(), idSegmentDistributor, prefetchWorkerExecutorService);}// 获取ID转换器配置IdConverterDefinition converterDefinition = idDefinition.getConverter();// 使用装饰器模式为SegmentId添加转换器功能,并返回装饰后的实例return new SegmentIdConverterDecorator(segmentId, converterDefinition).decorate(); }- 可以看到。在创建 SegmentID 实例时,会根据配置信息选择创建 DefaultSegmentId 还是 SegmentChainId;
- 其中 DefaultSegmentId 就是单 Segment 模式的分发器,而 SegmentChainId 自然就是 SegmentChain 模式的分发器;
-
接下来,将这个 SegmentID 实例注入到 Spring 的 IOC 容器中,同时保存到 idGeneratorProvider 中:
//me.ahoo.cosid.spring.boot.starter.segment.SegmentIdBeanRegistrar private void registerSegmentId(String name, SegmentId segmentId) {// 检查ID生成器提供者中是否已存在同名的生成器if (!idGeneratorProvider.get(name).isPresent()) {// 如果不存在,将SegmentId注册到全局ID生成器提供者中idGeneratorProvider.set(name, segmentId);}// 生成Bean名称:在原始名称后添加"SegmentId"后缀String beanName = name + "SegmentId";// 将SegmentId实例注册到Spring应用上下文的Bean工厂中作为单例BeanapplicationContext.getBeanFactory().registerSingleton(beanName, segmentId); } -
了解了这个工作机制后,再来看看 ID 是如何分发的;
-
首先来看 Segment 模式的实现方式:获取号段之后本地分配,本地分配完了再去重新申请
//me.ahoo.cosid.segment.DefaultSegmentId public long generate() {// 如果步长为1(即每次只分配一个ID),直接获取下一个最大IDif (this.maxIdDistributor.getStep() == 1L) {// 设置分组访问器(如果从未设置过)GroupedAccessor.setIfNotNever(this.maxIdDistributor.group());// 直接返回下一个最大IDreturn this.maxIdDistributor.nextMaxId();} else {long nextSeq;// 检查当前号段是否还有可用IDif (this.segment.isAvailable()) {// 从当前号段中递增获取下一个序列号nextSeq = this.segment.incrementAndGet();// 检查是否超出当前号段范围if (!this.segment.isOverflow(nextSeq)) {return nextSeq; // 返回有效的序列号}}// 当前号段已用完,需要同步获取新的号段synchronized(this) {while(true) {// 双重检查:再次检查当前号段是否可用(可能已被其他线程更新)if (this.segment.isAvailable()) {nextSeq = this.segment.incrementAndGet();if (!this.segment.isOverflow(nextSeq)) {return nextSeq;}}// 从分布式分配器获取下一个号段IdSegment nextIdSegment = this.maxIdDistributor.nextIdSegment(this.idSegmentTtl);// 如果不允许重置,确保新号段是连续递增的if (!this.maxIdDistributor.allowReset()) {this.segment.ensureNextIdSegment(nextIdSegment);}// 更新当前号段为新获取的号段this.segment = nextIdSegment;}}} } -
接下来看看 SegmentChain 模式分发ID的实现方式:
//me.ahoo.cosid.segment.SegmentChainId public long generate() {while(true) {// 遍历链表,查找可用的号段链节点for(IdSegmentChain currentChain = this.headChain; currentChain != null; currentChain = currentChain.getNext()) {if (currentChain.isAvailable()) {// 从可用节点中递增获取下一个序列号long nextSeq = currentChain.incrementAndGet();if (!currentChain.isOverflow(nextSeq)) {// 将当前节点前移到链表头部(LRU策略)this.forward(currentChain);return nextSeq; // 返回生成的ID}}}// 如果链表中的所有号段都已用完,需要添加新的号段链节点try {IdSegmentChain preIdSegmentChain = this.headChain;// 尝试在当前链表末尾添加新的号段链节点if (preIdSegmentChain.trySetNext((preChain) -> {// 生成下一个号段链节点,并保持安全距离return this.generateNext(preChain, this.safeDistance);})) {// 获取新添加的节点IdSegmentChain nextChain = preIdSegmentChain.getNext();// 将新节点前移到链表头部this.forward(nextChain);if (log.isDebugEnabled()) {log.debug("Generate [{}] - headChain.version:[{}->{}].", new Object[]{this.maxIdDistributor.getNamespacedName(), preIdSegmentChain.getVersion(), nextChain.getVersion()});}}} catch (NextIdSegmentExpiredException var4) {// 处理号段过期异常(可能由于分布式协调冲突)NextIdSegmentExpiredException nextIdSegmentExpiredException = var4;if (log.isWarnEnabled()) {log.warn("Generate [{}] - gave up this next IdSegmentChain.", this.maxIdDistributor.getNamespacedName(), nextIdSegmentExpiredException);}}// 触发预取服务,检查并补充链表上的号段,确保充足供应this.prefetchJob.hungry();} }- CosID 在后台会启动一个线程池 PrefetchWorker,异步进行链表扩充。而具体进行链表扩充的方法,就是
prefetchJob()方法;
- CosID 在后台会启动一个线程池 PrefetchWorker,异步进行链表扩充。而具体进行链表扩充的方法,就是
-
最终核心的扩充 Segment 的逻辑如下:
//me.ahoo.cosid.segment.SegmentChainId#PrefetchJob public class PrefetchJob implements AffinityJob {public void prefetch() {// 计算上次饥饿时间到现在的间隔(秒)long wakeupTimeGap = Clock.SYSTEM.secondTime() - this.lastHungerTime;// 判断是否处于饥饿状态(5秒内有饥饿触发)boolean hunger = wakeupTimeGap < 5L;// 保存当前的预取距离用于日志记录int prePrefetchDistance = this.prefetchDistance;// 根据饥饿状态动态调整预取距离if (hunger) {// 饥饿时:倍增预取距离(最大不超过1亿),提高供应量this.prefetchDistance = Math.min(Math.multiplyExact(this.prefetchDistance, 2), 100000000);if (SegmentChainId.log.isInfoEnabled()) {SegmentChainId.log.info("Prefetch [{}] - Hunger, Safety distance expansion.[{}->{}]", new Object[]{SegmentChainId.this.maxIdDistributor.getNamespacedName(), prePrefetchDistance, this.prefetchDistance});}} else {// 饱腹时:减半预取距离(最小不低于安全距离),避免资源浪费this.prefetchDistance = Math.max(Math.floorDiv(this.prefetchDistance, 2), SegmentChainId.this.safeDistance);if (prePrefetchDistance > this.prefetchDistance && SegmentChainId.log.isInfoEnabled()) {SegmentChainId.log.info("Prefetch [{}] - Full, Safety distance shrinks.[{}->{}]", new Object[]{SegmentChainId.this.maxIdDistributor.getNamespacedName(), prePrefetchDistance, this.prefetchDistance});}}// 从头节点开始查找第一个可用的号段链节点IdSegmentChain availableHeadChain = SegmentChainId.this.headChain;while(!availableHeadChain.getIdSegment().isAvailable()) {availableHeadChain = availableHeadChain.getNext();if (availableHeadChain == null) {// 如果所有节点都不可用,使用尾节点availableHeadChain = this.tailChain;break;}}// 将找到的可用节点前移到链表头部(LRU策略)SegmentChainId.this.forward(availableHeadChain);// 计算从可用头节点到尾节点的号段数量差距int headToTailGap = availableHeadChain.gap(this.tailChain, SegmentChainId.this.maxIdDistributor.getStep());// 计算当前号段数量与安全距离之间的差距int safeGap = SegmentChainId.this.safeDistance - headToTailGap;// 如果号段数量充足且不处于饥饿状态,不需要预取if (safeGap <= 0 && !hunger) {if (SegmentChainId.log.isTraceEnabled()) {SegmentChainId.log.trace("Prefetch [{}] - safeGap is less than or equal to 0, and is not hungry - headChain.version:[{}] - tailChain.version:[{}].", new Object[]{SegmentChainId.this.maxIdDistributor.getNamespacedName(), availableHeadChain.getVersion(), this.tailChain.getVersion()});}} else {// 计算需要预取的号段数量:饥饿时使用动态预取距离,否则使用安全差距int prefetchSegments = hunger ? this.prefetchDistance : safeGap;// 申请并添加新的号段到链表尾部this.appendChain(availableHeadChain, prefetchSegments);}} }- 这里核心的hungry模式,其实就是用来保证数据库不可用时,也还是用自己的 SegmentChain 先撑着。只要数据库可用,马上开始扩充Segment。
3.6 基于JDBC的ID分发机制实现分析
-
在实际构建新的 Segment 时,需要注册一个
IdSegmentDistributor接口,来计算新 Segment 的maxId。这个接口的具体实现,就会交由与各种第三方服务集成的扩展组件去完成。例如基于 JDBC 的 ID 分发器提供的实现类是JdbcIdSegmentDistributor,其具体实现是这样的://me.ahoo.cosid.jdbc.JdbcIdSegmentDistributor @Override public long nextMaxId(long step) {// 验证步长参数的有效性(必须大于0)IdSegmentDistributor.ensureStep(step);try (Connection connection = dataSource.getConnection()) {// 关闭自动提交,开启事务connection.setAutoCommit(false);// 第一步:更新最大ID值(原子性递增)try (PreparedStatement accStatement = connection.prepareStatement(incrementMaxIdSql)) {accStatement.setLong(1, step); // 设置步长accStatement.setString(2, getNamespacedName()); // 设置命名空间名称int affected = accStatement.executeUpdate();// 检查是否成功更新(如果没有影响行数,说明该命名空间不存在)if (affected == 0) {throw new SegmentNameMissingException(getNamespacedName());}}// 第二步:获取更新后的最大ID值long nextMaxId;try (PreparedStatement fetchStatement = connection.prepareStatement(fetchMaxIdSql)) {fetchStatement.setString(1, getNamespacedName()); // 设置命名空间名称try (ResultSet resultSet = fetchStatement.executeQuery()) {if (!resultSet.next()) {// 如果查询不到结果,抛出异常throw new NotFoundMaxIdException(getNamespacedName());}nextMaxId = resultSet.getLong(1); // 获取第一列的最大ID值}}// 提交事务connection.commit();return nextMaxId;} catch (SQLException sqlException) {// 处理数据库异常,记录错误日志并转换为运行时异常if (log.isErrorEnabled()) {log.error(sqlException.getMessage(), sqlException);}throw new CosIdException(sqlException.getMessage(), sqlException);} } -
如果上面的逻辑实现理解起来较困难,那么可以试着看懂下面两条 SQL 语句:
/*** 递增最大ID的SQL更新语句* 参数1: ? - 步长(step),表示要递增的数量* 参数2: ? - 名称(name),对应命名空间标识* 作用:原子性地增加指定命名空间的last_max_id,并更新最后获取时间*/ public static final String INCREMENT_MAX_ID_SQL= "update cosid set last_max_id=(last_max_id + ?),last_fetch_time=unix_timestamp() where name = ?;";/*** 获取最大ID的SQL查询语句* 参数1: ? - 名称(name),对应命名空间标识* 作用:查询指定命名空间当前的最大ID值*/ public static final String FETCH_MAX_ID_SQL= "select last_max_id from cosid where name = ?;";