C++ 二叉搜索树的详解与实现
一、二叉搜索树的概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值。
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值。
- 它的左右子树也分别为二叉搜索树。
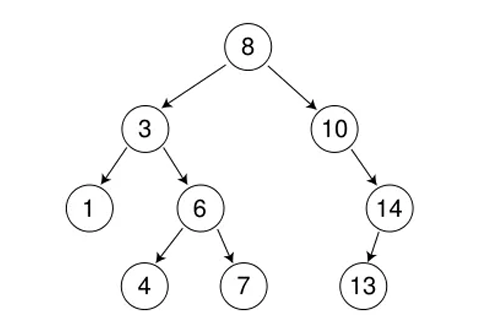
二、二叉搜索树的操作
(一)代码框架
#include <iostream> using namespace std;template <class K> struct BSTNode {BSTNode(const K& key):_left(nullptr),_right(nullptr),_key(key){ }BSTNode<K>* _left;BSTNode<K>* _right;K key; };template <class K> class BSTree {typedef BSTNode<K> Node; public:BSTree():_root(nullptr){} private:Node* _root; };(二)查找操作
从根开始比较、查找,比根大则往右边走,比根小则往左边走,最多查找高度次,走到为空还没找到的话,就是该值不存在。
1.非递归实现
bool Find(const K& key) {Node* cur = _root;while (cur){if (key > cur->_key){cur = cur->_right;}else if (key < cur->_key){cur = cur->_left;}else{return true;}}return false; }从根节点开始,根据要查找的值与当前节点值的大小关系,决定向左子树还是右子树查找,直到找到或遍历到空节点。
2.递归实现
public:bool FindR(const K& key){return _FindR(_root, key);} private:bool _FindR(Node* root, const K& key){if (root == nullptr) return false;if (key > root->_key){return _FindR(root->_right, key);}else if (key < root->_key){return _FindR(root->_left, key);}else{return true;}}递归的逻辑同样根据值的大小关系,递归地在左子树或右子树中查找,直到找到或到达空节点。
(三)插入操作
如果树为空,则直接新增一个节点,直接赋值给
root指针;如果树不为空,按照二叉搜索树的性质查找插入位置,并同时更新
parent位置,方便最后的链接。注意最后找到插入位置时还要先判断该插入位置是在parent的左还是右。1.非递归实现
bool Insert(const K& key) {if (_root == nullptr){_root = new Node(key);}Node* cur = _root;Node* parent = nullptr;while (cur){if (key > cur->_key){parent = cur;cur = cur->_right;}else if (key < cur->_key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key);if (key > parent->_key){parent->_right = cur;}else{parent->_left = cur;}return true; }先处理空树的情况,直接创建根节点。否则,从根开始查找合适的插入位置,记录父节点,最后根据值的大小将新节点链接到父节点的左或右子树。
2.递归实现
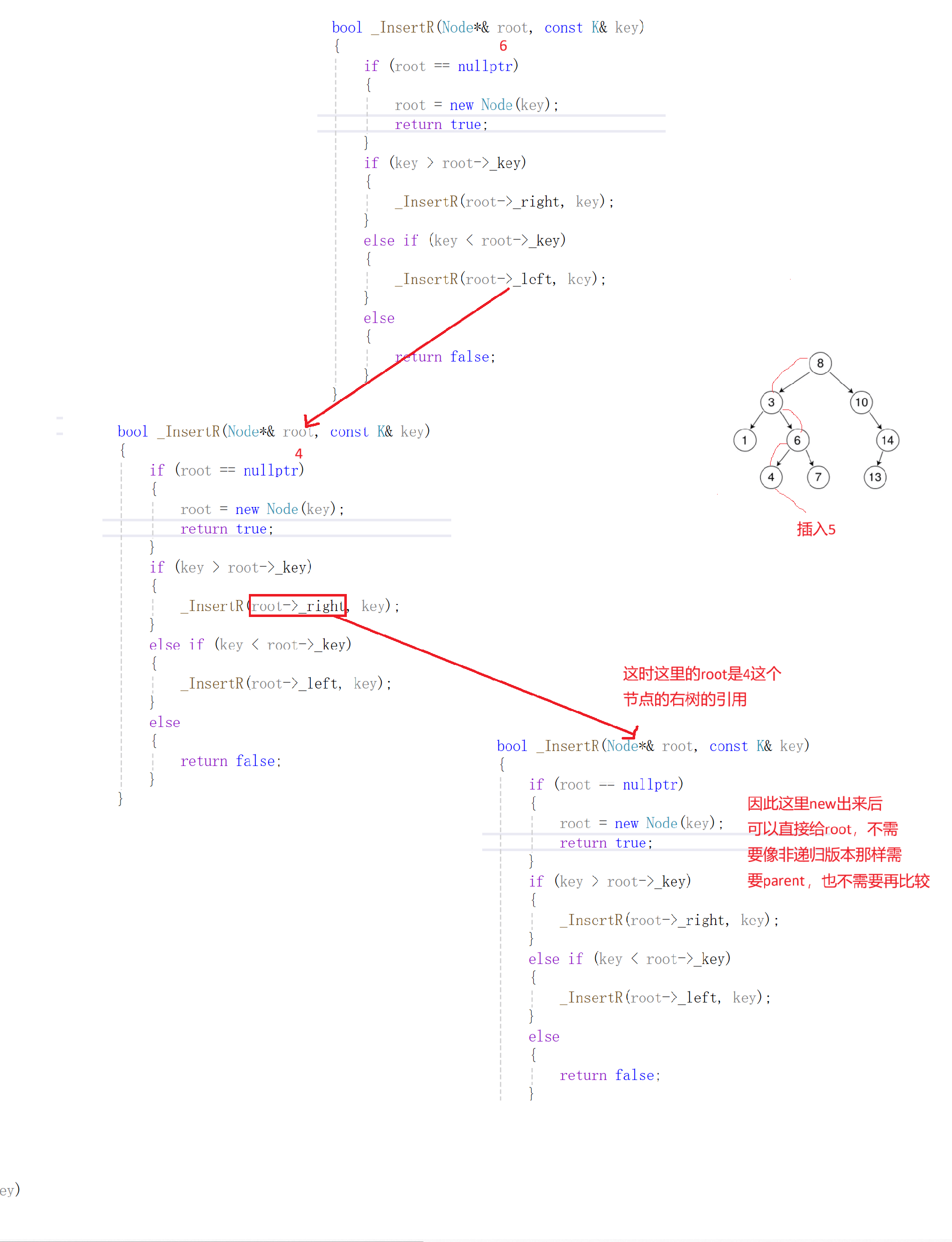
public:bool InsertR(const K& key){return _InsertR(_root, key);} private:bool _InsertR(Node*& root, const K& key){if (root == nullptr){root = new Node(key);return true;}if (key > root->_key){return _InsertR(root->_right, key);}else if (key < root->_key){return _InsertR(root->_left, key);}else{return false;}}
这里传指针引用是关键!因为在递归过程中,当需要在某个子树中插入新节点时,通过传递指针的引用,我们可以直接修改该子树的根指针(比如
root->_left或root->_right)。这样就无需像非递归版本那样,额外维护parent指针来记录父节点,从而大大减少了代码量,让插入逻辑更加简洁。(四)删除操作(重点)
首先查找元素是否在二叉搜索树中,如果不存在,则返回,否则要删除的节点可能分下面四种情况:
- 要删除的结点无孩子结点。
- 要删除的结点只有左孩子结点。
- 要删除的结点只有右孩子结点。
- 要删除的结点有左、右孩子结点。
看起来要删除的有四种情况,实际上前三种可以合并起来,因此真正删除的过程如下:
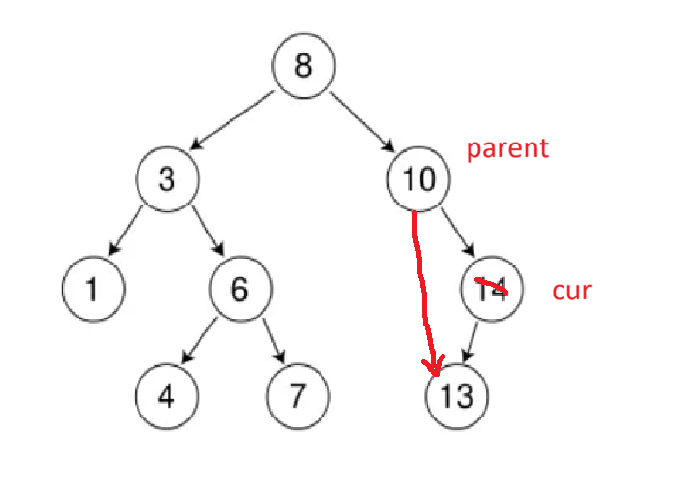
- 情况一:删除该结点且使被删除节点的双亲结点指向被删除节点的左孩子结点 - 直接删除(要删除的节点右树为空)。例如:如图要删除14,当找到14后,只需让parent的右指针指向cur(14)的左。
- 情况二:删除该结点且使被删除节点的双亲结点指向被删除节点的右孩子结点 - 直接删除(要删除的节点左树为空)。
还有一种特殊情形,如要删除的节点是根且根的左树为空,由于删除操作需要依赖父节点(
parent)的指针调整,但是这种情况下parent为nullptr,所以必须单独处理根节点被删除的情况,直接让root = cur->_right即可。
情况一和二的代码如下:

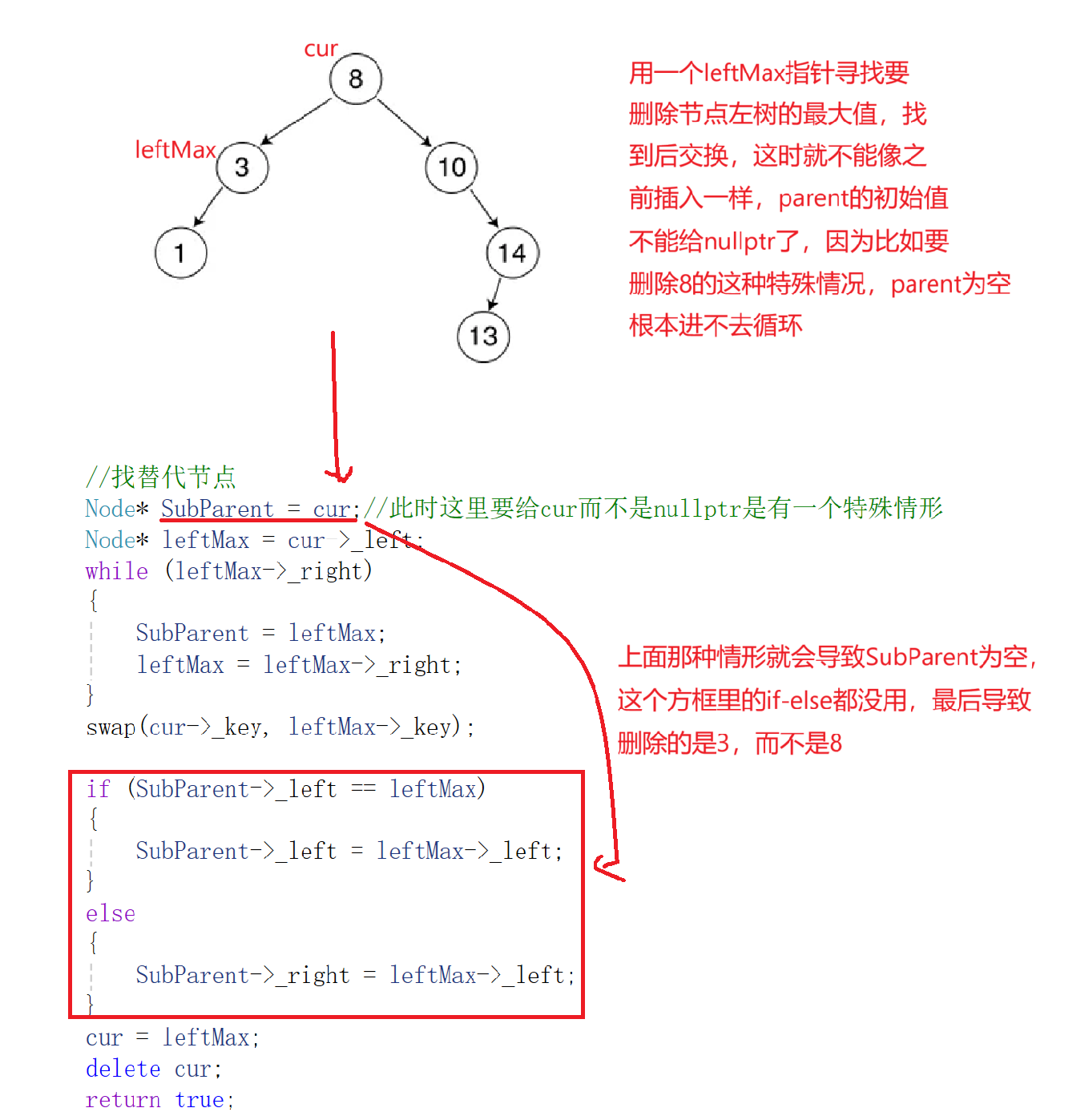
情况三:在它的右子树中寻找中序下的第一个结点或者
在左树寻找中序下最大的数这样才能保证替代后还能保持二叉搜索树的特性,用它的值填补到被删除节点中,再来处理该结点的删除问题--替换法删除(要删除的节点左右树都不为空)。该情况的思路就是,找到要删除节点的左树的最大值与要删除的该节点交换,最后的删除leftMax与情况一和二一样。
如图:SubParent初始值没有给nullptr的原因。
1.非递归实现
bool Erase(const K& key){//1、先寻找被删除节点Node* cur = _root;Node* parent = cur;while (cur){if (key > cur->_key){parent = cur;cur = cur->_right;}else if (key < cur->_key){parent = cur;cur = cur->_left;}else{//2、判断 右树为空 左树为空 左右树都不为空 这三种情况if (cur->_right == nullptr){//易错点:当要删除的恰好是根,且根的右子树为空if (cur == _root){_root = cur->_left;}else{if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}delete cur;return true;}else if (cur->_left == nullptr){//易错点:当要删除的恰好是根,且根的左子树为空if (cur == _root){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}delete cur;return true;}else{Node* SubParent = cur; //易错点,不能给成空Node* LeftMax = cur->_left;while (LeftMax->_right){SubParent = LeftMax;LeftMax = LeftMax->_right;}swap(LeftMax->_key, cur->_key);if (SubParent->_left == LeftMax){SubParent->_left = LeftMax->_left;}else{SubParent->_right = LeftMax->_left;}delete LeftMax;return true;}}}return false;}先查找要删除的节点,找到后根据节点的子节点情况进行不同的处理。子节点为空或只有一个子节点时,直接调整父节点的指针;有两个子节点时,找到左子树的最右节点(或右子树的最左节点)来替代当前节点,再删除该替代节点。
2.递归实现
public:bool EraseR(const K& key){return _EraseR(_root, key);} private:bool _EraseR(Node*& root, const K& key){if (root == nullptr) return false;if (key > root->_key){return _EraseR(root->_right, key);}else if (key < root->_key){return _EraseR(root->_left, key);}else{Node* del = root;if (root->_left == nullptr){root = root->_right;}else if (root->_right == nullptr){root = root->_left;}else{Node* LeftMax = root->_left;while (LeftMax->_right) LeftMax = LeftMax->_right;swap(root->_key, LeftMax->_key);return _EraseR(root->_left, LeftMax->_key);}delete del;return true;}}同样,这里利用指针引用,在递归过程中可以直接修改子树的根指针,从而简洁地完成节点删除后子树的重新链接,避免了非递归版本中需要维护
parent指针的繁琐操作,减少了代码量。(四)其他操作
1.中序遍历
public:void InOrder(){_InOrder(_root);cout << endl;} private:void _InOrder(Node* root){if (root == nullptr) return;_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}中序遍历二叉搜索树可以得到一个有序的序列,这也是二叉搜索树 “排序树” 名称的由来。
2.拷贝构造与赋值运算符重载
public:BSTree(const BSTree<K>& t){_root = Copy(t._root);}BSTree& operator=(BSTree<K> t){swap(_root, t._root);return *this;} private:Node* Copy(Node* root){if (root == nullptr) return nullptr;Node* copyRoot = new Node(root->_key);copyRoot->_left = Copy(root->_left);copyRoot->_right = Copy(root->_right);return copyRoot;}通过递归的方式实现树的拷贝,赋值运算符重载则利用拷贝构造和交换操作实现。
3.析构函数
public:~BSTree(){Destroy(_root);} private:void Destroy(Node*& root){if (root == nullptr) return;Destroy(root->_left);Destroy(root->_right);delete root;root = nullptr;}递归地释放树中所有节点的内存,防止内存泄漏。

三、二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:
最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其平均比较次数为:
.
最差情况下,二叉搜索树退化为单支树(或者类似单支),其平均比较次数为:
.
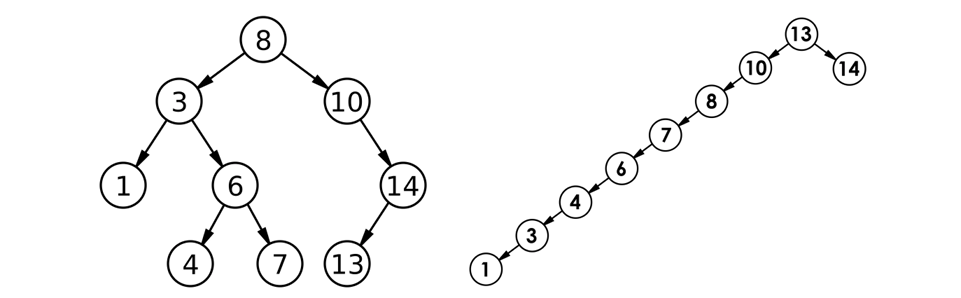
二叉搜索树是一种重要的数据结构,它利用自身的性质(左小右大),使得查找、插入、删除等操作可以在平均 O(log n) 的时间复杂度内完成(在树平衡的情况下)。递归实现中,指针引用的使用是关键技巧,它能让我们更简洁地处理子树的链接关系,减少代码量,提升代码的可读性和可维护性。同时,二叉搜索树的中序遍历结果是有序的,这一特性也有很多应用场景。